基于改進堆棧自編碼的診斷錯誤標簽修正
2022-01-27 14:14:42黃亦翔肖登宇劉成良李懷洋
振動與沖擊 2022年1期
張 旭, 黃亦翔, 張 軒, 肖登宇, 劉成良, 李懷洋, 朱 濤
(1.上海交通大學 機械系統與振動國家重點實驗室,上海 200240;2.徐州重型機械有限公司 高端工程機械智能制造國家重點實驗室,徐州 221004)
隨著物聯網的發展和機械檢測設備的密布,利用大數據進行故障診斷成為現代工業發展的重要方向之一。監督學習中,正確的標簽樣本是診斷的基礎,但標記錯誤的標簽會降低診斷的精度和泛化能力。在實際工程中,錯誤標簽的情況難以避免。
數據采集后,試驗工作人員會根據需要給數據設置標簽以便于使用,而標簽的設置依賴于操作人員的水平。故障類型,故障程度的診斷會因為標準不同而造成標簽不夠準確,甚至錯誤。數據本身也會存在限制條件,如多故障的齒輪箱,因為裂紋而忽視了其他故障;緩慢變化的故障在前期被認為是正常等。另外,在信號轉換,通信傳輸,預處理中的程序錯誤也會造成錯誤標簽的產生[1]。
Quinlan[2]證明,相對于數據本身的特征噪聲,錯誤的標簽對于分類器影響更大。現有算法,如KNN,決策樹,AdaBoost等在進行故障診斷時,容易受到錯誤標簽的負面影響[3],Zhang等[4]也發現深度模型會擬合隨機標簽,進而影響預測結果的準確性。因此,對原始數據標簽進行修正有助于提高數據的可信程度,從而提升模型的泛化能力。
基于以上原因,錯誤標簽的研究受到了國內外各個領域學者的廣泛關注和研究。錯誤的標簽樣本多被認為是異常點,常采用過濾篩選方式剔除異常標簽,以降低錯誤標簽率。羅俊杰等[5]將Bayes分類器獲取的樣本信息熵作為樣本歸屬的判斷依據,從而篩選異常樣本。高瓊[6]采用KNN聚類后的樣本類別概率來判斷樣本歸屬。為了保持樣本中正確標簽的流形結構,Liu等使用保持流形稀疏圖(MSPA)的方法來過濾錯誤標簽,夏建明等[7]結合稀疏流行聚類模型(SMCE)和KNN聚類結果確定樣本的真實標簽。上述方法多假設原有正確樣本具有一定流形結構,方法準確性易受到樣本分布的影響。因此,有學者在提升現有方法的魯棒性方面進行研究。Liu等[8]首先證明了損失函數加權方法在錯誤標簽中的重要性,并提出了給定錯誤標簽數據分布和變化矩陣情況下的權重計算方法。對于標簽未知或不確定的數據,常采用聚類獲取偽標簽以幫助訓練的方法。深度聚類[9],根據聚類結果建立混合信息增益比參數以降低錯誤標簽影響[10]等方法均是如此。除此以外,劉藝[11]結合知識圖譜對訓練數據權重進行調整。Jiang等[12]提出了基于數據的導師網絡來監督學生深層網絡訓練,并提供樣本訓練權重。Han等[13]訓練兩個并行神經網絡,利用小損失的數據進行下一輪交叉訓練。上述方法多采取提高正確標簽權重,剔除錯誤標簽影響的方式,需要大量數據樣本,并且會舍棄一部分數據樣本,減少了數據中的信息量。針對于神經網絡會優先記憶簡單數據,之后記憶復雜數據的特點,Guo等[14]利用數據的分布密度來衡量數據的復雜性,并使用排序后數據依次訓練神經網絡。Cao等[15]采用雙Softmax層進行分類,減少深層模型對錯誤標簽的過度擬合,這些方法同樣對訓練的數據量提出了一定要求。
在機械故障診斷領域,正確的樣本標簽是診斷準確度的保證。目前來看,與錯誤標簽相關的機械故障診斷研究較少。針對此問題,本文提出一種基于改進堆棧自編碼的錯誤標簽修正方法。該方法通過編碼器對樣本特征進行映射,利用孤立森林(isolation forest, iFroest)獲取降維后樣本的偽標簽,根據偽標簽調整編碼器的權重,從而使編碼器注重于正確樣本。考慮到數據類別導致的區別,利用基于隨機森林的交叉驗證方法獲取樣本的信息熵,修正錯誤標簽。試驗表明,本文提出的方法可以獲得信號的深層特征,而且在多個錯誤標簽比例下均能顯著降低樣本錯誤標簽率,修正錯誤標簽,提高故障診斷的準確率。
1 錯誤標簽修正原理
1.1 錯誤標簽修正流程
實際工程中,樣本數據量少,數據分布未知,單一標簽修正方法依賴于數據的分布。因此,本文通過改進堆棧自編碼獲得一部分錯誤標簽率低的樣本,然后用這類數據來訓練分類器以實現標簽修正,具體流程如圖1所示。在提取信號初步特征后,將含有錯誤標簽的樣本集輸入到堆棧自編碼中,獲得低維度輸出特征。同時使用孤立森林將樣本賦予“正確”和“錯誤”的偽標簽,進而調整樣本權重,使自編碼注重于“正確”標簽樣本。循環結束后,利用堆棧自編碼獲得所有樣本的低維度特征,通過孤立森林將所有樣本分為“正確”樣本和“錯誤”樣本兩類,并使用所有“正確”標簽的樣本訓練分類器,通過對比分類器下樣本的信息熵來進行錯誤標簽的修正。
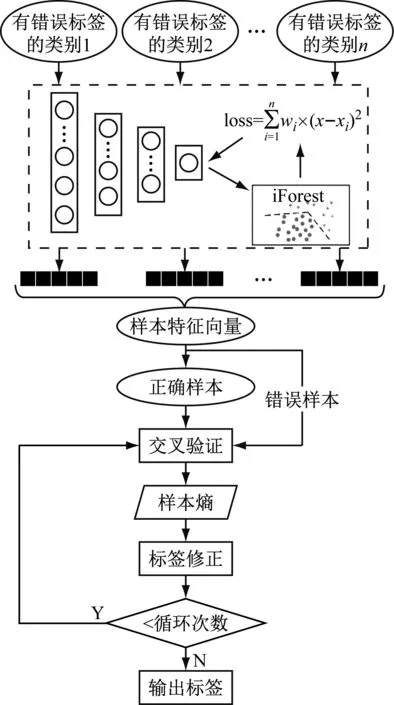
圖1 錯誤標簽修正流程圖Fig.1 Noise label correction flow chart
1.2 堆棧自編碼神經網絡
自編碼網絡(auto-encoder, AE)由編碼器(encoder)和解碼器(decoder)兩部分組成[16],如圖2所示。

(1)
式中:L(x(i),gθ′(fθ(x(i))))為損失函數;n為樣本個數。

圖2 自編碼網絡結構Fig.2 Structureof auto-encoder
堆棧自編碼神經網絡(stacked auto-encoder, SAE)是由多個自編碼首尾相連接組成的無監督學習網絡,包括一個輸入層,一個輸出層,多個隱藏層,結構如圖3所示。
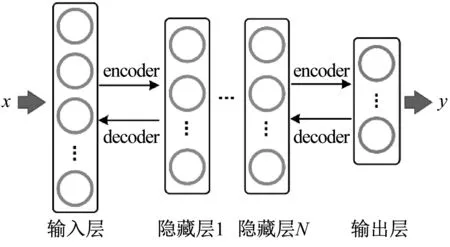
圖3 堆棧自編碼結構Fig.3 Structureof stacked auto-encoder
正如前文所說,提高對正確標簽樣本的關注是降低錯誤標簽樣本影響的有效方法,本文在訓練時會剔除錯誤標簽的樣本對損失函數的影響,只選用正確標簽樣本所帶來的損失,式(1)所對應的優化函數更新為
(2)
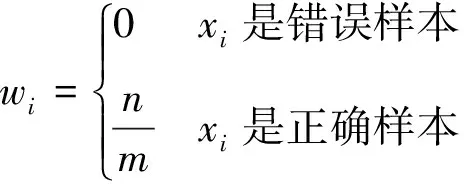
(3)
式中:n為所有樣本個數;m為偽標簽為“正確”的樣本個數;wi為基于偽標簽的權重。
1.3 孤立森林
孤立森林(iForest)是基于隔離樹(iTree)的集成快速異常點檢測方法,能夠準確檢測出分布稀疏且距離大密度群體遠的異常點[17]。
對于維度為d的n個樣本數據X={x1,x2,…,xn},表1給出了構建iTree的具體方法。
相對于正常點,異常點距離根節點的路徑較短。對多個iTree中點x的平均路徑進行計數,將結果記作E(h(x)),其中h(x)代表x的平均路徑長度。

表1 iTree的構建方法
對于有n個點的X,樣本x的異常分數可以表示為
(4)
其中c(n)為n個樣本的平均搜索路徑長度,用來歸一化E(h(x))。
異常分數越接近1,x為異常樣本的可能性越大。在堆棧自編碼每次循環中,iForest用于給樣本賦予偽標簽,調整堆棧自編碼對樣本的權重。其次,在所有循環結束后,iForest根據預先設置的錯誤標簽比例η,將樣本分為正確標簽樣本和錯誤標簽樣本兩類。
1.4 基于信息熵的標簽修正
信息熵是對樣本類別不確定性進行評估的有效方法[18]。類別數為k的樣本集中,樣本x屬于類別i的概率為Pi(x),則x的信息熵H(x)表示為
(5)
當所有可能相等時,信息熵最大,屬于完全不確定的情況;當其中一種情況的概率為1,其他為0時,信息熵H(x)取到最小值0,此樣本被稱為典型樣本。在樣本標簽修正中,如果樣本是典型的,則使用預測的標簽作為此輪中樣本的最終標簽。
k折交叉驗證方法將數據集D劃分成為k個大小相似的互斥集合,然后使用k-1個子集作為訓練集,剩下的子集作為驗證集,共進行k次訓練和測試。圖4是本文5折交叉驗證的示意圖。
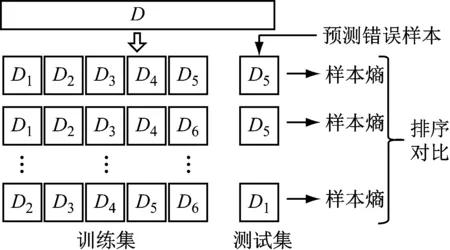
圖4 5折交叉驗證Fig.4 5-fold cross-validation
在堆棧自編碼中,孤立森林會選擇出“正確”標簽樣本和“錯誤”標簽樣本。
本文的交叉驗證主要分為兩部分。在第一輪訓練中,“正確”樣本為訓練數據,“錯誤”樣本為測試數據。對于“錯誤”標簽樣本,默認其原始標簽是錯誤的,選取五次預測結果中的出現次數最多的標簽(相同取平均信息熵小的標簽)作為其預測標簽;對于“正確”標簽樣本,通過分類概率獲取樣本的信息熵,當信息熵小于信息熵閾值β時,認為該樣本是典型樣本,將預測標簽作為樣本的標簽。
在第二輪及以后的輪次中,將“正確”標簽樣本與“錯誤”標簽樣本合起來作為數據集D′,進行交叉驗證,并基于信息熵修正樣本標簽。
2 試驗驗證
齒輪是機械設備的核心部件之一,隨著工業需求的提高,人們對齒輪的可靠性也提出了更高的要求。本文以不同故障的齒輪為對象,人工生成錯誤標簽數據來驗證方法的可行性。
2.1 試驗設置
實際工程會因為時間、成本、安全性等原因,較少在有故障零部件的情況下進行工作并采集數據,所以采用動力傳動故障診斷試驗臺來獲得齒輪故障數據以進行試驗。如圖5所示,試驗臺包含行星齒輪箱,平行軸齒輪箱,負載控制器以及磁力制動器等設備。測試齒輪健康狀態分5類,分別是正常、磨損、缺齒、斷齒、齒根裂紋,圖6是部分故障齒輪圖片。

圖5 齒輪故障試驗臺Fig.5 Test system for gear fault

(a) 磨損齒輪

(b) 缺齒齒輪

(c) 斷齒齒輪圖6 故障齒輪Fig.6 Faulty gear
試驗使用加速度傳感器采集齒輪箱振動信號,采集頻率為10 kHz,電機輸入轉速為15 Hz,每類齒輪采集500 s數據,各類齒輪的時域波形如圖7所示。
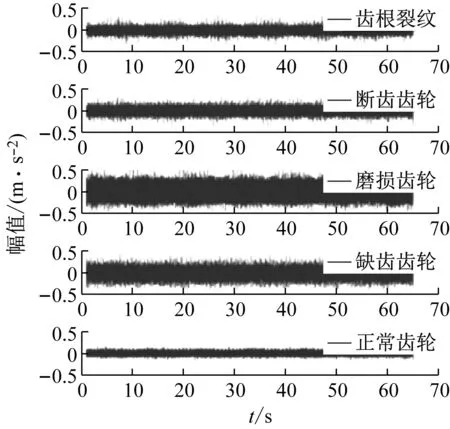
圖7 齒輪時域波形Fig.7 Timedomainwaveformof gear
2.2 數據預處理
選取振動穩定后的數據作為后期處理的原始數據。每個數據樣本包含5 000個樣本點,5類數據共獲得637×5=3 138個樣本。
考慮到齒輪箱振動頻率復雜,因此采用經驗模態分解[19](empirical mode decomposition,EMD)得到的內涵模態分量(intrinsic mode functions, IMF)統計特征作為樣本的初步特征。特征生成步驟如圖8所示。
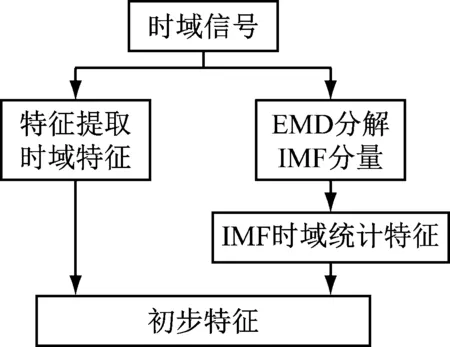
圖8 EMD獲取時域統計特征Fig.8 Time domain feature through EMD
對不同健康狀態下的數據樣本xp利用EMD分解,得到個數為Np的IMF分量IMFp={c1,c2,…,cNp}。考慮到不同樣本分解數量的不同,選用所有樣本前Nmin個IMF分量作為EMD分解結果,其中Nmin=min{N1,N2,…,Np}。根據下式計算截取IMF分量的能量占原有信號能量的比例。
(6)
計算結果顯示,前5個IMF分量樣本的能量占比達到93%以上,基本滿足特征提取的要求。圖9是正常齒輪前6階IMF的時域圖。
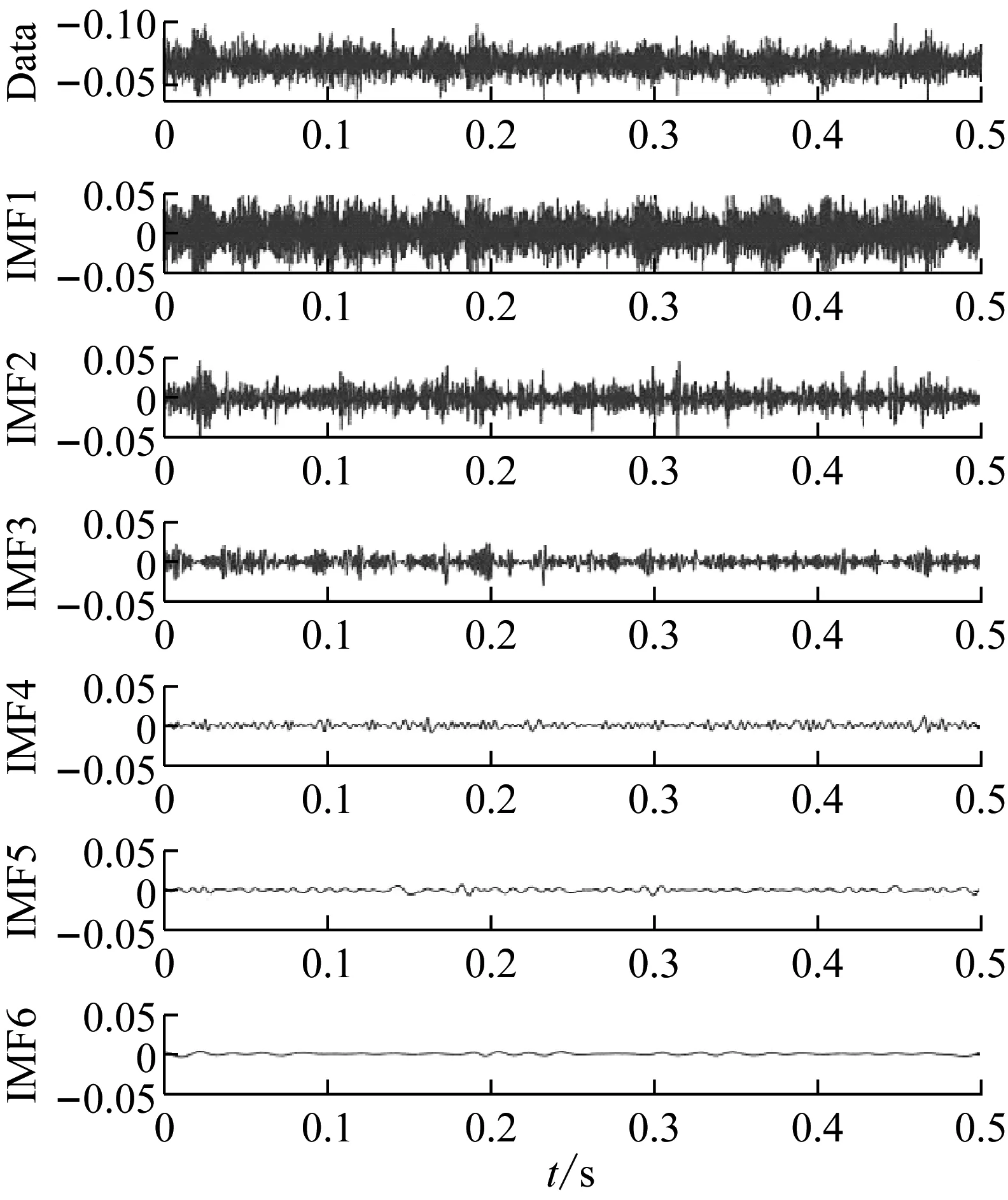
圖9 正常齒輪IMF時域圖Fig.9 Time domain diagram of IMF ofnormal gear
對提取的IMF分量分別計算時域統計特征,包括均值,峰峰值,峭度等20維時域特征[20]。具體計算方法如表2所示。
5個IMF分量時域統計結果共20×5=100維向量,與原始信號的20維時域統計特征拼接,將其進行Min-Max 歸一化獲得120維初始向量。
(7)
2.3 錯誤標簽樣本生成
實際工程中,錯誤標簽產生的情況較為復雜,難以重現真實錯誤標簽產生過程,因此本文基于齒輪類別間距離生成錯誤標簽數據集。
實際錯誤標簽分兩種情況:一種是隨機標簽,錯誤標簽的生成過程是完全隨機的;另外一種是類別相關的錯誤標簽,錯誤標簽和真實標簽有一定相關性,如磨損程度所導致的錯誤標簽。本文根據類別間中心距離進行錯誤標簽的設計。對于采集得到的5個類別數據集,選定錯誤標簽比例η,則樣本數量為nk的數據集中錯誤標簽樣本總個數Nnl為
Nnl=nk×η
(8)
為了構建類相關的錯誤標簽樣本,采用類別中心之間歐拉距離D(i,j)作為衡量相關性的指標。
(9)
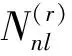
(10)
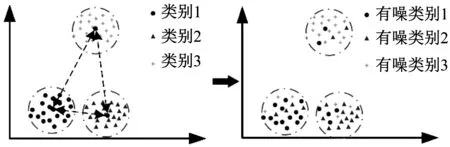
圖10 基于類間中心距的錯誤標簽樣本生成方法Fig.10 Noise label generation methodbased on center distance
2.4 堆棧自編碼提取正確樣本
堆棧自編碼的輸入是人工生成,具有同樣標簽的樣本,如圖10中的有噪類別1。在循環過程中,通過iForest對樣本進行分類,獲得正確樣本,從而提高自編碼對該類樣本的關注度。在訓練結束后,同樣使用iForest挑選錯誤標簽比例低的一部分樣本,作為后續交叉驗證第一輪的訓練樣本。堆棧自編碼具體參數如表3所示。

表3 堆棧自編碼參數
iForest在異常點檢測時,需要設置閾值以篩選出錯誤標簽數據。綜合考慮后,本文將初始正常點比例設置為0.8,之后基于前后兩次正確樣本的平均方差σ(x)更新錯誤標簽比例。
(11)
式中,x(i)是數據集樣本的第i個特征。
錯誤標簽比例更新方法如圖11所示,具體方法如表4所示。
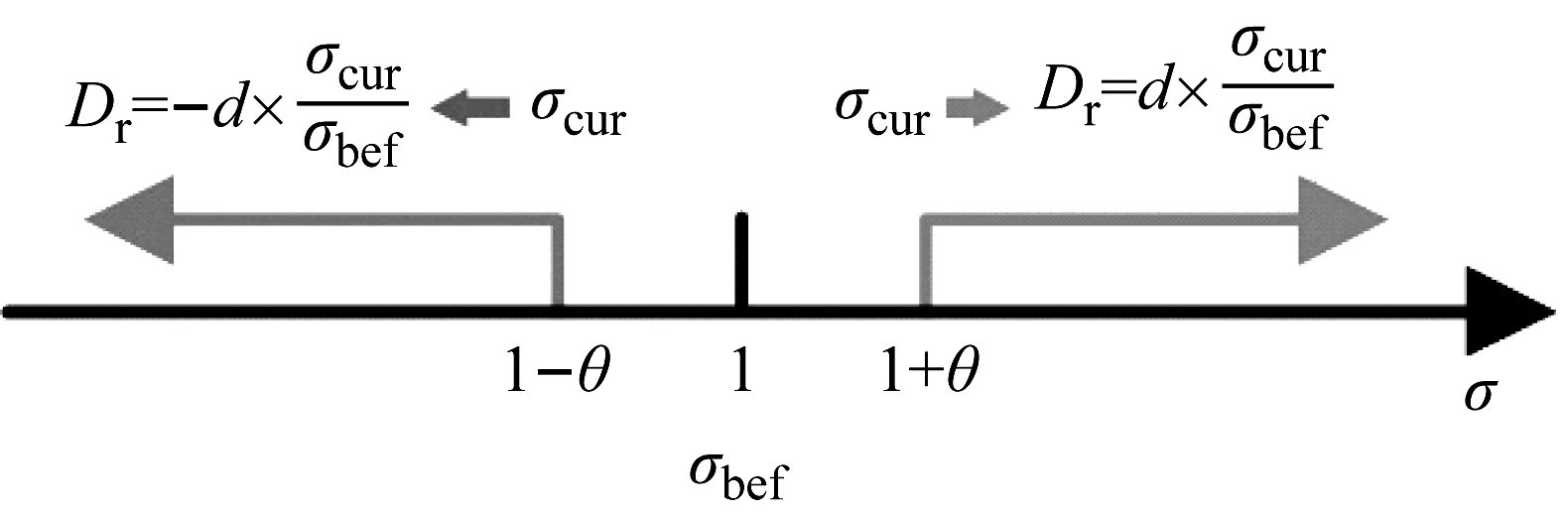
圖11 錯誤標簽比例估計方法Fig.11 Method of estimating noise label ratio
改進堆棧自編碼是為了獲得一部分具有較低錯誤標簽率的樣本,因此利用正確樣本的個數與偽標簽為“正確”樣本個數的比值,即精確度作為改進堆棧自編碼效果好壞的衡量標準。基于表5所示混淆矩陣,精確度計算方法如式(12)所示。

表4 錯誤標簽比例更新方法

表5 混淆矩陣
(12)
依次將前述生成的5類含有錯誤標簽的樣本集作為堆棧自編碼的輸入數據集,通過iForest對樣本進行分類。對比在不同錯誤標簽比例(0.1,0.2,0.3,0.4)下,方法的分類精確度以及錯誤標簽比例的估計情況。
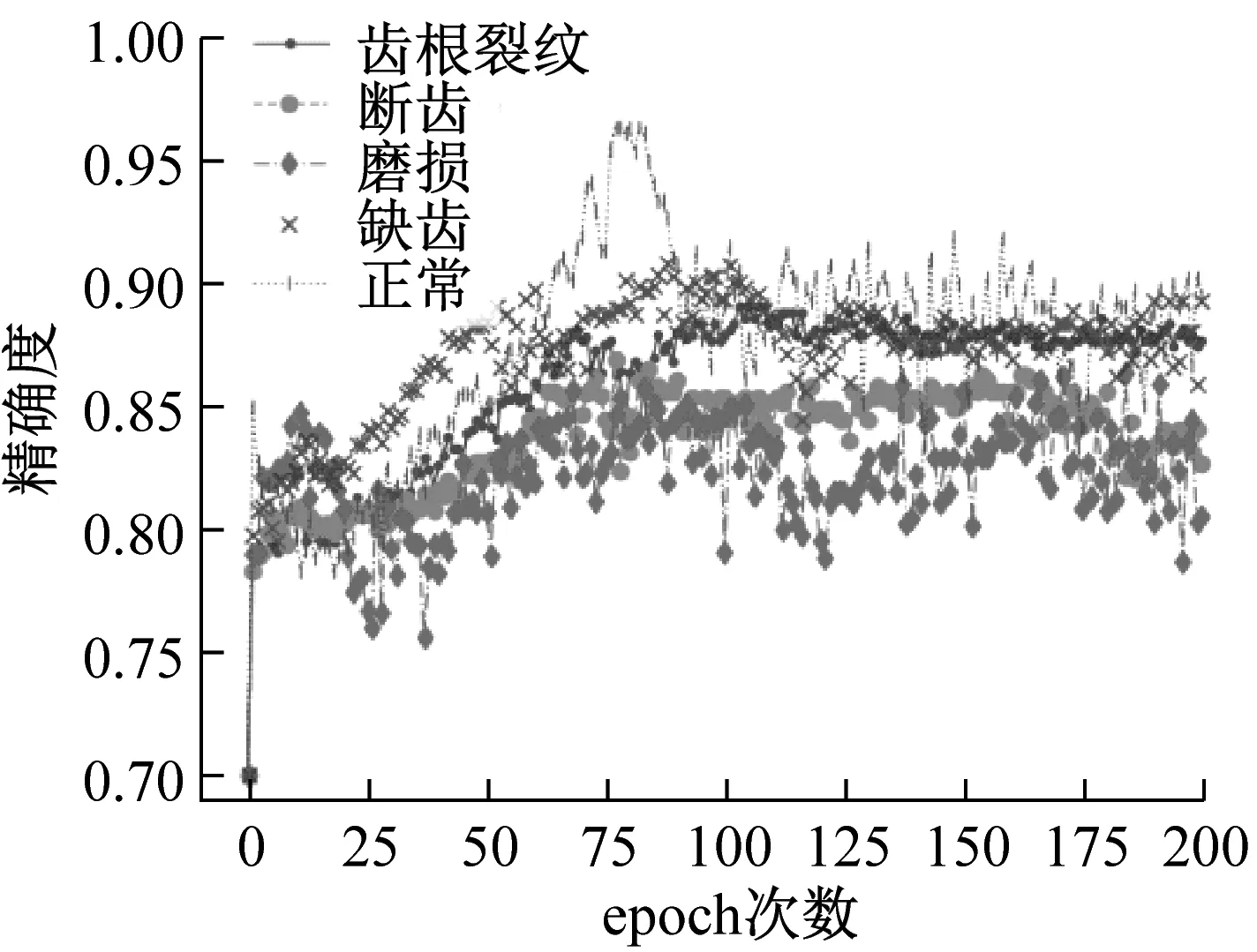
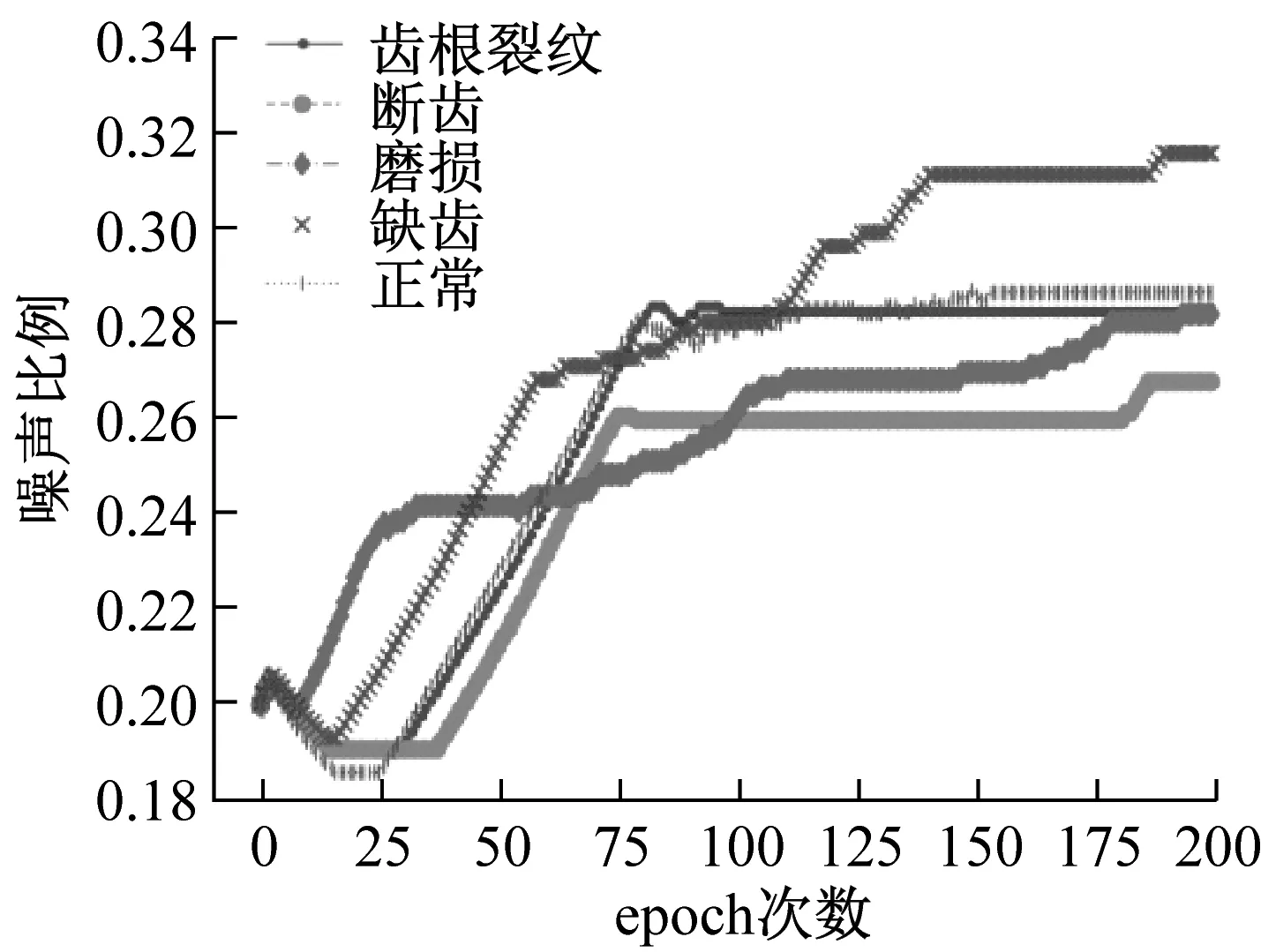
以初始錯誤標簽比例0.3為例,圖12(a)為五類齒輪數據經過堆棧自編碼和iForest后,分類精確率的變化,12(b)為基于樣本平均偏差的錯誤標簽比例變化。
(a) 分類精確度
(b) 預測錯誤標簽比例圖12 錯誤標簽比例為0.3時分類精確度和預測錯誤標簽比例的訓練情況Fig.12 Training process of classification precision and predicted noise label ratio when noise label radio is 0.3
圖12(a)表示,隨著迭代次數的增加,分類的精確度從最開始的0.7先快速上升至0.8,之后緩慢上升并逐步穩定。正常齒輪數據集的最高精確度可以達到0.95,最終穩定在0.9附近;磨損齒輪數據集精確度最低,穩定在0.8以上。圖12(b)表明,隨著訓練次數的增加,錯誤標簽比例朝向實際比例的方向移動,預測的五類齒輪錯誤標簽比例均落入[0.26,0.32]的區間。綜合來看,隨著循環次數的增多,改進堆棧自編碼的分類精確度在不斷上升并穩定,錯誤標簽比例估計也趨于真實情況。
對堆棧自編碼獲得的特征使用PCA[21],t-SNE[22]兩種方法實現可視化,如圖13所示。
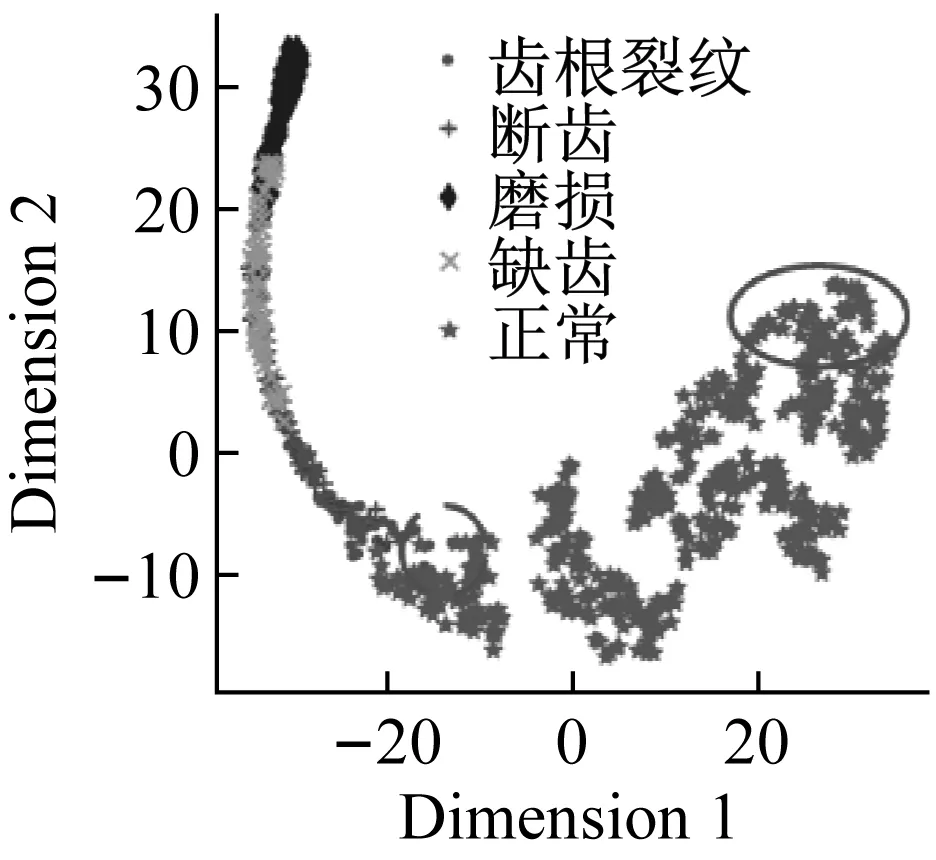
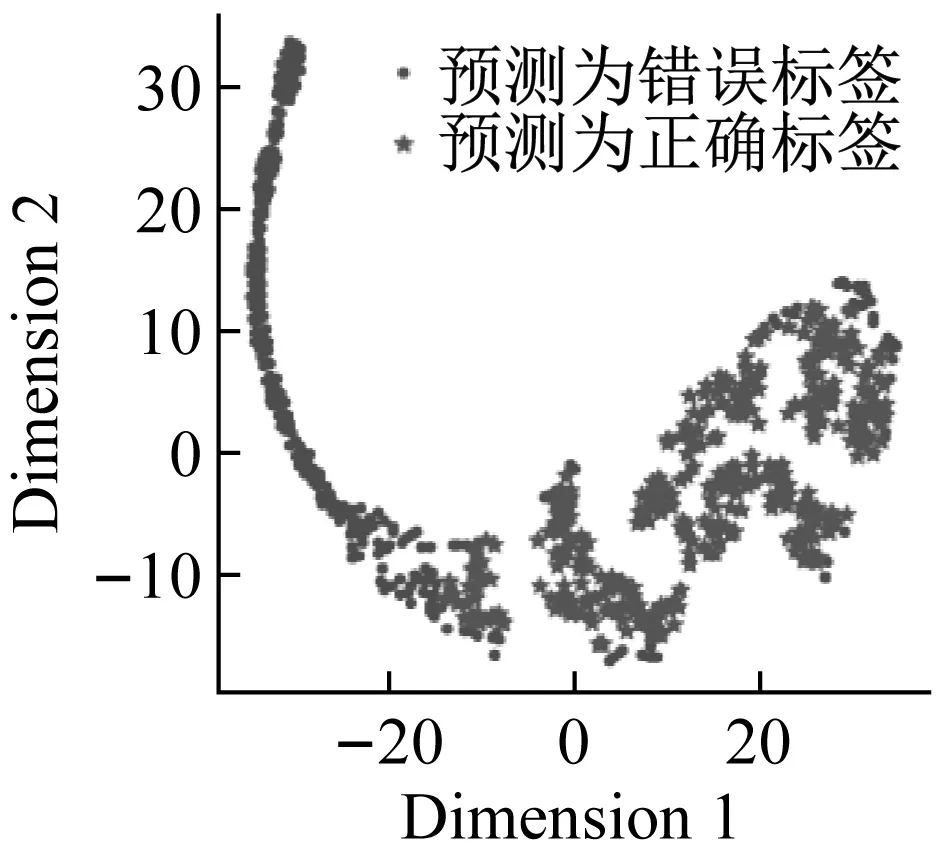
(a) t-SNE
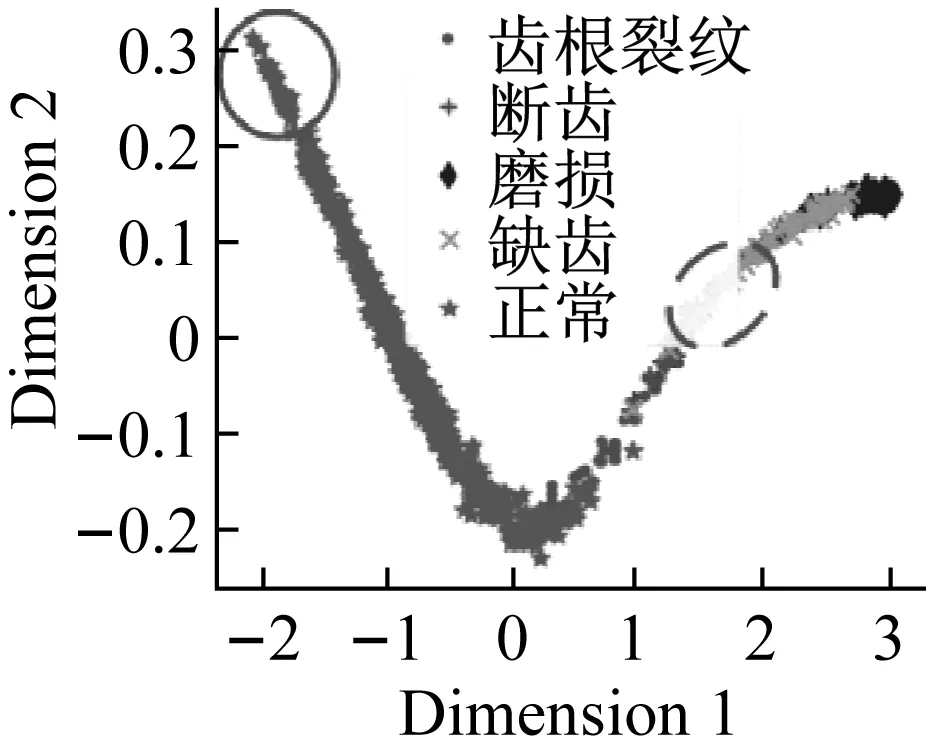
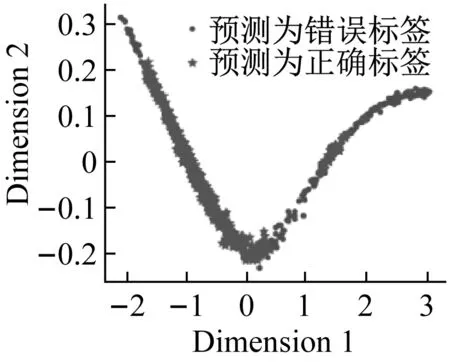
(b) PCA圖13 特征可視化和分類結果Fig.13 Visualization of feature and classificationresults
可視化結果表明經過改進堆棧自編碼后,正確標簽樣本與錯誤標簽樣本的特征具有一定可區分度。虛線內的樣本,錯誤標簽樣本被賦予了“正確”的偽標簽,實線內的樣本,正確標簽樣本被賦予了“錯誤”的偽標簽。此類情況的出現,降低了分類樣本的精確率,后續基于信息熵的標簽修正會改善這一情況。
對于錯誤標簽比例η為0.1,0.2,0.4的樣本,經過200 epoch后的精確度及預測錯誤標簽比例結果如表6所示。
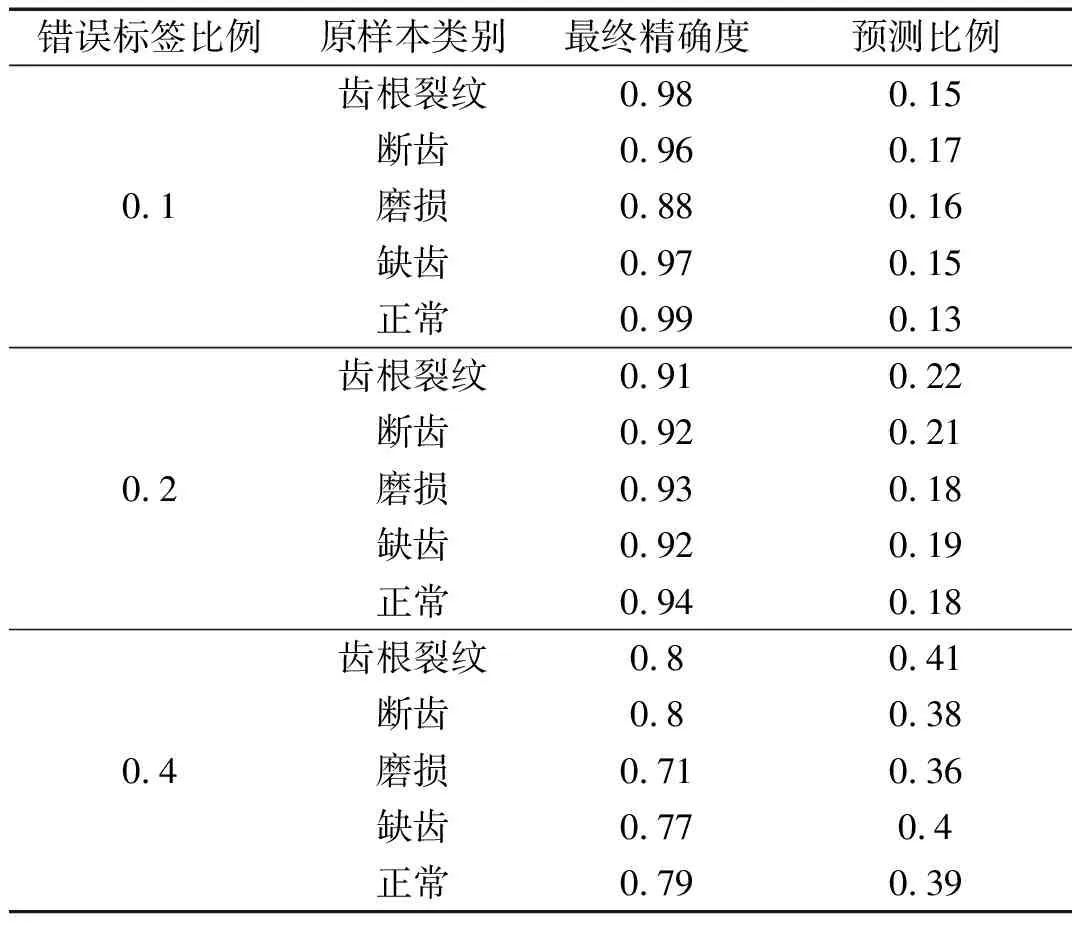
表6 精確度及錯誤標簽比例結果
在不同的比例下,上述5類含噪樣本經過改進堆棧自編碼提取樣本后,分類精確度受到比例影響,但均有所提高,且能夠實現初步的錯誤標簽比例估算。
2.5 基于熵的錯誤標簽修正
利用五類齒輪數據分別訓練改進的堆棧自編碼網絡,得到5個自編碼網絡。對于每個樣本,將五個自編碼器生成的結果進行拼接,得到10×5=50維特征,作為交叉驗證中的輸入特征。
經過30輪交叉驗證,錯誤標簽比例η=0.3的樣本在不同信息熵閾值β下的錯誤標簽率變化如圖14所示。
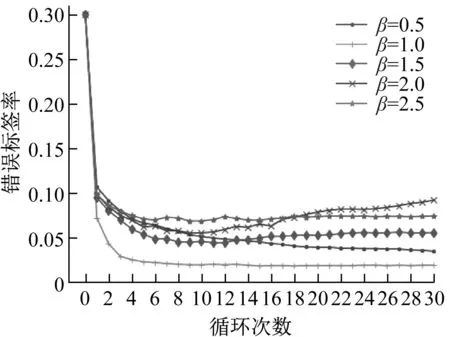
圖14 不同閾值下錯誤標簽比例變化Fig.14 Noise label ratiounder different thresholds
由圖14可知,經過信息熵的標簽修正后,錯誤標簽率均下降明顯,可以接近2.5%的錯誤標簽率。具體來講,在前幾輪交叉驗證中,錯誤標簽比例有明顯下降,后期錯誤標簽比例的變化情況與閾值有關。當熵閾值較小時,比例會隨著循環次數逐漸下降,下降速率與閾值大小有關,如β=1與β=0.5的對比。當熵閾值較高時,后期錯誤標簽比例有上升趨勢,如β=2的情況。因此信息熵的閾值需要根據樣本種類個數進行設置,過高易增加不確定性因素,過低的閾值會降低標簽更新速率。
對于η為0.1,0.2,0.4的樣本,錯誤標簽比例下降情況如表7所示。
可以發現,其他比例下,信息熵閾值所帶來的結果相類似。在信息熵閾值較小時,改進效果明顯;信息熵閾值變大后,精確率會有所下降。
綜合改進堆棧自編碼和基于熵的錯誤標簽修正兩個步驟,不同情況下錯誤標簽比例的變化如圖15所示。在不同的初始錯誤標簽比例情況下,本文提出的方法可以使錯誤標簽比例有一個明顯的下降。
2.6 模型訓練
為了對比錯誤標簽數據對模型的影響程度,使用原始含有錯誤標簽樣本的數據集和標簽修正后的數據訓練分類模型,對比分類的準確度。

表7 錯誤標簽比例變化
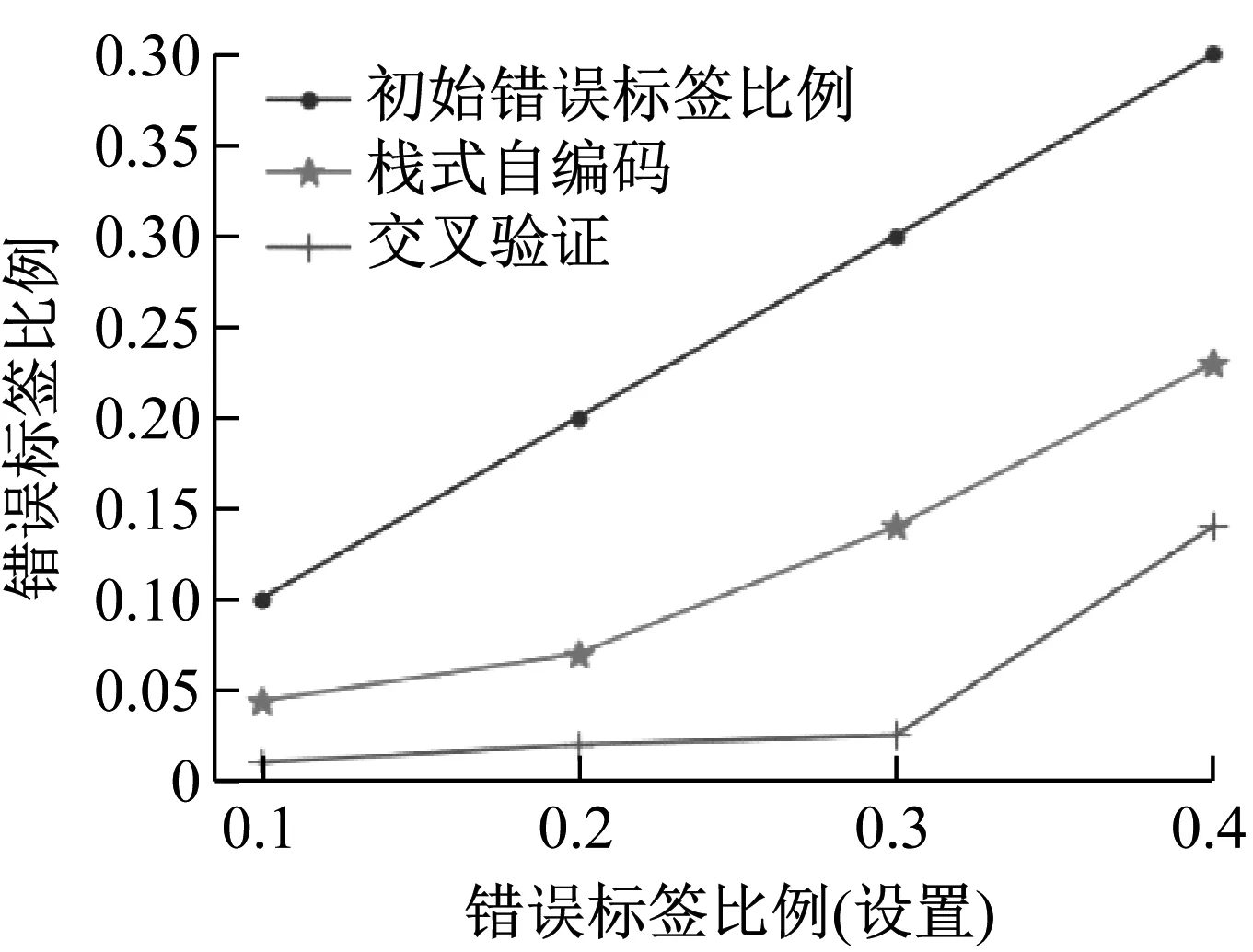
圖15 錯誤標簽比例與方法的變化關系Fig.15 Variation of noise ratio and method
選擇所有樣本中80%的樣本作為訓練數據,20%樣本作為測試數據,使用LighGBM,XGBoost,卷積神經網絡三種方法作為分類器。卷積神經網絡參數如表8所示,另外兩種方法均采用默認參數。

表8 卷積神經網絡分類器參數
不同錯誤標簽比例下預測精確度如圖16所示。
使用錯誤標簽數據訓練分類器,分類器精確度均在85%以下,最低分類精確度為70%,可見錯誤標簽樣本的存在明顯影響了分類器的性能。在錯誤標簽修正后,三種分類器的準確度都有上升,低錯誤標簽比例下的初步分類精度可以達到95%。本文所采用的三種分類器受到錯誤標簽的影響也不同,LightGBM和卷積神經網絡分類器的精確度在各種錯誤標簽比例下均有15%以上的下降,而XGBoost的分類精確度下降不明顯。
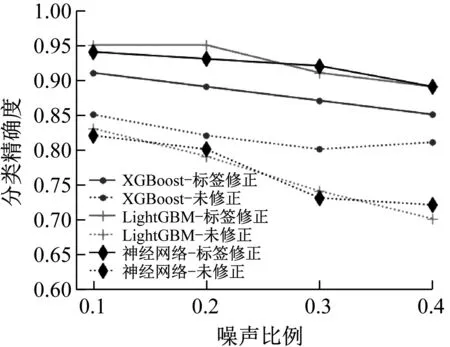
圖16 錯誤標簽修正前后分類精確度對比Fig.16 Comparison of classification accuracy before and after noise label correction
3 公共數據集
為了進一步驗證本文的方法在樣本接近的錯誤標簽數據中的效果,本文選用美國凱斯西儲大學(Case Western Reserve University,CWRU)的公開軸承振動數據作為驗證數據。試驗用軸承的內圈裂紋長度分別為0,7,14,21,28 mm,使用采樣頻率為12 kHz的軸承驅動端振動數據作為樣本。首先基于經驗模態分解獲取樣本特征,選取錯誤標簽比例η=0.3的情況,按照距離挑選其他類別的數據,堆棧自編碼網絡結構及參數與之前相同。圖17,圖18分別是樣本精確度,錯誤標簽預估比例的變化情況。
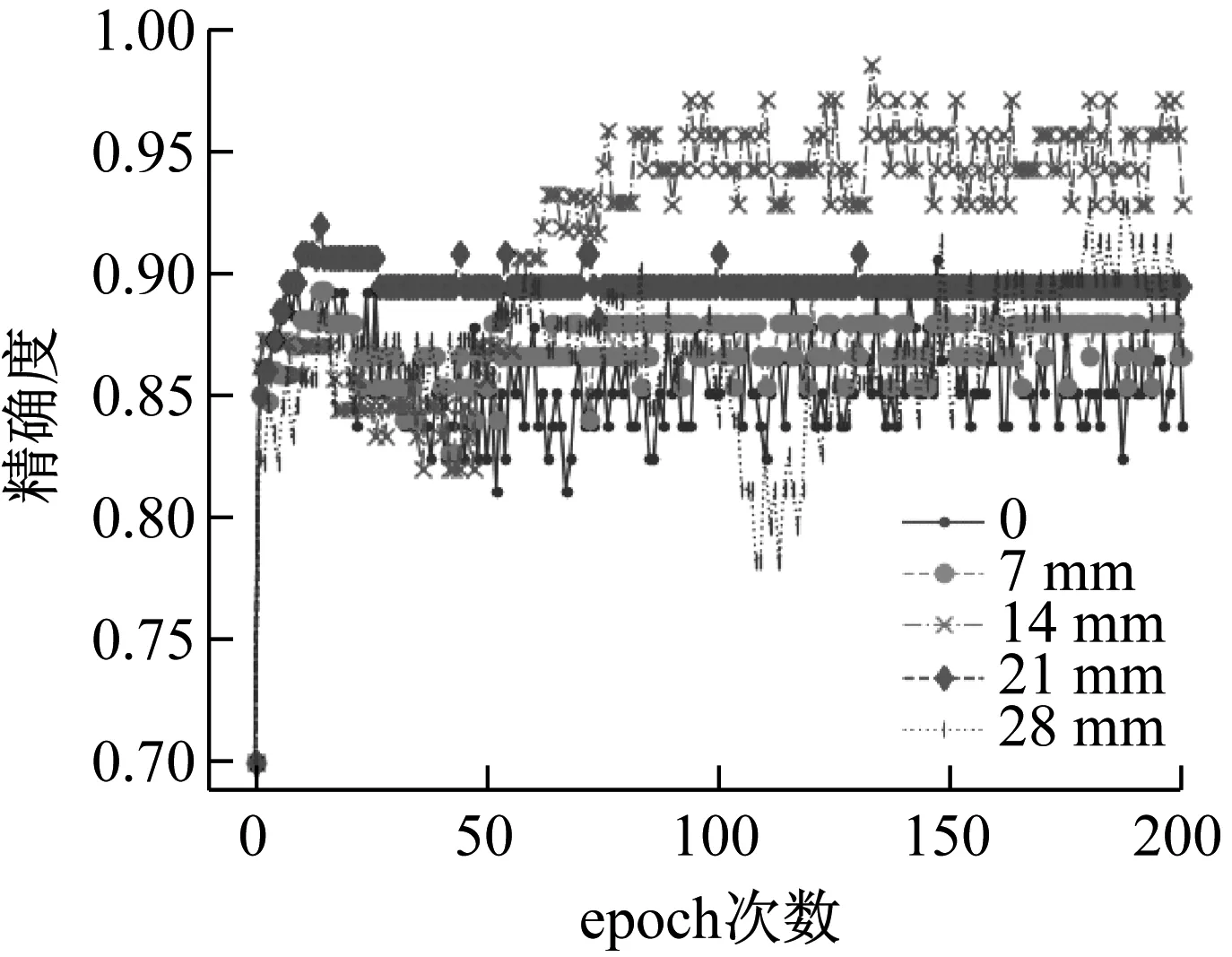
圖17 樣本精確度Fig.17 Precision of samples
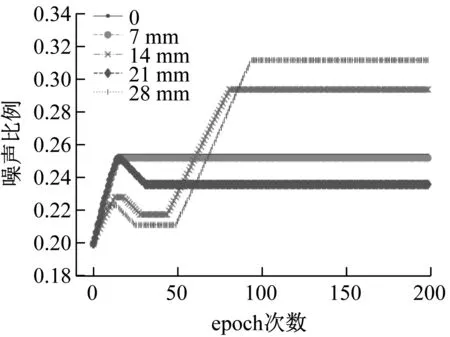
圖18 錯誤標簽比例預測Fig.18 Predicted noise ratio
對于錯誤標簽比例為0.3的軸承數據,本文的方法能夠將平均分類準確度提升17.5%,并保持較小的波動。對比圖17和圖18可以發現,當錯誤標簽比例預測準確的時候,精確度能夠得到較好的提升,如裂紋長度為14 mm時,比例估計為0.3,與實際相符,初步的分類精確度在0.95附近波動,有25%的提升。
4 對比分析
存在錯誤標簽樣本集可以當作未知標簽情況處理,有研究人員通過聚類獲得樣本偽標簽進而辨別錯誤標簽。將錯誤標簽比例η=0.3的齒根裂紋數據集作為對比數據,在堆棧自編碼降維后依次使用KNN,譜聚類,iForest的方法獲取樣本偽標簽以識別錯誤標簽。不同方法獲得的樣本精確度如圖19所示。
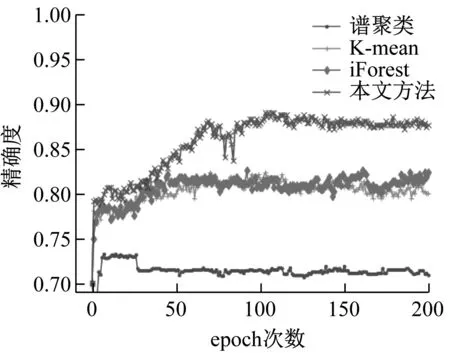
圖19 分類精確度對比Fig.19 Comparison of classification accuracy
相比于本文的方法,使用聚類獲得偽標簽進而判斷錯誤標簽的方法在齒根裂紋數據集中的精確度只能達到80%,譜聚類的方法幾乎沒有帶來精確度的提升。本文改變堆棧自編碼對不同樣本的重視程度,進一步提高了樣本之間的區別,相對于無權重的情況,精確度有8%的提升。
5 結 論
實際問題中,錯誤標簽的出現會使得分類模型產生較差的結果,針對此問題,本文提出了改進堆棧自編碼的方法,在錯誤樣本標簽修正的問題上進行了探索性的研究。對于存在錯誤標簽的樣本集,使用堆棧編碼器進行特征的提取以及正確樣本的篩選,利用孤立森林獲取偽標簽,從而使堆棧編碼器注重于正確樣本。為了彌補權重可能引起的數據偏差,利用基于隨機森林的k折驗證獲取樣本的信息熵,通過閾值修正錯誤的標簽。試驗表明,本文提出的方法在多個錯誤標簽比例下能夠通過修正錯誤標簽來降低樣本錯誤標簽率,提高分類器的分類準確度。
本文同時給出了一些簡單可行的錯誤標簽數據生成,錯誤標簽比例迭代,以及權重賦予的方法,不同參數更新方法對于整體效果的影響也是進一步探索的工作。
猜你喜歡
云南教育·中學教師(2020年11期)2021-01-07 08:26:28
山東煤炭科技(2020年1期)2020-03-06 06:43:28
兒童故事畫報(2019年5期)2019-05-26 14:26:14
新教育時代·教師版(2017年30期)2017-09-12 08:17:15
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
高考金刊·理科版(2012年3期)2012-01-01 00:00:00
