大數據是對傳統經濟學研究范式的顛覆嗎?
2022-02-19 01:20:18劉寬斌
重慶理工大學學報(社會科學) 2022年1期
劉寬斌,張 濤
(1.西南大學 經濟管理學院, 重慶 400716; 2.中國社會科學院 數量經濟與技術經濟研究所, 北京 100735)
一、引言
現代科技技術的進步不僅改變了人類生產、生活的方式,也改變了人類認識事物的方式。近年來,隨著計算機技術以及互聯網技術的飛速發展,人類能存儲下來的數據信息量出現了爆炸式的增長。互聯網出現之前,人類存儲數據信息最方便也最常用的方式是書籍。據國際數據公司(IDC)的研究報告顯示,截止到2012年,人類所有印刷材料所記錄的數據信息總量為200PB ,而在互聯網時代,僅2008年一年產生的數據信息量就高達0.49ZB,并且數據信息量的產生呈現加速趨勢,2009年產生了0.8ZB的數據,2010年為1.2ZB,到2011年就達到1.82ZB(1)https://www.idc.com/.。據2017年IDC的研究報告估計,到2025年人類產生的數據信息量將高達163ZB,將比2016年創造的數據信息量增加10倍(2)數據來源于IDC 2017年發布的白皮書《數據時代 2025》。。互聯網時代不僅數據信息量出現高速增長,參與數據信息創造和使用的群體或對象也發生了改變。在人類還處于印刷時代時,被記錄下來的數據信息源頭只能是那些能夠寫書的個人或有出版書籍能力的單位以及其他愿意用紙質文件記錄信息的群體,這一記錄數據的方式很大程度上限制了數據信息源。社會中的廣大普通成員及企業單位產生的、無法用紙質文件記錄的信息均被遺失,這些信息都是描述整個社會運行狀況信息的組成部分,但受限于條件,均無法被保存下來。進入當前計算機和互聯網的時代,普通個人能通過互聯網與他人分享生活狀況,對社會事件表達自己的看法;工廠企業已經在一定程度上實現了電子化,甚至信息化,能夠被記錄的不僅僅是企業的財務狀況、人員變動等基礎信息,還能記錄企業工廠機器運行信息等,所有的這些信息均被存儲在互聯網平臺或者企業的數據庫中并被長期保存。這類信息量巨大、數據源頭廣泛的數據信息被稱為“大數據”。
大數據對人類生產生活產生了巨大的影響,也給研究人類社會經濟規律的經濟學帶來改變。大數據可以從以下3個方面給經濟學問題研究帶來較大影響:檢驗當前經濟理論的正確性、提供識別此前不能被識別的影響因素、提供經濟理論新見解[1]。當前大數據,特別是網絡大數據已經開始被應用到經濟問題的分析當中,主要包括失業率、通貨膨脹、社會宏觀經濟消費量、房地產市場、選舉、社會輿情分析以及國內生產總值(GDP)等問題的研究[2]。雖然大數據已經在眾多經濟學領域開始被應用,但當前對大數據應用于經濟學領域的研究范式問題卻缺乏探討,導致當前大多使用大數據分析經濟學問題時缺乏理論依據,最終的研究結論也難以從經濟學的角度來解釋。
本研究試圖從網絡大數據的角度探討大數據的概念、特點,分析大數據應用于經濟學研究時與傳統統計數據的區別以及大數據本身具有的優勢,總結當前大數據應用于經濟學分析過程中存在的問題,并在以上分析基礎上探討大數據應用于經濟學分析時的范式問題,為大數據應用于經濟學分析的研究范式提供思考。
二、大數據概念發展
為分析大數據在經濟學中的應用范式,首先需要清晰界定大數據的概念并且總結出大數據相比于傳統的統計數據所具有的獨特優勢。大數據是當前研究的熱點,但關于大數據的概念或定義卻難以統一。為分析大數據的概念、特點,本文從大數據的概念演進的角度來分析。大數據的概念有一個逐步發展的過程,不同時期、不同學者從各自不同研究領域提出了不同的見解。
最初,大多數學者對大數據的界定是從計算機技術角度來描述,重點關注大數據信息的體量,強調大數據信息難以被當時的計算機處理和分析。例如,2013年來自亞馬遜公司的數據科學家約翰·老薩(John Rauser)在一次計算機研討會上將大數據描述為“超過一臺計算機處理能力的數據量”(3)https://www.networkworld.com/article/2188435/defining-big-data-depends-on-who-s-doing-the-defining.html.,這樣的定義方式局限于大數據“量級大”特點。另外,日本野村綜合研究所研究員城田真琴在其文章中將大數據定義為“用當期企業數據庫中占主流地位的關系型數據庫無法進行管理的、具有復雜結構的數據”[3]。該定義增加了數據的“響應時間”,認為大數據是數據量巨大,導致數據查詢時間超過了容忍范圍的數據集合。中國工程院院士李國杰也有過類似表述[4]。全球著名的管理咨詢公司,也是世界上首次系統闡述大數據概念和應用的公司麥肯錫(McKinsey)定義大數據為:數據量大小超過典型數據庫軟件采集、存儲、管理和分析等能力的數據集[5]。研究機構高德納(Gartner)認為大數據需要新的處理模型才能增強決策力、洞察力、優化分析能力的高增長和多樣化的信息資產(4)https://www.gartner.com/en/information-technology/glossary/big-data.。約翰·沃克(John Walker S)通過“4V”特征來定義大數據,認為大數據信息應該滿足數據量巨大(Volume)、數據處理速度極快(Velocity)、數據形式多種多樣而不局限于結構化的數據信息(Variety),有價值的信息隱含在海量的數據信息中,需要通過數據挖掘的技術方法提取出來(Value)[6]。維基百科中對“大數據”的定義是:利用傳統的計算機和方法來管理、處理消耗的時間超過可接受范圍的數據集。
國內學者對大數據的概念也有所闡述。《大數據時代的歷史機遇》一書作者認為大數據是指“在多樣的或者大量數據中,迅速獲取信息的能力”[7]。中科院院士徐宗本認為,大數據是指不能夠集中存儲,并且難以在可接受的時間內分析處理的數據,其中個體和部分數據呈現低價值性而整體呈現高價值的海量復雜數據集[8]。中國通訊院(CAICT)在發布的《大數據白皮書(2016)》(5)http://www.cac.gov.cn/2016-12/28/c_1121534609.htm.中給大數據的定義是“復雜混合體的認知理念”。
在此,可以將關于大數據概念的不同闡述總結如表1。

表1 關于大數據概念的主要表述
通過以上對大數據概念的梳理可以看到,不同的機構和研究者對大數據的理解存在一定的差異,但均是從技術角度來界定,強調大數據信息體量超過了傳統計算機技術處理能力范圍。也有從價值角度來理解大數據概念的觀點,主要的觀點總結如表2。

表2 大數據概念外延
學者對大數據的概念外延表述時更多強調大數據的價值,認為大數據的核心在于能夠創造價值,而不是數據集本身。
通過這些專家和學者對“大數據”的描述或界定發現能被視為“大數據”的數據信息應該具有如下特點:
(1)數據體量大。傳統統計方法收集的數據信息量一般為KB級、MB級,而大數據的信息量在GB級以上,甚至是TB、PB、EB級別的數據信息。
(2)傳統計算機在可接受的時間內無法處理。傳統計算機計算能力有限,面對巨量的數據信息,無法有效勝任分析處理工作。
(3)數據信息多樣性。傳統的統計數據一般為截面數據、時間序列數據或面板數據,歸結起來都是結構化的數據信息,而大數據的數據信息擴展了范圍,不僅包括結構化的數據,還包含文本、圖片、語音、視頻、網絡搜索、日志信息、URL等。
(4)高價值,但價值密度低。一堆無用的,對增強認識事物能力無幫助的數據是不能稱之為“大數據”的,高價值體現在“大數據”蘊含的信息能夠提供傳統數據不能提供的精準信息,但是由于數據量巨大,單個樣本或數據單元提供的價值信息降低,只能通過海量的數據分析才能提取出完整的價值信息。
三、大數據在經濟學應用中的優勢
當前,應用于經濟學研究的大數據信息主要來源為網絡大數據,包括百度搜索指數[12-13]、微博[14-15]、網絡新聞信息[16-17]等。基于此,本研究以網絡大數據為主要分析對象,介紹網絡大數據在經濟學研究中的優勢。網絡大數據是指通過網絡平臺匯聚的數字、文本、圖片、語音、視頻等各類信息,這些數據信息具有能被數據提供者以外的人通過網絡平臺及時獲取的可能,是極度分散又涵蓋范圍極廣的超大數據集。相比于傳統統計數據,這類大數據信息具有如下獨特的屬性:
(1)時效性極強。通過互聯網平臺積累起來的數據信息存儲于網絡空間中,包括交易的數量、銷售的價格、發表的言論、檢索的關鍵詞等,這些信息在發生時,實時在網絡中留下記錄痕跡,可以被一定的方法和技術提取出來,用于處理和分析問題,不存在時間滯后性。這是網絡大數據與傳統統計數據之間重要的區別。
(2)數據真實性強。網絡平臺記錄下的信息是在事件發生時按照實際的發生情況自動記錄,減少了人為的干預,提供原始的數據,而非人為搜集經過處理后的數據信息,相對更加真實。這里的真實性主要是指網絡痕跡信息是真實的,被篡改的概率較小。
(3)獲取數據成本較低。由于網絡大數據信息均在事件或交易發生時自動被記錄下來,無需人為調查和搜集,通過一定的技術方法即可提取出來,并用于經濟問題的分析。基于程序化的數據搜集方式能夠極大地節約人力成本的投入,相比于傳統人工填報的方式,能夠極大壓縮數據搜集成本。
(4)數據細分度高。為了降低成本,傳統的數據搜集會盡量搜集總量數據,而非細分數據信息。網絡大數據時代,提取總量數據信息與提取細分數據信息的難度差異并不大,因此可以在不顯著增加成本的前提下,提供更加詳細和更加有意義的數據信息,這主要是由網絡數據搜集方式決定的。網絡數據信息繁雜,并且信息量巨大,數據搜集方式基本上是程序化的,利用計算機強大的數據處理能力和計算速度對數據按照設計者的思路來搜集并處理。由于所有個體微觀行為或其他標識性信息均能夠通過一定方式獲取,設計者通過修改數據搜集和處理的程序即可改變數據的搜集范圍,能夠方便地處理細分化領域的數據信息。
(5)大樣本。利用互聯網大數據信息,可以獲取總體或者接近全體的樣本信息,而非通過統計抽樣的方式獲取樣本信息來推斷總體信息。在這樣的大數據支持下,用于計算的樣本量是海量的,并且能較大程度上接近全樣本,直接獲取較為全面的數據信息。傳統統計數據受制于搜集成本,基本上會基于統計理論,設計一定的抽樣方式,從整體中獲取少量樣本數據信息,利用抽樣的樣本信息來估計整體水平。這種方式獲取的數據質量嚴重依賴于抽樣方法設計的合理性、數據采集過程的準確性以及數據分析方案的科學性,容易造成選擇性偏差、數據失真、估計誤差等問題。利用接近全樣本的數據信息能夠有效緩解上述弊端。
以上總結了網絡大數據信息的優點,這些優點能給經濟學研究帶來巨大的改變,主要體現在以下幾個方面:首先,經濟指標實時監控(Now casting)成為可能,由于大數據具有較強時效性,能夠在短時間獲取海量的實時數據,通過構建網絡大數據與經濟指標之間的聯系,能夠實現對經濟狀況的實時監控。其次,經濟運行“拐點”預測成為可能,傳統統計數據受制于滯后性問題,只能利用歷史數據來歸納經濟運行規律,利用歷史規律來預測未來,但大數據信息具有較好的時效性,能夠在更短的時間內發現經濟運行的“拐點”,并指導做出及時的調控。第三,經濟問題宏微觀一體化研究成為可能。利用傳統統計數據做經濟問題分析時,微觀數據信息無法直接用于分析宏觀經濟問題,大數據雖然獲取的是微觀個體的數據信息,但樣本量卻涵蓋了數以億計的群體(6)根據中國互聯網信息中心(China Internet Network Information Center,縮寫CNNIC)統計,截至2018年6月,我國網民規模已經達到8.02億人,相比于2017年末增加3.8%,互聯網在全國普及率高達57.7%。 另據互聯網數據研究機構We Are Social和Hootsuite共同發布的“數字2018”(Digital in 2018)互聯網研究報告顯示2017年末全球網民人數達40億人,占全球總人數的50%。,匯聚這樣的數據信息量,足以反映宏觀經濟狀況。最后,大數據信息能夠擴展經濟學研究范圍,傳統統計數據受制于數據搜集方式,難以統計全面的信息,而大數據可以更加細致地分析經濟現象,擴展經濟問題的研究范圍。
經過以上的分析可以看到,由于大數據信息與傳統統計數據存在較大的差異,在經濟問題分析時具有獨特優勢,因此能夠給經濟問題的研究帶來巨大改變。但大數據信息的出現僅是對傳統統計數據的補充,是應該融入到傳統經濟問題的研究過程當中,還是對傳統經濟問題分析范式的顛覆?當前對該問題的探討較少,但對這一問題的回答又十分重要,關系到利用大數據信息分析經濟學問題的科學性。接下來本文將就這一問題進行分析。
四、大數據對傳統經濟學問題研究的改進
當前,應用大數據分析經濟問題的研究缺乏機制分析,而機制分析對規范的經濟問題研究十分重要。本節內容首先在總結傳統經濟問題分析范式的基礎上提出應用大數據來做經濟分析的研究范式。本研究認為大數據信息應用于經濟分析,是對傳統經濟學分析方法中數據缺陷的改進,而非對傳統分析方法范式的顛覆。
(一)傳統經濟問題分析范式
傳統的經濟問題分析方法強調經濟模型背后的理論基礎,無論是統計學理論還是經濟學理論基礎,均能夠為經濟模型穩定性提供良好的支撐。傳統的經濟學研究從方法論上來說是演繹法,其基本范式為“假設—檢驗”。在具體的經濟問題研究過程中,通過已經接受的經濟規律進行經濟學邏輯推導,并基于一定的約束性條件,給出所研究的經濟問題規律認識的假說,最后利用經驗事實的數據信息來檢驗或驗證假說的成立與否。若實證檢驗結果與假說一致,則暫時接受假說關于事物關系的判斷,并指導實踐活動;否則,拒絕假說,修改假設、重新進行邏輯推導并提出新的假說,再次進行驗證分析。傳統經濟學的研究方法基于邏輯演繹推導結論,其遵循嚴格的科學規范,這種演繹推導的范式與自然科學并沒有本質的區別[18]。其基本的研究范式可以用圖1表示。
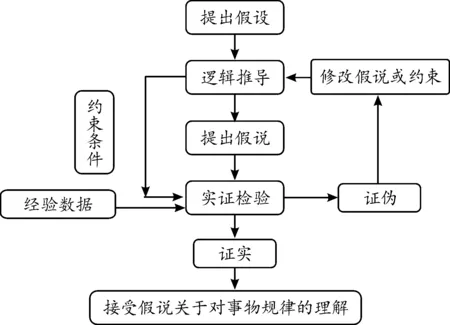
圖1 傳統經濟學研究的基本范式(7)借鑒汪毅霖[18]對經濟學研究問題范式的總結。
傳統經濟學研究方法的邏輯背景是經濟學研究可解釋性的基本要求以及傳統統計數據的有限樣本信息。首先,經濟學是研究人類經濟活動規律的學科,研究發現經濟規律,以指導經濟活動,創造價值。為了能夠指導經濟活動,經濟學的研究結論必須具有一定的理論可解釋性,若只是經驗總結,難免造成“地心說”類的錯誤判斷(8)“地心說”是古代人對觀察到的現象進行的經驗總結。,難以稱為科學;其次,由于數據采集手段以及成本的限制,傳統統計數據樣本量有限,基本依靠有限樣本來推斷總體的規律,為了實現這一目的,需要對樣本數據的統計屬性進行大量假設或限制,以滿足有限樣本能夠代表總體樣本的統計規律。
(二)大數據對傳統經濟學研究的改進作用
基于前文可知大數據信息與傳統統計數據之間存在較大差異,在分析經濟問題時具有獨特的優勢,將大數據應用于經濟問題的研究分析中應該遵循怎樣的研究范式呢?接下來將就這一問題進行探討。
維克托·麥爾-舍恩伯格(Viktor Mayer-Schonberger)的著作《大數據時代》(BigData:ARevolutionThatWillTransformHowWeLive,Work,andThink)認為在大數據時代,研究問題時不必注重數據之間的“因果關系”,而只需要關注數據之間的“相關關系”即可[6]。因此,當前許多利用大數據信息來做經濟分析或預測的研究并不探求經濟變量之間的內在邏輯聯系,而是獲取大數據信息后就直接用于模型分析,最后查看模型的效果,得出研究結論[19-24]。這種分析研究問題的方法從方法論的角度可以認為是歸納法,而歸納法研究問題的基本范式為“歸納—總結”。
由于大數據應用于經濟學問題分析的研究還未形成標準的研究范式,還處于探索的過程中,因此,當前的大部分研究都只是應用大數據信息來分析經濟學問題的嘗試,但這些研究大都過分強調大數據分析問題時的“相關性”,較少去分析“因果性”問題。這樣的處理方式的好處是研究者有充分的自由空間,設計模型時不再受到約束條件的限制,發現和應用數據來分析經濟問題變得簡單化,讓數據自己發聲。如果通過數據發現了某種規律就認為是真理,經濟規律成了數據間相關關系的副產品,而非理性推導的必然結果。當前,大數據研究夸大相關性的作用,有意忽視經濟問題的因果關系,這樣的研究范式難以讓大數據經濟分析成為一門真正的科學,可能會成為一種迷信式的思維[18]。這樣的經濟問題研究方式將導致研究結論難以解釋并且缺乏說服力。經濟問題的研究目的是解釋經濟問題、指導經濟活動,若經濟研究的結論僅僅依靠的是數據之間的相關性表現,則難以從理論上解釋為何具有這樣的相關性,難以形成對經濟規律認識的邏輯體系。另外,在大樣本數據信息的條件下篩選變量之間的相關性,會存在“強相關性表現是否是偶然現象”這樣的疑問,研究結論缺乏說服力。
本研究認為將大數據信息應用于經濟問題的分析是對傳統經濟問題研究方法中數據缺陷的改進,而非對傳統經濟學研究方法范式的顛覆。因此,應用大數據來分析經濟問題時,依然需要遵循一般化的經濟問題研究范式。但由于大數據自身的信息特點,也會對一般化的經濟問題的研究范式產生影響,這種影響主要是關于數據信息方面的假設。因為大數據信息的來源廣泛,而且數據信息量巨大,獲取全樣本或近乎全樣本的數據信息成為可能。傳統經濟問題研究使用的數據基本要求滿足一定的抽樣理論,以使獲取的數據具有足夠的代表性,而近乎全樣本的信息量則不再考慮樣本的代表性問題,可以放寬數據統計屬性的假設。
大數據信息又增加了一個問題,那就是數據噪聲的問題。大數據信息量巨大,但數據信息中無效信息也急劇增加,如果無法有效地去除噪聲信息,將對經濟問題的研究結果造成巨大的影響,甚至導致對經濟問題規律認識的錯誤判斷,沒有經過去噪處理的大數據信息將會導致“垃圾進入,垃圾輸出”(garbage in,garbage out)。在具體經濟問題的分析過程中,網絡數據信息的使用需要很強的技巧性來剝離與研究問題不相關的網絡信息。例如在使用網民網絡搜索“通貨膨脹”的頻率信息時,針對該搜索行為的動機可能是關注市場價格整體變動,也可能是查看經濟學名詞的含義,而這兩種不同的搜索動機對具體的經濟問題研究具有不同的意義,因此在利用網絡數據時需要通過特定的方式來識別、剔除與研究問題無關的信息。若處理不當,可能會導致研究結論與真實情況之間存在較大的偏差。
當前,針對大數據信息的去噪方法,主要是通過統計學的方式來篩選[25-27],但這種方式依然基于“歸納—總結”的研究范式,只要具有統計學意義上的強相關性或者滿足其他的相關性就認為數據信息有助于預測和分析經濟問題。這樣的研究思路依然避免不了“偽回歸”類的錯誤,以此為依據的研究結論也不具有強說服力。例如Ginsberg等利用“谷歌”數據庫,基于相關性來篩選與流感相關的“關鍵詞”,最終得到了5 000多萬個“關鍵詞”的搜索時間序列數據,并利用該大數據信息來預測流感爆發時間,得到了較好的預測效果[27],相關成果發表在《NATURE》雜志上,轟動一時。但這樣的研究思路得出的規律卻無法應用于現實。2014年,《SCIENCE》雜志發表的一篇文章指出Ginsberg等的預測方法存在嚴重的問題,應用該方法來預測2011年8月至2013年9月流感爆發時間的結果誤差比傳統統計方法預測結果更高[28]。該研究以相關性為依據選擇網絡數據信息,缺乏對網絡數據背后行為動機的考察,導致模型高精度的預測效果難以持續。在面對海量數據信息時,總能找到與研究問題強相關的數據,但強相關并不一定意味著存在直接的邏輯關系。因此,本研究認為針對大數據的“去噪”處理也應該基于經濟學的理論分析,在篩選數據信息時,應在經濟學理論指導下判斷哪些數據信息應該被收納到經濟學問題的分析中,而不應該僅僅只是考察統計關系。
基于以上的分析,本研究總結了利用大數據做經濟學問題分析時的一般范式,如圖2。
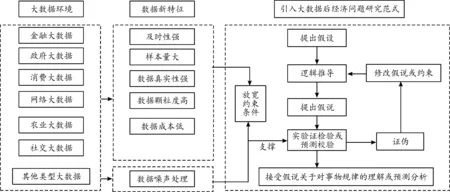
圖2 大數據對傳統經濟學問題研究范式的改進
五、總結及展望
(一)總結
大數據(Big Data)概念自1997年首次提出來后(9)美國宇航局研究員邁克爾·考克斯(Michael Cox)以及大衛·埃爾斯沃斯(David Ellsworth)在當年美國電子電器工程師學會(IEEE)舉辦的第八屆可視化會議上將超級計算模擬飛機在飛行過程中氣流的超大信息稱之為“大數據”。,自然科學和社會科學工作者均對其產生了濃厚的興趣。自然科學關注大數據的技術特征,包括數據量的大小,是否能夠在較短的時間獲取以及是否能夠在傳統計算機上在可接受的時間內處理和分析等技術細節;社會科學則更加關注大數據的價值特征,強調大數據能夠增強當前人類對社會經濟問題的認識能力,能夠改進人類社會生產和生活方式。整體而言,大數據信息具有體量大、難處理、信息多樣性以及高價值的特征,具有這樣特征的大數據信息應用于經濟學問題的分析能夠帶來傳統數據無法具備的一些優勢,包括高時效性、數據誤差率低、數據成本低、數據細分度高以及大樣本屬性。傳統經濟學主要研究因果判斷問題,基于抽樣理論獲取有限樣本信息用于實證,并在一系列嚴格假設基礎上推斷因果關系。這樣的研究范式對樣本數據信息的假設過于嚴苛,以至于有些假設在實際問題中難以完全滿足,因此具有一定的局限性。大數據信息在一定程度上能夠緩解小樣本或者有限樣本的缺陷,有助于適當放寬對樣本數據的假設條件,進而帶來經濟學問題分析范式的改進。
(二)展望
大數據時代的來臨,帶來了與傳統統計數據不同屬性的數據信息,經濟學問題研究者為之興奮,甚至認為大數據已經突破傳統假設檢驗的研究范式,大數據使得因果關系變得不太重要[29]。做出如此樂觀判斷的主要依據是大數據可能獲取總體樣本信息,暫且認為這種判斷是合理的,即使如此,經濟學研究經濟規律,總體數據信息僅僅是經濟規律影響下的外在表現而已,而從經濟內在規律到外在表現之間并不是一一對應的關系。例如我們分析X影響Y的問題時,并不會簡單看兩者之間的相關系數就判斷他們之間的關系,而是會通過計量模型控制其他重要的影響因素,更多可能的影響因素則放置到隨機干擾項中。全樣本信息也僅僅能獲取某一維度或有限維度的信息量,無法獲取影響Y的全息數據信息(10)筆者認為的全息數據信息是能夠描述影響該經濟規律或現象的一切有關因素的數據信息。。在全息數據信息條件下,或許可以顛覆傳統經濟學研究范式,通過簡單的數據統計分析即可發現經濟規律,但在可見的未來,全息數據信息依然是無法實現的目標。
大數據的出現給當前的經濟學研究帶來了不同的數據信息來源,通過這些數據來源獲取的數據信息能夠改進傳統統計數據的不足。由于大數據信息并不等同于全息數據信息,因此無法完全涵蓋影響某一經濟學問題的全部因素。基于以上的分析,大數據僅是對傳統統計數據的補充,能在局部改變經濟學的研究范式,而非對傳統經濟問題研究范式的顛覆。
當前,大數據在經濟學中的應用相對混亂,還沒有形成固定范式。另外,大數據概念發展至今,也依然沒有形成廣泛認可的理論來支撐大數據的應用。截至目前,最為常用的大數據信息為網絡搜索數據以及文本數據。本研究認為未來可以研究網民檢索行為的規律,組成大數據理論的一部分,為應用大數據信息來分析經濟問題提供理論支撐。此外,隨著自然語言處理(NLP)技術的發展,文本數據將極大擴展經濟問題研究思路,為大數據理論分析和應用帶來廣闊的應用前景。大數據噪聲是影響大數據應用于經濟問題分析的主要因素,探索合理有效的大數據去噪方法或理論是未來大數據應用研究的主要方向。
猜你喜歡
今日農業(2022年14期)2022-09-15 01:44:56
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
民生周刊(2020年13期)2020-07-04 02:49:22
電子制作(2018年18期)2018-11-14 01:48:24
華人時刊(2018年23期)2018-03-21 06:26:00
中華手工(2017年2期)2017-06-06 23:00:31
山東工業技術(2016年15期)2016-12-01 05:31:22
中外會展(2014年4期)2014-11-27 07:46:46
全國新書目(2009年24期)2009-07-17 08:12:46
祝您健康(1987年3期)1987-12-30 09:52:32
