改進YOLOv4 的車輛圖像檢測算法研究
2022-02-07 09:20:28劉瑞峰孟利清
智能計算機與應用 2022年12期
劉瑞峰,孟利清
(西南林業大學 機械與交通學院,昆明 650224)
0 引言
近年來,隨著經濟和社會的發展,機動車作為一種方便的交通工具得到大規模的使用,截至2022 年3 月底,全國機動車保有量達4.02 億輛。然而眾所周知的是,機動車輛事故也可能會給社會及個人帶來嚴重危害。基于此,無人駕駛汽車的開發和推廣對保障行車安全、提高通行效率發揮著重要作用[1]。自動駕駛日益受到廣泛關注。目標檢測作為自動駕駛環境感知中圖像方面的關鍵技術,也吸引了眾多學者參與研究[2]。丁樂樂[3]提出了一種深度學習與強化學習相結合的方法來對大巴車、轎車和貨車進行分類。然而,由于缺乏有效訓練數據集,即需進一步證明模型的適應性。余勝等人[4]提出了復雜場景下車輛識別方法,對漏標注、誤標注的車輛進行重新標注,但是卻沒有關注到自動駕駛場景下的遮擋問題。在自動駕駛視角下,車輛目標往往會存在如目標間遮擋、環境背景遮擋等現實問題[5],會直接影響目標檢測的準確度。在真實環境下對車輛檢測的錯誤,會對自動駕駛造成不小的干擾,甚至引發后續安全問題。
因此,對于真實場景下因車輛間遮擋、環境背景遮擋而導致的車輛檢測中產生的誤檢、漏檢等問題,亟需研發能夠在復雜場景中對車輛進行較為準確檢測的車輛檢測算法。研究可知,YOLOv4 算法有著檢測準確率高和檢測速度快的優點,能滿足車輛檢測對實時性和準確度的要求[6]。但是YOLOv4 算法應用于車輛檢測時,也存在因復雜場景下車輛重疊遮擋和環境背景遮擋問題導致的誤檢和漏檢問題[7]。
因此,本文提出了一個改進的YOLOv4 算法,在YOLOv4 網絡的Neck 部分添加了CBAM 通道和空間注意力機制。并采用k-means 均值算法,生成合適的錨框應用于該網絡,提升算法對真實環境下不同尺寸車輛的識別率。以期為自動駕駛車輛識別提供一個有效的方法。
1 改進的YOLOv4 算法
1.1 YOLOv4 算法
YOLOv4 的輸入為固定大小。主干網絡(Backbone)與YOLOv3算法相比,使用了CSPDarkNet 網絡。CSPDarkNet 網絡的整體CSP 結構是將原來的網絡分為2 部分。一部分是原來的殘差結構、另一部分通過運算后直接與前一部分的運算結果結合,有效提升了網絡的學習能力。YOLOv4網絡在保持一定輕量化的同時,擁有較高的識別精度。主干網絡與頸部網絡通過3 個尺寸的通道頭進行連接。3 種尺度用以檢測大、中、小型的物體。網絡的頸部(Neck)采用了PANet 結構,用來進行特征融合。為YOLOv4 網絡還提出了moasic 數據增強方法,使網絡能夠在有限的數據集上得到更好的效果。
1.2 注意力機制
CBAM 注意力機制包括通道注意力機制(Channel Attention Module,CAM)和空間注意力機制(Spartial Attention Module,SAM)[8]。CBAM 模塊中,通道注意力模塊的輸出作為空間注意力模塊的輸入。CAM 模塊中,輸入特征圖先經過一個全局平均池化和全局最大池化層,再經過Sigmoid激活操作,生成通道注意力特征Mc,再與該模塊的輸入相乘,得到空間注意力模塊需要的特征圖。通道注意力特征Mc計算公式可表示為:
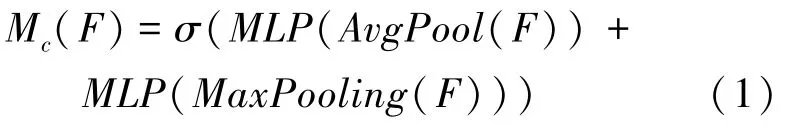
其中,“σ” 為Sigmoid操作。
SAM 空間注意力模塊中,輸入特征圖同時進入全局平均池化和全局最大池化,通過2 個池化層進行通道拼接,經過7*7 卷積層卷積操作后輸入Sigmoid層,由此得到的空間注意力特征Ms與該子模塊的輸入做乘法,得到最終生成的特征。空間注意力特征計算Ms可由式(2)進行描述:
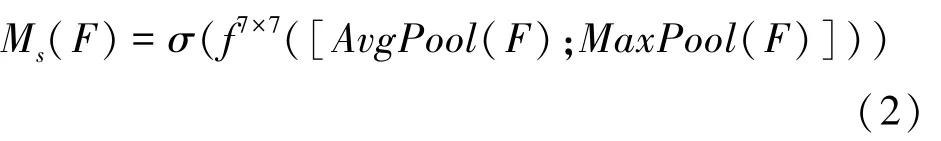
1.3 k-means 算法
聚類算法是能夠通過數據的特點,將具有相似特征的數據分為同類的算法[9]。k-means 算法是通過選定K個中心點,再計算數據中每個例子到中心點的歐氏距離,將距離相近的數據劃分到一類。分類后,重新計算同類數據的中心點,得到K個新的中心點后重復上述過程。當各類別中的數據劃分不再變化時,最終確定K個中心點。k-means 聚類算法的損失函數具體如下:
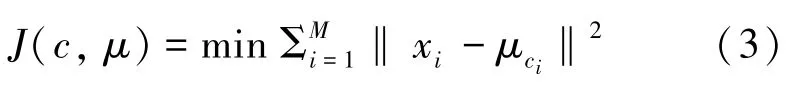
將K-means 聚類算法引入到錨框的選定上,可以提高檢測的準確率[10]。通過k-means 算法計算錨框時,需要引入新的損失函數來評價錨框。采用IoU的損失函數見式(4):

其中,i為目標真實框的長寬;c為中心點的長寬;IoU是計算聚類中心與真實框交并比的過程。交并比是2 個框在圖像上的交集與并集之比,交并比越接近1,說明2 個框的重合程度越高。因此,用1 減去交并比的差來作為本文聚類算法的損失函數,能夠較為合理地評價錨框對于指定數據集的優劣。本文由BBD100K 數據集生成的anchor box 尺寸大小 為[6,2],[7,5],[10,4],[11,7],[17,6],[23,11],[42,17],[78,31],[165,72]。
1.4 改進的YOLOv4 算法
本文主要對YOLOv4 算法的網絡結構、錨框生成進行改進。網絡結構上,本文將CBAM 注意力模塊分別添加在PANet 的3 個輸入后面,再分別添加4 個CBAM 注意力模塊到2 個上采樣和2 個下采樣模塊上的輸出上。注意力模塊對輸入的通道和空間位置進行加權后輸出,不改變特征圖的維度。改進后的YOLOv4 模塊如圖1 所示。同時,網絡采用了由k-means 聚類算法在數據集上計算出的錨框,可以使錨框尺寸適合數據集中的物體。
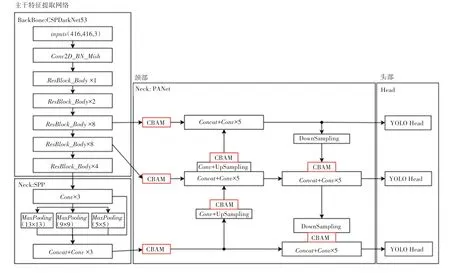
圖1 改進的YOLOv4 目標檢測網絡Fig. 1 Improved YOLOv4 target detection network
2 實驗
2.1 數據集和實驗平臺
數據集選用由加州大學伯克利分校發布的BBD100k 數據集,這是自動駕駛領域規模最大,場景最多樣的駕駛視頻數據集之一。數據集中包含晴天、陰雨天、夜晚等各種車輛行駛中采集的圖像數據。本文從中選取了10 000 張圖片作為數據集,其中2 000 張為測試集,1 600 張為驗證集,6 400 張為訓練集。本文刪去原數據集的pedestrian、rider、train、motorcycle、bicycle、traffic light、traffic sign、trailer 類,將car、truck、bus 合并為vehicle 類。
實驗平臺為Windows10,GPU 為RTX3070,顯存為8 G;CPU 為R9 5900hx,內存為16 G。
2.2 參數設置
消融實驗中,優化器種類為Adam,初始學習率設為0.001,最小學習率為0.000 01,momentum設為0.937,學習率下降方式設為cos。epoch設為100,使用主干網絡預訓練權重,前50 個epoch凍結Backbone 訓練,凍結時batch_size設為8,解凍階段batch_size設為4。輸入圖片尺寸設為416×416,使用mosaic 數據增強方法。
對比實驗中,優化器為Adam,學習率下降方式設為cos,epoch設為100,凍結訓練50 個epoch后進行解凍訓練。其他參數因各算法網絡結構不同,選擇各模型推薦參數進行訓練。
2.3 消融實驗
為驗證改進網絡的效果,進行消融實驗。改進前后網絡在測試集上的表現見表1。由表1 可知,添加了注意力機制后的網絡在數據集上的準確率Precision達到了82.23%,比基線網絡提高了4%。添加了k-means 算法生成的錨框后,準確率達到了83.24,比基線網絡提高了5.3%。添加了注意力機制并采用k-means 算法生成錨框的模型與基線網絡相比,準確率達到了82.62%,提升了4.54%;召回率達到了61.07%,提升了0.9%;AP值達到了70.52,提高了4.8%。
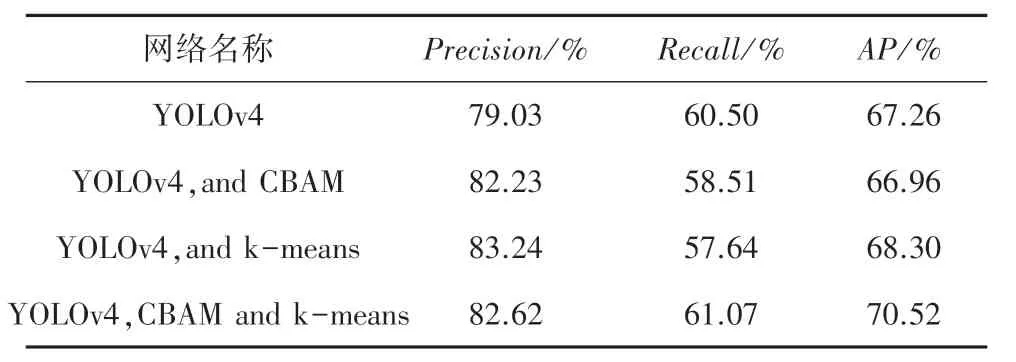
表1 消融實驗Tab.1 Ablation experiments
2.4 多種檢測方法對比
為檢驗方法的有效性,本文選取了YOLOv3、Faster R-CNN、GhostNet-YOLOv4、YOLOv5s_6.1 進行對比實驗。首先使用上述網絡分別在數據集中訓練,然后使用測試集對上述訓練過的網絡進行測試,測試結果見表2。更直觀的實驗結果如圖2 所示。具體來說,圖2(a)為車輛行駛數據原圖,圖2(b)為Faster R-CNN 算法檢測結果、圖2(c)為GhostNet-YOLOv4 算法檢測結果,圖2(d)為YOLOv5s_v6.1算法檢測結果,圖2(e)為YOLOv3 算法的檢測結果,圖2(f)為YOLOv4 算法的檢測結果,圖2(f)為改進YOLOv4 算法的檢測結果。

圖2 不同目標檢測算法與改進算法實驗結果Fig. 2 Experimental results of different target detection algorithms and improved algorithms

表2 多種模型對比評價Tab.2 Comparative evaluation of multiple models %
從表2 中可以看到,YOLOv5s 和本文的模型準確率最高,分別達到了92.54%和82.62%;Faster RCNN 和本文模型召回率最高,分別達到了66.84%和61.07%;本文算法的AP高于其他算法,達到了70.52%。
圖2 中,圖2(g)的第一張圖片表明,只有本文模型檢測到了被樹木遮擋的車輛,其他模型均出現了漏檢的情況;對于圖2 的第4 張夜晚的情景,圖2(e)和圖2(g)中均檢測到了左方的車輛,而圖2(c)和圖2(d)均未能檢測出左方車輛,圖2(b)雖然檢測到了左方車輛,但是卻出現了誤檢情況。從圖2中可以看出,改進算法能夠適應不同光照條件,與文中的其他參照算法相比,不易出現漏檢和誤檢情況。由圖2(f)和圖2(g)可看到,YOLOv4 算法對被環境遮擋的車輛無法進行準確識別,而改進算法在車輛被嚴重遮擋的情況下,依然能夠準確識別出車輛。
3 結束語
復雜外部環境下的車輛檢測算法對于自動駕駛車輛的安全和實時控制至關重要。雖然已經取得了一些研究成果,然而這些研究對于車輛拍攝角度下的車輛遮擋、環境遮擋問題還未能提供有效解決方案。針對這種情況,本文對自動駕駛汽車行駛過程中的車輛圖像檢測問題展開研究,選用了對于主流目標檢測算法具有很大的挑戰性的數據集BBD100k,數據集是由車輛在實際路面中采集而來,其中包含了晴天、夜晚等各種行駛場景下的圖像。從該數據集中選取10 000 張圖片作為實驗的數據集,并對原數據集中的類別進行合并和調整,刪去了和車輛無關的類別。本文選擇YOLOv4 網絡作為基線網絡進行改進,在網絡的7 個位置添加了CBAM注意力機制,添加通道注意力機制使網絡忽略不重要的通道,添加空間注意力機制使得網絡忽略遮擋部分的特征,提升網絡對被遮擋車輛識別準確率。利用k-means 聚類算法生成適合該數據集的錨框,提升對不同尺寸大小車輛的檢測能力,并通過實驗進行驗證。實驗證明,改進的YOLOv4 網絡在該數據集上的AP值達到了70.64%,比基線網絡提高了5%,證明改進的YOLOv4 算法在自動駕駛中對車輛檢測具有更高的精度,該方法適用于復雜條件下的自動駕駛場景。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
