基于激光視覺融合的幀間匹配方法
2022-02-15 06:16:58何仲偉張小俊張明路
汽車實用技術 2022年1期
何仲偉,張小俊,張明路
基于激光視覺融合的幀間匹配方法
何仲偉,張小俊,張明路
(河北工業大學 機械工程學院,天津 300132)
同步定位與地圖構建(Simultaneous Location and Mapping, SLAM)是機器人在未知環境中實現自我導航能力的重要保證。目前SLAM算法使用的主傳感器基本是激光雷達或視覺相機。二者各具優劣,激光雷達能更精確地進行測距,視覺相機能反映環境豐富的紋理信息。與使用單一傳感器相比,將二者融合的SLAM算法能夠獲得更多環境信息,達到更好的定位和建圖效果。文章提出一種融合激光雷達和視覺相機的幀間匹配方法,通過在SLAM幀間匹配過程中加入地面約束以及視覺特征約束,提高幀間匹配過程精度,增強算法魯棒性,從而提升SLAM算法整體效果。文章最后利用采集的地下停車庫數據進行結果驗證,與開源算法A-LOAM進行對比。結果表明,相比A-LOAM的幀間匹配方法,文章提出的方法相對位姿誤差提升約30%。
SLAM;多傳感器融合;地面提取;迭代最近點;隨機一致性采樣;Fast特征;光流法;幀間匹配
引言
同步定位與地圖構建(Simultaneous Location and Mapping, SLAM)能夠讓處于未知環境中的機器人進行自身定位和獲取周遭信息,進而實現路徑規劃和自主導航。SLAM算法中使用的主傳感器有激光雷達和視覺相機,其中激光雷達能夠獲取精確的環境距離信息,但因其具有一定的角分辨率,所以在空曠環境中獲取的數據較為稀疏;視覺相機能夠得到豐富的紋理信息,相比激光雷達數據更加連續致密,但對環境光照變化敏感[1]。因此,融合二者的SLAM系統更能適應復雜多變的環境。
目前,已有多位學者對激光視覺融合SLAM算法進行了研究。J. Zhang等利用視覺里程計估計機器的運動,高速率低精度地對準點云,然后基于激光雷達來優化運動估計和進行高精度點云對準[2]。Y. Xu等提出了一種基于EKF的RGB-D相機與激光雷達融合的SLAM方法用于處理相機匹配失敗,即當相機匹配失敗時使用激光雷達對相機3D點云數據進行補充并生成地圖[3],該方法沒有真正地融合兩種傳感器數據,只是進行了傳感器的切換。Y. Shin等提出了一種利用了雷達提供的稀疏深度,基于單目相機直接法的SLAM框架[4],為了保證實時性,文章提出了利用滑動窗口進行追蹤,嚴格的位姿邊緣化和深度的大場景幀間匹配方法。歐陽毅利用激光數據為視覺圖像增加了深度信息,提高了圖像特征的提取效率,完成了對特征點的深度估計,且基于PnP算法完成了對機器人的運動估計,并采用光束平差法(Bundle Adjustment, BA)完成了局部優化[5]。J.Graeter等開源了SLAM方案LIMO,利用單目相機和激光雷達來模擬超廣角深度相機,將提取到的視覺特征點轉換為三維數據點,利用PnP估計相機幀間運動,但整體采用VIO的策略[6]。
上述算法雖進行了激光雷達和視覺相機數據融合,但在解算過程僅采用單一傳感器進行運動估計,而非采用緊耦合的融合方式。與這些方法不同,本文提出了一種融合激光雷達和相機的緊耦合的幀間配準方法,將點云特征和視覺特征共同加入幀間配準誤差方程進行求解。同時為了增加程序魯棒性,在進行點云預處理過程中,本文提出了一種基于隨機一致性采樣(Random Sample Consensus, RAN- SAC)的地面點云提取方法,并將地面點云作為一種約束加入幀間配準誤差方程。改進的幀間配準算法流程如圖1所示。
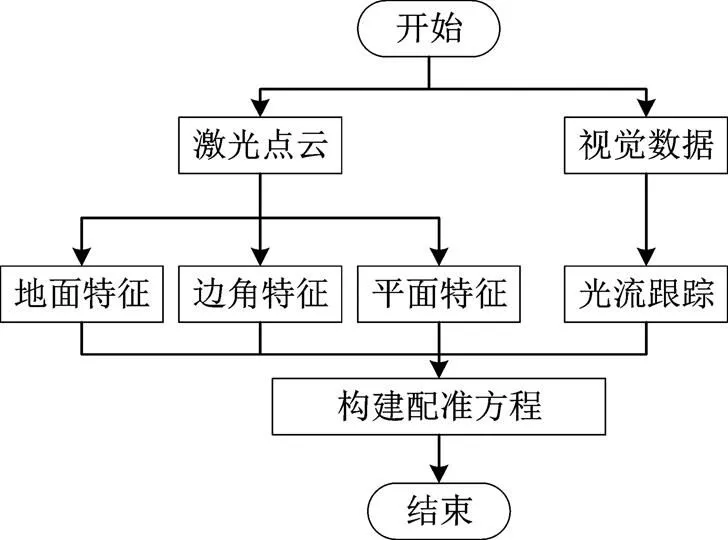
圖1 算法流程圖
1 算法框架
該流程主要包括預處理部分和運動估計部分。點云預處理部分包括利用慣性導航單元(Inertial Measurement Unit, IMU)去除激光點云畸變、提取地面點云、依曲率提取邊角點云和平面點云。視覺預處理部分包括提取Fast特征和光流跟蹤。完成上述過程后,利用預處理得到的數據進行緊耦合的運動估計。
1.1 點云預處理
1.1.1分割地面點云
地面提取算法流程如圖2所示,在實際場景中,地面并非完美平面而是具有一定的弧度,但為方便配準方程的構建,仍采用平面模型進行地面提取。場景中的墻面也會對平面模型提取過程造成干擾,因此首先依據雷達實際安裝高度利用直通濾波提取候選點云。為增加提取速度,直通濾波通常區間長度通常較小。當地面本身具有坡度或激光雷達安裝誤差問題,將導致地面與激光雷達坐標系的平面具有一定夾角,該情況使得候選點云中包含較大比重的非地面點云,影響地面提取效果。為解決上述問題,本文逐漸增加候選點云數量獲得多個平面模型,利用模型篩選單幀點云中符合該模型的內點數據。若相鄰兩次內點數據變化幅度不大,則認為提取到了正確的地面模型。
平面提取過程利用的是隨機一致性采樣(Random Sample Consensus, RANSAC)算法,該算法是從一組包含異常數據的觀測數據集中估計其數學模型參數的迭代方法[8],是一種不確定算法,通過重復選擇數據中的一組隨機子集來達成目標。
圖2為地面點云提取效果,圖中顯示的是單幀點云數據,其中彩色點云為地面點云,可以看出該方法成功提取到大部分地面點,能夠為運動估計階段提供正確的地面特征。

圖2 地面點云提取效果
1.1.2提取點云特征

特征點云分為邊角點和平面點,分別計算每個點的曲率,式(1)為曲率計算公式。()代表第幀點云中第個數據點,代表()的鄰近點集。
依據曲率閾值將所有點分為邊角點和平面點。為使數據分布均勻,將點云劃分為多個子區域,每個子區域中提取固定數量的特征邊角點和特征平面點。若某個數據點被選為特征點,其鄰域內的點則不予考慮,避免特征點過于集中,使運動估計過程陷入局部最優的狀況。
1.2 提取視覺特征
采集單幀圖片中的FAST(Features from Accele- rated Segmentst)特征,利用LK光流法在幀間進行特征像素追蹤。
LK光流[9]算法原理基于三個假設:(1)亮度恒定,即連續的前后幀圖片中相同物體的像素值大小不發生變化;(2)時間連續,即在連續前后幀的圖片中物體的運動狀態是緩慢變化的;(3)空間均勻,即圖片場景中某一像素點的運動狀態的變化和它相鄰區域像素點的運動狀態變化相同。
假設在時刻,圖像中(,)像素點亮度為(,,),經過短時間?后,其像素坐標變為(+?,+?),亮度變為(+?,+?,+?),根據亮度恒定假設,得到公式(2)。
(+?,+?,+?)=(,,) (2)
對上式進行一階泰勒展開,由于?很小,忽略高階項,得到公式(3)。
(+?,+?,+?)
(3)
將公式(2)和公式(3)聯立,等式兩邊同時除以?,得到公式(4)。
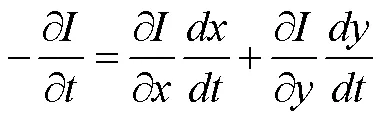
根據光度不變假設,等號左側為零。根據空間均勻假設,利用特征像素的多個鄰近像素構造超定方程,求方程的最小二乘解得到像素速率,實現特征點的追蹤。
1.3 構建誤差方程
1.3.1特征點ICP約束
傳統ICP算法需已知兩幀點云中數據點的對應關系,將前幀點云利用幀間位姿變換到后幀坐標系下,以對應兩點間的距離作為誤差項,迭代求解變換矩陣。
在實際場景中,沒有數據點之間的對應關系,同時高線數激光雷達數據量龐大,用全部數據點構建誤差方程進行幀間匹配難以達到實時性要求。因此,該部分采用經典激光SLAM算法LOAM中的特征點ICP匹配。將點云預處理階段的特征點利用幀間位姿變換到目標坐標系下,在目標坐標系中使用k-維樹[10](k-dimensional tree, kd-tree)搜索邊角特征的兩個最近邊角點和平面特征的三個最近平面點,得到特征之間的匹配關系。以兩幀特征間的距離1(T+1,k)作為誤差項,變換矩陣T+1,k作為待優化變量,進行迭代優化計算,見公式(5),其中為邊角特征到對應邊角線的距離,為平面特征到對應平面的距離。
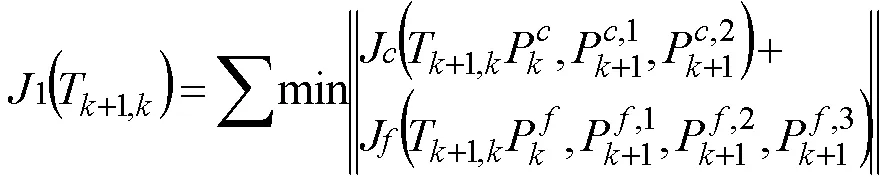
1.3.2地面約束
在較為空曠的環境中,點云數量會大幅減少。此外,由激光雷達存在水平角分辨率,導致單線距離雷達較遠數據點間有更大的間距,從而影響數據點曲率的計算,可能導致錯誤的數據點分類,降低特征點ICP匹配的精度。相比提取到的特征點,地面點云在兩幀間連續,更具穩定性。因此,將地面點云作為約束加入誤差方程,能降低錯誤匹配特征點帶來的影響,使匹配算法更加精確、魯棒,見公式(6),式中J代表點到平面距離誤差,P代表第幀中提取的地面點云,F,k+1代表從+1幀地面點云中提取的平面模型。
2(T1,k)=min‖J(P,F+1)‖ (6)
1.3.3視覺特征約束
由于激光雷達角分辨率的緣故,實際點云并不連續,隨著雷達線數降低越發稀疏。而相機圖像攜帶的場景信息更加連續致密,大部分像素無法利用外參和激光數據獲得深度。因此,本文利用對極約束和兩幀間特征像素的對應關系解算出不含尺度信息的位姿變換,將該變換中的旋轉加入誤差方程中進行約束,加快結果收斂速度。公式(7)中T1,k和T1,k分別代表視覺特征獲得的幀間旋轉和待求的角度旋轉,J(P,P)代表兩種旋轉間對應歐拉角的差值。
3(T1,k)min‖J(T1,k,T1,k)(7)
聯立以上各式,構建幀間位姿變換誤差方程,待求變量為T1,k,利用高斯牛頓法對其進行迭代求解,完成緊耦合的運動估計過程。相比于A-LOAM中單純利用特征點作為運動估計的約束,本文算法額外添加了地面約束和視覺旋轉約束,能夠對旋轉和軸向位移做出更嚴格的限制,從而在有限的迭代輪數中獲得更精確的前端配準結果。
2 實驗與結果分析
本文的實驗平臺為Inter Core i5-4210H, 2.90 GHz,4 GB內存,操作系統Ubuntu 16.04。以上述算法替換A-LOAM中的前端配準模塊得到改進算法,完成智能車位姿估計并構建地下停車庫點云地圖。利用SLAM領域開源工具EVO繪制智能車軌跡,計算智能車的絕對位姿誤差和相對位姿誤差,并與改進前的算法A-LOAM進行精度對比。
圖4為本文算法與A-LOAM的軌跡對比圖,其中深色線條為A-LOAM算法軌跡,淺色線條為改進后算法軌跡。從圖中可以看出在路徑前半部分兩種算法得到的結果相差無幾。但在后半程中,A-LOAM算法出現了明顯的漂移,而本文算法表現相對更好。
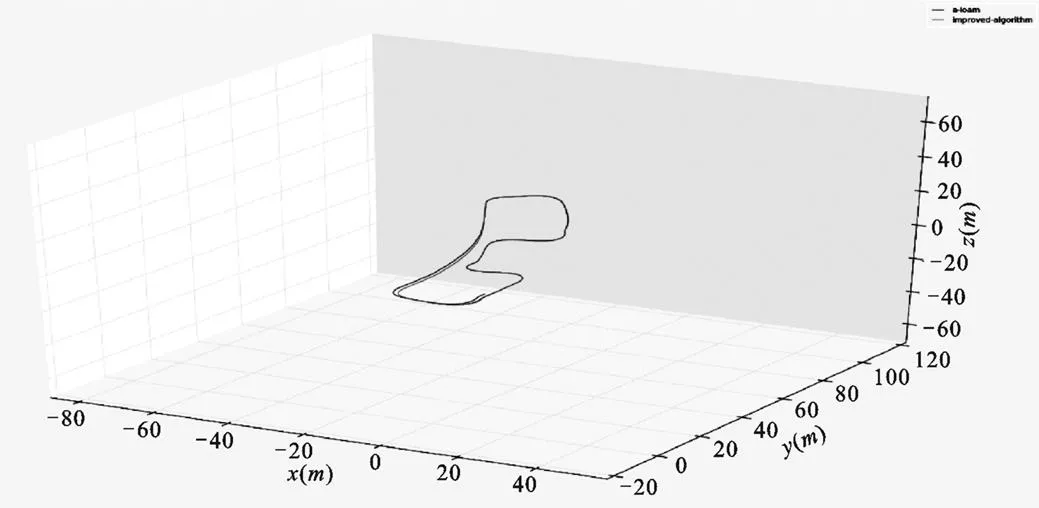
圖4 軌跡對比圖
表1為兩種算法相對位姿誤差的結果對比,該項指標與絕對誤差不同,其計算兩幀間的位姿變換并與真值進行結果對比。即便某次幀間變換誤差過大,并不影響后續誤差的計算,能夠對全局位姿估計誤差作出更為公正的判斷,評價結果更全面。因此,本文將相對位姿誤差作為算法精度的判定標準。該項指標中,最大值下降約59.67%,平均值下降約29.09%,中位數下降約27.66%,標準差下降約31.71%,均方誤差下降約30.43%。
表1 相對位姿誤差
絕對誤差A-LOAM本文算法 最大值0.041 90.016 9 平均值0.005 50.003 9 中位數0.004 70.003 4 標準差0.004 10.002 8 均方誤差0.006 90.004 8
SLAM算法框架的前端部分實時性要求較高且需要進行傳感器數據預處理,較長時間的解算過程將會影響后續傳感器數據的讀取,因此前端配準精度一般較低。而算法框架的后端優化部分在前端配準結果的基礎上進行點云幀到局部點云地圖的高精度位姿估計,更為準確的前端結果能有效加快算法的收斂速度,從而在相同的迭代次數下獲得更準確的結果。
3 結語
本文提出了一種基于激光視覺融合的SLAM前端幀間配準方法,通過耦合多種數據,添加約束使配準結果更加精確。實驗結果證明,改進算法相比改進前精度提升約30%。同時,添加的視覺信息能夠保證在一些退化環境中仍得到正確的旋轉約束,提升了前端幀間配準算法的魯棒性。
[1] 王錦凱,賈旭.視覺與激光融合SLAM研究綜述[J].遼寧工業大學學報(自然科學版),2020,40(06):356-361.
[2] J.Zhang,S.Singh.Visual-lidar odometry and mapping: Low- drift, robust, and fast[C].2015 IEEE International Conference on Robotics and Automation (ICRA),2015,2174-2181.
[3] Y. Xu, Y.Ou and T. Xu. SLAM of Robot based on the Fusion of Vision and LIDAR[C].2018 IEEE International Confe- rence on Cyborg and Bionic Systems (CBS), Shenzhen,2018, pp.121-126.
[4] Y.Shin,Y.S.Park and A.Kim.Direct Visual SLAM Using Sparse Depth for Camera-LiDAR System[C].2018 IEEE Internati- onal Conference on Robotics and Automation (ICRA), Brisb- ane,QLD, 2018, pp. 5144-5151.
[5] 歐陽毅.基于激光雷達與視覺融合的環境感知與自主定位系統[D].哈爾濱:哈爾濱工業大學,2019.
[6] Graeter J, Wilczynski A, Lauer M. LIMO: Lidar-Monocular Visual Odometry[C], IEEE/RSJ International Conference on Interlligent Robots and Systems(IROS), 2018 7872-7879.
[7] J.Zhang, S. Singh. LOAM: Lidar Odometry and Mapping in Real-time[C]. Robotics:Science and Systems Conference.2014.
[8] Fischler M A,Bolles R C.Random Sample Consensus:A Para- digm for Model Fitting with Applications to Image Analysis and Automated Cartography-ScienceDirect[J].Readings in Computer Vision, 1987:726-740.
[9] Lucas B D,Kanade T.An Iterative Image Registration Techniquewith an Application to Stereo Vision[C].Proceedings of the 7th International Joint Conference on Artificial Intelligence. Morgan Karfmann Publishers Inc.1997.
[10] Bentley J L,Friedman J H.Data structures for range searching [J]. ACM Computing Survyes,1979,11(4):397-409.
Frame-matching Method Based on Laser and Vision Fusion
HE Zhongwei, ZHANG Xiaojun, ZHANG Minglu
( School of Mechanical Engineering of Hebei University of Technology, Tianjin 300132 )
Simultaneous location and mapping (SLAM) is an important guarantee for robot to realize self navigation ability in unknown environment. At present, the main sensors used in SLAM algorithm are lidar or vision camera. Lidar can range more accurately, and visual camera can reflect the rich texture information of the environment. Compared with using a single sensor, SLAM algorithm can obtain more environmental information and achieve better positioning and mapping effect. In this paper, an inter frame matching method combining lidar and vision camera is proposed. By adding ground constraints and visual feature constraints in the process of slam inter frame matching, the accuracy of inter frame matching process is improved, the robustness of algorithm is enhanced, and the overall effect of SLAM algorithm is improved. Finally, the paper uses the collected underground parking data to verify the results, and compares with the open source algorithm A-LOAM. The results show that the relative pose error of the proposed method is improved by about 30% compared with A-LOAM.
SLAM; Laser and vision fusion; Ground extraction; ICP; RANSAC; FAST; Optical flow method; Inter frame match
A
1671-7988(2022)01-19-05
TP 24
A
1671-7988(2022)01-19-05
CLC NO.:TP 24
何仲偉,男,碩士研究生,河北工業大學機械工程學院,主要研究方向為智能車環境感知。
10.16638/j.cnki.1671-7988.2022.001.005
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
無線電工程(2020年11期)2020-10-29 01:25:46
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
