基于改進EfficientDet 網(wǎng)絡的疲勞駕駛狀態(tài)檢測方法
2022-02-01 12:36:22張光德
汽車安全與節(jié)能學報 2022年4期
宋 巍,張光德
(武漢科技大學 汽車與交通工程學院,武漢 430081,中國)
隨著汽車保有量和駕駛?cè)藬?shù)的增長[1-2],交通安全問題也日趨嚴峻。汽車安全事故的發(fā)生與駕駛員的狀態(tài)密切相關(guān),其中疲勞駕駛最為普遍。當駕駛員感到疲倦時,駕駛員行為處置不當和反應力減弱,進而對人生安全和社會財產(chǎn)造成極大危害[3-5]。因此,駕駛員疲勞狀況的實時監(jiān)測是預防交通安全事故發(fā)生的重要手段,值得深入研究。其中,機器視覺與人工智能技術(shù)在人類狀態(tài)與行為識別領(lǐng)域應用廣泛,且效果顯著。
隨著成像技術(shù)與圖形處理器(graphics processing unit,GPU)等軟硬件的快速迭代,基于深度學習的圖像識別技術(shù)應運而生,其以卷積神經(jīng)網(wǎng)絡(convolutional neural networks,CNNs)為特征提取器,克服了傳統(tǒng)機器學習應用中的種種瓶頸,在駕駛員狀態(tài)檢測方面的研究日益增多。王政等[6]針對傳統(tǒng)的、基于單一特征的疲勞檢測方法誤檢率高、可靠性不強、無法適應復雜多變的行車環(huán)境等問題,提出了一種基于深度學習的駕駛員多種面部特征融合的疲勞駕駛檢測方法,取得了相對優(yōu)異的檢測效果。李昭慧等[7]提出一種基于改進YOLOv4 算法的疲勞駕駛檢測方法,測試中平均精度均值(mean average precision,MAP)達到97.29%,相較原YOLOv4 算法提高了1.98%,其中對眼睛部位的檢測精度提高了6%。此外,仍有部分學者基于深度學習技術(shù)對駕駛員疲勞檢測的應用效果進行測試,將不同特征提取網(wǎng)絡、不同模型搭建方式的深度學習目標檢測網(wǎng)絡應用于實際的檢測過程之中,取得了相對優(yōu)異的檢測結(jié)果[8-15]。
然而,大量特征點的定位與識別造成了計算數(shù)據(jù)量和難度大大提升,降低了實時檢測效率。本文通過構(gòu)建多類別疲勞駕駛狀態(tài)圖像數(shù)據(jù)庫,以瞌睡度量方法判定駕駛員的疲勞駕駛狀態(tài),以EfficientDet[16-17]目標檢測網(wǎng)絡提取駕駛員面部圖像特征,以k-means先驗框邊界聚類方法確定目標檢測區(qū)域,并利用雙向特征金字塔網(wǎng)絡檢測駕駛員狀態(tài),避免繁雜面部特征點的細致識別,實現(xiàn)駕駛員疲勞狀態(tài)精確、高效檢測。
1 疲勞駕駛狀態(tài)檢測網(wǎng)絡
1.1 EfficientNet 特征提取網(wǎng)絡
1.1.1 EfficientNet 架構(gòu)
在基礎(chǔ)CNNs 網(wǎng)絡模型(如圖1a 所示)的基礎(chǔ)上提升層寬(如圖1b 所示),即增加網(wǎng)絡特征圖個數(shù)可以使網(wǎng)絡獲得更高細粒度的特征,且降低模型訓練難度。其次,增加網(wǎng)絡層數(shù)(如圖1c 所示),即搭建更深層次的網(wǎng)絡使CNNs 模型有能力提取到更加豐富、復雜的特征,且提取到的特征能被有效應用于具體圖像分類任務之中。此外,提高輸入圖像的分辨率(如圖1d 所示)能夠潛在的獲得更高細粒度的特征模板,即在輸入端提高CNNs 模型的分類性能。因此,若同時優(yōu)化基礎(chǔ)CNNs 寬度、深度及輸入分辨率(如圖1e 所示)則能最大程度上提升卷積神經(jīng)網(wǎng)絡的特征提取能力,進而優(yōu)化模型的圖像分類效果。
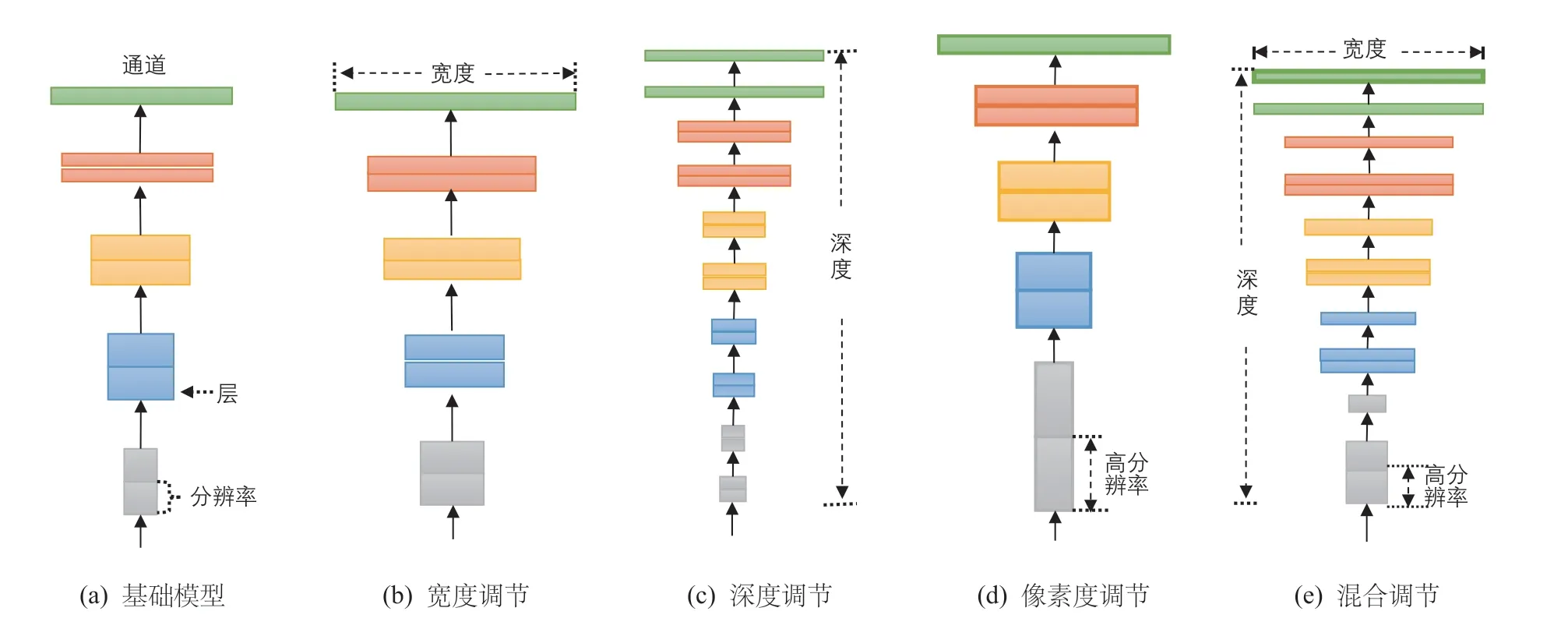
圖1 EfficietNet 設計思路
1.1.2 視覺注意力機制
將視覺注意力機制融入于CNNs 模型中,是一種高效的特征提取方法[18]。在EfficientNet 中,采用“視覺注意力模塊(或壓縮和激勵模塊) (squeeze &excitation block,SE block)”來實現(xiàn)注意力增強。SE 模塊的結(jié)構(gòu)如圖2 所示。
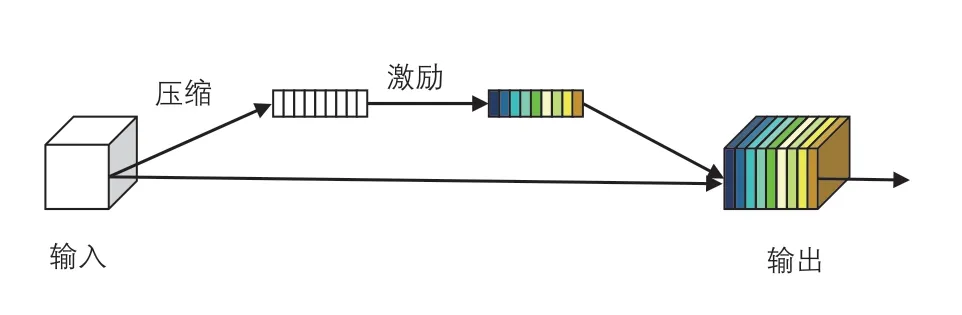
圖2 SE 視覺注意力模塊
SE 視覺注意力模塊是一種基于注意力的特征圖運算。首先對輸入特征圖進行Squeeze 操作,并在通道維度方向上進行全局平均池化(global average pooling)運算,以獲得輸入特征圖在通道維度方向上的全局特征。其次,SE 模塊對全局特征圖進行Excitation 操作,以學習圖像中各個通道之間的關(guān)系。最終,SE 模塊通過sigmoid 激活函數(shù)獲得不同通道所占的權(quán)重,并將各通道權(quán)重與輸入特征圖相乘以獲得最終注意力增強后的特征圖像。
1.2 改進EfficientDet 目標檢測網(wǎng)絡
EfficientDet 主要由EfficientNet 特征提取網(wǎng)絡與雙向特征金字塔網(wǎng)絡(bidirectional feature pyramid network,BiFPN)所組成[19]。
1.2.1 雙向特征金字塔網(wǎng)絡(BiFPN)
特征金字塔網(wǎng)絡(feature pyramid network,FPN)將CNNs 特征提取網(wǎng)絡中較為抽象的頂層特征圖像進行上采樣運算,并將上采樣運算結(jié)果通過橫向連接與特征提取網(wǎng)絡中其他層級所提取的相同特征大小的特征圖像進行融合,在不顯著增加模型計算量的前提條件下顯著提升了深度學習目標檢測網(wǎng)絡對不同尺度目標的檢測性能。啟發(fā)于基礎(chǔ)FPN,研究人員對特征提取網(wǎng)絡中不同層級所提取的特征圖像進行融合實驗,而路徑聚合網(wǎng)絡(path aggregation network,PANet)[20]則是其中一項特征融合效果較優(yōu)的變體網(wǎng)絡。PANet 在PFN 的基礎(chǔ)上提出為特征融合網(wǎng)絡提供自下而上特征融合路徑的方法,進而提升了目標檢測模型對多尺度目標的整體檢測性能,但PANet 的參數(shù)量與計算消耗也較大。
為進一步提升PANet 的深度學習目標檢測技術(shù)在多尺度目標檢測任務中的性能,并降低特征融合網(wǎng)絡的計算消耗,EffiicentDet 將跨尺度連接和加權(quán)特征融合應用于網(wǎng)絡搭建之中,進而提出全新的特征融合網(wǎng)絡BiFPN,如圖3 所示。
以圖3中P6融合特征輸出為例,其運算過程如式(1)和式(2)所示。
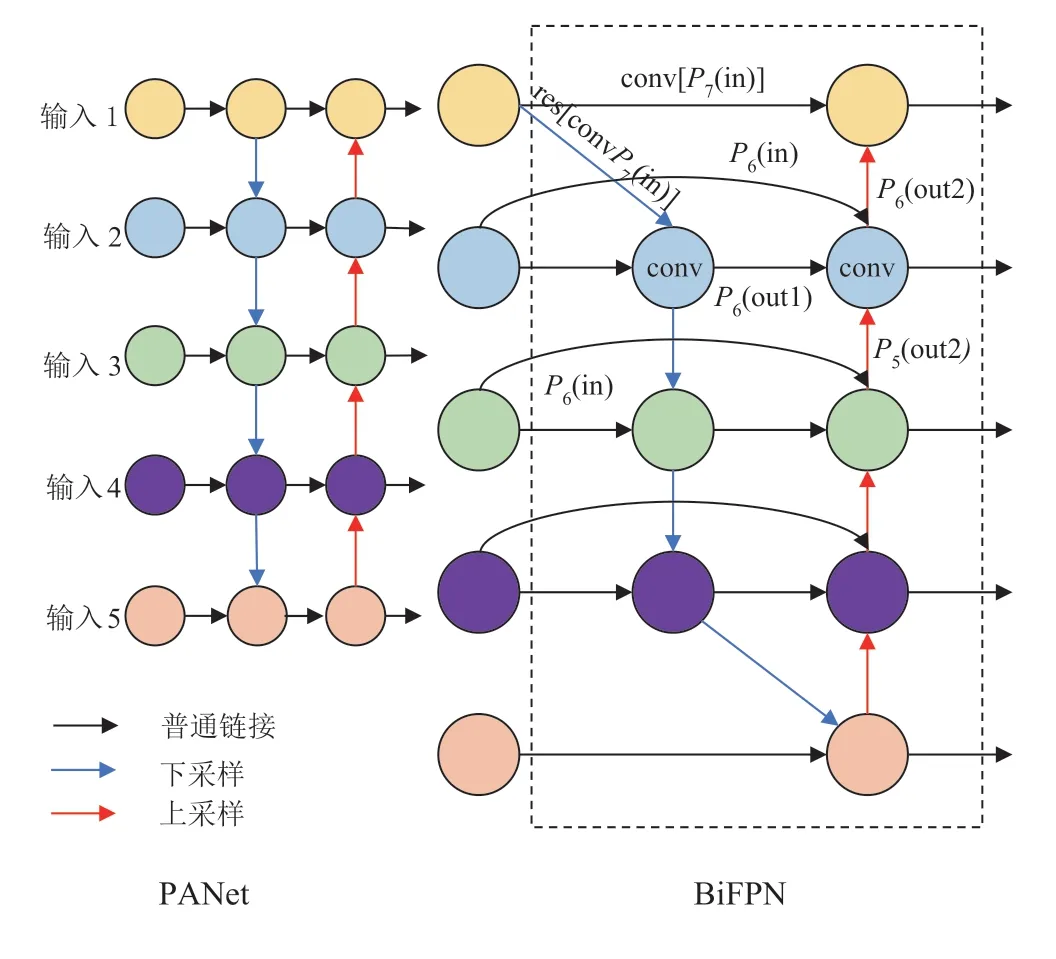
圖3 特征金字塔網(wǎng)絡結(jié)構(gòu)

式中:代表經(jīng)過加權(quán)運算后的代表經(jīng)過加權(quán)最終輸出;代表對應特征層所被賦予的權(quán)重;ε為預設參數(shù),用于防止分母為0,本文預設ε=1×10-4。
1.2.2 EfficientDet 架構(gòu)
EfficientDet 是一類基于EfficientNet 特征提取網(wǎng)絡而提出的深度學習目標檢測架構(gòu),其主要由圖像輸入端、特征提取網(wǎng)絡、BiFPN 特征融合網(wǎng)絡、類別預測網(wǎng)絡與位置預測網(wǎng)絡五個模塊所構(gòu)成,模型架構(gòu)如圖4所示。
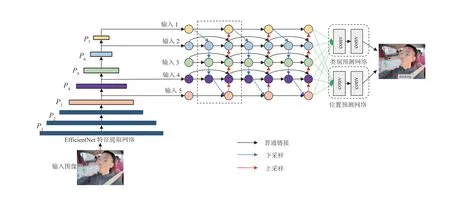
圖4 EfficientDet 目標檢測網(wǎng)絡架構(gòu)
在EfficientNet 特征提取網(wǎng)絡中,模型通過初始階段高效的下采樣與通道維度擴張后獲得P1、P2、P3、P4、P5等5 層的特征圖像,且P5特征圖像經(jīng)過后續(xù)2 次下采樣獲得P6、P72 層的特征圖像,其中P3、P4、P5、P6、P7被應用于BiFPN 的后續(xù)特征加權(quán)融合,而由于P1、P2特征圖像所包含的語義信息較弱,未進行后續(xù)特征融合。其次,為精確定位輸入圖像中目標所在位置,EfficientDet 將BiFPN 所輸出的具有語義和空間信息的特征圖像劃分為N×N個不同網(wǎng)格,以每個網(wǎng)格為錨點生成先驗框,以用于目標定位。最終,類別預測網(wǎng)絡與位置預測網(wǎng)絡將分別對先驗框內(nèi)所包含目標的類別進行判斷和先驗框位置回歸,進而確定輸入圖像中所包含的目標類別與目標位置,完成目標檢測任務。
1.3 先驗框邊界聚類
在EfficientDet 目標檢測網(wǎng)絡中,先驗框的高寬比(aspect ratios)由實驗者手動設計,更加貼合具體檢測任務實踐的預設高寬比將有效提高模型的收斂速度與目標檢測準確度。因此,為提高疲勞駕駛狀態(tài)目標檢測網(wǎng)絡的模型收斂速度與檢測準確性,本文提出采用k-means 聚類方法來確定預設先驗框高寬比的優(yōu)化方案。其中,k-means 主要通過以下步驟完成先驗框高寬比聚類任務:
步驟1隨機選取疲勞駕駛樣本圖像中的k個真實框作為初始化簇心,即anchor box。
步驟2順序計算疲勞駕駛樣本圖像樣本中每個真實框與k個anchor box 之間的距離,并將距離簇心最近的真實框樣本劃分為該類,其距離為
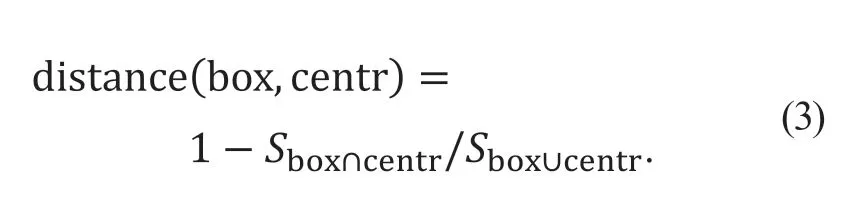
式中:box 為邊界框位置;centr 為簇心點位置;Sbox∩centr為聚類中心與真實框相交區(qū)域面積;Sbox∪centr為聚類中心與真實框并集區(qū)域面積。
步驟3計算簇心除所有真實框的參數(shù)均值、更新簇心位置,并不斷重復步驟2、步驟3 過程,直至簇心點確定。
因此,通過k-means 預設先驗框高寬比聚類過程,其最終的高寬比能夠有效反映圖像數(shù)據(jù)集中的目標形狀特征及大小,進而確定更為合理的預設先驗框高寬比值,以優(yōu)化目標檢測網(wǎng)絡的訓練過程與檢測效果。
2 實驗驗證
2.1 數(shù)據(jù)預處理與數(shù)據(jù)集制備
面向于駕駛員疲勞駕駛檢測的實際任務,本實驗選取正常駕駛狀態(tài)及3 種疲勞駕駛狀態(tài)下的圖像為研究對象,其中,3 種疲勞駕駛狀態(tài)圖像包括閉眼樣本、張嘴樣本和低頭樣本。本數(shù)據(jù)由專業(yè)圖像數(shù)據(jù)公司所采集,其攝像機部署位置在機動車左側(cè)A 柱上方,該拍攝位置能夠清晰、直觀的獲取駕駛員在駕車行駛過程中的行為,并對駕駛過程中疲勞駕駛狀態(tài)下的圖像進行采集,且選取各類別中2 張圖像為示例,攝像機部署位置及圖像拍攝效果如圖5 所示。

圖5 攝像機部署位置及疲勞駕駛圖像數(shù)據(jù)集示例
在實驗數(shù)據(jù)集準備階段,采用8 : 1 : 1 劃分疲勞駕駛圖像訓練集、測試集與驗證集。同時,為避免模型訓練過程中可能出現(xiàn)的訓練數(shù)據(jù)量不足及組間數(shù)據(jù)量不平衡等問題,采用色彩變換、旋轉(zhuǎn)等圖像數(shù)據(jù)增強技術(shù)擴充數(shù)據(jù)集大小,經(jīng)數(shù)據(jù)增強后的圖像數(shù)據(jù)集中各類別的數(shù)據(jù)量如表1 所示。
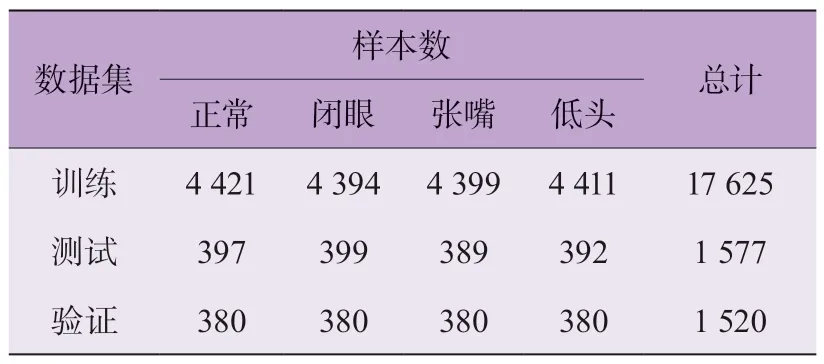
表1 駕駛員疲勞駕駛圖像數(shù)據(jù)集劃分
2.2 實驗條件與評價指標
采用平均精度均值(mean average precision,MAP),檢測頻率(每秒幀數(shù),frame per second,FPS),召回率(Recall)和訓練時間(Time,或t)等常用指標來評價EfficientDet 目標檢測性能。其中,Recall 表征查全率,Time 表征訓練難度。在MAP 值的計算過程中需要使用P(Precision)和R(Recall) 2 個指標:

式中:tp (true positive)為模型檢測正確的駕駛行為數(shù)量;fp (false positive)為模型檢測錯誤的駕駛行為數(shù)量;fn (false negative)為模型漏檢的駕駛行為數(shù)量。
模型的平均檢測精度(average detection precision,AP)代表了以P為橫軸、以R為縱軸的P-R曲線下的面積,即
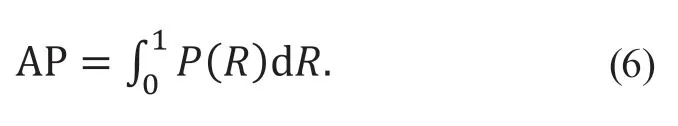
平均精度均值為
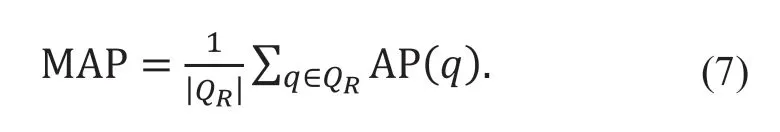
式中:QR為測試集中所包含圖像個數(shù)。
實驗過程中,通過Win10 系統(tǒng)Python 環(huán)境搭建疲勞駕駛圖像檢測模型,其訓練環(huán)境條件如表2 所示。
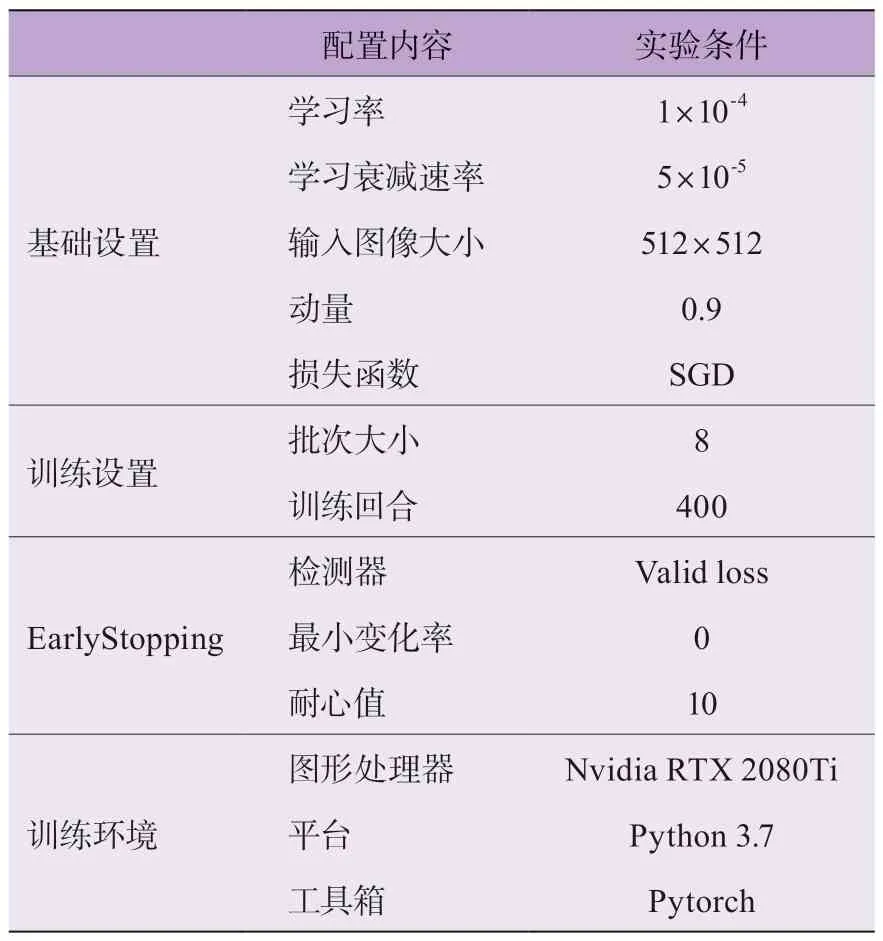
表2 實驗模型訓練環(huán)境條件
另外,采用Carnegie Mellon 研究所實驗驗證[21]的、用來判定駕駛員疲勞狀態(tài)的瞌睡程度指數(shù)為

計算結(jié)果的疲勞駕駛評價標準如表3 所示。其中,疲勞狀態(tài)幀數(shù)包括 閉眼、張嘴、低頭 3 種表現(xiàn)形式的幀數(shù);依照Perclos[21]的計算結(jié)果,可以劃分為正常駕駛狀態(tài)、輕微疲勞駕駛、嚴重疲勞駕駛 3 種駕駛狀態(tài)。同時,在駕駛員疲勞駕駛狀態(tài)的檢測任務中,考慮實時性,檢測時間總幀數(shù)設置為0.8 s,以此來判別駕駛員當前時段的駕駛狀態(tài)。
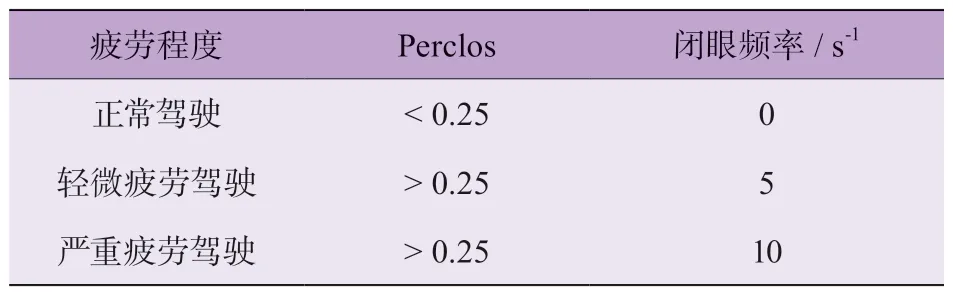
表3 疲勞駕駛評價標注
2.3 實驗結(jié)果與分析
在本實驗中,未使用k-means 先驗框邊界聚類算法時,使用平均精度均值MAP、召回率R、檢測頻率FPS、訓練時間t等4 個評價指標來評估各階段EfficientDet 疲勞駕駛目標檢測模型。結(jié)果如表4 所示。
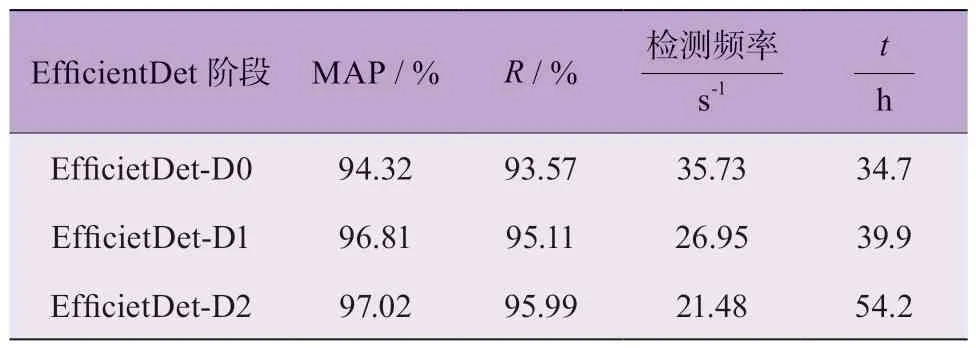
表4 未使用k-means 先驗框邊界聚類算法時各階段EfficientDet 的檢測性能
EfficientDet-D2 模型的平均檢測精度相對更高;EfficientDet-D1 次之;EfficientDet-D0 平均 檢測精度MAP 相對較低;其他3 個指數(shù)也展現(xiàn)出了類似的變化趨勢,R指數(shù)、訓練時長t隨著特征提取網(wǎng)絡的優(yōu)化而逐漸增大,檢測頻率隨著特征提取網(wǎng)絡的優(yōu)化而逐漸減小,主要原因在于不同模型的圖像特征提取能力不同,影響了模型檢測精度和效率。
使用k-means 先驗框邊界聚類方法實現(xiàn)先驗框大小比例的預先決策。同時,在疲勞駕駛圖像先驗框邊界聚類實驗時,不改變特征層預設先驗框尺度大小及個數(shù)的前提下,聚類類別k選定為3,即聚類出3 種符合駕駛員疲勞駕駛圖像檢測先驗框分布的長寬比。之后,將各尺度大小的先驗框各自分配聚類后,3 組長寬比能夠在特征層上生成9 種先驗框,且經(jīng)過20 次聚類實驗,所得聚類精確度最高的3 組先驗框長寬比比例分別為(55,63)、(59,53)、(56,57)。
以上述3 組先驗框長寬比例為先驗框預設值,3 種EfficientDet 目標檢測網(wǎng)絡的評價指標,以及以相同數(shù)據(jù)集訓練并測試的YOLO V3、Faster-RCNN 模型的實際檢測效果,如表5 所示。
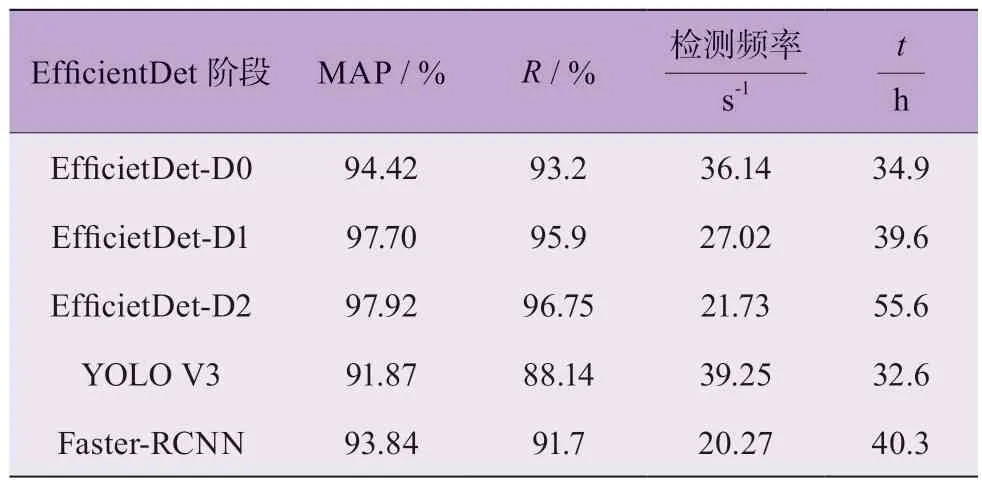
表5 使用k-means 先驗框邊界聚類算法時各模型的檢測性能
對比于未使用k-means 先驗框邊界聚類算法時的檢測性能,其檢測精度均有一定幅度的提升,這表明k-means 先驗框邊界聚類算法的使用能在一定程度上優(yōu)化目標檢測網(wǎng)絡的檢測性能。YOLO V3、Faster-RCNN 模型的檢測精度相比于EfficientDet 模型稍差,但YOLO V3 框架的檢測頻率較高,訓練耗時較短,而Faster-RCNN 框架并沒有明顯優(yōu)勢。總體來說,本文所提EfficientDet-D2 模型檢測精度最高,檢測速度適中,綜合檢測效果較好。
選取除采樣人員外的2 名測試人員進行駕駛測試,并錄制對應視頻。實驗模擬真實駕駛環(huán)境,由實驗人員側(cè)前方攝像頭實時采集面部信息,分別模擬出3 種疲勞駕駛狀態(tài)。每位實驗人員分別進行100 次模擬實驗,共進行200 次模擬實驗。其測試結(jié)果如表6所示。
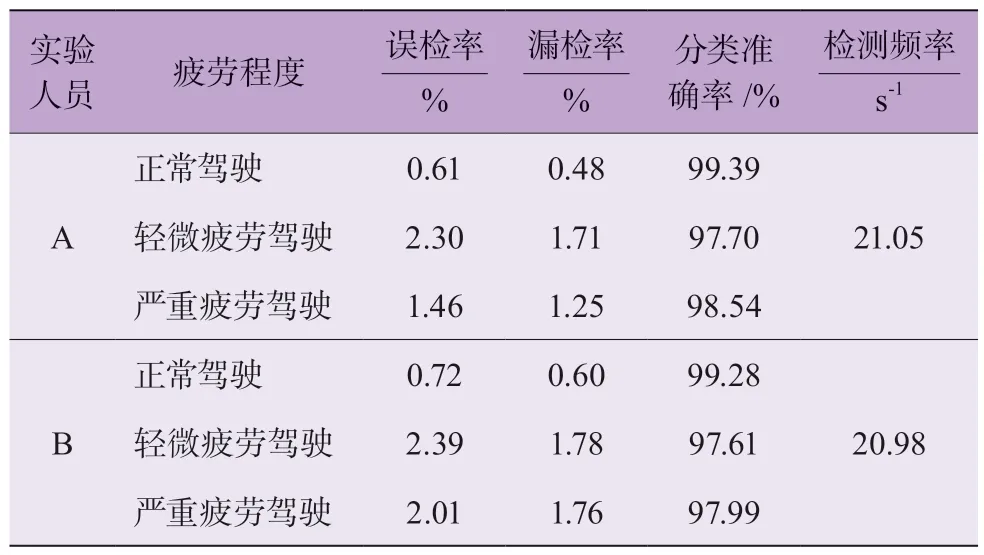
表6 使用先驗框邊界聚類算法的視頻檢測效果
使用先驗框邊界聚類算法的EfficietDet-D2 在2 名實驗人員拍攝視頻中的檢測過程如圖6 所示。整體趨勢上,使用先驗框邊界聚類算法的EfficietDet-D2 誤檢率及漏檢率相對較低,且分類準確率相對較高。其次,正常駕駛狀態(tài)下的檢測精度較高,而在駕駛員輕微疲勞駕駛狀態(tài)下的檢測精度相對要低,這表明輕微疲勞駕駛狀態(tài)仍是當下基于深度學習的疲勞駕駛檢測算法的應用難點。此外,EfficietDet-D2 模型檢測速度分別達到21.05 和20.98,即檢測速度相對較快,且面對不同駕駛員時的檢測速度相對接近。

圖6 EfficientDet-D2 在2 名實驗人員拍攝視頻中的檢測過程
3 結(jié)論
本文提出了一種基于改進EfficientDet 深度學習網(wǎng)絡的疲勞駕駛視覺檢測方法。通過深度可分離卷積與移動反轉(zhuǎn)瓶頸卷積模塊降低了特征提取網(wǎng)絡部分的計算復雜度,提升了圖像特征的提取效率;應用視覺注意力機制并構(gòu)建擠壓與激勵模塊,進一步加強整個檢測網(wǎng)絡的特征提取能力,并融合檢測模型中低層位置信息與高層語音信息,增加了網(wǎng)絡整體的信息流動性;同時,采用k-means 聚類算法對數(shù)據(jù)集中的真實框進行統(tǒng)計,設定更加符合具體任務需求的先驗框,優(yōu)化了網(wǎng)絡特征提取方向,降低了模型對冗余信息的關(guān)注度。對比分析3 種不同深度、不同寬度、不同分辨率大小的改進EfficientDet 模型以及YOLO V3、Faster-RCNN模型檢測效果。
結(jié)果表明:使用k-means 先驗框邊界聚類算法時的EfficientDet 模型檢測精度和幀率均有一定幅度提升,其中EfficientDet-D2 模型檢測效果較好,其平均精度和召回率分別達到97.92%和96.75%,誤檢率和漏檢率分別低于2.39%和1.78%。
猜你喜歡
汽車實用技術(shù)(2022年14期)2022-07-30 06:13:42
汽車實用技術(shù)(2022年4期)2022-03-07 06:07:20
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫(yī)學工程學報(2017年6期)2017-02-10 05:11:45
公民與法治(2016年4期)2016-05-17 04:09:26
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
河南科技(2014年23期)2014-02-27 14:19:15
