知識圖譜問答研究進展
2022-03-25 04:45:36王月春郝曉慧王會勇
軟件導刊 2022年3期
論 兵,王月春,郝曉慧,2,谷 斌,王會勇
(1.石家莊郵電職業技術學院計算機系;2.中國郵政集團公司人才測評中心;3.河北科技大學信息科學與工程學院,河北石家莊 050000)
0 引言
問答系統(Question Answering System,QA)是利用自然語言處理技術對自然語言問句進行自動分析,并準確回復答案的智能系統。近年來,隨著信息技術的飛速發展,現實世界中的信息量呈指數式增長,傳統依賴大量規則或模板的問答系統已無法滿足人們的實際需求。為了解決傳統基于語義解析的方法中存在的問題,研究者們逐漸將研究興趣從語義解析轉移到信息檢索中。基于信息檢索的問答系統依靠關鍵詞匹配和信息提取分析淺層語義,并從相關網頁或文檔中提取相關知識,從而實現自然語言問句回答。這種方法需要問答系統預先設置問題答案,因此無法實現開放領域的問答。
隨著語義網(Semantic Web)、知識圖譜(Knowledge Graph,KG)和信息檢索技術的快速發展,一大批高質量的知識圖譜被推出,如YAGO[1]、DBpedia[2]和Freebase[3]。知識圖譜將現實世界中的知識以網狀的形式進行存儲,被廣泛應用于醫療[4]、金融[5]、軍事[6]等領域,并取得了較為顯著的效果。基于知識圖譜的問答系統(Knowledge Graph Question Answering,KGQA)根據知識圖譜內部存在的大量實體間的直接關系,挖掘并推理隱藏關系[7]。與傳統基于信息檢索的問答系統相比,KGQA 可以在知識圖譜的基礎上爭取理解用戶問題的語義,并通過實體檢索、關系推理,最終反饋最準確的答案。本文對近年來提出的知識圖譜問答技術進行追蹤和整理,為更多知識圖譜問答研究者提供參考信息。
1 背景知識
1.1 問答系統
問答系統作為人工智能中的一個關鍵領域[8],其能夠快速回答用戶利用自然語句提出的問題,是信息檢索和人工智能的交叉研究方向。早在人工智能出現早期,阿蘭·圖靈就提出了經典的圖靈測試,以驗證機器是否具有類人智能。在之后的數十年間,伴隨著人工智能技術的興衰,一大批具有代表性的問答系統不斷涌現。1966 年,Weizenbaum 設計并實現了ELIZA 聊天機器人[9],其能夠處理簡單的問題語句。公認最早應用于現實生活的問答系統是Baseball 系統,僅能限定性地回答棒球領域的基礎問題。隨后Colby 設計的PARRY 聊天機器人[10]在利用ELIZA 規則的基礎上,添加了自己的情感,成為第一個通過圖靈測試的聊天系統。這些基于規則匹配的問答系統受限于當時匱乏的數據資源,不能得到大規模應用。
隨著深度學習和自然語言處理技術的快速發展,問答系統逐漸從早期的規則匹配過渡到檢索匹配[11]。其核心思想是通過提取自然語言問句中的核心詞,之后根據問題核心詞在文檔或網頁中搜索相關答案內容,并利用相關排序算法返回對應答案。Ma 等[12]基于文檔自動檢索的方法提出偽相關反饋算法,該方法利用文檔中的上下文信息檢索最相似的答案。基于檢索的方法在提出之初取得了較好效果,但隨著數據量激增、用戶問題多樣性及自然語言復雜性等問題的出現,基于檢索匹配的問答系統從文檔或網頁中抽取的答案質量參差不齊,嚴重影響了系統的響應時間和答案的準確性。
直至知識圖譜、知識庫等概念的提出,問答系統利用知識圖譜內存在的大量結構化知識和計算機強大的算力,從根本上解決了前兩種問答系統的不足,實現了問答系統從文檔形式的問答轉變為基于知識圖譜的問答,且越來越受到研究者的重點關注,成為自然語言處理領域的熱點[13]。
1.2 知識圖譜
2012 年,Google 首次提出知識圖譜概念,并將其應用于改善傳統搜索引擎的能力。知識圖譜將現實世界中的知識以三元組(實體—關系—實體或概念—屬性—值)的形式進行組織,形成了一個多邊關系網絡,其本質是一種語義網絡,可揭示實體間的相互關系。圖1 展示了一個簡單的知識圖譜示例,其中節點表示實體或概念,連接節點的邊表示實體間的關系或概念的屬性。根據知識覆蓋領域不同,知識圖譜可簡單分為通用領域知識圖譜(如:Wikidata[14]、DBpedia、CN-DBpedia[15]、Freebase 等)和特定領域知識圖譜(如:阿里商品圖譜[16]、美團美食圖譜[17]、AMiner[18])。傳統知識圖譜構建方法包括實體識別[19]、實體消歧[20]、關系抽取[21]和知識存儲等。
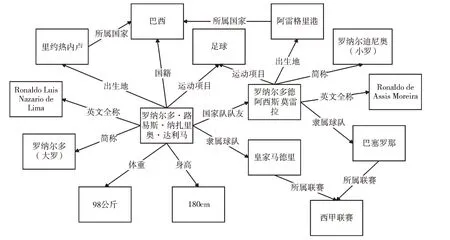
Fig.1 Simple example of knowledge graph圖1 知識圖譜簡單示例
隨著深度學習的出現和快速發展,知識圖譜也逐漸由“符號”連接轉變為“向量”表示。Boards 等[22]提出的TransE模型將知識圖譜中的實體和關系嵌入到低維向量語義空間,把關系向量視為頭實體向量到尾實體向量的一種翻譯;Lin 等[23]提出的TransR/CTransR 為每個關系設置一個獨有的關系矩陣空間Mr,并將實體和關系通過Mr矩陣嵌入到向量語義空間中進行翻譯計算。基于知識表示學習的知識圖譜構建方法從根本上解決了傳統知識圖譜構建方法帶來的長尾效應,極大提高了知識圖譜的可用性。
2 知識圖譜問答主要方法
KGQA的關鍵問題是如何將自然語言問題轉換為計算機可以理解的形式語言,并在構建好的KG 內通過查詢、推理獲得問題答案,其本質是自然語言處理的問題。現有KGQA的主要方法大致可以分為:基于語義解析的方法(Semantic Parsing-based Method)、基于信息檢索的方法(Information Retrieval-based Method)、基于知識嵌入的方法(Knowledge Embedding-based Method)。圖2 展示了上述3種方法的主要工作流程。其中,基于語義解析方法的核心思想是將自然問答語句解析為SPARQL 查詢語句,并以此獲取答案核心詞實現問題的回答;基于信息檢索方法的核心思想是將自然語言語句進行識別和抽取,構建知識圖譜查詢子圖,并以此從知識圖譜內獲取最優結果;基于知識嵌入方法的核心思想是將知識圖譜和自然問句嵌入到低維空間中進行向量計算以獲取最優結果,從而實現知識問答。
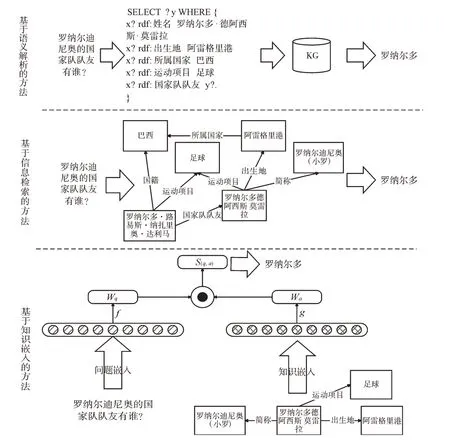
Fig.2 Main methods of knowledge graph question answering圖2 知識圖譜問答主要方法
2.1 基于語義解析的方法
基于語義解析方法的KGQA 主要是將非結構化的自然語言轉換為一系列的邏輯表達式,并將拼接后的邏輯表達式放入知識圖譜中,查詢問題的最終答案。這種基于語義解析的方法對問題答案的可解釋性較高,能夠解釋KGQA系統答案的來源。基于語義解析的方法主要包括直接映射和神經網絡兩種。
2.1.1 直接映射方法
直接映射方法主要采用語義解析語法工具完成邏輯表達式構建。Steedman[24]提出的組合范疇語法(Combinatory Categorial Grammar,CCG)使用詞匯表完成問句到邏輯表達式的轉化,并通過排序算法選擇最佳邏輯表達式;Artizi 等[25]將CCG語義類型部分中的λ-算子替換為AMR(Abstract Meaning Representation),從而提升了語義解析效果;Berant 等[26]將CCG 語義解析直接融入KGQA 中,解決了傳統語義解析器需要大量人工標注的詞匯表問題。基于CCG 語法的語義解析方法具有很強的可解釋性,同時結構也較為清晰,在特定領域取得了較為出色的效果,但面對大規模通用知識圖譜時該方法使語義歧義問題更加凸顯。
Reddy 等[27]對自然語言問題語句進行分析,將傳統直接映射方法分析問句的依存解析樹轉為構建自然語言問句所對應的知識圖譜子圖,并將子圖映射到知識圖譜中,利用圖匹配方法實現問題回答;Hao 等[28]將自然語句解析為復雜的知識圖譜子圖,從而實現復雜問題回答,且模型效果較為出色;孟明明等[29]設計一種語義查詢拓展方法解決從數據源中難以獲得理想答案的問題,該方法對問題三元組中的查詢術語從3 個語義角度進行拓展,實現了對問題三元組的多語義拓展;Hu 等[30]認為基于語義解析方法的知識圖譜問答大致分為問題理解和查詢評分兩個階段,難點在于解決問題理解階段中的歧義性問題,即解決短語鏈接問題和復合問題。為此,他們提出一種基于圖匹配的方法,該方法將解決歧義問題與查詢評分兩個階段進行融合,并提出關系優先(relation-first)和節點優先(node-first)的方法,relation-first 方法盡可能地抽取對應關系,并根據句法樹中識別出的實體構建查詢圖,node-first 方法則從自然語言問句中抽取對應的實體,再對實體間的關系進行填充以構建查詢圖。這種方法不需要人工定義邏輯表達式模板,且對復雜問題解析非常有效。Dhandapani 等[31]認為直接將問題轉化為三元組的方法無法獲取問題中的語義信息,為此他們提出一種基于問題類型分類的模板匹配方法,該方法對問題類型進行分類,并為每種類型找到最合適的SPARQL 查詢模板。該方法在QALD-8 數據集上表現出較好的優越性。
直接映射方法可以較為清晰地將自然語言問題語句轉換為邏輯表達式,但該方法需要人工定義大量的邏輯表達規則,在特定領域內表現尚佳,而在面對大規模知識圖譜時無法實現未定義規則的轉化,造成通用性較差。
2.1.2 神經網絡方法
為了解決直接映射方法無法處理未定義規則轉化問題,研究者受到機器翻譯中編碼器—解碼器結構網絡(Sequence-to-Sequence,Seq2Seq)思想啟發,提出神經網絡方法。基于神經網絡方法的語義解析模型將自然語言問句翻譯成邏輯表達式,并將翻譯后的邏輯表達式放入知識圖譜中實現問題回答。
Dong 等[32]提出一種基于注意力增強機制的編碼—解碼(Encoder-Decoder)方法,從而將語義解析問題轉換為翻譯問題。具體而言,他們設計了Seq2Seq 模型和Seq2Tree模型。其中,Seq2Seq 模型將語義解析視為序列轉換的一種任務,Seq2Tree 模型配備了分層樹解碼器,可以清晰地捕獲用于翻譯后的邏輯表達式。Dong 等[32]的方法主要關注的是解碼器部分,而Xiao 等[33]認為編碼器對語義解析非常重要。為此,他們將符號先驗知識引入RNN 模型中,從而實現語義解析。在Xiao 等[33]的基礎上,Xu 等[34]使用圖編碼器(Graph2Seq)對語義圖進行編碼,之后將注意力機制引入RNN 模型對編碼結果進行解碼,以獲得邏輯表達式;Cao等[35]為了更好地對問題與知識圖譜Schema 以及Schema 內部關系進行建模,提出一種結合線性有向圖和普通有向圖的Text2SQL 模型。該模型通過引入線性有向圖,在簡化問題子圖的同時突出實體間的關系,同時該模型還設計了問題子圖修剪的輔助任務,從而對局部圖特征和非局部圖特征進行區分。Cao 等[35]在Spider 數據集上測試了所提出的方法,結果表明其在Spider 上已超過所有基準模型,成為最優方法。Zhu 等[36]認為基于神經網絡的方法主要關注了問題和關系之間的語義對應,忽視了問題的結構信息,為此他們提出了一種Tree2Seq的模型。該模型將問題的結構信息編碼到其向量空間中,從而提升它與自然語言問句匹配的準確性。Zhang 等[37]提出一種Multi-point語義表示框架,其將每個屬性拆分為細粒度的4 種因子(topic、predicate、objectcondition、query type)以此區分易混淆的屬性,之后利用雙向注意力compositional intent 模型(Compositional Intent Bi-Attention,CIBA)將粗粒度的屬性信息和細粒度的因子與自然語言問句表示相結合,從而實現問句語義表示的增強。
相比于直接映射方法,神經網絡方法不需要預先定義大量的邏輯表達式模板,但因神經網絡存在黑盒效應,造成其可解釋性較差,同時該方法還需大量的訓練語料,導致訓練時間過長。
綜上所述,基于語義解析的方法旨在將自然語言問句通過直接映射或神經網絡等方式轉化為邏輯表達式,進而放入知識圖譜中進行查詢,最終生成最優答案。但無論是直接映射方法還是神經網絡方法都有其優缺點,構建低成本、高可解釋性的模型成為該類方法的主要研究方向之一。表1總結了基于語義解析的方法優缺點和主要適用范圍。
2.2 基于信息檢索的方法
基于信息檢索的方法是將自然語言問句進行分析,提取其中包含的問題實體構建知識圖譜子圖,并在知識圖譜內根據構建的子圖選取多跳內的相關實體作為候選答案集合,之后根據問題及答案中的人工特征對候選答案進行排序,輸出最優答案。基于信息檢索的方法與基于語義解析的方法之間并沒有直接關系,基于語義解析的方法是受到基于信息檢索方法原理啟發,并進行相應演變而得到。基于信息檢索的方法主要分為特征匹配方法和神經網絡方法。
2.2.1 特征信息匹配方法
Yao 等[38]最早提出特征信息匹配方法,其將開放知識圖譜Freebase 作為信息檢索數據集,并將特征信息分為問題特征信息和答案特征信息。
(1)問題特征信息。Yao 等[38]首先使用依存句法分析方法對自然語言問句進行分析,生成其對應的語法依存樹(或稱為問題圖)。語法依存樹中主要包含問題詞(question word,qword)、問題焦點(question fucus,qfocus)、問題主題詞(word topic,qtopic)和問題中心動詞(question verb,qverb)4 個問題特征,其中問題詞如when、who 等作為問題的明顯特征;問題焦點主要表明答案的類型,如name、time、place 等;問題主題詞表示問題的實體可用來尋找相關頁面以幫助尋找答案,其中問題主題詞使用實體識別方法(Named Entity Recognition,NER)確定;問題中心動詞能夠提供與真實答案相關的特征信息,如play、wear 等。總體而言,從自然語言問句到語法依存樹之間的轉換,實質就是對問題進行信息提取,抽取出對尋找答案有利的問題特征,并剔除掉無用信息的過程。

Table 1 Summary of the existing semantic parsing-based methods表1 基于語義解析的方法小結
(2)答案特征信息。Yao 等[38]在Freebase 內檢索語法依存樹中所有的Qtopic 多跳內的實體節點,將其組合成候選答案集,答案集中包含實體和實體間的關系。其中,候選答案集中最重要的特征是實體間的關系與問題直接的關聯度,這一特征值主要是通過檢索關系表ReverbMapping獲得。并且,將屬性或者實體之間的有向關系也作為節點的特征類別。
將分析得到的語法依存圖中的所有特征與答案特征圖中所有節點的特征進行組合,形成候選答案特征集,捕獲問題與答案的關聯關系和其對應的權重。在候選答案特征集找到最優答案,其本質是一個二分類問題,Yao 等[38]將WebQuestion 作為數據集利用L1 正則化的邏輯回歸模型訓練一個分類器以尋找最優答案。
圖3 展示了Yao 等[38]提出的基于特征匹配問答方法的基本思想,總體而言該方法將自然語言問句轉化為問題特征子圖,將知識圖譜內的答案特征作為檢索元,且聚焦在權重較高的答案特征節點上,從而減少搜索空間,獲取最優答案。該方法優化了答案生成過程,且在大規模通用知識圖譜中表現出較好的適用性和優越性,但面對復雜問題或復雜關系時仍然存在一定缺點。Vakulenko 等[39]為了解決傳統特征匹配方法存在的問題,提出一個新的基于特征匹配的復雜KGQA 方法。該方法使用無監督方法通過解析文本并將知識圖譜中屬于匹配到一組可能的答案而獲得相應置信度,并對置信度進行排名以獲取最優答案。
2.2.2 神經網絡模型
隨著機器學習和神經網絡技術的快速發展,研究人員將神經網絡模型引入信息檢索過程中,以實現候選答案排序和關系匹配。Dong 等[40]提出一個基于Freebase的自動問答模型,該模型在不使用任何手工特征和詞匯表的基礎上,利用多列卷積神經網絡(Multi-column Convolutional Neural Networks,MCCNNs)從答案路徑、答案背景信息,以及答案類型方面理解問題,從而實現問題特征的提取和分類,并將答案的嵌入向量和前者同時作為評分函數,獲取評分最高的候選答案。Dong 等[40]在WebQuestion 數據集上測試了MCCNNs 模型的效果,其結果在各項性能上均表現出了優越性。隨著注意力機制逐漸成為解決KGQA 問題的關鍵技術,Golub 等[41]將注意力機制引入信息檢索過程中,并將原來的詞級別嵌入替換為字符級嵌入,提出一個引入注意力機制的字符級編碼器和解碼器模型,有效地改進了問答系統中詞表外問題的回答效果;Hao 等[42]將交叉注意力機制引入問題表示和候選答案生成環節,其結果優于MCCNNs 模型。
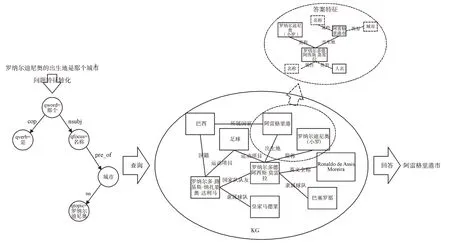
Fig.3 Example of feature matching method圖3 特征匹配方法示例
此外,Yu 等[43]提出關系檢測的HR-BiLSTM 模型,該模型使用殘差雙向長短期記憶網絡(BiLSTM)在不同層面上對問句和關系進行對比,從而根據給定的問句識別出其對應關系,該方法在KGQA 數據集SimpleQuestions[44]和Web-QuestionsSP[45]上獲得了最佳結果;Qiu 等[46]提出一個基于強化學習的神經網絡模型(Stepwise Reasoning Network,SRN),SRN 模型將問題形式化為一個順序策略問題,并使用注意力機制決定獲取問題中的獨特信息,極大程度上提升了基于信息檢索方法的問答效果;Xu 等[47]認為雖然KG中包含豐富的結構信息,但缺乏上下文以提供更精確的概念理解。為此,他們設計一個使用外部實體描述來提供知識理解的模型以輔助完成知識問答。該方法在CommonsenseQA 數據集上實現了最優效果,且在OpenBookQA的非生成模型中獲得了最好結果。
神經網絡方法是基于信息檢索方法中較為理想的方法,其對簡單問題和復雜問題具有較優的適用性,但在縮小搜索空間方面仍有不足。
綜上所述,基于信息檢索的方法是將自然語言問句中的實體和關系進行識別和抽取,從而構建知識子圖。利用子圖在知識圖譜中搜索查詢候選答案實體集,并根據問題及答案中的人工特征對候選結果進行排序,輸出最優答案。基于信息檢索的方法不需要大量的人工標準邏輯表達式規則和龐大的詞匯表,但仍然面臨著時間復雜度過高、語義信息太復雜等問題的挑戰。基于信息檢索的方法優缺點和主要適用范圍如表2 所示。

Table 2 Summary of information retrieval-based methods表2 基于信息檢索的方法小結
2.3 基于知識嵌入的方法
知識嵌入方法是將知識圖譜中的實體和關系嵌入到低維稠密的向量語義空間中,并對其進行特定的向量計算。這種針對知識三元組進行嵌入的方法不同于傳統詞嵌入方法,知識嵌入能夠直接表示實體與關系間的語義相關性,能夠保存知識圖譜中原有的信息量。Boards 等[22]受word2vec 中詞向量遷移語義不變現象的啟發提出翻譯模型TransE。如圖4 所示,TransE 模型將知識三元組嵌入到低維稠密向量語義空間中,并在空間內構建h+r≈t的向量表示,其中h表示頭實體向量,r表示關系向量,t表示尾實體向量。TransE 模型的提出極大程度上解決了傳統知識圖譜中存在的計算量大、長尾效應等問題。隨著研究的不斷深入,研究人員提出了多種知識嵌入模型及其應用,如TransH[48]、TransR、ConvE[49]、ITMEA[50]等。

Fig.4 Example of TransE model圖4 TransE 示例
Wang 等[51]基于知識嵌入模型提出一種解決SPARQL未匹配到答案的方法。該方法專門為SPARQL 查詢語句設計了一個知識嵌入模型,使得答案實體在向量空間中與問題實體建立特定的關聯關系,從而更高效地生成高質量的近似答案;Huang 等[52]提出一種基于知識嵌入的問答系統,其設計了一個謂詞與頭實體學習模型,將問題視為輸入,返回與問題謂詞/實體更接近的嵌入向量,進而確定頭實體和關系,并利用實體鏈接方法找到尾實體,從而實現問題回答;Saxena 等[53]提出一種利用知識嵌入改進多跳KGQA的方法EmbedKGQA,該方法包含知識嵌入模塊、問題嵌入模塊和答案選擇模塊。其中,知識嵌入模塊將知識圖譜中的所有實體進行嵌入,得到實體對應的嵌入向量;問題嵌入模塊將問題視為輸入,獲得其對應的問題向量;答案選擇模塊則將所有可能的答案實體向量與問題向量進行關聯評分,選擇得分最高的實體。此外,為了解決大規模知識圖譜造成搜索空間過大的問題,設計了一個候選實體修剪方法,極大改善了EmbedKGQA的性能。EmbedKGQA 方法在MetaQA KG-50 和WebQSP KG-50 數據集上表現出了較好的效果,超過了所有的基準模型,成為最優模型(State-Of-The-Art,SOTA)。Niu 等[54]認為前期引入知識嵌入的知識圖譜問答方法只考慮了三元組信息,忽視了路徑與多關系問題間的語義。為此,他們提出了一個路徑和知識嵌入增強的多關系問答模型PKEEQA,該模型利用KG中實體間的多條路徑評估路徑嵌入和多關系問題嵌入間的相關性,并制定了一套路徑表示機制。通過實驗對比,PKEEQA 模型提升了多關系問答性能,同時一定程度上從路徑信息方面得到了答案的可解釋性。
綜上所述,知識嵌入方法是將知識圖譜中的知識三元組根據一定關聯關系嵌入到低維向量語義空間,這種做法能夠最大程度上表示頭、尾實體與關系間的聯系,從而保留知識圖譜中的重要信息。基于知識嵌入的問答方法對未知問題具有較高的處理效果,同時其對大規模通用知識圖譜具有較優的魯棒性和適應性。然而,如何將新知識引入到已構建好的知識嵌入模型中成為知識嵌入方法亟待解決的問題,也成為基于知識嵌入問答能否回答新知識的關鍵所在。表3 展示了基于知識嵌入的方法優缺點和主要適用范圍。

Table 3 Summary of knowledge embedding based methods表3 基于知識嵌入的方法小結
3 知識圖譜問答數據集
隨著知識圖譜問答技術的快速發展,知識圖譜問答數據集不斷被提出。現有知識圖譜問答數據集可大致分為通用領域知識圖譜問答數據集和特定領域知識圖譜問答數據集,詳細的知識圖譜問答數據集比較如表4 所示。
3.1 通用領域知識圖譜問答數據集
WebQuestions 是2013 年 由Berant 等[26]利 用Google Suggest 生成,數據集為每個答案都提供了其對應的主題節點。WebQuestions 數據集采用先提問后解答的構建思路,同時數據集的問題獨立于Freebase 知識庫外,從而比Free917[55]數據集更加自然,更偏向于自然語言,但該數據集僅提供了答案而沒有給出對應的查詢語句,從而造成邏輯表達式的生成變得極為困難,此外數據集中只包含少量的復雜問句。
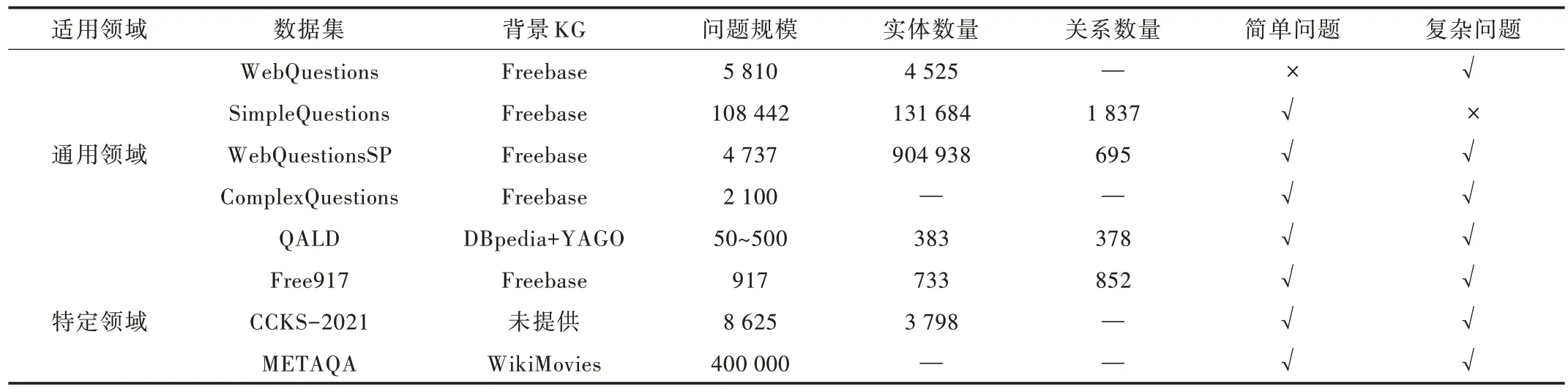
Table 4 Datasets of knowledge graph question answering表4 知識圖譜問答數據集
SimpleQuestions 是Bordes 等[44]提出的一個大規模問答數據集。該數據集以問答系統處理覆蓋面為主要研究內容,數據集內包含了大量的簡單問答語句,這些問答語句可以用知識三元組進行回答,同時數據集中包含了問題對應的查詢語句。
WebQuestionsSP 是Yih 等[45]對WebQuestion 數據集進行改進,補全了問題所對應的查詢語句,可以簡單地將其視為WebQuestions 數據集的子集。
ComplexQuestions 是Bao 等[56]為了測試KGQA對復雜問題的處理能力所提出的一個多限制問答數據集。Bao等[56]從WebQuestions 訓練集和測試集中分別抽取了596 個和326 個問題,從搜索引擎中爬取了878 個問題,并從其他數據集中抽取了300 個問題從而構建ComplexQuestions 數據集。然而,ComplexQuestions 數據集內未提供問題所對應的查詢語句。
QALD[57-61]是一種通用領域的大規模數據集,相比于其他知識問答數據集更加生活化、復雜化。QALD 數據集不僅包含問題和答案,還為每個問句設置了關鍵詞和對應的查詢語句。
3.2 特定領域知識圖譜問答數據集
Free917 是2013 年由Yahya 等[55]提出,數據集以房地產領域數據為主,并將數據形式化表示為“問題-λ 微積分表達式”。數據集中問題的答案為Freebase 知識庫中的某個屬性,同時通過人工定義的方式提出與其相關的自然語言問句。然而,Free917 并未對問題類型進行限制。
CCKS 問答數據集是CCKS 全國知識圖譜與語義計算大會提出的一項知識圖譜問題評測任務所使用的數據集。CCKS 每年提出一個全新的知識圖譜評測任務和數據集,包含保險領域問答、醫療領域問答等。數據集中包含了大量真實且復雜的問答語句,但未給出其對應的查詢語句。
METAQA 是由Zhang 等[62]構建的電影領域知識圖譜問答數據集,數據集中包含了近29 000 個多跳測試查詢數據。
4 知識圖譜問答測評指標
4.1 功能性測評指標
功能性測評指標主要反映知識圖譜問答方法(系統)返回答案的正確性和完備性,當返回的答案與正確答案無關時評定其為錯誤答案,相關但不完備時也將其評定為錯誤答案。通常功能性測評指標指精確率、召回率、準確率、F1 值。
(1)精確率。精確率(Precision)指問答方法對每個自然語言問句給出的黃金標準答案(問題對應的一個標準答案)占所有返回答案總數的比例。精確率計算公式可以形式化表示:

(2)召回率。一個自然語言問句可能存在多個標準答案,如:問題“杭州有那些景點?”就有多個標準答案,因此需要評測知識圖譜問答方法召回完整答案的能力。召回率(Recall)表示知識圖譜問答方法返回的正確答案數占返回的黃金標準答案的比例。召回率計算公式可以形式化表示為:

(3)準確率。準確率(Accuracy)表示知識圖譜問答方法回答正確的問題數占所有問題的比例。準確率計算公式可以形式化表示為:

通常使用準確率定義指標Hits@K,即將答案列表按照特定值進行排序,如果前K 個答案中有一個正確的則為1hit,否則為0hit,并最終計算整個問題集的平均值。
(4)F1 值。通常知識圖譜問答方法(系統)的總體性能使用F1 值對精確率和召回率進行整體測評。測試集中的每個問題都有其對應的F1 值,其計算公式可以形式化表示為:

4.2 性能測評指標
除上述功能性測評指標外,還可以從性能指標角度對知識圖譜問答方法(系統)進行測評。具體而言,知識圖譜問答方法(系統)的性能測評指標分為方法響應時間和方法故障率兩方面。
(1)知識圖譜問答方法(系統)響應時間。通常,智能問答系統需要實時響應用戶的文本或語音輸入,因此知識圖譜問答方法(系統)的響應時長(Response Time)成為測評方法性能的一個重要指標。如果響應時間過長,知識圖譜問答方法的可用性就會大大降低。一般而言,知識圖譜問答方法的響應時長應縮短到1s 以內。
(2)知識圖譜問答方法(系統)故障率。知識圖譜問答方法(系統)出現故障的概率,即統計方法在回答自然語言問句時發生系統錯誤或故障的比率,通常采用壓力測試檢驗知識圖譜問答方法(系統)的故障率。
5 知識圖譜問答研究挑戰與機遇
5.1 面臨的挑戰
(1)語義歧義。無論是利用語義解析方法還是信息檢索方法,都需要將自然語言問句映射到知識圖譜中,因此實體鏈接和關系抽取成為關鍵過程。然而,現有實體鏈接方法的質量并不高,使得錯誤實體信息被不斷傳遞到關系提取階段,造成自然語言問句無法與知識圖譜進行匹配或無法避免增大搜索空間。雖然現有許多語義表示方法在不斷地改進實體鏈接和關系抽取的效果,但如何從自然語言問句中精確完整地獲取語義信息成為KGQA 面臨的一大挑戰。
(2)復雜問題。復雜問題中常常包含多個問題實體和關系,需要KGQA 系統具有推理和判斷的功能。例如:“2020 年東京奧運會男子乒乓球比賽項目單打冠軍分別戰勝了那些對手?”然而,現有的KGQA 對于簡單問題(僅有一個問題實體和關系)的處理能力已較為優秀,但對于真實應用場景中復雜問題的處理能力尚且不足。雖然,研究人員嘗試解決平行的復雜問題,但仍然無法解決大多數復雜問題。因此,對于復雜問題的處理與研究成為學術界和工業界亟待解決的重大挑戰。
(3)長尾問題。長尾問題包括知識圖譜長尾問題和問句長尾問題。知識圖譜長尾問題指現有大規模知識圖譜中存在著大量的實體和關系,這些實體和關系中只有部分實體間存在大量的關系連接,但其他實體僅有單一或少量關系,從而造成答案實體的搜索空間和計算量劇增。問句長尾問題指少量表示相似含義的問句頻繁出現在問答數據集中,造成KGQA 系統對于該類問題有較強的回答能力,而對于大量出現頻率較低的問句處理能力較弱。因此,知識圖譜長尾問題和問句長尾問題成為阻礙KGQA 性能進一步提升的關鍵因素。
5.2 未來研究方向
(1)知識圖譜推理機制。現有的知識圖譜推理機制常常根據知識嵌入后的知識三元組對實體或關系進行推理,但使用該機制預測缺失實體或關系的能力尚不足以支撐復雜問題的知識推理,尤其是對長尾關系的知識三元組的推理。目前,除利用知識嵌入方法外,還可以使用統計關系學習和GNN 等方法進行知識推理。如何將高效的推理機制引入知識圖譜內,充分利用圖譜中高質量的三元組信息實現復雜問題的回答,成為未來研究的熱點問題。
(2)預訓練模型有效利用。隨著預訓練模型的出現,包括智能問答在內的多項自然語言處理任務的性能不斷被突破,許多研究人員致力于將預訓練模型與知識圖譜相結合,使得在KGQA 訓練數據較少的情況下,仍然能夠取得相比于傳統KGQA 方法更優的問答效果[63]。但如何將預訓練模型更加充分地與KGQA 相結合,利用好預訓練模型和知識圖譜中的先驗知識,同樣成為提升KGQA 性能的熱點研究方向。
(3)多模態知識問答。隨著多模態數據(如圖像、視頻、文本描述數據等)越來越多地被用來提升知識圖譜的表示能力[50,64-66]。多模態知識圖譜能夠有效提升知識的多樣性、豐富知識的隱藏信息,能更加完整地組織知識圖譜內的知識。因此,為了滿足用戶日益增長的知識和認知服務需求,利用多模態知識圖譜進行知識問答成為未來主要研究方法。
綜上所述,知識圖譜問答方法在處理簡單、開放領域問題方面已經取得較為突出的進展,但仍然面臨著語義歧義、復雜問題理解、知識圖譜長尾和自然語言問句長尾等多因素的挑戰。這些挑戰成為阻礙知識圖譜問答系統大規模應用于實際生產環境的重要因素。同時,隨著自然語言和深度學習技術的快速發展,如何將多模態信息和預訓練模型等新思想引入知識圖譜問答方法中也成為未來主要研究方向,如利用預訓練模型獲取結構化知識、文本、圖像等模態數據特征,并引入注意力機制將多模態信息進行融合從而實現多模態知識圖譜問答。
6 結語
隨著智能時代的到來,能夠理解和回答自然語言問題的智能問答系統得到了廣泛應用。作為智能問答系統主要方法的知識圖譜問答成為國內外學者的主要研究方向,且取得了突出進展。本文對現有知識圖譜問答研究進展進行追蹤,介紹了3 種主要的知識圖譜問答方法和兩類知識圖譜問答數據集,并針對知識圖譜問答面臨的主要挑戰和未來研究方向進行了討論,期望可以為未來KGQA 研究者提供幫助,以開拓不同領域知識圖譜問答的應用場景。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
大連民族大學學報(2015年2期)2015-02-27 08:28:11
