基于關鍵詞價值細分的高價值熱點主題識別方法研究
2022-03-07 08:29:30孫佳佳李雅靜
情報學報 2022年2期
孫佳佳,李雅靜
(武漢大學信息管理學院,武漢 430072)
1 引言
近年來,關鍵詞的相關研究一直是各學科領域關注的熱點。關鍵詞是研究成果的高度概括性表達,體現了其核心思想或重點內容。研究關鍵詞分布情況、演化趨勢等規律,有助于揭示學科發展動態和領域前沿。當前,已有研究大多是運用共詞分析[1]、詞頻分析[2]或知識圖譜[3]等方法,揭示某個領域內、某個時期內的學科熱點或主題演化,這些方法的本質是關鍵詞頻次及其共現次數的研究,鮮有學者在同時考慮關鍵詞的價值屬性和生存周期的基礎上,研究熱點主題的識別。關鍵詞是文獻主題的外在體現,在某個研究領域內,其頻次的累計反映該主題的熱點程度,并未反映出該主題的價值高低,且隨著時間的推移,頻次不斷地發生變化[4],呈現出一定的生命周期[5]。因此,對關鍵詞進行價值細分,并考慮關鍵詞生命周期,有助于發現高價值熱點主題。本文所論述的關鍵詞,皆指作者關鍵詞,即在撰寫文獻過程中,由作者提煉或標注出來的一系列關鍵詞匯[6]。
價值細分在客戶營銷領域一直是研究重點,指以客戶價值為細分指標,根據客戶價值的大小,將所有客戶分為具有不同價值的客戶群體[7]。企業或者機構以此為依據,制定最優的客戶管理策略。當前,價值細分已被廣泛應用于工商管理、信息科學以及社會科學等多個領域,在圖書情報與檔案管理領域(下文簡稱“圖情檔領域”)也有學者開始關注,特別是RFM(recency,frequency,monetary)模型,在圖書館用戶與精準服務[8]、情報學用戶與知識共享[9]等研究領域已經有了相應的研究。
生存分析(survival analysis)起源于生物醫學研究領域,將事件出現終點所經歷的時間(即sur‐vival time,生存時間)作為標準,分析各種影響因素的現代統計方法,也稱為風險模型或者持續模型(hazard model/duration model)[10]。生存分析在分析過程中考慮了研究目標的生命周期,可以深刻地反映一段時期內各種因素對研究目標的影響程度,因此,在醫藥衛生科技、工程科技及信息科技等學科領域,生存分析都得到了廣泛的關注和應用。生存分析方法基于生命周期的核心理念,在圖情檔領域的主題識別[11]、文獻老化[12]等方面都有所應用。
本文將營銷領域的客戶價值細分RFM模型和醫學領域廣泛使用的生存分析方法結合起來,引入到圖情檔領域,形成跨學科研究方法,深入探討該方法的適用性和合理性,將客戶價值細分的研究對象遷移到關鍵詞,形成多方位、多角度的關鍵詞價值細分結果,對學科領域的高價值研究熱點進行識別,以期為圖情檔領域關鍵詞和主題的相關研究提供一種新的方法和思路。
2 相關研究
本文將兩個不同領域的研究方法結合起來,以作者關鍵詞為研究對象,探討高價值熱點主題的識別方法。因此,本文主要梳理圖情檔領域價值細分、生存分析以及熱點主題發現相關的研究。
2.1 價值細分相關研究
價值細分在客戶管理工作中具有重要作用,具體表現在客戶識別、客戶策略制定及客戶忠誠度分析等方面。在圖情檔領域,研究者主要運用價值細分的理論和方法,來解決圖書館評價體系、大數據服務平臺建設、用戶信息行為分析等問題。在圖書館評價體系方面,陳宇奇等[13]將RFM模型進行適用性改進,應用到圖書館圖書評價體系的研究中,對完善圖書評價體系和提高圖書館用戶服務具有重要意義;張海營[14]引入RFM模型探索構建圖書評價系統;在用戶及用戶行為方面,樂承毅等[15]構建改進RFM模型,為高校圖書館用戶構建畫像,深入研究了高校圖書館用戶行為和偏好;趙洪波[16]將RFM模型應用于高校圖書館的精準服務,以期為用戶提供更加優質的服務;在大數據服務平臺建設方面,邢海龍等[17]將價值細分模型應用到大數據服務平臺,構建改進RFM模型對用戶進行價值識別;李杭[18]將RFM模型應用于圖書質量評價系統的實現中,是較為新穎的研究思路。從上述研究可以看出,RFM模型在價值細分研究方法中應用較為廣泛,且在圖情檔領域也有較多應用。
2.2 生存分析相關研究
在生物醫學領域,生存分析方法已經得到非常廣泛的應用,特別是在分析患有某種疾病人群的生存率及影響因素方面[19],有相當多的研究成果。生存分析方法的優勢在于考慮了目標客體的某事件結束的時間因素及周期性,這使得揭示影響因素時可以進行多組對比。近年來,在工程學、社會科學等領域也有研究者關注并使用該方法。在圖情檔領域,生存分析主要應用于引文分析、專利研究及互聯網用戶數據分析等方面。例如,張中文等[20]將生存分析方法引入論文被引次數的研究,提出了學術論文生存被引次數的概念;宋爽等[21]探討了生存分析應用于專利維持研究的適用性和有效性;鄭為益[22]使用生存分析方法構建了客戶流失模型,為客戶流失問題提供了一種新的解決方案;賴院根等[23]在考慮信息服務特點的基礎上,使用生存分析方法對用戶生存狀況和影響因素進行了研究。
2.3 熱點主題識別相關研究
熱點主題識別(hot topic detection,HTD)指將一系列文檔按照其主題分組以后,找到一段時間內頻繁出現的主題集[24]。熱點主題反映某個學科或者研究領域在某個時間段內,研究者們關注的重點內容。熱點主題識別立足于生命周期理論,對于揭示研究熱點和進展具有重要作用。國內外對于熱點主題識別的研究主要集中于計算機算法設計和具體應用上。在算法設計方面,Sun等[25]針對短信的文本特征,提出了一種基于特征關聯分析的短信熱點提取算法;Zhu等[26]對TF-IDF(term frequency-inverse document frequency)算法進行改進,提出了一種基于時間分布和用戶關注度的熱點主題識別算法TA TF-IDF;張申旭等[27]通過情感分析和LDA(latent Dirichlet allocation)構建模型,提出了基于多特征的微博熱點主題發現算法,并通過實驗驗證了該算法的有效性;陸蓓等[28]將對蟻群聚類算法進行改進,并提出了類別關注度(category attention degree,CAD)的概念,實現了熱點主題集的抽取工作。在具體應用方面,研究者們著重將已有研究方法應用于互聯網信息平臺以及學術研究領域。例如,王林等[29]通過構造基于興趣的論壇用戶網絡,將社區結構發現的理論和方法應用于社區論壇的熱點主題發現研究中,獲得了較好的實驗效果;唐果等[30]將熱點主題發現作為一種方法,應用于BBS(bulletin board system)文本聚類的研究中;吳立峰[31]將復雜網絡的自相似性應用于BBS興趣網絡,通過仿真實驗將其運用于BBS網絡中的熱點主題發現,驗證了方法的有效性。
綜上所述,熱點主題識別研究一直是國內外研究者關注的重點,其識別結果是由一系列表達文檔核心含義且在一段時間內被高頻關注的關鍵詞所組成的主題集合。已有研究大多聚焦于算法設計和理論方法應用等方面,鮮有研究從細粒度的角度,對關鍵詞的價值進行研究,實現高價值熱點主題的識別。從第2.1節可知,價值細分在圖情檔領域已經有較多研究成果,且RFM模型是廣泛應用的模型之一;從第2.2節可知,生存分析方法在應用時重點關注事物的生命周期,這與熱點主題識別立足于生命周期理論的出發點是相同的。鑒于上述因素,本文從細粒度的角度,提出動態權重的RFM模型,對關鍵詞進行價值細分,并在此基礎上對不同價值層次的關鍵詞進行生存分析,通過Logrank檢驗,確定最優的價值細分結果,依據帕累托法則[32]確定熱點關鍵詞集合,通過聚類算法實現具有價值區分度的熱點主題識別。
3 基于關鍵詞價值細分的學科熱點主題識別方法
3.1 識別方法概述
本文在構建關鍵詞RFM模型的基礎上,充分考慮近度、頻度、值度三個指標的權重,實現動態權重,在多次實驗的情況下,結合生存分析函數(survival function)和Logrank檢驗,確定最優的權重參數,實現關鍵詞價值細分,識別高價值關鍵詞,具體構建流程如圖1所示。
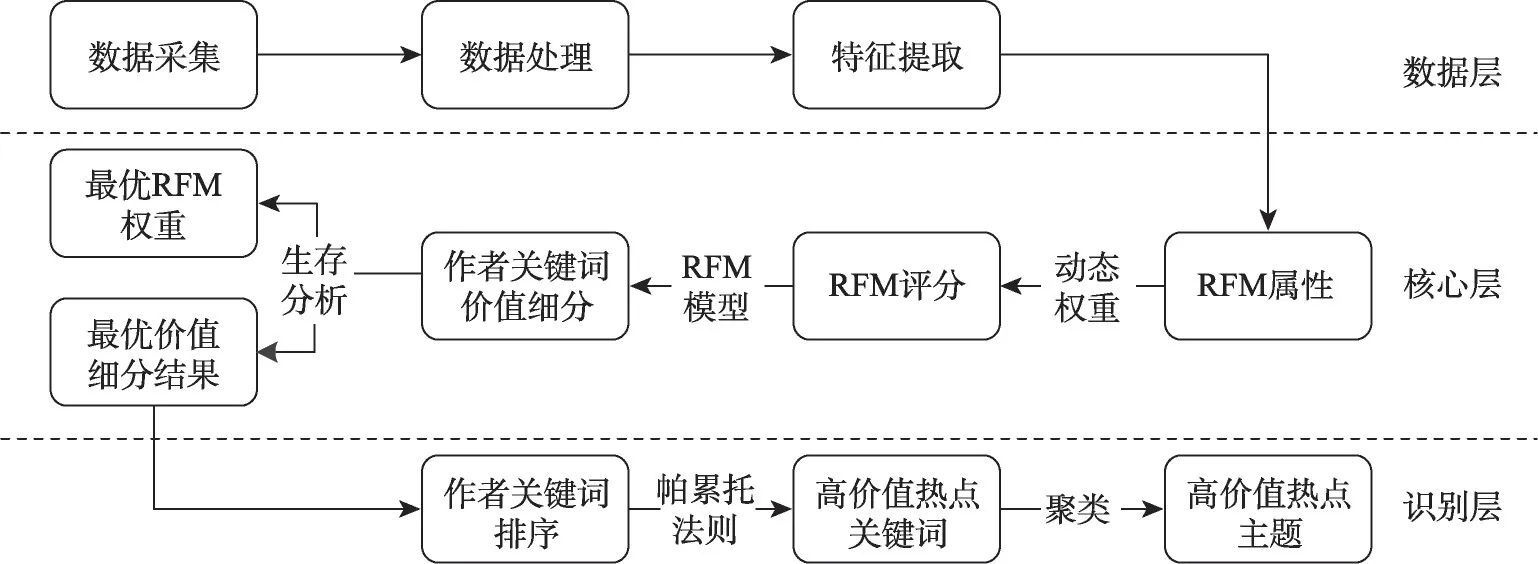
圖1 識別方法構建流程
數據是可行性研究的基礎,足夠準確的數據是研究工作得出科學可靠的研究結論的前提。秉承上述原則,在數據層中,凡是涉及數據處理的操作,全部使用Python語言編寫程序,實現數據的自動化處理,避免人工處理可能造成的數據失真。其中,數據搜集環節對目標數據源數據進行搜集與存儲;數據預處理環節對所采集到的數據進行結構化處理,去除不滿足實驗要求的條目;提取特征環節針對本文模型和方法的要求,將隱性信息提取為顯性特征數據。
核心層是整個實驗的關鍵環節,經過對R、F、M三個指標進行動態權重實驗,在計算RFM評分的基礎上,結合生存分析函數,確定出最為合適的權重值,從而得到價值細分層次。
識別層的功能是高價值熱點主題的識別。在RFM模型的設計原則中,價值細分層次的最上層為高價值層次,據此得到高價值關鍵詞。將該層中的關鍵詞按照頻次進行降序排序,依據帕累托法則,20%的成員貢獻了80%的價值,本文選取排序結果中前20%的關鍵詞作為熱點關鍵詞,計算關鍵詞的相似度矩陣,通過K-means++算法進行主題聚類,識別出高價值熱點主題。
3.2 識別關鍵技術
3.2.1 構建關鍵詞RFM模型
1)關鍵詞價值及價值細分的定義
目前,國內外關鍵詞價值的相關研究較少,還未形成統一的定義。Nishikido等[33]對關鍵詞的動態演化進行了研究,提出了關鍵詞價值主要體現在其在網絡中的關系上,并在實驗中驗證了關鍵詞價值隨著時間和網絡關系的變化而變化。在信息檢索研究領域,關鍵詞價值研究主要在搜索引擎推廣方面。例如,Byers等[34]提出,在搜索引擎的廣告活動中,關鍵詞價值主要體現在貨幣價值上;Hou等[35]使用貝葉斯網絡設計了關鍵詞競標價值預測模型,考慮了關鍵詞的出價、點擊次數和時間等維度。從上述研究中可以得到啟示,關鍵詞價值與時間、頻次、價格及網絡關系密切相關。此外,李劍鋒[36]認為,價值是指客體能夠滿足主體需要的那些功能和屬性。基于此,本文對關鍵詞價值的概念進行闡述:關鍵詞價值是指關鍵詞的時間、頻次及經濟效益等屬性對主體或使用者的有效性和有益性。
Kamakura等[37]認為,價值細分是對群體進行劃分,從而識別出具有正向意義和經濟意義的部分。結合關鍵詞價值的概念,關鍵詞的價值細分是指通過對關鍵詞的時間、頻次、經濟效益等屬性進行綜合考慮,按照一定的規則和方法,對關鍵詞集合進行劃分,從而識別出影響力、有效性或有益性更大的部分。秦嘉杭[38]認為,學術價值是國家社科基金項目的研究成果(論文、專著等形式)的特征之一,而關鍵詞表達了研究成果的核心內容,因此,關鍵詞具有一定的學術價值。本文立足于中文社會科學引文索引(Chinese Social Sciences Citation In‐dex,CSSCI)期刊論文的關鍵詞數據,通過綜合考慮頻次、時間以及基金項目次數,識別出對研究者進行項目申請選題、把握學科動態具有指導意義的關鍵詞集合,可以看出,關鍵詞的價值是對使用者和研究者的價值。
2)關鍵詞RFM模型定義
傳統RFM模型由Hughes[39]于1994年提出,是企業根據顧客數據庫中的交易信息記錄對顧客價值進行識別和評估的模型,包括三種指標:近度(R)、頻率(F)和額度(M)。其中,R表示最近一次購買時間離樣本數據截止日的時間距離,F表示研究期限內(樣本的時間跨度)的購買次數,M表示購買總金額[39]。本文的研究目的與該模型相似,將關鍵詞視為“顧客”,識別其價值能夠預測出未來相應主題的發展方向,因此,采用該模型具有合理性。相應地,本文將R用關鍵詞最近出現離實驗數據截止的時間距離表示;F用實驗數據時間跨度內出現的總頻次表示;M則用關鍵詞所在文獻獲基金資助的頻次表示。一般來說,基金項目是由國家部署實施的科技創新驅動規劃方針,往往代表前瞻性和探索性,有利于情報跟蹤和推動學科研究,也有較多研究從基金項目的角度出發,研究主題的識別。例如,楊辰毓妍等[40]基于國家社會科學基金和國家自然科學基金項目,用科學計量的方法研究了圖情檔學科的知識結構和主題;張蒙等[41]對國家社會科學基金項目的圖書館、情報與文獻學學科進行了熱點可視化分析;王效岳等[42]從基金項目和論文數據出發,在考慮項目資助因素的情況下,提出了一種前瞻性和更高價值主題識別方法。因此,本文認為獲得的基金資助次數越多的文獻,其關鍵詞的價值越高。最終,得到關鍵詞RFM模型指標體系,如表1所示。為了綜合衡量關鍵詞的價值程度,引入加權平均數的計算思想,給出RFM score的計算方法,即

表1 關鍵詞R、F和M特征的定義與影響

其中,R、F、M分別為關鍵詞的近度、頻度和值度;wr、wf、wm分別為R、F、M的權重,取值范圍為(0,1),且滿足wr+wf+wm=1。三個特征分數的計算公式為
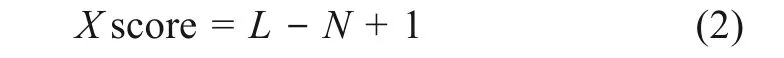
其中,X表示指標R、F、M;L表示價值細分總層次數,本文中L=5;N為排序等分后,關鍵詞所在的層次數。
RFM模型每個指標得分實現步驟:①計算每個作者關鍵詞的R、F和M的特征值;②對所有作者關鍵詞分別按照R、F、M特征值進行排序;③本文的指標賦值標準依據Hughes的五等分思想,將三個指標分別進行排序,按照公式(2)得到每個關鍵詞的R、F、M指標得分;④依據公式(1)計算每個關鍵詞的價值得分(RFM score)。
3)關鍵詞價值層次定義
在對關鍵詞劃分層次以后,需要在理論上對關鍵詞價值層次進行定義。Ha等[43]提出自組織特征映射網絡(self-organizing feature map,SOM)對客戶RFM指標進行分類,將客戶的價值劃分為重要和一般價值客戶、重要發展和保持客戶、一般發展和保持客戶、重要和一般挽留客戶共8種價值類型。該分類方法更加適用于以客戶為研究對象的領域,本文以關鍵詞為研究對象,對該方法進行適用性改進。參考楊琳等[44]的細分方法,結合本文的5等分思想,將關鍵詞的價值層次分為5層,其定義如表2所示。

表2 關鍵詞價值層次定義
3.2.2 最優RFM指標權重確定方法
為了對關鍵詞進行價值細分更具有區分度,需要確定最優RFM權重。具體過程分為三個步驟:①動態調整RFM模型每個指標的權重值,計算RFM score,共37種組合;②對每一種結果依據RFM score降序排序,劃分為5等份,得到關鍵詞價值細分層次;③引入生存分析方法,考量不同價值層中關鍵詞的生存函數,畫出Kaplan-Meier曲線,采用觀察法和對比法進行篩選,利用Logrank檢驗驗證結果,得到最優RFM權重,確定最優價值細分層次。下文將對以上步驟的實現方法進行詳細敘述。
1)計算關鍵詞RFM score
在大多數RFM模型應用中,識別客戶價值時認為各指標權重相同,也有學者質疑三個權重同樣重要的假定,認為學者應根據研究目的彈性設定指標權重[45]。因此,為了解決三個指標所占權重不一致問題,學者一般采用的價值權重設置原則是R、F、M三個指標的權重相加等于1[46],即wr+wf+wm=1。需要說明的是,當前確定權重采取的方法主要是主觀賦值法[47]和層次分析法[48];也有學者結合其他方法確定權重,如熵權法[49];較少有學者采用枚舉法。由于當前缺乏可參考的文獻,且枚舉法求取最優解具有較高的效率和較大的準確性,因此,本文采用枚舉法,遍歷所有可能存在的情況。令wr、wf、wm在(0,1)的范圍內取值,開區間保證三個指標同時存在,分別枚舉三個權重的值,得到多組權重組合,依據公式(1)和公式(2),計算每個作者關鍵詞的RFM score。
2)確定最優RFM權重與關鍵詞價值細分層次
在計算每個作者關鍵詞的RFM score以后,按照得分從高到低進行排序,然后對排序列表進行5等分,得到作者關鍵詞價值細分結果。該過程動態調整RFM權重,得到多組實驗結果,考慮到時間因素影響,如果某關鍵詞最近出現的時間較近,次數卻不高,那么可能會影響識別結果。在圖情檔領域,已有學者使用生存分析函數分析作者關鍵詞的生存狀況以及衡量關鍵詞的生命周期[19],因此,為了排除關鍵詞時間因素的影響,本文引入生存分析方法,對價值細分層次繪制Kaplan-Meier曲線,使用Logrank驗證來確定最優的RFM權重和價值細分層次。Kaplan-Meier曲線是對Kaplan-Meier估計量[50](也稱為乘積極限估計量)的圖形化表達,該估計量是一種非參數統計量,用于從具有生命周期的數據集中估計生存函數。在醫學領域研究中,經常被用來測量患病人在治療后一定時間內的存活率,近年來也被廣泛應用在其他領域,例如,衡量人們失業后處于失業狀態的時間長度[51]。生存函數Ka‐plan-Meier估計量的數學表達式為
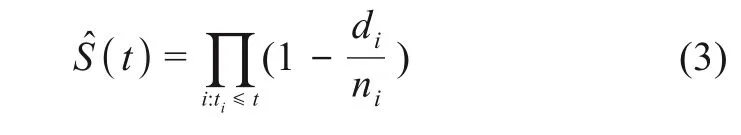
其中,ti表示發生終點事件的時間;di表示在時間點ti發生終點事件的個體數量;ni表示已知存活到時間ti的個體總數。
Logrank驗證也稱為對數秩檢驗,是一種統計分析測試方法,用于比較兩個或者多個組別之間的生存函數是否具有顯著差異性,該檢驗的原假設為各組別的生存函數之間沒有顯著差異性,在檢測結果中,如果P<0.005,則拒絕原假設,表明各個組別的生存函數具有顯著性差異。
對各個價值細分組別的生存曲線可視化以后,本文采用觀察法和對比法篩選出曲線劃分最為明顯的實驗結果,并使用Logrank檢驗各個組別生存函數是否具有顯著性差異,從而確定最優的價值細分結果以及對應的RFM權重。
4 實證研究
4.1 數據源
本文選取中文社會科學引文索引(CSSCI)作為數據源,以期刊名稱為檢索對象,將檢索條件設置為精確匹配,檢索1998—2019年共22年的文獻題錄數據。期刊名稱來源于《CSSCI來源期刊(2019—2020)目錄》,“圖書館、情報與文獻學”學科上榜的20種期刊。數據搜集下載時間為2020/04/13—2020/04/14,共搜集到83369條題錄數據,共包含關鍵詞321020個,去重合并后共86344個。圖2是文章數目、作者數目、關鍵詞數目隨著時間變化的趨勢。由圖2可以看出,1998—2009年,文章數目逐年升高,2009年達到頂峰;之后文章數目雖呈下降趨勢但較為平穩。一般來說,一篇文章對應若干個作者和關鍵詞,因此,作者數目、關鍵詞數目的趨勢由文章數目的趨勢決定,這也符合上述描述。
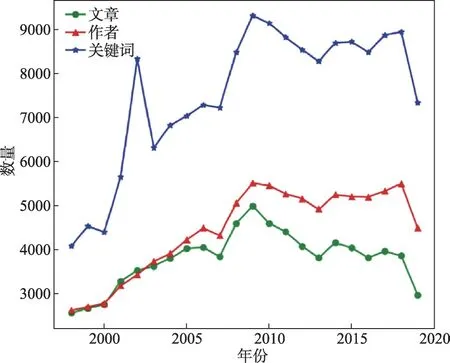
圖2 數據集變化趨勢
4.2 數據處理
按照第3.1節中的識別方法概述,本文需要對所搜集的數據進行特征提取。CSSCI題錄數據是以文章為單位,將其處理為以關鍵詞為單位的數據形式,僅保留實驗過程需要的數據,以JSON格式保存,所包含的具體字段如表3所示。其中,status字段表示該關鍵詞是否出現終點事件,即若其最后出現的年份小于數據集時間年份2019,則用1表示出現終點事件,反之,則用0表示未出現終點事件。

表3 作者關鍵詞字段示例
4.3 實驗過程
4.3.1 計算RFM score
依據第3.2.1節中的方法,計算作者關鍵詞對應的R、F和M;按照第3.2.2節中的方法,對三個維度指標的權重進行調節,計算RFM score。為了保證適量的實驗次數,同時保證后續實驗易于分析和觀察,本文將每個特征權重的小數位數設置為1。動態權重的RFM score計算過程如圖3所示,首先令wr在(0,1)的范圍內依次取值,然后分別枚舉wf、wm的值,并確保三個權重的和為1,得到36種權重值組合;考慮到wr=wf=wm的情況,共37種權重值組合,使用公式(1)計算每個關鍵詞的RFM score。
圖3 動態權重RFM score計算過程
4.3.2 確定最優RFM權重和價值細分層次
依據RFM score進行關鍵詞價值細分,按照降序對其排序,并劃分為5等份,每個關鍵詞價值細分層次稱為RFM level。RFM模型考慮了關鍵詞的近度,但忽略了生命周期對關鍵詞的影響,因此,使用Python語言編寫程序,對37種權重組合分別繪制Kaplan-Meier曲線圖,用于考量關鍵詞的生命周期,將生命周期的長短因素納入到價值細分層次劃分中,但鑒于篇幅所限,本文挑選出wr在[0.1,0.2,…,0.8]中取值時,每種權重組合情況下,層次最為明顯的曲線圖,如圖4所示;三個權重值相等情況下的曲線圖,如圖5所示。從圖4中可以清晰地看出,在權重值wr、wf和wm分別為0.8、0.1和0.1時,關鍵詞價值細分層次的區分最為明顯,且較為均勻;而其他權重值組合下,均不滿足價值細分均勻的條件;在圖5中,三個權重值相等時,RFM level為1的線條在第1年全部出現終點事件,即該層次下,作者關鍵詞存在時間過短,因此,排除此種情況。
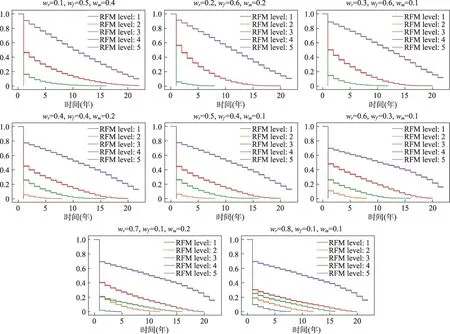
圖4 動態權重價值細分的Kaplan-Meier曲線圖(部分)(彩圖請見http://qbxb.istic.ac.cn/CN/volumn/home.shtml)
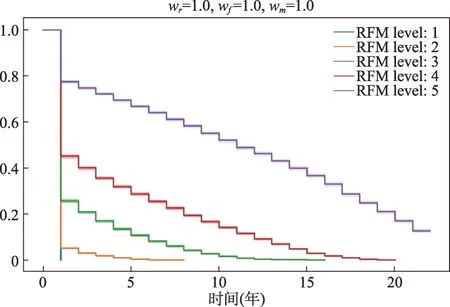
圖5 3個權重值相等情況下價值細分的Kaplan-Meier曲線圖(彩圖請見http://qbxb.istic.ac.cn/CN/volumn/home.shtml)
在初步獲取最優RFM權重以后,還需要使用Logrank檢驗進行顯著性驗證,目的是確定各個價值細分層次的關鍵詞生命周期具有顯著性差異,驗證結果如表4所示。可以發現,各個層次之間的P值均小于0.005,拒絕原假設(各層次沒有顯著性差異),這說明,在R、F、M三個指標的權重分別為0.8、0.1、0.1時,各個作者關鍵詞價值細分層次之間具有顯著性差異。也就是說,最終得到關鍵詞RFM模型最優指標權重如表5所示。
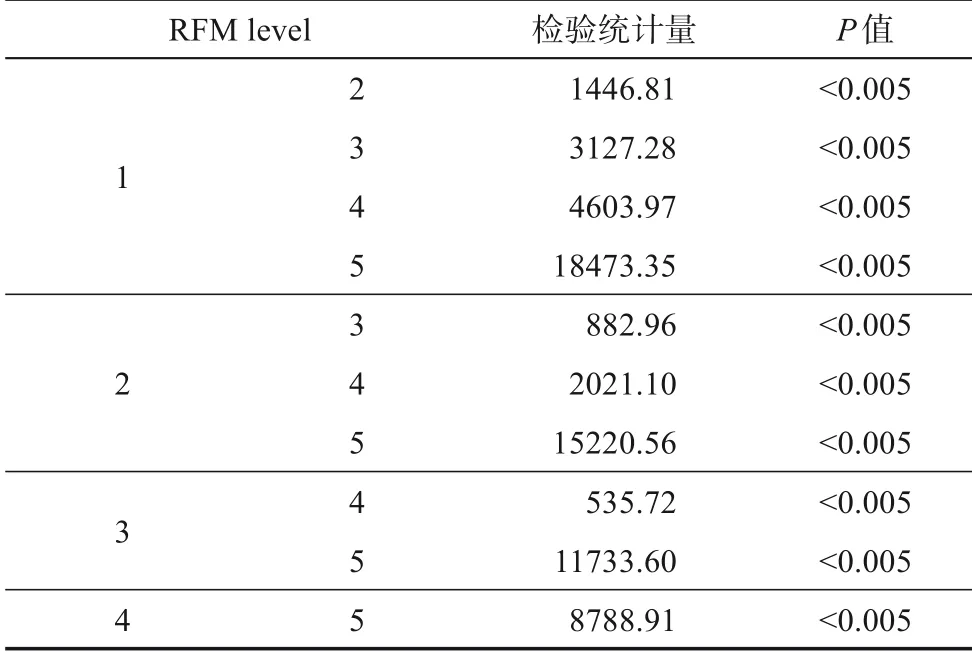
表4 Logrank檢驗結果

表5 關鍵詞RFM模型最優指標權重
4.3.3 高價值熱點主題識別
在得到關鍵詞的最優RFM權重及價值細分層次以后,本文將每個層次中的關鍵詞按照頻次進行降序排列,依據帕累托法則——20%的成員貢獻了80%的價值,從每個價值層次中提取前20%作為熱點關鍵詞。對熱點關鍵詞構建共現矩陣,并計算相似度矩陣,使用K-means++算法進行聚類,聚類數目的確定方法是,使用枚舉法在[2,30]范圍內多次實驗,依據Silhouette Coefficient(即輪廓系數)和SSE(the sum of squares due to error,誤差平方和)評價指標確定最合適的聚類數目。根據高頻特征詞對聚類所得的各個類別進行主題概念概括。表6展示了每個價值層次所提取的熱點主題及其基金支持平均值。其中,位于高價值層次的熱點主題,是本文識別出的高價值熱點主題。
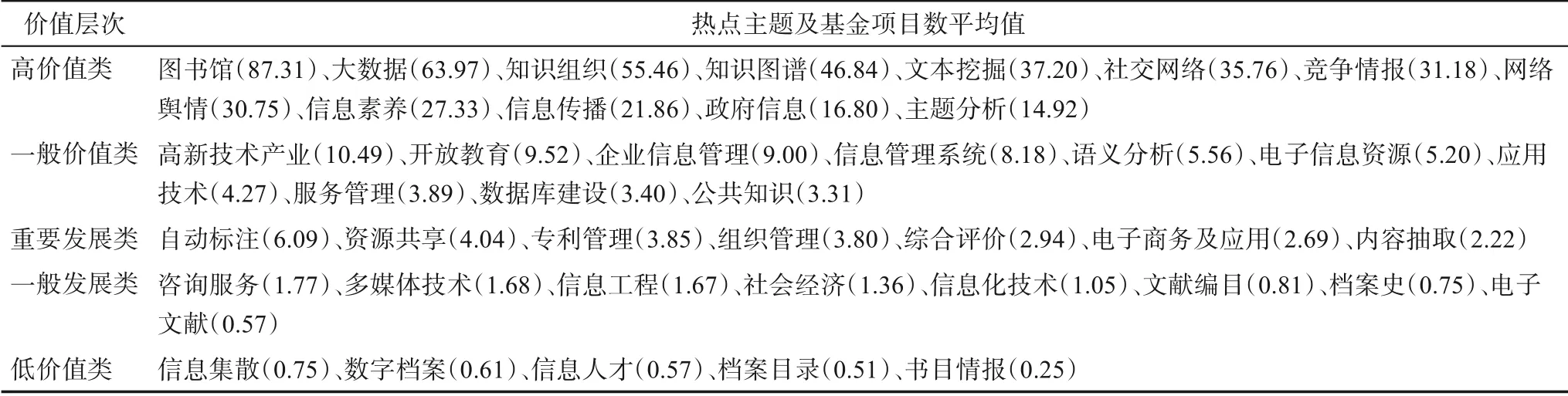
表6 熱點主題識別結果
4.4 實驗結果與分析
本節對高價值熱點主題識別結果進行對比分析和總結。為了說明實驗的效果,本文增加了基于頻次排序的分類方法作為實驗對照組。首先,從總體上進行分析,說明應用本文識別方法是有效的;其次,與實驗對照組進行對比分析,來說明本文識別出來的熱點主題是具有高價值的,證明有效性;最后,歸納總結各個價值層次的主題特征。
4.4.1 識別方法的有效性
在第4.3節中,本文通過使用動態權重的RFM模型對關鍵詞進行了價值細分,同時,為了考慮生命周期對關鍵詞價值細分的影響,引入生存分析Kaplan-Meier曲線對多組實驗結果進行篩選,最終識別出高價值熱點關鍵詞,通過聚類算法得到高價值熱點主題。為了對第4.3.3節中的結果加以解釋和說明,本文再次對數據集中的關鍵詞進行處理,采用傳統的基于詞頻提取重要關鍵詞的方法,對關鍵詞降序排列,分為5等份,稱為頻次分類。對比價值細分和頻次細分兩組實驗結果,如圖6所示,可以看出,與頻次分類方法相比,價值細分方法在考慮了關鍵詞的近度和值度特征后,有31%的關鍵詞層級升高,16%的關鍵詞層級降低。其中,有6%的關鍵詞降低了1個層級,1%降低了4個層級。可以得出結論,關鍵詞的近度和值度對價值的衡量存在影響,本文提出的識別方法具有有效性。
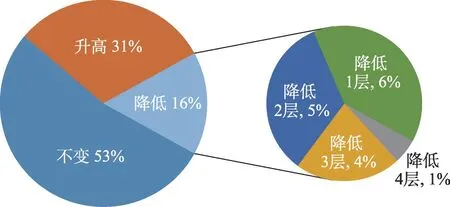
圖6 對比實驗下關鍵詞等級變化情況
4.4.2 關鍵詞參數對比分析
為了進一步說明本文提出的高價值熱點關鍵詞識別方法的優勢,本文將其與傳統的頻次細分方法進行對比實驗,分析兩組實驗下關鍵詞相關參數的變化情況(表7),表中每個參數值是該層次下關鍵詞參數的平均值。以下從對比分析和整體效果分析兩個角度進行分析。
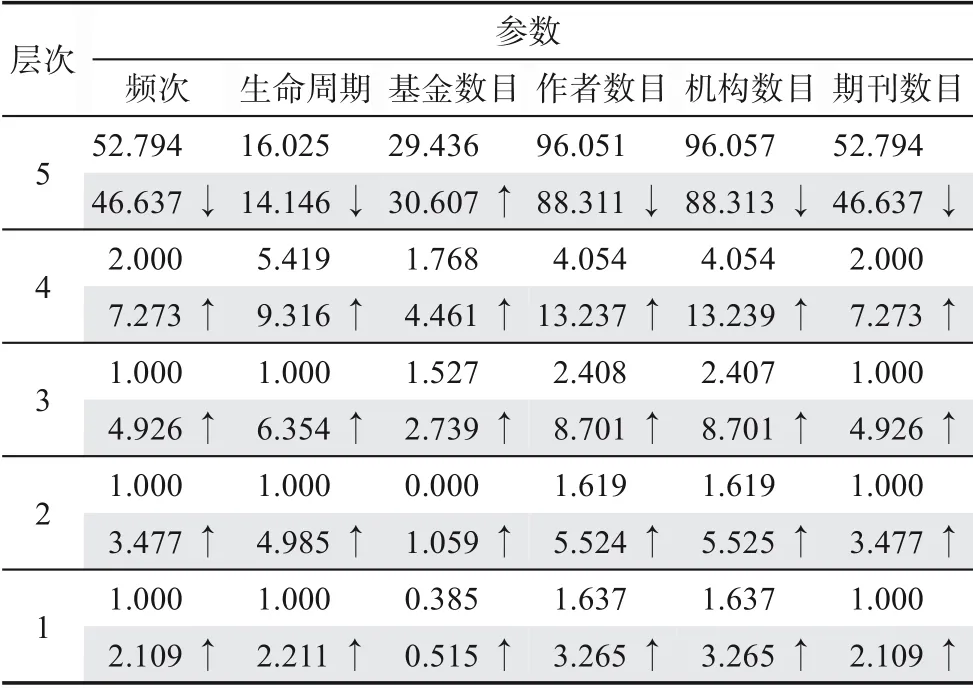
表7 對比實驗下關鍵詞相關參數變化情況
(1)對比分析角度。采用本文價值細分方法后,相較于傳統頻次細分方法可以發現以下規律:①對于最高層次5,除了基金項目參數平均值出現小幅上升,各項參數平均值均出現小幅下降,究其原因,主要有兩點:其一,頻次細分方法并未考慮基金項目對關鍵詞的影響,在納入指標M后,出現小幅上升,證明本文的識別方法在識別熱點關鍵詞過程中較好地考慮了價值因素,為關鍵詞賦予了價值屬性;其二,其余參數平均值下降,說明引入RFM模型以后,將某些依賴于頻次較高而劃分到高層次的關鍵詞被降權,說明對關鍵詞引入近度和值度指標以后,能夠更全面地衡量關鍵詞。②除了層次5以外,各項參數平均值均出現了上升,說明本文的識別方法具有較高的區分度和調節作用。③頻次細分實驗對照組中,層次3、2和1中出現多個1.000參數值,說明在這些層次中,傳統的頻次細分方法已經不具有較好的區分度,而本文提出的價值細分方法,參數在每個層次上的平均值呈相對平穩的下降趨勢,說明層次區分度較好。
(2)整體效果分析角度。本文基于價值細分的識別方法,得到的關鍵詞價值層次更具有區分度,符合關鍵詞RFM模型的定義,即重要價值關鍵詞、一般價值關鍵詞、重要發展關鍵詞、一般發展關鍵詞和低價值關鍵詞。
4.4.3 高價值熱點關鍵詞分析
本節對每個層次下識別出的高價值關鍵詞進行分析。如圖6所示,部分關鍵詞在不同識別方法下,所處細分層次發生變化。舉例分析識別出來的每個層次中的高價值熱點關鍵詞的層次變化情況,對說明本文提出的識別方法的思想具有較大的意義。在實驗過程中,本文計算了每個高價值熱點關鍵詞的基于頻次的層級(count level)和基于RFM模型的層級(RFM level),下文針對層級發生變化的高價值熱點關鍵詞進行分析,如表8所示,變化情況是指關鍵詞的RFM level相對于count level升高或者降低,由于篇幅所限,僅舉例分析。示例中,升高情況下,多數關鍵詞的頻次較低,因此在劃分層級的時候,劃分為4;但在使用本文的識別方法中,由于充分考慮了最后年份(近度)、基金項目數目(值度)和終點事件(用于生存分析)三個參數以后,這些關鍵詞的層級從count level為4提升到RFM level為5,分析發現該類關鍵詞符合兩個特征:①近幾年被作者最新提到或者使用;②雖然存在生命周期較短和頻次較少的現象,但被基金項目支持的次數較高,價值量較大。以上兩個特征,表明該類關鍵詞較為新穎,且價值量較大,未來可能成長為新的高價值熱點關鍵詞。降低情況下,該類關鍵詞的重要特征是其最后年份(近度)在數據截止年份(2019年年底)已經超過3年,本文在第4.3.2節中得到的最優RFM權重中,近度所占權重為0.8,因此,該類關鍵詞在使用本文識別方法后,所處層級降低,表明其屬于重要發展關鍵詞,若未來在較長一段時間仍然沒有被再次關注或使用,則可能不再是學科關注或研究的重點主題。
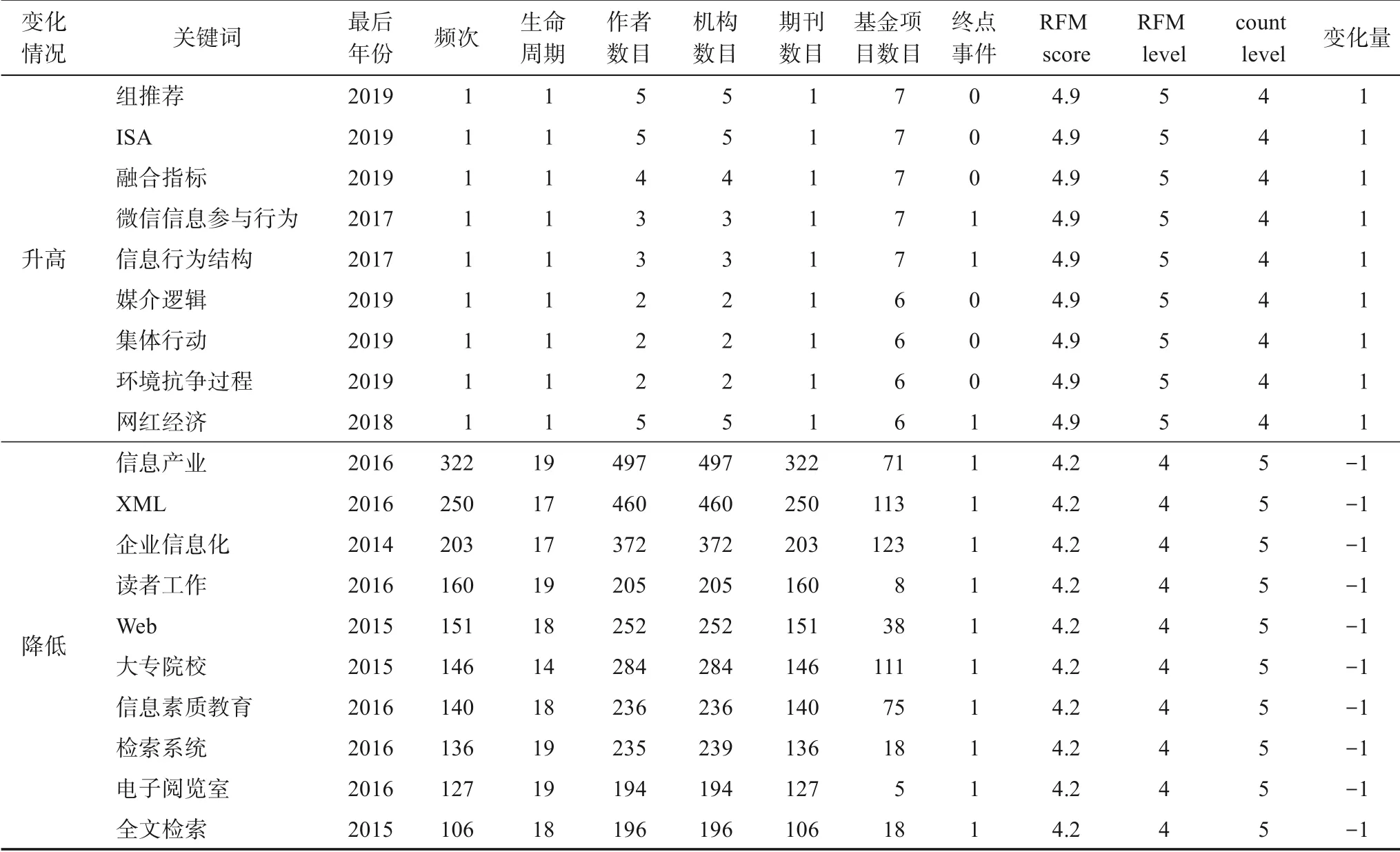
表8 高價值熱點關鍵詞層級變化舉例(部分)
4.4.4 高價值熱點主題識別結果驗證
鑒于熱點主題識別方法目前沒有統一的驗證標準,本節采用資料驗證法和數據對比分析方法,對實驗設計進行驗證。
(1)資料驗證法。本文對目前我國圖情檔領域研究主題分類的文獻進行深入調研,發現本文高價值熱點主題的識別結果與已有研究成果具有一致性。例如,宋娜等[52]通過基金項目名稱檢索相關學術論文成果,采用內容分析法分析了1991—2019年的論文關鍵詞,識別出的熱點主題;趙蓉英等[53]以2001—2012年國家科學基金為演技視角,透視圖書情報檔案學科的研究主題。與上述研究對比來看,本文提取的主題基本覆蓋了上述研究中提到的主題,證明了本文提出的識別方法具有準確性和合理性。
(2)數據對比分析法。將價值細分方法和頻次細分方法提取的熱點主題進行對比,計算每個主題下關鍵詞基金項目數的平均值,再從大到小進行排序,如圖7所示。由圖7可知,從主題數量來看,兩種識別方法一致,但主題排序有所變動。兩者結合分析發現,相較于頻次細分方法,價值細分方法更能識別出國家高度重視的主題。例如,“圖書館”是國家基金長期重點支持的研究主題,排名第一;大數據作為一門新興技術主題,排名第二。這充分說明了大數據主題也是我國基金項目的資助重點,同時反映了圖情檔是一個交叉學科,大數據是研究的一個重要組成部分。此外,在新興主題識別上,本文價值細分方法能識別出當前熱點主題,如價值細分方法識別出大數據、社交網絡、網絡輿情是熱點主題,在價值上高于頻次細分方法識別出的相應主題,為研究者的科研選題和研究方向提供了新的依據。
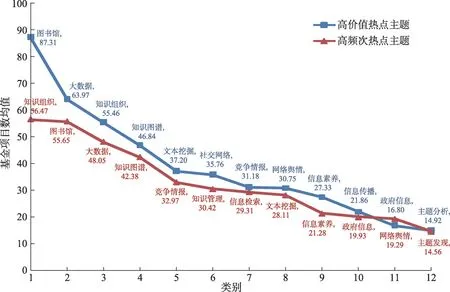
圖7 識別結果驗證
5 總結與展望
本文所實現的高價值熱點關鍵詞識別方法,考慮了關鍵詞的多個維度的屬性,包括時間維度、頻次維度和價值維度。在實現過程中,時間維度重點探索兩個屬性:關鍵詞最近一次出現的時間和關鍵詞的生命周期。關鍵詞的高價值主要體現在基金項目的支持頻次,熱點主要體現在生命周期內被使用的頻次。相較于傳統的熱點主題識別方法大多只考慮關鍵詞的頻次,缺少層次劃分和價值體現,本文提出的識別方法彌補了上述不足。同時,本文也存在一定的不足之處,如使用基金項目支持頻次作為價值尺度是一個較為粗粒度的角度,未來使用基金項目資助金額可以進一步完善價值衡量標準。由于篇幅所限,本文僅探索了高價值熱點主題的識別方法,沒有對主題演化做進一步探索,在未來的研究中,將結合知識圖譜對高價值熱點主題的演化進行研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
文理導航·科普童話(2016年7期)2017-02-04 15:09:20
小天使·四年級語數英綜合(2016年11期)2016-11-29 22:37:30
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
