具有輸入數據注意力機制的卷積神經網絡用于氟化工產品質量預測
2022-03-09 00:38:36李欣銅陳志冰魏志強李蘇桐陳旭宋凱
化工進展 2022年2期
李欣銅,陳志冰,魏志強,李蘇桐,陳旭,宋凱
(1 天津大學化工學院,天津 300350;2 航天長征化學工程股份有限公司,北京 100176;3 巨化清安檢測科技有限公司,浙江 衢州 324004;4 巨化股份有限公司,浙江 衢州 324004)
在現代化工行業中,尤其是對于產品廣泛應用于工業、日常生活、醫學和核工業等各個領域的氟化工而言,產品質量控制格外重要。工業生產上的質量測量往往需要通過昂貴的儀器、實驗室分析和其他額外工作來實現。盡管在線成分分析儀的應用日益廣泛,但受限于成本,工業實踐中通常是多套設備輪流共享一個在線成分分析儀。因此,重要成分質量測量過程中高成本、低效率和滯后性大的缺點,仍然嚴重阻礙了質量控制水平的進一步提高。另一方面,隨著大數據技術的飛速發展,集散控制系統(distributed control system,DCS)在線收集過程數據的能力越來越強。目前,開發質量預測模型來提取變量中蘊含的大量特征信息,實現對產品質量的精準預測,或者說實現質量變量的軟測量,又一次成為了研究熱點。現階段常用的質量預測方法主要包括:多元線性回歸(MLR)、主成分回歸(PCR)、偏 最 小 二 乘 法 (PLS)、 Fisher 判 別 分 析(FDA)、獨立成分回歸(ICR)等線性回歸方法。這些方法通常將原始測量數據投影到低維線性子空間上提取可變特征,然后在低維子空間內構建預測模型,從而有效處理具有多重共線性的高維數據。此外,還包括適用于非線性問題的神經網絡PLS、徑向基函數PLS、核函數PLS、核函數PCR、核函數ICR 等非線性回歸方法。雖然這些研究已為實現在線產品質量預測做出了開創性工作,但由于氟化工多種變量之間復雜的非線性關系,工業應用仍然困難重重。更重要的是,氟化工過程中重要零件或設備的腐蝕、老化、結垢等變化具有不同的時間尺度特性。多種時間尺度特性的共存,使其成為一個時變特性非常復雜的過程。這種非線性與強時變特性復雜的耦合使得非線性方法甚至是常規的機器學習方法難以完成質量預測任務。
隨著計算機技術(即計算速度、存儲容量)的快速發展,深度學習方法在質量預測實踐中的應用越來越普遍。在過去的幾年中,相比其他數據驅動方法,深度學習方法在許多領域吸引了更多的研究關注并展示出更佳的性能。Hinton 等證明了具有多個隱藏層的人工神經網絡(ANN)所學習的特征對數據表征更為本質,這有助于提高分類性能。同時,“分層預訓練”策略有效克服了訓練深度神經網絡的困難。這些提議激發了學術界和工業界關于深度學習研究應用的新熱潮,并逐步發展出深度人工 神 經 網 絡 (DANN)、 深 度 置 信 網 絡(DBN)、深度卷積神經網絡(CNN)等。
CNN 能夠根據不同時間軸上輸入數據的特性進行參數的自適應調整,以實現模型訓練動態迭代。換句話說,CNN 是一種在數據處理過程中實現動態建模的方法。因此,CNN 非常適用于時間序列預測任務,如工業過程的質量預測任務。然而,由于氟化工過程的上述特征,常規CNN 的性能仍然不足以實現精準的質量預測。
立足于上述氟化工過程所面臨的實際困難,本文提出了具有輸入數據注意力機制的卷積神經網絡算法(ACNN),針對性地解決了氟化工數據帶有復雜而強烈時變特性的質量預測難點問題,以滿足工業過程高水平質量控制的需要。一方面,該算法作為基礎框架,可推廣到各類具有強時變特性過程的質量預測任務當中;另一方面,訓練過程無需任何時變特性的先驗知識,最大限度地簡化了實際工業生產過程中訓練、部署模型的步驟。雖然該方法作為深度學習算法在實踐中應用尚存在一定挑戰,例如,對計算機硬件水平的高要求、模型泛化性和訓練時間等,但是其能夠充分利用氟化工生產過程中的海量數據,具有大幅提高工業控制水平的潛力。將該方法應用于氟化工生產數據和Tennessee Eastman(TE)模擬數據,證實了算法的有效性,揭示了良好的工業應用前景。
1 卷積神經網絡算法
卷積神經網絡(CNN)是一種典型的深度學習算法,受到生物過程的啟發,其神經元之間的連通性模式類似于動物視皮層的組織。越來越多的應用有力地證明了CNN 在非線性監督學習應用中的優越性。
常規的CNN 結構包括一個輸入層、一個輸出層以及多個隱藏層。這些隱藏層通常由一系列卷積層、池化層、全連接層和歸一化層組成。卷積層的基本功能是特征提取,這是CNN 最重要的功能。常見的卷積核為正方形(即3×3、5×5等),以便從行和列中均勻提取變量特征。連續幾個卷積層之后添加一個池化層,以壓縮數據和減少參數數量,進而提高網絡學習的速度并避免過度擬合。通過多重卷積和池化提取到的特征圖被輸入全連接層,歸一為預測值,從而實現從輸入到最終輸出的特征提取及預測任務。常用的訓練方法有Adam 算法、高級隨機梯度下降(SGD)算法和其他梯度下降方法等。另外,為了防止過度擬合,CNN 訓練過程中還使用dropout算法。
2 具有輸入數據注意力機制的CNN模型構建
2.1 輸入數據注意力機制
相對于其他簡單的化工過程,氟化工過程的數據具有更復雜的時變特性。而這類時變特性往往體現在不同長度的時間跨度之中,無法被某一個時間序列所表征。受限于輸入數據矩陣X的固定,常規CNN 僅能提取有限時段的單一時變特性,因此不利于把握整體時變特性,無法準確預測氟化工過程的產品質量。基于此,本文提出具有輸入數據注意力機制的CNN算法。利用輸入數據注意力機制,自適應地提取不同跨度的時變特性,從而對輸入數據加權優化后,再進行特征提取完成質量預測,以提高其預測精度。
本文提出的ACNN算法中,CNN的輸入數據不再是單個的矩陣,而是多個不同時間跨度的矩陣。如圖1(a)所示,這些矩陣被儲存在個不同的通道之中,作為CNN 的一次輸入。借鑒SE-NET設計了輸入數據的注意力層,如圖1(b)所示。首先進行擠壓(squeeze)操作,即利用全局池化(global pooling)逐通道壓縮特征,以表征特征通道上的全局分布,由式(1)求得。
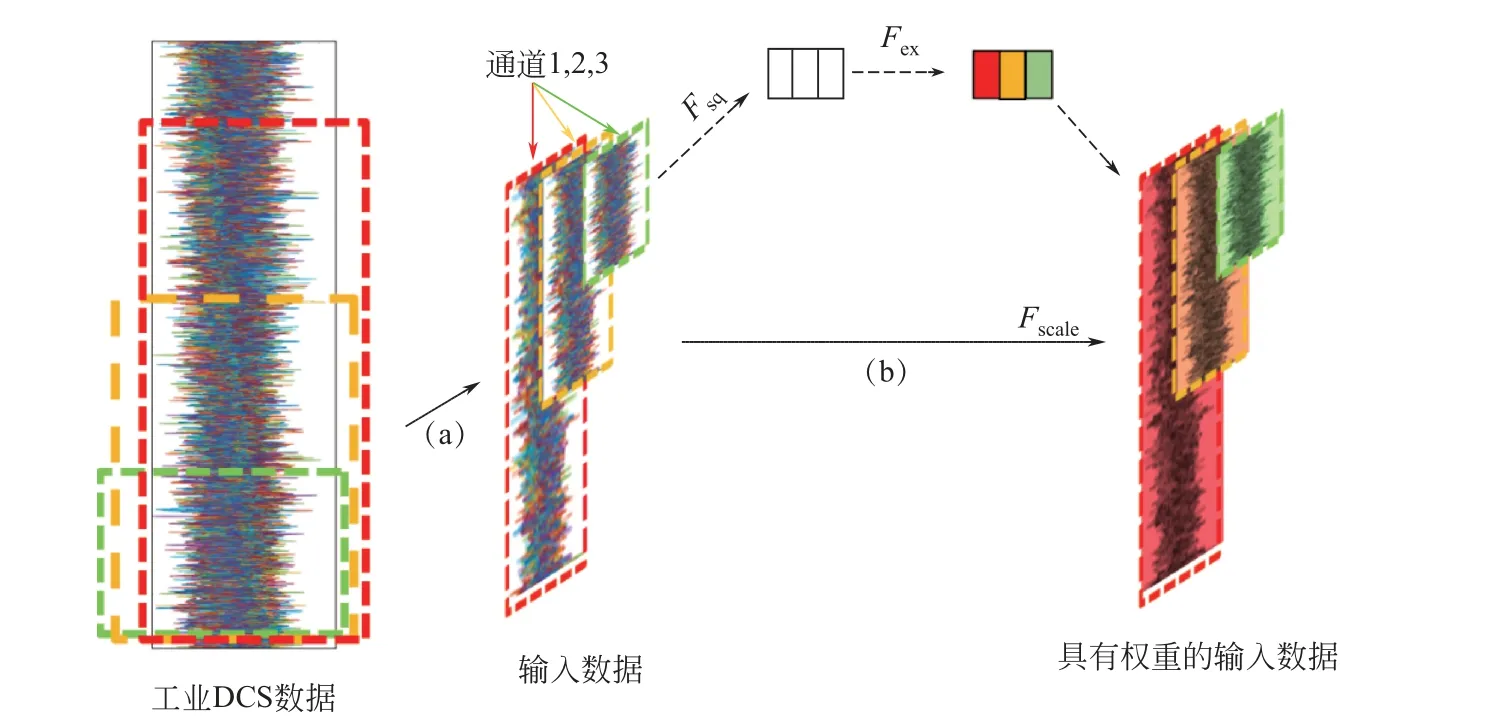
圖1 輸入數據注意力機制
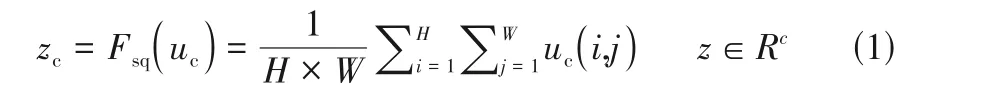
再通過激勵(excitation)操作為每個特征通道生成優化權重。為了降低模型復雜度并提升泛化能力,設計了兩個全連接層,從而保證重要尺度的特征不會因其他尺度特征的加入而被削弱。整個過程如式(2)所示。
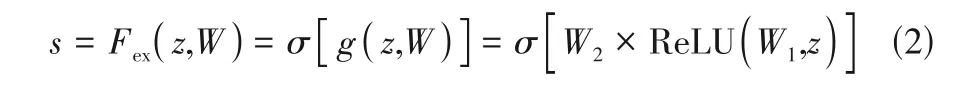
最后,將sigmoid激活后的權重作為每個特征通道的重要性,經乘法逐通道加權到先前的特征上,完成對原始特征在通道維度上的加權標定,如式(3)所示。
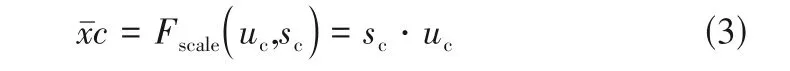
在具有輸入數據注意力機制卷積神經網絡模型訓練時,不同通道的權重會根據最終的預測值在反向傳播中自適應地調整。因此,模型能夠通過不斷調整各個通道的權重來充分利用各個跨度時間序列內的特征信息。
2.2 矩形卷積核和池化層的構建
不同通道內數據長度的不一致,影響了下一步卷積的進行。本文采用多通道異步長的卷積方式,通過對較長數據序列等距采樣,克服不同通道內輸入數據尺寸不一致問題,方法如圖2(a)所示。對于常規圖像處理任務而言,正方形卷積核通常非常有效。但是,在本文的研究中,輸入工業數據矩陣X=[(),(),…,x()]由在個采樣時間點的個過程變量組成。顯然,X的行和列包含完全不同的信息:每行包含同一時間采樣的不同變量的值,而每列包含不同時間采樣的同一變量的值。相應地,行(變量)之間和列(變量的時間序列)之間的相關性完全不同。由于正方形卷積核容易混淆變量和時間的特征關系,采用了沿變量方向的長方形卷積核(如1×3、1×5 等),如圖2(b)所示。其運算如式(4)所示。

式中,是沿可變方向構造的長方形卷積核;和分別是輸入和輸出矩陣;是的列數。為了盡可能全面地提取高維特征,ACNN在一個卷積層中使用了多個卷積核。相應地,卷積層的輸出可以由式(5)計算。
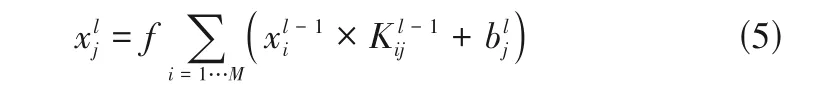
式中,表示激活函數;是第個卷積層的卷積核數;x
是第層的第個輸出特征圖;xl是第-1層的第個輸入特征圖;是卷積核;bl是第個卷積核的偏置。
類似地,為了盡可能多地保留變量在時間序列中所包含的時變信息,以獲得更好的在線質量預測性能,ACNN使用了沿時間方向(列)的長方形池化層,如圖2(c)所示。
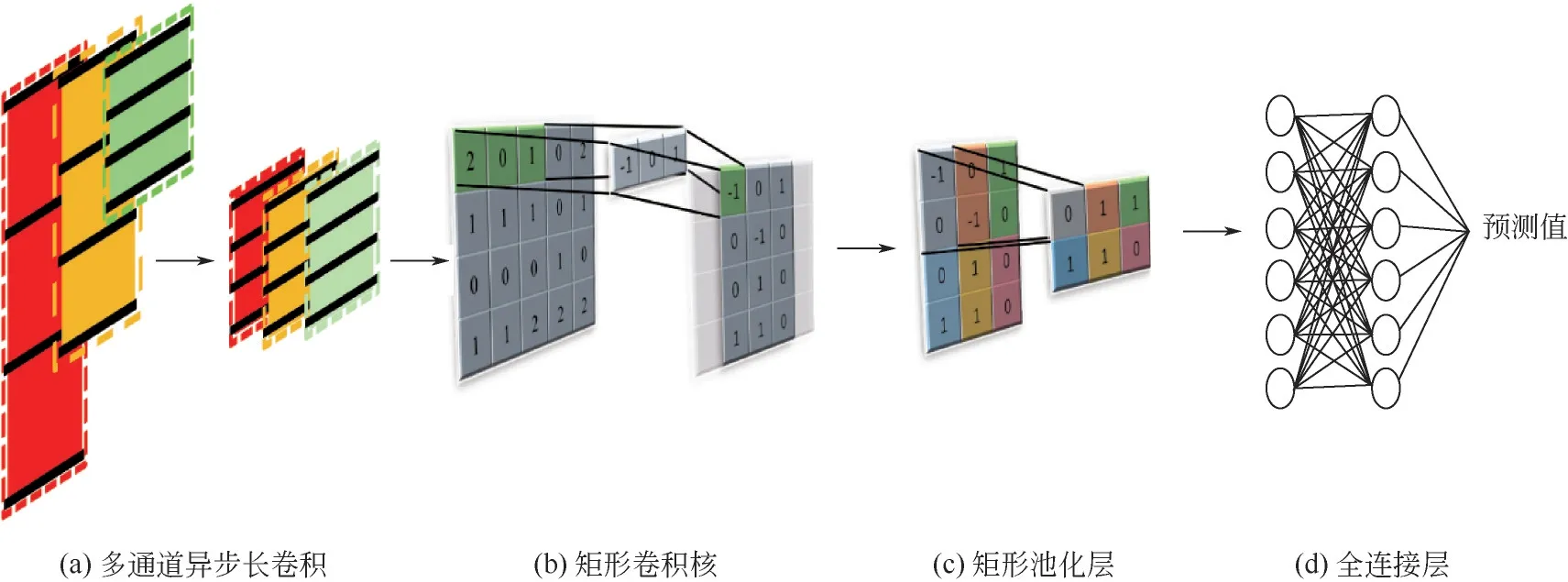
圖2 ACNN卷積操作
2.3 損失函數
損失函數是卷積神經網絡訓練過程中的關鍵因素之一,因此需要針對不同的問題選擇不同的損失函數。損失函數是模型對數據擬合程度的體現,擬合程度越好,損失函數的值也越小。同時,損失函數的值越大,其對應的梯度也越大,變量更新的速度就越快,根據梯度下降進行的訓練越迅速。因而ACNN 中使用了擬合效果良好的均方誤差(MSE),如式(6)所示。
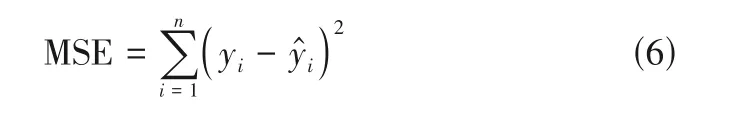
3 結果與討論
3.1 預測TE模擬過程產品質量
TE 模型是化工生產過程的模擬程序,其可以為高級過程控制研究提供大量的模擬工業數據而無需任何損耗。另外,現階段應用于TE 模型的算法很多,便于對算法效果進行橫向比較。因此先在TE 模型上對上述方法的有效性進行了驗證。圖3為TE 模型的示意圖,它包含5 個主要單元:反應器、汽提塔、冷凝器、循環壓縮機和分離器。
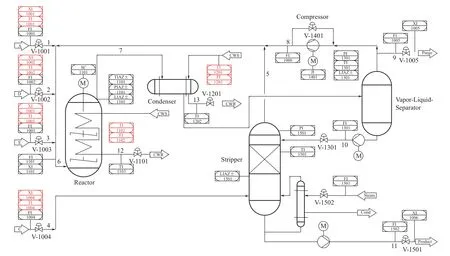
圖3 TE模型流程
本研究中使用模式3 中反應動力學漂移故障(故障13)來模擬具有緩慢時變的波動特性。由于模式3中的兩個過程操作變量是常量,因此僅使用剩余46 個連續變量來預測最終產物的成分分析數據。連續變量采樣間隔為200 個樣本/h,成分分析數據采樣間隔為4 個樣本/h。所有數據連續收集500h,并用前400h 作4E3A 訓練集,后100h 作為測試集。
ACNN 結構優化為Conv(32)-Conv(64)-Pool-Conv(128)-Conv(128)-Pool-FC(1024)-FC(1),同時將前兩個卷積層的“Padding”參數設置為“VALID”。為了驗證該方法的性能,將預測結果與其他方法(如KPLS、O-ICA-KPLS、常規的CNN、SE-NET)應用于TE模型的最佳結果進行了比較。3種深度學習方法均采用相同模型結構和參數,以證實輸入數據注意力機制的有效性。表1總結了不同方法對組分D的預測結果,其評價指標為MSE。
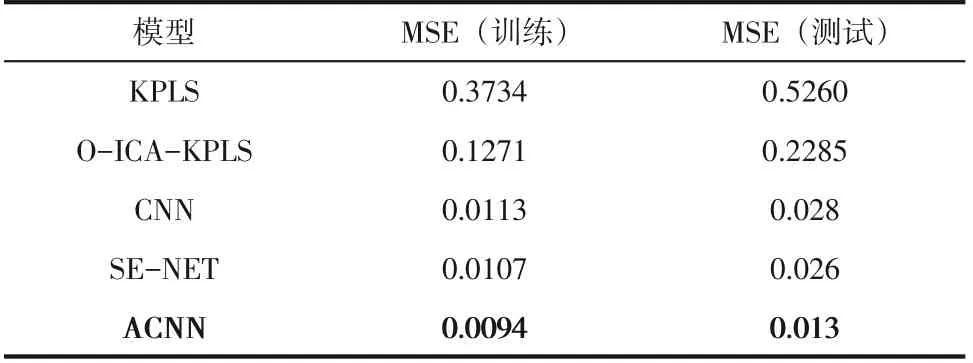
表1 不同方法TE模型質量預測結果比較
總的來說,ACNN在訓練集和測試集上都表現出最低的MSE 值,分別為0.0094 和0.013。普通非線性方法與深度學習方法的差距明顯,KPLS 方法和O-ICA-KPLS方法在測試集上結果僅為0.5260和0.2285,基本難以準確預測,而各類深度學習方法均獲得較低MSE。盡管3種深度學習方法選用的模型結構和參數完全一致,但是由于SE-NET 和ACNN方法分別引入不同的注意力機制,因而精度上呈現較大差異。常規CNN 方法在訓練時表現良好,但其在測試集上的性能不佳,僅為0.028。SE-NET與常規CNN方法類似,受到訓練集為包含的特征干擾時無法有效把握整體的波動特性,測試集上結果為0.026。ACNN 取得最佳結果,證實了ACNN獨特的輸入數據注意力機制使其能夠更準確地提取不同時間尺度上的故障波動特征,并做出更精確的數據預測趨勢。
3.2 預測氟化工過程產品質量
3.2.1 R-22生產流程簡介
R-22 也稱為HCFC-22,是主要的氟化物之一。盡管R-22 作為制冷劑或推進劑的應用一直存在爭議,但由于其是四氟乙烯(TFE,主要用于聚四氟乙烯樹脂、共聚物和食品氣霧劑)以及其他含氟聚合物產品的主要原材料,全世界對R-22 的需求量一直穩定增長。
AHF(無水氫氟酸)和氯仿反應生成R-22 粗產物,再通過水和堿純化除去殘留的HCl 和HF 獲得精細產品。R-22 生產過程的主要操作單元包括進料、反應器、兩個精餾塔,水洗塔和分離器,如圖4所示。
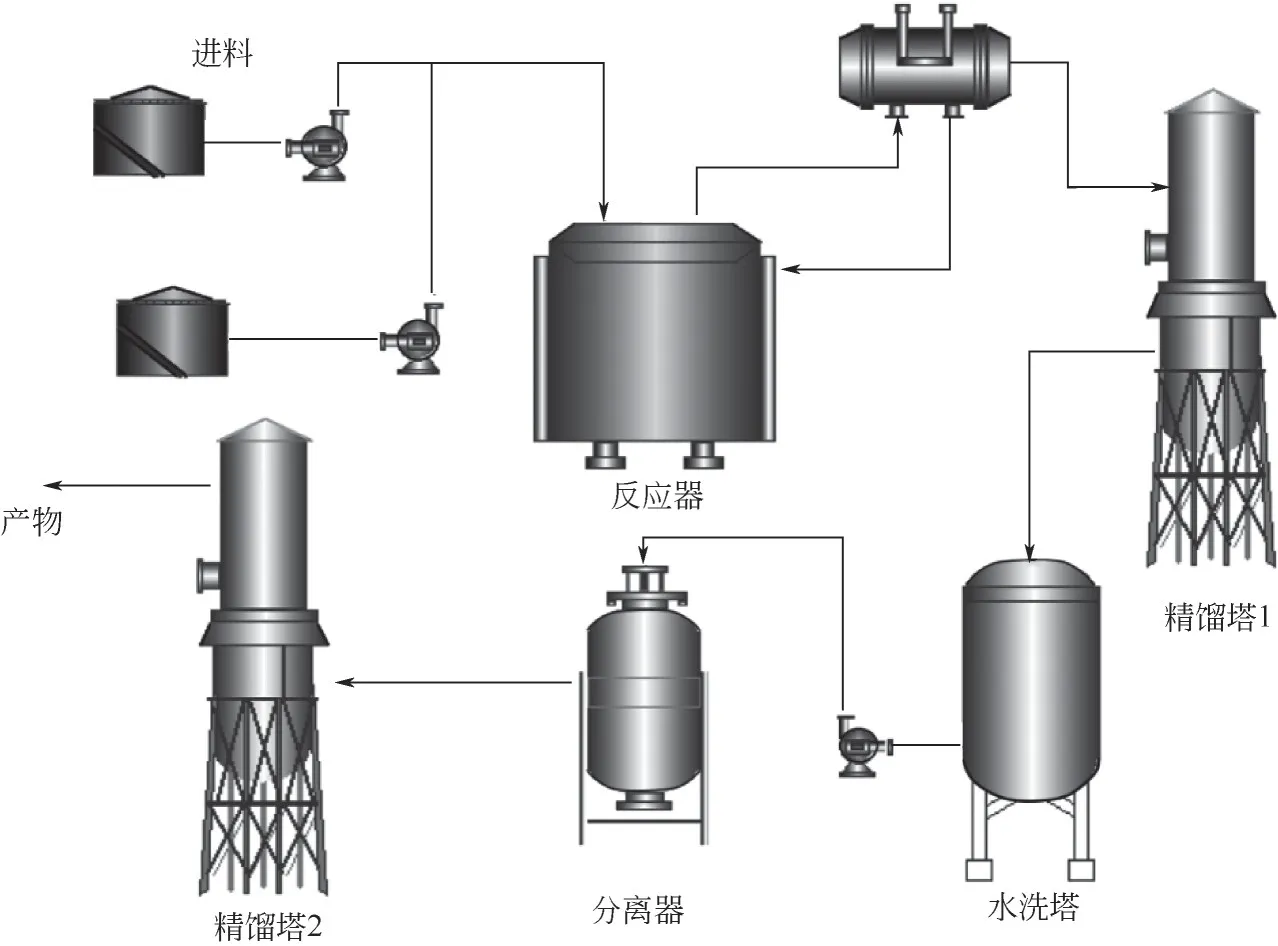
圖4 R-22生產流程
主要產品R-22 的質量分數是衡量產品質量高低的主要指標,影響后續一系列氟化物的生產,因而,精確的R-22 產品質量預測手段對工業流程的整體效益至關重要。另外,過程變量中存在的強烈時變特征以及變量之間復雜的非線性耦合關系使得常規質量預測方法的性能遠遠不能令人滿意。因此,選用R-22 生產過程來驗證上述具有輸入數據注意力機制的CNN模型的有效性。
3.2.2 氟化工過程數據集構建
使用R-22 生產過程的真實數據來驗證該方法的有效性,所有數據均來自位于中國衢州的氟化工廠。根據保密協議,僅使用了對整個生產過程影響最大的R-301反應器相關過程變量,見表2。所有DCS 數據均以1min 的采樣間隔進行采樣,從2020年1月到9月,共274天。成分分析數據為R-22產物質量分數,通過人工測量每8h一次。使用前8個月的數據構建訓練集訓練模型,并用第9個月數據構建測試集進行驗證。

表2 R-22生產過程中R-301反應器的相關變量
3.2.3 氟化工過程模型結構參數調整
與其他深度學習算法一樣,設計ACNN的難點在于沒有統一的指導原則。因而由淺及深設計并驗證了6種不同的網絡結構,不同結構下的最優解見表3。模型性能的優劣由損失函數MSE確定。
適當地增加卷積神經網絡的深度可以提高預測精度,增強模型學習能力,在測試集上獲得較好的結果。但是,過度復雜的網絡結構反而導致過擬合現象,降低模型性能。如表3所示,模型4具有適當的網絡深度,在測試集上MSE 值最小,具有良好的擬合能力。下文內容中將使用模型4進一步分析討論。

表3 不同卷積神經網絡結構下的預測結果
在模型4 中,輸入數據尺寸為(480, 240,120)×10,其中“(480,240,120)”分別代表對應通道中矩陣的時間序列長度,“10”代表變量的數量。卷積核和池化層尺寸分別優化為1×2和2×1。這種設計可以突出不同變量之間的相關性,并在考慮計算負擔的情況下最大程度地提取不同時間序列中包含的特征信息。將卷積層的“Padding”參數設置為“SAME”,以解決對輸入數據邊緣信息提取不足的問題。另外,為避免過度擬合,“dropout”設置為0.5。
3.2.4 氟化工過程質量預測結果
為了驗證本文方法在質量預測任務中的準確性,表4 中列出了最佳性能下的KPLS、O-ICAKPLS,常規的CNN、SE-NET 以及ACNN 方法的預測結果MSE,3種深度學習模型采用完全相同的模型結構和參數。一般任務中常用的非線性方法KPLS 和O-ICA-KPLS 無法適應氟化工過程復雜的非線性特征,對R-22 過程質量預測不準確。常規CNN與SE-NET作為深度學習方法已經遠遠強于之前的非線性回歸方法,但是仍有部分氟化工時變特征信息無法被其合理應用。ACNN由于引入獨特的輸入數據注意力機制,在測試集表現上遠優于常規CNN,MSE值低55%。
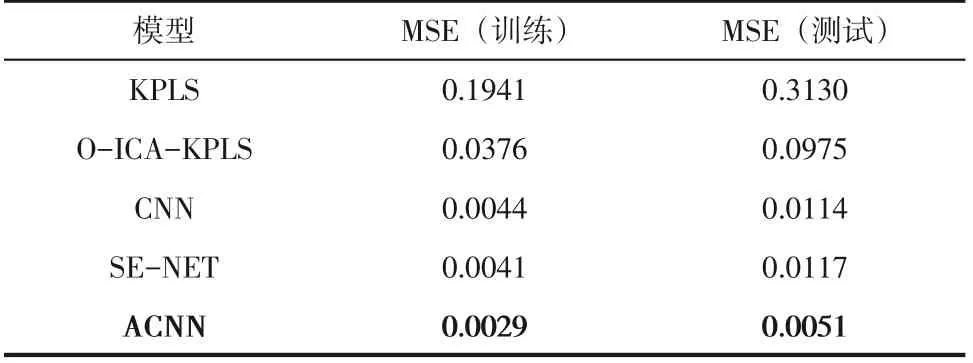
表4 不同方法R-22過程質量預測結果比較
為了更為直觀地展示性能的提升,R-22 真實值、ACNN 預測值和常規CNN 預測值如圖5 所示。可以發現,ACNN和常規CNN均能夠在一定程度上跟蹤質量變化。其中,ACNN擬合更為精確,尤其對第23、52、89 個點上的強烈跳變也做出了準確的預測。相比之下,常規CNN 在整體擬合趨勢上出現偏差,且在部分點響應遲鈍。總體而言,ACNN質量預測結果具有更高的準確性,能夠更加準確地反映時變特性對產品質量的影響。
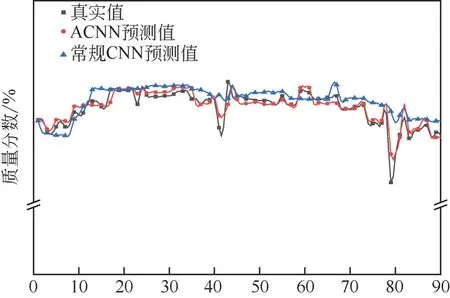
圖5 R-22真實值、ACNN預測值和常規CNN預測值的、比較(根據保密協議,不顯示縱坐標具體取值)
4 結論
為了提高復雜非線性與強時變特性耦合的氟化工過程的質量預測性能,克服質量變量測量滯后的局限性,本文提出了一種具有輸入數據注意力機制的卷積神經網絡(ACNN)的質量預測方法。通過引入輸入數據注意力機制,達到無需先驗知識即可針對性地提取原始數據中復雜時變特性的目的,克服了卷積神經網絡輸入矩陣尺寸單一而無法準確跟蹤復雜時變特性的缺點。同時,針對工業數據特點,構造的長方形卷積核和池化層進一步提高了ACNN 的特征提取能力。該方法在TE 模型中進行了初步的驗證,在異常波動狀態下的MSE 為0.013,遠優于常規CNN 和SE-NET。在氟化工R-22 過程的應用結果表明,在無任何先驗知識的情況下,ACNN的特征提取能力明顯優于常規CNN和SE-NET,取得更佳的質量預測結果,在總體預測和其中強烈跳變點的結果上更為可靠。以上結果證明,該方法的泛化性良好,可推廣到具有強時變特性或波動特征的實際工業過程,具有良好的工業應用前景。雖然深度學習模型的訓練過程中參數量過大,對計算機硬件的要求較高,是制約其工業應用的最主要原因。但是,隨著產業轉型升級,控制系統的更新換代,深度學習先進控制方法必定在工業控制領域大放異彩。
猜你喜歡
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
中學生數理化·中考版(2020年10期)2020-11-27 01:59:48
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中國生殖健康(2019年2期)2019-08-23 08:12:08
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
汽車觀察(2016年3期)2016-02-28 13:16:26
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
