基于數據分析的打葉復烤流量控制方法
2022-03-09 01:49:42王一夫王濤周鵬飛
科技與創新 2022年4期
王一夫,王濤,周鵬飛
(昆明卷煙廠,云南 昆明 650000)
1 研究目的
在打葉復烤生產中,流量、水分和溫度是最基本也是最重要的物理控制量[1],而流量是否穩定,對復烤成品工藝控制尤為重要。與打葉工序的流量控制不同,復烤機內部多采用恒速網板的輸送方式,因此流量波動一般通過測定入口流量來判定。
現代打葉復烤工業中一般采用綜合流量控制系統,即結合了以定量管和電子秤為核心的體積流量控制和質量流量控制方法[2]。其中就質量流量控制方法而言,多是利用PLC 進行PID(Proportion Integration Differentiation)運算,這種控制方式在工業中的應用極為廣泛,在被控對象的數學模型不能完全確定的情況下,依然具有簡單、穩定、可靠的特點,通過計算所得出的比例、積分、微分線性組合,有效地控制系統的誤差。
但經典的PID 算法也存在明顯的缺點:PID 控制屬于一種閉環控制系統,在檢測到誤差時,算法將誤差與設定值進行對比并計算出控制量,再將控制量反饋給輸入以達到控制效果。考慮到計算速度和輸入的波動大小,這種算法存在不可避免的調節過度或調節滯后現象。
近年來,針對煙草工業流量控制的研究不斷增加,但多以體積流量控制為主,通過最小二乘法、模糊控制等系統控制理論對計量管前端的提升喂料機進行控制方法的改進。但實際應用中,體積流量控制本身不具備精確性和穩定性,因此往往與質量流量控制搭配使用,可以簡單理解為對煙料輸送過程的粗調和微調環節。而關于質量流量控制方法的研究則極為少見,究其原因也是由于目前使用的PID 改進算法可以達到較高的精度和穩定度,且多是采用采購標準件的緣故。隨著數據時代的來臨,基于數據分析的控制方案靈活簡單,且具有學習能力,而云計算服務的興起更是為數據分析提供了更經濟的解決方案。
2 算法策略
基于數據分析的控制系統其核心在于如何通過歷史采集的輸入數據和控制數據判定當前誤差所需給出的控制量[3]。解決這一問題的過程可分解為兩步:第一步是將歷史采集的控制量與誤差值一一映射,第二步則利用訓練好的控制算法來預測當前誤差值所需給出的控制量。這一方法的特性,是無需確定系統的實際數學模型和模型特性,僅利用系統的輸入和輸出即可實現控制功能。
上述方案即人工神經網絡的算法思想。神經網絡依靠許多個神經元模型,并通過帶有權重的連接方式相互傳遞,當某一個神經元收到的所有輸入突破激活函數時,該神經元便會釋放輸出,這就是經典的“M-P神經元模型”。無數的單個神經元多通過某種特定的連接方式,即構成了多層神經網絡,當滿足激活特性時,低層次的神經元將向高層次的神經元進行輸出,以逐層引出更高階的統計特性。每一層的輸入都是上一層級的輸出,最后一個輸出層給出的輸出信號對應于第一個輸入層的輸入信號。
傳統的模式識別技術需要建立觀測環境模型,通過對系統地觀察建立模型后再利用已測得的數據測試模型的穩定性和有效性,最后利用固定的模型對所有新的數據進行分析。由于實際使用過程中的誤差和干擾,這一模型往往難以維持在穩定狀態。而人工神經網絡的策略完全相反,在對大量的輸入輸出信號進行學習后,網絡會對一個新的數據進行分析并給出適當的輸出值;而誤差和干擾也可以加入網絡的學習,使得網絡有效地辨別實際輸入信號和策略誤差及干擾。在對歷史數據和干擾進行學習后,利用新的數據不斷修正人工神經網絡的輸出結果,對系統進行測試。
在流量控制系統中,一組固定時間內進行采樣統計的實際質量與設定質量的誤差和控制量構成了一組輸入輸出對,而大量的輸入輸出對構成的數據庫則組成了神經網絡的訓練樣本。針對這些樣本進行訓練,需要穩定的學習規則。
其中,誤差逆傳播算法(即“BP 算法”)是最具代表性的神經網絡算法。上文提到,神經網絡中的各個神經元之間需要通過某種規則相互聯系,這種聯系在神經網絡中被稱為隱藏層。BP 算法的原理,是通過將外界輸入處理為向量的形式,傳遞到輸入層神經元中的向量信號在隱藏層中進行信息的交流和變換,然后輸入到下一層級的神經元,當最后一個隱藏層的信號輸出后,該信號作為輸入傳遞到輸出層的每個神經元中,這就完整地形成了一次正向傳播過程,而當實際的輸出與理論值對比出現誤差時,就進入了逆向傳播階段。通過計算輸出值與理論值的誤差,從輸出層往輸入層的方向逐步修正各層神經元的誤差和加權值,直到與輸入層的數據相匹配,這就形成了一次BP算法的循環。通過不斷地校正這種神經元誤差和連接加權的方法,達到學習的效果,直到將誤差值減少到預設的目標。這種算法的時間速率是不變的,越多的數據意味著越多的學習循環,而越多的數據和學習循環也意味著越多的修正過程,即越長的學習時間,收斂速度就越慢。因此,面對大規模的數據,BP 算法存在耗時長、響應慢的特點,在需要實時響應的流量控制過程中,這一方法顯然不適用。另一方面,加權值的確定是一個逐漸收斂的過程,即便收斂到某個確定的值時,也并不意味著這個值相對誤差平面全局最小,從而陷入了局部最優。
針對這兩個問題,算法策略的改進方向即可確定為縮小訓練時間并提高測試準確率。極限學習機(以下簡稱“ELM”)是近年來提出的另一種新型前饋神經網絡模型,ELM 采用隨機輸入加權值和隱藏層偏執值的方法,將系統看作線性模型,通過求解廣義矩陣得到輸出權重,最終把問題轉換為簡單的線性回歸算法[4]。ELM 采用隨機輸入加權值和隱藏層偏執值的方法,將系統看作線性模型,通過求解廣義矩陣得到輸出權重,最終把問題轉換為簡單的線性回歸算法,從而極大地縮短訓練時間,其基本表示式為:

將訓練數據集輸入ELM 隱藏層的神經網絡后,即可得到狀態轉移矩陣H,再求出逆矩陣β。當訓練達到預設的次數或是誤差以降低至預設范圍內時,學習停止。
與BP 算法不同,ELM 隨機選擇輸入層至隱藏層間的加權值和隱藏層各神經元的偏差值,已大幅度地提高學習效率,減少訓練時間。而由于輸入層至隱藏層間參數選擇的隨機性,為了保障輸出的準確度,則需要相應的增加隱藏層中的神經元數量。如此一來,便將非線性系統簡化成為一個線性系統求解。
對400 組輸入輸出數據進行學習,并參照20 組數據進行測試,采用ELM 得到的結果如表1 所示。
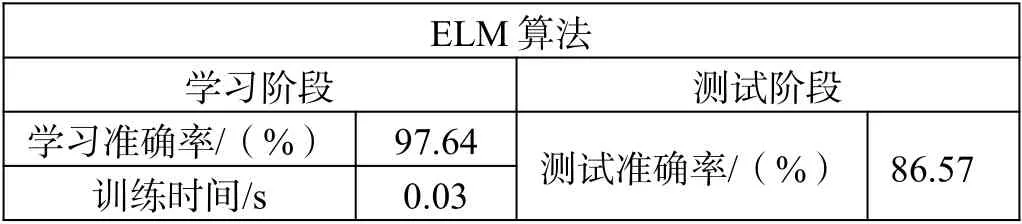
表1 ELM 算法學習測試結果
根據表1 的數據可以看出,ELM 僅需要極端的訓練時間,便可保障較高的學習準確率,但測試準確率較低,算法需改進。
3 算法改進
ELM 在輸入層至隱藏層間隨機選擇加權值的特性,許多非必要的輸入反而以更高的加權值進入了隱藏層中,為接下來各層的偏差值校正提高了難度,需要不斷增加隱藏層的層數和隱藏層中神經元的個數以提高準確度。因此,使得算法在隱藏層中準確找到最優路徑和最優參數并得到最優解是提高測試準確率的重要切入點,即求解組合優化問題[4]。
模擬退火算法是一種全局搜索算法,能有效避免算法在局部最小或最大中滯留,是一種經典的求解組合優化問題算法。
在求解組合優化問題時,首先給定一個較大值t,并隨機給定解i,將其作為初始解。在給定t的情況下,再隨機給定解j,j∈N(i),N(i)是i的領域,則從解i到j的轉移概率為:
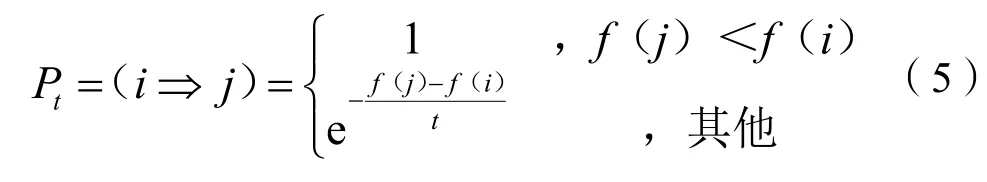
如果解j被接受,則代替解i成為新的解,否則保留原來的解i,該過程重復至在控制參數t下平衡。在進行足夠多的狀態轉移后,需將控制參數t緩慢下降,再在新的參數t下重復以上過程,直到參數t下降到足夠小,最終得到的結果即為組合優化問題的一個最優解。

可看出,模擬退火算法為兩層嵌套的循環結構,以隨機求解的方式達到全局搜索的效果,與局部搜索方法最大的不同是,該算法會隨機接受一些較接近指標函數的解,在開始時,幾乎不可能找到最優解,但隨著控制參數t的下降,找到最優解的概率也在上升,如此一來,就避免了算法從局部中求解的局限性,轉而在全局中求解。
ELM 通過對訓練數據集進行訓練確定算法中的各個參數,參數的差異決定了準確率的大小。因此,利用模擬退火算法全局搜索的特性,可以對參數的選擇進行優化。這里采用模擬退火算法對ELM 的改進步驟進行說明。
首先給出指標函數f(i)。這里將訓練樣本的方差作為指標函數進行評價,以代表誤差水平較為合適,即:
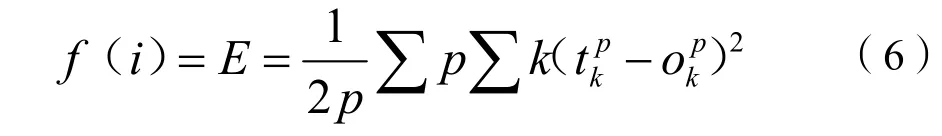
預設誤差小于等于Em,下降系數a=0.97,則參數tk+1=atk。

4 結論
通過表2 的數據結果可以直觀地看出,在選擇了模擬退火算法對神經網絡的兩種學習方法參數進行改進后,測試準確率均有了明顯的提高。BP 算法的準確率雖然優于ELM,但訓練時間明顯較長,不符合實際使用情景。
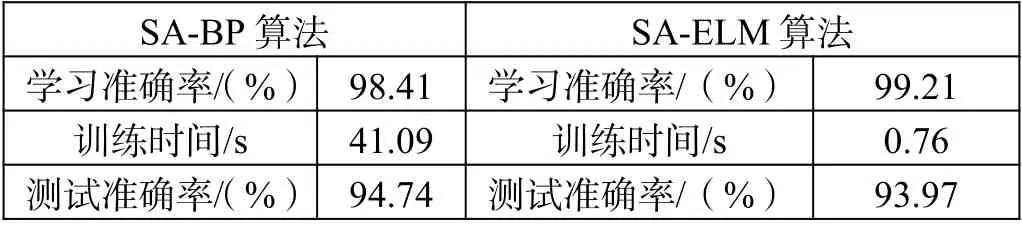
表2 改進后的BP 算法和ELM 學習測試結果
本文基于數據分析的打葉復烤流量控制方法,對比其他文獻中所使用的改進PID 方法或者模糊控制方法等基于經典PID 的流量控制方法,提出了一種新的控制思路。最終的測試準確率已達到較高的水準,這也證明了利用數據作為控制手段是可行的,而隨著歷史數據的增加和學習方法、優化算法的進一步改進,準確率仍能進一步提高。
雖然基于數據的流量調節具有快速實時、可學習進步、算法優化方便等優點,但硬件購置或是采用云計算的解決方案成本仍然過高,在未來硬件技術的飛速進步和互聯網概念的高速發展趨勢下,經濟性的成長也將持續拓寬數據的利用價值。另一方面,本文提出的方法與現有廠家標準調控方案相比,尚未考慮設備測量誤差和機械運作對系統帶來的干擾,期望更多的專家學者能夠補足這一短板,實現更大的突破。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
