基于全局注意力的多尺度顯著性檢測網絡
2022-02-19 10:23:46葉協康馬晨陽陳小偉林家駿
計算機應用與軟件 2022年2期
葉協康 馬晨陽 陳小偉* 張 晴 林家駿
1(上海應用技術大學計算機科學與信息工程學院 上海 201418) 2(華東理工大學信息科學與工程學院 上海 200237)
0 引 言
顯著目標檢測是對圖像中最具視覺特點和吸引人的區域或物體進行定位,并按照符合人眼視覺特征的邊界進行分割。顯著目標檢測作為圖像處理的重要預處理步驟,其應用十分廣泛,如視覺跟蹤[1],語義分割[2]、目標識別[3]和圖像檢索[4]。
早期的顯著目標檢測算法主要依賴于啟發式先驗信息,如顏色、紋理和對比度,但是這些手工的特征很難捕捉高級語義關系和上下文信息,往往不能準確定位和分割出顯著目標,特別是面對顏色對比度低、多目標、背景結構雜亂等復雜場景。近年來,深度學習技術發展迅速,其中卷積神經網絡在各類計算機視覺任務中較大提升了模型性能[5-6]。基于卷積神經網絡的顯著目標檢測模型[7-8]較傳統的方法將檢測性能提高到了一個新的高度。這些模型采用編碼器與解碼器組合的結構。編碼器部分通常由預訓練好的模型組成,如ResNet[9]或VGG[10],提取不同層次不同尺度的各類特征。在解碼器中,提取到的特征會以不同的方式進行特征融合,最終生成顯著圖。
盡管基于卷積神經網絡的顯著性檢測模型取得了較好的研究進展,但是在面對低對比度、雜亂背景等復雜場景時,仍存在一些問題有待解決。從卷積神經網絡得到的不同層次的特征具有不同的特征屬性。高層次的特征包含豐富的語義信息但是缺少準確的位置信息,低層次的特征包含豐富的細節信息但卻無法排除背景噪聲干擾。研究人員提出多尺度特征融合方法,但是簡單的多尺度特征融合方法不能高效地融合特征。另外,對于從不同的卷積層提取的特征,并不是所有的特征通道都對最終的顯著圖有同等重要的影響。部分特征通道對顯著目標具有較高的敏感度,對檢測顯著目標提供了積極的響應,而其他特征通道的敏感度較低,甚至對非顯著目標有較高的響應,反而對檢測顯著目標產生了負面影響。因此,如果能夠選擇出相對重要的特征通道,去除噪聲通道產生的負面影響,便可以更好地檢測顯著目標,從而獲得更好的模型性能。
為了解決上述問題,本文提出一種基于全局注意力的多尺度網絡模型用于顯著目標檢測。首先,所提網絡采用主干網絡提取輸入圖像的多層級特征,將多層級特征分別融合,得到高層級特征和低層級特征。隨后,針對從主干網絡提取的最深層特征信息進行處理,利用不同膨脹率的空洞卷積獲得不同感受野信息以提取輸入圖像的多尺度全局信息,通過面向通道的注意模塊選擇合適的注意特征通道,計算表示每個特征通道重要性的權重系數,將得到的注意力權重作用于整合得到的高層級特征和低層級特征,利用注意力權重突出顯著目標特征通道,并且過濾噪聲通道。最后,利用高層級特征去指導低層級特征定位顯著目標,通過融合引導優化,豐富顯著目標的細節信息并抑制不相關的背景噪聲,提高模型性能。
為了驗證提出模型性能,在5個公開顯著目標檢測基準數據集上進行實驗并與近年發表的具有代表性的方法進行比較,實驗結果表明,本文模型可以獲得更好的局部細節和顯著圖。
1 相關工作
傳統的顯著性檢測方法大多根據圖像的低級特征和啟發式先驗信息來預測圖像的顯著性,如顏色、紋理、對比度[11]等。雖然這類方法在簡單場景中能夠檢測出大部分顯著性物體,但是這些方法主要依賴低層和中層特征,缺乏高層語義信息,無法在紋理復雜、背景雜亂的圖像中準確識別出顯著的目標。
卷積神經網絡在高級語義信息表征方面具有優勢,近年來被廣泛應用于顯著計算模型中[5-6]。文獻[12]將啟發式顯著先驗特征與循環深度網絡相結合,使用手工處理后的特征作為顯著先驗特征輸入。近年來,研究人員嘗試利用多層、多尺度特征融合[7],同時聚合高層語義信息和低層結構細節,以進一步提升模型性能。文獻[13]提出了一種分層優化模型,通過整合局部上下文信息逐步優化圖像細節。文獻[14-15]利用短連接融合多層級特征,同時利用高層語義信息和低層細節結構進行顯著性檢測。然而,多尺度特征存在冗余信息,只利用簡單的加法操作和連接操作的多尺度特征融合方法無法解決多層級特征間的信息冗余。
注意力機制可以在一定程度上有效過濾多尺度特征中的冗余信息,可顯著提升特征表示和學習性能,已應用于目標跟蹤[16]、姿態估計[17]、圖像分割[18]等多個計算機視覺任務中。文獻[19]提出了一種注意引導網絡,該網絡有選擇性融合多尺度上下文信息,產生注意特征來抑制背景的干擾,從而獲得更好的性能。文獻[20]采用門控雙向信息傳遞模塊,提供一個自適應并且有效的策略來集成多層級特征。文獻[21]使用殘差學習融合多層級特征進行顯著性優化,提出反向注意力的方式指導殘差學習。
2 本文方法
2.1 模型整體結構
本文提出的基于全局注意力的多尺度特征顯著性檢測模型的結構如圖1所示,主要由三個模塊組成,分別為特征增強模塊(Feature Enhancement Module,FEM)、全局注意力模塊(Global Attention Module,GAM)、多尺度優化模塊(Multi-scale Optimization Module,MOM)。其中:特征增強模塊針對從骨干網絡各個側邊輸出的多層級特征進行處理,提升特征的表達能力;全局注意力模塊利用空洞空間卷積池化金字塔(Atrous Spatial Pyramid Pooling,ASPP)模塊[22]提取全局信息,再從全局特征中提取通道權重信息;多尺度優化模塊將經通道權重優化后的高層級特征引導優化后的低層級特征進行優化,最后將優化后的低層級特征和高層級特征進行連接,生成最終的顯著圖。
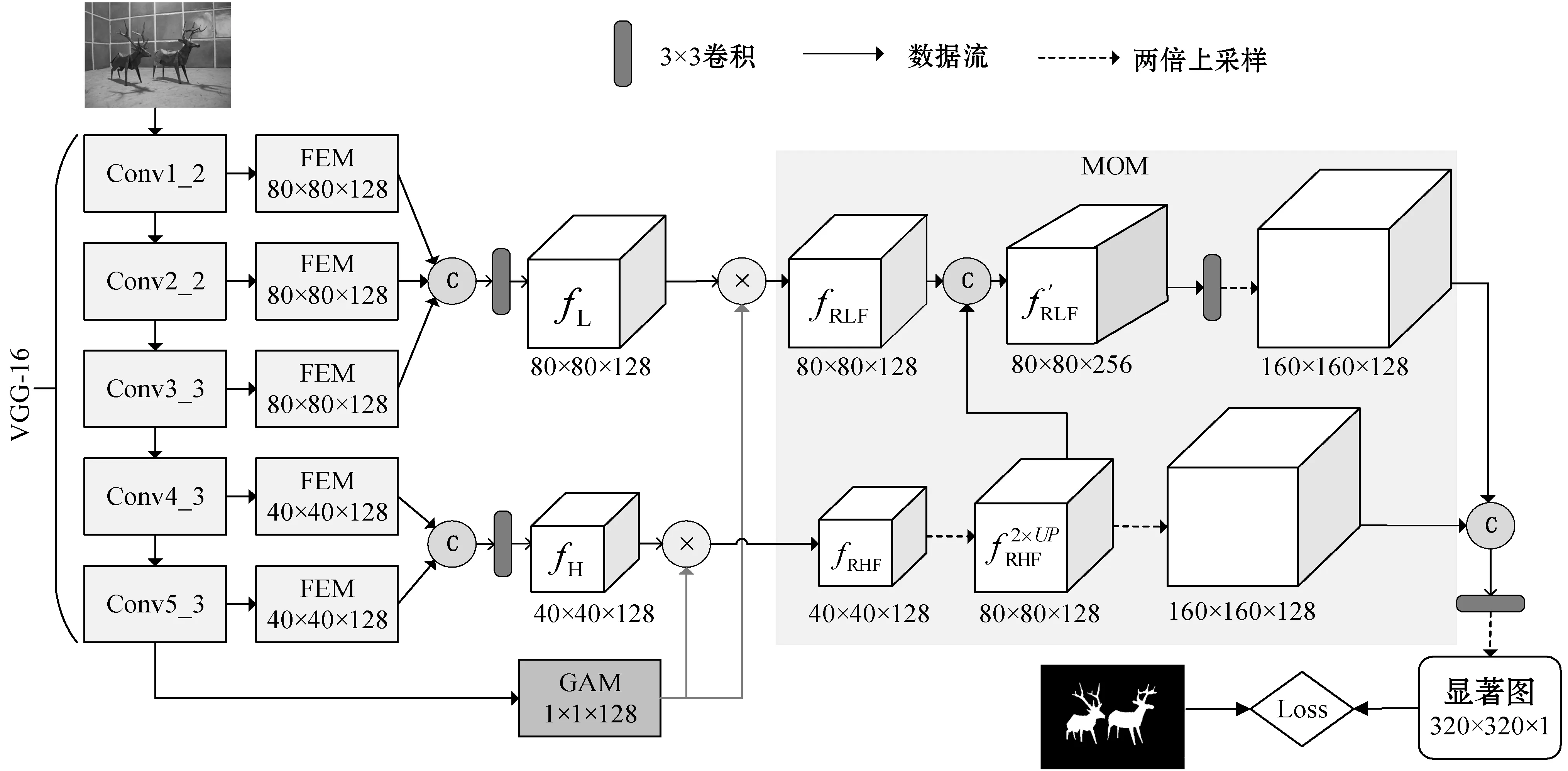
圖1 網絡模型
2.2 特征增強模塊
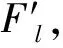
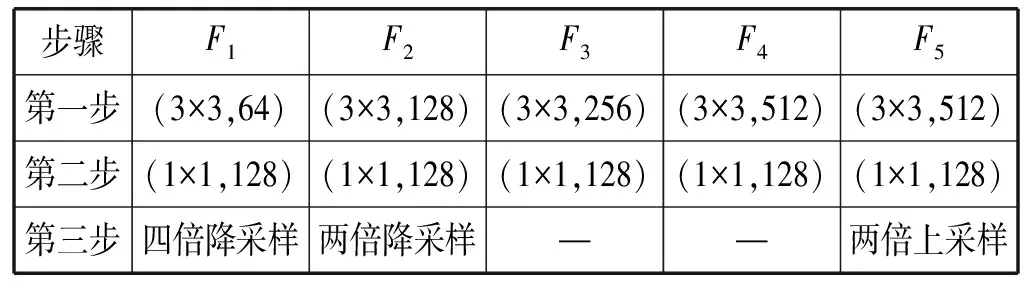
表1 特征增強模塊中的卷積層細節
最后,分別將采用處理后的前三層特征和后兩層特征進行連接,使用3×3大小的卷積核進行卷積操作,再將融合特征降至128維,得到高層級特征(High-level fusion features,fH)和低層級特征(Low-level fusion features,fL)。
2.3 全局注意力模塊
為了更好地提取全局信息,本文用ASPP模塊對VGG-16中從Pool5層提取的深層特征進行處理。與普通的卷積操作相比,空洞卷積能夠增大特征的感受野而不增加模型的計算量,因此使用空洞卷積可以提取更豐富的全局信息,本文模型分別采用膨脹率為1、6、12、18的空洞卷積,將不同空洞卷積后得到的特征融合得到多尺度全局信息特征X。
不同特征通道對不同的對象會有不同的響應值,對于一幅給定圖像,并不是所有的物體都是顯著目標,因此無區別地對待所有特征通道可能會導致檢測性能下降,甚至出現完全相反的結果,所以找到對顯著目標具有高響應值的特征通道會大大提高模型性能。受文獻[23]的啟發,本文對全局信息優化后的特征進行重要性權重計算,網絡模塊如圖2所示。首先用全局平均池化操作處理,然后采用兩個1×1卷積操作,最后使用Sigmoid激活函數得到通道注意力權重。
圖2 全局注意力模塊細節
2.4 多尺度優化模塊
由于來自深層的高層級特征圖包含較多的高級語義信息,能夠準確定位顯著目標,而來自淺層的特征具有豐富的空間信息,能夠更好地捕捉結構細節,為了高層特征與低層特征更好地融合以獲得更優的顯著圖,本文提出新的融合方法,采用高層級特征指導低層級特征定位顯著目標。
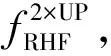
3 實驗與結果分析
3.1 基準數據集
本文方法在5個常用基準數據集上進行性能評估實驗。ECSSD數據集包含1 000幅各種復雜場景的圖像。DUT-OMRON數據集包含5 168幅更具挑戰性的圖像。HKU-IS數據集包含4 447幅圖像,其中包含很多不連續顯著的對象、對比度較低或顯著目標觸及圖像邊界的圖像。PASCAL-S數據集是從PASCAL-VOC分割數據集中挑選出來的,這個數據集共有850幅自然圖像。DUTS-TE是DUTS數據集的測試集,包含很多具有挑戰性的復雜場景。
3.2 評估指標
本文采用5種性能評價指標來定量評價。
(1) PR曲線:通過使用0到255之間的不同閾值對顯著性圖進行二值化計算,然后將二值化后的圖與真值圖進行比較,得到一系列成對的查準率和查全率,即可繪制PR曲線。
(2) F-measure是對查準率和查全率進行加權計算,即:
(1)
式中:β2通常設置為0.3[24];p為查準率;r為查全率。
(3)ωFβ是F-measure的加權,彌補了傳統評價指標的插值、依賴和重要性相同等不足,類似于Fβ,ωFβ由pω和rω的加權調和平均值計算而得,即:
(2)
(4)MAE定義為預測的顯著圖與真值圖之間的像素級平均絕對誤差:
(3)
式中:w和h分別代表預測的顯著圖S的寬度和高度;G表示真值圖。MAE的值越小表示預測的顯著圖與真值圖之間的差距越小,即性能越強。
3.3 實現細節
本文網絡基于PyTorch實現,并使用單個NVIDIA GTX TITAN GPU訓練網絡。使用DUTS-TR數據集訓練模型,該數據集包含10 553幅圖像。為了使模型更具魯棒性,通過水平翻轉進行數據增強。模型使用Adam優化器訓練,其權重衰減為0.000 5,初始學習率為0.000 5,并在迭代了15個epoch后學習率下降10%,總共訓練24個epoch。為了更好地監督損失,本文采用混合損失函數監督的方式,同時使用BCE[25]、SSIM[26]、IoU[27]作為損失函數。
3.4 與新近算法的性能比較
本文方法與9種相關顯著目標檢測方法進行比較,包括DCL[14]、RFCN[5]、DHS[13]、NLDF[6]、Amulet[7]、PAGR[19]、C2S[8]、RAS[21]和DSS[15],出于公平原則,本文使用上述算法作者提供的模型和顯著圖。
3.4.1定量評估
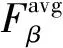
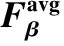
表2 不同方法在不同數據集的Fβ和比較

續表2
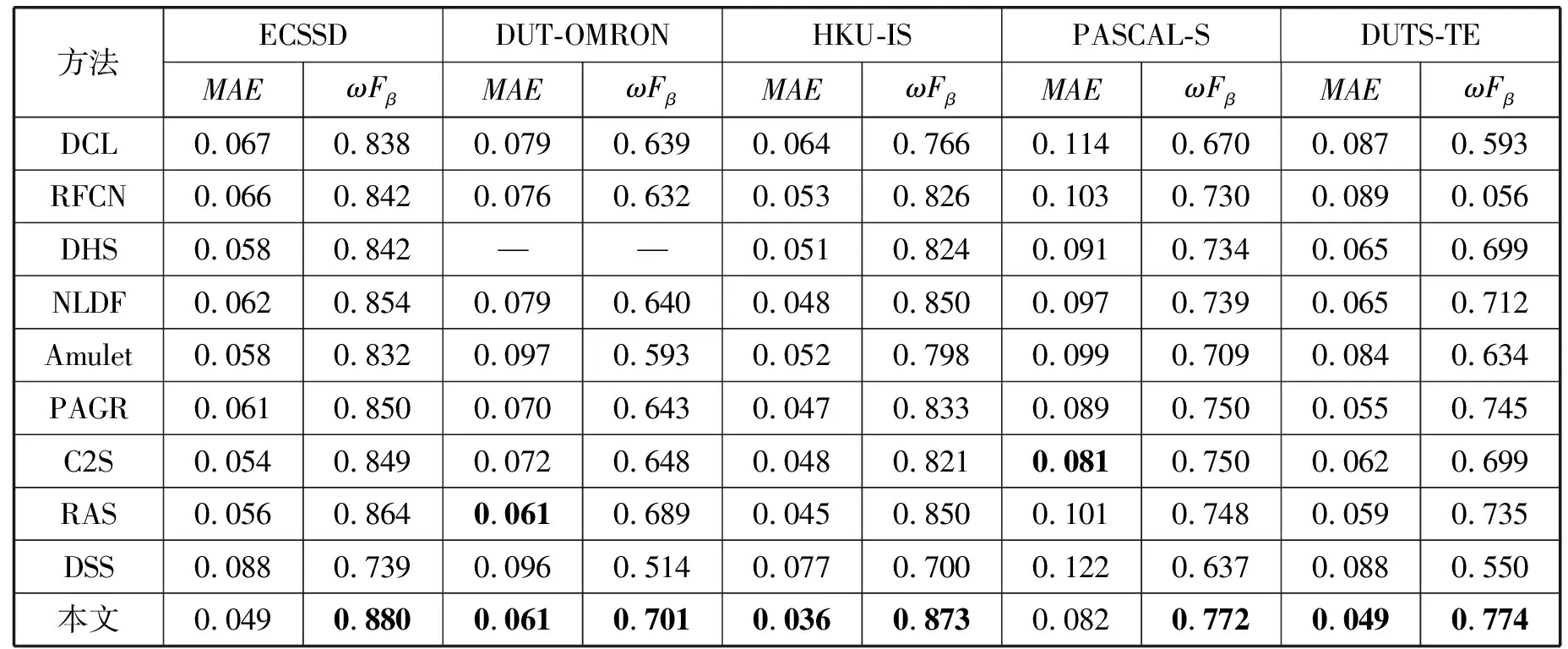
表3 不同方法在不同數據集的MAE和ωFβ比較
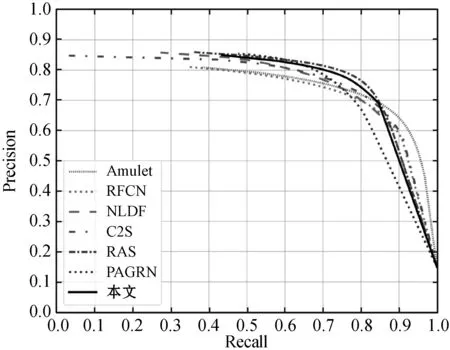
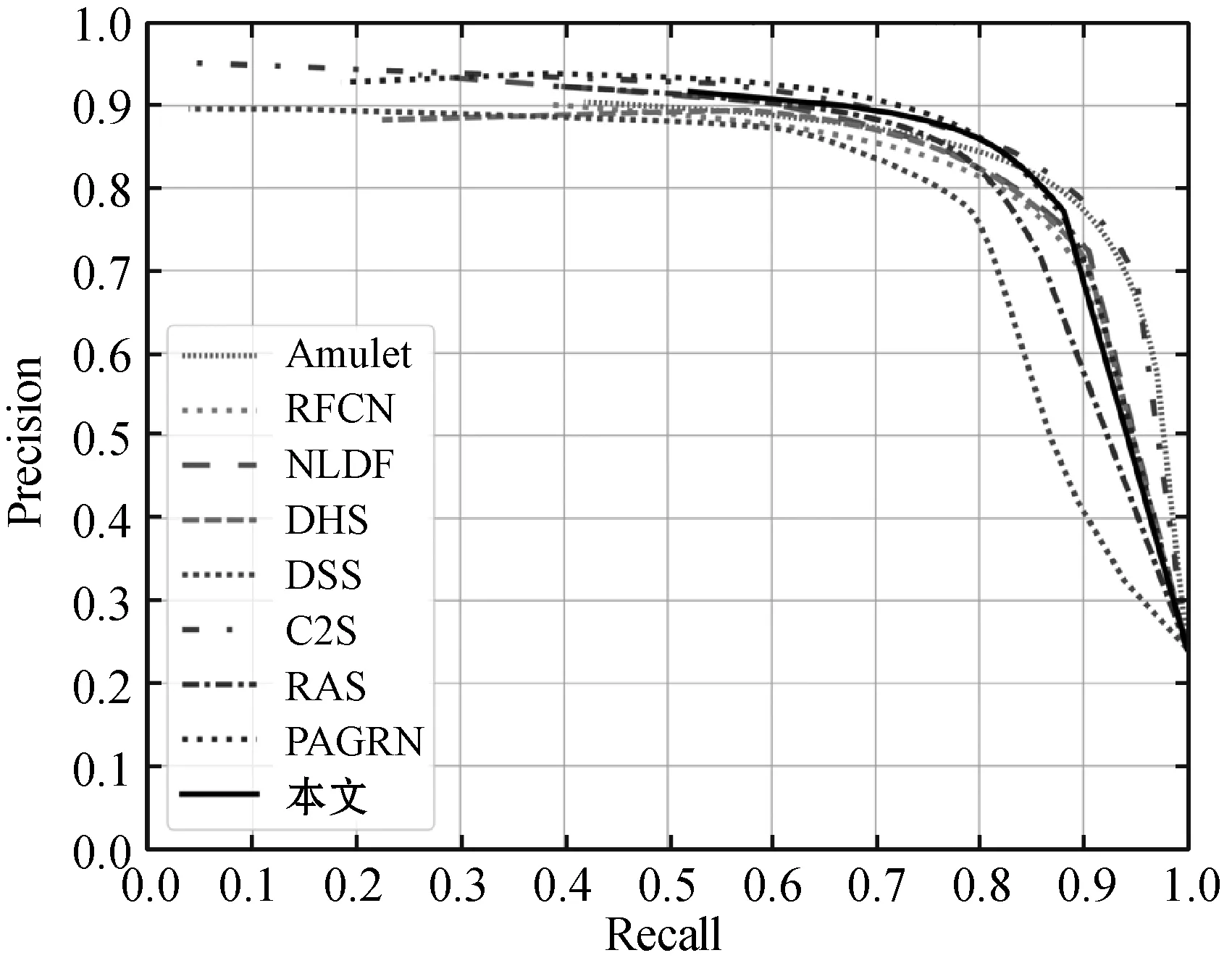
圖3為各方法在基準數據集上的PR曲線比較,可以看到,本文方法在DUT-OMRON數據集上與RAS性能相當,在ECSSD、PASCAL-S、HUK-IS數據集上,本文方法較其他方法均具有優勢,說明本文方法性能優于其他方法。
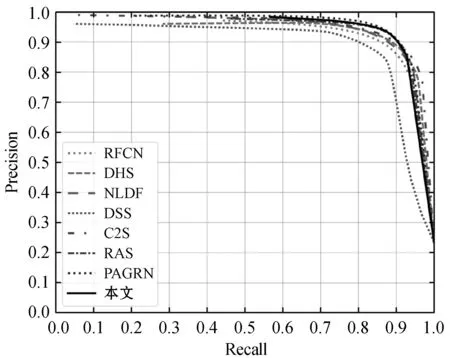
(a) ECSSD
(b) DUT-OMRON
(c) PASCAL-S
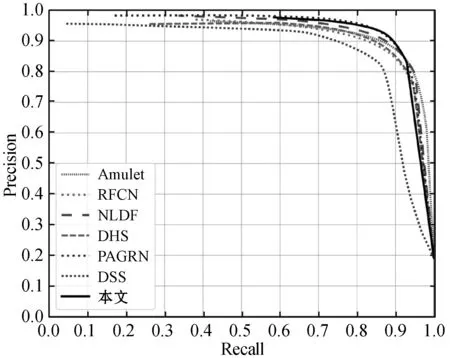
(d) HUK-IS圖3 不同算法在不同數據集的PR曲線比較
3.4.2定性評估
圖4是本文方法和其他方法的顯著性檢測直觀視覺效果比較。可以看出,本文方法的顯著性檢測視覺效果比其他方法好,能夠更加準確地檢測顯著性目標。例如,在第5幅圖像中,其他方法未能完整地檢測出顯著性目標,而本文準確檢測出完整的顯著性目標。在第7幅圖像中,其他方法檢測出來的蝴蝶被蝴蝶后的花朵干擾,導致檢測出來的顯著性區域比真值多出一部分,而本文方法精準地檢測出完整的蝴蝶。無論是顯著性目標邊界比較細致(第1、第2、第6行)、前景背景對比度不大(第3行),還是有多個顯著性目標(第4、第8行),本文方法均能準確定位顯著性目標,檢測出完整顯著區域。

(a)輸入 (b) 真值 (c) DCL (d) RFCN (e) DHS (f) NLDF (g) Amulet (h) PAGR (i) RAS (j) DSS (k) 本文圖4 不同方法的視覺對比
3.5 消融分析
為了驗證本文模型各模塊的有效性,我們分別依次移除各個模塊,在DUTS數據集上重新訓練模型,在DUT-OMRON和HKU-IS數據集上進行性能測試。
如表4所示,其中:Ourswo_ASPP表示移除全局注意力模塊中的ASPP模塊;Ourswo_Weight表示移除全局注意力模塊中的通道權重模塊;Ourswo_GAM表示移除整個全局注意力模塊;Ourswo_MOM表示移除多尺度優化模塊中高層特征與低層特征融合步驟。可以看出本文模型的各個模塊移除后,性能有明顯下降,說明本文算法中各個模塊的有效性。
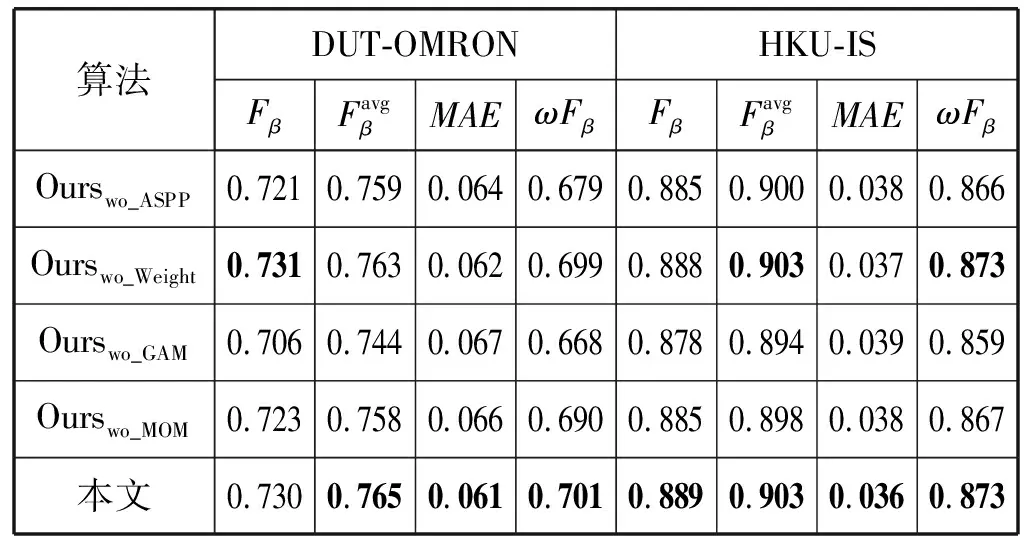
表4 本文模型各模塊性能比較
4 結 語
本文提出一種基于多尺度優化和全局注意力的網絡結構。首先,該網絡增強主干網絡的特征,融合前三層和后兩層特征,進行多尺度特征融合得到高層和低層特征,然后利用ASPP模塊提取全局信息,再提取全局信息中的通道權重,以此權重引導優化高層和低層特征,最后融合高層特征和低層特征,得到顯著性預測圖。本文方法在常用的基準數據集上與近幾年基于深度學習的顯著性檢測方法進行比較,實驗結果證明本文方法整體上相較于近幾年的方法性能更加優異。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
