基于深度學習圖像特征匹配的雙目測距方法
2022-03-25 04:45:32姚堯,張生
軟件導刊 2022年3期
姚 堯,張 生
(上海理工大學光電信息與計算機工程學院,上海 200093)
0 引言
隨著計算機視覺技術的飛速發展,雙目視覺系統成為一大研究熱點,在機器人視覺、軍事技術、三維重建等領域發揮著重要作用[1]。基于超聲波、雷達、紅外等技術的測距方法很早就應用在移動機器人領域中,與這些主動測距技術相比,雙目視覺測距具有成本低、魯棒性強、抗干擾性能強的優點。
雙目測距的原理是基于物體在雙目相機左右成像平面上的視差,通過相似三角形原理計算物體的真實深度。因此,對物體在左右相機成像平面的投影進行正確匹配是雙目測距系統精度的重要保證。目前,傳統的雙目圖像匹配技術包括基于全局特征匹配的GC(Garbage Collection)算法、基于半全局匹配的SGBM(Semi-global Block Matching)算 法[2]、基于局部特征的SIFT(Scale-invariant Feature Transform)算 法[3]、SURF(Speeded Up Robust Features)算法[4]以及ORB(Oriented FAST and Rotated BRIEF)算法[5]。雖然全局與半全局匹配算法能構建出完整的視差圖像,但運行速度較慢且精度較差。基于局部特征的ORB 算法運行快,但提取特征點匹配性能較差,存在大量誤匹配現象。
近年來,深度學習方法因其對深層特征有優越的學習和表達能力而被廣泛應用于計算機視覺的各個領域。例如,基于卷積神經網絡(Convolutional Neural Network,CNN)的圖像處理方法已經在圖像匹配領域嶄露頭角并取得了成效。深度學習在圖像匹配中最合理的應用便是直接從包含相同或相似結構內容的圖像對中學習到像素級別的匹配關系,其主要形式是以深度學習的方法替換傳統匹配算法中的一個或多個環節,或直接設計一個端到端的匹配網絡,從圖像中學習每個特征點的主要方向、尺度以及更具有匹配能力的描述符,代表方法包 括LIFT[6]、UCN[7]、LF-Net[8]、R2D2[9]、Superpoint[10]等。
針對雙目圖像的特征匹配,本文提出一種自監督學習的圖像特征提取網絡模型,該模型由一個編碼層與兩個解碼層構成。從雙目相機獲得的兩張圖像分別進入模型提取特征點,隨后根據特征點的描述符進行匹配并計算視差,進而獲得目標深度。實驗結果表明,本文提出的特征提取網絡具有良好性能,在雙目測距實驗中精度較高。
1 相關研究
目前,基于深度學習的圖像特征匹配方法已經逐漸取代傳統方法。例如,Detone 等[10]基于全卷積神經網絡建立了Superpoint 模型,主要功能為提取圖像的特征點并獲得對應的特征點描述符。該模型的訓練分為兩個部分,第一部分是采用監督學習方法在一個幾何模型數據集中訓練特征點檢測器;第二部分是采用預訓練完的檢測器對訓練集進行標注,獲得偽真值點標簽,再以自監督方法訓練檢測器并同時學習描述符;Truong 等[11]提出一種采用單應性變化方法訓練的特征點檢測器GLAMpoint,運用非極大值抑制方法提取圖形特征點,并結合SURF的描述符實現了特征點匹配功能;Jakab 等[12]提出一種自監督學習的特征點檢測器,利用圖像生成的方法獲得同一物體不同視角或不同相機位姿的圖片對,分別輸入神經網絡提取特征并計算損失;宋超群等[13]對ORB 算法進行了改進,在測量階段采用二維二次函數擬合的方法獲得特征點的亞像素坐標,通過三角測量原理獲得對應特征點的空間三維坐標,從而得到被測物體的尺寸;楊潔等[14]對SURF 算法進行了優化,運用FLANN 算法與PROSAC 算法進行匹配與去誤,再應用于目標測距系統中。上述研究中均是改進的傳統匹配方法,雖然運行速度較快,但提取特征點質量不高、測距精度較低。在立體匹配領域,Godard 等[15]提出的AnyNet 網絡利用U-net 特征提取4 個尺寸的特征圖,可直接通過網絡輸出圖像的視差圖,不過該類方法往往需要耗費較長的運行時間才能獲取可靠的深度數據。
基于以上分析,雙目測距特征匹配方法需要具備檢測性能強、特征點覆蓋全面、特征點匹配可靠、運行速度適宜等特性。受Superpoint 啟發,本文網絡模型也選用類似的自監督學習方法,不過訓練過程比Superpoint 簡化許多,去除了預訓練和對訓練集進行標注兩個步驟,模型直接采用真實圖像進行訓練。
2 自監督學習的圖像特征提取網絡
2.1 網絡模型
本文建立的圖像特征提取網絡包括一個共享的類VGG 卷積網絡編碼層[16]與兩個解碼層,分別為特征點檢測器解碼層和描述符解碼層。參考Superpoint的網絡模型結構,保留了編碼層與描述符的部分,對激活函數進行了改進,檢測器解碼層、訓練過程與損失函數亦不相同。整體網絡框架如圖1 所示。
2.1.1 編碼層
使用一個類VGG的卷積骨干網絡作為編碼器,作用是使圖片降維,便于提取特征。編碼層包括卷積網絡層、池化層與非線性激活函數。編碼層使用3 個最大池化(maxpooling)層,使原圖片的尺寸H×W變為Hc=H/8 和Wc=W/8。激活函數選用leaky ReLU[17]的激活函數。
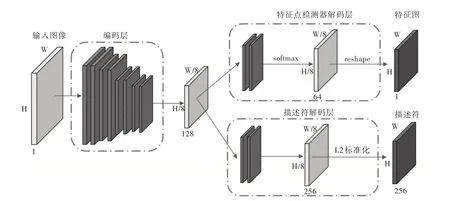
Fig.1 Architecture of the feature extraction network圖1 特征提取網絡框架
2.1.2 特征點檢測器解碼層
特征點檢測器解碼層對共享的特征圖進行兩層卷積操作,將特征圖變為H/8 ×W/8 × 64。經過Softmax的操作使特征圖取值介于0~1 之間,特征點取值接近于1 說明該位置是真實的特征點。然后經過維度變換,輸出與原圖像尺寸一致的特征點圖,用于計算特征點檢測層的損失函數。
2.1.3 描述符解碼層
描述符解碼層對描述符的特征圖進行3 次插值上采樣,再使用L2 范數將特征圖取值規范為單位長度,輸出H/8 ×W/8 × 256的稠密描述符,配合特征點檢測器輸出的特征圖進行描述符的損失計算。
2.2 模型訓練
模型的訓練基于圖片的單應性變換以及噪聲添加進行。單應性變化即一個平面到另一個平面的映射關系,包括仿射變化、透視變換等。對原圖I進行隨機單應性變化得到Ih,再對兩者計算損失函數,達到自監督學習的效果。損失函數表示為:
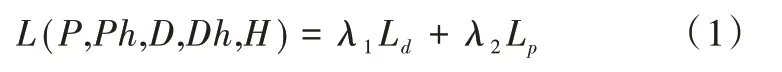
式中,λ1、λ2為權重參數,P、Ph為原圖I和變換后Ih的特征圖,D、Dh為兩圖的描述符,Ld、Lp分別為描述符及檢測器的損失函數。經過變換后,對I和Ih增加隨機噪聲,包括高斯噪聲、隨機亮度變化、椒鹽噪聲、模糊處理,以增強模型性能。
特征點的訓練原理來自于最大期望(Expectation Maximization,EM)算法,主要步驟如圖2 所示。訓練過程中需要對目標特征點進行以下處理:①在原圖I中檢測到點K,根據施加的單應性變換,將點K投射到Ih上,形成Kproj;②采用兩種方式對經過變換的點Kproj與Ih上檢測到的點Kh進行匹配,分別為2D 坐標和描述符,均采用最鄰近匹配的方式形成兩對匹配點集;③通過匹配好的點集形成目標點K′h,再根據單應性變換的逆變換投射到原圖I形成K′,與K′h組成一對點集,用于計算損失函數。
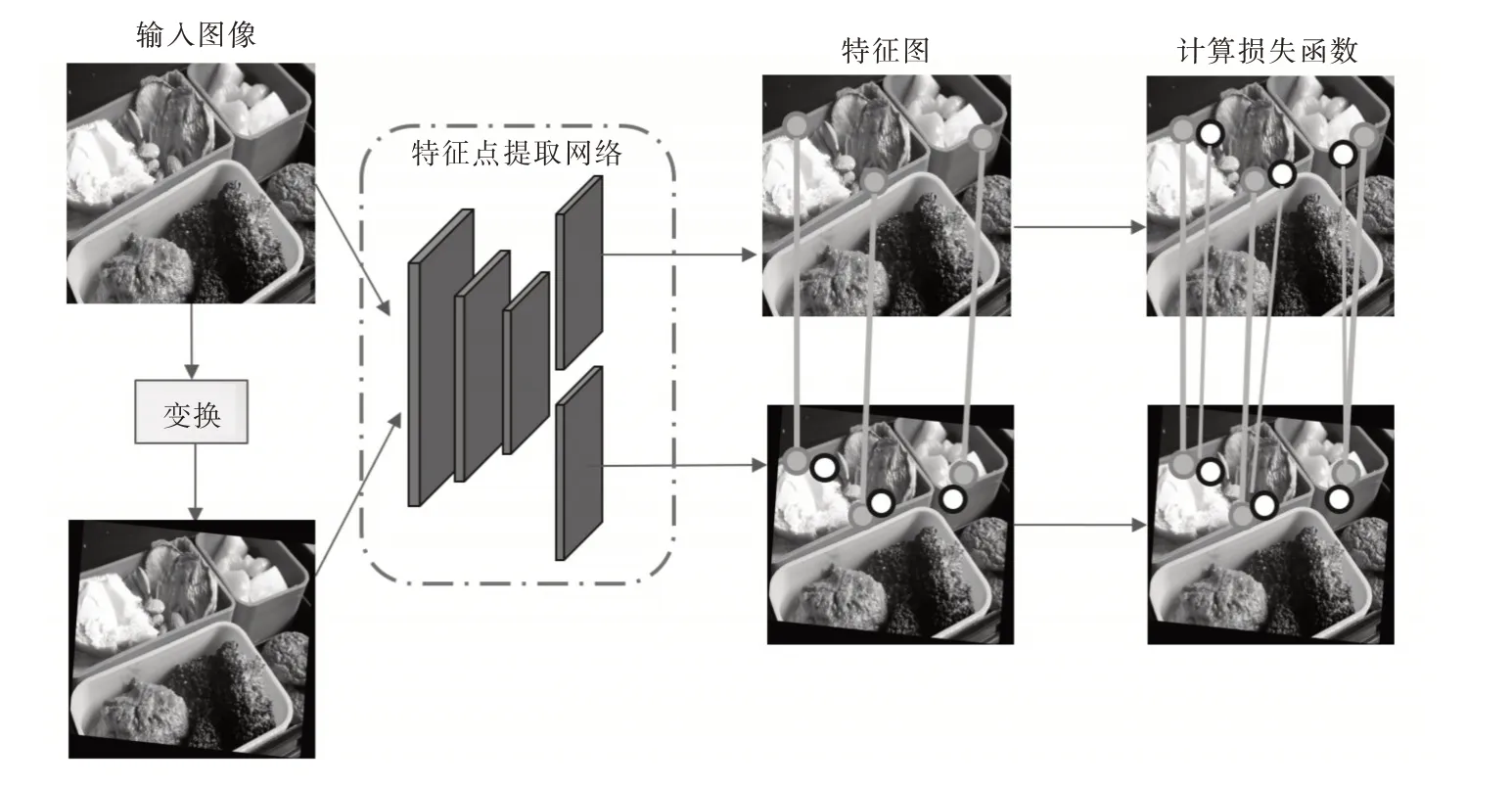
Fig.2 Feature training procedures圖2 特征點訓練步驟
2.3 檢測器損失函數
檢測器部分的損失函數應用負對數似然的方法,表示為:
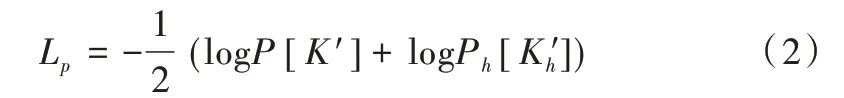
式中,P[K′]、Ph[K′h]分別表示I與Ih上檢測到的特征點分布。
給定待訓練的I與Ih兩幅圖片,通過以下步驟提取出真實特征點K′、K′h:
(1)通過兩種不同的池化操作從圖中提取出特征點集合K與Kh,分別表示為:
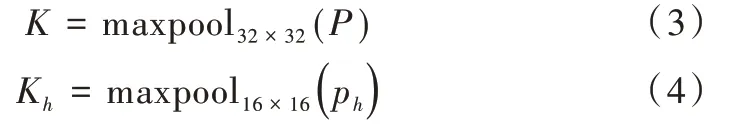
采用32×32、16×16 兩種不同大小的區域選擇特征點,可使特征點分布覆蓋全圖但不會過于稠密。圖像經過池化操作返回特征點的坐標數組(xi,yi)。
(2)對K進行單應性變換,超出圖像邊界的點則被舍棄,Dproj、Dh為Kproj與Kh的描述符。
(3)在Ih上分別根據描述符和坐標關系進行匹配,表示為:
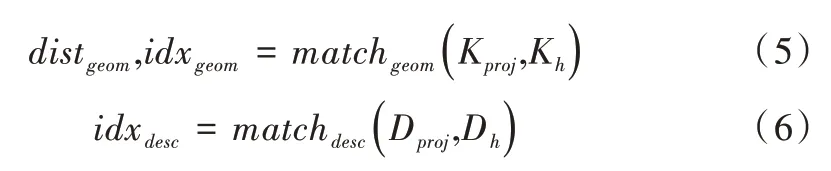
式中,matchgeom的作用是根據歐氏距離對Kproj和Kh進行最鄰近匹配,返回匹配點之間的距離以及點的索引。idxdesc給出了Kproj在描述符上最匹配點的索引。
(4)Ih上可能的真實特征點坐標表示為:
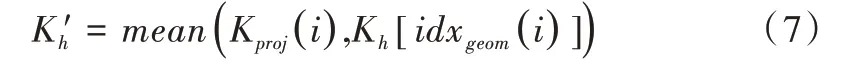
從上式可以看出,可能的真實特征點K′h由Kproj與相匹配的Kh取均值獲得,再對此進行單應性變換的逆變換,投射回原圖上,獲得K′。經過上述步驟后得到的K′、K′h用于計算損失函數式(2)。
2.4 描述符損失函數
描述符部分的損失函數包括兩個部分,表示為:
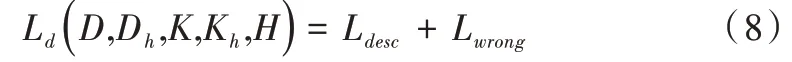
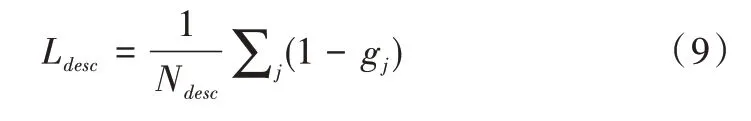
Lwrong的作用恰好相反,目的是使錯誤匹配特征點描述符的相似度最小,表示為:
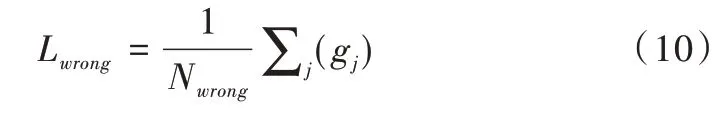
3 雙目視覺原理
雙目相機由放置在同一水平線上的兩個單目相機組成,根據物體在左右成像平面上的像素差進行深度距離測量。圖3 為雙目相機測距模型,其中b 為雙目相機的基線,f為相機焦距。假設物體的真實深度為z,距離左相機光學中心的距離為x,物體在左右相機成像平面上投影后的距離XL、XR 分別表示為:
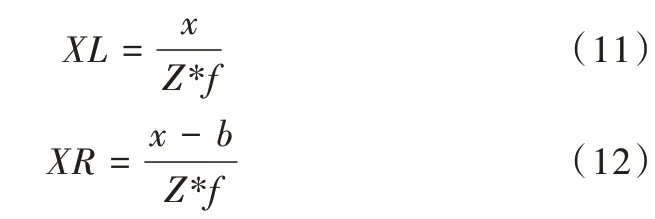
獲得XL、XR 后即可計算視差,進而計算深度,表示為:

式中,disp=XL-XR。通過式(13)即可得到物體與相機平面間的距離z。
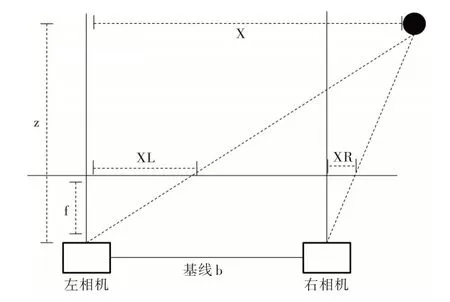
Fig.3 Binocular camera ranging model圖3 雙目相機測距模型
4 實驗方法與結果分析
4.1 特征提取網絡實驗搭建
使用PyTorch 框架搭建本文網絡模型,訓練時采用的優化算法為AdamW[18],學習率為0.000 5,數據集為MSCOCO[19]。將訓練集轉換為灰度圖,圖片大小縮放為256×256,同時將尺度變換、旋轉變換和透視變換相結合,構成隨機的單應性變換。實驗硬件平臺為Intel Core i7-8700 3.2GHz CPU,NVIDIA RTX 2080 GPU,操作系統為64 位Windows10。評價數據集為KITTI 雙目數據集[20],包括stereo2012 和stereo2015 兩部分。評價指標為重復性(Repeatability)和匹配度(Matching Score)。評價時需要設置正確匹配閾值?,? 越小表示對特征點是否匹配的判斷越嚴格,本次實驗將? 設為1px。
4.2 特征提取網絡評價
選取兩個傳統圖像特征提取方法SIFT 和ORB,以及基于深度學習的Superpoint 算法,與本文模型進行性能比較,結果如圖4(彩圖掃OSID 碼可見,下同)所示。

Fig.4 Matching result圖4 匹配結果
通過重復性指標評價各模型在相同條件下圖像特征提取結果的相似程度,結果如表1 所示。本文算法在重復性的表現上優于Superpoint,與SIFT 持平,但不及ORB 算法。原因可能是ORB 算法提取的特征點往往十分稀疏,但在提高可重復性的同時降低了挖掘特征點的能力,這點在圖4 中可以看出。
使用匹配度評價各模型的特征點不變性和辨別力,結果如表2 所示。可以看出,本文算法的匹配性能優于其余3種算法,提取到的特征點十分可靠,具有良好的不變性,為后續計算視差與深度奠定了基礎。
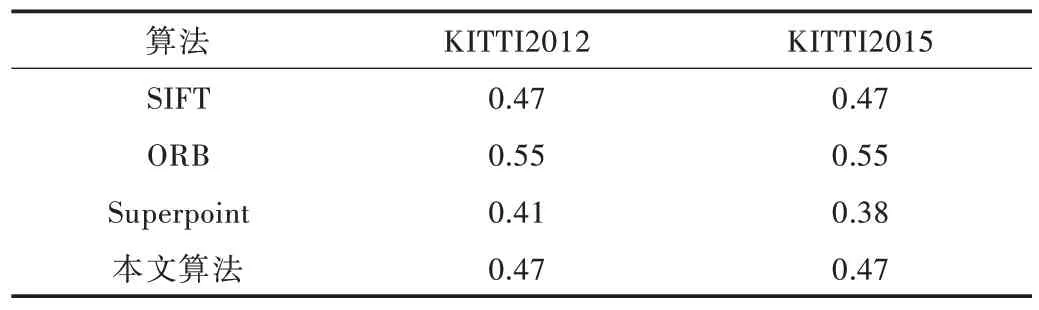
Table 1 Repeatability compaison of different methods表1 不同算法重復性比較
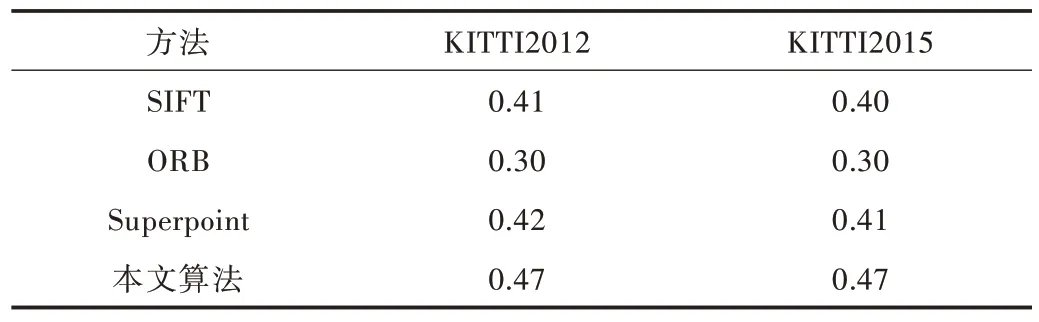
Table 2 Matching score comparison of different methods表2 不同算法匹配度比較
4.3 雙目視覺測距實驗搭建
雙目視覺測距實驗流程包括相機標定、圖像預處理、特征匹配、計算視差等。實驗選用的雙目相機型號為HBV-1780-2,設備與實驗環境如圖5 所示,白色的點即為提取出的可用于計算視差的特征點。

Fig.5 Instrument and measuring environment圖5 設備與實驗環境
相機的標定至關重要,目的是建立相機的像素坐標與空間真實坐標之間的關系,確定相機內參(焦距、扭曲因子、主點位置)和外參(平移矩陣、旋轉矩陣)。本文使用張正友標定法進行標定[21],標定板使用11×8的黑白棋盤格,單元格邊長為15mm。使用MATLAB 完成相機標定,基線距離為117.645 2mm,其余參數如表3、表4 所示。
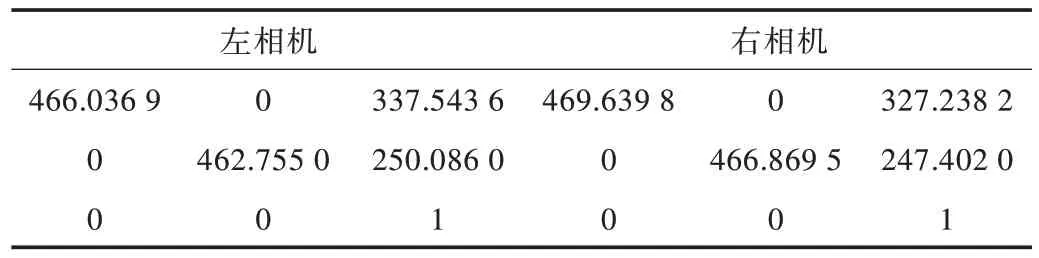
Table 3 Internal parameters of the binocular camera表3 雙目相機內參
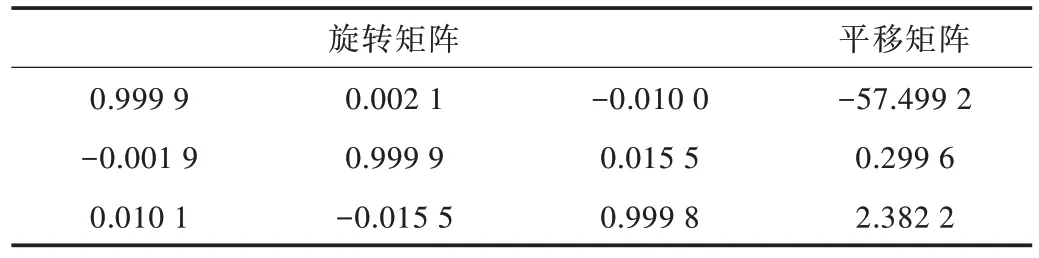
Table 4 External parameters of the binocular camera表4 雙目相機外參
4.4 雙目視覺測距算法評價
設計試驗比較本文方法與其余兩種方法的性能:方法一為基于優化SURF 特征點的深度測距法,采用FLANN 算法與PROSAC 算法對提取到的SURF 特征點進行去誤;方法二為基于AnyNet的立體匹配網絡。硬件環境準備完成后,在真實距離20~150cm的范圍內,通過測量目標物體與相機間的距離,得到3 種方法的精度。其中,AnyNet 算法從生成的視差圖中直接讀取深度信息,本文方法和SURF 需要對匹配完成的特征點計算視差,并通過相機標定得到的參數將視差轉換為真實深度值。表5 為3 種算法的測距精度比較。
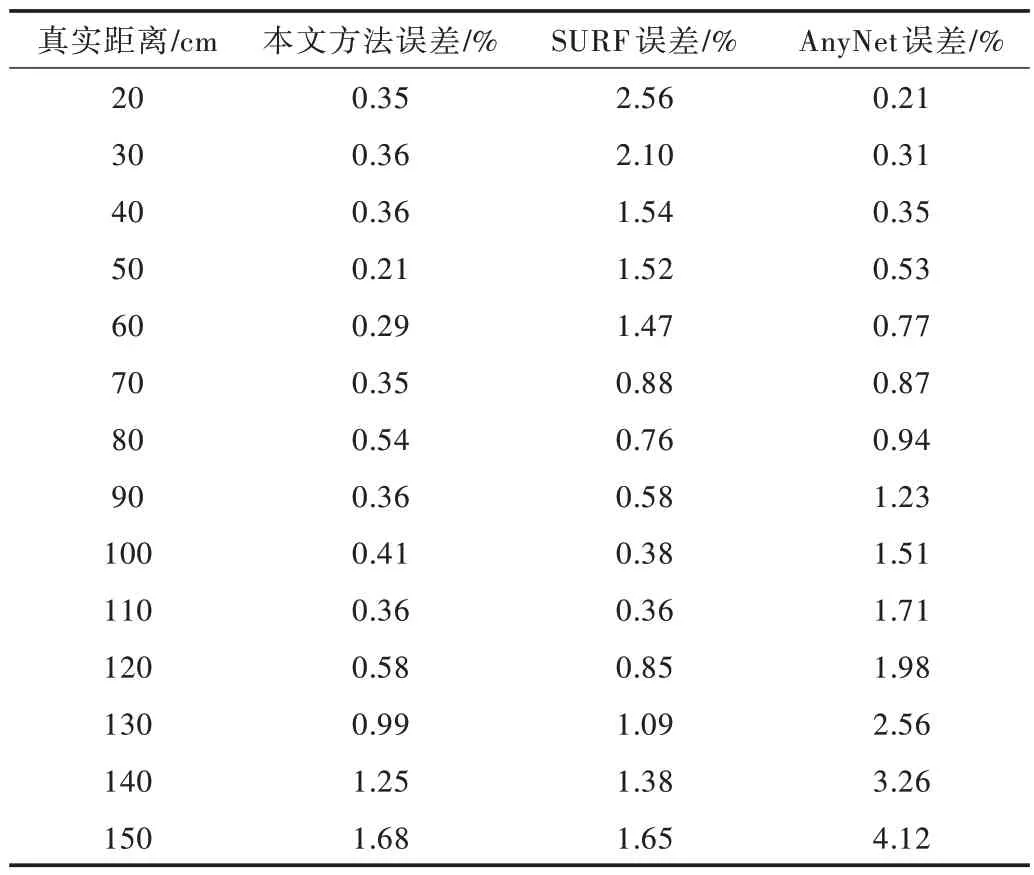
Table 5 Measuring accuracy comparison表5 測距精度比較
從表5 可以看出,在20~150cm的范圍內,本文方法的平均絕對誤差為0.58%,SURF 為1.22%,AnyNet 為1.46%。實驗過程中發現,在50cm 以內的距離,采用SURF 方法提取到的特征點數量較少,再經過一系列去誤后導致可用于計算的特征點數量不足,誤差較大。AnyNet 方法在近距離內的表現優秀,但隨著測量距離增大,誤差變化明顯,在大于120cm的距離上已經無法滿足測距要求。相比之下,本文特征提取網絡能夠提供穩定的特征點數量,且誤匹配現象較少。結果表明,本文方法在雙目測距中有較好的精度與魯棒性。
5 結語
本文提出一種自監督學習的圖像特征提取網絡模型,并將其應用于雙目視覺測距中。該模型以編碼—解碼的構造以及單應性變化的方式從圖片集中學習特征點提取的功能,其在KITTI 數據集上的表現優于一些常用測距方法。同時,在雙目測距實驗中,本文方法具有較高的精度與魯棒性,在20~150cm的范圍內平均誤差為0.58%。后續將考慮優化整個網絡模型性能以提高訓練效率,并在保證特征點匹配精度的同時減少網絡參數量,以提高模型運行速度。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
河南科技(2014年23期)2014-02-27 14:19:15
