融合LDA和GloVe模型的病癥文本聚類算法
2022-04-06 10:43:10趙玉鳳
河北工程大學學報(自然科學版) 2022年1期
吳 迪,趙玉鳳
(河北工程大學 信息與電氣工程學院,河北 邯鄲 056038)
隨著醫療信息平臺日益普及,醫療數據日益豐富,整個社會對醫療信息的需求巨大[1]。本文采用主題模型技術,對病癥文本數據進行深入分析,有助于患者根據自身病癥了解所患疾病,輔助醫生進行臨床決策[2],提高醫院醫療服務質量,為總結各類病癥發展趨勢以及自主診斷發展等有著巨大的價值。主題模型是一種識別文本集潛在主題信息的概率生成模型[3]。與潛在語義分析(Latent Semantic Analysis, LSA)、概率隱性語義分析(Probabilistic Latent Semantic Analysis, PLSA)相比較,隱含狄利克雷分布(Latent Dirichlet Allocation, LDA)主題模型化解了隨著文本數量直線增加而產生的的過度擬合問題,實現了概率化[4]。閆俊伢等[5]利用LDA模型表示文本,將其輸入到K-means中進行聚類分析。Kim等[6]提出了利用LDA模型提取關鍵詞,并計算詞頻-逆文檔頻度(Term Frequency-Inverse Document Frequency, TF-IDF)值,將其應用到K-means聚類算法獲取主題相似的文本內容。王少鵬等[7]提出了一種基于LDA模型的文本聚類算法,該算法將TF-IDF和LDA建模后進行相似度融合,從而實現文本聚類。由于TF-IDF所構建的矩陣具有較高的稀疏性[8],2013年Google發布了Word2Vec詞向量訓練工具,其不僅具有降維效果還能夠表示詞的語義信息[9-10]。Chen等[11]提出了將文本用LDA進行表示后,利用Word2Vec計算主題之間的語義關聯,以提高關鍵詞準確性。Kim等[12]提出了一種基于Word2Vec的建模方法,該方法基于Word2Vec和K-means聚類能夠提高捕捉和表示語料庫文本的能力。鄭恒毅等[13]利用LDA主題模型提取特征詞隱含主題,Word2Vec獲取特征詞向量,將兩者融合以實現文本聚類。Word2Vec提出不久,Pennington J等在2014年提出了全局文本表示(Global Vectors for Word Representation, GloVe)模型,其充分考慮了語料中的統計信息,使其能夠攜帶更多的語義信息。王欣研等[14]提出了將LDA和GloVe模型進行主題語義關聯,通過LDA識別主題并基于GloVe相似性獲取主題語義關聯。李少華等[15]提出了GV-LDA模型,該模型在LDA建模前,利用GloVe提取詞向量,將相似性較高的詞替換以降低稀疏性。
綜上所述,傳統聚類方法特征提取時,在局部上下文窗口訓練模型,忽略了文本集中的部分統計信息。因此,本文提出一種融合LDA和GloVe模型的病癥文本聚類算法。LDA建模后利用JS距離計算相似度,以提取基于主題表示的文本相似度;GloVe建模后利用余弦距離計算相似度,以提取基于詞向量表示的文本相似度;將兩者結合后進行K-Medoide聚類,以提高病癥文本聚類精度。
1 問題定義
詞性是以語法特征作為主要依據同時兼顧詞語意義的劃分結果。對于病癥文本數據而言,名詞與其它詞的重要性不同,名詞一般為概括性詞語,具有代表性,因此,詞性可作為病癥文本特征詞提取時重要的衡量指標之一。為了提高醫療名詞這類蘊含主要特征的單詞對病癥文本相似度影響,在GloVe詞向量建模時應把詞的詞性因素考慮進去,提出詞性貢獻權重。利用GloVe建模后得到病癥詞向量,并根據相應詞性,對詞向量權重進行標注,進而計算病癥文本向量。
(1)
式中,i的取值范圍為i=1,2,μ1表示名詞貢獻度,μ2表示其它詞貢獻度。設定μ1=1,μ2=0.5。
對病癥文本數據進行聚類時,利用相似度計算出病癥文本與各個聚簇中心之間的距離,進而判斷該病癥文本所屬簇,因此距離計算對聚類效果尤為重要,故本文提出相似度結合距離。根據LDA和融合詞性的GloVe分別對病癥文本建模后,利用JS和余弦距離計算得到文本相似度,并將其進行結合。
定義2 (相似度結合)假設F={f1,f2,…,fn}表示病癥文本數據集{f1,f2,…,fn},fi表示第i個病癥文本,cK表示聚簇中心,λ表示線性結合系數,則文本fi與cK的相似度Dt(fi,cK)公式如下:
Dt(fi,cK)=λ·DtLDA(fi,cK)+(1-λ)·DtGloVe(fi,cK)
(2)
其中,λ取值范圍為0<λ<1,i的取值范圍為i=1,2,…,n。
2 融合LDA和GloVe模型的病癥文本聚類算法
針對LDA主題建模時忽略語義信息以及病癥文本詞性貢獻度不同的問題,本文提出了一種融合LDA和GloVe模型的病癥文本聚類算法。首先,收集病癥文本數據,構建醫療專業詞匯分詞詞典,并對病癥文本數據進行預處理;其次,利用LDA主題模型對預處理后的病癥文本集建模,得到基于主題的文本表示,采用JS距離計算文本相似度;再次,利用GloVe全局向量模型對預處理后的病癥文本集建模,根據病癥詞性貢獻度賦予詞向量權重,得到基于詞向量的文本表示,采用余弦距離計算文本相似度;最后,將兩種相似度結合應用到K-Medoide聚類中,進而得到病癥文本數據的聚類結果。具體框架如圖1所示。
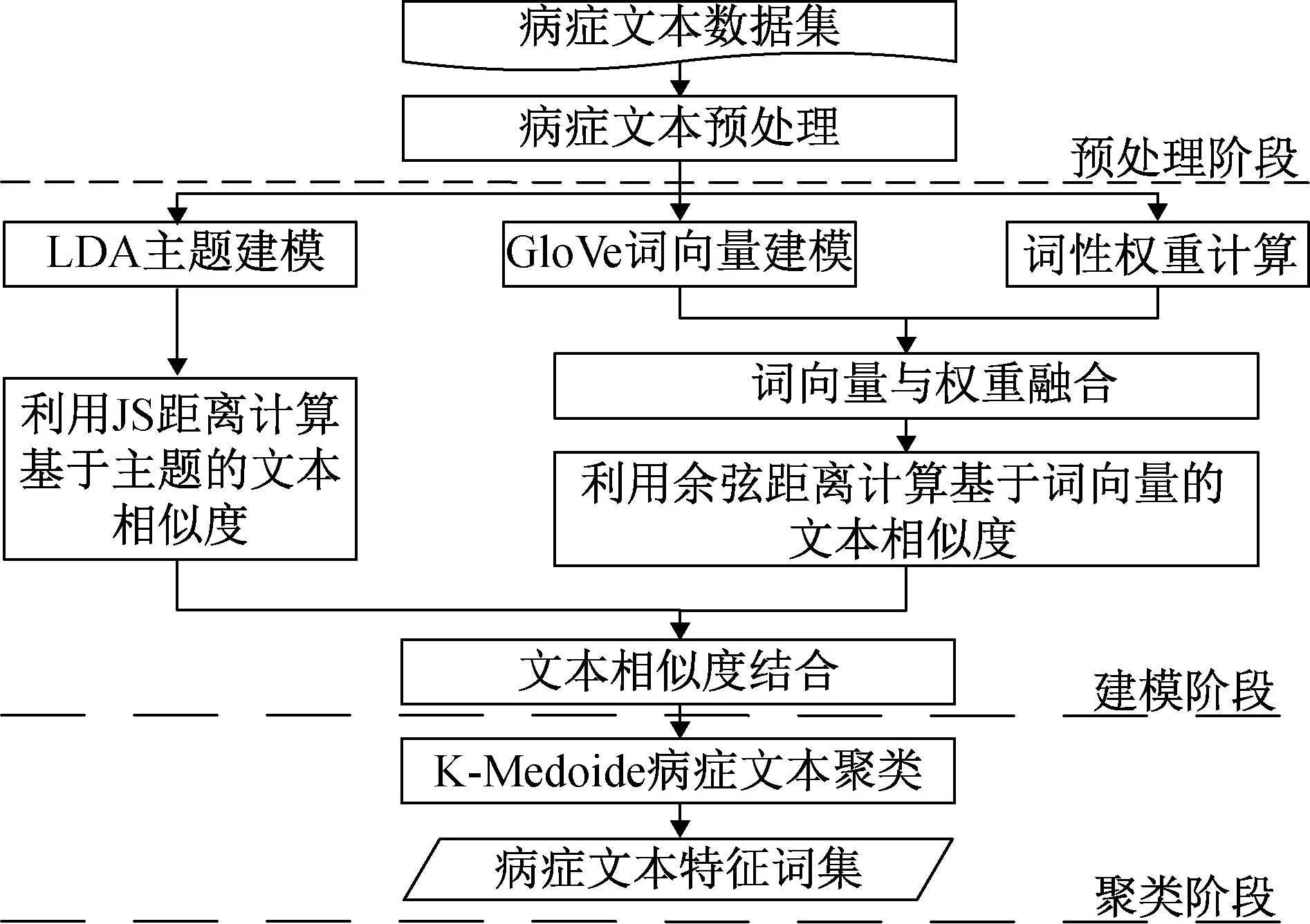
圖1 融合LDA和GloVe模型的病癥文本聚類算法框架圖Fig.1 Framework diagram of disease text clustering algorithm based on LDA and GloVe model
2.1 病癥文本數據預處理
病癥文本數據集預處理主要包括篩選、中文分詞、詞性標注、去停用詞四個部分。針對病癥文本數據包含諸多醫學專有詞匯的問題,構建醫療專業詞匯分詞詞典對病癥數據進行分詞,以提高病癥分析結果的準確度。具體流程如圖2所示。

圖2 病癥文本數據集預處理流程圖Fig.2 Flowchart for preprocessing of disease text data set
2.2 LDA&GloVe建模
對病癥文本數據建模時分為基于LDA主題建模和基于GloVe詞向量建模的文本相似性度量兩種部分。
(1) 利用困惑度選擇最優主題數目,對病癥文本數據集進行LDA主題建模,使用JS距離計算基于主題表示的文本相似度。
(2) 對病癥文本數據集進行GloVe詞向量建模,根據病癥詞性貢獻度不同,對詞向量權重進行標注,使用余弦距離計算基于詞向量表示的文本相似度。
2.2.1 LDA文本相似性度量
本文利用Gibbs采樣算法求解主題分布和詞分布。LDA為無監督模型,建模前需先確定α、β、K三個超參數,α、β選取默認值,主題數的選取直接影響LDA模型對病癥文本數據的釋義情況,本文利用困惑度確定K的最優值,困惑度最小時表示建模結果最理想。病癥文本F的困惑度公式perplexity(F)如下:
(3)
式中,M表示病癥文本語料庫大小,Nf表示文本f中的詞數量,Wf表示文本f中的詞,p(Wf)表示詞Wf產生的概率。
LDA主題建模完成后,對于每一篇病癥文本,在其文本-主題分布p(t|f)的最大概率主題下選取主題-詞分布p(w|t)概率中前6個詞作為該文本的特征詞,這樣即可以最大化保留文本語義又能夠降低算法復雜度。基于LDA主題模型的文本向量可用文本-主題概率分布表示,文本fi_LDA計算公式如下:
fi_LDA={p(t1|fi),p(t2|fi),…,p(tK|fi)}
(4)
兩篇病癥文本間可通過計算這兩個文本-主題分布之間的相似性來實現。本文使用JS距離計算基于LDA主題建模的相似度,文本fi_LDA和fj_LDA的相似度Dtjs(fi_LDA,fj_LDA)計算公式如下:
(5)
基于LDA建模和JS距離(LDA-JS)的相似性如算法1所示。

算法1:基于LDA-JS的相似性算法輸入:病癥文本數據集F={f1,f2,…,fM},超參數α和β輸出:基于LDA的文本相似度DtLDA(fi,fj)步驟1: 根據公式(4)確定主題數K;步驟2: for fm∈F do步驟3:從α分布取樣生成fm的主題分布θm步驟4:從θm中取樣生成第n個詞的主題tm,n步驟5:從β分布取樣生成主題對應的詞分布ηtm,n步驟6: end for步驟7:統計主題和特征詞的共現頻率,得到主題分布和主題-詞分布步驟8:根據公式(5)為每條病癥文本選取特征詞并對其進行向量化表示步驟9:根據公式(6)計算基于LDA的文本相似度并輸出
2.2.2 GloVe文本相似性度量
GloVe病癥詞向量的訓練過程如下:首先,掃描整個病癥文本數據集,根據上下文窗口的大小,統計目標詞與上下文詞在整個病癥文本數據集中共同出現的次數,構造詞共現矩陣。然后,以矩陣作為輸入,使用最小二乘法作為損失函數,通過訓練使損失函數值最小時得到最終的詞向量。
GloVe模型作者Pennington進行對比實驗得出詞向量維度和上下文窗口大小的經驗值分別為300和8。
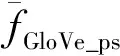
(6)
利用余弦距離計算基于GloVe詞向量建模的文本相似度,文本fi_GloVe_ps和fj_GloVe_ps的相似度DtGloVe_ps(fi_GloVe_ps,fj_GloVe_ps)計算公式如下:
(7)
基于GloVe建模和COS距離(GloVe-COS)的相似性如算法2所示。

算法2:基于GloVe-COS的文本相似性算法輸入:病癥文本數據集F={f1,f2,…,fM},詞向量維度vector_size,上下文窗口大小window_size輸出:基于GloVe的文本相似度DtGloVe_ps(fi,fj)步驟1:構造病癥文本數據集的詞共現矩陣步驟2:根據詞共現矩陣和GloVe建模獲得病癥詞向量集W={w1,w2,…,wn}步驟3:for i=1 to n do步驟4:根據詞性標注判斷w是名詞還是其它詞步驟5:根據公式(1)對詞向量權重進行標注步驟6:end for步驟7:根據公式(8)計算基于GloVe的文本相似度并輸出
2.3 融合LDA和GloVe模型的相似度結合文本聚類
K-Medoide算法思想為:在數據集中隨機選取K個對象作為初始簇,計算其余對象與各個代表對象的距離劃分到其所代表的簇;然后反復利用非代表對象替換代表對象,試圖找到最優的簇中心;利用代價函數表示聚類質量;當某個代表對象被替換時,除了未被替換的代表對象,其余對象被重新分配。
融合相似度的距離采用平方誤差準則E,公式如下:
[λ·DtLDA(fi,cK)+(1-λ)·DtGloVe_ps(fi,cK)]2
(8)
融合LDA和GloVe模型的聚類算法(LG&K-Medoide)如算法3所示。

算法3:LG&K-Medoide算法輸入:病癥文本數據集F={f1,f2,…,fM},主題數目K,融合系數λ輸出:K個主題特征詞集步驟1:從病癥文本數據集F={f1,f2,…,fM}中隨機選取K個代表文本為初始簇的中心步驟2:利用公式(2)計算相似度融合距離步驟3:repeat步驟4:計算其余文本fi到K個代表文本cK的距離Dt(fi,cK),并將其劃分到最近的簇步驟5:隨機選擇一個其余文本,步驟6:計算用其余文本替換代表文本的總代價S(S為絕對誤差值的差)步驟7:if S<0,then 替換代表文本,形成K個新簇步驟8:until 不再改變步驟9:輸出K個主題特征詞集
K-Medoide算法選擇某個到所有點距離之和最小的點作為簇中心,以此能夠減輕孤立點對聚類的影響F1,從而提高聚類效果。
3 實驗與結果分析
為了驗證本文所提出的融合LDA和GloVe模型的病癥文本聚類算法具有的優勢,將其與基于LDA、LDA+TF-IDF、LDA+Word2Vec模型同在K-Medoide聚類算法中進行比較,在精確率、召回率和F1值方面進行測試。
3.1 融合LDA和GloVe模型的相似度結合文本聚類
本實驗在Windows 7操作系統下進行,CPU為 Intel Core I5-4210 M@2.60 GHz,內存 4 GB,編譯語言為 Python 3,數據采集軟件為八爪魚 V7.6.4。
本文采用好醫生筆記、39健康、好大夫等咨詢平臺中患者的病癥描述提問作為數據集,經過文本預處理,保留了13 125條病癥文本。實驗數據基本信息如表1所示。

表1 實驗數據基本信息
3.2 聚類評價指標
本實驗衡量聚類結果時采用的評價指標包括精確率(Precision,Pre)、召回率(Recall,Rec)和F1值(F1-Measure)。計算公式如下:
(9)
(10)
(11)
其中,Ni表示病癥文本數據集中類別i的文本數量,Nj表示病癥文本聚類完成后類別j的文本數量,Ni,j表示病癥文本聚類結果中類別j正確劃分到類別i的文本數量。
3.3 困惑度測試
根據2.2.1所述,本文利用困惑度確定主題數K值。實驗重復進行10次,不同K值對應的困惑度取10次實驗結果的平均值,實驗結果如圖3所示。
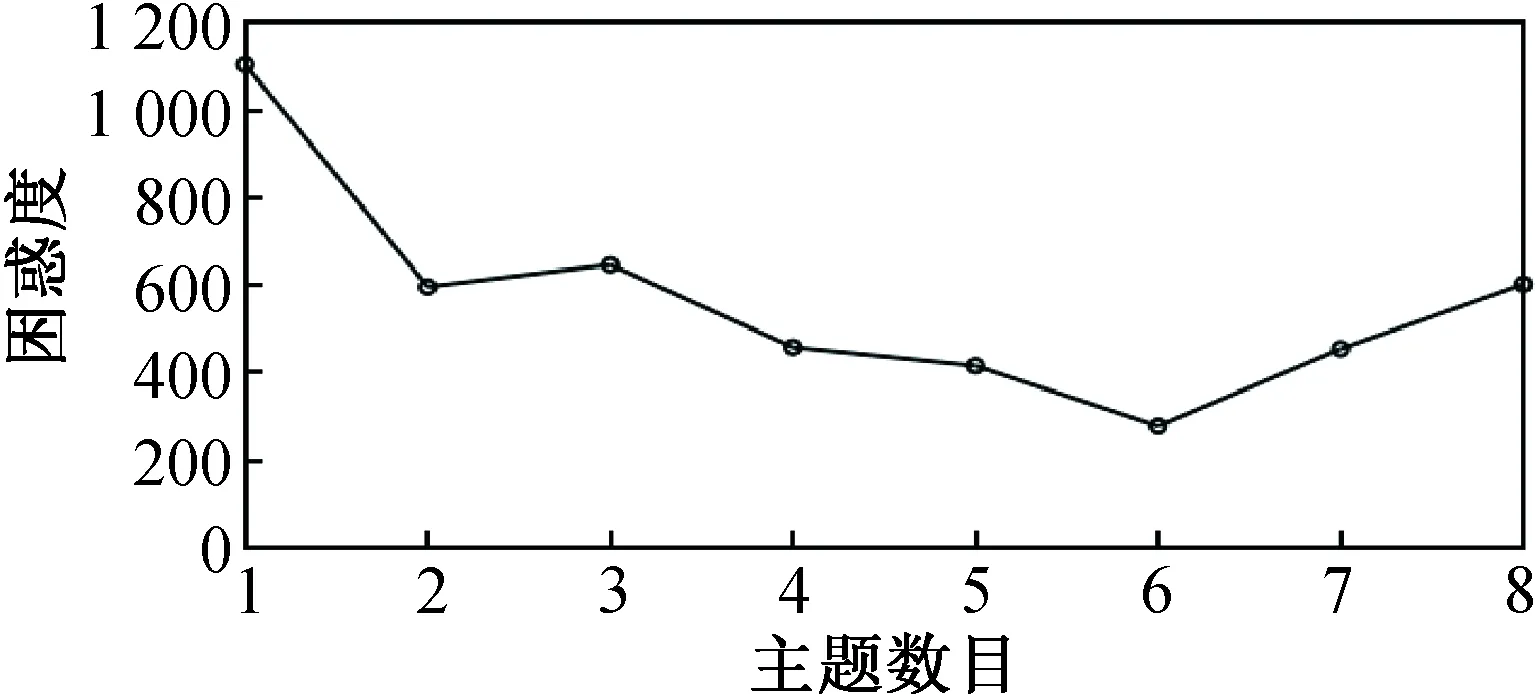
圖3 LDA模型在不同主題數目下的困惑度值Fig.3 Perplexity value of LDA model under different number of topics
由圖3的實驗結果可知,當主題取值K=6時,困惑度最小,表明此時LDA建模效果最好,故最優主題數K=6。
3.4 融合系數λ值測試
融合系數λ的取值能夠根據K-Medoide聚類結果的F1值確定。融合系數取值測試時,分別取λ=0.1,0.2,…,0.9,將本實驗的算法重復運行10次,不同取值時所對應聚類結果的F1值取10次實驗結果的平均值,實驗結果如圖4所示。
由圖4可以看出,隨著λ取值的變化,F1值不斷提高,當λ=0.6時,F1達到最高值。由此可得,λ取值為0.6時,病癥文本數據的聚類效果最佳。
3.5 準確率測試
確定主題數K=6時,將LG&K-Medoide算法與LDA、LDA+TF-IDF、LDA+Word2Vec模型進行準確率對比,結果如圖5所示。
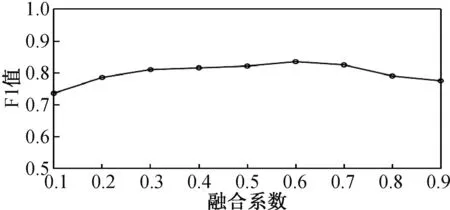
圖4 λ在不同取值時所對應的F1值Fig.4 λ corresponds to the F1 value at different values

圖5 準確率對比結果Fig.5 Accuracy comparison results
由圖5可知,本文提出的算法在準確率上優于其它模型,較基于LDA+Word2Vec模型的聚類算法相比提高了3%,達到了85%的準確率。由此可見,融合LDA和GloVe模型的病癥文本聚類算法在最終結果的準確率上得到了進一步地提升。
3.6 F1值測試
為證明本算法在病癥文本聚類方面的優勢,實驗計算了不同主題下的精確率、召回率以及最終聚類結果的F1值,分別與LDA、LDA+TF-IDF、LDA+Word2Vec模型進行對比。
6個主題所對應的精確率(Precision)比較如圖6所示。
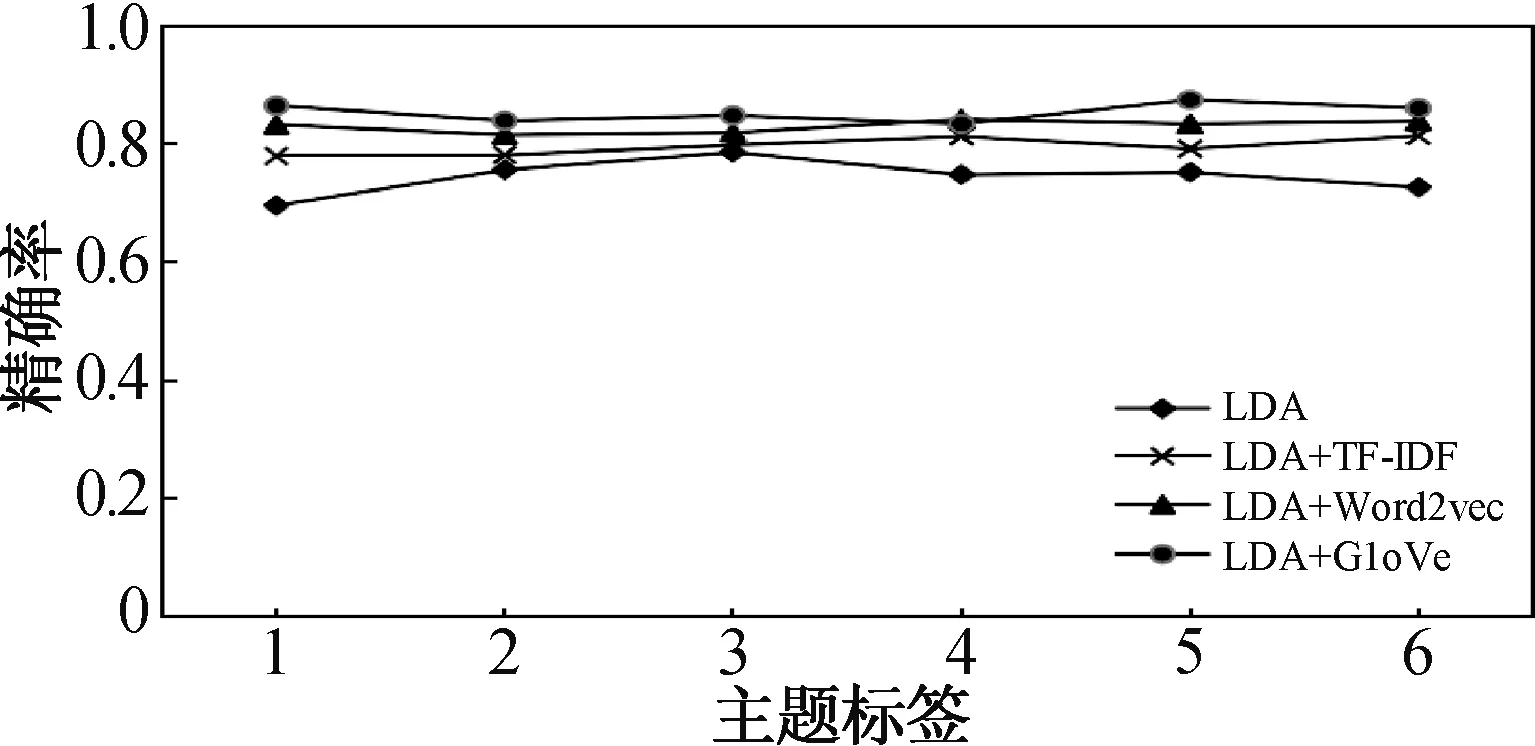
圖6 不同主題下精確率對比結果Fig.6 Comparison results of accuracy rates under different topics
6個主題所對應的召回率(Recall)比較如圖7所示。
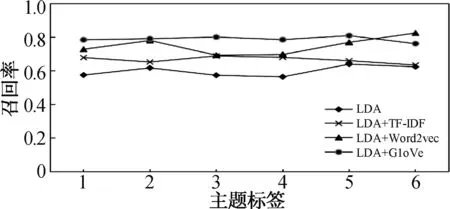
圖7 不同主題下召回率對比結果Fig.7 Comparison results of recall rates under different topics
從圖6、圖7中可以看出,分別在6個主題聚類結果下,LG&K-Medoide算法所對應的精確率和召回率均高于LDA、LDA+TF-IDF、LDA+Word2Vec模型算法。在實驗中,其它三種算法在不同主題下的精確率和召回率波動較大,而LG&K-Medoide算法處于較平穩的狀態,主要是因為數據集為病癥文本,不僅可細分為“呼吸科”、“消化科”、“神經科”、“骨科”、“皮膚科”和“其它”6個主題,還可粗分為“內科”和“外科”2個主題,所以建模時若未考慮全局語義信息,則在聚類時會出現錯誤。
為了更直接、準確地比較這四種算法在病癥文本上的聚類精度,對最終聚類結果的精確率、召回率和F1值進行計算,實驗結果如圖8所示。
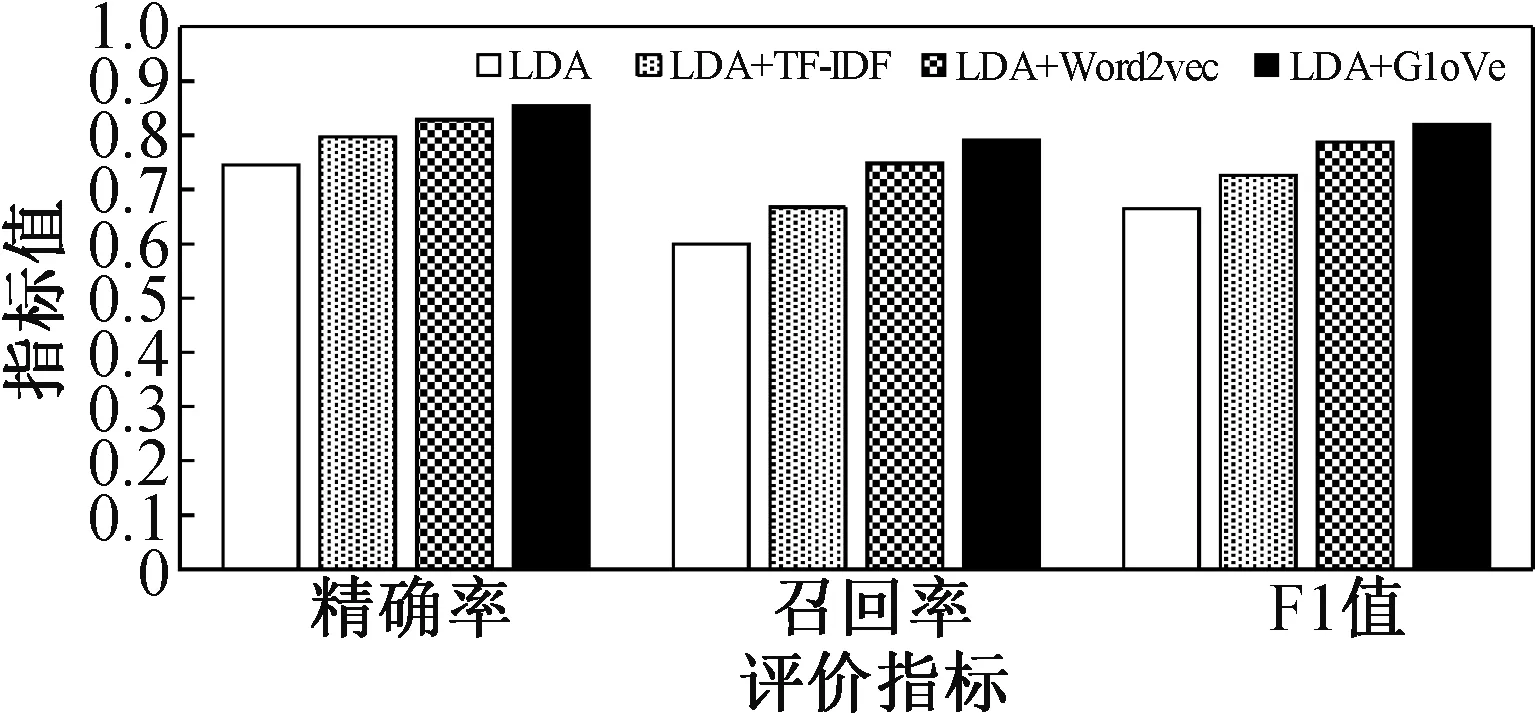
圖8 精確率、召回率、F1值對比結果Fig.8 Accuracy rate, recall rate, F1 value comparison results
從圖8可看出,四種聚類算法的結果在準確率、召回率和F1值上依次逐漸升高,本文所提出的融合LDA和GloVe模型的聚類算法在三個指標上都處于最優,這是因為該算法在LDA模型提取主題分布和詞分布的基礎上,融合了GloVe模型考慮全局語義信息的特點,并且利用了文本集中的統計信息,從而提高病癥文本的聚類精度。
最終,根據困惑度和融合系數測試結果,設置聚類算法參數K=6,λ=0.6。各個主題的特征詞集結果如表2所示。

表2 病癥主題特征詞集
由上表可知,本文提出的聚類算法所得到的實驗結果有“呼吸科”、“消化科”、“神經科”、“骨科”、“皮膚科”和“其它”這6類主題,與所標注的標簽類型一致,且提取的特征詞集大都具有代表性,屬名詞性病癥詞匯,說明本文提出的基于詞性貢獻權重的詞向量對詞語的區分度有一定的提高,使相似度計算更加準確。
4 結論
本文考慮醫療名詞蘊含的主要特征,設置了不同詞性的貢獻權重,突出病癥名詞的代表性;相似度計算時,結合LDA和GloVe相似度改進距離函數,提高了K-Medoide聚類準確率。實驗結果表明,本文提出的LG&K-Medoide算法在病癥文本數據集上具有更高的聚類精度,且相較與LDA+Word2Vec模型在F1值上提升了3%,準確率上提升了2%。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學與工程(2015年4期)2015-09-26 11:59:03
