基于兩階段分類算法的中國交通標志牌識別*
2022-04-07 03:31:56馮潤澤于偉光楊殿閣
汽車工程 2022年3期
馮潤澤,江 昆,于偉光,楊殿閣
(清華大學,汽車安全與節能國家重點實驗室,北京 100084)
前言
自動駕駛技術被廣泛地認為是一種減少交通事故、提高交通效率和舒適性的極具發展前景的技術。自動駕駛技術得以實現的基礎是車輛可以自主地獲取到交通環境中語義信息,而交通標志中包含了豐富的語義信息,其提供的警示、指示和禁止信息可以輔助緩解交通擁堵,降低交通事故發生率。此外,交通標志牌識別算法也是高級駕駛員輔助系統(ADAS)的重要子系統之一。正因為交通標志牌識別算法如此重要,最早的交通標志牌識別算法可以追溯到1987年,文獻[3]中嘗試構建一套交通標志牌識別系統。
交通標志牌識別可以分為交通標志牌的檢測與分類兩個步驟。傳統交通標志牌識別算法依賴于人工設計的特征,一些算法將圖片映射到RGB、HSV、YCbCr和LUV色彩空間利用交通標志牌的顏色特征對其進行檢測,但這些算法易受到光照、天氣和標志牌的表面反射率等因素影響,所以還有一些改進算法利用霍夫變換、距離變換、遺傳算法或者快速徑向對稱算法等利用交通標志牌的形狀特征對其進行檢測。交通標志牌識別系統檢測到圖像中的交通標志牌后對交通標志牌實例進行分類進而得到交通標志牌蘊含的語義信息。傳統的交通標志牌分類算法包括模板匹配算法和支持向量機算法等。通過近20年的研究,人工設計特征對交通標志牌的識別算法的性能在2010年左右達到了瓶頸。
在2012年,隨著AlexNet被提出,基于卷積神經網絡的方法被用于交通標志牌識別。之后由于并行計算硬件高速發展,許多基于卷積神經網絡的目標識別算法被應用在交通標志牌識別領域。根據算法是否提前生成候選區域可將算法分為單階段識別算法,如SSD和YOLO系列算法以及兩階段識別算法如RCNN、Fast-RCNN和Faster-RCNN。由于單階段識別算法只需要進行一次特征提取便可實現交通標志牌的檢測與分類,所以其運行速度較兩階段算法快,但是精度較低。
對于自動駕駛系統或者高級駕駛輔助系統而言,越早地識別出交通標志牌的語義信息就能越早地將信息傳遞給決策系統或者駕駛員,所以這就要求交通標志牌識別算法能夠較好得識別出圖像中微小的交通標志牌。YOLO系列算法的實時性和泛化性能較好,并且對于細粒度實例的識別效果好,所以YOLO系列算法非常適用于交通標志牌的識別。但由于車載相機獲取得到的圖片往往較大,而為了提高識別速度,識別算法會縮小圖片后再輸入到識別網絡中。圖片中的交通標志牌往往占據很小的像素區域,而且道路中的交通標志牌種類繁多,包含的語義信息可分為幾十甚至上百種,各類別之間的特征差異不明顯,這都增加了交通標志牌分類任務的難度,而交通標志牌的信息隨著圖片的縮小而丟失,導致分類的精度得不到保證,即便是性能優異的YOLO系列算法也很難在交通標志牌識別中取得優異的精度。
在交通標志牌數據集方面,因為基于卷積神經網絡的識別算法需要利用大量的數據來訓練神經網絡,所以很多交通標志牌數據集相繼被提出(如表1所示)。在交通標志牌識別領域十分流行的GTSDB(German traffic sign detection benchmark)于2013年被公開,其中包含有900張圖片,這些圖片中的1 200個交通標志牌分別標注為“指示”、“禁止”和“警示”3類。2016年由清華和騰訊公司聯合制作的中國交通標志牌數據集TT100K(Tsinghua-Tencent 100K)包含有10 000張圖片,30 000個交通標志牌分為128類被標注,但是因為其中很多種類的交通標志牌樣本數量太少,所以在文獻[28]中只對樣本數目多于100個的45類交通標志牌進行了訓練。2017年,長沙理工大學公開了CCTSDB(changsha university of science and technology Chinese traffic sign detection benchmark)數據集,其中包含有15 723張圖片,其中包含有21 134個被分為“指示”、“禁止”和“警示”3類的交通指示牌。

表1 主流交通標志牌數據集
由于我國的交通標志牌不同于任何其他國家,所以基于GTSDB等國外數據集的交通標志牌識別算法在我國交通場景下不具備應用價值。對于自動駕駛系統或者高級駕駛輔助系統而言,不僅需要能夠識別出交通標志牌歸屬的大類(“指示”、“禁止”和“警示”),還需要識別出其具體的語義信息,因此CCTSDB數據集的分類方式并不滿足需求。而在TT100K數據集中將限速類、最低限速類和限高類交通標志牌枚舉出來(例如,“限高4.5 m”和“限高5 m”被分為兩類),訓練出的識別算法在實際應用中容易遺漏掉沒有被枚舉出來的其他限速類、最低限速類和限高類交通標志牌。
另外,由于TT100K中只標注了左轉、直行等動作指示類交通標志牌(如圖1(a)所示),而沒有標注車道指示類交通標志牌(如圖1(b)所示)。因此,在實際應用中會出現將車道指示類標志牌誤識別為動作指示類標志的情況。
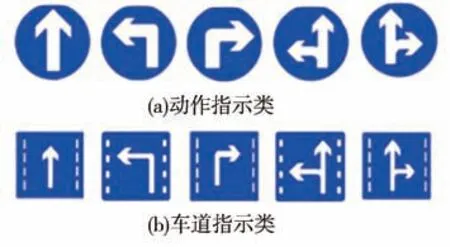
圖1 標志牌
為解決目前國內交通標志牌數據集標注分類不清的問題,本文重新制作了中國交通標志牌數據集并且為了提升交通標志牌識別精度,提出了基于兩階段分類算法的交通標志牌識別算法框架(如圖2所示)。本文提出的算法首先對YOLO系列單階段目標識別算法進行改進作為檢測模塊,用于檢測圖像中的前景區域,然后從原始圖片中截取出前景區域作為大類分類網絡的輸入將前景分為“禁止”、“指示”和“警告”這3大類,然后再將前景輸入到對應的子類劃分網絡對前景進行子類劃分。
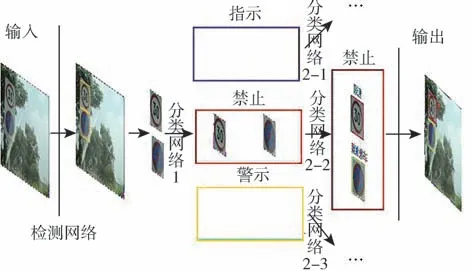
圖2 算法架構
1 改進YOLO系列算法
YOLO系列算法是當前性能最好的目標檢測算法之一,該算法具備單階段算法的高實時性特征,其在Microsoft COCO數據集和Pascal VOC數據集上的效果都驗證了這一點。本文中作為基線算法的YOLO系列算法首先將圖片縮小到608×608像素大小,然后輸入YOLO系列算法的骨干網絡(YOLOv3算法的骨干網絡為Darknet-53,YOLOv4和YOLOX算法的骨干網絡為CSPDarknet-53)中,得到3個尺寸分別為76×76、38×38和19×19的特征圖。
YOLOv3和YOLOv4算法會在最小的19×19特征圖(有最大的感受野)上對每個網格生成3種尺寸不同的先驗框(YOLOv3先驗框尺寸為116×90,156×198和373×326像素,YOLOv4先驗框尺寸為142×110,192×243和459×401像素),適合檢測較大的對象。在中等的38×38特征圖(擁有中等感受野)上對每個網格同樣生成3種尺寸的先驗框(YOLOv3先驗框尺寸為30×61,62×45和59×119像素,YOLOv4先驗框尺寸為36×75,76×55和72×146像素),適合檢測中等大小的對象。在最大的76×76特征圖(擁有最小的感受野)上還是對每個網格生成3種尺寸的先驗框(YOLOv3先驗框為10×13,16×30和33×23像素,YOLOv4先驗框尺寸為12×16,19×36和40×28像素),適合檢測較小的對象。YOLOv3和YOLOv4算法會生成預測框相較先驗框的位置變化以及長寬放縮尺度,而YOLOX算法并不生成先驗框,直接生成特征圖網格對應的數個預測框左上角的坐標以及預測框長寬。
由于大特征圖的網格(對應小感受野,適合檢測小目標)數目最多,生成的先驗框最多,所以YOLO系列算法有很強的小目標的識別能力,非常適于交通標志牌的識別任務。
YOLO系列算法的最終輸出為預測框的位置、預測框內為前景的置信度以及前景的分類概率。YOLO系列算法的損失函數包含3個部分,分別是預測框的回歸誤差、置信度的誤差和類別概率的誤差。YOLO系列算法的損失函數中的置信度誤差往往使用均方差函數計算,類別概率的誤差往往使用交叉熵損失函數計算,而計算預測框的誤差則各有不同,YOLOv3算法使用均方差函數計算預測框回歸誤差,YOLOv4算法使用CIoU誤差來表示預測框誤差,YOLOX算法使用IoU誤差表示預測框誤差。
為了使用YOLO系列算法專門檢測交通標志牌前景而不進行分類,本文去掉了原損失函數關于類別概率的誤差,修改后的損失如下式所示:



圖3 CIoU參數圖示[30]
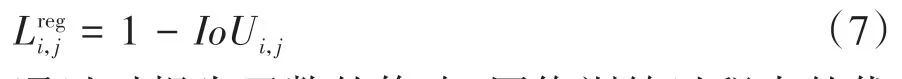
通過對損失函數的修改,網絡訓練過程中的優化目標變為提升預測框位置尺寸的準確度以及提升置信度的預測準確度。一方面,檢測階段更準確地對前景進行提取,有助于提升兩個分類階段對前景的分類準確度;另一方面,檢測階段更準確地對預測框置信度進行估計,有助于降低識別算法漏檢率。
2 設計兩階段分類模塊
為了提高檢測算法的速度,當前主流算法都是將圖片進行縮小后輸入到識別網絡中,以此來減少算法的計算量。但是在交通場景下,交通標志牌在圖像中的占比往往較小,而交通標志牌各類別之間的特征差異不大,這就使得交通標志牌的分類任務難度較大,如再縮小圖像,也即舍棄部分像素信息,勢必會以降低檢測精度為代價。因此為了提高對交通標志牌識別的準確率,算法從檢測模塊中獲取前景,然后從原始圖像中截取前景輸入到分類模塊中,這樣便充分利用了圖像中的像素信息。

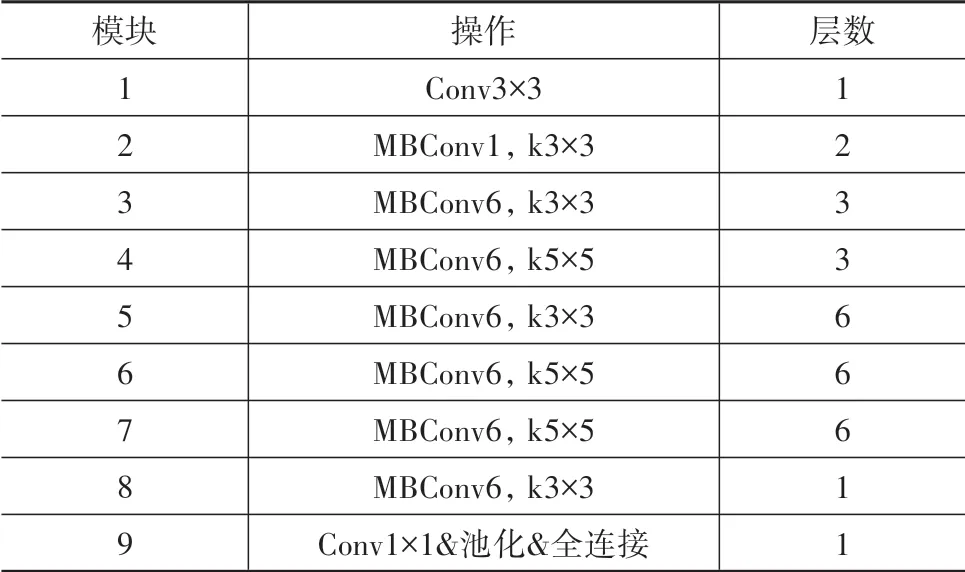
表2 EfficientNet-B3網絡結構
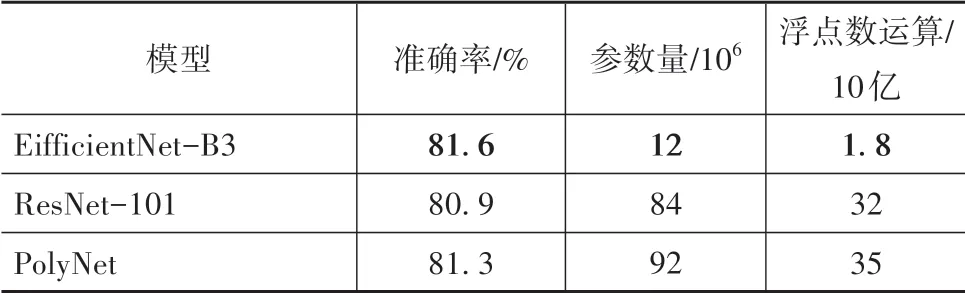
表3 EifficientNet-B3與其他模型比較
EfficientNet-B3的網絡輸入是分辨率為300×300的RGB三色彩通道圖像,首先經過一個大小為3×3的卷積層被處理為移動反轉瓶頸卷積層(MBConv)需要的輸入維度;然后經過27個卷積核為3×3或5×5的MBConv提取出特征圖。之后,網絡借鑒全卷積網絡(FCN)的思路,將特征圖輸入到一個卷積核為1×1的卷積層中,這可以將任意尺寸的特征圖轉換到特定的通道數;最后通過1個池化層和1個全連接層得到輸入圖像屬于各個種類的概率。訓練過程中通過計算網絡預測結果與真實類別的交叉熵損失函數作為損失函數,利用Adam算法優化網絡參數。
因為本文提出的兩階段分類算法采用EfficientNet-B3,在保證分類準確率的情況下,運算量和參數量都達到最少,也即在相同硬件條件下,分類速度最快,所以識別算法可以利用最少的時間消耗來對識別準確率進行提升。
3 數據集標注
為解決上述數據集的問題,本文從CCTSDB和TT100K這兩個中國交通標志牌數據集中抽取部分質量較好的圖片并重新標注,標注種類如圖4所示,圖片中的交通標志牌實例的標注為中心點坐標,寬高所占像素x,y,w,h,實例所屬大類C(“指示”、“禁止”和“警示”)和小類Sc(“禁止停車”、“最低速度”和“注意火車”等),所以每個實例可以用一個6維數組[x,y,w,h,C,Sc]表示。本文數據集包含18 955張如圖5所示的圖片以及其中的41 028個交通標志牌實例,數據集中包含實例數多于100的種類數目為53個(表4)。其中,“禁止”大類下有“禁止停車”等48個子類,“指示”大類下有“最低速度”等39個子類,“警示”大類下有“注意火車”等47個子類。

圖4 交通標志牌種類

圖5 數據集示例

表4 數據集比較
本文所構建的數據集中禁止類實例占比58%,指示類占比32%,警示類占比10%。另外,由于一些子類樣本數較少(少于100),無法用于神經網絡訓練,故將這些子類歸入“其他”子類,處理后數據集中樣本數多于100的子類數為53個。
本文從自動駕駛技術和高級駕駛輔助技術的需求出發,重構了中國交通標志牌的類別范圍,構建得到的數據集較已有數據集包含的圖片數目、交通標志牌示例數目和可訓練類別(樣本多于100)數目更多。
4 實驗驗證
首先本文將數據集中的圖片按照4∶1的比例劃分為訓練集和測試集,訓練集用于訓練網絡,測試集用于測試最終性能。其次,截取訓練集中的交通標志牌,將交通標志牌實例劃分為“禁止類”、“指示類”和“警告類”3大類用于訓練大類分類網絡,然后再將各大類交通標志牌實例劃分子類,用于訓練3個子類分類網絡。
本文對參數進行如下設置λ=5,λ=λ=1,并利用一臺配備有主頻為2.3 GHz的Intel(R)Xeon(R)Gold 5118 CPU和3個顯存為12 GB的Titan V GPU的服務器對YOLOv3、YOLOv4和YOLOX算法進行訓練作為基線算法,并分別對YOLOv3、YOLOv4和YOLOX算法進行改進作為檢測模塊,結合分類模塊組成two-stage-YOLOv3算法、two-stage-YOLOv4算法和two-stage-YOLOX算法,最后本文訓練了傳統兩階段識別算法Faster-RCNN與本文提出的兩階段識別算法進行比較。
表5為本文算法和基準算法和Faster-RCNN的性能比較結果,其中mAP@0.5是Pascal VOC挑戰賽所采用的評價指標,是IoU閾值設為0.5時各類別平均準確率(average precision)的均值,通過比較基準算法與本文算法可以發現,YOLO系列算法改進為twostage-YOLO系列算法后mAP平均提高了8.52%。
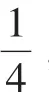
本文還比較了算法在工程實際中的性能。將置信度域值設為0.5,并根據Pascal VOC挑戰賽中將與真實框之間的交并比大于等于0.5的預測框視為預測正確。將預測框與真實框之間的交并比大于等于0.5且預測種類與真實種類一致時視為算法識別準確,其余視為預測錯誤來計算算法對每種交通標志牌的召回率、準確率和誤檢(檢測出前景但分類錯誤)率,得到的算法性能比較如表5所示。由表可見,YOLO系列算法的誤檢率都在11%以上,這說明YOLO系列算法在檢測出交通標志牌后很容易將其劃分到錯誤的類別中,而two-stage-YOLO的誤檢率都在7%以下,平均誤檢率降低了7.42%,這說明本文提出的算法在檢測出交通標志牌前景后的分類準確率大大提升,這也使得在工程應用中,本文提出的two-stage-YOLO系列算法召回率較YOLO系列算法平均提高12.18%,準確率提高2.70%。在Titan V顯卡上測試,two-stage-YOLO系列算法的幀率在14幀/s左右,而YOLO系列算法的幀率都在20幀/s以上,本文提出的算法為了提高檢測精度確實犧牲了檢測速度,但是文本算法的檢測速度要略優于同樣是兩階段算法的Faster-RCNN。
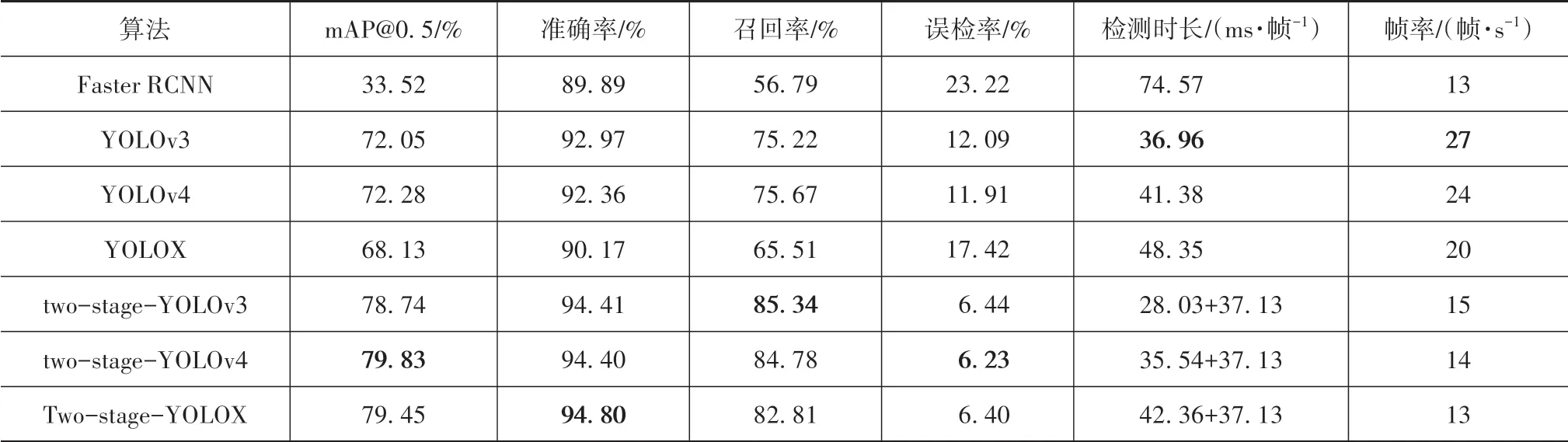
表5 本文算法與基線算法以及Faster-RCNN的性能比較
圖6中列舉two-stage-YOLOv3算法在測試集上的檢測效果,可以看出本文提出的交通標志牌識別算法框架可以區分圖4中的車道類標志牌和動作指示類標志牌。Faster-RCNN、YOLOv3以及twostage-YOLOv3的檢測結果對比如圖7所示,圖片中的交通標志牌占比較小,Faster-RCNN沒能檢測出圖片中的交通標志牌,而YOLOv3算法檢測到了交通標志牌,但是將真實的前景的置信度檢測為較低的0.42并且將“禁止鳴笛”標志牌錯誤地分類為“其他禁止類”,two-stage-YOLOv3算法成功地識別出了交通標志牌并且將正確的前景的置信度較好地檢測為0.97(對于正確的預測框,置信度越趨近于1.00越合理)且分類正確。


圖7 檢測結果對比
5 結論
本文基于中國交通場景特點以及自動駕駛系統和高級駕駛輔助系統對交通標志牌識別的高準確率需求,提出了一種基于兩階段分類算法的交通標志牌識別算法。檢測模塊使用善于小目標檢測的YOLO系列算法對標志牌進行檢測,分類第1階段將檢測到的標志牌實例進行大類分類,分類第2階段對各大類下的標志牌進行小類劃分。并針對當前數據集在實際應用中存在的問題,制作了一組包含種類更多、圖片數和實例數更多的中國交通標志牌數據集。本文提出的算法通過細化分類任務,獨立提升各算法模塊的性能,進而提高整體算法的識別精度。本文提出的two-stage-YOLO系列算法較Faster-RCNN的mAP提升40%以上,較基準YOLO系列算法的mAP提升了8.52%,平均誤檢率降低了7.42%。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
