自動駕駛汽車外顯界面對過街行人的行為影響研究
2022-03-09 01:50:34陳寧秦華褚英帆張然
科學技術創新 2022年4期
陳寧 秦華 褚英帆 張然
(北京建筑大學機電與車輛工程學院,北京 102616)
隨著自動駕駛汽車行業的迅速發展,預計在不久的將來,在公共交通中引入完全自動駕駛汽車將成為現實[1]。在這種情況下,今天的行人將很難再依賴于駕駛員行為中的線索去選擇是否過街。為了實現未來自動駕駛汽車與行人之間高效、安全的交互,以及自動駕駛汽車如何將其意圖傳達給行人,由此設計了很多種車輛外部接口[2],也就是自動駕駛汽車的外顯界面,它能將車輛的模式和內容與行人進行通信,很好的代替了傳統車輛中駕駛員的行為線索。目前為止,自動駕駛汽車外顯界面有許多種表現形式,比如文字、圖案等,此前有許多人研究這些表現形式對行人過街行為的影響[3]。例如文字溝通形式適用于呈現簡短、明確的信息,研究者常用文字信息向行人呈現當前車輛狀態、意圖或對行人的指示。文字信息不需要被刻意地學習, 能更明確地傳達車輛的讓行意圖, 且更具說服力, 也讓行人感覺更安全;圖標界面溝通方式多采用簡單圖像呈現交互線索, 按照呈現的圖形特點可以分為兩種類型:擬人化/非擬人化圖形;靜態/動態圖形[4]。與非擬人化的圖形相比, 擬人化圖形,能夠更明確傳達有關當前過街是否安全的信息(Fridman et al.),研究者們還發現, 靜態信息在可識別性和信息傳遞效果方面都不如動態圖形(Othersen et al.),并且此類界面的可理解性需要通過培訓才能被提高。此外,信息呈現角度同樣有研究表明,自動駕駛汽車外顯界面的信息可分為兩類[5]:涉及行人的信息以及涉及自動駕駛汽車為中心的信息。例如在某個特定的場景中以行人需要過街為背景,如果外顯界面提供了一個以汽車為中心信息,行人首先需要解釋自動駕駛汽車將要做什么,然后才能決定行人是否可以過馬路。相比之下,如果外顯界面顯示以行人為中心的信息,行人可以直接遵守該信息[6]。因此,我們預計以行人為中心的信息將被視為比以汽車為中心的信息更清晰。但是目前尚不清楚自動駕駛汽車是否應指示其狀態或行人要求采取的行動[7]。綜上所述,目前外顯界面與行人交互的研究大都集中在國外,且研究內容相對分散并未將外顯界面的多方影響因素進行整體性的研究,國內更是鮮有此類探究。本研究則是從呈現形式和呈現角度兩個研究因素出發,通過多維度評價指標進行了整合性分析,為未來實現完全自動駕駛提供外顯界面在呈現內容的設計提供新的視角和方向。
1 研究方法
考慮到當前自動駕駛汽車外顯界面的呈現形式中文字、圖案的研究比較廣泛,本研究就針對自動駕駛汽車外顯界面中文字、圖案、圖文結合這三種不同的呈現形式以及以汽車為中心和以行人為中心兩種不同的呈現角度一共設計了6 組實驗。6 組實驗都是自動駕駛汽車給行人讓行的意圖,但其中也加入了不讓行的設計,是為了避免行人每看到一個呈現內容都會選擇過街的效應。實驗過程分為:(1)采用綠野仙蹤實驗法;(2)當每個參試者完成一組實驗需要填寫一份問卷,一共6 組實驗全部完成需要填寫6 份問卷;(3)在后續還會進行一個焦點小組訪談。
1.1 參試者
本次實驗共有10 名參與者,分為7 名男性和3 名女性,年齡從22 歲到26 歲(標準差為1.18 歲,方差為1.39 歲),構成最終樣本。參試者通過校內招募,被試需滿足:(1)無自動駕駛使用經驗;(2)視力良好;所有參與者隨機被安排實驗順序,并且均是簽完書面知情同意書并獲得了金錢補償。
1.2 實驗平臺
如圖1 所示,本次實驗所用的設備為一輛模擬自動駕駛汽車與放置在車頂的LED 顯示屏(長為80cm,高為16cm 的全彩LED顯示屏,分辨率為80*16)。如圖2 所示,實驗在校內封閉道路進行。實驗道路長度為100 米,寬度為3 米的雙車道,道路兩頭會設置路障柱將道路封閉。如圖3 所示,本次實驗所用的汽車是采用“綠野仙蹤”實驗法模擬的自動駕駛汽車,將車上的駕駛員用一塊黑布擋住,只露出兩個眼睛,這樣就能達到從行人的視角來看是無駕駛員操作汽車,同時車上會坐一位安全員,目的就是為了模仿自動駕駛汽車的行駛狀態。

圖1 實驗車輛和LED 顯示屏

圖2 封閉實驗道路

圖3 綠野仙蹤實驗法
1.3 實驗變量
研究有兩個自變量,分別是外顯界面不同的表現形式,文字、圖標、圖文結合相結合三種表現形式;車輛信息呈現的角度,以汽車為中心和以行人為中心這兩種角度進行研究。
實驗場景基于交通路口,行人與自動駕駛車輛交互時,自動駕駛汽車呈現信息,行人做出行為反饋。由此,實驗參數設計如下:

表1 LED 外顯界面6 種不同的呈現內容
1.4 評價指標
客觀評價指標:將參試者在面對6 組不同的外顯界面呈現內容時過街的平均通過時間以及通過率作為客觀指標進行分析。
主觀評價指標:為了對自動駕駛汽車外顯界面有一個主觀評價,從黎蘭平的自動駕駛汽車車外人機交互界面設計研究中引入了簡單明確性、熟悉性、一致性、舒適性這四個評價標準,并對外顯界面整體的呈現進行一個總體評價。其中簡單明確性、熟悉性、一致性、舒適性這四種評分標準為(1-5 分);總體評價的評分標準為(1-10 分),分數越高代表越好。
1.5 實驗過程
首先,行人閱讀實驗指導書。然后參試者戴好眼罩由實驗員帶到實驗交通路口的道路兩邊進行等候,同時駕駛員需要用一塊黑布將自己遮擋住來模仿綠野仙蹤實驗法,車上還需配備一名安全員,起到保證實驗安全的目的。
車輛從距離行人100 米處開始加速行駛,當行駛到距離行人50 米處時汽車速度需要達到15km/h,然后保持這個速度進行勻速行駛(15km/h 等于4.6m/s,一個成年人正常的過街的步行速度大約為1m/s,所以通過3m 寬的街道大約需要3s,而汽車行駛以15km/h 的速度行駛50m 需要13s,所以即使汽車勻速行駛行人也有足夠的時間穿過街道),與此同時行人需要摘下眼罩,車輛上的LED 顯示屏開始播放需要展示的內容,行人開始觀察車輛上的LED顯示屏所顯示的內容,并且做出自己的過街決策。
每個行人共有6 個實驗任務(分別為以行人為中心的三個任務和以汽車為中心的三個任務),每完成一個任務時行人都需要重新返回起點處進行準備下一次的實驗;汽車也需要重新返回到距離行人100 米處的地方開始準備下一次的實驗,直到當完成6 個任務為止,則算是一個行人完成了所有的實驗內容。每個行人遇到汽車上的LED顯示屏所顯示內容的順序都是隨機排列的,并不是每個人都按統一的順序進行實驗。
每個參試者每完成一個任務需要填寫一份問卷,填完之后再進行下一個任務,以此類推到6 個任務都完成并且填完6 份問卷算是任務結束。
2 數據結果
2.1 描述性統計
2.1.1 客觀評價指標
根據表2 可以知道在實驗中通過率最高的為B 任務和E任務,都達到了100%的通過率,并且B任務和E 任務平均通過時間最低,都為5.5s。在實驗中通過率最低的為D 任務,只有60%的通過率,并且D 任務的平均通過時間也是最高的,為7.16s。參試者對于3 種顯示方式(文字、圖案、圖文結合)理解最好的為以行人為角度的文字和圖文結合的顯示方式,理解最差的為以汽車為角度的圖案的顯示方式。

表2 客觀評價指標描述性統計結果
2.1.2 主觀評價指標性來說評分最高的為E,評分最低的為D;對于總體評價來說評分最高的為E,評分最低的為D。從上述的分析可以得出在不同的顯示內容中文字和圖標的表現方式的得分最高,而圖標的表現方式得分最低,這就說明對于文字、圖標、圖文結合這三種表現方式來說最能被大家所理解、所接受的表現方式為圖文結合,而大家最不認可的表現形式為圖標。

表3 主觀評價指標描述性統計結果
2.2 方差分析結果
2.2.1 客觀評價指標
由表4 可知,A 顯示方式與D 和F 這兩種顯示方式存在顯著性影響(P=0.003 和P=0.011),B 顯示方式與D 和F 這兩種顯示方式同樣存在顯著性影響(P=0.001 和P=0.004),C 顯示方式與D顯示方式存在顯著性影響(P=0.045),D顯示方式與A、B、C、E 這四種顯示方式存在顯著性影響(P=0.003、P=0.001、P=0.045、P=0.001),E 顯示方式與D 和F 這兩種顯示方式存在顯著性影響(P=0.001 和P=0.004),F 顯示方式和A、B、E 這三種顯示方式存在顯著性影響(P=0.011、P=0.004、P=0.004)。
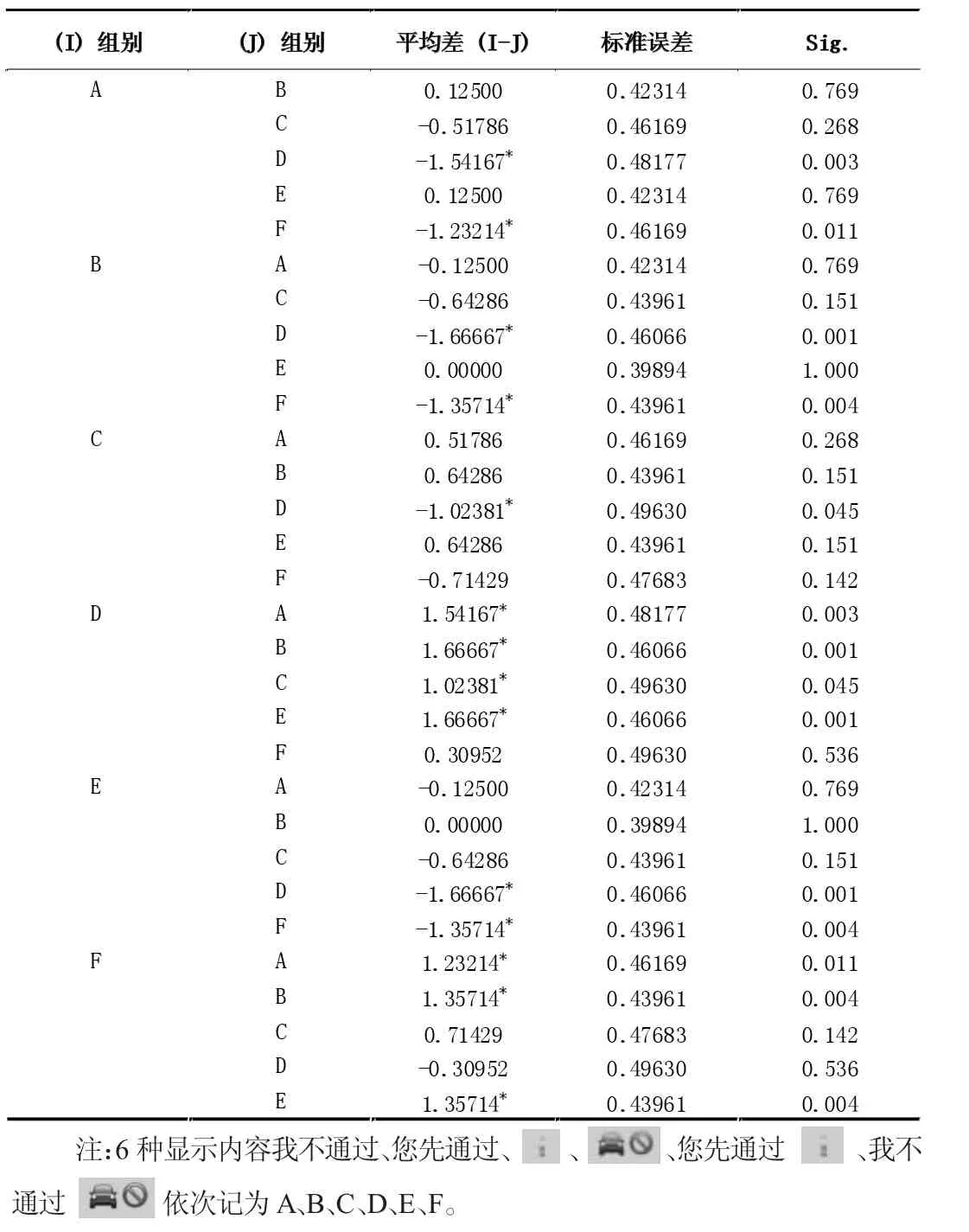
表4 客觀評價指標方差分析結果
2.2.2 主觀評價指標
在利用此次實驗結果進行的方差分析可以看出,在對于外顯界面文字、圖案、圖文結合三種不同的顯示方式和以行人為中心和以汽車為中心兩種不同的顯示角度的結果如表5 所示。其中在簡單明確性中顯示方式和顯示角度都具有顯著性影響(P=0.000 和0.008),在舒適性中顯示方式和顯示角度都具有顯著性影響(P=0.009 和0.033),在熟悉性中顯示方式具有顯著性影響(P=0.013),但顯示角度不具有顯著性影響(P=0.551),在一致性中顯示方式具有顯著性影響(P=0.006),但顯示角度不具有顯著性影響(P=0.075),在總體評價中顯示方式具有顯著性影響(P=0.022),但顯示角度不具有顯著性影響(P=0.135)。
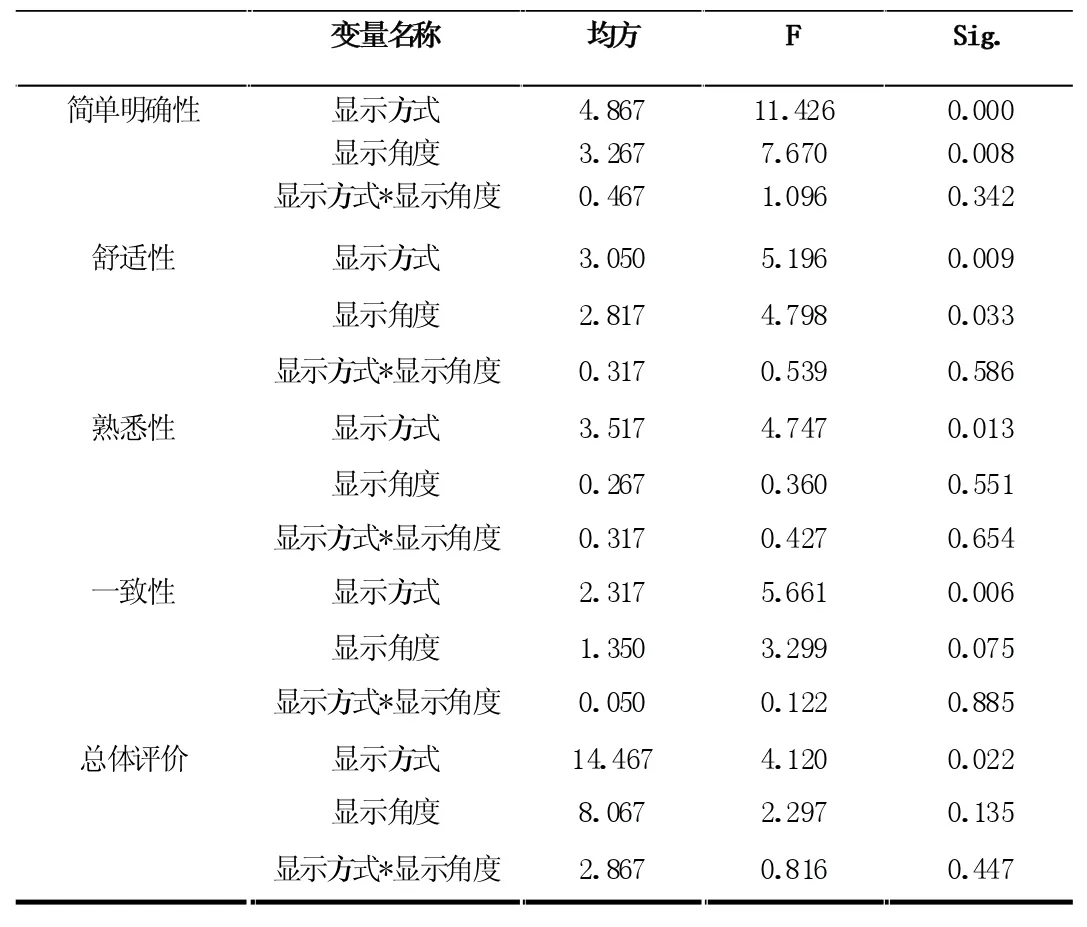
表5 主觀評價指標方差分析
3 分析與討論
本研究通過實驗考查了自動駕駛汽車外顯界面不同的顯示方式以及顯示角度對行人過街決策產生的影響以及找出最優外顯界面的呈現方式及呈現角度。
根據客觀評價指標描述性統計結果可知,以行人為角度的文字的呈現方式效果最好,根據Schubert 的研究可知行人對外顯界面提供的信息有一個認識和理解的過程,文字的優勢在于語言是人們日常使用的交流工具,外顯界面的呈現方式用文字能夠起到通俗易懂的作用。以汽車為角度的圖案的表現形式效果最差,根據Sucha,M[12]的研究可知呈現的信息為圖案時,如果未經學習過含義的模糊性就比較高,并且當交互界面顯示的是圖案時,行人無法參考先前的經驗進行解讀,而且以圖案這種表現形式來看,行人往往更能理解擬人化的圖案,所以以汽車為角度的圖案的表現形式效果較差。
從簡單明確性、舒適性、熟悉性、總體評價這四個方面來看,根據主觀評價指標描述性統計結果可以看出效果最好的為圖文結合的顯示方式E,這結果與Pavlo Bazilinskyy[13]等人的研究結果一致,這是因為圖文結合的顯示方式更能給行人清晰、明確的信息,而且簡單的圖文結合能夠讓行人更容易明確自動駕駛汽車所傳達出的意圖;從一致性來看,根據主觀評價指標描述性統計結果可以看出效果最好的為文字顯示方式B,這和Chang C[10]等人的研究是一致的,是因為B這種顯示方式通過外顯界面所傳達出來的意思和參試者所理解的意思最為相近,直截了當的指明了汽車的意圖。從簡單明確性、舒適性、一致性、總體評價這四個方面來看,可以看出效果最差的為圖案的顯示方式D,這結果與Stefanie M.Fass[14]等人的研究結果一致,光給出一個圖案對于行人來說并不是很好理解,反而會導致行人做出錯誤的判斷,最理想的呈現信息為汽車狀態+意圖;從熟悉性來看,可以看出效果最差的為圖案的顯示方式C,這是因為參試者在生活中對這種圖案并不常見,導致在實驗的時候對此圖案感到比較陌生,并且很難理解這個圖案所傳達出來的信息。
根據客觀評價指標方差分析結果可知,A 和B 這兩種顯示方式都與D 和F 這兩種顯示方式存在顯著性影響,根據Beggiato[15]的研究可知單獨放圖案或者用圖文結合的方式時會增加會使得行人很難理解外顯界面所傳遞出來的意圖并且增加行人的認知負荷,而且文字信息不需要刻意去學習,能更明確的傳達車輛的意圖,且更具有說服力,也能讓行人感覺更加安全,并且研究者常常僅使用文字信息向行人傳達車輛狀態,因此行人在面對文字時的通過率是高于圖案的。C這種顯示方式與D這種顯示方式存在顯著性影響,由于圖案是根據研究者們的設計而人為后期賦予的,行人在實驗前并沒有學習過此類圖案的含義,因此此類界面的可理解性和清晰性需要通過培訓才能被提高,E 顯示方式與F 顯示方式也存在顯著性影響,根據蔣倩妮[9]的研究可知向行人傳達過街指導或建議信息,支持行人過街決策,相比于車輛的狀態和意圖信息,在人車交互的過程中更適合呈現行人的建議信息。
根據主觀評價指標方差分析可以知道從熟悉性、一致性、總體評價這三個方面來看顯示角度對行人過街決策并沒有顯著影響。從黎蘭平[8]等人的研究可以知道,外顯界面呈現內容對顏色有很大的影響,也就是外顯界面的顯示內容在色彩設計時應該與當前的交通系統一致,比如指示行人可以通行時應設置為綠色的內容,而禁止行人通行時則應設置為紅色的內容,以免造成行人的困惑;根據Strawderman,L.J[11]的研究可知在設計圖案時應該用交通系統中常見的圖形,比如斑馬線或者綠色的步行的行人等,這樣能夠更準確的傳達信息,由于參試者對于本實驗中從兩個呈現角度設計的圖案都比較陌生,在未提前經過培訓的情況下很難理解,這樣就會導致參試者在實驗過程中對這兩種圖案所傳達的意思產生理解偏差。
本研究還存在一定的局限性:(1)本次實驗只進行了文字、圖案、圖文結合三種顯示方式去實驗,未來還可以考慮加入比如擬人化表情、仿聲學等方式去進行實驗;(2)本實驗是在真實場地進行的,在行人處于或接近車輛軌跡時為了保證行人的安全,車輛必須停止,且出于道德標準實驗車輛不能包含任何不屈服車輛,未來可以在模擬平臺上可以整合不屈服車輛進行實驗。
4 結論
本次實驗探究了自動駕駛汽車外顯界面對行人過街決策的影響,結果表明:
4.1 在主觀評價指標中最好的呈現方式為圖文結合,角度為站在行人角度,也就是E 這種表現形式;效果最差的呈現方式為圖案,角度為站在汽車的角度,也就是D。
4.2 在客觀評價指標中最好的呈現方式為B,最差的呈現方式為D。
實驗結果可以為未來自動駕駛汽車外顯界面的設計提供參考, 未來自動駕駛汽車外顯界面可以設計成文字或者圖文結合的表現形式,這樣更能方便行人去理解自動駕駛汽車所傳遞出的意圖,最好不要用圖案這種表現形式,因為行人對于這種表現形式的理解最差。未來研究方向:本次實驗做的為單人單車的實驗,未來可以考慮進行單人多車、多人多車的實驗。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
當代陜西(2020年13期)2020-08-24 08:22:02
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
兒童時代·快樂苗苗(2017年7期)2018-01-24 18:28:45
制造技術與機床(2017年5期)2018-01-19 02:49:17
濰坊學院學報(2016年2期)2016-12-01 13:00:11
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
作文大王·低年級(2016年4期)2016-04-18 00:24:37
新聞傳播(2015年11期)2015-07-18 11:15:04
