一種基于多任務學習的方面級情感分析方法
2022-02-19 10:24:16唐伶俐劉永堅
計算機應用與軟件 2022年2期
馬 雨 解 慶 唐伶俐 劉永堅
(武漢理工大學計算機科學與技術學院 湖北 武漢 430070)
0 引 言
當今時代互聯網迅猛發展,網絡上每天都會產生大量的信息,包括各種各樣的用戶評論信息。比如用戶可以對某個企業的某個產品做出評價,可以對剛看完的電影做出評價,也可以對政府對于重大事件的決策發表意見等。企業可以通過用戶反饋的評價信息來優化產品及運營,政府可以通過分析評論來體察民情民意,用戶可以通過其他用戶對于某款產品的評價來決定是否消費該產品等。對這些信息做出合理的分析,不管是對于政府、企業還是用戶都大有裨益。而在這些信息中用戶的主觀情感取向是極其重要的組成部分,因此研究者開始分析如上所述的不同類型的評論數據中所包含的個人主觀情感取向,由此產生了情感分析技術。
情感分析(Sentiment Analysis)又稱意見挖掘(Opinion Mining),它利用文本分析、機器學習、語言學、深度學習等方法對帶有情感色彩的文本進行分析、處理、推理和歸納[1]。通俗而言,主要是對文本所表達的情感傾向做出判斷,一般有三種情感極性:正面、中立和負面。基于對文檔分類粒度的不同又分為:篇章級和句子級的粗粒度情感分析和方面級的細粒度情感分析。粗粒度情感分析假設每一篇或者每一句文本的評論對象以及對應的情感極性只有一個,這顯然不符合實際應用中復雜的情況。
因此,近來學術研究越來越關注細粒度情感分析,即針對某一句或某一段評論文本中的多個評論對象,分別分析各自的情感極性。方面級的細粒度情感分析又分為方面類別情感分析ACSA(Aspect Category Sentiment Analysis)和方面詞項情感分析ATSA(Aspect Term Sentiment Analysis)兩個子任務。對于ACSA,上述細粒度情感分析定義中的“評論對象”指的是方面類別詞;對于ATSA,其中的“評論對象”指的是方面詞項。ACSA任務例如:“The boiled fish is delicious, but the price is too expensive.”,boiled fish對應的food類是積極的情感極性,而price對應的price類是消極的情感極性;ATSA任務的實例如下:“The boiled fish is delicious, but the beef is too salty.”,boiled fish這個詞項對應的是積極的情感極性,而beef這個詞項對應的是消極的情感極性。雖然兩個詞項都屬于food類,但是ATSA的處理對象更加細化。目前的研究成果大多基于深度學習方法,且只關注方面級情感分析的其中一項任務,而且目前方面級情感分析的數據集不足,因此整體的性能表現并未達到預期。
本文提出一種基于多任務學習的方面級情感分析模型(Aspect-level sentiment analysis model based on multi-task learning,ASA-MTL)來解決方面級情感分析問題。該模型的核心思想是利用多任務學習網絡的性能,同時學習方面級情感分析的兩個子任務和輔助的方面詞項重建任務[2],共享其中的隱層參數和各個子任務的特征表示,促進多個子任務共同學習,解決了單任務網絡因不能共享自身特征而導致性能不佳的問題。同時,多任務學習框架使得每一個子任務都為其他子任務提供額外的信息,一定程度上緩解了方面級情感分析數據集不足的問題。在模型訓練結構中,首先使用雙向門控循環單元(Bi-GRU)及Sentence-level的注意力機制來對詞向量編碼,獲得更好的語義向量。然后在各個任務的單獨網絡層,對于兩個情感分析子任務,使用Aspect-level的注意力機制能夠在句子中根據不同方面捕獲不同的重要信息。綜上所述,本文的工作有如下三個方面:
(1) 將兩個方面級情感分析子任務利用多任務學習框架進行共同訓練學習。
(2) 使用Sentence-level和Aspect-level兩層注意力機制來更好地注意方面詞和情感詞,從而提升模型的總體表現。
(3) 多任務學習框架中添加方面詞項重建任務在一定程度上確保方面特定的信息對其他兩個子任務產生積極的影響。
本文的模型在SemEval的餐館和電腦領域數據集上進行評測,結果表明,與當前具有代表性的方法進行比較,本文提出的模型在方面級情感分析任務中的效果有了顯著的提高。
1 相關工作
1.1 情感分析
基于深度神經網絡的方面級情感分析工作取得了不錯的進展,尤其是基于循環神經網絡RNN(Recurrent Neural Network)、長短期記憶網絡LSTM(Long Short-Term Memory)、門控循環單元GRU(Gate Recurrent Unit),以及注意力機制[3](Attention Mechanism)等模型。文獻[4]總結了各種深度神經網絡用于情感分析任務,其中包括RNN、LSTM、CNN和基于注意力機制[5]的RNN等,同時也介紹了篇章級、句子級和方面級等幾項情感分類子任務。文獻[6]闡述了如何使用LSTM及其優化模型,即雙向LSTM網絡和“門控”對文本進行分類。文獻[7]提出了兩種基于長短期記憶網絡的模型:TD-LSTM和TC-LSTM,并驗證了這兩個模型在情感分類任務上的出色表現。CNN最早應用在圖像識別領域[8],而以CNN為基礎的模型在自然語言處理上同樣也不遜色。文獻[9]首先將CNN模型用于文本分類上,CNN的特點在于能夠保留句子的局部關鍵信息,因此取得了優異的成績。文獻[10]認為雖然深度神經網絡取得了不錯的進展,但是并未充分利用情感語言學知識,忽略了情感詞、否定詞等的重要性,因此提出了一種多情感資源增強注意網絡(MEAN),通過注意力機制將情感詞、否定詞和強度詞整合到深層神經網絡來緩解該問題,用于句子級的情感分類。文獻[11]提出基于注意力的LSTM用于方面級情感分析,其核心思想是學習aspect向量,讓aspect向量參與到attention權重的計算中。文獻[12]認為位置信息對于方面級情感分析任務是有益的,因此提出了一種基于層次關注的位置感知網絡,也取得了不錯的成績。文獻[13]將方面級情感分析任務細化為兩個子任務:方面類別情感分析ACSA和方面詞項情感分析ATSA。提出了GCAE模型,該模型由兩個卷積層和兩個非線性的門單元組成,繼承了LSTM中門單元的特性,又比LSTM的結構簡單太多,可以并行工作,獲得了較短的模型訓練時間和優秀的模型性能。
1.2 多任務學習
多任務學習(Mutli-task Learning)屬于遷移學習領域,但不同于遷移學習注重從源域到目標域的知識遷移,多任務學習基于共享表示,注重任務之間的相關性,通過并行學習來改善單個任務學習的性能。多任務學習有很多形式,聯合學習(Joint Learning)、自主學習(Learning to Learn)和帶有輔助任務的學習(Learning with Auxiliary Task)[14]。文獻[15]分析基于單任務監督目標學習的模型通常受到訓練數據不足的影響,因而提出了使用多任務學習框架來共同學習多個相關任務。文獻基于循環神經網絡,提出了三種不同的共享信息機制,以模擬具有特定任務和共享層的文本,整個網絡共同訓練所有任務。對四個文本分類任務的實驗表明文獻提出的模型可以借助其他相關任務來提高單一任務的性能。文獻[16]認為情感分析中三分類和五分類問題是相關的,因此提出了一個基于RNN的多任務學習方法。實驗表明多任務模型有助于改善細粒度情感分析。文獻[17]提出了一種對抗性的多任務學習框架,減輕了共享和私有潛在特征空間之間的相互干擾。對16種不同的文本分類任務進行實驗驗證,表明了該方法的優勢。文獻[18]針對當前的大多數工作無法直接優化所需任務的非監督目標,或受訓練數據不足困擾的單任務監督目標來學習模型,提出了一種多任務深度神經網絡,用于學習跨多個任務的表示形式。
2 多任務情感分析模型ASA-MTL
本文提出一種基于多任務學習的方面級情感分析模型ASA-MTL,如圖1所示,主要包括以下2種結構。
(1) 多任務共享提取特征結構。該結構基于Bi-GRU及Sentence-level的注意力機制,是多任務的共享部分,在此結構中共同訓練各個子任務的數據,達到共同學習的目的。模型將兩個任務的語料庫經過共享Embedding層得到詞向量,將詞向量送入Bi-GRU編碼獲得新的向量。通過Sentence-level的注意力機制更好地捕獲句子的內部結構,提高句子中方面詞和情感詞在詞嵌入中的權重,得到最終的句子表示(圖1中“H”部分)。

圖1 基于多任務學習的方面級情感分析模型ASA-MTL
另外,考慮到實際評論文本中普遍存在的多方面情感交織問題,本模型采用一個額外的CNN完成方面詞項的識別和提取的工作。如圖2所示,模型以窗口滑動的形式提取句子的局部特征,通過最大池化層、全連接層、Softmax層,最終提取方面詞項。

圖2 CNN結構提取方面詞項
(2) 任務特定輸出結構。該結構基于Aspect-level的注意力機制,是各個子任務的獨有部分,分別使用注意力機制為不同任務服務并將結果輸出。首先通過上述共享層得到任務共享的句子表示。
對于ACSA任務,首先將句子表示和方面類別嵌入拼接作為該任務特定的注意力層的輸入,當不同的方面類別詞輸入的時候,注意力機制可以專注于句子的不同部分,最后用Softmax層將結果映射至概率空間,完成方面類別情感分類。
對于ATSA任務,首先將方面詞項從句子中提取出來,并得到方面詞項嵌入,然后將方面詞項嵌入和句子表示拼接送入該任務特定的注意力層,不同的方面詞項的輸入會使得注意力機制對句子的不同位置產生關注,最后用Softmax層將結果映射至概率空間,完成方面詞項情感分類。
方面詞項重建任務ATR(Aspect Term Reconstruction)為ACSA和ATSA的輔助任務,重建方面詞項。句子中方面詞項可能由多個單詞組成,因此是多標簽問題。該任務將共享句子向量通過解碼器Bi-GRU對向量操作,之后用全連接層進行多標簽分類,得到方面詞項。
2.1 多任務共享提取特征結構
在多任務共享提取特征結構中,使用一個任務共享的Embedding層、Bi-GRU層、Sentence-level的注意力層來捕獲三個任務的特征,其中Sentence-level的注意力層采用Self-attention機制。將文本數據經過Embedding層,得到句子的詞向量表示之后共同送入Bi-GRU層,利用Bi-GRU結構,將所有任務的數據共同參與訓練,得到一個共同的隱藏狀態表示,并使用Self-attention機制更好地注意方面詞和情感詞,得到最終的句子表示,解決了單任務學習時因不能共享自身特征而導致性能不佳的問題。
2.1.1Embedding層
Embedding層將詞語轉化成向量的形式,實現將詞語從語義空間映射到向量空間,且原本語義接近的兩個詞匯在向量空間中的位置也是接近的。給定一個含有n個詞的句子s={w1,w2,…,wn},通過嵌入矩陣E∈RV×d來獲取句子向量表示。其中:V是詞匯表的大小;d是詞嵌入的維度。本文采用300維的Glove[19]向量矩陣來初始化矩陣E,并在訓練過程中進行微調。
2.1.2Bi-GRU層
多任務共享提取特征結構使用Bi-GRU來編碼句子向量,獲取句子的高維語義特征。GRU是由LSTM發展變化而來的模型。LSTM具有三個“門”機制,可以讓信息選擇性通過,能夠較好地處理長序列,但其模型復雜,需要學習的參數較多,需要很長的訓練時間[19]。GRU簡化了LSTM的內部結構,去除了細胞狀態,只包含更新門和重置門,使用隱藏狀態來進行信息的傳遞,能將輸入序列映射成一個包含高層語義信息的新序列。這樣模型具有更少的參數,能夠在提高模型訓練速度的基礎上保證訓練效果,其結構如圖3所示。

圖3 GRU的內部結構

zt=σ(Wz[ht-1,xt]+bz)
(1)
rt=σ(Wr[ht-1,xt]+br)
(2)
(3)
(4)

單向的GRU從左到右編碼句子,只能看到句子過去的上文信息,不能看到句子未來的下文信息。本文采用Bi-GRU從正向和反向兩個方向來獲取上下文信息,因此能夠獲得兩個隱藏表示,然后級聯每一個詞的正向隱藏狀態和反向隱藏狀態。第i個詞的輸出為:
(5)

H1=[h1,h2,…,hi,…,hn]
(6)
式中:n為句子所含詞語的個數。
2.1.3Sentence-level的注意力層
在情感分析任務中,一個句子中的不同單詞對幫助方面級情感分析做出不等同的貢獻。因此本文引入了一種Sentence-level注意機制,以提取更重要的單詞。Self-attention能通過將所有相關單詞的理解融入到正在處理的單詞中,充分考慮到句子之間不同詞語之間的語義關系。因此該層采用Self-attention機制對獲得的隱層表示進一步編碼,將方面詞和其情感詞等這些信息性單詞的表示形式匯總起來,從而形成Sentence-level的表示形式。
Self-attention是注意力機制的一種,對每一個單詞處理都能充分考慮到其他單詞,也就是說可能會和所有的詞語都做一個加權。而RNN及其變體在處理單詞時卻只能依靠上一個階段的輸出狀態和當前的輸入狀態。如圖4所示,可以看到Self-attention的處理機制,允許模型選擇性地關注一些詞。

圖4 Self-attention的工作機制
對于上文中得到的H1中的每一個詞向量,在Self-attention中都會經過計算得出三個不同的向量Q、K和V。每一個位置上詞的Q向量與所有位置上詞的K向量進行點積相乘后做Softmax歸一化操作,得到每一個詞的權重。最后,將得到的權重與每個位置上詞的V向量加權求和,得到最終的向量:
(7)

2.2 任務特定輸出結構
在兩個情感分析子任務中,為了更好地對應給定的方面來捕捉句子中重要的部分[11],使用Aspect-level的注意力機制作為共享層之后的任務特定層。在方面詞項重建任務中,使用Bi-GRU作為解碼器,之后接一個全連接層來進行多標簽分類,重建方面詞項。
該結構是在上述多任務共享結構基礎上對于兩個情感分析任務分別加入注意力層,當句子中有多種不同的方面時,注意力機制使得模型能夠捕獲句子中最重要的部分。分別將方面類別詞向量或方面詞項向量與多任務共享結構得到的向量H拼接起來作為注意力機制的輸入表示。注意力機制將會產生一個注意力權重向量α和給定方面的句子加權表示組成的向量r。α=[α1,α2,…,αi,…,αn],其中αi代表每個詞的注意力權重。
(1) 對于ACSA和ATSA任務。將H和va拼接后的向量經過tanh激活函數,得到M,然后經過Softmax得到注意力權重α,最終得到給定方面類別或方面詞項的句子向量r:
(8)
α=softmax(wTM)
(9)
r=HαT
(10)
式中:va代表ACSA任務中的方面類別詞向量或ATSA任務中的方面詞項向量;Wh、Wa和wT是參數。
最終得到句子表示是r和最后的輸出向量hN的非線性組合,并使用Softmax分類器將給定方面類別或方面詞項的句子特征表示h*轉化為條件概率分布:
h*=tanh(Wrr+WnhN)
(11)
y=softmax(Wsh*+bs)
(12)
式中:Wr和Wn是訓練過程中需要學習的參數;h*是給定方面的句子特征表示;Ws和bs是Softmax分類器的參數。
(2) 對于ATR任務。方面類別情感分析數據集中只有幾個預先定義的方面類別,例如餐飲領域的food類、service類和price類等。在方面詞項情感分析數據集中,方面詞項的數量有很多,而組成方面詞項的詞是有限的。方面詞項存在于句子中,一個方面類別可以對應多個方面詞項,因此在多任務學習結構中該任務對于兩個情感分析子任務是有助益的。
方面詞項重建是將句子中所包含的方面詞項找出來,具體表現為給每個句子打上標簽,標簽內容為方面詞項。例如:“The boiled fish is delicious, but the beef is too salty.”該句中方面詞項是boiled fish和beef,那么該句子將被打上這兩個標簽。句子中含有的方面詞項個數即為標簽的個數。
在多任務共享結構中得到句子表示之后,將其輸入至Bi-GRU中,這里的Bi-GRU作為解碼器,然后將結果輸入至全連接層進行多標簽分類,當一個句子中包含多個方面詞項時,則為這個句子貼上它所擁有詞項的標簽,重建句子中包含的方面詞項。對于多標簽問題,使用損失函數是Sigmoid交叉熵,公式如下:
(13)
式中:C代表構成訓練例子中所有詞項的單詞數;yi是單詞的真實值;pi是單詞的預測值。
2.3 損失函數
模型的損失函數采用交叉熵損失函數,通過反向傳播以端到端的方式來訓練模型。對于ASA-MTL模型,三個任務共有三個損失函數,總的損失函數是:
loss=αloss1+βloss2+γloss3
(14)
式中:loss1、loss2、loss3分別是ACSA、ATSA和方面詞項重建任務的損失函數,均采用交叉熵來估計損失;α、β和γ分別是權重系數,系數之和為1。三個權重系數通過訓練過程中反復調試得到。ACSA和ATSA任務的損失函數如下:
(15)
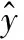
3 實 驗
3.1 實驗設置
3.1.1實驗環境
實驗環境:操作系統Ubuntu 12.0.3,內存16 GB,編程平臺Pycharm,Python 3.6版本,深度學習框架Keras。
3.1.2數據集與評估標準
數據集:本實驗采用公共數據集SemEval 2014 task4,2015 task12、2016 task5作為兩個任務的語料,其中包括餐廳和筆記本電腦的客戶評論。參考該數據集上的其他工作[11,20],移除了其中的“conflict”標簽,剩余三個情感標簽分別是“positive”“negative”和“neutral”,即進行“積極”“消極”和“中性”三分類的實驗。采用文獻[13]的方法,合并了2014至2016三年的餐飲領域的數據,修復了數據的不兼容性,刪除“conflict”標簽而不是把它替換為“neutral”,以此作為ACSA的數據集,最后共得到餐廳領域訓練集4 470條數據,測試集2 374條數據。對于ATSA的數據集,采用的是SemEval2014 task4的餐廳評論和電腦評論,其中電腦(Laptop,L)評論共有訓練集2 313條數據、測試集638條數據,餐廳(Restaurant,R)評論共有訓練集3 602條數據、測試集1 120條數據。表1是數據集各個類別的樣本數。

表1 ACSA和ATSA任務統計的數據集
評估標準:本文采用精確率(Accuracy,Acc)和F1值作為分類任務的評價指標,采用隨機初始化每種方法運行5次的平均值。使用到的統計項如表2所示。

表2 評估標準中使用到的統計項
精確率(Accuracy)及F1值的公式如下:
(16)
(17)
(18)
(19)
式中:precision和recall自身也是一種常見的評價指標,但事實上這兩者在一些情況下有矛盾,故使用同時兼顧了precision和recall的F1值作為評價指標。
3.1.3實驗方法
本實驗驗證了本文提出的多任務學習框架,根據方面詞項重建任務是否引入,分別按如下方式表示:(1) 只包含ACSA和ATSA兩個任務的訓練模型ASA-DTL;(2) 包含ACSA、ATSA和重建三個任務的訓練模型ASA-MTL。實驗目的主要是期望驗證多任務學習框架對比單任務學習框架的優勢,以及方面詞項重建任務在多任務學習框架下對兩個情感分析任務的輔助作用。
本實驗選用AdaGrad優化器來進行參數的更新。批處理大小和初始的學習率分別設置為32和0.01,dropout率為50%。詞向量采用300維的Glove向量矩陣來初始化,并在訓練過程中進行微調。不在Glove詞匯表中的單詞用均勻分布U(-0.25,0.25)來隨機初始化。實驗基于Keras來實現。
3.2 實驗結果與分析
3.2.1對比實驗的結果分析
為了評估本文模型的性能,需要與幾種基線模型做對比實驗。表3描述了對比模型和本文模型的分類精確率,實驗結果均為重復實驗五次的平均值。

表3 各個模型在不同數據集上的精確率和F1值
(1) LSTM[6]:由基礎的LSTM得到句子表示并運用分類器來分類。
(2) AT-LSTM[11]:在LSTM的基礎上做的改進,通過LSTM對句子建模,并連接方面向量以計算注意力權重,然后將其用于生成輸入句子的最終表示,以判斷情感極性。
(3) ATAE-LSTM[11]:通過將方面詞嵌入附加到每個單詞嵌入來擴展AT-LSTM,這樣能夠更好地發揮方面信息的優勢。
(4) TD-LSTM[7]:使用兩個LSTM網絡對目標的前后上下文進行建模,以生成與目標相關的情感預測表示。
(5) TC-LSTM[7]:在TD-LSTM的基礎上進行改進,在構建句子表示形式時更好地利用目標和每個上下文詞之間的聯系,將單詞嵌入和目標向量的串聯作為每個位置的輸入,最后進行情感分析。
可以看出,LSTM是表現最差的一個模型,其分類精確率僅有0.814,因為它無法獲得句子中有關方面詞的任何信息。AT-LSTM模型是在LSTM的基礎上做的改進,其表現優于LSTM。TD-LSTM的表現也優于LSTM,但由于該模型并未使用注意力機制,因此它無法知曉句子中的單詞對于給定方面的重要性。TC-LSTM模型的性能優于TD-LSTM,這得益于其很好地利用了目標詞語上下文的聯系。ATAE-LSTM是這些對比實驗中效果最好的,分類精確率是0.837,它既有方面向量的助益,又使用注意力機制極大地提升了性能。
ASA-DTL模型是ACSA和ATSA兩個任務共同學習的結構,該模型可驗證多個相關任務學習對于各自任務性能提升的有效性。從表3中可以看出,ASA-DTL模型在三個數據集上都取得了較好的情感分析效果,其中在R(ACSA)上的分類精確率為0.850,比起效果較好的TC-LSTM模型和ATAE-LSTM模型分別提升0.019和0.13;在R(ATSA)數據集上的分類精確率為0.773,而ATAE-LSTM和TC-LSTM的分類精確率分別是0.762和0.756,分別比上述兩個效果好的模型分別提升了0.011和0.017;在L(ATSA)數據集上的表現也是可觀的,比先前的實驗均有所提升。由表3中數據可得,ASA-DTL模型在R(ATSA)數據集上的F1值為0.778,比ATAE-LSTM模型高了0.012;在另外兩個數據集上的表現也都優于其他模型。綜上所述,通過這些實驗驗證了相關任務共同學習的有效性。
ASA-MTL模型在ASA-DTL模型的基礎上加入方面詞項重建任務作為輔助任務。從表3中可以看出,該模型在三個數據集上表現是最好的,在R(ACSA)數據集上的分類精確率為0.856,在R(ATSA)數據集上的分類精確率為0.780,在L(ATSA)數據集上的分類精確率為0.697,均高于ASA-DTL模型。由此可見,三個相關任務共同學習的模型優于兩個相關任務共同學習的模型,更進一步驗證了多任務學習的有效性。
總體來看,多任務學習比起單任務學習在精確率上有較大的提升,驗證了多任務學習在方面級情感分析任務上的有效性。
3.2.2方面詞項重建輔助任務的影響
由表3可見,ASA-MTL和ASA-DTL在R(ACSA)數據集上的分類精確率分別是0.856和0.850,在R(ATSA)數據集的分類精確率分別是0.780和0.773,在L(ATSA)數據集的分類精確率分別是0.697和0.690,ASA-MTL在三個數據集上的分類效果均優于ASA-DTL。可以驗證本文的三個任務的共同學習架構優于兩個任務的共同學習結構以及方面詞項重建任務的重要性。在方面類別情感分析數據集中,只有幾個預先定義的方面類別。在方面詞項情感分析數據集中,方面詞項有很多種,組成方面詞項的詞語是有限的,它們分別從屬于方面類別中的某一類別。方面詞項和方面類別對于兩個子任務能否有一個好的性能是非常關鍵的,重新構建方面詞項能夠在一定程度上確保方面特定的信息對上述兩個子任務產生積極的影響,以便對特定方面的情感傾向進行更好的預測。
4 結 語
本文提出一種基于多任務學習的方面級情感分析模型(ASA-MTL),同時學習方面級情感分析多個子任務,共享參數,促進多個任務共同學習,解決了單任務網絡不能共享每個網絡自身學習到的特征進而導致性能不佳的問題。在網絡結構中使用Sentence-level和Aspect-level兩層注意力機制對整個句子進行分析,在句子中根據不同方面捕獲不同的重要信息。添加方面詞項重建任務作為多任務結構中的輔助任務,確保方面信息能更好地發揮作用。在SemEval數據集上進行的實驗驗證了本文模型的性能相比其他基線模型有所提升。另外,一些詞在不同的領域表達的情感極性不同,因此領域特定的情感詞典對于方面級情感分析任務是非常關鍵的。在未來的工作中,將嘗試構建領域特定情感詞典,充分利用情感語言學知識進一步提高情感分析的效果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中國生殖健康(2020年5期)2021-01-18 02:59:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
電子制作(2018年18期)2018-11-14 01:48:24
中國生殖健康(2018年5期)2018-11-06 07:15:40
山東工業技術(2016年15期)2016-12-01 05:31:22
