基于目標檢測模型的無人機影像識別技術
2022-02-07 09:20:00孫盼盼丁學文常黎玫蔡鑫楠董國軍
智能計算機與應用 2022年12期
孫盼盼,丁學文,3,常黎玫,蔡鑫楠,董國軍
(1 天津職業技術師范大學 電子工程學院,天津 300222;2 天津市高速鐵路無線通信企業重點實驗室,天津 300350;3 天津云智通科技有限公司,天津 300350)
0 引言
目標檢測作為計算機視覺的研究熱點之一,引起了各國學者的關注。近年來深度學習的目標檢測算法得到了快速發展,識別精度和速度也在不斷提升。基于深度學習的目標檢測算法分為2 類:一階段和兩階段。其中,SSD[1-2]和YOLO(You Only Look Once)系列[3-6]是一階段檢測算法,R-CNN[7]、Fast R-CNN[8]和Faster R-CNN[9]是兩階段檢測算法。與兩階段識別相比,一階段識別準確率略低,但識別速度要快上數百倍。在單階段算法中,YOLOv5比SSD 快2~3 倍,所以YOLOv5 在開發人員中更受歡迎。目前,YOLOv5 已然廣泛應用在對實時性要求較高的各種目標識別領域中。雖然YOLOv5 具有良好的目標檢測性能,但對無人機影像這類小目標的識別率卻較低。與其他目標相比,容易發生漏檢和誤檢,這在一定程度上限制了YOLOv5 的使用。在實際應用場景中,會有相當多的對象都是小目標,小目標在圖像中面積小、特征也不明顯,采用多層卷積神經網絡后,可能出現部分特征丟失的問題,從而導致識別率的下降。針對以上問題,本文提出改進的YOLOv5 目標檢測算法,該算法增加了有利于小目標的處理,從而提高了精確率、召回率和平均精確率。
1 YOLOv5 算法及改進
1.1 YOLOv5 網絡結構
YOLOv5 按照網絡深度和網絡寬度的大小,可以分為YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x。YOLOv5s 的網絡結構最為小巧,同時圖像推理速度最快達0.007 s,故本文使用YOLOv5s模型。YOLOv5s 的網絡結構如圖1 所示。由圖1 可知,YOLOv5s 的網絡結構主要由輸入端、基準網絡、Neck 網絡以及Head 輸出端四部分組成。對此將展開研究分述如下。
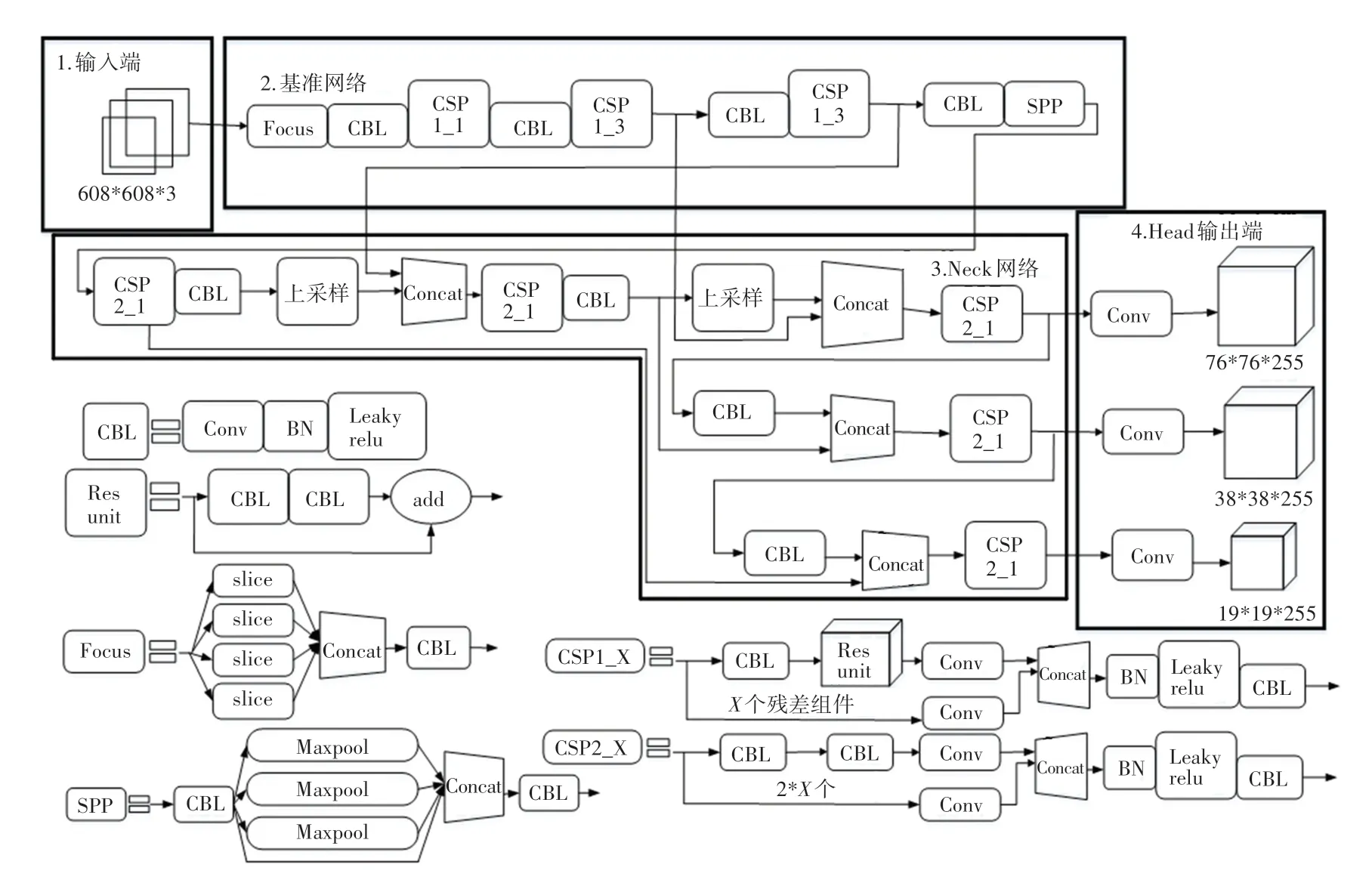
圖1 YOLOv5s 的網絡結構Fig. 1 Network structure of YOLOv5s
(1)輸入端。表示輸入的圖片的部分。YOLOv5s 輸入大小為608*608 的圖像,該階段會把輸入圖像進行縮放,直至與網絡的輸入大小相等,再對圖像進行歸一化處理。在網絡訓練階段,YOLOv5s 為了提高網絡模型的訓練速度和網絡精度,在網絡模型中增加了Mosaic 數據增強操作;為了使數據集多樣化以及減少GPU 的占用,在網絡模型中增加了自適應錨框的計算以及自適應圖片縮放。
(2)基準網絡。通常是提取一些通用的特征。YOLOv5s 中使用了CSPDarknet53 和Focus 網絡結構作為基準網絡,CSP 結構是用來進行下采樣的,但和傳統卷積的下采樣不太相同,CSP 結構可以對Focus 的計算量和普通卷積的下采樣計算量進行比較。
(3)Neck 網絡。通常位于基準網絡和輸入端之間的位置,利用Neck 網絡可以使提取的特征具有多樣性及更好的穩定性。YOLOv5s 用到了FPN+PAN模塊,FPN 層是自頂向下的特征卷積用于傳達強語義特征,而特征金字塔是自底向上的特征卷積用于傳達強定位特征,兩兩聯合,從不同的主干層對不同的檢測層進行參數聚合,進而達到很好的效果。
(4)Head 輸出端。用來完成目標檢測結果的輸出。YOLOv5s 主要是GIoU_Loss代替IoU作為bounding box 回歸的損失,IoU的缺點是不重合或者重合面積相等,而YOLOv5s 的GIoU在計算時,不同位置的預測框都會對GIoU產生影響,從而彌補了IoU的不足,并進一步提升算法的檢測精度。
1.2 YOLOv5 效果展示
不同版本的YOLOv5 檢測算法在COCO2017 驗證集與測試集上的檢測效果如圖2 所示。
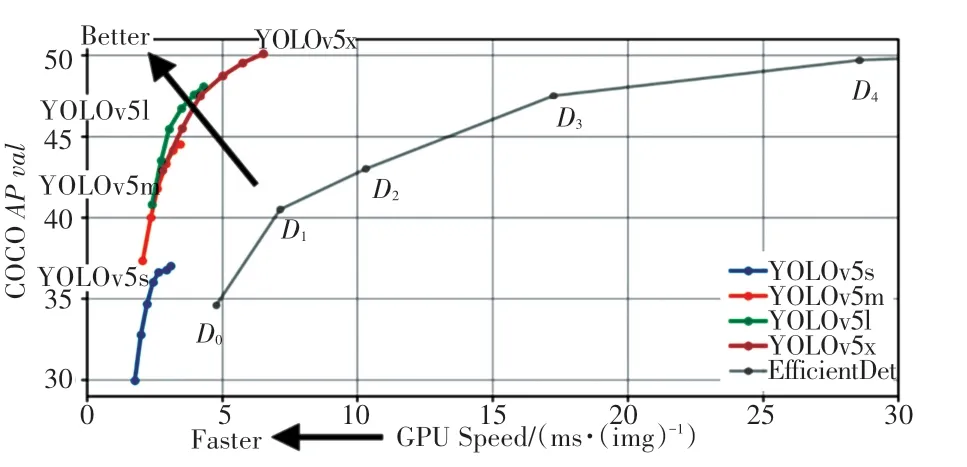
圖2 YOLOv5 效果展示Fig. 2 YOLOv5 effect display
圖2 中,橫軸表示YOLOv5 算法在GPU 上推理出每張圖片需要的毫秒數,距原點越近、效果越好;縱軸表示YOLOv5 算法在COCO2017 的測試集上測試出的AP值,距離原點越遠、效果越好。通過觀察分析可以看出,相較于EfficientDet,YOLOv5s 的AP值更高,而且推理速度更快;相較于YOLOv5m、YOLOv5l、YOLOv5x,YOLOv5s 具有更高的速度,但AP值并不高,不過也在可接受范圍內。
YOLOv5 的整體效果展示見表1。由表1 可知,YOLOv5s 的輸入圖片分辨率為640*640,在COCO測試集與驗證集上的AP指標為36.8,AP50 指標為55.6。該算法在V100 GPU 上的推理速度僅僅需要2.2 ms,幀率為455 FPS,該網絡的模型大小僅為7.3 M。相對YOLOv5m、YOLOv5l 及YOLOv5x 模型來說,YOLOv5s 的速度更快、模型較小、且精度也較高。故而,在本文中擬選擇YOLOv5s 模型進行研究。

表1 YOLOv5 效果展示Tab.1 YOLOv5 effect display
1.3 YOLOv5s 算法的改進
考慮到YOLOv5s 對傳統目標檢測較好,但對小目標經常出現誤檢、漏檢,從而造成精度較低的問題,本文提出了改進的YOLOv5s。改進的YOLOv5s主要是在第17 層后,對特征圖增加上采樣操作,使特征圖繼續擴大,如此一來就改善了小目標淺層語義信息不足的缺陷。
2 實驗及結果分析
2.1 數據集的相關說明
本文實驗采用無人機影像VisDrone 數據集。VisDrone 數據集由中國天津大學機器學習和數據挖掘實驗室的AISKYEYE 團隊收集并且標注的[10]。該數據集在采集時把攝像機架設在無人機上,在中國14 個不同地區的城市和村莊以及不同的天氣和光照下,采集稀疏程度不同的行人、小汽車、三輪車、自行車等不同的物體。VisDrone 目標檢測數據集中包 括 pedestrian、people、bicycle、car、van、truck、tricycle、awning-tricycle、bus、motor 共10 類被標注的物體。其中,pedestrian 為直立姿勢或者行走的人,除pedestrian 以外的人定義為people。通過對數據集進行分析,得到可視化結果,如圖3 所示。

圖3 數據集可視化結果Fig. 3 Visualization results of the dataset
由圖3(a)中可以看出,圖像中的大多數都是較小的標記框。由圖3(b)中可以看出,物體中心點位置在x軸方向大多數分布在0.4~0.6 之間,在y軸方向大多數分布在0~0.6 之間。在圖3(c)中,橫坐標表示物體的寬,縱坐標表示物體的高。綜合圖3(b)和圖3(c)的分析可知,該數據集中小物體較多,并且存在一定程度的遮擋。
2.2 實驗環境參數
本文實驗采用的電腦硬件配置及Pycharm 軟件設置情況見表2。

表2 實驗環境參數Tab.2 Experimental environmental parameters
2.3 模型評價指標
預測值為正例,記為P(Positive);預測值為反例,記為N(Negative);預測值與真實值相同,記為T(True);預測值與真實值相反,記為F(False)。改進的 YOLOv5s 采用平均精度(mean average precision,mAP)來驗證所提模型相較于YOLOv5s模型的優越性。mAP在計算時需用到Precision、Recall、AP,對此可做闡釋表述如下。
(1)精度。具體計算公式為:
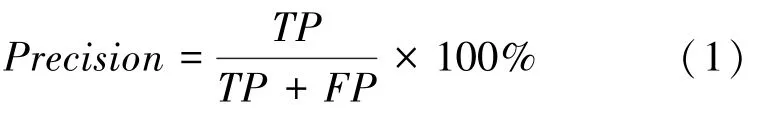
(2)召回率(Recall)。具體計算公式為:

(3)AP和mAP。具體計算公式為:

2.4 不同模型檢測精度對比
本實驗選用數據集中的6 471 張圖片作為訓練集,548 張圖片作為驗證集訓練300 次,YOLOv5s 和改進YOLOv5s 的VisDrone 數據集的評估結果見表3。
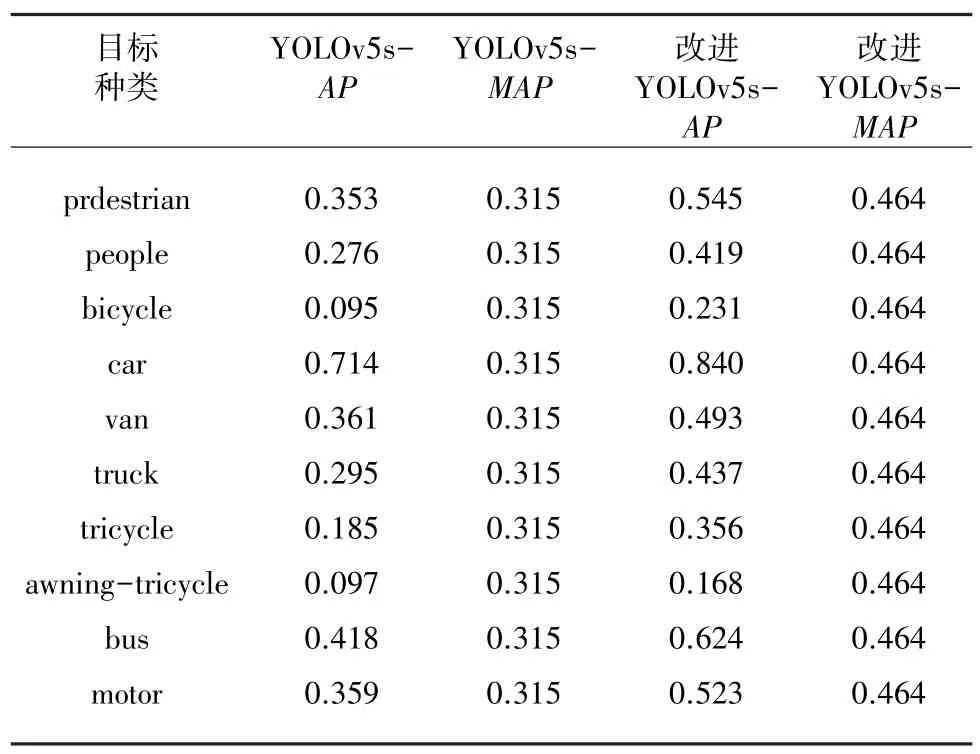
表3 VisDrone 數據集結果評估Tab.3 Results evaluation of VisDrone data set
從仿真實驗結果可以看出,改進YOLOv5s 各個類別的AP值都有10%~15%的提升,mAP值提升了14.9%,由此可見改進的YOLOv5s 確實對小目標有了很好的改善。
訓練結束后,本文采用無人機重新捕獲圖片進行測試,運行的效果如圖4 所示。

圖4 測試結果Fig. 4 Test results
為方便查看無人機影像的檢測結果,從圖像中選取圖4(a)的局部區域①、②、③,如圖5(a)~(c)所示,選取圖4(b)的局部區域①、②、③,如圖6(a)~(c)所示。
圖5(a)中把井蓋誤檢為bicycle,圖6(a)中此井蓋沒有被認為是標簽中的物體;圖5(b)中漏檢多輛被樹木遮擋的car,圖6(b)中被樹木遮擋的car 均被正確檢出;圖5(c)中把tricycle 誤檢為car,漏檢pedestrian 和people,car 的概率為39%;圖6(c)改進YOLOv5 測試結果中將該car 的概率提升為72%,pedestrian 和people 均被正確檢出,但此圖卻把tricycle 誤檢為motor。因此改進的YOLOv5s 改善了漏檢、誤檢以及檢測效果不佳的問題,也仍有待進一步擴充數據集,并且進行更多訓練來優化模型。總之,改進的YOLOv5s 算法在小目標檢測方面已經具有較好的檢測性能。

圖5 YOLOv5s 測試結果Fig. 5 YOLOv5s test results

圖6 改進YOLOv5s 測試結果Fig. 6 Improved YOLOv5s test results
3 結束語
針對自然環境使用YOLOv5s 檢測無人機影像時出現的漏檢、誤檢以及檢測效果欠佳等問題,本文提出了一種基于YOLOv5s 模型改進的無人機影像檢測模型。研究中,在17 層后增加上采樣模塊,來彌補淺層特征語義信息的不足,從而提高了模型的特征提取能力,模型的檢測精度也得以提升。改進后的YOLOv5s 與原網絡的無人機影像檢測模型對比,獲得了很好的檢測結果,然而整體的平均精度稍微偏低。在今后的研究當中,將會在這一方向做更加深入的探討,以利于有效提升最終效果。
猜你喜歡
中老年保健(2021年12期)2021-11-30 02:58:01
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
中華詩詞(2018年11期)2018-03-26 06:41:34
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年8期)2016-10-09 02:11:50
