
電網經營環境下的用戶需求反饋分析
2022-02-08 05:52:36國網青海省電力公司信息通信公司謝浩榮雷曉萍王雪群史正良
電力設備管理 2022年24期
國網青海省電力公司信息通信公司 謝浩榮 雷曉萍 秦 浩 王雪群 史正良
隨著我國電力市場化改革的不斷推進,電網經營在滿足用戶用電需求的情形下,產生了大量結構化與非結構化的數據。對生成的海量數據進行情感等級分析和基本事件統計,有助于獲取電網用戶對電網政策的意見及對電網電力服務的滿意度信息。因而,可以搜集線上監測系統和線下調查問卷、客戶訪談的非結構化數據,構造電網用戶需求反饋研究Grid-2數據集。非結構化數據主要指中文文本,中文文本具有以下特點:
一是評論人/記錄人的專業理解與習慣不同,存在著錯填或誤填的情況;二是中文文本多數來說都是高維的,需要高維空間本征表示;三是中文文本存在相同語句表達確不是相同意思的情況即一詞多義現象。
中文文本情感分析主要有兩種方法:基于傳統的機器學習和現在流行的深度學習。如Lee等人結合樸素貝葉斯極大估計和支持向量機來進行中文文本的情感推斷,但是模型訓練需要依賴大量的有標簽監督數據以及專家先驗知識,造成模型的泛化性較差;Aydin等人利用word2vec淺層神經網絡的靜態詞向量技術與雙向長短期記憶網絡 (BiLSTM)極強的雙向特征提取能力,在句子級別進行文本情感分類分析,取得了不錯的效果,但word2vec屬于靜態詞向量嵌入技術,無法表達一詞多義問題;Petets等人在2018年提出了ELMO動態詞向量方法,其利用了雙層雙向的長短期記憶模型來尋找詞向量的隱藏編碼,并能根據當前詞根的上下文來動態調整詞的特征,但其提取特征的能力還是偏弱;Radford等人采用參數超大的基于Transformer的GPT模型來進行文本特征提取,但是特征編碼過程中單方面考慮上文信息而忽略了詞根的下文信息,其特征提取的有效性還是不高;Bert模型的提出彌補了ELMO和GPT存在的問題[1-2],其是以字為級別的向量編碼,通過參考上下文環境,進行語義提取,故不存在一詞多義的問題。本文利用預訓練Bert模型,在SST-2數據集上微調和語料關鍵詞,相似詞規則匹配方法對用戶需求反饋Grid-2數據集進行情感分類挖掘和梳理統計分析,并對分類和統計結果進行可視化。
1 基于Bert詞向量文本情感分類與用戶反饋需求基本統計
基于Bert詞向量中文文本情感分類與搜索引擎用戶需求事件統計的數據預處理和詞向量表示的模型流程如圖1所示,通過調查問卷、客服訪談與系統監測的形式形成Grid-2分析數據集。經過數據預處理分別送入文本情感分類及用戶反饋需求基本統計的通道中,最后將所得結果進行可視化展示。

圖1 整體結構圖
1.1 Bert預訓練模型
Bert采用了融合語言能力更強的Transformer模型,通過其多頭自注意力機制對文本中的每個詞考慮其重要性程度,其特征表達能力更好,Bert情感分類模型如下所示,其中c1,c2,...,cn是模型的輸入,out1,out2,...,outn是模型的編碼輸出,softmax層作為情感分類類別的輸出層,本文中將文本情感分成積極、中性、負面三類[3]。
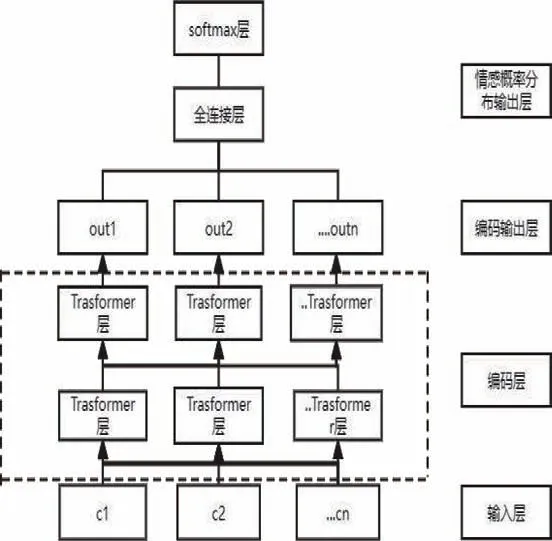
圖2 Bert情感分類模型流程圖
Bert輸入層由三個部分組成,ci由文本向量,詞向量和位置向量三個部分組成,句中每個句子的第1個向量是【CLS】標志,句中向量【SEP】標志用作不同句子的分隔符,本文是中文文本級別的情感分析,詞向量是詞的隨機靜態編碼[4-5],文本向量的取值在模型訓練過程中自動學習,用于刻畫文本的全局語義信息,位置向量P記錄分詞在句子中的位置。

圖3 Bert詞初始向量化過程
位置編碼計算公式如下:
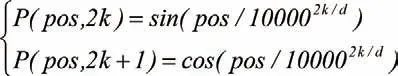
其中,pos表示位置,k表示所在維度,d表示文本向量編碼維度。
預訓練模型的Transformer結構如圖4所示。Transformer結包括1個編碼器和1個解碼器,編碼器由6個Encoder堆疊組成,解碼器由6個Decoder連續堆疊而成。
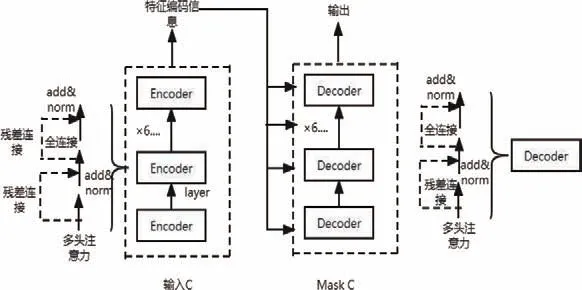
圖4 Transformer結構圖
Encoder由N=6個相同的layer組成,layer指的就是上圖左側的單元,這里是6個。每個Layer由兩個sub_layer組成,分別是多頭自注意力機制和全連接層。其中,每個sub_layer都加了殘差連接和正則化,因此可以將sub_layer的輸出表示為:
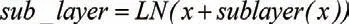
多頭注意力機制的計算過程分別如下所示:

其中,LN(.)是層正則化算子,Q,K,V分別是查詢矩陣,鍵矩陣,值矩陣,dk為平衡懲罰參數,WQi,WKi,WV>i均為線性變換矩陣,Concat(.)是矩陣連接算子,WO代表參數矩陣。
1.2 用戶反饋基本事件統計
通過采集的Grid-2數據集進行關鍵詞、相似詞匹配分析對用戶反饋相關的中文文本進行匹配,對相似詞進行分組計數統計,并生成詞頻表,共現詞表及語義網絡結構圖。
2 試驗與試驗結果
2.1 試驗環境及數據集
本文試驗的開發環境Tensorflow 1.15,開發工具為Pycharm,開發語言為Python,使用NvidiaRTX 2060運行程序。采用的是開源的預訓練Bert模型,然后在SST-2數據集上做微調訓練,SST-2數據集包含6920 條訓練樣本,872 條驗證樣本,1821 條測試樣本,包含兩種情感分類。搜集的Grid-2數據集包含了30000多條國網用戶的評論文本,每條評論文本均不超過200個字符。
2.2 試驗評價標準
為驗證本文模型在中文文本情感分析中的有效性, 使用的評價標準有準確率(Precision)、召回率(Recall)和F1,其計算公式如下所示:
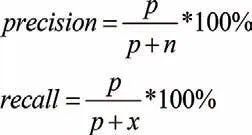
其中,p為真實標簽積極類,預測也為積極類的樣本數,n為真實標簽是消極類,預測為積極類的樣本數目,x是真實標簽為積極類,預測為消極類的樣本數。
2.3 試驗參數設置
試驗參數的設置對實驗結果具有很大的影響,經過試驗對比后,模型參數取值如下:句子最大長度為200;隨機參數更新比例dropout率為0.4;損失函數為交叉熵函數;優化器為Adamw,學習率為1E-6;訓練Epoch都設置為15,Batch_size都為16。
2.4 試驗分析及可視化
在SST-2數據集做微調生成混淆矩陣,計算精確度與召回率,與常見的情感分類算法作比較,并在Grid-2數據集上進行情感等級分類,將分類結果進行可視化。

圖5 SST-2混淆矩陣
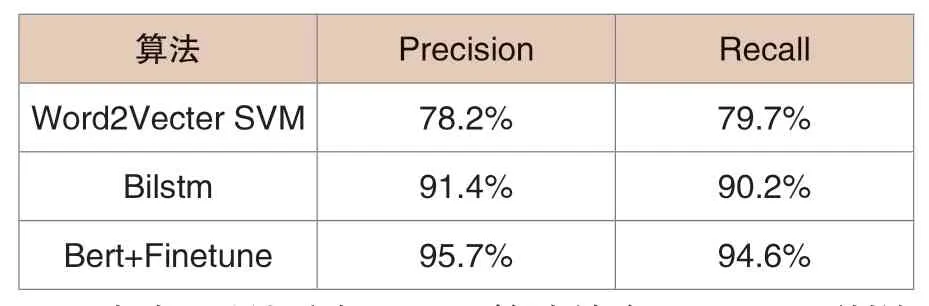
表1 算法比較
由表1可以看出,Bert算法結合Finetune訓練的分類精度和分類召回率都比基于SVM的和雙向長短期記憶模型有所提升,驗證了模型的有效性。Bert模型提升了模型對中文文本的特征提取能力,采用詞的上下文語境來自監督訓練來生成高質量的詞向量,且由于采用預訓練的方式,可以節省大量的訓練算力資源,具有即插即用的優良性能。

圖6 Grid-2國網數據集情感分類
將在SST-2數據集上微調的Bert模型運用到Grid-2數據集的情感分類任務當中,由分類結果可以知道有超過10000條的積極性評論,中性和消極評論各自約5000條。
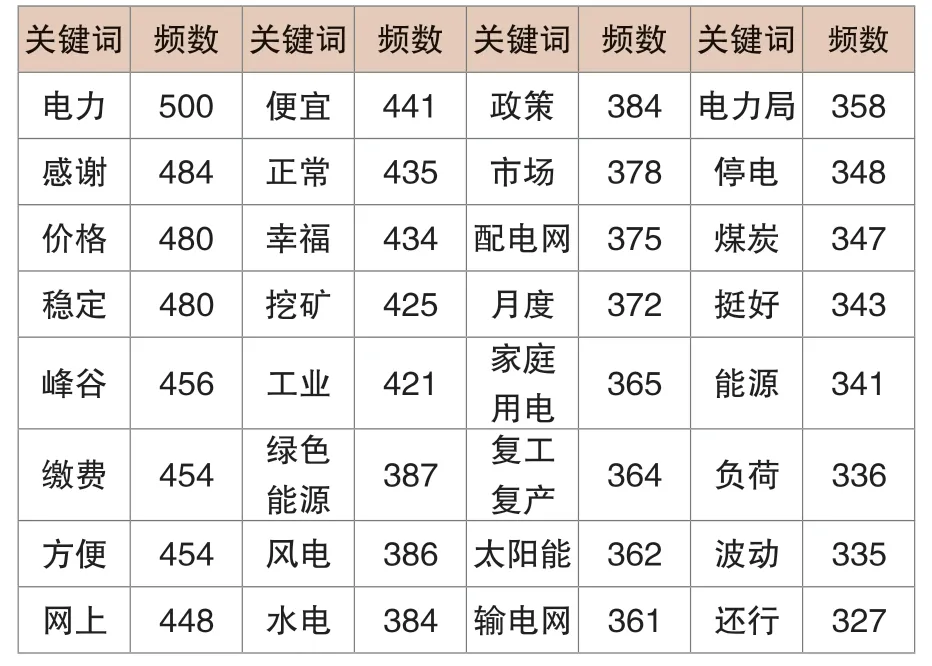
表2 詞頻分布表
由表2可以看出“電力”“感謝”“價格”“穩定”等詞頻數較高,說明電網用戶對國網電力價格政策總體上還是滿意的,由“繳費”“網上”等高頻關鍵詞來看,表明電網用戶對電網的電費支付信息化建設十分支持。

表3 熱詞共線分布表
由表3可知,國網電力用戶對電力價格,電力穩定性比較關注,在人民生活水平逐漸提高的情況下,每月的用電量也逐漸上升,家庭用電與商用/工業用電巨大的價差也引起了居民的注意,對用電的穩定性品質提出了更大的要求。
3 結語
本文提出的結合Bert預訓練與Finetune微調的文本情感分析模型實現了電網中文文本的情感分類,利用Bert預訓練模型得到融合文本上下文的詞向量深度表征,使預訓練模型能更好地刻畫文本語義。在SST-2與Grid-2數據集上的實驗結果表明,本文提出的模型具有較好的效果。并利用統計分析手段對獲取的電力文本進行了關鍵詞頻統計和共現矩陣分析,初步探討了在大數據場景下的民眾對于國網電力政策的認同感和影響力,為將來國網政策的制定和市場化改革提供一定的參考信息。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
