基于可信列表的改進拜占庭容錯算法
2022-02-19 10:24:20湯紅波王領偉
計算機應用與軟件 2022年2期
喬 康 湯紅波 游 偉 王領偉
(解放軍戰略支援部隊信息工程大學 河南 鄭州 450053)
0 引 言
共識算法是區塊鏈的核心技術之一[1],是確保所有節點(包括普通節點和處理交易的節點)彼此同步,并就交易的合法性和區塊的上鏈達成一致的協議。迄今為止,研究者已就區塊鏈的共識算法做了大量研究工作,提出了多種多樣的共識算法[2~10],如工作量證明(PoW)[2]、權益證明(PoS)[3]、股份授權證明(DPOS)[4]和實用拜占庭容錯(PBFT)[5]等。由于特別適合聯盟鏈的應用場景,PBFT算法及其改進算法是目前最常用的聯盟鏈共識算法[11]。
盡管采用PBFT算法后聯盟鏈的共識效率得到極大提升,但PBFT算法仍然存在通信開銷大的問題[12]。隨著網絡節點數目N的增加,其通信量將呈平方級O(N2)增長,當節點數目超過一定值后,由于網絡帶寬的限制,將造成通信瓶頸,進而導致PBFT算法性能的顯著下降。
因此,為減少通信開銷,許多研究在保證安全的前提下,以選舉方式挑選少量節點參與共識[13]。Crain等[14]借鑒PoS算法思想對PBFT算法進行改進,提出DBFT算法,根據節點權益值來選舉主節點和副本節點;Agarwal等[15]結合PoW算法,提出改進算法Elastico,由普通節點相互競爭當選;Chen等[16]則利用密碼抽簽協議,提出改進算法AlgoRand,隨機選舉共識節點; Copeland等[17]結合Raft算法,對PBFT算法進行改進,提出更簡潔的Tangaroa算法。
通過選舉少量共識節點將減少節點間通信次數,從而降低開銷和時延。但是,現有算法仍存在以下不足,一是靈活性差,共識節點數目固定,節點身份提前確定,無法動態添加或刪除;二是容錯率低,系統的故障節點數量不得超過全網節點的1/3,導致容錯率相對較低;三是資源耗費高,無法避免故障節點的存在,造成通信資源的浪費和算法耗時的增加。
針對上述不足,本文提出了一種基于可信列表的改進拜占庭容錯算法(CPBFT),主要的改進包括:(1) 建立一個信用節點列表。該信用節點列表有兩方面作用,一是將共識節點的參與方式由靜態改進為動態,節點可動態進入或退出;二是支持通過投票選出信任節點,在投票周期內,網絡中的所有參與節點均可進行投票,獲得票數最多的前位節點組成一個信任節點列表,該列表將作為共識節點的候選列表。(2) 設計一種信用評價機制。該機制是共識節點選舉的依循,包括信用值計算模型和節點選舉策略。通過該機制,可從信用節點列表中,選舉出可信的共識節點(主節點和副本節點)。可信的共識節點,將提升系統容錯率,降低資源開銷。(3) 簡化算法流程。基于信用評價機制,確保了共識節點的可信度,由此將PBFT算法的三階段協議簡化為二階段協議,進一步減少通信開銷、降低算法時延。
1 實用拜占庭容錯(PBFT)算法
為解決存在節點故障情況下的共識達成問題,1982年Lamport等提出了拜占庭容錯算法(Byzantine Fault Tolerance,BFT)。但是,長期以來,BFT算法及其改進算法都存在復雜度過高的問題。直到1999年,Castro等[5]提出實用拜占庭容錯算法(PBFT),將算法復雜度從指數級降到多項式級,使得拜占庭容錯算法在實際應用中變得可行。PBFT算法可以在故障節點不超過節點總數1/3的情況下同時保證共識的安全性和靈活性[18]。PBFT算法的執行流程如圖1所示,其包括請求過程、廣播過程和響應過程三個過程。
(1) 請求過程。請求過程包括選主和請求兩個步驟,首先通過輪換或者隨機算法選擇某個節點為主節點,然后由客戶端向主節點發送請求消息〈〈REQUEST,operation,timestamp,client〉,σc〉,此后只要主節點不切換,就稱為一個視圖。
(2) 廣播過程。主節點收集請求消息,經檢查后向所有其他副本節點廣播該請求消息。
(3) 響應過程。所有節點處理完請求后,將處理結果〈REPLY,view,timestamp,client,id_node,response〉返回客戶端。客戶端統計收到的處理結果,當接收到至少f+1個(f為可容忍的拜占庭節點數目)來自不同節點的相同結果時,該處理結果為最終結果。
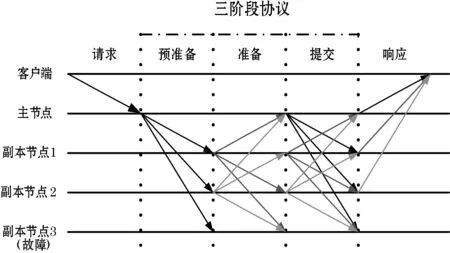
圖1 實用拜占庭容錯算法的執行流程
其中,主節點廣播過程包括三個階段,分別為預準備階段、準備階段和提交階段。
① 預準備階段。主節點首先為客戶端的請求分配編號,然后向各副本節點發送預準備消息〈〈PRE-PREPARE,view,n,digest〉,σp,message〉,其中view是視圖號,n是提案號,message是請求消息,digest是消息的數字摘要。
② 準備階段。副本節點首先驗證預準備消息的合法性,通過驗證后向其他節點發送準備消息〈〈PREPARE,view,n,digest,id〉,σi〉,其中id為副本節點的身份證明。副本節點在發送準備消息的同時,也接收其他節點的準備消息。準備消息驗證后,則被添加到消息日志中,當接收到至少2f個驗證過的準備消息后,節點進入準備階段。
③ 提交階段。節點廣播確認消息〈〈COMMIT,view,n,digest〉,σi〉,通知其他節點某個提案n在視圖view中已處于準備階段,當接收到至少2f+1個驗證過的COMMIT消息后,說明提案通過。
2 算法設計
2.1 信任節點列表建立
如圖2中第一部分所示,在投票周期T內,區塊鏈網絡中的所有節點i均可參與投票,通過統計各節點得票數目ni,獲得票數最多的前h位節點,排序組成一個列表作為信用節點列表。投票提案vote由系統每隔一段時間發起,首先,投票主節點向普通投票節點廣播投票準備消息PREPAREvote;其次,投票節點自由投票并將投票結果RESULTvote回復主節點;最后,由投票主節點統計得票結果并廣播給所有節點。信任節點列表的建立主要依賴投票制度,其前提假設為區塊鏈網絡中的大部分節點是合法節點。每個節點擁有一次投票機會,可選擇自己,也可選擇其他節點。信用節點列表將作為候選集,供下一步共識節點選舉使用,如圖2中第二部分所示。通過建立信用節點列表,將共識節點的參與方式由靜態改進為動態,節點可動態進入或退出,提高了節點的靈活性。
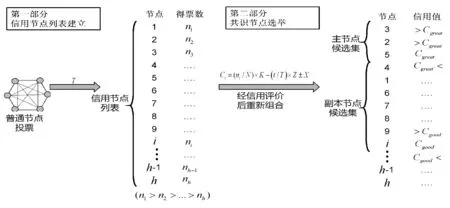
圖2 基于信用列表的共識節點選舉
2.2 節點信用評價機制
為從信用節點列表中選擇出高可信度的共識節點,本文設計了一種節點信用評價機制,該機制包括了信用值計算模型和共識節點選舉策略。
2.2.1信用值計算模型
首先,對節點信用值計算進行建模,信用值的計算分為兩種情況:一是信用獎勵,如式(1)所示;二是信用懲罰,如式(2)所示。
Ci=(ni/N)×K-(t/T)×Z+X
(1)
Ci=(ni/N)×K-(t/T)×Z-X
(2)
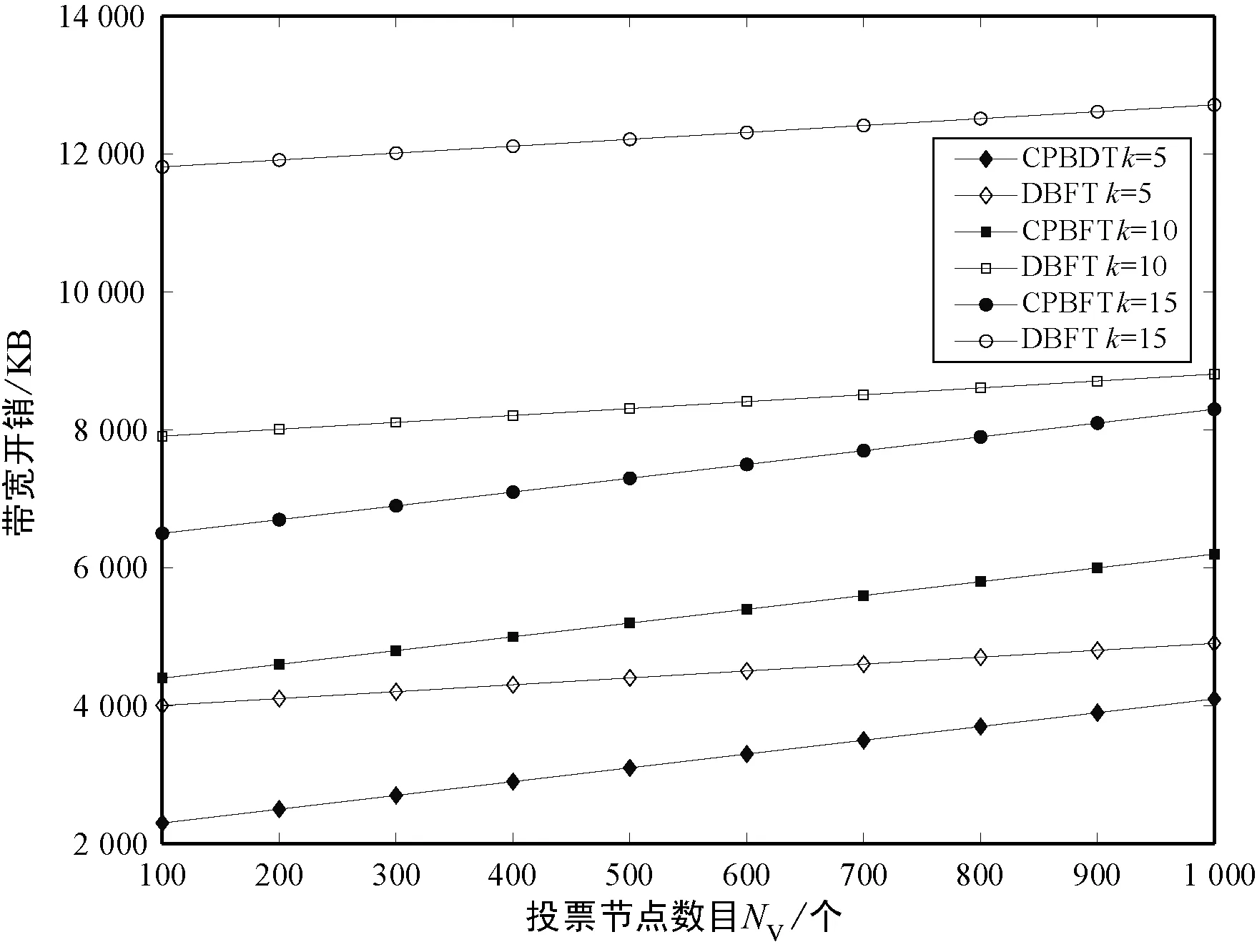
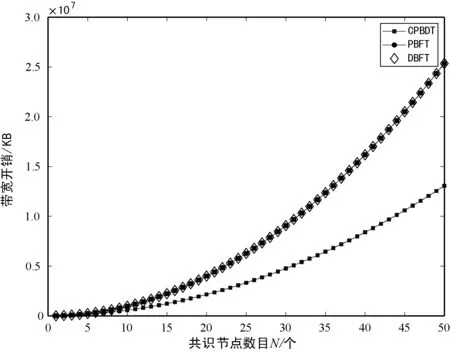
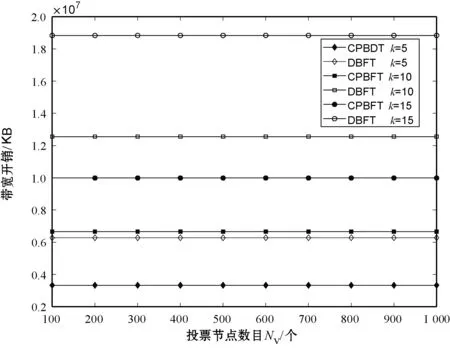
式中:Ci代表節點i的信用值;ni代表節點i獲得的投票數;N代表總的投票數;K代表信用參數;t為節點添加到列表后經歷的時間(0 節點信用值計算模型的描述。節點的信用值計算模型由三部分組成:初始信用值Cinit,Cinit=(ni/N)×K,由節點的初始得票情況決定;信用衰減值Cfall=(t/T)×Z,在一輪投票周期T內,隨著時間t的增加,節點信用值將不斷衰減;信用獎懲值Cmotiva=X,如果節點作為共識節點成功完成一輪共識,則獲取信用值獎勵,增加X,如果節點在共識中出現故障,則受到懲罰,減少X。根據實際的共識算法要求,設置合理的參數,可以建立合適的節點信用值計算公式。 2.2.2共識節點選舉策略 經信用值計算得出節點信用值后,通過以下策略為節點劃分信用等級,并選舉出可信共識節點: (1) 當節點i的信用值Ci≥Cgreat時,將該節點劃分為高信用等級節點。然后,將節點i添加到主節點的候選集,如果每次共識主節點的數目需求為1個,則將候選集中的節點按照信用值大小排序,輪流擔任主節點; (2) 當節點i的信用值Cgood≤Ci (3) 當節點i的信用值Ci 此外,為激勵節點參與維護區塊鏈,本文設置經濟激勵措施來回饋共識節點的工作。每筆交易會按照比例收取一定的服務費,作為獎勵金。共識完成后,所有共識節點(主節點和副本節點)均分50%的服務費,負責成塊的主節點額外獲得剩余50%的服務費。為最大化收益,參與節點會盡可能提高信用值,以增大成為主節點的幾率。該方式利用經濟博弈論思想來降低節點作惡風險。 通過節點信用評價機制,可從信用節點列表中,選舉出可信的共識節點(主節點和副本節點)。可信的共識節點,將提升系統容錯率,降低資源浪費。 基于上述方法,本文提出基于可信列表的改進拜占庭容錯算法(CPBFT)。與PBFT算法不同,CPBFT算法的執行流程包括選舉過程和共識過程,如圖3所示。 圖3 CPBFT共識算法的執行流程 值得注意的是:(1) CPBFT算法的選舉過程并非每輪共識前都進行,而是在一輪投票周期內執行一次選舉,然后支持多輪共識;(2) CPBFT算法的共識過程由PBFT算法的三階段協議簡化為二階段協議。 算法1CPBFT共識算法 開始 選舉過程 1.clientvote→primnodevote:〈〈REQUESTvote,operation,timestamp,client〉,σvc〉 //投票請求 2.primnodvote→nodevote:〈〈PREPAREvote,vote,digest〉,σvp,messagevote〉 //投票準備 3.IfHash(messagevote)=digest //投票消息校驗 4.nodevote→clientvote:〈〈REPLYvote,vote,digest2,id〉,σvi,messagereply〉 //投票響應 5.IfHash(messagereply)=digest2 //響應消息校驗 6.clientvote→primnodevote:〈〈RESULTvote,vote,digest3,client〉,σvcl,messageresult〉 //共識過程 7.clientcon→primnodecon:〈〈REQUESTcon,operation,timestampcon,clientcon〉,σc〉 //共識請求 8.primnodecon→replica:〈〈PRE-PREPAREcon,view,n,digestcon〉,σp,messagecon〉 //預準備 9.IfHash(messagecon)=digestcon //共識消息校驗 10.replica→primnodecon,replicai:〈〈COMMITcon,view,n,digestcon〉,σi〉 //提交 11.primnodecon,replica→clientvote: 〈〈REPLYcon,view,timestampcon,clientcon,id_node,response〉,σi〉 結束 CPBFT算法的選舉過程包括投票請求、投票準備、投票響應和廣播結果四個階段。 (1) 投票請求階段。客戶端向投票主節點發送請求消息〈〈REQUESTvote,operation,timestamp,client〉,σvc〉,其中:client是請求投票的客戶端號,timestamp是申請投票的時間,σvc是投票客戶端對消息的簽名。 (2) 投票準備階段。投票主節點首先為客戶端的投票請求分配編號,然后向各普通節點發送投票準備消息〈〈PREPAREvote,vote,digest〉,σvp,messagevote〉,其中:vote是提案號,messagevote是投票請求消息,digest是請求消息的數字摘要,σvp是投票主節點對消息的簽名。 (3) 投票響應階段。普通節點首先驗證投票準備消息的合法性,通過驗證后向客戶端發送投票響應消息〈〈REPLYvote,vote,digest2,id〉,σvimessagereply〉,其中,id是各節點的身份證明,messagereply是投票響應消息,digest2是響應消息的數字摘要,σvi是普通投票節點對消息的簽名。 (4) 廣播結果階段。客戶端驗證投票響應消息的非法性,通過驗證后向各節點(包括投票主節點和普通節點)發送投票結果消息〈〈RESULTvote,vote,digest3,client〉,σvc1,messageresult〉,其中:messageresult是投票結果消息,digest3是結果消息的數字摘要,σvc1是投票客戶端對投票結果消息的簽名。 CPBFT算法的共識過程包括請求、預準備、提交和響應四個階段。 (1) 請求階段。客戶端向共識主節點發送請求消息〈〈REQUESTcon,operation,timestampcon,clientcon〉,σc〉,其中:clientcon是請求共識的客戶端號,timestampcon是申請共識的時間,σc是客戶端對消息的簽名。 (2) 預準備階段。主節點首先為客戶端的請求分配編號,然后向各副本節點發送預準備消息〈〈PRE-PREPAREcon,view,n,digestcon〉,σp,messagecon〉,其中:view是視圖號,n是提案號,messagecon是共識請求消息,digestcon是消息的數字摘要,σp是主節點對消息的簽名。 (3) 提交階段。副本節點首先驗證預準備消息的合法性,通過驗證后,副本節點廣播〈〈COMMITcon,view,n,digestcon〉,σi〉消息,通知其他節點某個提案n在視圖view中已處于準備階段,當接收到至少2f+1個驗證過的COMMITcon消息后,說明提案通過。 (4) 響應階段。所有節點處理完請求后,將處理結果〈〈REPLYcon,view,timestampcon,clientcon,id_node,response〉,σi〉返回客戶端,其中:id_node是節點編號,response是節點回復,σi是節點對消息的簽名。客戶端統計收到的處理結果,當接收到至少f+1個來自不同節點的相同結果,則該結果作為最終結果。 為綜合評價CPBFT共識算法的性能,以交易吞吐量、交易時延和通信帶寬開銷三個指標為衡量標準,進行仿真實驗。其中吞吐量是衡量算法執行效率的指標,時延是衡量算法響應能力的指標,帶寬開銷是衡量算法通信復雜度的指標。 吞吐量是指每秒完成的交易數,定義吞吐量的計算式為: TPS=SizeBlock/SizeTx/Tblock (3) 式中:TPS代表吞吐量;SizeBlock代表區塊的存儲容量;SizeTx代表交易的大小;Tblock代表成塊的時間,即共識達成的時間。以比特幣的工作量證明算法(PoW)為例,成塊時間約為10分鐘,在現有的大多數區塊鏈平臺中,區塊的存儲容量約為1 MB,交易的大小約為250 B,因此,比特幣的交易吞吐量TPS約為7筆/秒。 對于單筆交易,時延是指請求時間(t1)和共識完成時間(t2)的差值(t2-t1)。對于一組交易,時延是指一組交易中第一筆交易的請求時間和最后一筆交易共識完成時間的差值,即最大單筆交易時延。 為評價CPBFT算法的吞吐量和時延情況,在配置為Intel Core i7-6700M @3.40 GHz處理器和16 GB內存,安裝了64位Windows 7系統的PC,通過Eclipse2018平臺用Java語言編程實現了PBFT和CPBFT算法,并進行了時延和吞吐量測試。其中,PBFT算法的實現與測試利用了Github平臺上的pbftSimulator項目所共享的部分代碼。每組實驗獨立運行10次并求平均值作為測試結果,主要參數設置如表1所示。 表1 吞吐量和時延實驗參數表 圖4展示了吞吐量和交易數量的關系,隨著交易數量的增加,除在交易數為7 000時有拐點外,兩個算法的吞吐量整體均呈線性增加趨勢。當交易數量小于100時,CPBFT算法的吞吐量小于PBFT算法;當交易數量大于1 000時,CPBFT算法的吞吐量大于PBFT算法,且隨著交易數量增加,吞吐量差值逐漸增大。 圖4 吞吐量和交易數量的關系 在不考慮時延的情況下,討論吞吐量是不嚴謹且無意義的,并且時延也是衡量算法響應能力的指標,因此本文還測試了時延和交易數量的關系,結果如圖5所示。可以看出,隨著交易數量的增加,兩個算法的時延均呈線性增加,且當交易數小于100時,CPBFT算法的時延大于PBFT,當交易數大于1 000時,CPBFT算法的時延小于PBFT算法。 圖5 時延和交易數量的關系 由圖4和圖5可見,隨著交易數量的增加,吞吐量和時延均呈線性增加,但是在實際的聯盟鏈應用中,一般要求時延小于3秒。由圖5可知,3秒時延對應的交易數量約為4 000筆;再由圖4可知,4 000筆交易對應的吞吐量約為1 400筆/秒。因此,基于實際應用考慮,討論CPBFT和PBFT算法的吞吐量和時延比較,應限制在時延小于3秒和交易數低于4 000筆的范圍內。在本文實驗條件下,當交易數為4 000時,CPBFT算法的時延為2 812 ms,PBFT算法的時延為2 900 ms;CPBFT算法的吞吐量為1 422筆/秒,PBFT算法的吞吐量為1 379筆/秒。此時,相較于PBFT算法,CPBFT算法的吞吐量提升了約3.12%,時延降低了約3.03%。 CPBFT算法的執行選舉和共識過程均產生通信帶寬開銷。其中,選舉過程包括投票請求、準備、響應和廣播結果四個階段,共識過程包括請求、預準備、提交和響應四個階段,定義其帶寬開銷為: Bandwithcpbft=k×[1+(N-1)+N×(N-1)+N]×message+ [1+(NV-1)+NV+NV]×Vote= k×(N2+N)×message+3NV×Vote (4) 式中:Bandwithcpbft為通信帶寬開銷;N為總的共識節點數目;NV是總的投票節點數目(NV?N);message為驗證消息;Vote為投票消息;k為一輪投票周期內執行的共識次數。 將CPBFT算法應用于區塊鏈中,共識過程驗證的消息為區塊數據(SizeBlock),選舉過程傳遞的數據為投票數據(Vote),SizeBlock?Vote,此時帶寬開銷為: Bandwithcpbft=k×(N2+N)×SizeBlock+3NV×Vote (5) 同理,PBFT[19]算法僅執行共識過程,包括請求、預準備、準備、提交和響應五個階段,定義其帶寬開銷為: Bandwithpbft=k×[1+(N-1)+(N-1)×(N-1)+ N×(N-1)+N]×message= k×(2N2-2N+N+1)×message (6) 將PBFT算法應用于區塊鏈中,帶寬開銷為: Bandwithpbft=k×(2N2-2N+N+1)×SizeBlock (7) DBFT[22]算法執行選舉和共識兩個過程,選舉過程包括廣播節點身份一個階段,共識過程包括請求、預準備、準備、提交和響應五個階段,定義其帶寬開銷為: Bandwithdbft=k×(2N2-2N+N+1)× message+NV×Vote (8) 將DBFT算法應用于區塊鏈中,帶寬開銷為: Bandwithdbft=k×(2N2-2N+N+1)× SizeBlock+NV×Vote (9) 其中,由于廣播節點身份的數據量和投票的數據量大致相當,為便于對比,本文用投票數據Vote替代廣播節點身份的數據。 為評價CPBFT算法通信帶寬開銷情況,在相同配置的計算機上進行仿真,通過MATLAB 2018a對CPBFT、PBFT和DBFT共識算法進行數學計算仿真,參數設置如表2所示。 表2 帶寬開銷實驗參數表 第一組仿真是為比較不同算法的帶寬開銷情況。圖6展示了不同算法的帶寬開銷和共識節點數目的關系,該實驗中固定NV=1 000,k=5。隨共識節點數目的增加,三種算法的帶寬開銷均呈指數遞增,且CPBFT算法的增長率較小,PBFT和DBFT算法的增長率相近且較大;在共識節點數少于15時,算法帶寬開銷由大到小排序為CPBFT算法、DBFT算法、PBFT算法,這是由于CPBFT和DBFT算法與PBFT算法相比,增加了選舉過程的通信開銷;當共識節點數目大于25后,算法帶寬開銷由大到小排序為DBFT算法、PBFT算法、CPBFT算法,且PBFT算法帶寬開銷有超越DBFT算法的趨勢。在本文實驗條件下,當節點數目為50時,PBFT算法的帶寬開銷約為2.576×104KB,DBFT算法的帶寬開銷約為2.476×104KB,CPBFT算法的帶寬開銷為1.475×104KB,此時,CPBFT算法較PBFT算法帶寬開銷下降了約42.74%,較DBFT算法帶寬開銷下降了約40.43%。可以得出,在共識節點數目較多的情況下,CPBFT算法具有更低的帶寬開銷。 圖6 通信帶寬開銷和共識節點數目的關系 圖7展示了在不同共識執行次數k下,帶寬開銷和投票節點數目的關系,該實驗中固定N=20。當執行次數k相同時,隨投票節點數目的增加,CPBFT和DBFT算法的帶寬開銷均呈線性增加,且CPBFT算法的增長率更大;當投票節點數目NV相同時,隨執行次數k的增加,CPBFT和DBFT算法的帶寬開銷均增加,且DBFT算法增長幅度更大。可以得出,CPBFT算法的帶寬開銷受投票節點數目的影響更大,DBFT算法的帶寬開銷受執行次數的影響更大。 圖7 通信帶寬開銷和投票節點數目的關系 第二組測試是為比較不同算法應用于區塊鏈中時的帶寬開銷情況。應用于區塊鏈時,共識是以包含多條交易的一個區塊為最小單元進行的,這不同于第一組實驗中以一條交易為最小單元的共識過程,其測試結果如圖8所示。圖6和圖8變化趨勢相似,不同點在于PBFT和DBFT算法的曲線幾乎重合,而CPBFT算法的曲線一直處于兩者的下方。在本文實驗條件下,當節點數目為50時,PBFT和DBFT算法的帶寬開銷相近且約為2.535×107KB,CPBFT算法的帶寬開銷約為1.306×107KB,此時CPBFT算法較PBFT和DBFT算法的帶寬開銷下降了約48.48%。 圖8 通信帶寬開銷和共識節點數目的關系(應用于區塊鏈) 圖9所示為應用于區塊鏈時通信開銷和投票節點數目的關系。圖7和圖9差別在于,當執行次數相同k時,隨投票節點數目NV的增加,帶寬開銷幾乎不變。這是由于共識過程驗證的消息為區塊數據SizeBlock,其數據量遠大于投票消息message的數據量,相較于共識過程,投票過程的帶寬開銷占比極小。 圖9 通信帶寬開銷和投票節點數目的關系(應用于區塊鏈) 由上述仿真結果可以得出,相較于PBFT和DBFT算法,CPBFT算法具有更低的通信帶寬開銷。 本文針對PBFT算法存在的靈活性差、容錯率低和資源耗費高的不足,提出了一種基于可信列表的改進拜占庭容錯算法。首先,建立了一個信用節點列表,將共識節點的參與方式由靜態改進為動態,節點可動態進入或退出;其次,設計了一種節點信用評價機制,作為共識節點選舉的依循,提升了系統容錯率;最后,基于信用評價機制,將PBFT算法的三階段協議簡化為二階段,進一步減少了通信開銷、降低了算法時延。區塊鏈作為一種公開的賬本系統,交易信息被收集并詳細記錄其中,任何參與者都可以查詢鏈上信息,故其面臨嚴重的隱私泄露風險。下一步將重點研究區塊鏈隱私保護問題。2.3 改進共識算法
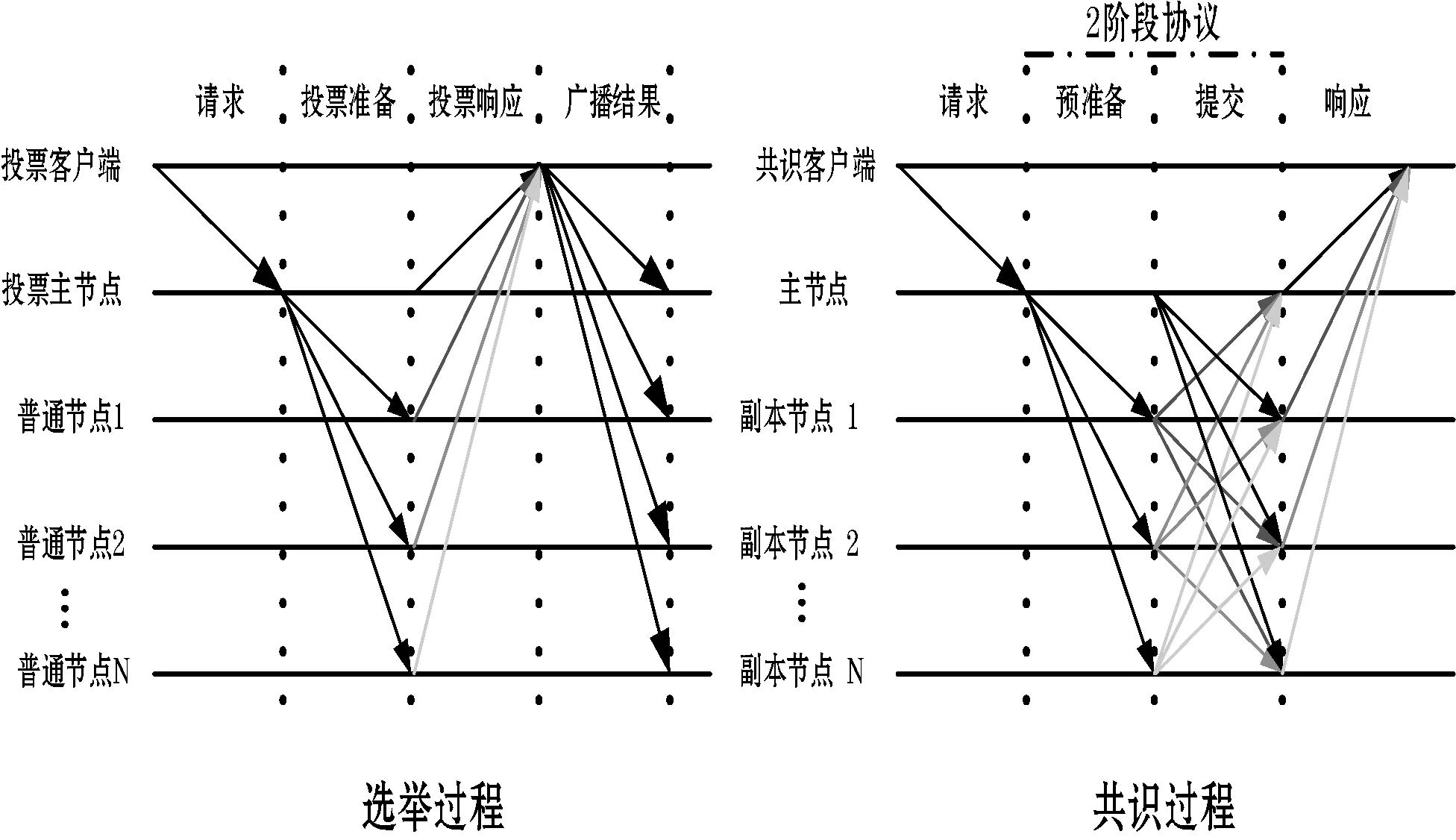
3 仿真分析
3.1 吞吐量和時延分析
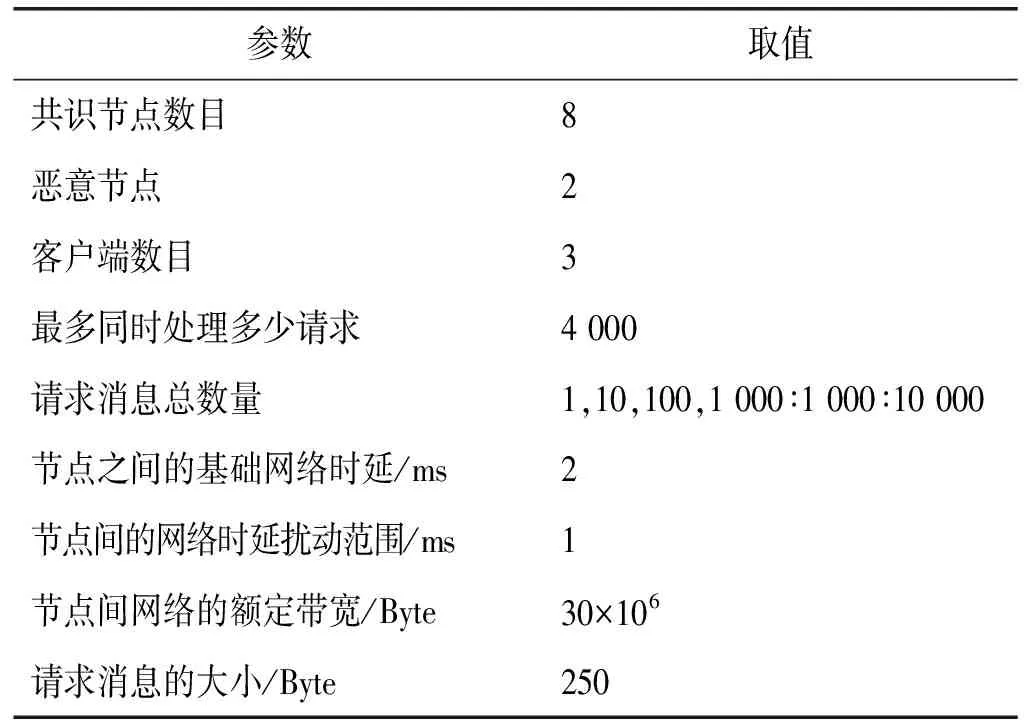
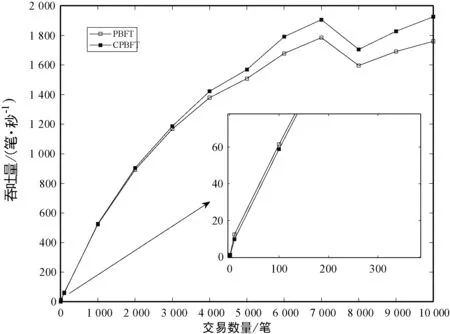
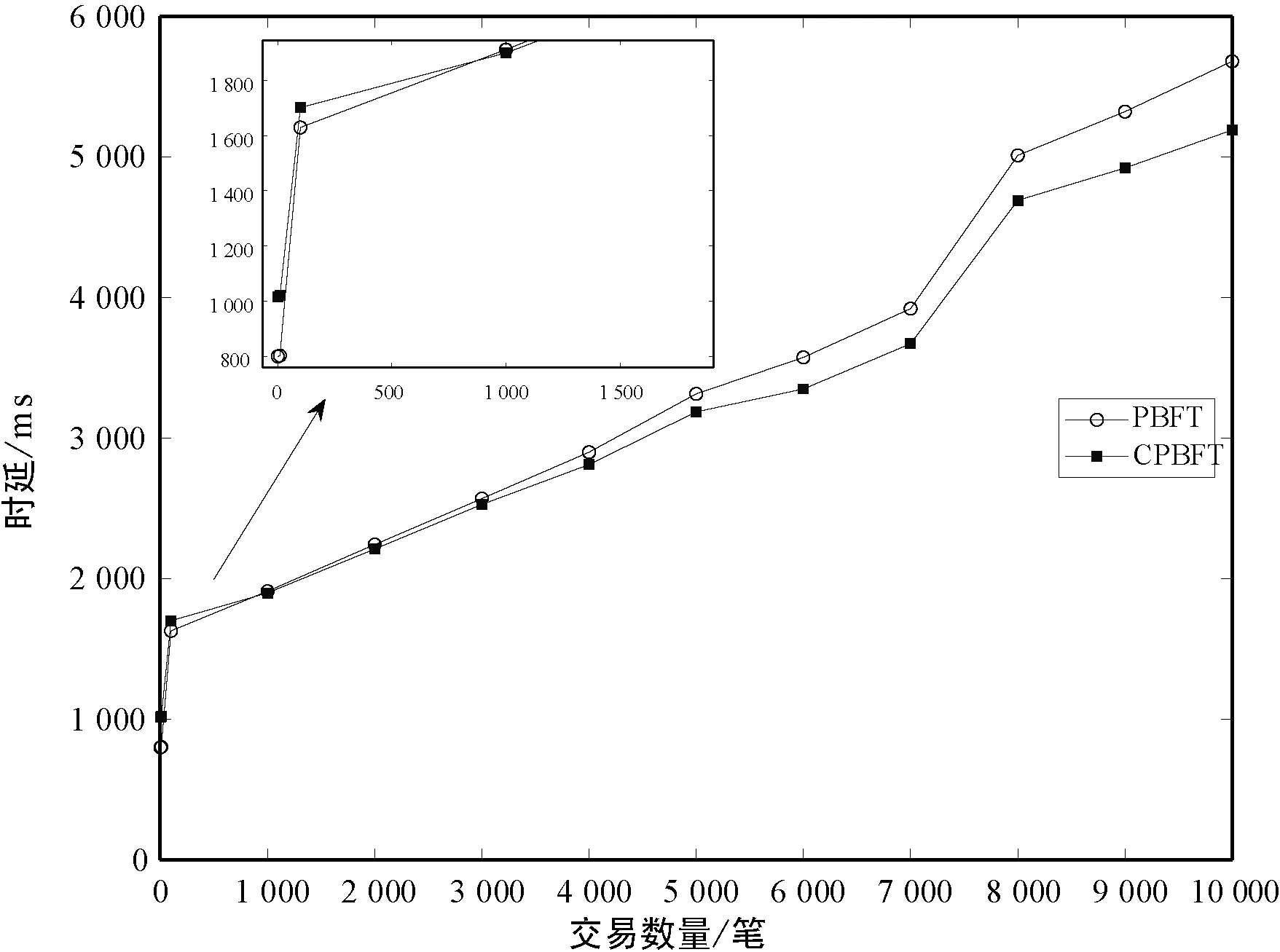
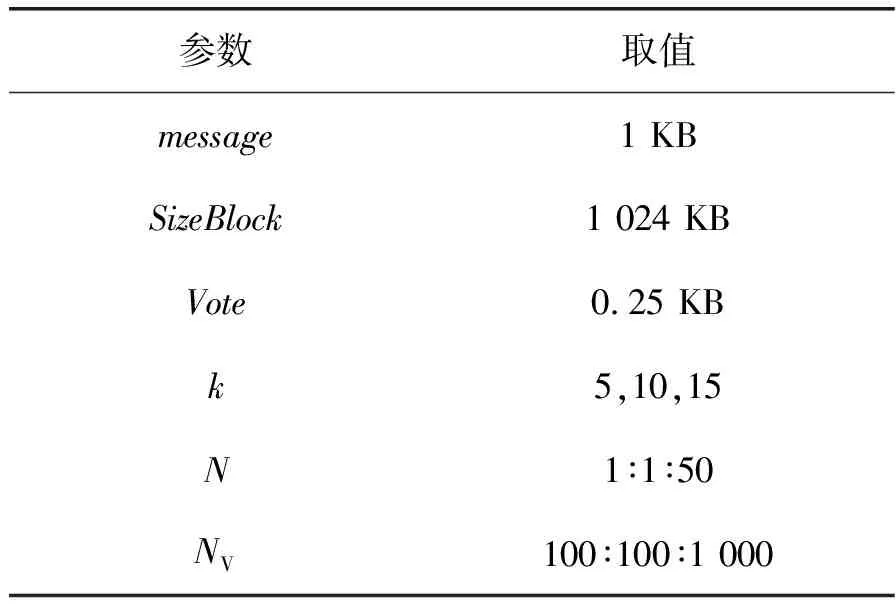
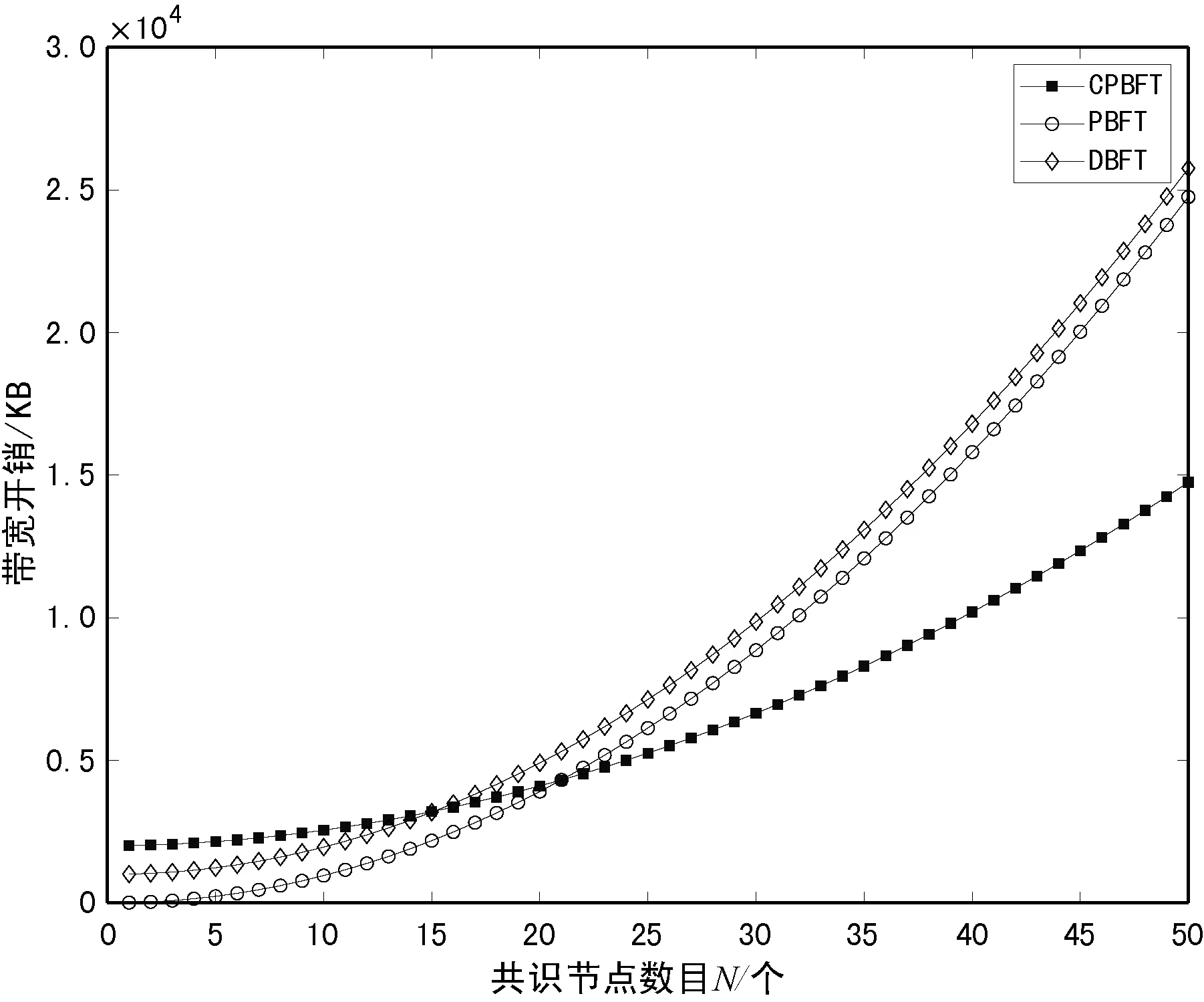
3.2 通信帶寬開銷分析
4 結 語
