基于小樣本數據和深度殘差網絡的月度供電量預測研究*
2022-03-17 10:18:26尹力周琪
計算機與數字工程 2022年2期
尹 力 周 琪
(國網武漢供電公司 武漢 430070)
1 引言
區域供電量預測是電氣工程領域的一項基本工作,國內外已在該領域開展了多年的研究[1]。根據預測原理的不同,預測方法可概括為簡單數學推理法、傳統數學模型法和人工智能預測法三類。簡單數學推理法有專家預測法、綜合用電水平法、單耗法、彈性系數法、負荷密度法、平均增長率法、類比法、指數平滑法等[2]。簡單數學推理法,能夠對未來供電量情況做出初步預測,但卻由于預測精度不足,現已很少采用。第二類為傳統數學模型法,采用更為復雜的預測模型,能夠得到較高的供電量預測精度,主要包括時間序列法[3]、回歸分析法[4]、趨勢外推法[5]等。第三類為人工智能預測方法,包括以各類神經網絡為主的機器學習預測方法[6~9]、支持向量機預測法[10]等。
其中,隨著人工智能技術的飛速發展,人工智能在供電量預測方面的研究受到了越來越多的關注。然而,以深度學習為代表的人工智能方法,需要大量的、標準化的樣本集完成模型的訓練。因此,在供電量預測樣本準備中,需要完整的小粒度歷史統計數據,包括按天統計的供電量數據、天氣數據等。這種小粒度樣本的準備,將極大增加統計工作量,并且可能由于歷史數據的部分缺失,造成模型訓練精度下降。
針對上述問題,本文提出了一種基于歷史供電量月度統計數據,及少量按天統計的輔助數據的樣本增強方法,實現了樣本集的有效擴充;同時通過構建深度殘差網絡,解決預測模型訓練過程中的網絡退化問題,有效提高了模型的訓練效率和預測精度。
2 樣本增強
采用優化的生成對抗網絡,實現以將全序列按月統計的供電量數據,結合少量按天統計的數據,模擬生成每天的供電量數據,實現樣本空間的小粒度解析。
2.1 生成對抗網絡
生成式對抗網絡(Generative Adversarial Networks,GAN)是一種深度學習模型,由生成模型(Generative Model)和判別模型(Discriminative Model)兩部分組成,通過兩部分的相互博弈,使生成模型的輸出不斷優化,直至產生滿足應用需求的模型輸出。

2.2 網絡優化
傳統的GAN 模型,輸入為隨機噪聲,生成的圖片具有一定的隨機性,模型無法應用于供電量的預測,需要對模型進行修改、優化。考慮和供電量預測最為密切相關的幾個因素,分別為歷史同期供電量參考、預測時間段天氣情況,因此輸入需在傳統GAN 輸入的基礎上加上5 個維度:歷史供電量、日期、天氣(包括平均溫度和平均降雨量)、該日期所在月份供電量數據,重新構建GAN 深度學習模型。優化、改進后GAN的結構如圖1所示。
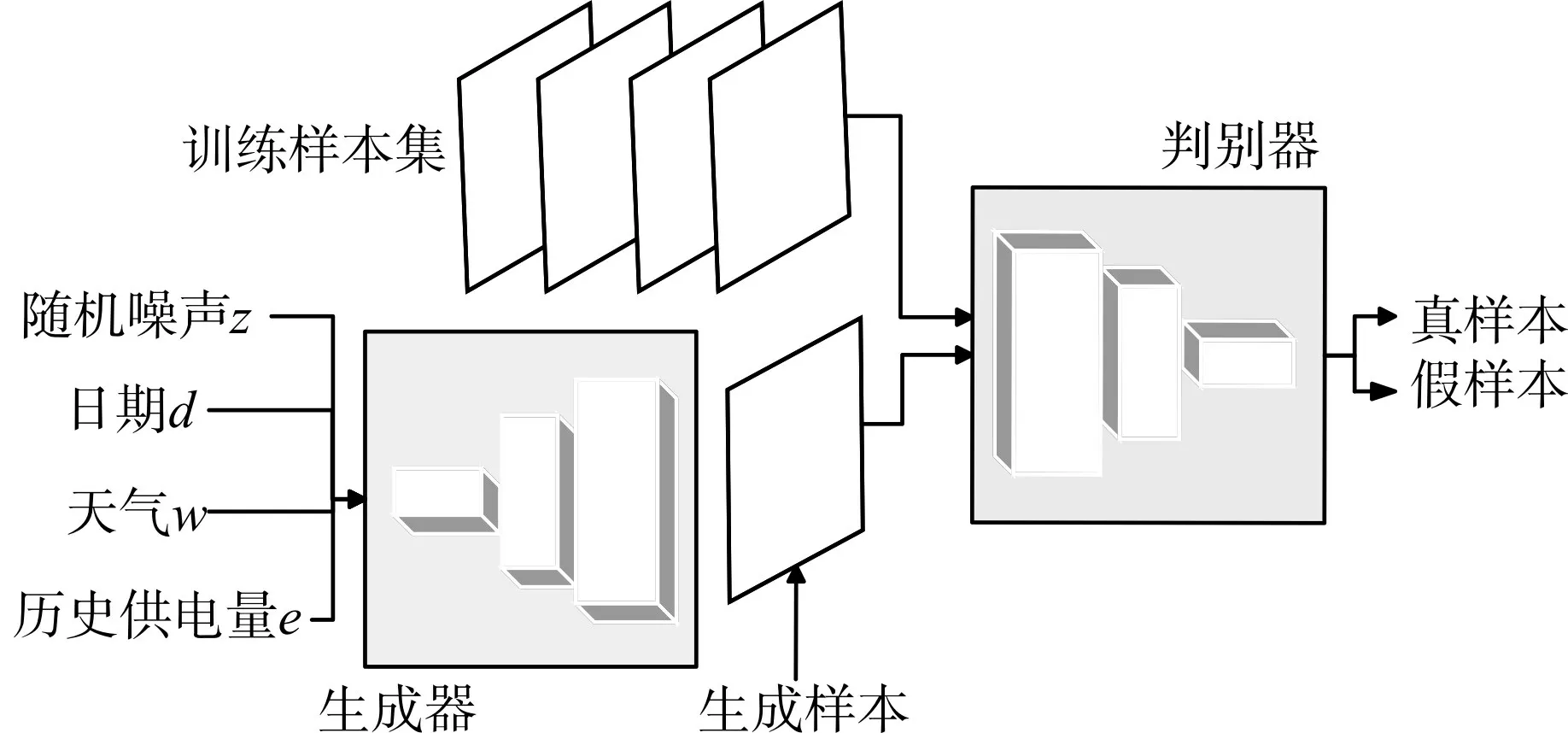
圖1 改進GAN的結構圖

2.3 樣本集構建
需要構建專門的樣本集,用于上述改進GAN的訓練。樣本集應包括供電量信息、時間信息和天氣信息。以天為單位來制作樣本,每個樣本包括當天的供電量信息,日期信息以及天氣信息。其中,供電量信息直接以數值表示;日期信息取值區間為[1,365],標識按時序計量的一年中的每一天;天氣信息,統計最為重要的溫度信息和降雨量信息。因此,樣本集中的每一個樣本可用列向量表示:
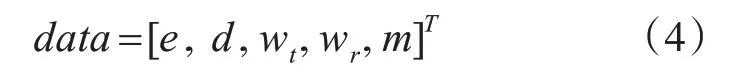
式中,e表示該天供電量信息的具體數值;d取值[1,365]區間,標明日期信息;wt為該日期全天平均溫度的數值信息;wr為該日期全天平均降雨量的數值信息;m為該日期所在月份的供電量信息。
3 深度殘差網絡
傳統的卷積神經網絡在不斷增加神經網絡的深度時,模型準確率會先上升然后達到飽和,再持續增加深度則會導致準確率下降,這種情況稱之為網絡退化問題(Degradation problem)。深度殘差網絡(Deep Residual Network,DRN)[11]能夠有效解決上述問題。
深度殘差網絡是由多個殘差學習模塊重復堆疊形成的神經網絡,與傳統卷積神經網絡區別在于學習模塊內部結構的不同。通過殘差學習模塊的不同組合方法,可以構建多種不同架構、特性的卷積神經網絡。如在文獻[12]中,殘差學習模塊與Inception 模型結構結合,搭建了Inception-ResNet卷積神經網絡模型,在眾多公開數據集的分類問題上,取得了優異的性能。
3.1 殘差學習模塊
DRNs 模型的核心在于殘差學習模塊,其基本思想為通過在卷積神經網絡單元訓練過程中,保存部分原始輸入信息,從而避免由于卷積層數過多引起的分類精度飽和問題;同時,殘差模塊(Residual Module)不需要學習完整的輸出,只需學習輸入、輸出差別的部分,簡化了學習目標和難度。
設x為輸入,經過卷積層運算后輸出為F(x,W),激活函數采用Sigmoid或ReLU[13],激活函數變換用f表示。因此,學習模塊單元最終輸出可定義為
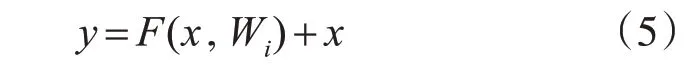
同時,在所設計的殘差學習模塊中,還將采用批歸一化(Batch Normalization,BN)處理技術[14],以提升分類性能。
3.2 深度殘差網絡
每個殘差學習模塊內部包括兩個卷積層,所設計的網絡包括14 個殘差學習模塊,共28 個卷積層。在這28 個卷積層構成的完整神經網絡中,設第n層輸入為xn(1 ≤n≤28),最后總的輸出為y。由于第i層輸出等于第i+1 層輸入,其中(1 ≤n≤28),因此有:
至此,便可構建完整的深度殘差網絡,用于供電量預測模型的訓練。
4 算例分析
實驗采用谷歌公司的開源機器學習框架Tensorflow(V2.0)的Slim 模塊完成基于生成對抗網絡的樣本增強和深度殘差網絡訓練模型的搭建,同時使用GPU 計算加速訓練過程,硬件運行環境選擇為TitanX 顯卡、16G 內存。實驗數據來源于某區域2016 年1 月至2019 年11 月的供電量數據,數據按月度統計,共47組數據。數據情況如圖2所示。
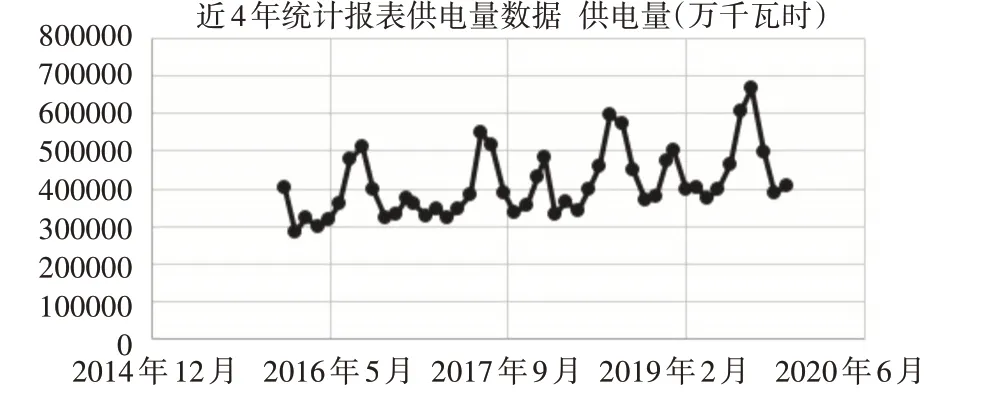
圖2 2016~2019年某區域月度供電量數據
同時,收集了334 天的按天統計的供電量信息,為2019 年1 月~11 月每天的供電量數據。此外,整理了近4 年該區域每天的天氣數據,包括平均溫度與平均降雨量。
將上述數據按照前述方法,整理為樣本集。
4.1 樣本增強實驗
將整理好的334 組樣本分為兩部分:一部分為320組樣本,作為訓練集;另一部分為14組,作為測試集。運用深度殘差網絡進行生成模型訓練,并將訓練好的模型在測試集上計算準確率。模型輸入參數為隨機噪聲z、日期d、該日期其它年份供電量數據e、該天所在月份的供電量信息m。其中,若e在原始樣本集中缺失,則以平均供電量數據代替(月度供電量/該月天數)。
分別在訓練1000 步、5000 步、1 萬步、2 萬步時統計測試集上的平均精度如圖3所示。

圖3 測試集上模型精度統計
如圖3 所示,由于樣本集較小,訓練過程在10000步時,即已達到了94%的模型精度,增加一倍迭代次數后,20000步時精度達到95%,說明生成模型已趨于穩定。
將模型應用于2016 年1 月~2019 年11 月所有日期的供電量數值生成,增強按天統計的供電量樣本。其中1096 天供電量數據缺失,需要運用模型生成。由于這部分生成的樣本數據,沒有真實數據比對,無法直接計算準確率。因此,實驗采用生成樣本(每天的供電量數據)按月匯總求和,并與月度供電量統計數據對比分析的方式,計算準確率。運用訓練20000 步生成的模型,2016 年1月至2018 年12月,各月度供電量樣本精度如圖4所示。
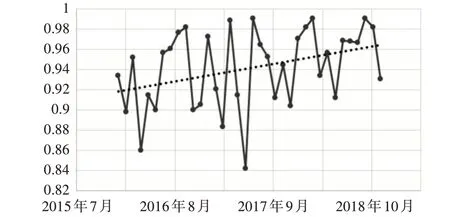
圖4 2016~2018年月度供電量預測精度(生成樣本精度)
每年度的月度供電量平均預測精度統計如表1所示。

表1 2016~2018年每年平均預測精度(生成樣本精度)
由表1 可見,從2016 年~2018 年,生成樣本(每天供電量)的精度逐年攀升,主要由于原始樣本集為2019 年數據,時序上越近的年份,生成的樣本越真實。
4.2 供電量預測實驗
運用前述方法構建的深度殘差網絡,對擴充后的樣本集進行深度學習訓練。擴充后樣本集共1430 組數據,每組數據包含當天的供電量數據、平均溫度數據、平均降雨量數據、當前日期供電量數據,以及該日期所在月份的供電量數據。數據集將分為三部分:一部分為1300 組數據,用于預測模型的訓練;一部分為100 組數據組成測試集,用于評估模型性能;剩下的30 組數據選定2019 年11 月1日~2019 年11 月30 日的數據,用戶最終月度供電量預測精度評估。分別在訓練10000 步、20000 萬步、50000 步和100000 步時,生成預測模型,模型在測試集上精度如圖5所示。
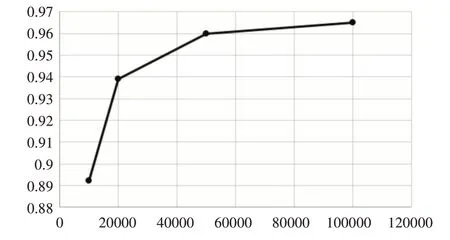
圖5 不同訓練步長的預測模型精度
將模型運用于2019 年11 月的第三組數據,生成30個預測結果,將30個預測結果相加,得到最終2019 年11 月供電量的月度預測結果。重復5 組預測模型訓練,每次訓練100000 步,得到最終的預測結果如表2所示。

表2 月度供電量預測精度統計
上表平均預測精度為95.36%。
為比較采用樣本增強和深度殘差網絡后的模型性能,增加兩組實驗。兩組實驗均不做樣本增強。第一組用傳統的卷積神經網絡(Convolutional Neural Networks,CNN)直接對原始按月度統計的供電量信息進行訓練,訓練生成的模型用于預測2019 年11 月的月度用電量信息;第二組用深度殘差網絡對原始樣本集訓練,同樣用生成模型預測2019 年11月的月度用電量信息。每組實驗重復五次,訓練步長均為100000 步,求得平均預測精度。最終比較結果如表3所示。

表3 月度供電量預測精度比較
比較結果顯示,本論文采用的樣本增強方法和殘差神經網絡用于月度供電量預測,對比同類型的傳統方法,具有較為明顯的優勢。
5 結語
本文提出了一種基于樣本增強和深度殘差網絡的月度供電量預測方法。首先,提出了一種改進的生成對抗網絡模型,通過該模型將所有按月度統計的供電量數據,同分布生成小粒度的按天統計的供電量信息,實現有效樣本的增強,避免深度學習預測模型訓練過程中,由于樣本量不足造成的欠擬合現象;其次,運用深度殘差網絡,對增強后的樣本集實現與預測模型訓練;最終通過不同實驗,驗證并分析了本文所述方法,能夠有效提升同類傳統模型的預測精度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
