相似重復記錄檢測研究與發展動態的知識圖譜分析
2022-03-18 05:01:04董永權
計算機應用與軟件 2022年3期
顧 晴 董永權 胡 楊
(江蘇師范大學智慧教育學院 江蘇 徐州 221116)
0 引 言
隨著信息技術的快速發展和信息化管理的不斷推進,數據庫中的記錄數量呈指數上升,引發了大數據環境下相似重復記錄檢測的需求,是近年來數據挖掘領域的研究重點。大量相似重復數據在整合時降低了數據質量,對數據庫的利用率帶來直接影響。因此,如何高效率地檢測出相似重復記錄是數據清洗的關鍵點和提高數據質量的首要任務。
相似重復記錄檢測是識別出多個數據庫中的同一實體,在不同研究領域中有多種名稱表示,如duplicate record detection、entity resolution和 record linkage等,相應中文名稱有相似重復記錄檢測、實體識別和記錄鏈接等。Newcombe等[1]提出這個概念后,國內外研究者在各個領域進行深入的研究,提出大量的檢測方法,檢測精度也不斷提升。Elmagarmid等[2]總結了當時國外的相似重復記錄檢測技術,從字符、標記、語音和數字四個方面分析相似性度量方法,從機器學習和概率推理兩類技術進行歸納,提出減少記錄比較數量和提高單記錄比較速率兩種提升相似重復記錄檢測效率的方法。自發表至今,一共被引用672次,是目前為止分析最全面、被引次數最多的相似重復記錄檢測綜述。經過之后十多年的積累, 國內外相似重復記錄檢測方法又涌現出相當多的高水平成果,迫切需要對新的文獻加以歸納整理。考慮到簡單的文獻回顧難以客觀分析該領域的作者合作關系、研究熱點及發展趨勢,有必要通過文獻計量和可視化的方式進行探究。
文獻計量方法可以對海量文獻進行可視化分析,得到特定領域的文獻特征,能夠全面分析某一領域的熱點及發展趨勢[3]。社會網絡是指行動者 (個體、群體或組織等) 及其關系的集合[4]。社會網絡分析則是對這些關系數據的分析與研究。科學知識圖譜是結合文獻計量法及信息可視化原理,以科學知識為對象,展示科學知識的演進過程與結構關系的一種圖形表示方法。
本文收集了2008—2019年間國內外對相似重復記錄檢測的相關文獻,分析了發文量的時間分布以及發文核心機構分布。通過社會網絡分析軟件Ucinet對這些論文的作者建立合作網絡圖譜,分析了核心作者群。使用數據可視化軟件CiteSpace對文獻關鍵詞進行聚類,并根據時間脈絡進行分析,呈現出近十年在相似重復記錄檢測問題的知識圖譜,并對其研究熱點和趨勢進行了探究,提出面臨的挑戰,指明今后的研究方向。
1 研究方法與數據來源
1.1 研究方法
(1) 社會網絡分析。社會網絡分析采用Ucinet(University of California at Irvine NETwork)軟件。Ucinet內置大量的網絡指標計算模塊,是一款功能強大的社會網絡分析軟件[4]。最初由社會網絡研究的開創者Linton等網絡分析者編寫,之后由美國波士頓大學的Steve和英國威斯敏斯特大學的Martin共同維護。它可以生成多種可視化圖譜,反映分析對象的結構和關系。
本文將EndNote格式的中文文獻題錄和.txt格式的外文文獻題錄分別導入Bicomb,通過格式轉換后分別創建.txt格式的作者共現矩陣,之后將矩陣導入Ucinet生成.##h文本矩陣,通過對Netdraw的調用產生可視化圖譜,并對社會網絡參數進行中心度等計算。
(2) 知識圖譜分析。知識圖譜采用CiteSpace(5.5.R2)軟件,CiteSpace是由美國德雷塞爾大學的陳超美博士開發的文獻數據可視化軟件[5]。該軟件主要運用共引分析理論對某領域的文獻信息進行計量,通過尋徑網絡算法等方法找出關鍵節點,繪制出相關的科學知識圖譜,實現信息可視化分析[6]。通過它展現的知識圖譜,可以較直觀地顯示該研究學科過往的演化歷程、當今的研究熱點、日后的研究趨勢。迄今為止,CiteSpace被廣泛運用于對文獻的可視化分析。
本文在CiteSpace中將時間閾值設置為“2008”到“2019”, 連線閾值數據對象(Links)強度設為‘cosine’類型,節點閾值(Selection Criteria)中三個時間切片的最低被引次數(citation)、本切片內的共引次數(cocitation)和共被引率(Cocitation cosine coefficient)分別為1、1、20;1、1、20;2、2、20。剪枝(pruning)采用尋徑網絡算法(Pathfinder),filter為1。主要應用CiteSpace的聚類分析(Cluster)、文本主題共現(Term、Keyword),對文獻關鍵詞進行分析,進而總結出相似重復記錄檢測的研究熱點及發展趨勢。
1.2 數據來源
本文采集2008—2019年國內外有關相似重復記錄檢測的相關文獻進行統計分析。采用的外文文獻來源于World of Science(WOS)的核心數據庫,以“duplicate record”“entity resolution”“record linkage”“ record ma-tching”“entity matching”和“record merge”為標題分別進行檢索。中文文獻來源于中國知網(CNKI),以“重復記錄”“記錄匹配”“實體匹配”“記錄鏈接”和“記錄合并”為篇名分別進行檢索。經過相關內容篩選后共獲得153條有效國外文獻記錄和149條有效國內文獻記錄。
2 文獻發文量
文獻的發表數量及其在時間上的分布,可以反映出該研究內容在研究歷史上的被關注程度以及發展情況。將國內外關于相似重復記錄檢測的文獻按照年份繪成發文量年度分布圖(見圖1)。
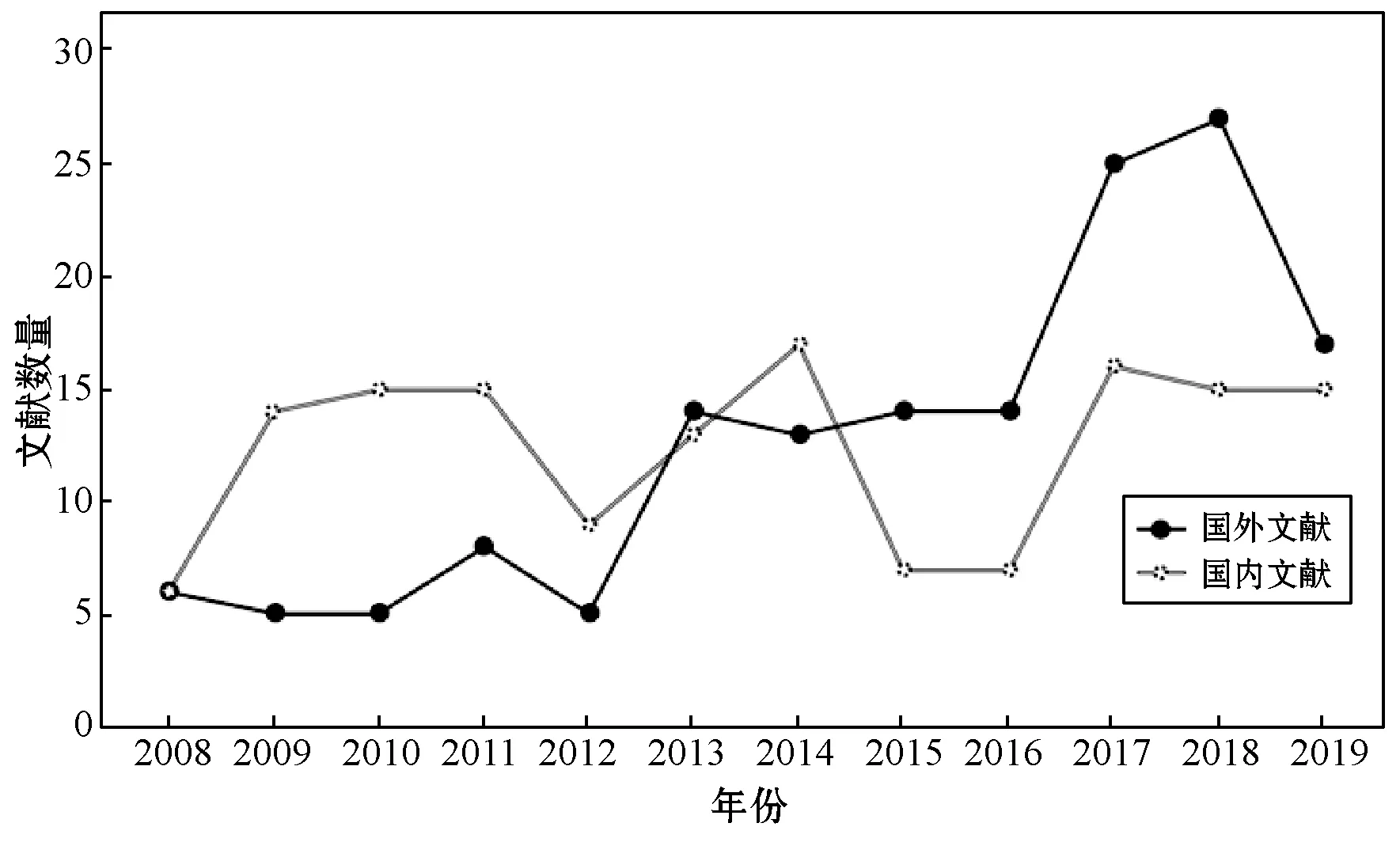
圖1 國內外文獻發文量年度分布
相似重復記錄檢測最早起源于國外,從每年度文獻發表的數量上來看,近10年內國內外相關的文獻發表量總體上逐步上升,這表明近10年國內外在相似重復記錄檢測研究上的關注度呈增長趨勢。從圖1可以看出,2008年到2012年,國外研究經歷了一個低潮期,發文量較少。隨著相似重復記錄檢測應用領域的擴大和檢測技術的發展,自2012年起發文量開始逐步增長,2018年高達27篇文獻。國內近10年一直持續著對相似重復記錄檢測的研究熱情,發文量整體上波動幅度不大,每年穩定在15篇左右。2015年和2016年出現一個明顯的低潮期,但從2017年起,由于深度學習等技術被重新關注研究和發展,以及其在自然語言處理領域的應用,相似重復記錄檢測這一研究又吸引了眾多學者的目光,發文量呈現穩步回升。從整體數量上看,國內外文獻近10年文獻發表量相差不大,但是自2015年起國外文獻數量均高于國內文獻數量。
3 核心研究機構
通過對發文作者所在機構的統計,可以了解相似重復記錄檢測領域研究的核心機構。根據World of Science和CNKI的文獻分析,獲得相似重復記錄檢測文獻發文量排名前五的國內外高產機構如表1和表2所示。

表1 國外文獻高產機構

表2 國內文獻高產機構
2008年以來,發文量并列排名第一的研究機構是澳大利亞國立大學(Australian National University)、谷歌公司(Google Incorporated)和哈爾濱工業大學(Harbin Institute of Technolog)。澳大利亞國立大學偏向于隱私保護的相似重復記錄檢測技術,通過分析各種不泄露隱私信息的方式進行相似重復記錄檢測[7]。谷歌公司發表的8篇文獻中有6篇與斯坦福大學(Stanford University)合作,總被引用次數為341次,提出基于否定規則、web、多個數據集和主動抽樣等一系列通用實體識別模型。哈爾濱工業大學在外文期刊上同樣發表了8篇文獻。希臘開放大學(Hellenic Open University)共發表6篇文獻。
國內在相似重復記錄檢測方面發表文獻最多的是東北大學,發表數量達18篇,對關系數據對象識別、復雜數據空間中的數據對象識別、具有時間特性的數據對象識別、隱私保護下數據對象識別和Deep Web環境下的實體識別研究等方面進行了深入研究。哈爾濱工業大學在國內期刊上發表了15篇文獻,總產量屬于國內外第一位。高紅、李建中、李玲麗和王洪志等相繼做了記錄匹配的動態約束、基于規則的實體解析方法等相關研究。
4 社會網絡分析
White博士[8]認為,作者共現頻率越高,則作者在這一研究領域的學術相關性越強。因此,通過圖譜和網絡結構分析,可以了解相似重復記錄檢測領域的核心作者群。為了更明顯地展示出主要合作團隊,將閾值設為2,使用Bicomb生成作者共現矩陣。共現矩陣導入Ucinet社會網絡分析軟件,生成.##h文件,再進一步借助Netdraw,經過中心性度計算,去掉沒有合作的單節點,生成作者共現社會網絡圖譜(見圖2和圖3)。
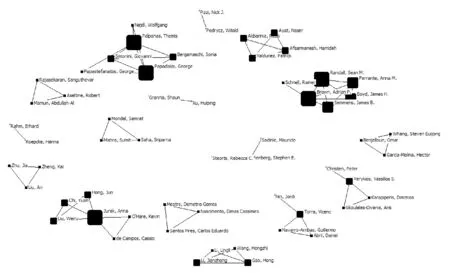
圖2 國外文獻作者合作社會網絡圖譜

圖3 國內文獻作者合作社會網絡圖譜
根據Ucinet統計以及圖2和圖3中的信息,在發表兩篇及以上的作者中有合作關系的外文文獻作者共57位,中文文獻作者共24位,國外形成合作團體共16個,國內共6個,無論是作者數量還是合作團隊數量都明顯多于國內。網絡密度的數值越大則表示網絡中成員聯系越緊密,國外文獻作者合作網絡的密度為0.071 6,國內為0.284, 國外研究學者主要是多個小團體的合作,總體合作情況要優于國內,而國內除了幾個大團體的合作,其他作者之間的合作關系不明顯。整體上看,國內外的作者合作結構都比較松散,作者之間聯系不多。
根據發文量排名前十的作者 (見表3),并結合圖2、圖3的信息可以得出,發文量高的作者擅長團隊合作,因此可以從團隊角度分析其研究內容。
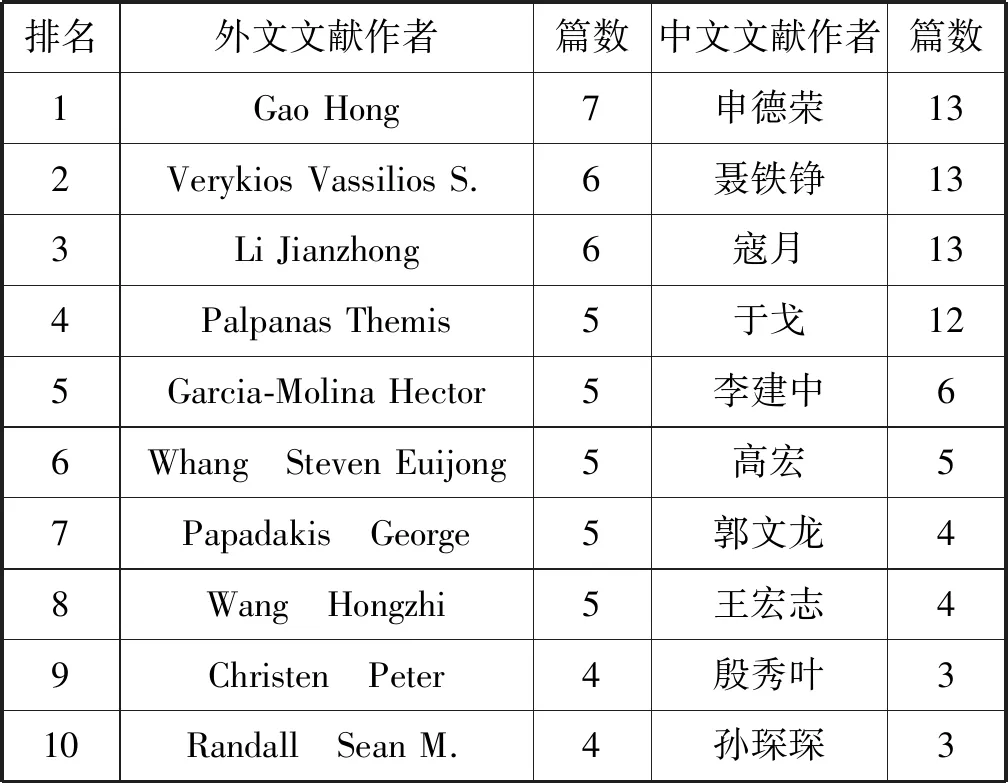
表3 作者發文篇數前十位
國外文獻作者影響力較大的有四個合作團隊。第一個是科廷大學(Curtin University) 的Ferrante、Randall、Semmens和Boyd等組成的團隊, 在2016年和2017年互相合作4篇文獻,主要研究在大型醫療數據集上,確保隱私的相似重復記錄檢測方法。提出的PPRL(Privacy-Preserving Record Linkage)模型,在不影響隱私和質量的情況下擴展了記錄鏈接[9]。第二個是雅典大學(University of Athens)的Palpanas 、 Papadakis和George等組成的團隊, 從2013年起共合作4篇文獻,注重研究分塊技術,希望通過元分塊對生成的塊進行重組以提高精度。第三個是哈爾濱工業大學的李建中、高宏和王宏志等組成的團隊,共合作發表5篇外文文獻,同時,這個團隊在國內期刊上也合作發表5篇文獻。研究主題包括基于規則的實體識別、異構數據庫中的實體識別、基于Map-Reduce的大數據實體識別、基于二分圖的最優匹配的記錄相似度計算、基于并行機群的大數據實體識別等。研究范圍十分廣泛,可以看出這個團隊在國內外相似重復記錄檢測領域都具有影響力。第四個是斯坦福大學(Stanford University)的Garcia-Molina 和Whang等組成的團隊,共發表4篇合作文獻。結合無監督學習中的聚類,研究基于規則的相似重復記錄檢測技術。高產作者中,Verykios、Vassilios和Christen也產生過合作關系,但是合作頻次不大,僅有兩篇合作文獻。
國內文獻作者合作中除哈爾濱工業大學的團隊外,還有一個來自東北大學的申德榮、聶鐵錚、寇月、于戈、孫琛琛、韓姝敏和楊丹組成的團隊,2008年至今,圍繞Deep Web、機器學習、異構網絡、隱私保護幾個主題,共發表13篇相關文獻。其中,寇月、申德榮等發表的《一種基于語義及統計分析的Deep Web實體識別機制》是2008年起國內的第一篇有關相似重復記錄檢測的文獻,被引用次數高達72次。該文獻針對Deep Web數據集成中的實體識別問題進行了深入的研究, 提出一種基于語義及統計分析的實體識別機制, 能夠有效解決Deep Web數據集成中的數據消重及表象整合等問題[10]。除了這兩個團隊,還有郭文龍和殷秀葉兩人,更擅長獨立探索,分別對異構數據庫和大數據環境下的相似重復記錄檢測技術有一定的研究。
5 研究熱點和趨勢
5.1 研究熱點
關鍵詞是學術論文研究內容的高度概括,它的關聯性在一定程度上可以體現出學科領域中的研究熱點[11]。為了保證分析的全面性, 本次圖譜構建沒有限制主題詞來源,將主題詞類型設置為名詞短語(noun phrases)及突現詞(burst terms), 節點類型設置為關鍵詞(keyword),得出國內外文獻關鍵詞共現圖譜。之后在其基礎上進行聚類,并使用對數似然率算法(LLR)抽取關鍵詞對每個聚類進行自動標識,由此得到國內外相似重復記錄檢測研究的關鍵詞聚類如圖4和圖5所示。模塊值(ModularityQ)和平均輪廓值(Mean Silhouette)是反映聚類邊界清晰度和聚類規模的兩個指標。國外文獻關鍵詞共現圖譜共有511個節點,1 394條連線, 網絡密度為0.010 7,Q值為0.847 3(>0.3),Mean Silhouette值為0.543 8(>0.4); 國內文獻關鍵詞共現圖譜共有371個節點, 760條連線, 網絡密度為0.011 1,Q值為0.875 6(>0.3), Mean Silhouette值為0.932 4(>0.4), 這表明該共現圖譜聚類結構顯著, 各聚類同質性較好。對聚類結果進行統計后,得到國內外頻數前十的關鍵詞匯如表4所示。
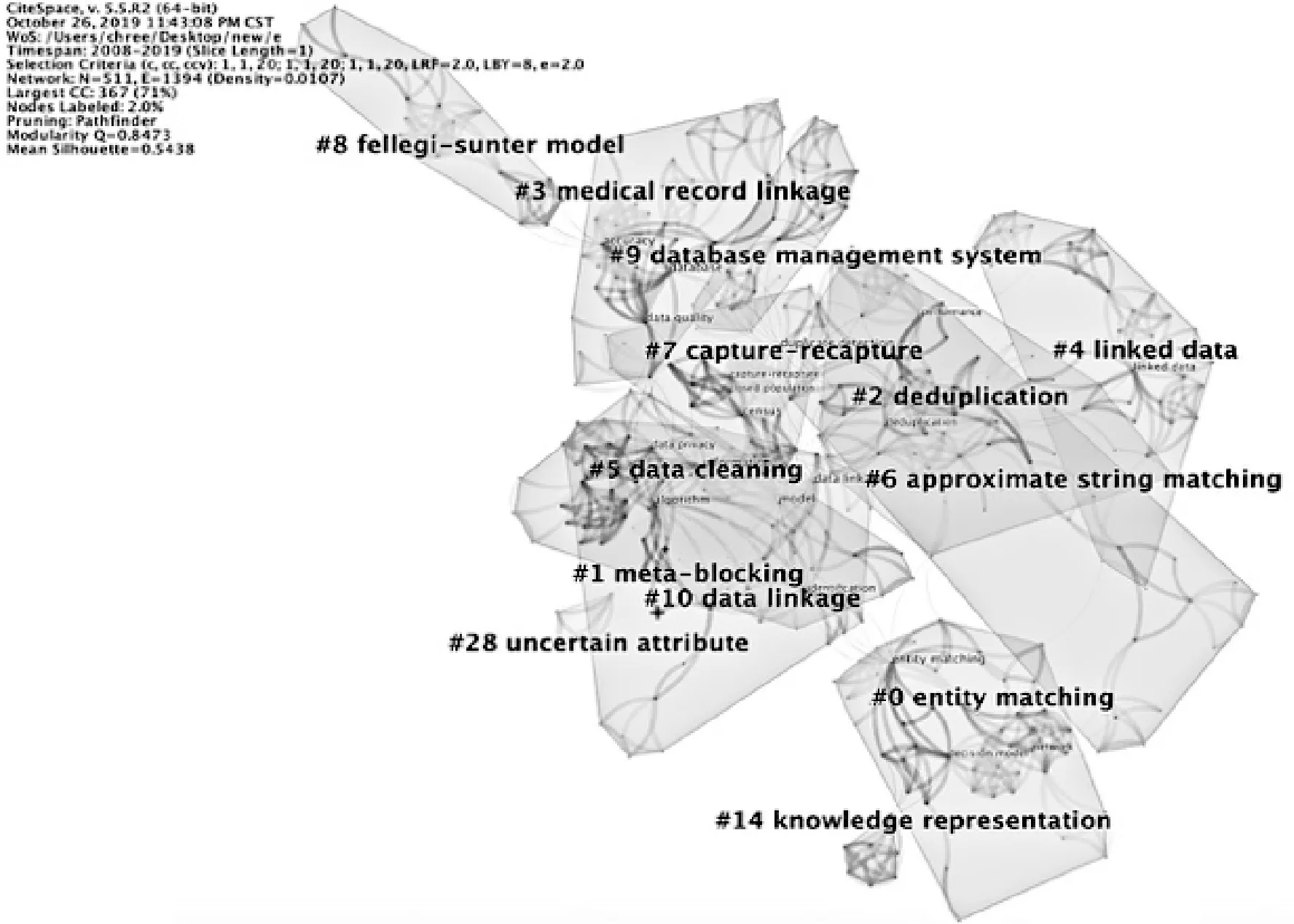
圖4 國外文獻關鍵詞聚類圖譜
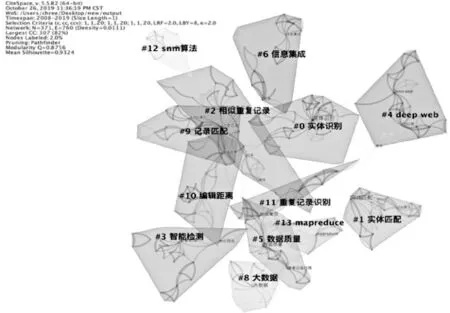
圖5 國內文獻關鍵詞聚類圖譜
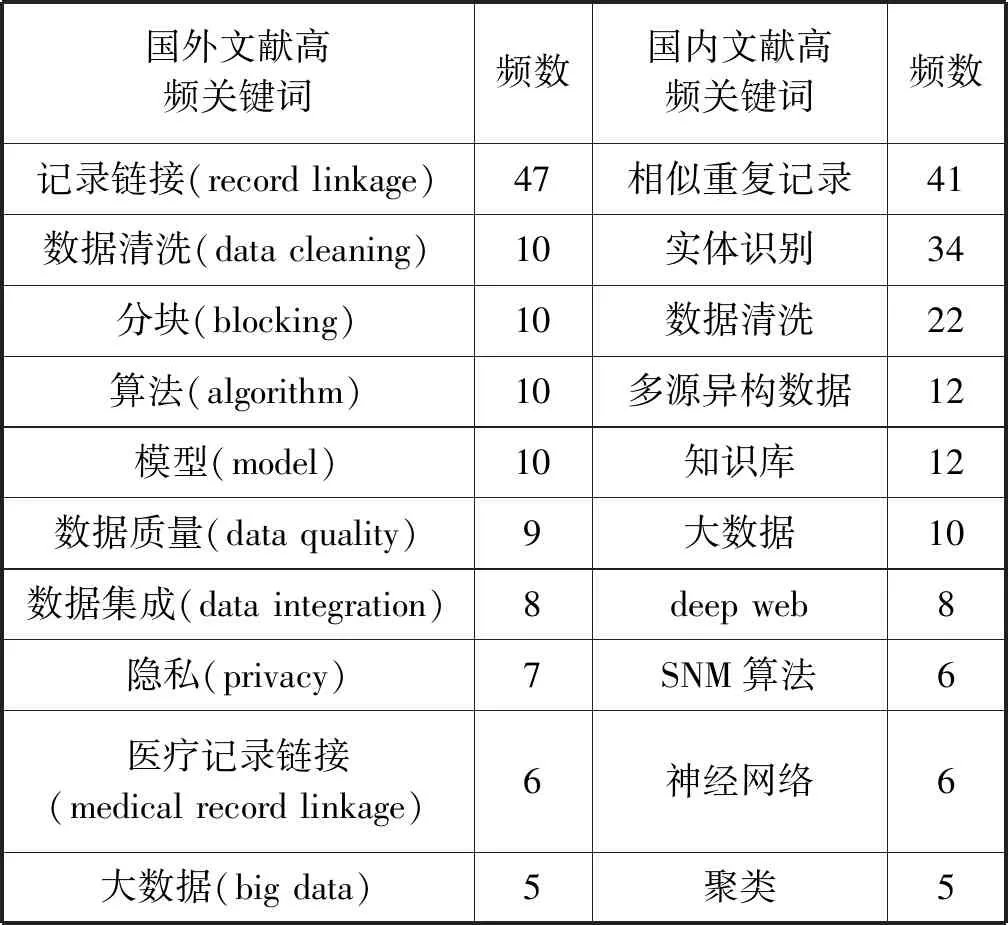
表4 國內外高頻關鍵詞
由圖4可知外文文獻包括13個主要聚類,分別是實體匹配(聚類#0 entity matching)、元分塊(聚類#1 meta-blocking)、重復數據刪除(聚類#2 deduplication)、醫療記錄聯動(聚類#3 medical record linkage)、關聯數據(聚類#4 linked data)、數據清洗(聚類#5 data cleaning)、近似串匹配(聚類#6 approximate string matching)、重復捕獲(聚類#7 capture-recapture)、fellegi-sunter模型(聚類#8 fellegi-sunter model)、數據庫管理系統(聚類#9 database management system)、數據鏈接(聚類#10 data linkage)、知識表示(聚類#14knowledge representation)、不確定屬性(聚類#28 uncertain attribute)。由圖5可知中文文獻包括13個主要聚類,分別是實體識別(聚類#0)、實體匹配(聚類#1)、重復記錄(聚類#2)、智能檢測(聚類#3)、deep web(聚類#4)、數據質量(聚類#5)、信息集成(聚類#6)、大數據(聚類#8)、記錄匹配(聚類#9)、編輯距離(聚類#10)、重復記錄識別(聚類#11)、SNM(sorted-neighborhood method,基本鄰近排序)算法(聚類#12)、mapreduce(聚類#13)。國內外的主要聚類出現實體匹配、數據清洗、數據質量等類似聚類,具有高度的相似性,總體說明在相似重復記錄檢測的研究主題上國內外的關注點是基本一致的。但是國外文獻在醫療數據鏈接上產生較大聚類,顯示出國外研究學者將相似重復記錄檢測應用在醫療數據中的程度較高,而國內文獻大多將其運用在智能檢測中。同時國內文獻關于Deep Web和大數據形成兩個較大的主要聚類,表明在2008年以來,國內對于有關deep web以及大數據的相似重復記錄研究關注度要高于國外。
從表3中可以看出國內外相似重復記錄檢測研究的熱點關鍵詞主要可以分為兩類。一類是應用環境與領域類,包括相似重復記錄、實體識別、數據清洗、多源異構數據、大數據、deep web、數據質量、數據集成、隱私和醫療記錄鏈接。另一類屬于檢測方法類,包括知識庫、SNM算法、神經網絡、聚類、分塊和算法。
SNM算法和CURE算法屬于相似重復記錄檢測中兩種比較主流的算法,近幾年,有較多學者對這兩種基本算法進行了改進。SNM算法最早由Hemandez等提出。針對其在數據量過大時,傳統排序需要大量的時間和空間的缺點,郭文龍[12]提出一種基于長度過濾和有效權值的SNM改進算法,將不可能構成相似重復記錄的數據排除在外,減少記錄比較的次數,提高檢測效率。Wang等[13]提出將SNM和迭代相結合的機制(SIER),兼顧了檢測效率與準確率。之后劉雅思等[14]針對屬性值缺失時容易造成誤判的情況,提出基于長度過濾和動態容錯的改進基本鄰近排序(SNM based on length filtering and dynamic fault-tolerance,LF-SNM)算法,根據記錄其他字段的相似度情況,動態調整記錄中屬性缺失字段的相似度結果,提高檢測精度。CURE算法對相似重復記錄進行分層聚類,可以針對任意分布、類型的數據進行聚類,效率較快,因此被人們廣泛地應用。王民等[15]針對CURE算法在隨機抽樣階段存在的隨機性問題,采用Binary-Positive算法進行改進,以獲取數據集中更有用的樣例進行層次聚類。伍恒等[16]在CURE算法的基礎上引入了信息熵,利用信息熵計算樣本的相似度,根據樣本間的相似度量與不同簇之間的關系,將數據集分為高低兩個階段,對不同階段的樣本采用不同的選取策略。孫元元等[17]提出一種新的原型選擇算法PSCURE(improved prototype selection algorithm based on CURE algorithm),針對CURE噪聲點不易確定及代表點分散性差的特點,利用共享鄰居密度度量的去噪方法和最大最小距離選取代表點方法進行改進,獲得較高的檢測準確率。
國內外研究學者在相似重復記錄檢測的應用領域及技術提升上有很高的關注度,提出了種類繁多的檢測算法,應用范圍也越來越廣。根據有關國內外關鍵詞知識圖譜以及關鍵詞聚類匯總結果表的分析可以得出結論,相似重復記錄檢測一直是數據清洗領域的熱門話題,大量的國內外研究學者不斷在擴展相似重復記錄檢測的應用領域、調整檢測相似重復記錄的角度、優化相似重復記錄檢測的算法、尋求更加高效的相似重復記錄檢測方案,提升檢測效果。
5.2 研究趨勢
時區演化圖譜能夠直觀地反映研究領域文獻的更新和關聯程度,從而反映出研究的演進趨勢和特點,以此預測未來研究的發展方向[5]。Citespace的時區演化圖譜根據產生年份,使用節點大小和線條色彩來繪制研究熱點發展全貌,可以清晰表征研究熱點的發展軌跡。利用Citespace對國內文獻和國外文獻的關鍵詞進行timezone操作,生成時區演化圖譜,并且標記出每個年度的重點關鍵詞 (見圖6和圖7)。各研究熱點顏色差異表征該熱點詞首次出現的時間差異,由深到淺、由紫向黃的分布代表出現時間從先到后,呈現出相似重復記錄檢測領域研究主題的變遷。這兩幅圖側重于在時間維度上表示研究熱點的變化,能夠更好地表達出研究主題的發展趨勢。

圖6 國外文獻的關鍵詞時區演化圖譜

圖7 國內文獻的關鍵詞時區演化圖譜
2008年以來,國內外對相似重復記錄檢測技術的研究主要分為三個階段。
第一個階段處于2010年之前,國內外研究方向集中在對相似重復記錄檢測的不同應用領域的探索。在異構數據庫上,Efthymiou等[18]提出一種并行執行方法,減少在異構數據上的數據交換消耗。在人口普查上,國外將相似重復記錄檢測應用于人口普查中,解決大規模人口普查問題,有效地對人口數據進行了數據清洗,提高了數據質量。在隱私保護上,國外掀起了在缺少值的情況下對隱私保護記錄鏈接的研究[19]。國內在保持數據間相對距離的基礎上進行記錄鏈接,在保證鏈接效果的同時實現隱私保護。此外,韓普等[20]以多源大數據為數據源,建立出面向醫療領域實體識別知識圖譜框架。
第二個階段由2010年到2017年,研究方向集中在對相似重復記錄檢測方法的研究。機器學習方法研究熱度久居不下,在監督學習中,支持向量機由于在相似重復記錄識別上的良好表現,被國內外學者重點研究;在無監督學習中,孫琛琛等[21]就面向實體識別設計出一種聚類算法,來彌補匹配問題的缺失。由于2010年Hinton在Nature上發表的深度學習論文,研究學者也開始結合其他研究方法,將深度學習應用到相似重復記錄識別領域。徐紅艷等[22]針對Deep Web提出一種基于BP神經網絡實體識別方法,該方法在提高實體識別的效率和準確率的同時能夠減少實體識別中的人工干預。吳慶輝等[23]結合神經網絡的非線性映射以及遺傳算法的優化特性,獲得了更佳的模型參數來解決大數據量情況下的相似重復記錄檢測問題。陳芬[24]提出的量子粒子群優化神經網絡模型,大幅度減少相似重復記錄檢測時間,在數據整合方面有了很大的進步。除此之外,用于解決大數據量的相似重復記錄檢測問題的分塊技術也有進一步發展。Papadakis等[25]通過分塊擴展到大型數據集合。佟丹妮等[26]利用局部敏感哈希結合后綴分塊的二次分塊方法,設計適用于大型數據的基于安全多方計算的匹配算法。同一時段,國外在眾包上做了深度探索,用人群的智慧和力量來提高實體解析的效率和質量,Chai等[27]搭建出具有成本效益的眾包實體解決方案框架,在保證質量的前提下,將成本降低至現有方法的1.25%。國內也開始考慮到維度的增加會提升識別的難度,使用R-樹構建索引保留記錄的高維特性,避免了高維數據稀疏性的影響。
第三個階段是2018年至今,國外開始更注重自動數據處理,以此減少人類的工作量,并且將關注點移動至特征選擇,借助更典型的特征提升檢測精度。國內在更多類型的數據上開始進行相似重復記錄識別研究,包括工業大數據、文本大數據等。為了提升深度學習的學習速率,國外開始使用多GPU進行計算,Boratto等同時利用多核和多GPU架構來執行數據庫的概率鏈接,同時提高了精度和性能[28]。國內更注重安全實體識別以及在大規模記錄上的相似重復記錄識別,并且在神經網絡中添加了自注意力機制。
6 結 語
如今信息系統中數據量成指數增長,對相似重復記錄檢測方法要求的穩定性、準確性及檢測速度提出巨大的挑戰,國內外學者開始尋求各種檢測方法的集成,希望能夠借助各種方法的優勢,達到更好的效果。
相似重復記錄檢測目前面臨的挑戰可以總結為3點。(1) 對數據缺失值的處理,數據缺失會對相似重復記錄的檢測制造出困難,需要根據具體數據的缺失類型,調整現有的相似度算法等。(2) 對多數據源的識別,在實際應用中,來自多個數據源的相同記錄由于組織結構、格式等的不同導致表示形式差異較大,提升檢測難度。(3) 分布式實體識別,在當今大數據時代,面向高級別數據量的相似重復記錄檢測一直是研究學者關注的熱點,如何設計有效的分塊技術,解決在大數據量環境下碰到的數據分布不均的問題也是相似重復記錄檢測如今面臨的挑戰之一。
本文運用可視化信息分析軟件CiteSpace和社會網絡分析軟件Ucinet,結合World of Science和CNKI的數據分析,呈現了2008年以來在相似重復記錄檢測領域國內外相關文獻的關鍵詞演化圖譜和作者合作網絡,主要分析了相似重復記錄檢測領域文獻發文量的年度分布、發文核心機構、作者合作群、研究熱點和研究趨勢,為今后探索相似重復記錄檢測方法提供了文獻參考及研究方向。
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
