CCU數據的多模態融合在動態死亡風險預測中的應用
2022-02-08 13:40:48李然,邱皖,婁巖
天津工業大學學報 2022年6期
李 然,邱 皖,婁 巖
(1.大連海洋大學 信息工程學院,遼寧 大連 116023;2.中國醫科大學 智能醫學學院,沈陽 110122)
冠心病監護室(CCU)是重癥監護室(ICU)的一部分,主要關注心臟病患者,病情通常嚴重威脅到患者的生命。CCU先進的設備和持續的監護保證了病人的病情可以得到有效監測,這些監測數據對醫生制定合適的干預措施至關重要。同時,在CCU可以得到患者的生命體征、檢查結果和處方等各種數據,為使用CCU數據決策提供了較好的支持。
死亡預測是CCU的醫務人員進行治療決策的重要的依據之一。作為重癥監護的一部分,各種危重評估系統用于CCU臨床預測,包括急性生理學和慢性健康評估(APACHE)[1]、簡化急性生理學評估(SAPS)[2]和死亡率概率模型(MPM)[3]。這些評估模型依賴患者在入住CCU后最初幾個小時內獲得的生理測量值(例如24 h),測量值與規定正常值的偏差越高,死亡風險越高。醫生制定治療方案時會考慮這些評估值。然而,這些傳統的基于統計的模型存在一些局限性,包括:①用于預測的數據取自于靜態數據;②模型更新周期長;③沒有利用多模態數據。
為了克服這些局限性,近年來,機器學習方法,如決策樹[4-5]和支持向量機(SVM)[6-8],被用來預測CCU死亡風險。由于這些數據驅動的預測模型的存在,建立基于局域ICU數據的個性化評估系統成為可能。而基準的機器學習方法很難充分利用ICU數據的時間性和異構性。最近,有研究人員引入深度學習技術來解決這些問題,將具有時間屬性的多模態ICU事件輸入到不同的神經網絡,如傳統神經網絡(CNN)[9-10]和遞歸神經網絡(RNN)[11-13],生成低維的特征表示。這些特征包含了患者歷史信息的核心特征,對提高死亡風險預測很有幫助。
已有的ICU相關研究中,邏輯回歸、支持向量機、樸素貝葉斯等方法適用于小規模和特定數據集,CNN、CNN-NHANES、GaborCNN、CNN-LSTM等方法需要大量數據進行訓練,且訓練出的模型可解釋性較差,CWT-CNN允許樣本有較大的的缺損、畸變,運行速度快,模型具備一定可解釋性。
目前大多數的針對ICU的死亡預測研究更加重視結構化數據,很少結合患者的CT影像和心電圖這樣的非結構化數據研究。但由于CCU主要關注心臟病患者,必須備有做心電圖的長期監護措施,所以CCU患者更需要關注心臟的檢測數據心電圖(ECG)和心臟超聲報告(ECHO)數據,這在CCU患者的死亡率預測中起著至關重要的作用。
本研究提出了一種動態預測CCU患者死亡風險的多模態融合方法,主要分析現有的CCU中危重風險評估系統的局限性,指出了在死亡預測中探索多模態數據機器學習方法的必要性。同時,從2個維度對CCU多模態數據進行了系統分類。在此基礎上,對不同類型的數據采用不同的融合方法,加入了時間維度進行預測。
1 CCU多模態數據的分類
現有的臨床多模態融合研究主要集中在醫學影像上,如核磁共振(MRI)、計算機斷層掃描(CT)和X射線。然而,CCU數據的形式遠不止這些。因此,本研究從2個維度進行系統分類,以展示數據的多樣性,如圖1所示。
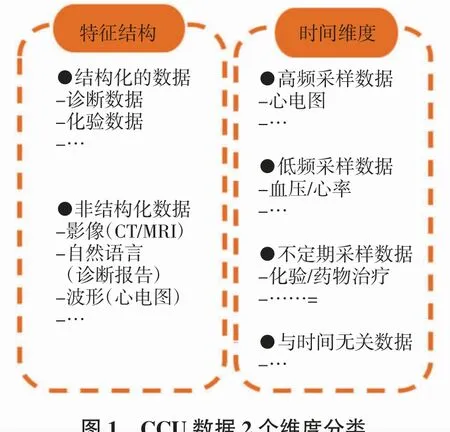
圖1 CCU數據2個維度分類Fig.1 Classification for CCU data from two orthogonal dimensions
圖1中,第1個維度將數據分為結構化數據和非結構化數據。基準的機器學習方法大多采用結構化數據進行建模,如年齡、性別和檢查數據等,很少采用醫學影像、自然語言報告和心電圖這樣的非結構化數據。第2個維度是關于時間屬性。數據可歸納為4類:高頻采樣數據、低頻采樣數據、不定期采樣數據及時間無關數據。在不同的時間維度上整合這些數據是本研究著重解決的問題。
2 問題定義
將患者在CCU中住院期間發生的臨床事件定義為si,觀察的時間為長度Ti,臨床事件s_(i)表示為三元組eji=(k,v,t)。k和v分別是事件的類型和值。k和v對應一個時間記錄t,在這里t是相對于患者進入CCU的時間間隔。例如,(pulse,56,5 h)表示患者入院后5 h脈搏為56。對于與時間無關的事件,設置t為NULL。
動態死亡風險預測任務定義為:對于每個CCU的臨床事件si,給定一個預測時間戳T(Tmin≤T≤Ti),根據事件順序預測患者是否會在未來24 h內死亡(從T到T+24 h),Tmin是預測中收集數據的最小時間跨度。在本研究中,每小時進行一次預測。
3 文本和波形數據的處理方法
在CCU數據的各種形式中,非結構化數據很少用于死亡風險預測。主要障礙是很難將這些數據與用于預測的結構化數據相集成。本研究的關鍵技術是對不同的非結構化數據使用不同的方法來提取不同的結構化特征,這些特征可以與結構化數據融合。以MIMIC-III數據集為例,有2種典型的非結構化數據:文本形式的ECHO和波形形式的ECG。這些數據對反映CCU患者的心臟狀態很重要[14]。
3.1 文本數據
對于自然語言處理,深度學習方法已經達到了較成熟的水平。本研究采用經典的處理路線,包含3個步驟來從超聲報告ECHO中生成結構化特征[15]。
(1)詞級嵌入。假設一個單詞可以用上下文單詞來表示,為每個單詞生成嵌入。單詞嵌入是一組包含豐富語義信息的低維向量[16]。
(2)報表級嵌入。基于單詞級嵌入,構建一個CNN為每個報告生成嵌入,如圖2所示。在CNN訓練中,解決兩個問題:①是冠心病還是其他功能性心臟病;②是否住院死亡。多任務學習不僅有助于避免過擬合,而且有助于提取更豐富的特征。使用不同大小的多個卷積核來捕獲各種詞序、語法和語義信息。從池層導出的向量形成報表級嵌入。
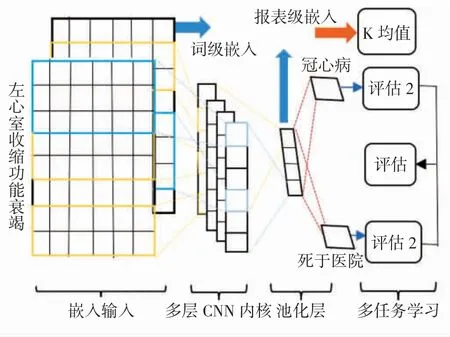
圖2 CNN和文本數據聚類Fig.2 CNN and clustering for textual data
(3)聚類。雖然報表級嵌入對于表示超聲報告ECHO是有效的,但是很難將它們與其他結構化特征融合以進行預測。本研究在這些嵌入上使用K均值將它們分到幾個集群中,使CCU的每個超聲ECHO報告都可以轉換為一個熱特征。
3.2 波形數據
心電圖作為反映心臟生理活動的高頻波形數據,在CCU患者的死亡風險預測中具有很大的潛在價值,信號處理在心電分析中起著重要的作用,結構化特征可以通過成熟的技術進行提取。本研究采用文獻[17]中提出的特征提取流程對心電數據進行處理。首先計算整個信號的頻譜圖以去除噪聲,然后從心電信號中提取形態學特征、心率變異性(HRV)特征、頻率特征、統計特征和一些噪聲檢測特征[18]。
3.3 多模態融合
大多數常用分類器沒有考慮時間因素對于預測的有效性。為了在模型中加入時間信息,本研究構造了2種與時間相關的特征集,使分類器具有時間屬性。一個特征集來自事件序列{eji}T-1h≤eji.t≤T),表示預測時間戳最近(1 h)發生的事件;另一個特征集來自事件序列,{eji}0≤eji.t≤T-1h)代表更早發生的歷史事件。時間屬性的事件中既包括定期測量的生命體征,也包括不定期采集的化驗結果,例如白細胞計數(WBC)和鉀含量。這些事件序列全部來自病人的歷史數據收集窗口,時間段為進入CCU后的前24 h。一個事件序列在數據收集窗口內會存在多個觀測值,而且不同事件序列的采樣頻率不相同[19]。為了解決事件序列采樣不均勻的問題,基于時間采樣窗口對事件序列進行重采樣,例如每小時采樣一次,這樣數據收集窗口可分成24個時間采樣窗口。在一個時間段內若仍然存在多個觀測值,則計算出現在同一個時間段內的所有觀測值的統計量,以此作為該時間段的特征表示。根據每個事件序列的特性選擇合適的統計量[20]。例如,尿量在某個時間段的表示是所有尿量的總和。將全部事件序列的特征表示向量拼接起來,即可得到時間序列數據的特征表示向量。對于臨床數據中的非事件序列,如離散型變量,則采用one-hot方法來表示。最終,將臨床數據中所有變量的表示拼接,得到病人的表示,再輸入到XGboost中,進行未來的死亡風險預測。
對具有不同時間屬性的事件使用不同的策略:
(1)對于波形事件(高頻或低頻),使用上述方法生成特征。
(2)對于不定期采樣的事件,使用最近特征集的最新值和早期特征集的平均值。
(3)對于與時間無關的事件,將它們插入到2個特征集中。
4 實驗結果與分析
4.1 數據源
MIMIC-III是一個可自由訪問的數據庫,包含5種不同類型的重癥監護室的多模態數據:CCU、心臟外科康復室(CSRU)、內科重癥監護室(MICU)、外科重癥監護室(SICU)和創傷外科重癥監護室(TSICU)。數據種類包括人口統計、生命體征、化驗數據、藥物信息等,這些數據來自4萬多名危重患者,時間跨度超過10 a。本研究從實驗數據集中提取了CCU的數據。MIMIC-III數據集和CCU子集的簡要統計數據如表1所示。
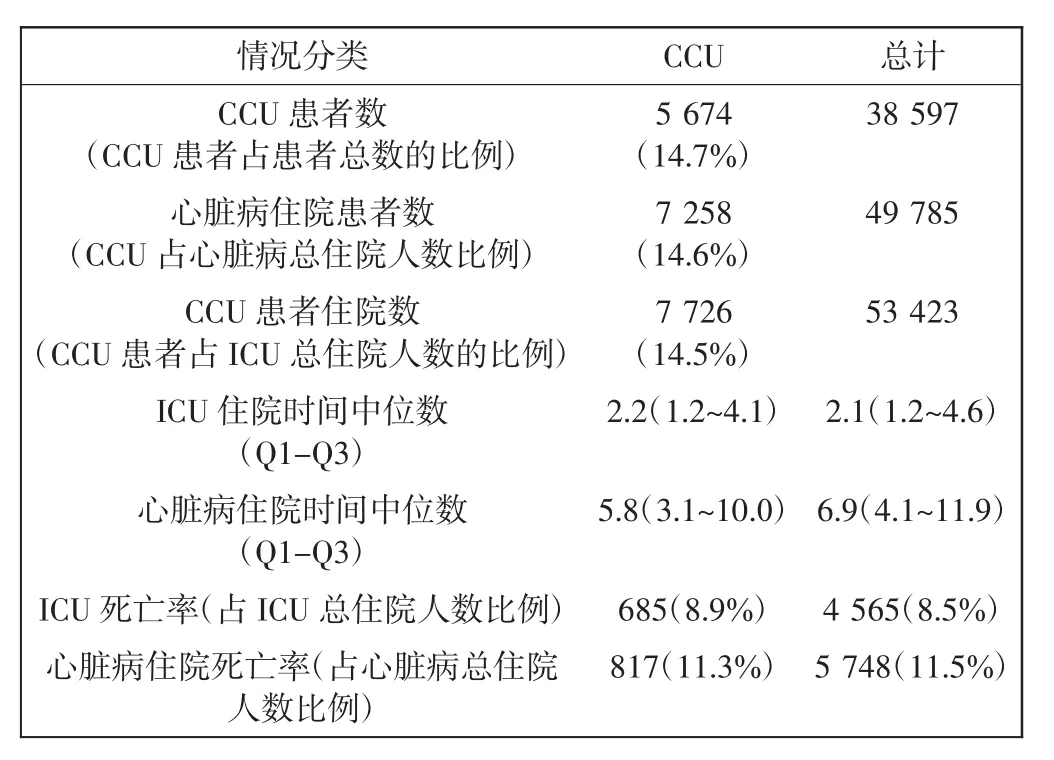
表1 MIMIC-III數據集的統計Tab.1 The statistic of MIMIC-III dataset
4.2 實驗設計
實驗的目標是基于病人在進入CCU后的前24 h的歷史數據,預測未來24 h內是否會死亡。實驗的輸入是從數據收集窗口中采集的非時間序列數據、臨床時間序列數據和ECG波形監測信號數據,標簽是病人在未來24 h內的死亡情況。在清洗后(刪除參考價值不高、缺失較多的數據)的數據中提取出患者在CCU期間死亡風險預測模型中所需的43個變量后進行數據歸一化后拼接,得到病人的特征表示,使用XGBoost將多模態數據融合,進行預測模型的學習,結合這些變量進行患者死亡風險的預測,最后輸出患者的預測類別(存活/死亡)。通過設置對照實驗,驗證本文所述方法性能的優越性。
4.2.1 患者數據集定義及樣本特征選取
本研究定義最小觀察窗Tmin=6 h,最長觀察窗Tmax=24 h。在實驗中。由于患者在整個CCU停留期間,ECG并非總是連續記錄的,因此將每個患者在CCU停留時間分割成幾個事件序列,對一次就診中的所有事件向量進行分組,以確保每個序列包含超過6 h的連續ECG數據。此步驟的主要原因是減少模型輸入數據,提高計算效率。
(1)患者數據集定義:選取第一次進入CCU以及年齡大于18歲的患者作為CCU患者數據集,對于患者第二次或者多次入院情況數據暫時不予考慮。樣本必須能從數據收集窗口中提取出3個模態的醫療數據,包括臨床時間序列數據、ECG信號數據和非時序的臨床數據。對于篩選過后的數據集中每一個CCU樣本,提取進入CCU后的前24 h內的多模態數據,包括MIMIC-III臨床數據庫中的臨床數據和MIMIC-III波形數據庫中的ECG第二導聯(Lead-II)數據。將患者首次入住CCU作為統計其是否死亡的起點,將患者死亡或者患者在數據庫記錄時間段內未死亡作為統計的終點。
(2)患者特征納入:除ECG和ECHO報告外,選用以下幾大類特征來構建模型,主要納入的特征是:①與時間無關的基礎變量,包括年齡、性別、民族;②低頻采樣變量,包括血氧飽和度、舒張壓、收縮壓等;③不規則采樣變量,包括血糖、pH值、鈉含量(全血)、動脈血氧飽和度等。
總共獲得了6 688個事件序列作為實驗的數據集,其中80%用于訓練,20%用于測試。利用10折交叉驗證法進行模型訓練與評估,得到10個驗證集的結果,并將其平均化為模型的平均結果。同時,根據這些結果進行模型選擇和參數調整。
4.2.2 參數選擇
在本研究中,采用網格搜索和隨機搜索來優化參數,通過結合5折交叉驗證來減少結果的偶然性,避免陷入局部最優。為了獲得參數的最優組合,實驗時,網格搜索不采用縮短步長的方式,而采樣窮舉策略來尋找參數,實驗次數為1輪。隨機搜索由于結果的不確定性,實驗次數為10輪。
4.2.3 實驗方法
本研究融合具有不同結構和時間維度的數據用于死亡預測。分別針對基準的機器學習方法SVM和主流機器學習方法進行預測及評估。實驗首先對比基準的機器學習方法SVM,設計了8種預測方法進行預測及評估。
(1)基準方法-無非結構化數據和時間信息的SVM:不會將數據分成與2個時間相關的特征集;同時不使用文本和波形數據進行預測。
(2)基準方法-無非結構化數據的SVM:將使用時間信息(與時間相關的特征集)進行預測。
(3)基準方法-無時間信息的SVM:使用TF-IDF[22]和統計信息(如平均值、最大值、最小值)用作超聲報告和波形數據的特征值。
(4)基準方法-SVM:使用非結構化數據和時間信息的SVM。
(5)本研究方法-無非結構化數據和時間信息:預測無非結構化數據和時間信息。
(6)本研究方法-無非結構化數據:預測沒有文本和波形數據。
(7)本研究方法-無時間信息分析:預測沒有時間信息。
(8)本研究方法-有非結構化數據和時間信息:預測使用文本和波形數據及時間信息。
其次,實驗對比主流機器學習方法,所有方法均在融合非結構化數據和時間信息情況下進行預測及評估。
4.2.4 評估指標
本研究選用的評估指標包括:準確率(Accuracy)、靈敏度(Sensitivity)、特異度(Specificity)、F1值、AUCROC及其AUC-PR值。
4.3 結果分析
定量評估結果如表2所示。
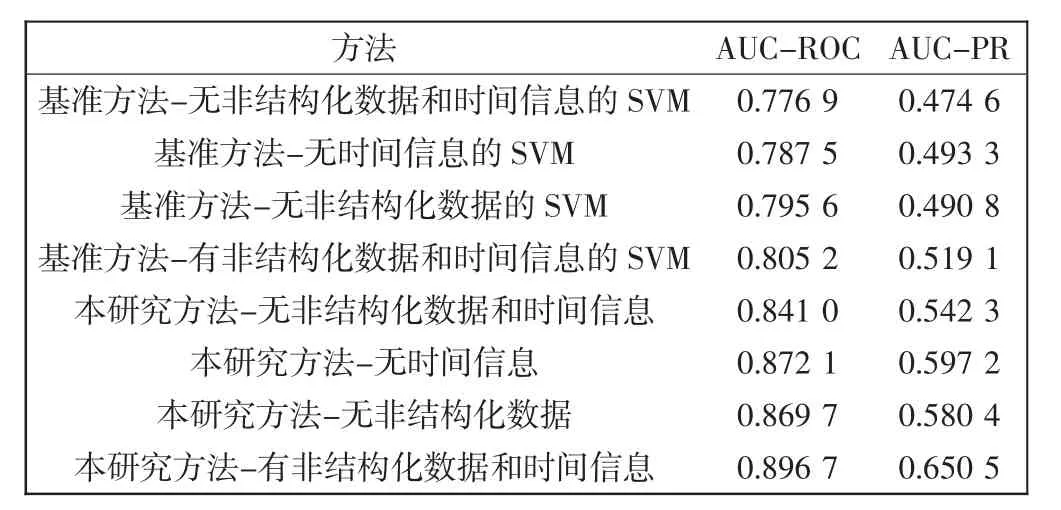
表2 預測性能評估Tab.2 Evaluation of the prediction performance
從表2中可以看到,本研究的方法在AUC-ROC和AUC-PR方面都比基準方法有顯著改進。分別從縱向和橫向2個方面進行詳細分析。
4.3.1 縱向比較
通過分析基準SVM的方法和本研究的方法,推斷出二者在預測性能上的差異。對于基準SVM的方法,非結構化數據(無時間信息的SVM)和時間信息(無非結構化數據的SVM)的引入分別比無非結構化數據和時間信息的SVM在AUC-ROC/AUC-PR上分別獲得1.36%/3.94%和2.4%/3.41%的改進。而組合使用非結構化數據和時間信息的SVM獲得3.64%/9.38%提升,對于本研究的的方法,可以得出類似的結論,如圖3所示。由此可見,通過引入多模態數據,可以獲得更好的動態死亡風險預測性能。
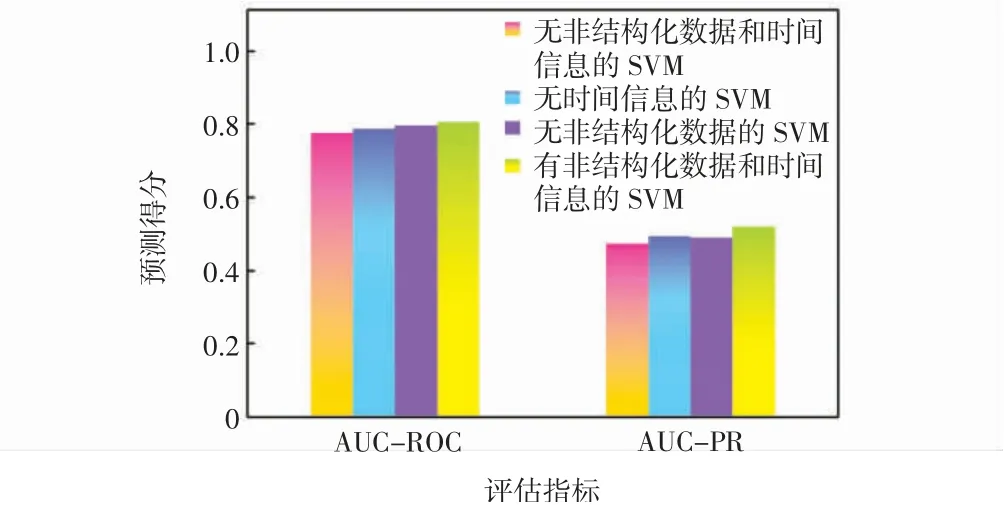
圖3 基于SVM方法的預測得分Fig.3 Prediction score based on SVMmethod
4.3.2 橫向比較
給定相同的數據類型,重點討論基準的SVM方法和本研究之間的差異。
首先,通過對不含時間信息的方法的比較,發現引入非結構化數據,本研究在AUC-ROC上比基準的SVM(0.776 9~0.787 5)有更大的改進(0.841 0~0.872 1),在AUC-ROC/AUC-PR上的改進分別為8.25%/14.26%和10.74%/21.06%。原因是本研究在方法中使用了更先進的技術從非結構化數據中提取特征,即:CNN用于文本數據處理;信號處理方法用于波形數據。
通過對含時間信息的方法的比較,分析無非結構化數據和有非結構化數據及時間信息的方法,結果標明本研究的性能較基準的SVM在AUC-ROC/AUCPR上獲得9.31%/18.25%和11.36%/25.31%的改進。原因之一可能是基準的SVM中變量獨立性的假設在很大程度上限制了多模態融合的能力,而XGBoost等機器學習方法可以更好地處理海量數據。
4.3.3 與其他主流機器學習模型對比分析
除了從縱向和橫向2個方面進行對比,為了更好的驗證本研究模型的性能,將本研究模型與4種主流機器學習算法進行對比,使用準確率、靈敏度、特異度、F1值、AUC值5個指標進行模型評估,如表3所示。將處理后數據集的80%劃分為訓練集,20%劃分為測試集,各模型均使用默認參數。
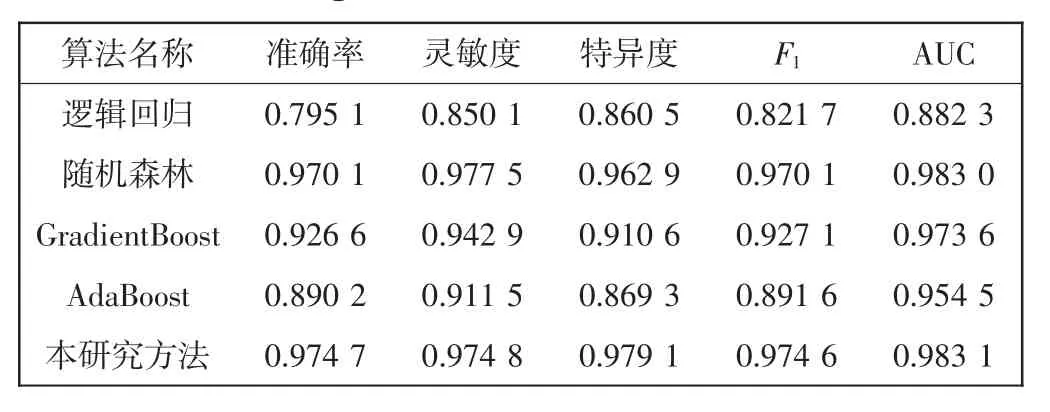
表3 主流機器學習模型的指標比較結果Tab.3 Comparison of index for mainstream machine learning models
由表3中對比的實驗結果可知:
(1)在融合非結構化數據和時間信息的情況下,對比基于線性分類的邏輯回歸模型,本研究在AUC上獲得11.42%的改進。這表明CCU臨床數據通常表現出復雜的非線性關系,所以基于非線性關系的模型可以獲得較好的分類效果。
(2)基于集成算法的模型在數據集上均表現較好,本研究采用的XGBoost算法是集成學習boosting方法的一種,實驗表明,在融合非結構化數據和時間信息的情況下,本研究較隨機森林、GradientBoost、AdaBoost在AUC上獲得平均1.31%的改進。原因是XGBoost在目標函數中加上了正則化項,使學習出來的模型更加簡單,有效地防止過擬合。
(3)XGBoost模型在訓練之前,對輸入特征數據排序,存儲為Block結構,在之后的預測過程中重復地使用這個結構,很大程度上減少了計算量,可以在預測中實現并行計算,因此具有更快的預測速度。綜合比較上述指標,在5種算法中,XGBoost算法預測結果相比其他算法更加優秀。
在本研究中,由于采用數據多模態融合策略,建模的所有特征都是結構化的。XGBoost提供了一個關于特征的權重,該權重體現了每個特征在構建預測模型中的價值。通過統計權重最高的前20個特征的特征類型,得到1個與時間無關特征(年齡)、3個與心電圖相關特征、9個低頻采樣特征(血壓/心率/呼吸頻率相關)和7個不規則采樣特征(pH/血糖/體溫相關)。這些特征中的大部分來源于最近和較近的特征集。以上結果表明,CCU數據的多模態性對提高預測模型的準確率起著重要的作用。
5 結論
本文從結構和時間2個維度對CCU數據進行了分類。為了融合文本形式和波形等非結構化數據,應用深度學習和信號處理技術提取其結構化特征。為了融合不同時間粒度的數據,采用不同的策略構造具有時間屬性的特征集。通過對MIMIC-III數據集中CCU數據的預測,結果表明:
(1)采用有效的融合策略,非結構化數據(無時間信息的SVM)和時間信息(無非結構化數據的SVM)的引入分別比無非結構化數據和時間信息的SVM在AUC-ROC/AUC-PR上獲得1.36%/3.94%和2.4%/3.41%的改進。組合使用非結構化數據和時間信息的SVM在AUC-ROC/AUC-PR上獲得3.64%/9.38%提升。
(2)使用CNN、信號處理等先進的技術從非結構化數據中提取特征的方法,通過基準的SVM方法和本研究方法的分析,對不含時間信息的方法的比較,引入非結構化數據,本研究在AUC-ROC/AUC-PR上的改進分別為8.25%/14.26%和10.74%/21.06%。對含時間信息的方法的比較,引入非結構化數據,本研究在AUC-ROC/AUC-PR上獲得9.31%/18.3%和11.36%/25.31%的改進。
(3)與主流機器學習模型對比分析,對于基于線性分類的模型,本研究在AUC上獲得11.42%的改進。對于其他基于集成算法的模型,在AUC上平均獲得1.31%的改進,本算法減少了計算量具有更快的預測速度。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學院學報(2015年4期)2015-02-28 14:30:00
中外會展(2014年4期)2014-11-27 07:46:46
計算物理(2014年2期)2014-03-11 17:01:39
河南科技(2014年23期)2014-02-27 14:19:15
外語學刊(2010年2期)2010-01-22 03:31:03
