基于注意力機(jī)制的光線昏暗條件下口罩佩戴檢測
2022-01-26 12:43:18王邱龍
電子科技大學(xué)學(xué)報(bào) 2022年1期
郭 磊,王邱龍,薛 偉,郭 濟(jì)
(1.電子科技大學(xué)計(jì)算機(jī)科學(xué)與工程學(xué)院 成都 611731;2.新疆大學(xué)信息科學(xué)與工程學(xué)院 烏魯木齊 830000;3.西藏民族大學(xué)財(cái)經(jīng)學(xué)院 陜西 咸陽 712082)
新冠肺炎疫情爆發(fā)后,人類健康受到巨大威脅,人們正常的工作與生活也受到了極大影響。為避免新冠肺炎疫情傳播,規(guī)范佩戴口罩便成為了一項(xiàng)有效的防控手段。僅靠人工方式對流動人員進(jìn)行口罩佩戴檢測不僅效率低,且會耗費(fèi)大量人力物力,同時(shí)由于新冠肺炎病毒易發(fā)生變異,且傳染性極強(qiáng),因此,做好公共衛(wèi)生干預(yù)措施,檢測活動人員在各類車站、大型商場等公共場合的口罩佩戴情況,對疫情防控具有重要的現(xiàn)實(shí)意義。
基于深度學(xué)習(xí)的目標(biāo)檢測算法主要分為兩大類,一類是以R-CNN[1]、Fast-RCNN[2]等為代表的兩階段檢測算法,該類算法在特征提取的基礎(chǔ)上,由獨(dú)立的網(wǎng)絡(luò)分支先生成大量的候選區(qū),再對其進(jìn)行分類和回歸。另一類是以SSD[3]、YOLO 系列算法為代表的一階段檢測算法,該類算法在生成候選框的同時(shí)進(jìn)行分類和回歸任務(wù)。
針對口罩佩戴檢測這一特定問題,目前國內(nèi)外有許多學(xué)者進(jìn)行了研究。文獻(xiàn)[4]將ReinaNet 網(wǎng)絡(luò)應(yīng)用在口罩佩戴檢測上,在驗(yàn)證集上AP 達(dá)到86.5%。文獻(xiàn)[5]將YCrCb 方法引入YOLOv3 中,對正確佩戴口罩的識別準(zhǔn)確率達(dá)82.5%。文獻(xiàn)[6]在RetinaFace 算法上進(jìn)行改進(jìn),引入自注意力機(jī)制,檢測效果較好。AIZOO(https://github.com/aky 15/AIZOO_torch)也提出了一種基于Fast-RCNN 和YOLOv3 的目標(biāo)檢測方法,在口罩佩戴檢測任務(wù)上取得了不錯(cuò)的成績,但在可見度不高、光照強(qiáng)度不強(qiáng)的昏暗條件下,其檢測精度仍有待提高。
本文主要針對在可見度不高、光線昏暗的場景下,利用圖像增強(qiáng)算法對圖片進(jìn)行預(yù)處理,將通道注意力和空間注意力結(jié)合,充分挖掘人臉口罩等關(guān)鍵特征點(diǎn),同時(shí)對YOLOv5 網(wǎng)絡(luò)的損失函數(shù)進(jìn)行相應(yīng)的改進(jìn),提高模型在昏暗條件下的魯棒性。
1 YOLOv5 模型簡介
YOLO 是一個(gè)基于深度神經(jīng)網(wǎng)絡(luò)的目標(biāo)識別定位算法,其最大的特點(diǎn)是運(yùn)行速度快,且檢測精度較好,能運(yùn)用于實(shí)時(shí)系統(tǒng),現(xiàn)在YOLO 系列已經(jīng)發(fā)展到v5 版本。YOLOv1[7]將目標(biāo)檢測問題看作空間上的多個(gè)邊界框和與邊界框?qū)?yīng)類別概率的回歸問題,令人耳目一新。隨后,YOLOv2[8]引入批量標(biāo)準(zhǔn)化方法,使用高分辨率圖像微調(diào)分類模型,采用先驗(yàn)框并使用聚類提取先驗(yàn)框尺度,約束先驗(yàn)框尺度等多種技巧,使得預(yù)測更加準(zhǔn)確、檢測速度更快、識別對象更多,由于YOLOv2 能識別并定位9 000 種不同的對象,因此也被稱為YOLO9000。YOLOv3[9]使用Darknet53網(wǎng)絡(luò)作為骨干網(wǎng)絡(luò)完成對圖像的特征提取,并利用多尺度特征進(jìn)行對象檢測,加速了目標(biāo)檢測在工業(yè)界的落地。YOLOv4[10]設(shè)計(jì)了一種強(qiáng)大而高效的目標(biāo)檢測模型,使得其能夠在在一塊普通的GPU(如GTX1080Ti)上訓(xùn)練超快而精準(zhǔn)的目標(biāo)檢測器。YOLOv5 與YOLOv4 相比,結(jié)構(gòu)更加小巧,配置更加靈活,圖像推理速度更快,能夠更好地滿足視頻圖像實(shí)時(shí)性檢測的需求。YOLOv5 自身也有其版本迭代,現(xiàn)已更迭至v5.0 版本,本文使用最新版本v5.0。YOLOv5 算法具有4 個(gè)大小不同的模型,具體包括:YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x。本文使用YOLOv5s,其他的版本都是在該版本的基礎(chǔ)上對網(wǎng)絡(luò)進(jìn)行加深與加寬,可以通過配置文件方便地進(jìn)行修改。
YOLOv5 的網(wǎng)絡(luò)結(jié)構(gòu)如圖1 所示,對于一個(gè)通用的目標(biāo)檢測算法而言,主要分為4 個(gè)基礎(chǔ)組件:輸入端、基準(zhǔn)Backbone 骨干網(wǎng)絡(luò)、Neck 網(wǎng)絡(luò)與Head 輸出端。其中輸入端表示要輸入的圖片。在輸入端中通常會對原始圖片進(jìn)行相應(yīng)的預(yù)處理,即對輸入圖像縮放到網(wǎng)絡(luò)的輸入大小,并采取歸一化等操作,最終轉(zhuǎn)化為640×640×3 的張量輸入到網(wǎng)絡(luò)中。在YOLOv5 中,還使用了Mosaic數(shù)據(jù)增強(qiáng)操作來提升模型的訓(xùn)練速度和網(wǎng)絡(luò)的精度。基準(zhǔn)Backbone 骨干網(wǎng)絡(luò)主要用來提取圖片中的某些特征供后面的網(wǎng)絡(luò)使用,通常采用Resnet、VGG 等典型網(wǎng)絡(luò)。YOLOv5 中使用的是CSPDarknet53[11]結(jié)構(gòu),并刪除了先前版本中的BottleneckCSP 中的部分Conv 模塊,經(jīng)過改進(jìn)后的BottleneckCSP 稱為C3 模塊,它將梯度的變化從頭到尾地集中到特征圖中,使得YOLOv5 網(wǎng)絡(luò)能夠具有很好的學(xué)習(xí)能力,能夠在輕量化的同時(shí)保持較好的準(zhǔn)確率,同時(shí)降低了計(jì)算瓶頸和內(nèi)存成本,在YOLOv5 中有兩種C3 模塊,以有無殘差邊為標(biāo)準(zhǔn),分為C3-False 和C3-True。YOLOv5還在Backbone 骨干網(wǎng)絡(luò)中引入了Focus 模塊,它與4 個(gè)Conv 模塊實(shí)現(xiàn)對輸入圖片的32 倍下采樣。Focus 模塊將輸入圖像進(jìn)行切片操作,每隔一個(gè)像素取一個(gè)值,與鄰近下采樣類似,將原始圖像數(shù)據(jù)切分為4 份數(shù)據(jù),接著在通道維度上進(jìn)行拼接,最后進(jìn)行卷積操作。這一過程將圖片長、寬維度上的信息集中到了通道維度,因此沒有造成信息的丟失,F(xiàn)ocus 模塊減少了卷積的成本,用重置張量維度的方法巧妙地實(shí)現(xiàn)了下采樣并增加了通道維數(shù)。Neck 網(wǎng)絡(luò)通常位于基準(zhǔn)Backbone 網(wǎng)絡(luò)和Head 網(wǎng)絡(luò)的中間位置,利用它可以進(jìn)一步提升特征的多樣性及魯棒性,更好地利用Backbone 網(wǎng)絡(luò)提取到的特征,YOLOv5 中使用 了 SPP(spatial pyramid pooling)[12]模 塊、FPN(feature pyramid network)[13]模 塊、PAN(path aggregation network)[14]模塊完成信息的傳遞融合。Head 輸出層主要利用之前提取的特征做出預(yù)測。
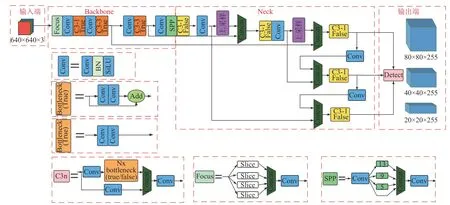
圖1 YOLO 網(wǎng)絡(luò)結(jié)構(gòu)圖
2 改進(jìn)后的網(wǎng)絡(luò)模型
YOLO 系列算法已在長期的實(shí)踐中被證明是一個(gè)優(yōu)秀的目標(biāo)檢測算法,YOLOv5 更是在其內(nèi)部針對目標(biāo)檢測中的各種常見問題做出了較大的優(yōu)化改進(jìn),因此本文選擇YOLOv5 作為口罩佩戴檢測模型的基礎(chǔ)網(wǎng)絡(luò)是可行的。注意力機(jī)制最早在2014年率先被Google Deep Mind 團(tuán)隊(duì)引入RNN 模型上來實(shí)現(xiàn)圖像的分類[15],實(shí)現(xiàn)了圖像中多個(gè)物體對象的高效準(zhǔn)確的識別。在卷積神經(jīng)網(wǎng)絡(luò)中,注意力機(jī)制作用在特征圖上,通過獲取特征圖中的可用注意力信息,能夠達(dá)到更好的任務(wù)效果[16]。
在昏暗條件下,光照強(qiáng)度不大,可見度低,難以對人臉進(jìn)行精確定位,口罩佩戴檢測任務(wù)的難度也更為困難,因此需要對YOLOv5 網(wǎng)絡(luò)做進(jìn)一步的結(jié)構(gòu)優(yōu)化和調(diào)整。
2.1 損失函數(shù)
在目標(biāo)檢測中,損失函數(shù)通常由定位損失、分類損失和置信度損失3 部分組成,如式(1)所示。常見的計(jì)算定位損失函數(shù)有GIOU Loss[17]、DIOU Loss[18]和CIOU Loss[19],經(jīng)過對比實(shí)驗(yàn),本文使用CIOU Loss 來計(jì)算目標(biāo)框的定位損失:
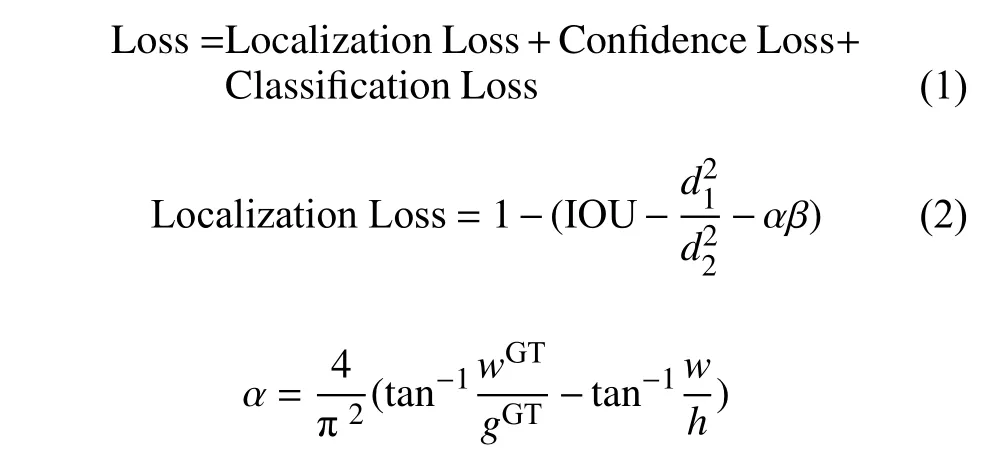
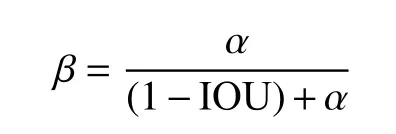
式中,IOU 是預(yù)測框與真實(shí)框GT(ground truth)的重疊面積;d1是預(yù)測框中心點(diǎn)到真實(shí)框中心點(diǎn)的距離;d2是覆蓋預(yù)測框與真實(shí)框的最小外接矩形的對角線長度。
可以看出CIOU Loss 不僅考慮了預(yù)測框與真實(shí)框的重疊面積,還兼顧了兩者中心點(diǎn)之間的距離和兩者的長寬比,因此在口罩佩戴檢測實(shí)例中,表現(xiàn)比其他兩種定位損失更好。針對置信度損失和分類損失,實(shí)驗(yàn)中采用交叉熵?fù)p失函數(shù)進(jìn)行計(jì)算,分別如式(3)和式(4)所示,采用交叉熵?fù)p失函數(shù)能使得網(wǎng)絡(luò)中的參數(shù)更新加快,讓模型更快地達(dá)到收斂狀態(tài)。
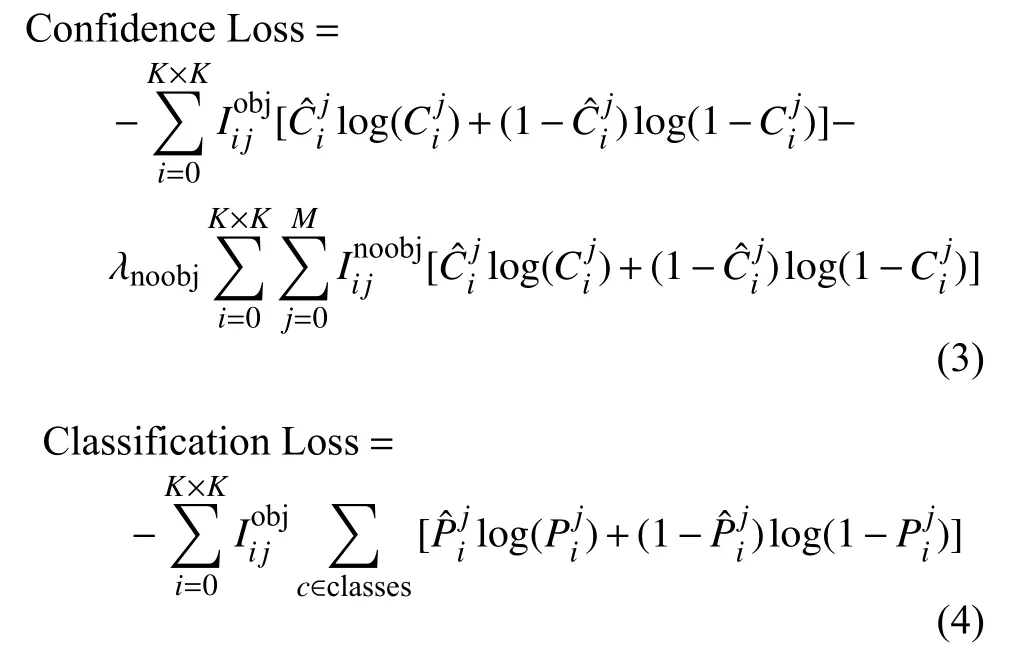
2.2 卷積注意力模塊
在原始的YOLOv5 網(wǎng)絡(luò)的基礎(chǔ)上,添加卷積注意力模塊(convolutional block attention module,CBAM)[20]。CBAM 是一種用于前饋卷積神經(jīng)網(wǎng)絡(luò)的簡單且有效的注意力模塊,它能將給定的特征圖依次沿著通道注意力模塊(channel attention module,CAM)和空間注意力模塊(spatial attention module,SAM)推斷出注意力圖,然后將輸入特征圖與注意力圖相乘進(jìn)行自適應(yīng)特征優(yōu)化,突出主要特征,抑制無關(guān)特征,從而使網(wǎng)絡(luò)更加關(guān)注需要檢測目標(biāo)的內(nèi)容信息和位置信息,以提高網(wǎng)絡(luò)的檢測精度。CBAM整體結(jié)構(gòu)如圖2 所示。
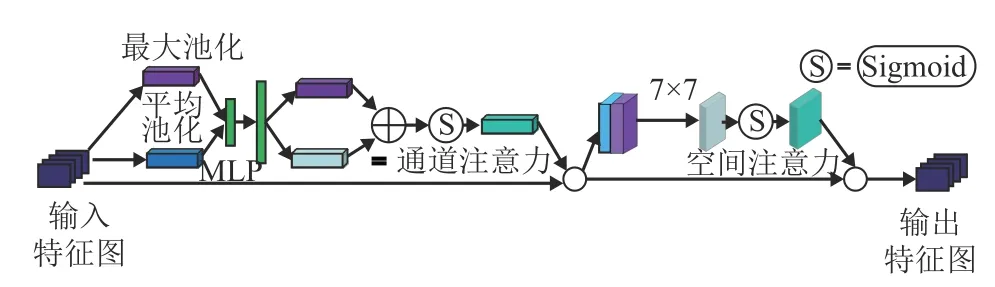
圖2 CBAM 網(wǎng)絡(luò)結(jié)構(gòu)
在CAM 中,特征圖的每一個(gè)通道都可以看成是一個(gè)特征檢測器。通道注意力模塊關(guān)注的是特征在通道與通道之間的關(guān)系,主要提取輸入圖像中有意義的內(nèi)容信息,壓縮輸入特征圖的空間信息。對給定特征圖F∈RC×H×W,采用全局平均池化和全局最大池化,分別生成兩個(gè)不同的空間信息描述特征圖Favg∈RC×1×1和Fmax∈RC×1×1,再將這兩個(gè)特征圖送入一個(gè)含有一個(gè)隱藏層的多層感知機(jī)的共享網(wǎng)絡(luò)中進(jìn)行計(jì)算得到通道注意力圖,最后通過點(diǎn)像素逐位相加將共享網(wǎng)絡(luò)輸出的兩個(gè)向量融合得到最終的通道注意力特征圖Mc∈RC×1×1。CAM的結(jié)構(gòu)如圖3所示。
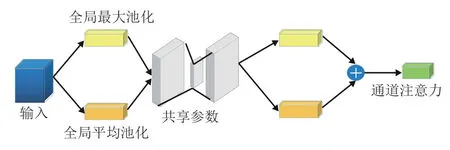
圖3 CAM 結(jié)構(gòu)
SAM 更關(guān)注特征在空間上的關(guān)系,主要提取輸入圖像中目標(biāo)的位置信息,與通道注意力模塊相互補(bǔ)充。它將CAM 的輸出特征圖作為本模塊的輸出特征圖。它首先做一個(gè)基于通道的全局最大池化和全局平均池化,分別得到∈R1×H×W和∈R1×H×W兩個(gè)特征圖,然后將這兩個(gè)特征圖串聯(lián),基于通道做拼接操作,再經(jīng)過一個(gè)7×7 卷積操作生成空間注意力特征Ms∈R1×H×W。SAM 的結(jié)構(gòu)如圖4 所示。
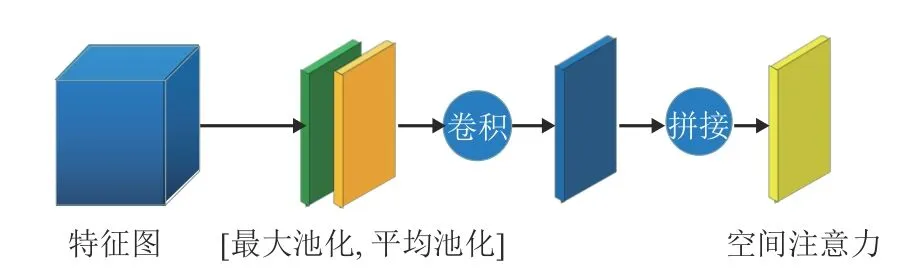
圖4 SAM 結(jié)構(gòu)
由于CBAM 模型在CAM 中加入了全局最大池化操作,它能在一定程度上彌補(bǔ)了全局平均池化所丟失的信息。其次,生成的二維空間注意力圖使用卷積核大小為7 的卷積層進(jìn)行編碼,較大的卷積核對于保留重要的空間區(qū)域有良好的幫助。添加了CBAM 的YOLOv5 網(wǎng)絡(luò)不僅能更準(zhǔn)確地對目標(biāo)進(jìn)行分類識別,而且能更精準(zhǔn)地定位目標(biāo)所在的位置。
3 實(shí)驗(yàn)與結(jié)果分析
3.1 數(shù)據(jù)集及實(shí)驗(yàn)環(huán)境介紹
目前開源的口罩佩戴檢測數(shù)據(jù)集較少,因此實(shí)驗(yàn)通過網(wǎng)絡(luò)爬取與自行拍攝相結(jié)合的方式制作數(shù)據(jù)集,數(shù)據(jù)集中80%來源于網(wǎng)絡(luò),20%來源于實(shí)際拍攝。昏暗條件下的口罩佩戴圖片相對缺乏,實(shí)際拍攝主要獲取的是這類圖片,實(shí)驗(yàn)過程中從樓道、室內(nèi)等光線昏暗的場所進(jìn)行了圖片采集,同時(shí)也在傍晚和清晨等光線較弱的環(huán)境下進(jìn)行了拍攝。數(shù)據(jù)集部分圖片如圖5 所示。

圖5 數(shù)據(jù)集部分圖片
實(shí)驗(yàn)數(shù)據(jù)集共包含9 000 張圖片,對其進(jìn)行手工標(biāo)注,標(biāo)注工具使用LabelImg。該數(shù)據(jù)集分為兩種類別,分別是bad 和good,bad 表示人員未佩戴或未按規(guī)范佩戴口罩,good 表示正確佩戴口罩。訓(xùn)練集與測試集的劃分如表1 所示。

表1 口罩?jǐn)?shù)據(jù)集劃分
本文使用圖像增強(qiáng)技術(shù),對原始圖片進(jìn)行圖像平移、翻轉(zhuǎn)、旋轉(zhuǎn)、縮放,分離3 個(gè)顏色通道并添加隨機(jī)噪聲,圖像增強(qiáng)后的數(shù)據(jù)集類別分布如圖6所示。
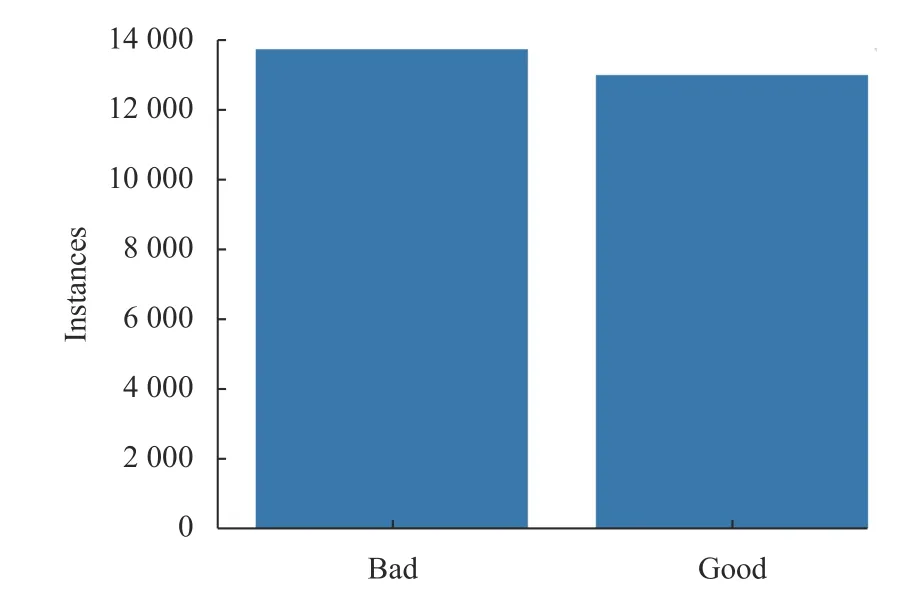
圖6 數(shù)據(jù)集類別分布
對增強(qiáng)后的數(shù)據(jù)進(jìn)行可視化,如圖7 所示,圖7a 中表示中心點(diǎn)位置分布,圖7b 中表示物體的大小分布,可以看出進(jìn)行數(shù)據(jù)增強(qiáng)后的數(shù)據(jù)物體中心點(diǎn)的分布較為均勻,物體大小以中小物體為主,符合日常生活場景。
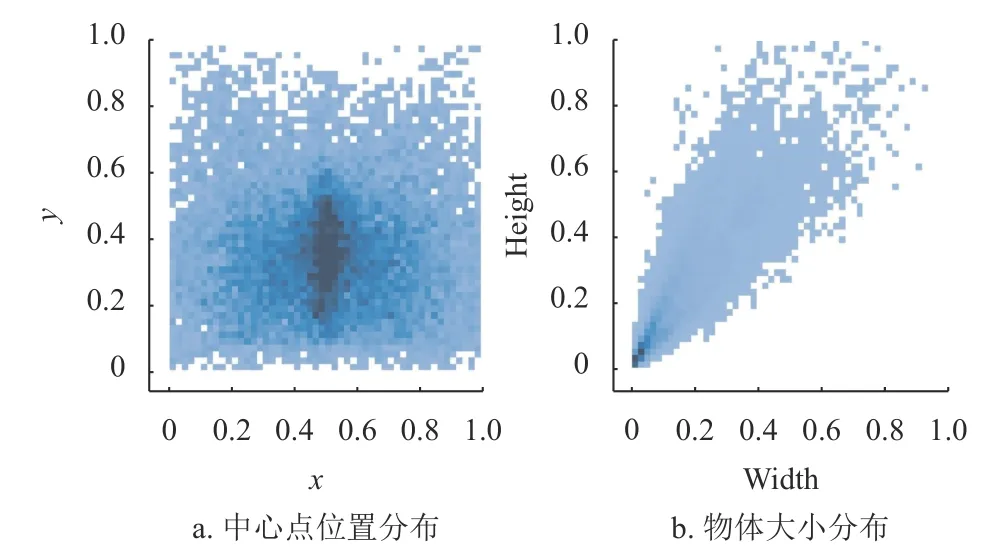
圖7 數(shù)據(jù)集可視化分析
本文具體實(shí)驗(yàn)環(huán)境如表2 所示。
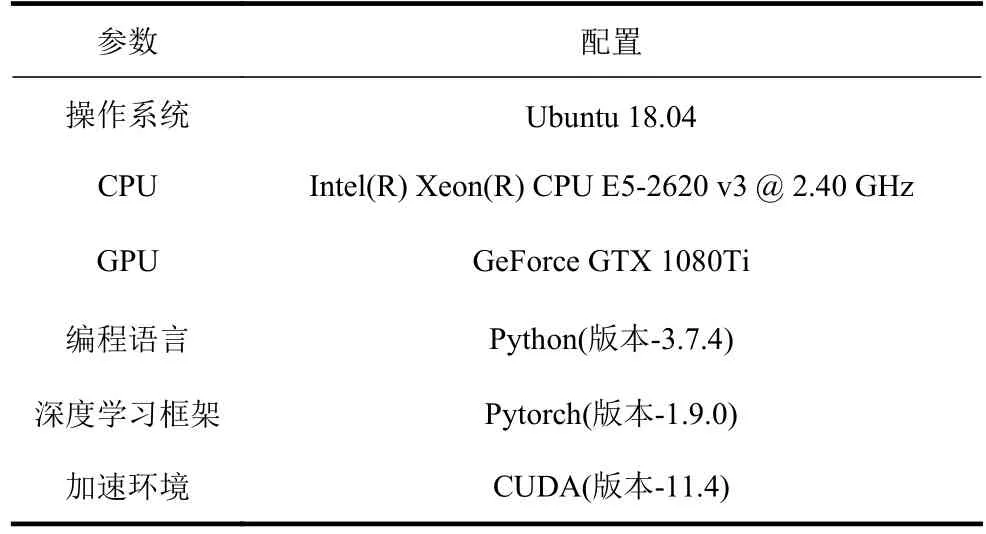
表2 實(shí)驗(yàn)環(huán)境配置
3.2 模型評估指標(biāo)
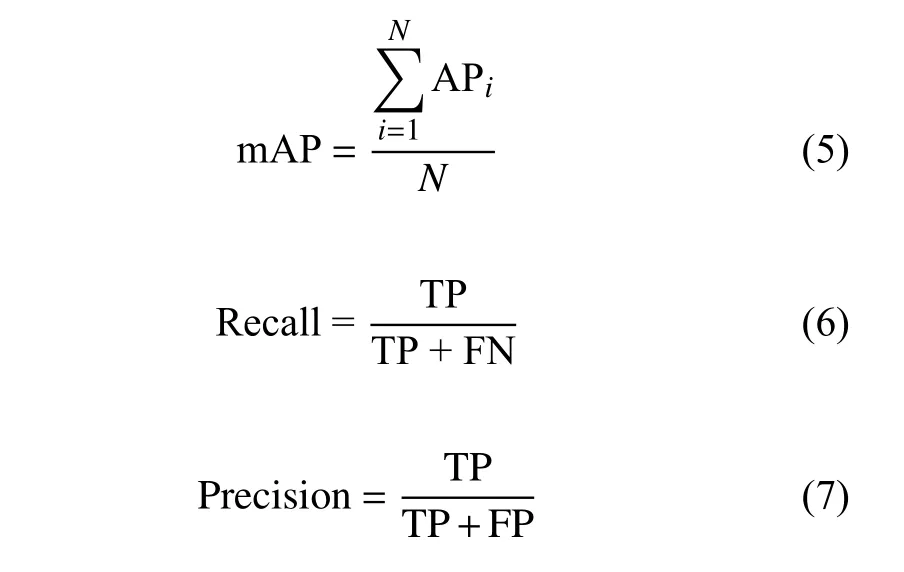
模型評估指標(biāo)主要包括平均精度均值(mean average precision,mAP)、召回率(recall)、精度(precision)。mAP 即所有類別的平均精度求和除以數(shù)據(jù)集中所有類的平均精度,召回率表示原始樣本中的正例有多少被預(yù)測正確的比率,精確率表示預(yù)測結(jié)果中預(yù)測為正的樣本中有多少是真正的正樣本的比率。在本次實(shí)驗(yàn)中,TP、FP 和FN 分別表示正確檢測框、誤檢框和漏檢框的數(shù)量:
從圖8a 中可以看出,當(dāng)?shù)螖?shù)接近400 次左右時(shí),MAP 的數(shù)值接近于0.996;從圖8b 中可以看出,當(dāng)?shù)螖?shù)接近450 次左右時(shí),召回率近1;從圖8c 中可以看出,當(dāng)?shù)螖?shù)接近500次時(shí),準(zhǔn)確率接近0.995。
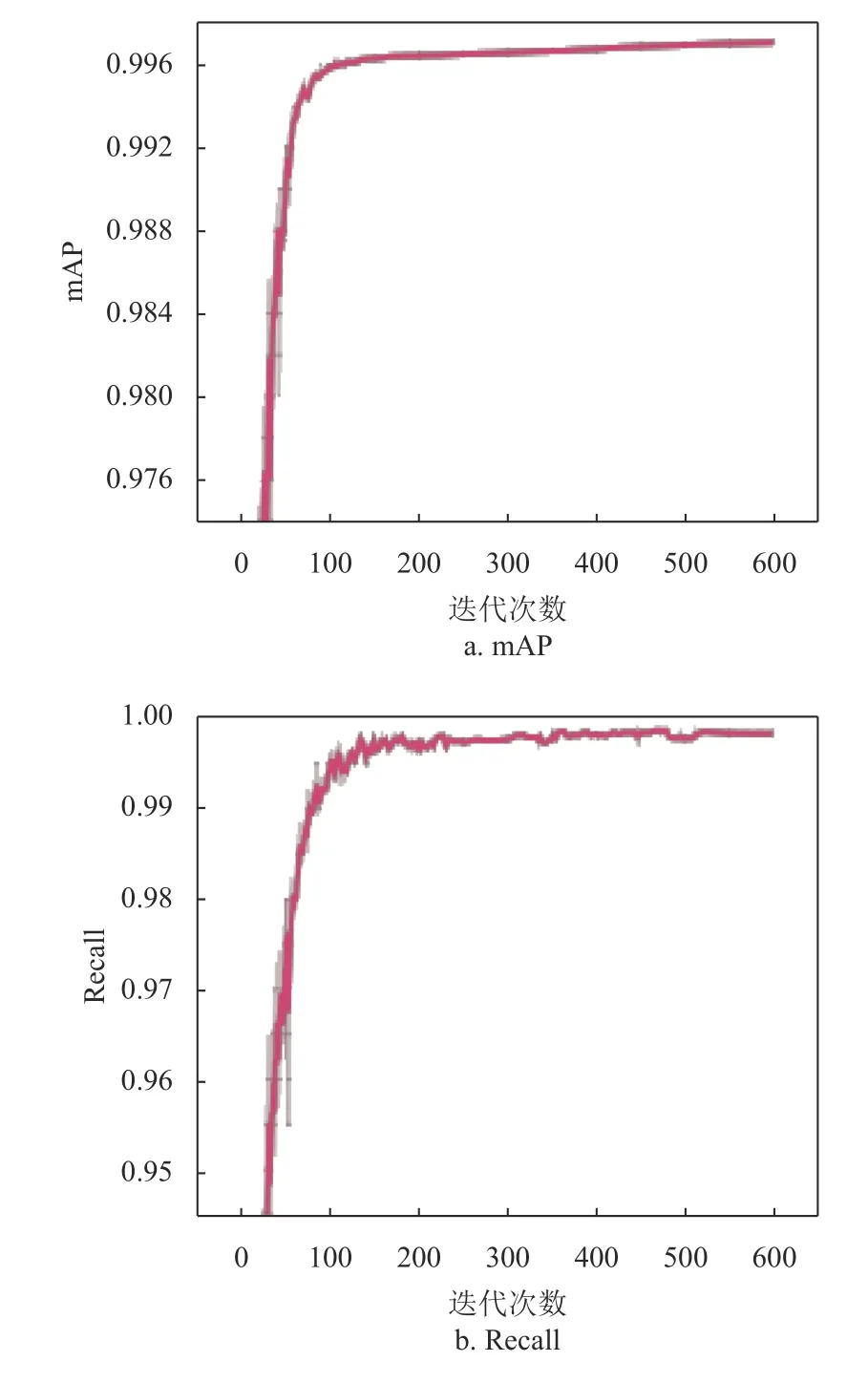
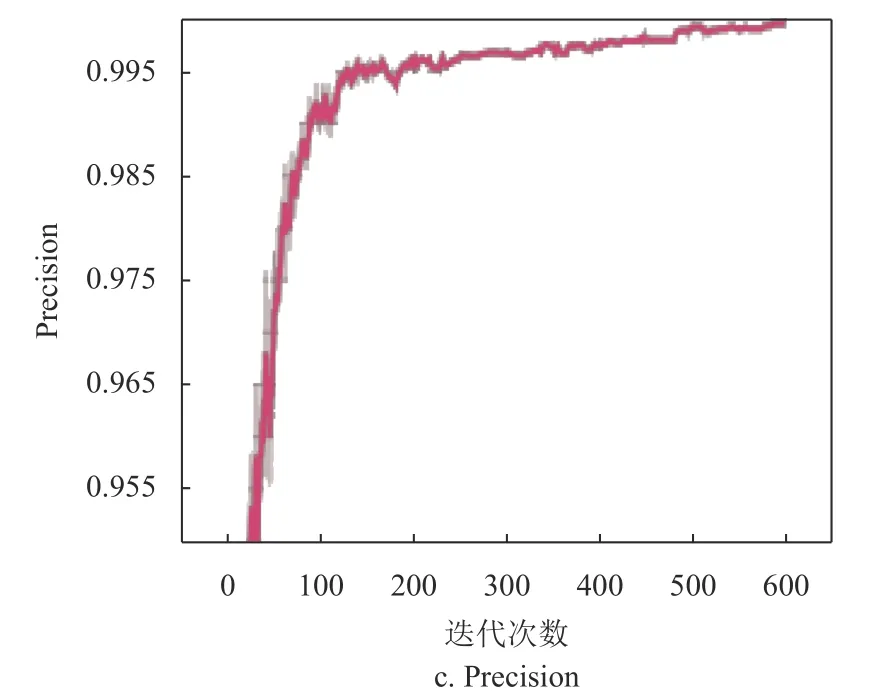
圖8 模型性能評估
網(wǎng)絡(luò)模型訓(xùn)練階段,迭代批量大小設(shè)置為32,總迭代次數(shù)為600 次。初始學(xué)習(xí)率設(shè)置為0.001,采用小批量梯度下降法,并使用Adam 優(yōu)化器計(jì)算每個(gè)參數(shù)的自適應(yīng)學(xué)習(xí)率。大約在350 次迭代后,模型開始逐漸收斂。
3.3 實(shí)驗(yàn)結(jié)果對比
模型訓(xùn)練完成后,將得到的模型與參考文獻(xiàn)[5]中的方法和AIZOO 方法的口罩檢測模型進(jìn)行對比實(shí)驗(yàn),分別在光照強(qiáng)度為30-75Lux(昏暗),75-250Lux(較昏暗)和250-1000Lux(正常光照)的條件下進(jìn)行對別實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果如圖9 所示。其中,光照強(qiáng)度是指單位面積上所接受可見光的能量,常用于指示光照的強(qiáng)弱和物體表面積的被照明程度,單位是Lux,光照強(qiáng)度越大,表明光照越強(qiáng),物體表面被照的越亮。
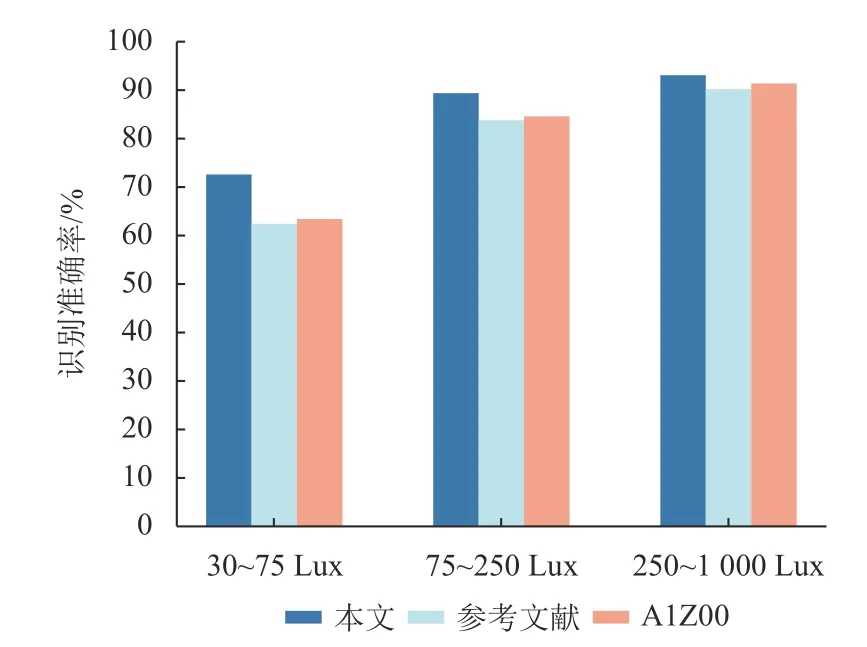
圖9 3 種方法實(shí)驗(yàn)結(jié)果
可以看出,在一定的光照強(qiáng)度范圍內(nèi),隨著光照強(qiáng)度的增加,本文方法與文獻(xiàn)[5]和AIZOO 方法對口罩佩戴檢測的準(zhǔn)確率也逐漸增加。在光照強(qiáng)度為250~1 000 Lux 的正常光照條件下,本文方法與文獻(xiàn)[5]和AIZOO 方法對口罩佩戴檢測的準(zhǔn)確率接近。在光照強(qiáng)度為75~250 Lux 的較昏暗條件下,文獻(xiàn)[5]和AIZOO 方法對口罩佩戴檢測的準(zhǔn)確率比較接近,但本文方法對口罩佩戴檢測的準(zhǔn)確率比文獻(xiàn)[5]和AIZOO 方法分別高5.6%、4.8%。在光照強(qiáng)度為30~75 Lux 的昏暗條件下,文獻(xiàn)[5]和AIZOO 方法對口罩佩戴檢測的準(zhǔn)確率相差不大,在圖像增強(qiáng)和注意力機(jī)制的加持下,經(jīng)過改進(jìn)的YOLOv5 模型實(shí)現(xiàn)了口罩佩戴的高效檢測,對是否正確佩戴口罩做出了正確的判斷。在光線昏暗的條件下,本文方法的檢測精度要比文獻(xiàn)[5]的方法和AIZOO 方法高10.2%、9.3%。
本文將算法應(yīng)用在在實(shí)際場景中,實(shí)驗(yàn)的結(jié)果如圖10 所示,圖中每一列分別是使用參考文獻(xiàn)[5]、AIZOO 與本文方法的檢測效果。從圖10a中可以看出,在光照正常的條件下,本文方法與參考文獻(xiàn)[5]中的方法和AIZOO 方法均實(shí)現(xiàn)了口罩佩戴的檢測,正確地檢測出了圖片中的目標(biāo)。圖10b中,在光線較昏暗的條件下,文獻(xiàn)[5]的方法和AIZOO 方法能檢測出人臉信息和口罩佩戴狀態(tài),但本文方法檢測出的目標(biāo)的置信度比其他兩種方法要高。圖10c 中,在可見度不高、光線昏暗的條件下,識別人臉信息和口罩的難度增大,文獻(xiàn)[5]中的方法和AIZOO 方法無法獲取到人臉口罩關(guān)鍵點(diǎn)信息,導(dǎo)致目標(biāo)檢測失敗,但本文方法不僅成功地檢測到了人臉信息,而且正確地檢測出口罩佩戴的狀態(tài),并給出了對應(yīng)的置信度。

圖10 口罩佩戴檢測效果實(shí)際場景對比示例
實(shí)驗(yàn)結(jié)果表明,在可見度不高、光照強(qiáng)度不大的昏暗條件下,與文獻(xiàn)[5]和AIZOO 的方法相比,本文方法使用圖像增強(qiáng)能改善圖片的質(zhì)量,通過注意力機(jī)制能更加準(zhǔn)確地提取人臉口罩關(guān)鍵點(diǎn)特征,使得檢測的準(zhǔn)確率更高,具有較強(qiáng)的魯棒性和擴(kuò)展性,基本能夠達(dá)到視頻圖像實(shí)時(shí)性的要求。
4 結(jié)束語
本文提出的基于注意力機(jī)制的光線昏暗條件下的口罩檢測方法可應(yīng)用在口罩佩戴識別系統(tǒng)中,具有較強(qiáng)的魯棒性和擴(kuò)展性,對推進(jìn)口罩佩戴檢測的自動化、智能化,實(shí)現(xiàn)疫情防控和公共衛(wèi)生安全具有重要的現(xiàn)實(shí)意義。
猜你喜歡
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
