基于深度神經網絡的時空編碼磁共振成像超分辨率重建方法*
2022-03-18 10:14:30向鵬程蔡聰波王杰超蔡淑惠陳忠
物理學報 2022年5期
向鵬程 蔡聰波 王杰超 蔡淑惠 陳忠
(廈門大學電子科學系,廈門 361005)
單掃描時空編碼磁共振成像是一種新型超快速磁共振成像技術,它對磁場不均勻和化學位移偽影有較強的抵抗性,但是其固有的空間分辨率較低,因此通常需要進行超分辨率重建,以在不增加采樣點數的情況下提高時空編碼磁共振圖像的空間分辨率.然而,現有的重建方法存在迭代求解時間長、重建結果有混疊偽影殘留等問題.為此,本文提出了一種基于深度神經網絡的單掃描時空編碼磁共振成像超分辨率重建方法.該方法采用模擬樣本訓練深度神經網絡,再利用訓練好的網絡模型對實際采樣信號進行重建.數值模擬、水模和活體鼠腦的實驗結果表明,該方法能快速重建出無殘留混疊偽影、紋理信息清楚的超分辨率時空編碼磁共振圖像.適當增加訓練樣本數量以及在訓練樣本中加入適當的隨機噪聲水平,有助于改善重建效果.
1 引言
單掃描時空編碼磁共振成像(spatiotemporallyencoded magnetic resonance imaging,SPEN MRI)是一種新興的超快速成像技術[1-3].與回波平面成像(echo planar imaging,EPI)相比,SPEN MRI在相位編碼維采用更大的帶寬,這使得其受磁場不均勻和化學位移的影響較小,但是大的采樣帶寬限制了其信號采樣點數,因此通常SPEN MRI 的信號是欠采樣的.根據SPEN MRI 的穩定相位點特性,可以直接對采樣信號取幅值重建出MRI 圖像.然而,這樣得到的圖像空間分辨率不能滿足實際應用的需要,因而需要對SPEN MRI 采樣信號進行超分辨率(super-resolved,SR)重建.
SPEN MRI 采樣時相鄰穩定相位點在空間位置上存在部分重疊,這種“過采樣”機制提供了可用于SR 重建的冗余信息[4].基于此,近十年來,已有數種針對于單掃描SPEN MRI 的SR 重建方法被提出,如共軛梯度下降法[4]、部分傅里葉法[5]、去卷積法[6]和超分辨率增強邊緣鬼影去除法(SEED)[7]等.共軛梯度下降法將采樣信號和相位信息矩陣離散化表示后,通過最小二乘擬合對采樣信號的線性方程組進行迭代求解得到SR 圖像.由該方法重建得到的圖像的數字分辨率理論極限為信號的采樣點數,當信號欠采樣倍數過大時,矩陣條件數隨之變大,導致可能無法對線性方程組進行求解.此外,通過梯度下降迭代法逼近方程的解,容易受磁場擾動和梯度不準的影響;同時,如果相位信息矩陣的維度大,迭代求解的過程將比較耗時.部分傅里葉法根據SPEN MRI 采樣信號的空間選擇特性,忽略距離穩定相位點較遠位置的采樣信號的貢獻,通過對相位信息矩陣加入空間位置選擇加權因子,僅使用穩定相位點相鄰區域的采樣信號貢獻重建出SR 圖像.部分傅里葉法不需要通過迭代法求解,計算量小,重建速度快,但其SR 圖像的理論數字分辨率極限也為信號采樣點數.去卷積法首先巧妙地去除SPEN MRI 采樣信號的二次相位調制,使原本相位震蕩劇烈的采樣信號變得平滑,然后對信號沿空間編碼維線性插值以抑制欠采樣帶來的混疊偽影,同時提升重建圖像的數字分辨率,最終通過反卷積重建出SR 圖像.去卷積法通過插值突破了采樣信號點數對重建結果數字分辨率的限制,但是這種插值只對圖像分段平滑的區域有效,不適用于圖像邊緣的尖銳區域和紋理信息比較豐富的區域,而這些區域往往包含重要的信息,重建結果在這些區域可能存在殘留偽影,空間分辨率較低.SEED 法利用與混疊偽影相關的額外二次相位信息,通過填零提高重建結果的數字分辨率,可以在不損失空間分辨率的情況下移除混疊偽影,達到理論上的最優空間分辨率.該方法通過非線性共軛梯度算法迭代求解出最終結果,計算量大,重建速度較慢.此外,在實驗條件不理想的情況下,重建結果邊緣區域存在殘留偽影.
隨著計算機硬件性能的不斷提升,深度學習技術得到飛速發展并越來越廣泛地應用于醫學成像領域[8-19].深度神經網絡(deep neural network,DNN)是包含多個隱藏層的神經網絡,它使用反向傳播算法對網絡進行訓練,并采用梯度下降法更新卷積核的權重.DNN 采用局部連接和神經元權值共享的方式,可以直接將圖像作為網絡輸入并自行提取如顏色、形狀、紋理、結構等圖像特征,在處理二維圖像問題上有巨大的優勢.基于DNN 的MRI 重建方法通過大量的數據樣本對深度神經網絡進行訓練,訓練完成后的網絡模型可以對相同特征類型的測試數據快速完成重建[9,15-17,19].2015 年,Ronneberger等[20]提出一種新型DNN 結構U-Net.U-Net 是目前非常流行的一種DNN,它使用對稱的編解碼器結構,在編解碼器的同層之間建立直連,可以融合多尺度的特征信息,在醫學圖像分割和重建上表現優異[21,22].在此背景下,本文提出了一種基于U-Net的單掃描SPEN MRI SR 重建方法.該方法根據實際SPEN MRI 實驗條件制作大量模擬訓練樣本,采用模擬樣本對網絡進行訓練[9,17],然后通過訓練完成的網絡模型對預處理后的SPEN MRI 采樣信號進行重建,得到SR 圖像.與現有的SR 重建方法相比,該方法在能得到SPEN MRI 的SR 圖像的同時,重建速度快,重建結果能消除混疊偽影.
2 基于深度神經網絡的重建方法
2.1 信號預處理
圖1 為本文所用單掃描SPEN MRI 脈沖序列,圖中G代表脈沖梯度場,T代表時間,N/2 代表采樣模塊重復次數.該序列在相位編碼(phaseencoding,PE)維進行時空編碼,讀出(readout,RO)維為傳統k空間編碼,采樣信號空間為圖像域-k空間的混合空間.SS 維為層選(slice selection)維.SPEN MRI 在PE 維的全采樣點數Nfull由90° chirp 射頻(RF)脈沖帶寬WB和持續時間Texc決定:
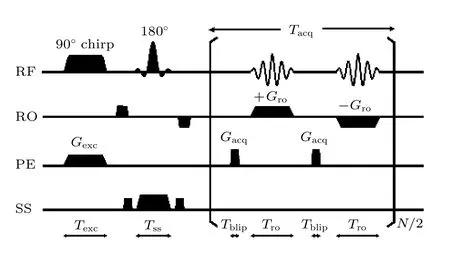
圖1 本文所用SPEN MRI 脈沖序列Fig.1.Pulse sequence of SPEN MRI used in this study.
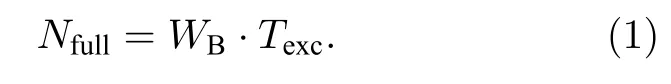
沿y方向進行時空編碼一維成像時,其采樣信號可表示為[5]
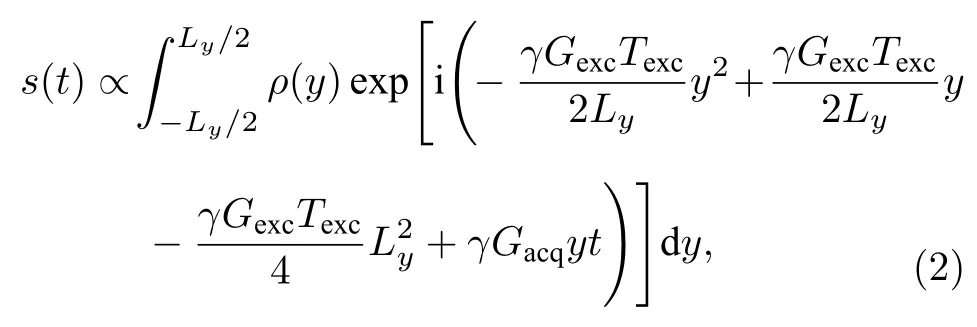
其中,ρ(y)為核自旋密度,γ為核自旋的旋磁比,Ly為成像視野,Gexc為時空編碼梯度強度,Gacq為采樣階段的解碼梯度強度.由(2)式可見采樣信號中存在一個與空間位置相關的二次相位調制.
SPEN MRI 信號的二次相位調制特性使其相位只在穩定相位點附近是緩慢變化的,其他區域的相位則變化劇烈.相位變化劇烈區域的信號相互抵消,對成像沒什么貢獻,卻給重建帶來困難,因此在將待重建信號輸入深度神經網絡前需要去除此二次相位.去除二次相位的過程為
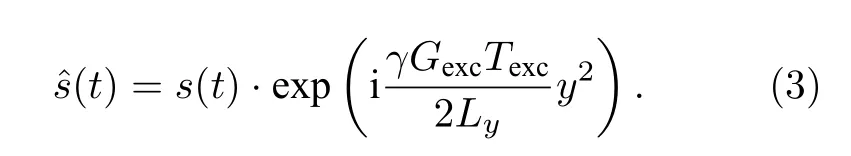
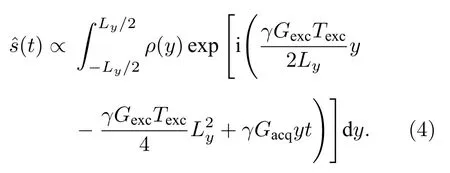
對(t) 沿PE 維進行線性插值,插值后的信號在PE 維方向上數據點數為全采樣點數Nfull.將插值后的信號歸一化,即可分別取其實部和虛部作為卷積神經網絡的雙通道輸入.
對二維采樣,如果RO 維采樣點數少于Nfull,在去除二次相位前要對混合空間域的采樣信號沿RO 維填零并進行一維傅里葉變換,將信號轉化為圖像域.RO 維填零后的大小與PE 維全采樣點數Nfull相等,以使采樣信號經預處理后作為網絡輸入的圖像域數據為方形矩陣.
2.2 訓練樣本制作
要對深度神經網絡進行訓練需要大量的樣本,樣本采集耗時長,而且真實的實驗環境往往不理想,無法獲得作為標簽的實驗數據,因此我們采用模擬方法生成SPEN MRI 信號來制作訓練樣本.
2.2.1 采樣模板制作
我們在MATLAB 軟件上運行自己編寫的代碼生成批量的具有不同紋理結構和磁共振參數分布的隨機模擬采樣模板,核自旋密度M0的取值范圍為[0,1],橫向弛豫時間T2的取值范圍為[0,0.25 s].縱向弛豫時間T1設為1 s,受不均勻磁場影響的橫向弛豫時間T2*設為0.02 s.
2.2.2 模擬信號采集
將SPEN MRI 序列和采樣模板導入MRiLab模擬軟件[23]中,設置序列參數與實際實驗一致.在實際實驗中,靜磁場B0往往不完全均勻.為了提高重建方法的魯棒性,根據實際實驗條件對B0場不均勻性進行建模,然后在模擬的不均勻磁場條件下進行模擬信號采集.B0場的不均勻性由(5)式表示:
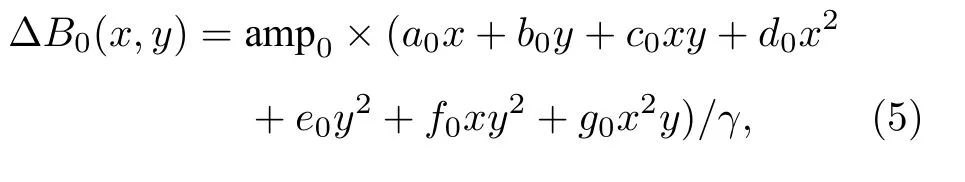
其中:amp0為控制B0場偏離程度的參數,在建模時通過拉莫進動頻率公式與頻率偏移Δf關聯;a0,b0,c0,d0,e0,f0,g0為方程中各項的系數,服從[—0.5,0.5]之間的均勻分布;x,y為B0矩形模板經過歸一化后的坐標值,范圍是[—1,1].
2.2.3 模擬信號預處理
在通過MRiLab 軟件獲得SPEN MRI 模擬采樣信號后,按2.1 節的方法對其進行預處理.考慮到實際實驗中存在噪聲,我們對預處理后的信號加入與實驗環境相當的正態分布的高斯隨機噪聲,然后分別取其實部和虛部作為訓練深度神經網絡的雙通道輸入數據.
2.2.4 標簽制作
采用理想實驗條件下的全采樣SPEN MRI 模擬信號圖像作為標簽.首先去除(5)式的磁場不均勻偏移量,然后采用相同的脈沖序列對采樣模板進行采樣,PE 維和RO 維的采樣點數均為Nfull,獲得相同采樣模板的理想SPEN MRI 全采樣模擬信號.對此全采樣模擬信號進行二維傅里葉變換,歸一化后取幅值作為訓練深度神經網絡的標簽.
2.3 網絡結構
本文選用U-Net[20]進行圖像重建.使用PyCharm編譯器和深度學習框架PyTorch 搭建一個如圖2所示的5 層的U-Net 深度神經網絡.輸入通道數為2,分別對應預處理后的采樣信號的實部和虛部,輸出通道為1,即輸出重建的SR 圖像.
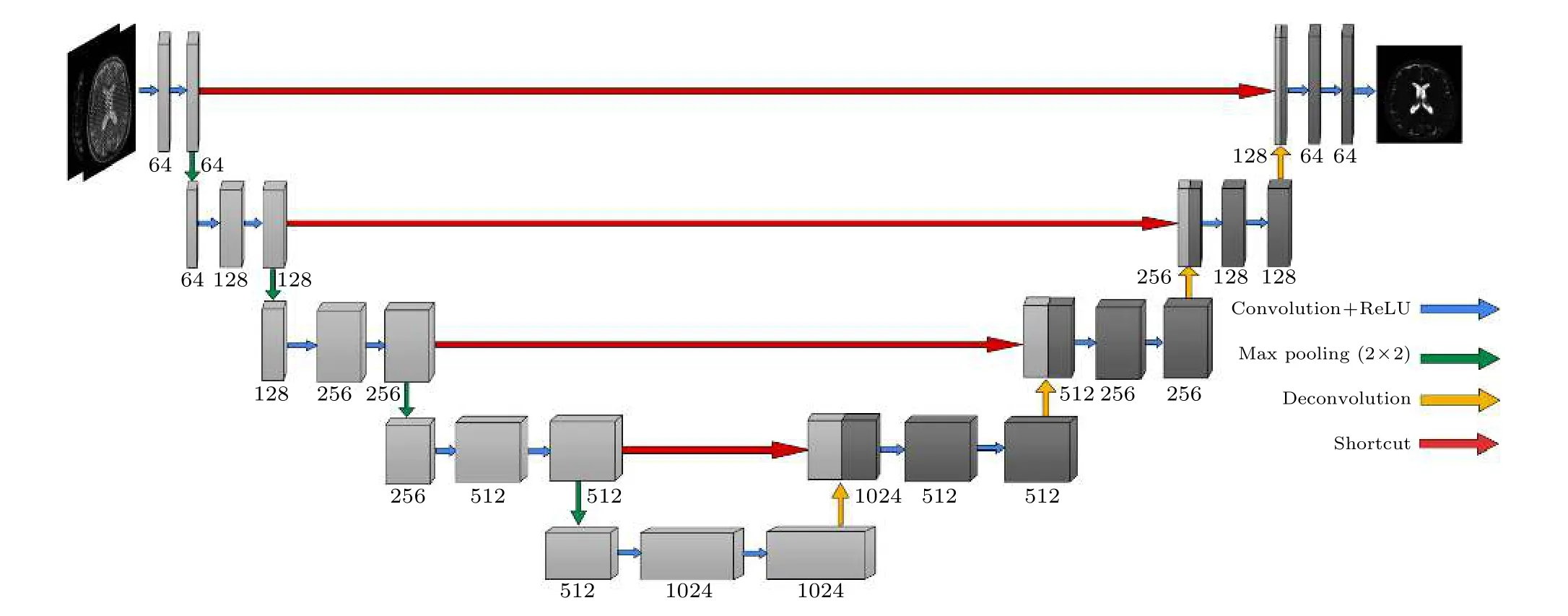
圖2 U-Net 網絡結構示意圖Fig.2.Diagram of U-Net network structure.
訓練網絡的損失函數采用均方誤差(mean square error,MSE),其可以表示為

其中,Ns為每次迭代訓練時的圖像塊數目,f() 為網絡所學習的輸入X和輸出Y間的非線性映射函數,L表示標簽,W表示網絡卷積層的權重信息,B表示偏置.W和B隨著對網絡的迭代訓練而不斷更新.
采用上述批量訓練樣本對深度神經網絡進行訓練,直至網絡收斂,然后保存訓練好的網絡模型.將按照2.1 節預處理后的SPEN MRI 實際采樣信號數據輸入訓練好的網絡模型,即可重建得到SR圖像.
3 實驗方法
實驗所用脈沖序列如圖1 所示.數值模擬實驗在MRiLab 上進行,水模和活體鼠腦實驗在7 T Varian MRI 儀上進行.使用異氟烷將大鼠麻醉并放置在動物床上進行實驗,所有操作均遵守廈門大學實驗動物管理中心的規定.對采樣信號的預處理在MATLAB 軟件上通過自己編寫的程序完成.
數值模擬實驗參數為:Texc=4 ms,WB=32 kHz,Tacq=38.912 ms,回波時間TE=45.21 ms,重復時間TR=67.76 ms;PE 維采樣點數Npe=64,欠采樣倍數為2;RO 維采樣點數Nro=Nfull=128.全采樣信號點數[Npe,Nro]=[128,128],模擬信號采樣時設置不均勻場頻偏Δf=1500 Hz.一共制作3000 個訓練樣本,訓練集、測試集、驗證集的樣本數比例為8∶1∶1.
水模和活體鼠腦實驗所用WB,Texc,TE,Tacq,Npe,Nro參數均與數值模擬實驗一致.采用單掃描SPEN MRI 序列進行水模實驗時,WB=250 kHz,視野(field of view,FOV)=5 cm × 5 cm,層厚為2 mm,層數為1.多掃描快速自旋回波(FSE)參考圖像和EPI 對比圖像的采集在與SPEN MRI相同的實驗環境下進行,且FOV、層厚、層數與SPEN 序列采樣時相同.FSE 的TR=3000 ms,采樣點數[Npe,Nro]=[128,128],重復掃描8 次.EPI 的TE=44.82 ms,采樣點數[Npe,Nro]=[64,128].三種方法的活體鼠腦實驗相關成像參數和水模實驗相同.考慮到多掃描FSE 序列的采樣時間較長,將FSE 重復掃描次數減為4.
訓練數據沿PE 維隨機切成64 × 128 的圖像塊.U-Net 卷積核大小為3 × 3,步長為1,padding形式為same.每次卷積后面都接一個ReLU 激活函數.降采樣過程最大池化尺寸為2 × 2,步長為2,padding 形式為same.反卷積核(也稱轉置卷積核)大小為2 × 2,步長為2,padding 形式為same.網絡訓練使用2 個GTX2080Ti,batch size 大小為8,初始學習率為1 × 10—4,每迭代20000 步學習率減小0.5 倍,共迭代15 萬步.
采用模擬樣本對U-Net 進行訓練的訓練誤差和驗證誤差曲線如圖3 所示,訓練完成后,訓練誤差和驗證誤差分別為7.89 × 10—4和8.33 × 10—4.
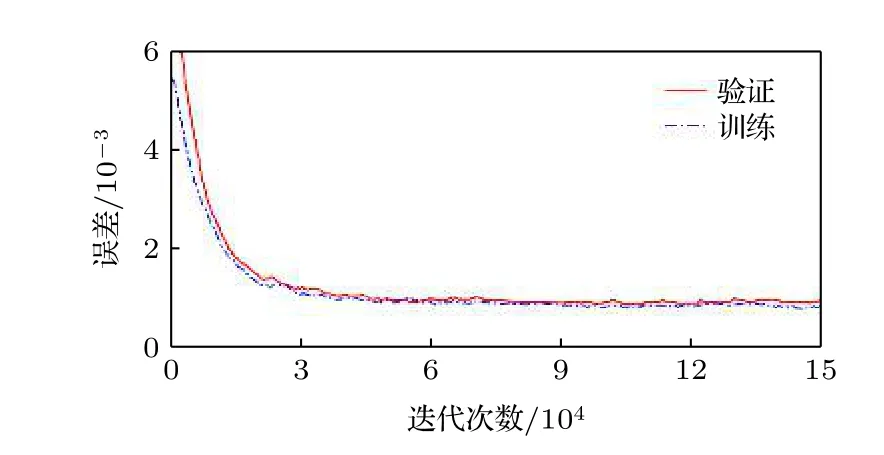
圖3 采用模擬樣本訓練U-Net 的訓練誤差曲線和驗證誤差曲線Fig.3.The training error curve and validation error curve of U-Net trained with simulated samples.
使用目前單掃描SPEN MRI 的最優SR 重建方法SEED 作為對比對本方法的重建結果進行評價.兩種方法的重建結果數字分辨率均為128 × 128.對于數值模擬實驗,通過計算兩種方法重建圖像的結構相似性(structural similarity index metric,SSIM)和峰值信噪比(peak signalto-noise ratio,PSNR)作為圖像質量評估指標.SSIM 和PSNR 的計算方式分別為
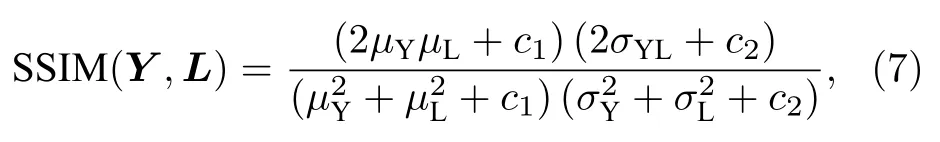
其中:μY為重建圖像Y的平均值;μL為標簽L的平均值;為Y的方差;為L的方差;σYL為Y和L的協方差;c1=(k1V)2,c2=(k2V)2為用來維持穩定的常數項,k1=0.01,k2=0.03,V為圖像的像素值范圍.
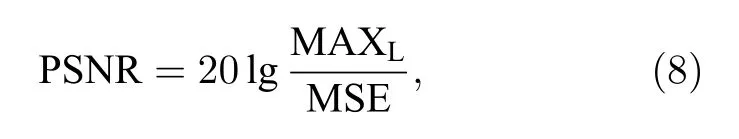
其中,MAXL為標簽L的最大值,MSE 為Y和L的均方誤差.
4 結果與討論
4.1 數值模擬實驗
圖4 為數值模擬實驗結果.由于數值模型的采樣信號在不同區域的交界處變化比較劇烈,全采樣標簽圖中有振鈴效應導致的截斷偽影.SEED 方法的重建時間約為117 s,而U-Net 方法的重建時間大約為1 s,重建時間大大縮短.比較U-Net 和SEED的重建結果可以看到,兩者都能對原始SPEN MRI 采樣信號進行超分辨率重建,解決SPEN 固有空間分辨率較低的問題.如圖4 中紅色矩形框所指區域所示,相比于SEED 方法,U-Net 的重建結果與全采樣標簽更接近.SEED 重建結果的SSIM和SNR 分別為91.56%和24.94 dB,而U-Net 重建結果的SSIM 和SNR 分別為93.61%和27.83 dB,兩項評價指標都有提升.
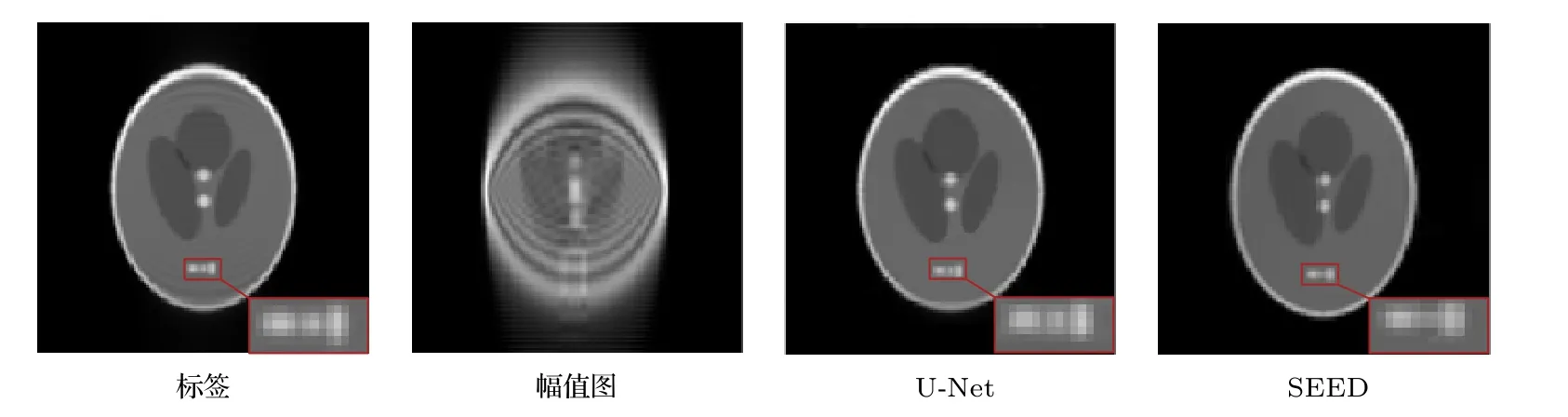
圖4 數值模擬結果,紅色矩形所圍區域放大顯示于相應圖的右下角Fig.4.Numerical simulation results.The region enclosed by the red rectangle is enlarged and displayed in the lower right corner of the corresponding figure.
4.2 水模實驗
不同成像序列和重建方法得到的結果如圖5所示.SEED 方法的重建時間約為129 s,U-Net 方法的重建時間約為1 s.由圖可見,SEED 方法重建結果存在受振鈴效應影響導致的截斷偽影,而該效應在U-Net 重建結果中得到了改善.比較圖5 中的紅色矩形框區域可以看到,U-Net 和SEED 方法對欠采樣倍數為2 的水模SPEN MRI 采樣信號SR重建后圖像的空間分辨率都接近多掃描FSE 全采樣參考圖,明顯優于相同采樣點數下的EPI 圖像.此外,由于主磁場并不完全均勻,加上水模樣品本身存在不均勻,EPI 圖像發生明顯扭曲,同時EPI圖像中還存在欠采樣導致的混疊偽影;而SPEN MRI 對不均勻場抵抗性較強,畸變較小,同時混疊偽影也被消除.
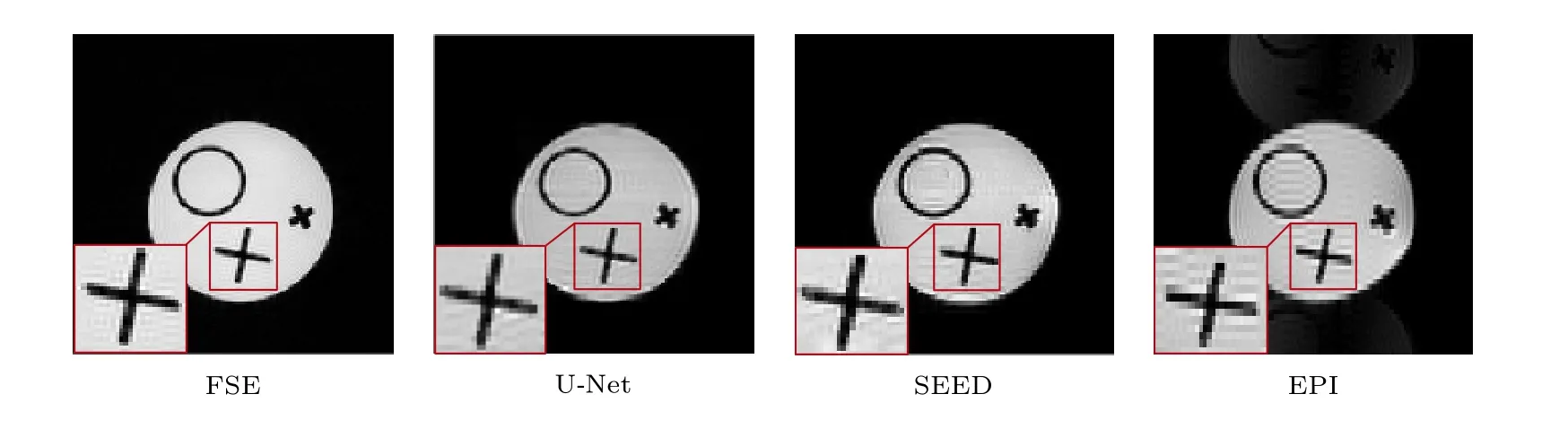
圖5 不同成像序列和重建方法得到的水模圖像,紅色矩形所圍區域放大顯示于相應圖的左下角Fig.5.Water phantom images obtained by different imaging sequences and reconstruction methods.The region enclosed by the red rectangle is enlarged and displayed in the lower left corner of the corresponding figure.
4.3 活體鼠腦實驗
不同成像序列和重建方法得到的結果如圖6所示.進行活體鼠腦實驗時,我們使用的接收線圈為體線圈,采樣信號SNR 較低,因此在比較不同方法的重建結果時,主要關注信號強度較高的腦區部分.SEED 方法重建時間約為154 s,U-Net 重建時間約為1 s.從圖6 可以看到,由于受不均勻場影響,相比于FSE 參考圖像,EPI 圖像扭曲十分嚴重,而SPEN MRI 對不均勻場的抵抗性明顯增強,鼠腦區域扭曲較小.與SEED 的重建結果相比,U-Net的重建結果在鼠腦邊緣區域的亮暗變化較小,更接近參考圖像.
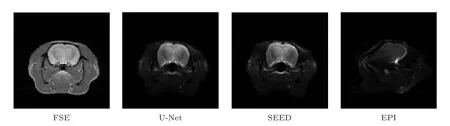
圖6 不同成像序列和重建方法得到的活體鼠腦圖像Fig.6.In vivo rat brain images obtained by different imaging sequences and reconstruction methods.
4.4 討論
由于SPEN MRI 在實際實驗時往往是欠采樣的,其SR 重建圖像往往存在混疊偽影,本文提出的方法利用深度神經網絡學習輸入和全采樣標簽之間的映射關系,能夠重建出無混疊偽影的圖像.SEED 方法也能去除欠采樣混疊偽影,然而它對信號采集的實驗條件要求比較嚴格,例如chirp 激發脈沖要準確,否則它可能無法提取到精確的邊緣混疊偽影信息,導致重建結果偽影不能完全消除.此外,采用SEED 方法重建時,需要設置合理的重建參數,因此需要耗費一定的時間對重建參數進行優化選擇.例如對于不同樣品的采樣信號,往往需要設置不同的小波變換和有限差分變換的正則化因子,這兩個正則化因子會影響重建結果的偽影抑制能力和空間分辨率.與SEED 方法相比,U-Net 方法對不同的待重建數據的泛化能力更強,同時重建速度也大大加快.
深度神經網絡方法的重建結果會受到一些因素的影響,例如:網絡模型結構和深度、損失函數的選擇、網絡通道數、訓練樣本數、訓練樣本的噪聲水平、訓練數據是否切塊以及切塊大小等.在重建過程中我們發現,在網絡深度方面,適當增加UNet 的卷積層深度可以增強網絡的特征提取能力,使得重建結果的分辨率更高、紋理更精細,但并不是層數越多越好,網絡層數越多占用的內存越多,計算量越大,訓練速度越慢,還可能產生過擬合.綜合考慮網絡的數據特征提取能力、計算量以及訓練時間,采用的下采樣卷積層深度為5.在對網絡的訓練過程中我們發現,對訓練樣本進行歸一化會大大提升重建結果質量,因此采用批最大值歸一化方式.另外,對訓練數據進行切塊以減小特征圖運算時的尺寸有利于加快網絡的訓練速度,因此在輸入給網絡時我們對訓練數據沿直接采樣維進行切塊處理,切塊大小為原訓練樣本尺寸的一半.
深度神經網絡通過大量的訓練樣本提取數據特征,并將學習到的輸入輸出間的非線性映射關系向同類型測試數據泛化,因此對基于深度神經網絡的SR 重建方法,訓練樣本至關重要.下面我們分別對訓練樣本數量和訓練樣本的噪聲水平這兩個比較關鍵的因素對重建結果的影響進行討論.對SPEN MRI 信號采樣的實驗條件和相關成像參數與前面相同.
為探討訓練樣本數對重建結果的影響,分別采用1000,1600 和3000 個樣本對網絡進行訓練,其對應的重建結果如圖7 所示.水模本身包含的紋理信息不豐富,我們通過比較空間分辨率的提升來討論訓練樣本數對本方法重建質量的影響.當將訓練樣本數量從1000 增大到1600 時,水模重建結果分辨率有提升但仍不太理想.繼續增大訓練樣本數量到3000 時,水模重建結果的空間分辨率表現良好.對鼠腦而言,當只用1000 個樣本訓練網絡時,由于數據量太少,鼠腦的重建結果缺失了一些紋理和組織結構信息,腦部區域的分辨率也比較低.隨著樣本數量的增加,網絡可以有更多的數據來學習輸入輸出之間蘊含的映射關系.當樣本量分別增加到1600 和3000 時,鼠腦組織結構的細節逐漸豐富,同時腦部區域的分辨率也有較明顯的提升.繼續增大訓練樣本量,網絡收斂時的損失值和對重建結果質量的提升不明顯.
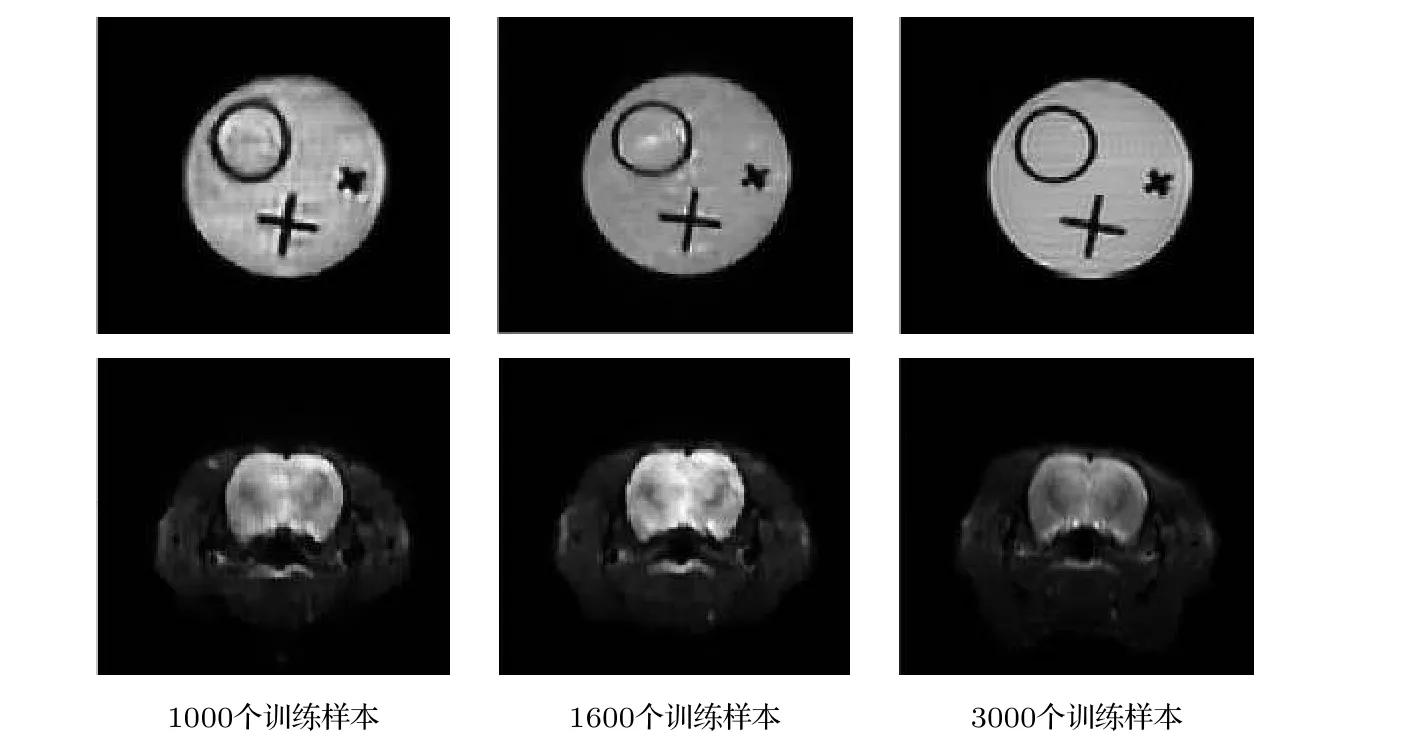
圖7 采用不同數量訓練樣本訓練的5 層U-Net 網絡重建的圖像Fig.7.Images reconstructed by 5-layer U-Net trained with different amount of training samples.
為了模擬實際實驗條件,增強重建方法的魯棒性,在制作模擬訓練樣本時往往需要加入與實際采樣信號相似分布的高斯隨機噪聲.經預處理后的訓練樣本的幅值取值范圍為[0,1],根據實際信號采樣時的噪聲水平范圍,本文對3000 個訓練樣本加入不同均值分布的高斯隨機噪聲,不同噪聲水平訓練樣本下水模重建結果如圖8 所示.由于用MRiLab模擬采樣時實驗環境是理想的,當不對模擬樣本加隨機噪聲直接對網絡進行訓練時,實采水模重建結果較差.逐漸加大噪聲水平,圖像重建質量得到提升,但當所加的隨機噪聲大于一定閾值后,重建結果變差.噪聲均值在8 × 10—3的訓練樣本所訓練的網絡重建結果最好.
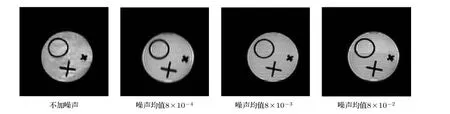
圖8 采用不同噪聲水平樣本訓練的5 層U-Net 網絡重建的水模圖像Fig.8.Water phantom images reconstructed by 5-layer U-Net trained with samples having different noise levels.
5 結論
本文提出了一種基于深度神經網絡的單掃描SPEN MRI 超分辨率重建方法.該方法根據實際實驗條件利用MRiLab 軟件制作出批量模擬訓練樣本,然后選取合適的網絡結構和參數對網絡模型進行訓練,最后將預處理后的單掃描SPEN MRI采樣信號輸入到訓練好的網絡模型,得到超分辨率圖像.與現有的超分辨率重建方法相比,本文的方法能在1 s 內快速重建出無殘留混疊偽影、紋理信息清楚的超分辨率SPEN MRI 圖像.本文也探討了訓練樣本數量和在訓練樣本中添加隨機噪聲對重建結果的影響.在未來的工作中,我們將進一步從訓練樣本制作和網絡結構方面進一步完善重建方法,并將其應用于SPEN MRI 的應用研究中.
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中國生殖健康(2019年3期)2019-02-01 06:12:26
Coco薇(2016年2期)2016-03-22 02:42:52
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
海軍航空大學學報(2015年3期)2015-11-11 17:20:00
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
