基于水化學場與水動力場示蹤模擬耦合的礦井涌(突)水水源判識
2022-02-12 06:21:16曾一凡梅傲霜華照來
煤炭學報 2022年12期
關鍵詞:模型
曾一凡,梅傲霜,武 強,華照來,趙 頔,杜 鑫,王 路,呂 揚,潘 旭
(1.中國礦業大學(北京) 國家煤礦水害防治工程技術研究中心,北京 100083;2.陜西陜煤曹家灘礦業有限公司,陜西 榆林 719000;3. 北礦大(南京)新能源環保技術研究院,江蘇 南京 210005)
煤炭是我國重要的基礎能源,受制于我國缺油、少氣、相對富煤的能源稟賦影響,在今后相當長的一段時間內,以煤炭為主體的能源格局將在我國長期存在[1-2]。隨著煤炭資源開采強度、深度、規模和資源量的日益增大,與煤礦開采有關的水害問題愈發突出,由此引發的水害事故也愈發嚴重[3]。在深入系統地查明礦區水文地質條件的基礎上,利用多種方法對礦井涌(突)水進行準確判識是確保煤礦防治水工作有效開展、降低煤礦水害事故損失的前提和基礎,對保障煤礦安全生產具有重要意義。
目前,基于不同含水層(水體)水化學特征上的差異性,運用模糊數學[4]、Fisher判別分析[2,5-6]、Piper三線圖[7]、距離判別分析[8-9]等多種方法對涌(突)水及其可能來源含水層(水體)的水化學數據進行處理對比分析,是較為常用的方法。隨著計算機技術的發展,近年來機器學習,特別是支持向量機(support vector machine,SVM)被廣泛應用于礦井涌(突)水的水源判別中[10-12]。另一方面,隨機森林(random forest,RF)由于其良好的穩定性和魯棒性,近年來也被逐漸應用采空區自燃預測、礦井涌(突)水水源判別等方面[13-14]。上述方法本質都是利用數學方法對涌(突)水及其可能來源含水層(水體)的水化學數據進行處理,忽略了涌(突)水可能來源含水層(水體)間的循環演化過程,使判識結果缺少實際水循環情況的支撐與驗證;另一方面,上述方法僅對來源進行判識,缺少對實際采礦過程中涌(突)水現象與礦井立體水文地質模型等結合。因此,筆者提出一種基于水化學場機器學習分析與水動力場反向示蹤模擬耦合的礦井涌(突)水水源綜合判識技術,結合陜西榆林曹家灘煤礦工程背景,在已有數據資料的支撐下,利用水文地球化學的原理和方法對礦井涌(突)水及其可能來源含水層(水體)的水化學特征進行分析,一方面利用特征上的相似性,定性對涌(突)水來源進行判識,另一方面水化學特征方面的分析賦予了機器學習定量判識結果的實際意義;此外,結合實際情況,建立地下水滲流場,利用GMS軟件中MODPATH反向示蹤涌(突)水水源,實現了涌(突)水路徑的可視化及對水化學機器學習判識結果的驗證,為礦井涌(突)水來源判識提供了一種新的思路。
1 研究區概況
陜西省榆林市曹家灘煤礦,地處陜北黃土高原北部,鄂爾多斯高原東北部,毛烏素沙漠東南緣,為沙丘沙地和風沙灘地、黃土梁峁地貌。曹家灘煤礦位于我國西北內陸,為典型的溫帶干旱、半干旱大陸性季風氣候,多年平均降水量535.51 mm,多年平均蒸發量1 916.1 mm,蒸發量遠大于降水量[15]。曹家灘煤礦內NW—SE向的分水嶺大致將礦區潛水劃分為東西2個面積大致相等且相對獨立的水文地質單元,西南部屬榆溪河流域,東北部屬禿尾河流域。煤礦東南有屬禿尾河支流的野雞河、高羔兔溝兩小溝流,為季節性溝流,在溝流的下游因老鄉農灌截流常出現斷流,區內原有一些海子多數已經干枯,現存的一些海子水位不深,蓄水量不大。

按照含水介質的不同,曹家灘井田含水層自2-2煤層向上可分為侏羅系中統延安組第5段孔隙裂隙承壓含水層、侏羅系中統直羅組孔隙裂隙承壓含水層、侏羅系中統安定組孔隙裂隙承壓含水層、風化巖基巖裂隙承壓水含水層、第四系中更新統離石黃土弱含水層和第四系上更新統薩拉烏蘇組孔隙潛水含水層。隔水層主要是新近系保德組紅土,其次為基巖中的泥巖和粉砂巖。其中,保德組紅土為研究區隔水性能較好且較穩定的隔水層,其沿分水嶺兩側最厚,自東向西、西南逐漸變薄。位于井田東翼的122108工作面和西翼的122109工作面所開采的2-2煤煤厚均為10 m左右,同為綜采放頂煤開采工藝且已完成回采,2個工作面面積相近,分別為1.67,1.56 km2。但根據涌水量數據統計顯示,井田東翼122108工作面平均涌水量約為341.21 m3/h,而西翼122109工作面平均涌水量約為758.33 m3/h,涌水量差異較大。筆者嘗試通過基于水化學場機器學習分析與水動力場反向示蹤模擬耦合的礦井涌(突)水水源綜合判識技術,對兩工作面的涌水來源進行判識。其中,122109工作面走向方向剖面示意如圖1所示。
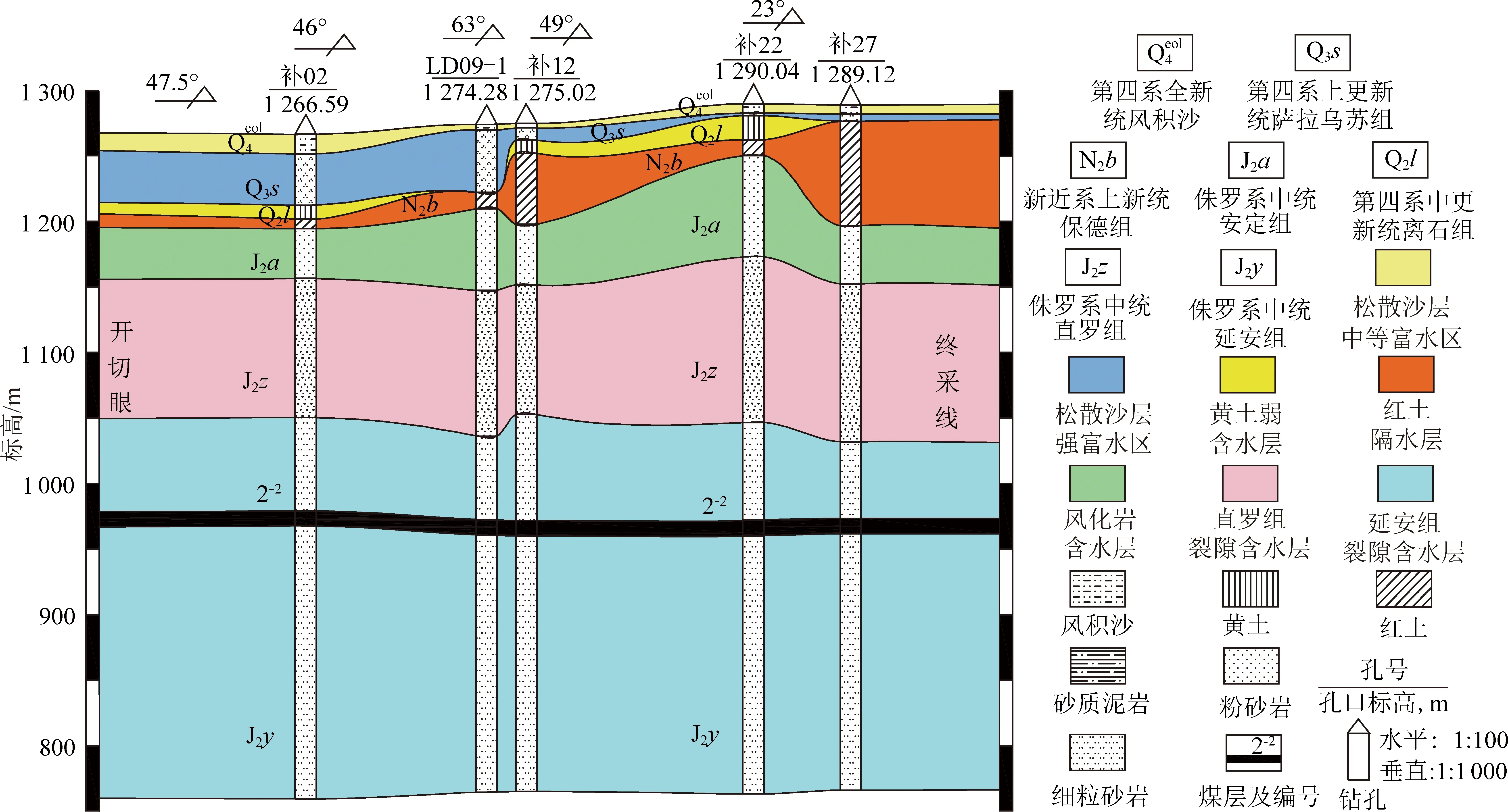
圖1 122109工作面走向水文地質剖面示意Fig.1 Hydrogeologic profile of No.122109 working face advancing direction

2 研究區地下水化學特征成因分析
地下水中各離子的質量濃度是不同含水層信息表征的載體,具有化學指紋識別的功能[2]。不同含水層地下水與含水介質發生著不同的水文地球化學作用,使其具有不同的水化學特征,這些差異是水化學特征可作為水源判別依據的根本原因。涌(突)水水源判別中,掌握當地水化學特征的成因,了解不同含水層之間的演化關系,是保證判別結果準確的基礎。
2.1 水化學參數統計特征
運用SPSS軟件對研究區地表水和各含水層地下水水樣的水化學成分進行統計分析,結果見表1。
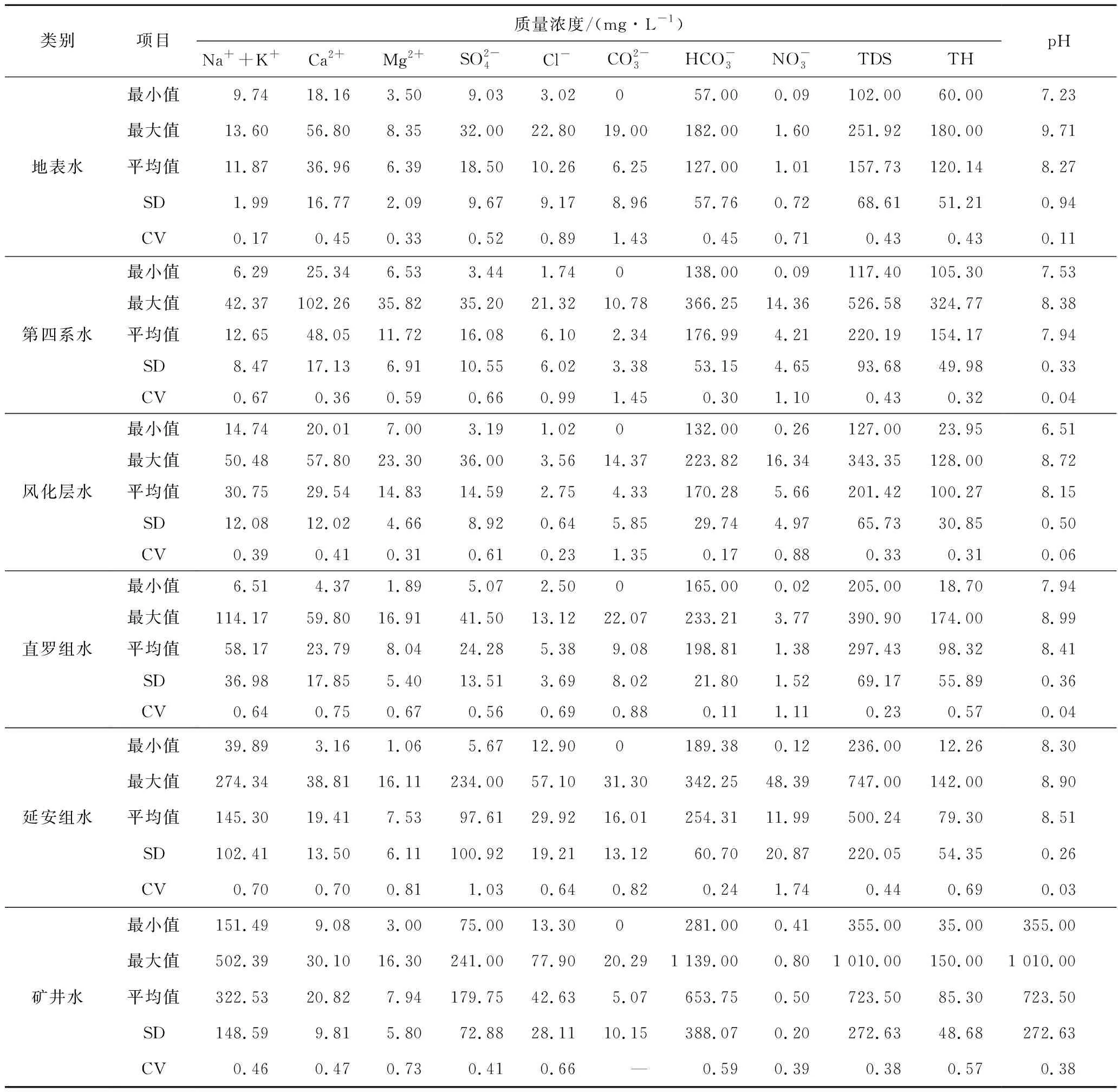
表1 水化學參數統計特征值Table 1 Statistical summary of hydrochemical parameters

2.2 水化學參數相關性分析

表2 研究區地下水水化學參數相關性系數矩陣Table 2 Pearson’s correlation coefficients of groundwater chemical parameters in study area
2.3 水化學類型及其空間分布
研究區各含水層地下水的Piper三線圖(圖2)顯示,從空間上來看,研究區內地表水和各含水層地下水中陽離子主要成分變化較大,地表水和第四系地下水以Ca2+為主導,風化層水無主導陽離子,直羅組水分布覆蓋Ca2+主導、無主導和Na++K+主導3種情況,延安組水分布覆蓋無主導和Na++K+主導2種情況,礦井水以Na++K+為主導,隨著水樣深度的增加,陽離子含量呈現由Ca2+為主導過渡到Na++K+為主導的趨勢。
從圖2中讀取了它們的水化學類型見表3(M801,M802和M901,M902分別為122108和122109工作面涌水)。地表水和第四系水的水化學主要類型均為HCO3-Ca型(75%和69%),代表這2類水之間水力聯系較強。風化層水的水化學類型比較復雜,沒有占明顯主導作用的水化學類型,部分陽離子以Ca2+(Mg2+)為主導,部分陽離子以Na+(K+)為主導,也可能是由于部分地區存在紅土薄弱區,使風化層水與第四系水存在水力聯系。直羅組水的水化學類型以HCO3-Na(50%)為主,可能和陽離子交替吸附作用及硅酸鹽礦物的溶解有關。

表3 研究區水樣水化學類型統計Table 3 Statistical table of hydrochemistry types in study area
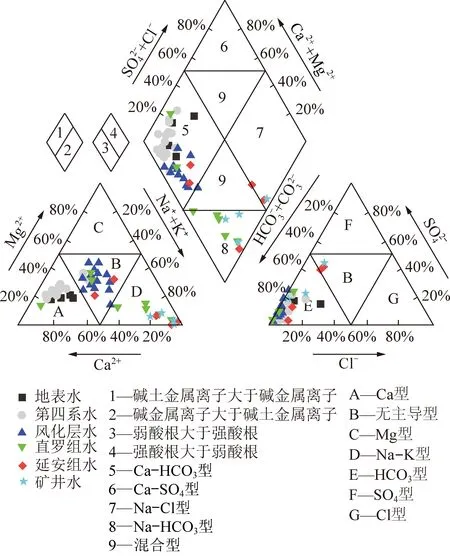
圖2 研究區地表水和地下水Piper三線圖Fig.2 Piper diagram of surface water and groundwater in study area
延安組的水化學類型主要為HCO3·SO4-Na(40%)和HCO3-Na·Mg·Ca(20%),可能和含水層中石膏的溶解以及Ca2+,Na+發生陽離子交替吸附作用有關。礦井水中122108,122109工作面水化學類型主要為HCO3-Na,礦井水的水化學類型與直羅組和延安組地下水的水化學類型相近,與地表水和第四系水的水化學類型不同,與部分風化層水的水化學類型相似。初步判斷,礦井水來源于直羅組和延安組裂隙含水層的補給,可能有少量風化層水的來源。
3 機器學習判別模型
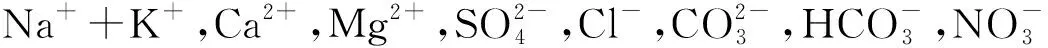
SVM基于統計學習理論基礎和結構風險最小化原理實現模式分類和非線性回歸[18]。對于模式分類問題,其主要思想是建立一個超平面作為分類的決策曲面,使類域邊界之間的隔離距離最大,進而將不同類別數據分開。SVM的結構如圖3所示,其中K為核函數,種類主要有線性核函數、多項式核函數、徑向基核函數和sigmoid核函數等。本文中SVM核函數選取最為常見且已被證實具有最優水源判別能力的徑向基核函數[11],其形式為
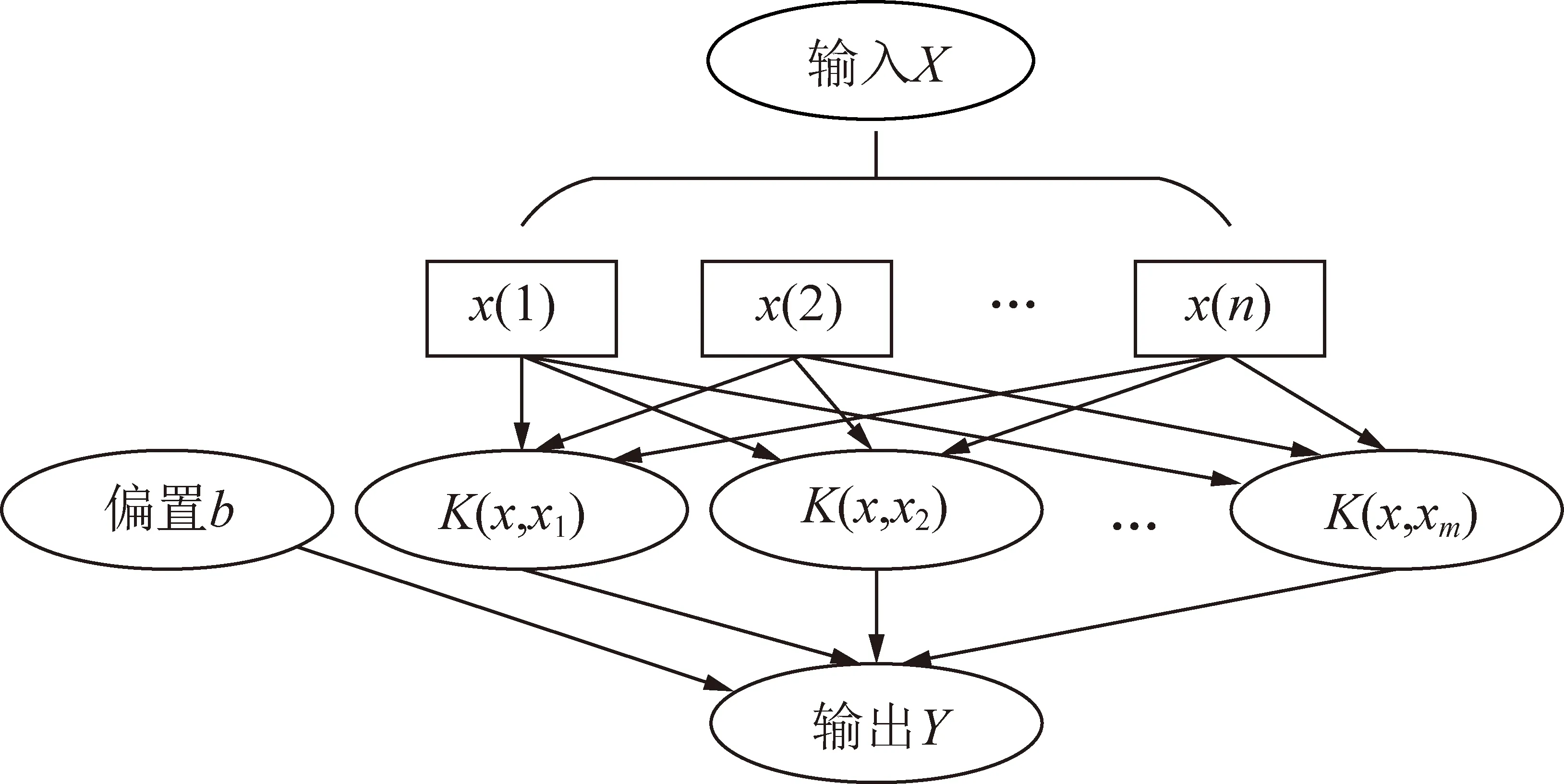
圖3 SVM結構示意Fig. 3 SVM structure diagram
(1)
式中,σ為核寬度。
RF是一種包含若干個決策樹的模型,這些隨機樹的形成采用的是隨機的方法。其基本原理是輸入測試數據后,首先讓每一個決策樹進行單獨分類,最后選取分類結果最多的那個類別作為最終輸出結果。RF結構如圖4所示,具體流程:
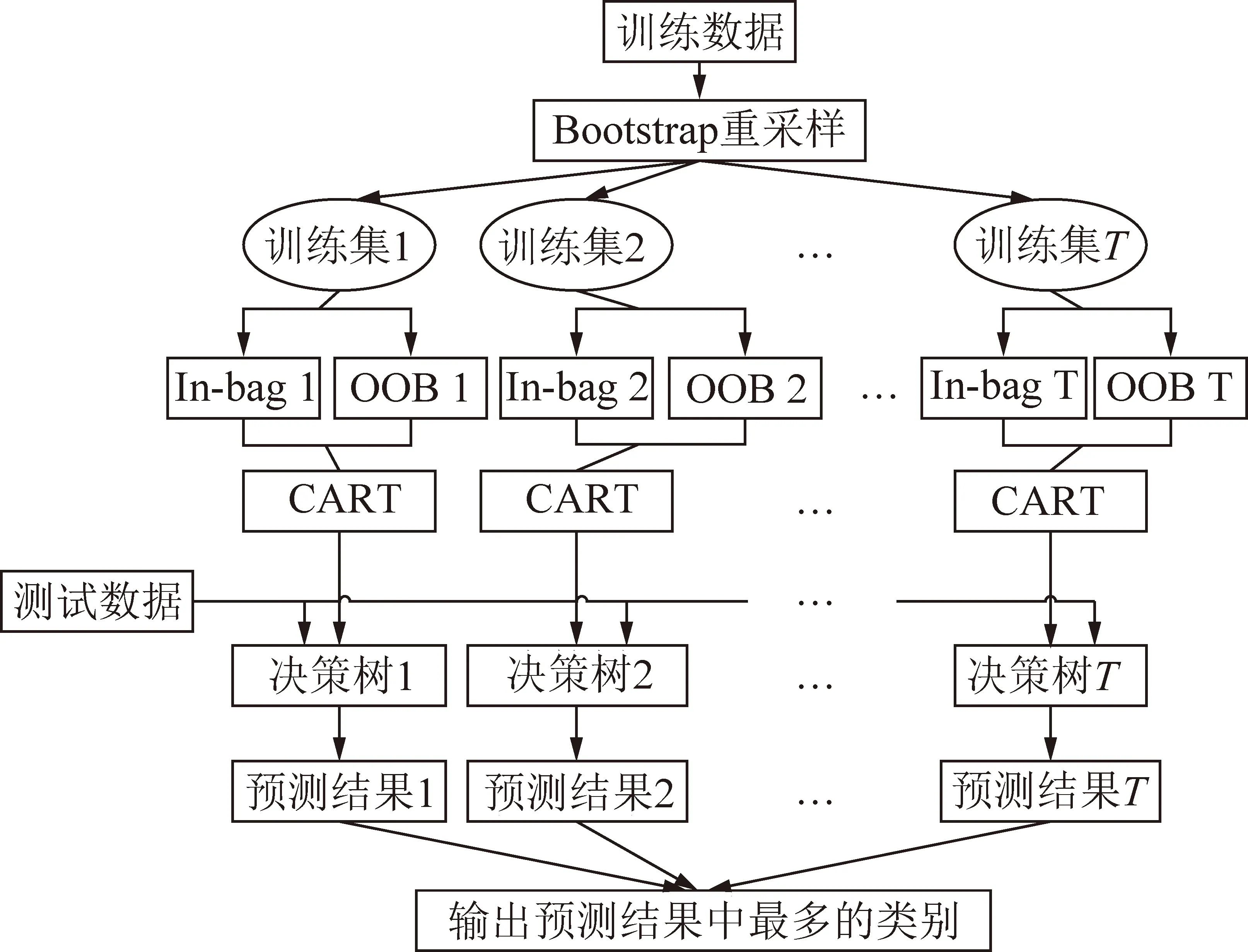
圖4 RF模型計算流程Fig. 4 RF model calculation process
(1)重采樣。利用bootstrap方法對訓練數據進行重采樣,隨機產生T個訓練集,每次沒有被抽到的訓練數據組成T個袋外數據(out-of-bag,OOB),抽到的訓練數據為袋內數據(In bag);
(2)生成決策樹。從每個訓練集樣本中的M個屬性中隨機挑選m個屬性,作為節點分裂屬性集,然后從屬性集中選出最優屬性進行節點分裂,構建出每個訓練集對應的CART樹,且每棵樹都保持完整成長,不進行任何裁枝,即m保持不變;
(3)決策。由于每個CART樹在訓練集選擇和屬性選擇上都是隨機的,因此,這T個決策樹是獨立的,將測試集輸入每個決策樹,得到T個預測結果,對于分類問題,利用少數服從多數的原則,選擇輸出結果最多的類別為測試集所屬的類別。
3.1 數據預處理
數據是否采用歸一化處理,以及不同的歸一化方式對模型的準確性有著不同的影響[19]。交叉驗證(Cross Validation,CV)是一種測試分類器性能的統計分析方法,其基本原理是將原始數據在某種意義下分組,一部分作為訓練集,一部分作為驗證集,然后用訓練集訓練出分類模型并用驗證集檢驗模型的準確率。其中K折交叉驗證(K-fold Cross Validation)的方法可以有效避免欠學習或過學習狀態的發生,能得到具有說服力的結果。筆者利用K折交叉驗證對不同數據預處理方式得到的模型驗證集準確率進行計算,進而對不同歸一化方式進行選取。結果(表4)表明,RF和SVM采用[-1,1]歸一化方式對本文的數據進行預處理,可以有效提高模型的精度。
表4 采用不同歸一化方式準確率對比Table 4 Accuracy comparison of different normalization methods
3.2 模型參數的選取優化
在使用SVM做分類預測時,需要調整懲罰系數c和核函數參數g,以得到比較理想的分類準確率。與傳統的網格搜索(Grid search)算法尋優相比,啟發式的遺傳算法(Genetic Algorithm,GA)尋優不必遍歷網格內的所有參數點,具有較強的魯棒性,且已被證實可以在復雜的參數空間中快速選取到最佳c,g值[10,12]。因此,筆者利用GA算法對SVM的參數進行優化,建立參數優化的GA-SVM模型。利用LIBSVM工具箱[20]、Sheffield遺傳算法工具箱和gaSVMcgForClass函數[21]實現懲罰系數c和核函數參數g的尋優,計算得到最優懲罰系數c=1.996 8,最優核函數參數g=4.093 6。
由RF模型的計算流程可知,每棵決策樹在生成時,沒有被抽到的樣本數據被保留在了OOB子集中,利用OOB子集數據中的樣本可以計算得到每棵樹的OOB錯誤率,則模型中所有決策樹的OOB錯誤率均值可以對RF模型的性能進行評價。此外,在決策樹生長過程中,節點預選變量m過多可能導致模型過擬合,預測精度下降[13]。筆者利用MATLAB對不同決策樹棵樹T和節點預選變量m對應的OOB錯誤率進行計算,結果如圖5所示。由圖5可以看出,隨著決策樹棵數的增加,運算量增大,但是OOB錯誤率的降低并不明顯,因此,本文所使用的RF模型中選取決策樹棵數T=150,節點預選變量m=1。
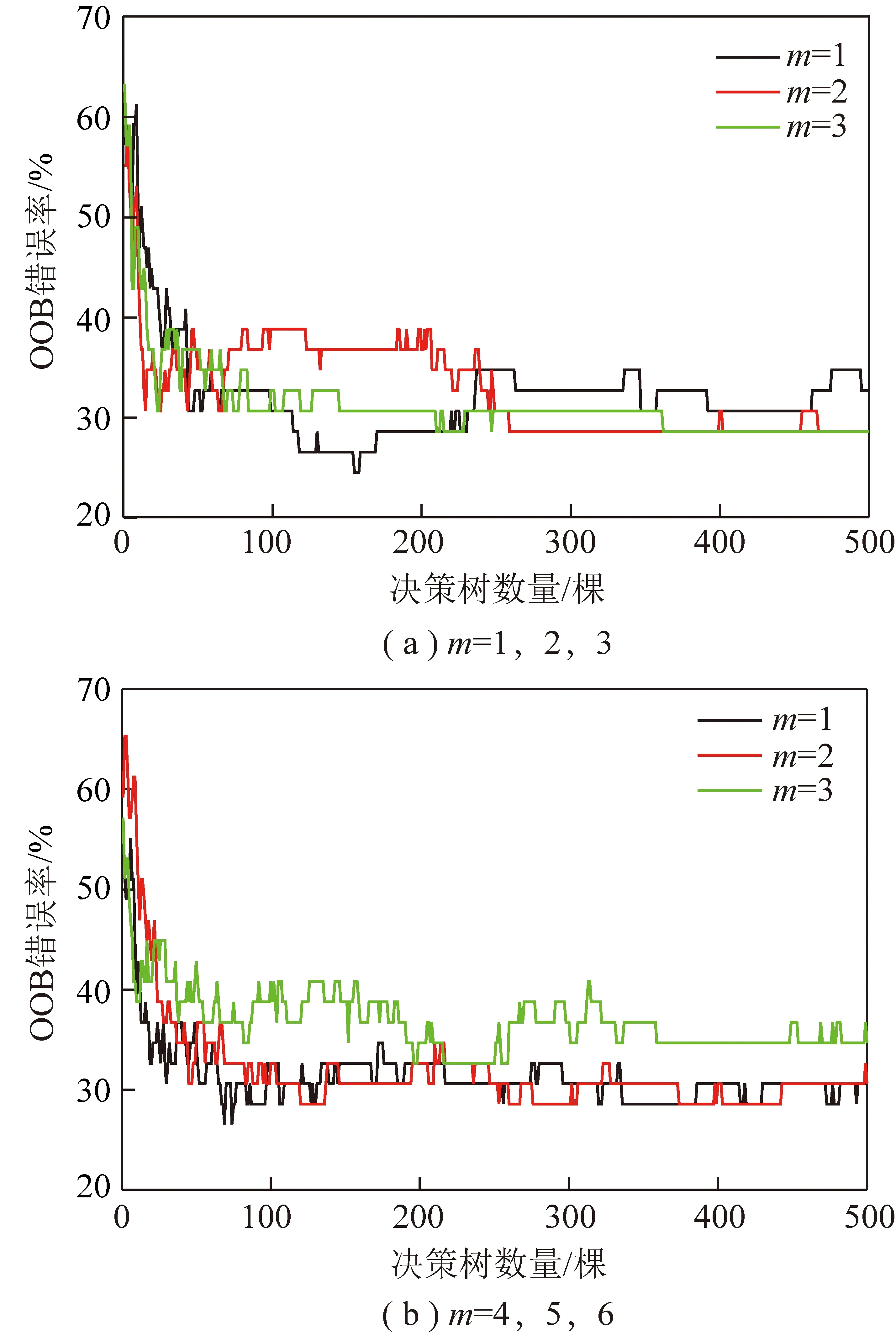
圖5 隨機森林OOB錯誤率Fig.5 OOB error rate of random forest
3.3 模型選取與水源判別
將原始數據輸入模型進行10次十折交叉驗證,得到GA-SVM模型和RF模型的訓練集與驗證集準確率如圖6和表5所示。
從圖6可以看出,GA-SVM和RF的訓練集和驗證集準確率均處于高位,說明2種模型的預測分類結果均具有一定的可信度。GA-SVM的訓練集正確率在接近100%處小范圍波動,驗證集的正確率在接近100%處波動較大,產生了較大的預測誤差,RF訓練集正確率均為100%,驗證集正確率在接近100%處小范圍波動,說明與GA-SVM相比,RF可以更好地降低噪聲對預測分類結果的影響,具有更好的魯棒性,也說明了RF具有優于GA-SVM的穩定性。從表5可以看出,RF的訓練集準確率和驗證集準確率分別為100%和98.00%,分別高出GA-SVM訓練集和驗證集準確率1.37%和7.83%。此外,SVM在進行模型訓練時,參數c和g對模型分類準確率影響較大,需要額外利用GA算法等方法對其進行優選,增加了模型的復雜度,而RF無需復雜的參數設置和優化便能得到較為滿意的性能,且決策樹為非線性處理器,可將RF視為若干個非線性關系組合形成的更為復雜的非線性關系處理器。總之,[-1,1]歸一化后的RF模型在研究區礦井水水源判別方面與GA-SVM相比具有更優的性能。
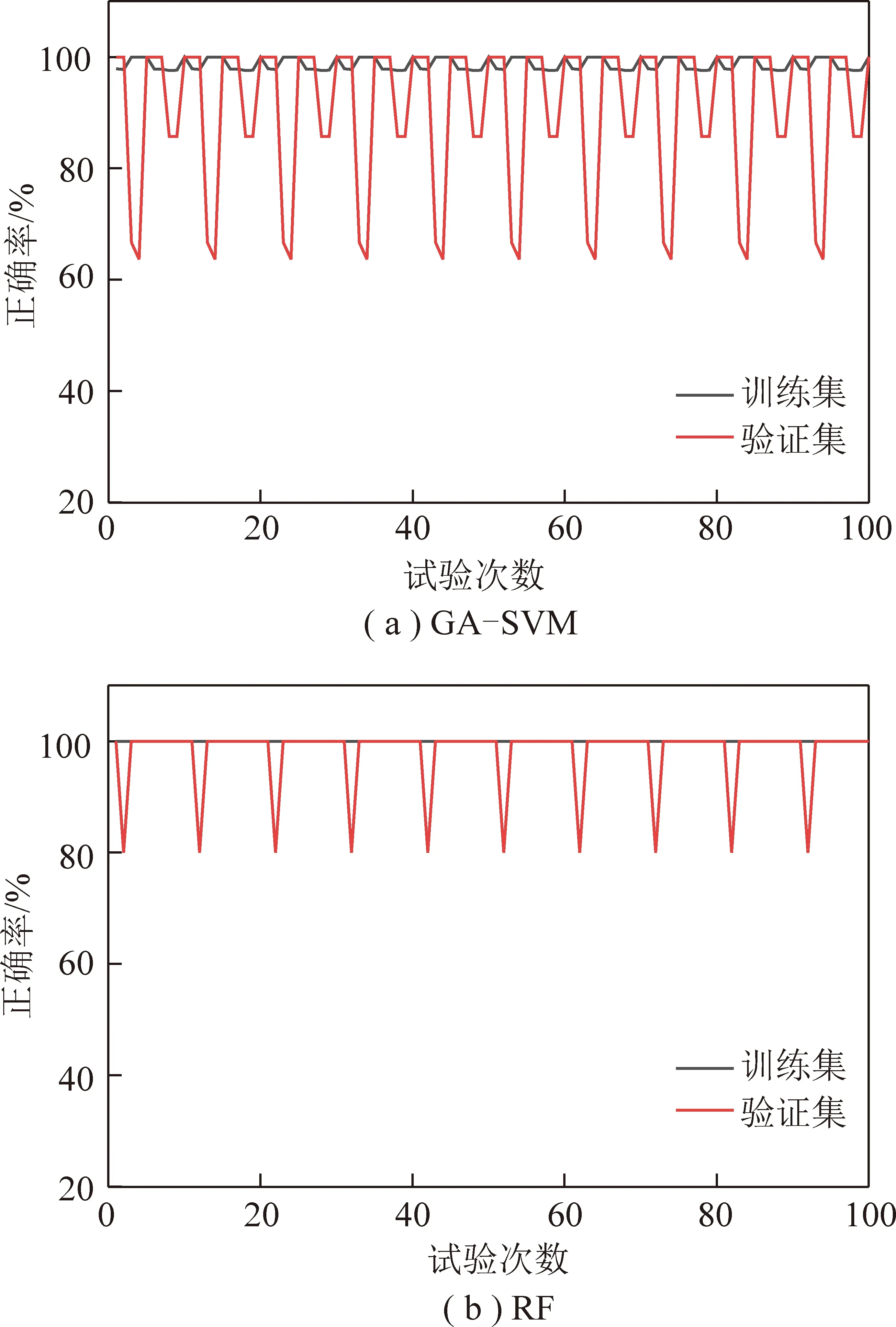
圖6 GA-SVM和RF10次十折交叉驗證結果對比Fig.6 Comparison of GA-SVM and RF 10-fold cross validation results

表5 10次十折交叉驗證正確率對比Table 5 Comparison of 10-fold cross validation accuracy
將待判別的122108和122109工作面的礦井水水化學數據進行[-1,1]歸一化后輸入訓練好的RF模型,即可快速得到預測結果。RF利用各個決策樹對數據進行預測分類,且每個決策樹給出一個預測分類結果,將每個預測分類結果與所有預測結果的比值稱為得分,得分最高的那個預測分類結果即為最終預測類別。預測結果見表6,可以看出,122108工作面礦井水主要來源于直羅組水和延安組水,122109工作面礦井水主要來源于第四系水。
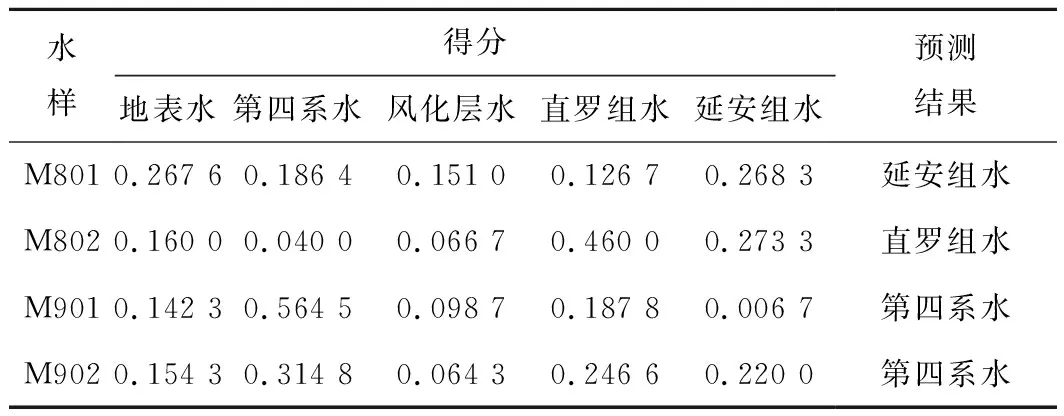
表6 RF預測結果Table 6 RF prediction results
4 剖面數值模擬
水文地球化學和機器學習的方法,分別對研究區涌(突)水水源進行判別,然而2種方法在122109工作面M901和M902水樣的判別結果上出現了差異。下面將利用滲流場模型可視化示蹤的方法,利用GMS軟件建立研究區典型二維水文地質剖面滲流場數值模型,進一步對M901和M902的涌水來源及通道進行判別與可視化輸出。
4.1 典型剖面選取
研究區分水嶺西部潛水總體向西南方向徑流,研究區紅土層下部裂隙承壓水徑流方向基本順巖層傾向由東向西南方向運移。另一方面,根據勘探鉆孔揭露,研究區紅土隔水層在西部存在薄弱區。典型剖面的選取主要目的是從地下水動力學方面分析122109工作面礦井水垂向來源于第四系地下水補給的可能性,并嘗試給出補給路徑,因此所選取的剖面應大致沿地下水徑流西南走向,且穿過研究區西部紅土薄弱區和122109工作面并靠近M901和M902取樣點位置。為了盡可能滿足研究目的,結合研究區鉆孔的分布情況,選取SW-NE方向22.1°的剖面為研究剖面(圖7)。
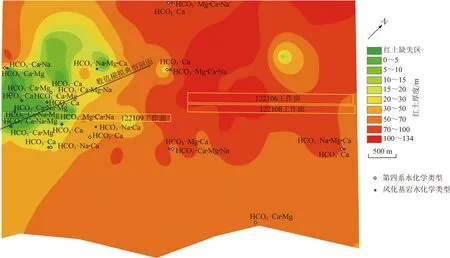
圖7 第四系與風化基巖水水化學類型與紅土厚度分布示意Fig. 7 Indications of hydrochemical types of Quaternary and weathered bedrock and thickness distribution of laterite
4.2 剖面地下水數值模型建立
由于本次剖面模擬的目的是分析礦井涌水來源和路徑,不考慮地下水隨時間改變而變化的情況,且所選剖面上含水層在水平上無明顯分帶,在垂向上不同深度的巖性有一定的分層性,因此將剖面結構概化為非均質各向異性穩定流地下水系統。垂向上概化為6層,即第四系含水層、保德組紅土隔水層、風化基巖含水層、直羅組含水層、延安組第五段含水層和煤層。模型的上部邊界,由于薩拉烏蘇組含水層水量豐富且剖面附近長觀孔監測數據顯示水位半年波動僅為0.19 m,因此,將剖面上部邊界視為定水頭邊界。模型的下部定義為隔水邊界,東部和西部為控制整個剖面內地下水的流向,設置為定水頭邊界。由于穩定流中地下水水位不隨時間發生變化,因此,初始水頭對模型流場無影響,設置為與地表高程一致。模型水平長5.8 km,垂向上標高在948.66~1 288.32 m,因此,將模型Y軸(水平方向)剖分為583列,X軸(厚度)剖分為2列(11.23 m),Z軸(垂直方向)剖分為31層,共計36 146個活動單元格。通過反復調參,使剖面滲透系數符合附近歷次抽水試驗成果并與巖性變化規律相對應,且剖面流場形態與實際流場形態相一致,最終利用GMS軟件運行后,得到煤層開采前等水位線分布如圖8(a)所示。

圖8 開采前后典型剖面水頭分布情況Fig. 8 Water head distribution of typical section before and after mining
4.3 采動后涌水來源情況模擬
煤層開采影響下,頂板巖體中,上部巖體的移動變形小于下部巖體,因而采空區上方的巖層會自下而上發育導水裂隙帶和彎曲下沉帶。其中導水裂隙帶自下而上可分為垮落帶和斷裂帶。根據巖層的斷裂、開裂及離層發育程度及導水能力,可以將斷裂帶區域自下而上進一步分為嚴重斷裂區、一般開裂區和微小開裂區(表7),其中垮落帶高度約為導水裂隙帶高度的1/4,嚴重斷裂區和一般開裂區高度約為導水裂隙帶高度的1/2,微小開裂區高度約為導水裂隙帶高度的1/4[22]。煤層上覆巖體的斷裂變形也會造成其滲透率發生變化,隨著與開采煤層垂直距離的增加,導水裂隙帶的滲透系數增加幅度逐漸減小,變化幅度由上至下均為開采前的1~10倍[22-26]。

表7 斷裂帶分區情況[22]Table 7 Fractured zone division[22]
通過在122109工作面施工的“兩帶”鉆孔的手段,以鉆進過程中沖洗液漏失量、鉆孔內水位變化、巖芯鑒定、鉆孔電視等多種方法,綜合確定122109工作面垮落帶最大發育高度為53.99 m,波及到延安組含水層;斷裂帶最大發育高度為215.01 m,波及到風化基巖含水層。因此,結合導水裂隙帶分區情況及導水裂隙帶滲透系數變化情況,將模型對應導水裂隙帶發育高度下部1/4位置、中部1/2位置和上部1/4位置滲透系數分別設置為原有10倍、5倍和2倍。此外,根據研究區附近已有紅土層采動前后壓水試驗成果,雖然導水裂隙帶未波及到紅土層,但應力的改變也導致了其滲透系數變為開采前的10倍[27],將模型對應層位滲透系數也進行調整。而紅土層上覆第四系松散沉積物主要成分為細沙和少量亞沙土、亞黏土,位于彎曲下沉帶,研究區已有成果表明在采動影響下,其滲透性變異程度不大,模型中對應滲透系數不做調整[28-29]。將調整后的參數輸入至模型中,使用GMS軟件中的Drain模塊模擬煤層開采后的情況,利用MODPATH模塊的反向示蹤功能對煤層開采后的涌水來源進行模擬,其中開采后水頭分布情況如圖8(b)所示,122109工作面礦井水來源路徑情況如圖9所示。
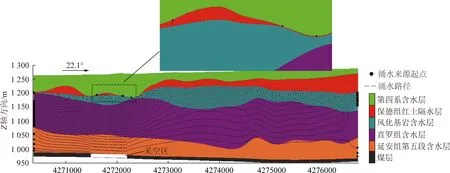
圖9 開采后涌水來源判識示意Fig.9 Source identification diagram of water inflow after mining
從模型計算結果可以看出,開采后,典型剖面流場較開采前發生了明顯變化,受煤層開采影響,采空區附近含水層水頭明顯降低。MODPATH模塊反向示蹤計算結果顯示,在紅土薄弱區存在第四系水越流并通過導水裂隙帶補給礦井水的情況。
5 討 論
根據水文地球化學特征相似性和隨機森林方法的判識結果,122108工作面礦井水的主要來源為直羅組和延安組含水層地下水。此工作面北部緊鄰的122106工作面“三帶”發育規律研究項目,通過理論分析、現場實測、物理相似模擬及數值計算等方法,綜合確定導水裂隙帶最大發育高度為162.0 m,波及到直羅組地層,與水文地球化學和隨機森林方法判識結果吻合。可以確定122108工作面礦井涌水的主要來源為直羅組和延安組含水層。
水文地球化學特征相似性判識122109工作面礦井水主要來源為深層直羅組或延安組含水層地下水,而隨機森林方法判識結果顯示其主要來源為第四系含水層地下水。通過引入典型剖面二維地下水數值模擬的方法,發現存在第四系含水層地下水通過紅土薄弱區和缺失區及導水裂隙帶涌入122109工作面的情況。研究區內保德組紅土結構致密,半堅硬狀,透水性差,分布連續,是較為穩定的隔水層。因此,當導水裂隙帶發育至安定組風化基巖含水層時,紅土層是否可以有效阻隔第四系水越流補給安定組風化基巖含水層,直接影響到122109工作面礦井水是否存在第四系含水層地下水作為來源。收集整理研究區范圍內各類鉆孔共129個,插值生成煤礦礦權范圍內紅土厚度分布圖,并將收集整理的水化學數據中,存在坐標的14個第四系含水層取樣點和14個風化基巖含水層取樣點投射至紅土厚度分布圖,最終成圖如圖7所示。
從圖7可以看出,研究區紅土分布情況為中部及東部較厚,厚度可達50~134 m;而研究區西部紅土較薄,厚度普遍在50 m以下,且存在紅土缺失區,經計算,缺失區面積為1.13 km2。由前文分析可知,研究區第四系地下水中陽離子為Ca2+,而風化層水無主導離子。結合圖水化學類型分布情況來看,在中部和東部紅土較厚區,風化層水中Ca2+質量濃度不大,其與臨近的第四系水水化學類型存在明顯差異,而在紅土薄弱區,特別是在紅土缺失區,風化層水中Ca2+質量濃度顯著增加。經進一步計算發現,研究區第四系水中Ca2+毫克當量百分比平均為61.60%,紅土厚度15~134 m處Ca2+毫克當量百分比平均為31.77%,而紅土厚度0~15 m處Ca2+毫克當量百分比平均為40.82%。對比分析判斷,在西部紅土缺失區和薄弱區,第四系含水層與風化層水之間存在水力聯系。考慮到紅土缺失區域與122109工作面存在重疊,重疊面積為0.17 km2,因此,在紅土缺失區域內,存在第四系含水層地下水通過導水裂隙帶涌入122109工作面的情況,這與隨機森林判識和典型剖面二維數值模擬判識結果相吻合。水文地球化學特征相似性判識122109工作面涌水來源為直羅組或延安組含水層地下水,可能是因為判識過程僅參照了K+,Na+,Ca2+,Mg2+等常規離子質量濃度,忽略了pH、TDS、總硬度和總堿度等理化指標,導致判識結果出現誤差。此外,在實際生產過程中,122108工作面平均涌水量約為341.21 m3/h,而122109工作面平均涌水量約為758.33 m3/h,達到122108工作面涌水量的2.22倍,結合122109工作面上部存在0.17 km2紅土缺失區,且第四系薩拉烏蘇組含水層水量大的特點,綜合判斷122109工作面涌水主要來源于第四系含水層地下水。
6 結 論
(2)通過十折交叉驗證方法,得出RF方法正確率為98.00%,優于GA-SVM的90.17%。此外,SVM需要額外利用GA算法等方法對參數c和g進行優選,增加了模型的復雜度,而RF無需復雜的參數設置和優化便能得到較為滿意的性能。因此,利用RF得出122108工作面涌水來源于直羅組和延安組含水層地下水,而122109工作面涌水來源于第四系含水層地下水。
(3)選取122109工作面取樣點附近典型剖面,利用反向示蹤原理,結合曹家灘礦水文地質條件、工程地質條件和抽水試驗滲透系數等信息,建立MODPATH礦井涌(突)水滲流場可視化模型,實現涌水路徑的可視化輸出,并對RF判識結果進行驗證。結果顯示,122109工作面在紅土薄弱區和缺失區位置,存在第四系含水層地下水通過導水裂隙帶涌入工作面的情況。
(4)基于水化學場機器學習分析與水動力場反向示蹤模擬耦合的礦井涌(突)水水源綜合判識結果,結合工程實例進行討論驗證分析,發現判識結果與工程實際情況相吻合,證明該方法具有較高的準確性和可信程度。最終判斷122108工作面涌水來源于直羅組和延安組含水層地下水,122109工作面涌水來源于第四系含水層地下水。判識結果可為曹家灘煤礦以后防治水工作的開展提供參考依據。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
