基于數據挖掘的G銀行信用卡客戶流失預測研究
2022-03-19 23:36:00沈哲
中國市場 2022年8期







摘 要:商業銀行在信用卡營銷的過程中,面臨著存量客戶流失的嚴峻問題。通過數據挖掘對流失的客戶進行分析,不僅能挽留可能流失的客戶,也可以使商業銀行有針對性地優化產品、提升管理。文章利用決策樹算法建立信用卡客戶流失預測模型,對信用卡流失客戶進行預測。經過測試,模型運行效果良好,具有較好的客戶管理意義。
關鍵詞:信用卡;客戶關系管理;決策樹;流失預測
中圖分類號:F832.4;F224-3 文獻標識碼:A 文章編號:1005-6432(2022)08-0049-04
DOI:10.13939/j.cnki.zgsc.2022.08.049
近年來,不少商業銀行的業務重心已從公司業務向零售業務轉移。公司業務客戶集中,產品偏個性化,受宏觀經濟、政策導向及個別客戶業務波動影響大;而零售業務小而分散,產品相對標準化,批量營銷、維護,行業分布貼近民生,周期性弱,受市場影響小,基礎客群較為穩定。部分轉型的商業銀行中,零售業務創造的營業收入比重過半,已超過公司業務的營業收入,零售業務在商業銀行中的地位逐漸凸顯。
而信用卡作為零售業務的“排頭兵”,在銀行零售業務的發展過程中占有舉足輕重的地位。信用卡業務的前期推廣需要大量人力、物力的投入來占領市場,構建信用卡生態圈,同業間競爭非常激烈。
隨著互聯網金融的快速發展,各大網絡平臺也陸續推出了花唄、京東白條等類信用卡產品。這些互聯網平臺不僅有著天然的消費場景,而且結合大數據的優勢,利用金融科技對消費客戶進行精準營銷,無論營銷的覆蓋面,還是精準度都大大優于傳統商業銀行,使得信用卡市場競爭更加激烈。
1 背景
就商業銀行而言,信用卡新客營銷的難度和成本遠大于存量客戶的挽留成本。信用卡新客戶的營銷難度逐年加大,需要由專業的團隊發掘客戶需求、產品準確推送并做好相關的售后服務,同時還會面臨同質產品的競爭,現在營銷往往還會借助場景的搭建。而信用卡的存量客戶已和銀行建立了業務關系,只需了解客戶流失的原因,設計有針對性的挽留方案,重新激活客戶需求(李偉等,2019)。
G銀行的信用卡銷戶概念包括兩類:銀行根據一定的規則主動銷戶和客戶主動銷戶。銷戶的原因很多,在整個信用卡業務周期的過程中都有可能產生銷戶行為。
G銀行對于停滯客戶會定期進行提取,然后給這批停滯客戶發短信進行觸動,如果沒有效果,會集中進行銷戶處理。如果客戶主動打電話要求銷戶,G銀行會安排銷戶挽留,通常客服人員會在電話中對要求銷戶的客戶進行挽留。
目前,G銀行每年信用卡的銷戶量超過5萬,G銀行只有在客戶提出申請銷戶,或者客戶滿足銀行主動銷戶規則的時候,G銀行才會安排銷戶挽留。由于無法對客戶是否流失進行預測,因此銷戶挽留沒有提前量。
2 理論基礎
2.1 數據挖掘理論
現今的信息化社會,數字生活已滲透各個角落,人們的生產、生活中留下了各式各樣的數據。數據挖掘就是將生活中的數據刪減、填補、清洗后,將參差不齊的信息整理為具備分析意義的基礎數據,從中提取有價值的數據,尋找內部規律,發掘隱藏含義,作為決策或者預測的依據。
金融、電信、醫療等行業擁有龐大的客戶信息,具備數據挖掘的先天優勢。特別是銀行業,隨著金融科技的全面推廣,不少商業銀行已將大數據、區塊鏈、人工智能等科技手段融入到零售業務的管理中,及時在市場中搶占了技術優勢。
2.2 客戶關系管理理論
客戶關系管理(簡稱CRM)原本是企業生產經營中的一個概念,指企業不應僅以簡單的產品銷售為目的,而更強調以客戶為中心的一系列綜合服務方案。提出企業應通過現代的信息技術和科技手段,在生產、銷售和服務等方面提升自己的經營管理能力,為客戶提供差別化的個性服務,提高客戶的滿意度,實現收益的最大化。
降低客戶流失率,更是客戶關系管理的基礎要求。提前對可能流失的客戶進行預測,根據不同客戶的特征,分別制訂個性化的客戶關懷和挽留策略。后臺服務創造的價值,可以超過前臺營銷,企業綜合管理能力的提升可以帶來“雙贏”的良好局面。
3 實證研究
3.1 樣本數據
樣本數據是指客戶主動聯系銀行“申請銷戶”或者銀行發起執行“申請銷戶”的動作,即可定義為“流失”;對應的流失時間分別為客戶主動“申請銷戶”的時間或者銀行執行“申請銷戶”的時間。流失客戶在樣本數據中定義為正樣本。
與流失客戶對照的是非流失客戶,取某個時間點上,其觀察期內沒有流失,同時在表現期內有完整的行為數據的客戶,即為非流失客戶。非流失客戶在樣本數據中定義為負樣本。
樣本數據從基礎數據中抽取2019年和2020年部分行為數據,觀察期定為6個月,取2019年10月1日至2020年9月30日的流失客戶構成正樣本,取2019年10月1日的非流失客戶作為負樣本,構成整個樣本數據。
基于當前數據,選擇6個觀察點來設定觀察期和表現期的時間窗口,6份正樣本的流失客戶在觀察期內都沒有流失,但在表現期內逐漸申請銷戶或者由銀行進行批量銷戶,見表1。通過觀察正樣本的消費、取現、還款、查詢行為的次數、金額、時間等趨勢變化,同時有條件的判斷客戶的投訴、違約、遲繳、爭議賬等行為來預測我行客戶流失(鄧致,2019)。
基于2019年10月1日至2020年9月30日的銷戶客戶數據統計個人流失客戶,剔除其中的高端卡客戶、測試客戶、銀行內部客戶等
3.2 變量選擇
基于對本次業務需求,建模過程中需要用到信用卡客戶的屬性特征及價值特征,通過對G銀行信用卡中心客戶信息的分析,從數據源中選取的變量主要包括以下四類:①個人基本信息:性別、年齡、職業、學歷、戶籍、婚姻等;②卡基本信息:最高卡齡、持有卡數以及信用額度等;③客戶流失信息:是否流失標識、流失時間、是否主動流失等信息;④客戶行為信息:消費、轉賬、還款等行為信息,最近查詢間隔天數等信息。
對以上幾類的變量進行篩選,從中選取客戶畫像特征明顯、卡類信息差別性較大,具有典型客戶行為動作,對可能導致未來客戶流失關系較大的變量,剔除關聯性弱,不具備分析意義的維度。
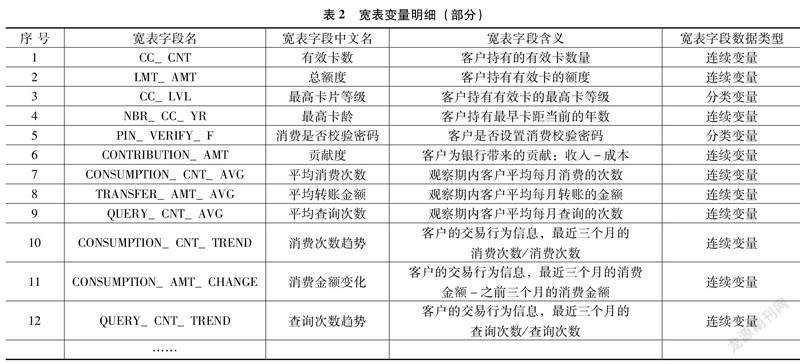
精簡分析變量,盡量減少其他數據的干擾性,從中選取43個有代表性的寬表變量,作為模型分析數據。其中部分寬表變量如表2所示(程勇等,2019)。
3.3 確定算法
信用卡客戶流失預測模型的目的是在客戶提出申請銷戶或者滿足銷戶規則之前及早的預測到客戶流失,即可以將客戶服務與關懷提前,從而降低客戶銷戶率。故根據客戶屬性特征及過去一段時間內的行為特征,預測信用卡客戶在未來一段時間內流失的可能性是建模需求的核心。
在對特征變量初步分析后,用數據分析工具SPSS提供的模型進行訓練和測試,分別選擇決策樹和神經網絡模型進行訓練,通過對其結果進行比較,發現決策樹具有較好的性能并且容易理解,因此選擇決策樹C5.0作為預測模型 (張宇等,2015)。
決策樹的圖形表示是一種倒樹形的結構,其中每個內部節點表示一個屬性上的判斷,每個分支代表一個判斷結果的輸出,最后每個葉節點代表一種分類結果。通過學習樣本得到一個決策樹,這個決策樹能夠對新的數據給出正確的分類。決策樹C5.0是基于C4.5算法的升級,更適用于數據挖掘。在模型建立階段使用代價矩陣調整置信率,同時使用Boosting技術多次迭代以調整樣本權重,提高了模型預測的準確性。
3.4 模型建立
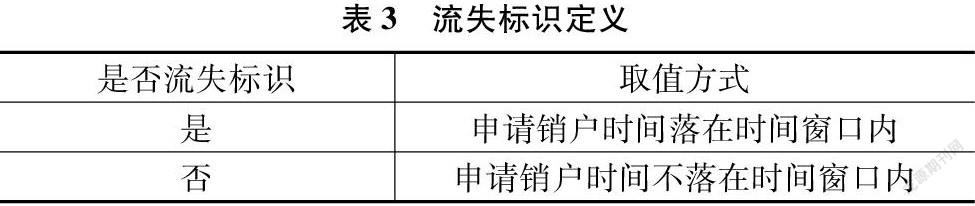
基于確定的樣本數據庫,利用SPSS數據分析工具構建決策樹信用卡客戶流失預測模型,模型的應變量為“是否流失標識”,其定義如表3所示。
由于主動申請銷戶的客戶數量過少,因此在建模過程中不區分主動或者被動銷戶,只考慮流失客戶。另外,未來保證非流失客戶在觀察期內有完整的行為數據,因此非流失客戶需要成為信用卡客戶半年以上。
模型訓練前,先根據上述是否流失標識定義做樣本數據的選擇。選擇流失與正常的客戶如表4所示。
隨機選定70%的數據作為訓練數據,剩余30%的數據作為測試數據,分布如表5所示。
在進行模型訓練的時候,對數據進行了處理加工,先使用特征選擇節點進行特征選擇,然后使用不同的模型進行訓練并比較了模型訓練的結果。
對于分類模型,判定模型結果好壞的指標有精確率、召回率和F測度,其公式如下:
精確率=模型預測為正且實際為正的樣本數量模型預測為正的樣本數量(1)
召回率=模型預測為正且實際為正的樣本數量實際為正的樣本數量(2)
F測度=2×精確率×召回率精確率+召回率(3)
在實際業務開展中,特別是流失預測模型中,需要提高模型的覆蓋率,以盡可能的識別所有可能流失的客戶,同時需要提高模型的精確度。在模型訓練過程中設置不同的代價矩陣來獲得不同的模型性能。在默認設置下精確度達到0.76以上,但是只覆蓋0.43左右的可能流失的客戶。
對業務部門來講,可以在市場營銷活動的時候覆蓋盡可能多的可能流失的客戶。這時候,需要訓練模型進一步提高其召回率,通過調整模型的代價函數,使模型的覆蓋率提升,而其精確率還滿足一定的條件。具體設置如圖1所示。
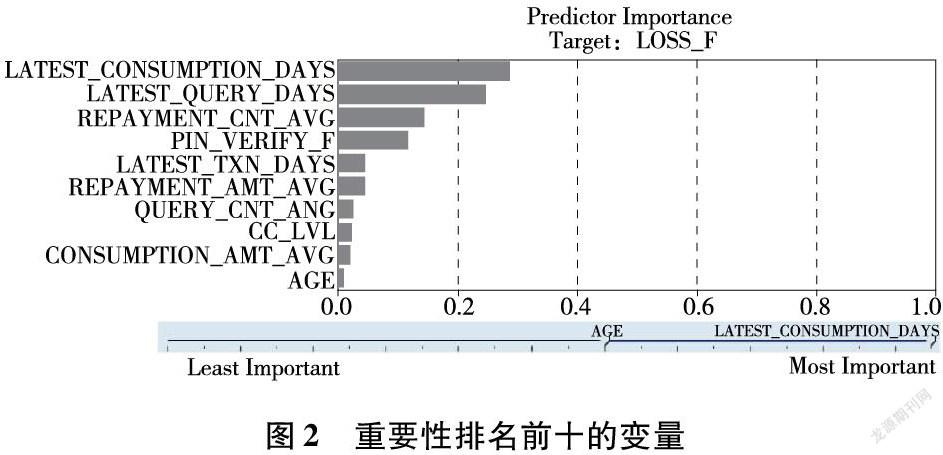
在該設置下,模型訓練后的變量重要性如圖2所示。
前十變量重要性依次是:最近消費間隔天數、最近查詢間隔天數、平均還款次數、消費是否校驗密碼、最近動賬交易間隔天數、平均還款金額、平均查詢次數、最高卡片等級、平均消費金額、年齡。
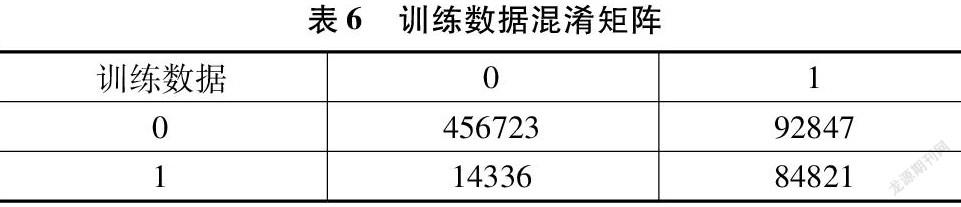
其訓練數據上的混淆矩陣如表6所示(0:未流失;1:流失):
測試數據上的混淆矩陣如表7所示(0:未流失;1:流失):
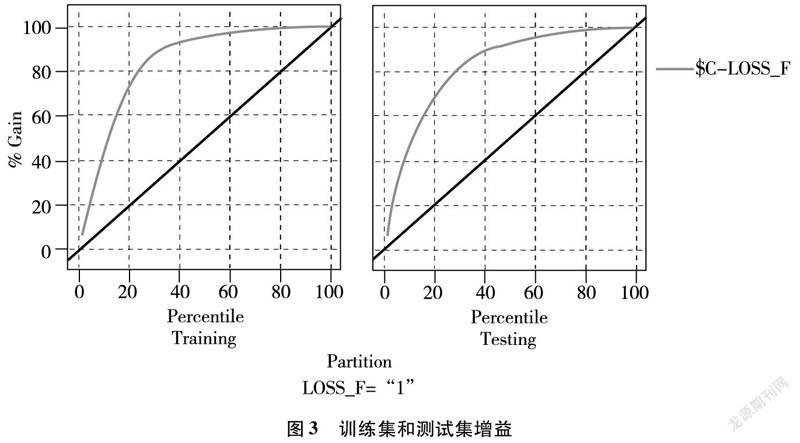
在測試集和訓練集上的增益圖如圖3所示。
其模型結果的性能指標如表8所示。
從模型結果可以看到,通過調整模型設置,隨著召回率上升到0.8以上,模型精確率下降到0.45左右,雖然精確率下降明顯,但覆蓋率也同步大幅提升,達到本次模型建立的目的,將預測范圍盡可能覆蓋到可能流失的客戶。F-測度值在默認參數時測試值為0.55,模型調整后F-測度值略有上升,說明實驗的有效性也有所提高。
從AUC和Gini系數的指標來看,原模型測試數據AUC值為0.868,Gini系數為0.736,調整后數值均有提升,并且在訓練數據上模型的表現更好。從這兩個指標來看,模型的預測能力均處于可以接受的范圍內,因此可以在實際應用中使用該模型進行預測。
4 模型應用
信用卡客戶流失預測模型主要結合信用卡業務開展,作為客戶挽留或者市場營銷等業務活動的參考依據。不同于其他模型,信用卡客戶流失預測模型應用需注意以下兩點。
第一,盡管流失預測模型能夠幫助銀行判斷可能流失的客戶,但是在流失真正發生前,銀行很難直接利用其名單進行客戶挽留。因此,需要將流失預測的結果與客戶關懷或者有針對性的市場營銷活動結合起來。
第二,信用卡客戶流失預測模型的建設,在流失客戶選取上傾向于選擇更多的樣本。在模型的實際應用中,由于流失客戶數量并沒有這么多,因此精確度會下降。故流失預測模型最為看重的是召回率,即盡可能的不要漏掉可能流失的客戶,以保障模型能夠幫助銀行盡可能的識別可能流失的客戶,從而通過客戶關懷或者營銷活動進行更多的接觸,以降低客戶的流失率。
信用卡客戶流失預測模型應參照市場營銷活動的應用場景,在制定和執行市場營銷活動的過程中,借助模型的能力提高業績考核,改造和優化現有業務流程。因此,信用卡客戶流失預測模型的應用建議落地在商業銀行的營銷管理中,成為整體營銷管理系統的一部分,對預測流失的客戶進行客戶關懷,或者開展有針對性的提前挽留、市場營銷等活動。
模型建設中以G銀行存量客戶為依據,通過決策樹進行客戶分類預測,有較好的本地化效果。但是商業銀行的客戶結構是不斷變化的,故在模型后續的應用過程中需根據客戶數據進行動態調整,提高預測的精準度。
5 總結與展望
本文通過對G銀行存量信用卡客戶的數據挖掘,用決策樹C5.0算法進行建模,對信用卡流失客戶進行預測。經過測試該模型運行效果良好,召回率在可接受范圍,下一步可將該模型投入到實際應用中。后續一方面將信用卡客戶流失預測模型應用到營銷管理過程中,對可能流失的客戶實施挽留策略,實時監控流失率的變化;另一方面定期更新基礎數據,修正、優化模型,不斷提升預測的覆蓋面和準確性。
參考文獻:
[1]程勇,梁吉祥.基于數據挖掘的掌銀客戶流失預測建模方法研究[J].中國金融電腦,2019(8):51-60.
[2]鄧致.信用卡客戶流失預測模型研究[J].金融科技時代,2019(9):22-25.
[3]李偉,孫新杰,陳偉.基于數據挖掘的客戶流失預測研究[J].電腦知識與技術, 2019,15(10):7-8.
[4]張宇,張之明.一種基于C5.0決策樹的客戶流失預測模型研究[J].統計與信息論壇,2015,30(1):89-94.
[作者簡介]沈哲(1981—),男,漢族,浙江寧波人,研究生,供職于中國光大銀行股份有限公司寧波分行,研究方向:銀行金融管理。
1913500783331
