模態自適應的紅外與可見光圖像融合
2022-04-08 08:43:24曲海成王宇萍高健康趙思琪
紅外技術 2022年3期
曲海成,王宇萍,高健康,趙思琪
模態自適應的紅外與可見光圖像融合
曲海成,王宇萍,高健康,趙思琪
(遼寧工程技術大學 軟件學院,遼寧 葫蘆島 125105)
為解決低照度和煙霧等惡劣環境條件下融合圖像目標對比度低、噪聲較大的問題,提出一種模態自適應的紅外與可見光圖像融合方法(mode adaptive fusion, MAFusion)。首先,在生成器中將紅外圖像與可見光圖像輸入自適應加權模塊,通過雙流交互學習二者差異,得到兩種模態對圖像融合任務的不同貢獻比重;然后,根據各模態特征的當前特性自主獲得各模態特征的相應權重,進行加權融合得到融合特征;最后,為了提高模型的學習效率,補充融合圖像的多尺度特征,在圖像融合過程中加入殘差塊與跳躍殘差組合模塊,提升網絡性能。在TNO和KAIST數據集上進行融合質量測評,結果表明:主觀評價上,提出的方法視覺效果良好;客觀評價上,信息熵、互信息和基于噪聲的評價性能指標均優于對比方法。
圖像融合;模態自適應;對抗生成網絡;殘差網絡
0 引言
圖像融合屬于信息融合的一部分,其目的是針對同一場景,將來自不同傳感器的圖像聯合起來,生成一幅信息豐富的融合圖像,以便于后續處理。CT、磁共振成像、可見光圖像與紅外圖像屬于不同成像類型的源圖像,在這些源圖像組合中,本文重點研究紅外與可見光圖像融合,原因如下:第一,紅外圖像通過捕獲物體熱輻射信息成像,可見光圖像通過捕獲反射光成像,二者成像原理不同,因此可以從不同的角度提供互補信息。第二,紅外圖像和可見光圖像幾乎可以呈現所有物體的固有特性。可見光圖像分辨率高,色彩和紋理信息豐富,但容易受到惡劣天氣的影響;紅外圖像中熱輻射信息豐富,目標突出,不受天氣影響,但分辨率低,細節不清晰,利用二者的優勢進行圖像融合可以得到一幅信息豐富的圖像。此外,這些圖像可以通過相對簡單的設備獲得。因此,紅外與可見光圖像融合技術可以比其它融合方案應用范圍更廣,例如可以應用到目標識別[1]、目標檢測[2]、圖像增強[3]、監控[4]和遙感[5]等領域。
圖像融合包括像素級融合、特征級融合和決策級融合方法。像素級融合方法只對圖像信息作特征提取并直接使用,代表性的方法包括變換域的各向異性擴散融合(anisotropic diffusion fusion, ADF)[6]、交叉雙邊濾波(cross bilateral filter, CBF)[7]和最小加權二乘法(weighted least square, WLS)[8]和稀疏域的自適應稀疏表示(adaptive sparse representation, ASR)[9]、拉普拉斯金字塔(laplacian pyramid, LP)[10]等方法。在變換域方法中,比較熱門的是基于多尺度變換[11]的方法,但其忽略了融合過程中的空間一致性,容易在融合圖像中引入光暈。稀疏域的方法[12]需要構建一個過完備字典,需要多次迭代,非常耗時。近年來,針對特征級圖像融合,國內外學者提出了許多基于深度學習的融合方法。2017年,Prabhakar等人[13]提出了基于卷積神經網絡的圖像融合方法,該方法適用于多曝光圖像融合,網絡結構簡單,僅使用編碼網絡中最后一層計算的結果,會造成中間層有用特征信息丟失的問題。2018年,Ma等人[14]提出了一種以生成對抗網絡為模型的圖像融合方法(FusionGAN),該方法通過生成器與判別器對抗性訓練產生融合圖像,無需預訓練,是端到端的無監督學習模型,但其生成器與判別器網絡結構相對簡單,可以進行優化改進。2018年,Li等人[15]提出了一種基于深度網絡的紅外與可見光圖像融合方法,該方法使用VGG網絡為特征提取工具,在計算時參數較多,耗費大量計算資源。2019年,Li等人[16]提出了以密集連接網絡為模型的圖像融合方法(Dense Fuse),訓練時只考慮編碼層與解碼層,不考慮融合層,測試時需要根據不同情況來設計融合規則。2020年,董安勇[17]等人改進了以卷積神經網絡為模型的圖像融合方法,有效地解決了低頻子帶融合模式給定的問題,同時又克服了手動設置參數的缺陷。2020年,Xu等人[18]提出了一種端到端的統一無監督學習(U2Fusion)圖像融合方法,可以解決多模態、多聚焦和多曝光圖像融合問題,但這種方法訓練起來非常復雜,且占用大量內存資源。
上述方法主要針對清晰明亮的圖像進行融合。可見光圖像在照明條件良好的情況下紋理清晰,紅外圖像在光照較差和存在煙霧的條件下也能較好地凸顯出目標,二者在不同條件下各有所長,考慮到圖像融合應該適應環境改變為源圖像分配權重,從而更加合理地利用多模態信息,于是,本文提出一種模態自適應的紅外與可見光圖像融合方法(MAFusion)。主要工作如下:①采用雙路特征提取網絡針對性的提取成像特點不同的兩類圖像特征,以減少特征丟失;②建立自適應加權模塊,通過雙流交互學習紅外與可見光圖像差異,得到當前環境條件下兩種模態在融合圖像中所占的權重;③在圖像融合過程中加入殘差塊與跳躍殘差組合模塊,補充融合圖像的多尺度特征,提升網絡性能;④在TNO和KAIST數據集上將MAFusion與其他方法進行對比實驗,實驗結果證明本文方法效果較好。
1 相關理論與分析
1.1 對抗生成網絡模型
生成對抗網絡是由Goodfellow等人[19]提出的,由生成器(generative,G)和判別器(discriminative,D)組成。生成器用來生成需要的圖片,判別器類似圖像分類器,判斷圖片是由生成器生成的融合圖像還是真實的可見光圖像。訓練后得到一個比較智能的自動生成器和一個判斷能力較強的分類器。GAN模型的優化函數公式(1)所示:
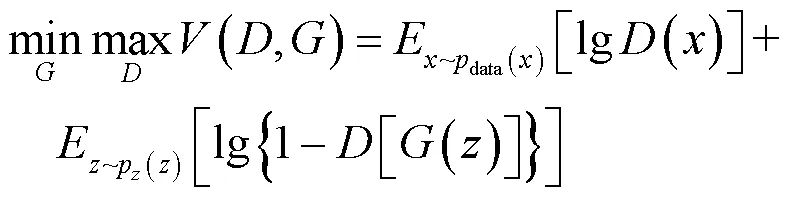
式中:(*)表示分布函數的期望值;表示輸入的真實值;表示輸入生成器的噪聲大小;data()表示真實樣本的分布;p()是定義在低維的噪聲分布;希望()越大越好,[()]越小越好,函數的目的是將最大損失最小化,即可得到損失函數的最優解。
1.2 殘差網絡模型
為解決模型增加網絡深度后網絡性能變差的問題,何凱明等人[20]創新性地提出了深度殘差網絡ResNet。殘差網絡的主要思想是將輸入層通過跳躍連接與卷積層后的輸出相加,有效地解決了梯度消失問題。殘差塊的結構如圖1所示,其中()為殘差學習函數,該函數的學習相對容易,有助于提取深層特征信息,激活函數為Relu。
1.3 問題分析
在深度學習圖像融合方法中,大多數方法采用相同的編解碼網絡進行特征提取,由于紅外與可見光圖像來自不同的信號,采用相同的編解碼網絡會造成突出特征提取不當的問題,因此,本方法將采用雙流特征提取網絡更具針對性地提取兩類圖像的特征。
傳統的模態堆疊策略在訓練過程中對兩類源圖像在通道維按1:1的權重直接Concat級聯,沒有考慮兩類圖像在不同環境條件的優缺點,容易引入冗余特征,降低融合圖像質量,因此需要一種融合策略能夠自適應環境改變提取紅外與可見光兩個模態的重要特征,因此設計自適應加權模塊為兩個模態分配合理的權重。
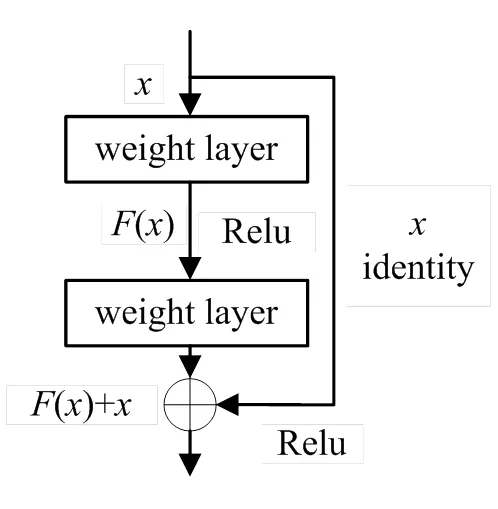
圖1 殘差塊結構圖
為了提高模型性能,使網絡訓練更加容易,同時解決反向傳播時的梯度消失問題,本文方法引入了殘差塊,將Conv1的輸出直接連接到Conv3后。利用殘差塊的恒等映射和跨層連接使前向傳播與反向傳播更加容易,同時有助于補充多尺度特征。在生成器網絡中構建跳躍殘差塊,這種大幅度跨層連接方式使前后層特征聯系更加密切,可以獲取更多有利特征信息。
2 模態自適應的紅外與可見光圖像融合方法
本方法主體網絡為GAN,包括生成器與判別器。生成器是整個模型的主要網絡,影響最終融合圖像的質量,主要用來生成可以騙過判別器的融合圖像。判別器的作用不被生成器生成的圖像騙過,經過訓練達到很強的區分可見光圖像與生成器生成的融合圖像的能力。生成器與判別器均參與訓練過程,測試時則直接利用訓練好的生成器模型生成融合圖像。
訓練過程如下:
1)將紅外與可見光圖像隨機采樣級聯輸入生成器,得到初步融合圖像(標記為假數據),記為();
2)將可見光圖像作為真實數據,隨機采樣記為;
3)將前兩步中某一步產生的數據(標記為假數據的融合圖像和標記為真實數據的可見光圖像)輸入判別器,判別網絡的輸出值為該輸入屬于真實數據(可見光圖像)的概率,真為1,假為0。
4)然后根據得到的概率值計算損失函數;
5)根據判別模型和生成模型的損失函數,利用反向傳播算法,更新模型的參數。先更新判別模型的參數,然后通過再采樣得到的紅外與可見光圖像更新生成器的參數。
2.1 網絡框架
生成器包含了雙路輸入與特征提取模塊、自適應加權模塊、殘差塊、跳躍殘差塊、特征重構模塊和輸出模塊6個部分,其網絡結構圖如圖2所示。
生成器首先對紅外圖像和可見光圖像進行特征提取,然后通過Concat操作將二者特征圖級聯為256通道特征圖,再輸入權值學習融合網絡,完成權值分配。然后,重新分配權值的融合特征輸入一個普通卷積Conv1后,進入殘差塊與跳躍殘差模塊,以實現提取深層特征的同時保留淺層特征;最后,通過輸出模塊進行特征重構得到融合圖像。其具體網絡結構參數見表1。
表中字母及縮寫定義如下:VIS代表可見光圖像,IR代表紅外圖像,ir_weight為紅外圖像權重,vis_weight為可見光圖像權重,表示卷積核大小,表示移動步長,1表示輸入通道數,2表示輸出通道數。
判別器希望訓練出來的模型具有很強的判別輸入圖像是融合圖像或可見光圖像的能力,它以可見光圖像為真實參考值,希望不被生成器生成的融合圖像騙過,輸出的判別值在(0, 1)之間,該值越趨近于1表明判別能力越強,即越趨向于真實參考值(可見光圖像)。其網絡結構如圖3所示。
判別器由4個卷積層、一個特征線性轉換模塊和一個線性層組成,卷積層以3×3大小的卷積核進行特征提取,填充方式均為VALID,激活函數為LeakyReLU,卷積層2、3和4使用BatchNorm來提高模型收斂速度。判別器的網絡結構及參數信息見表2。
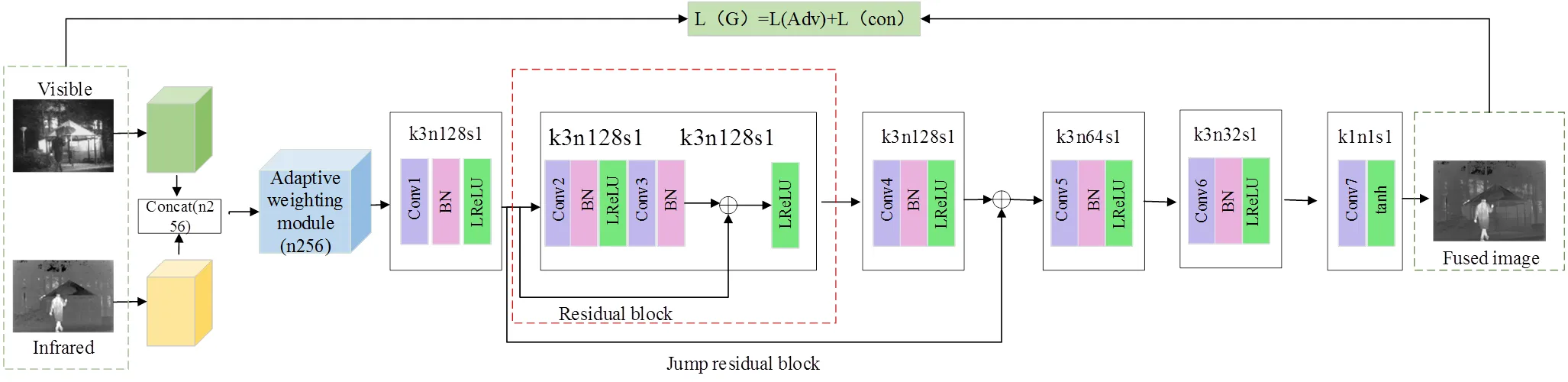
圖2 生成器網絡結構圖
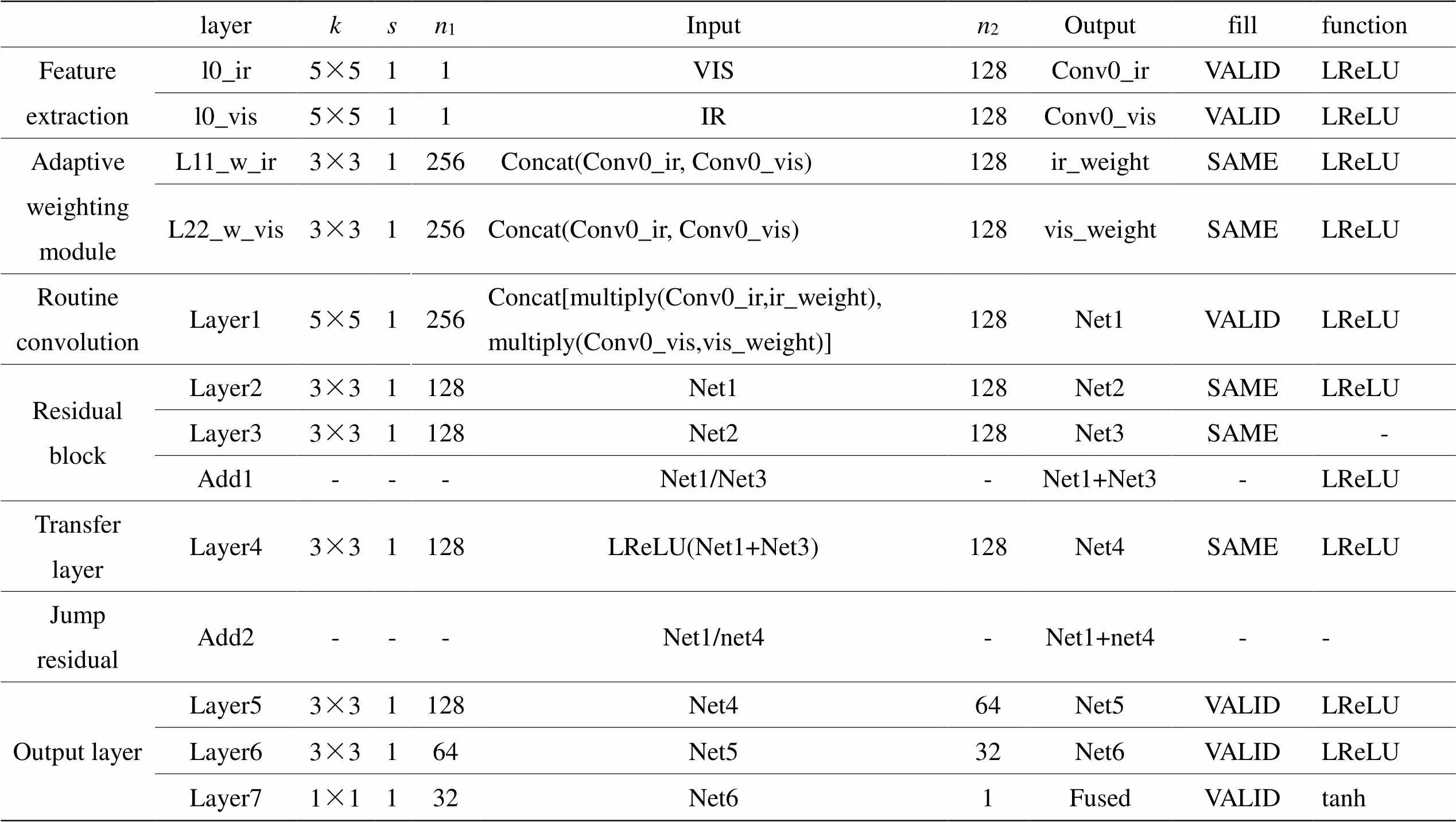
表1 生成器網絡整體結構
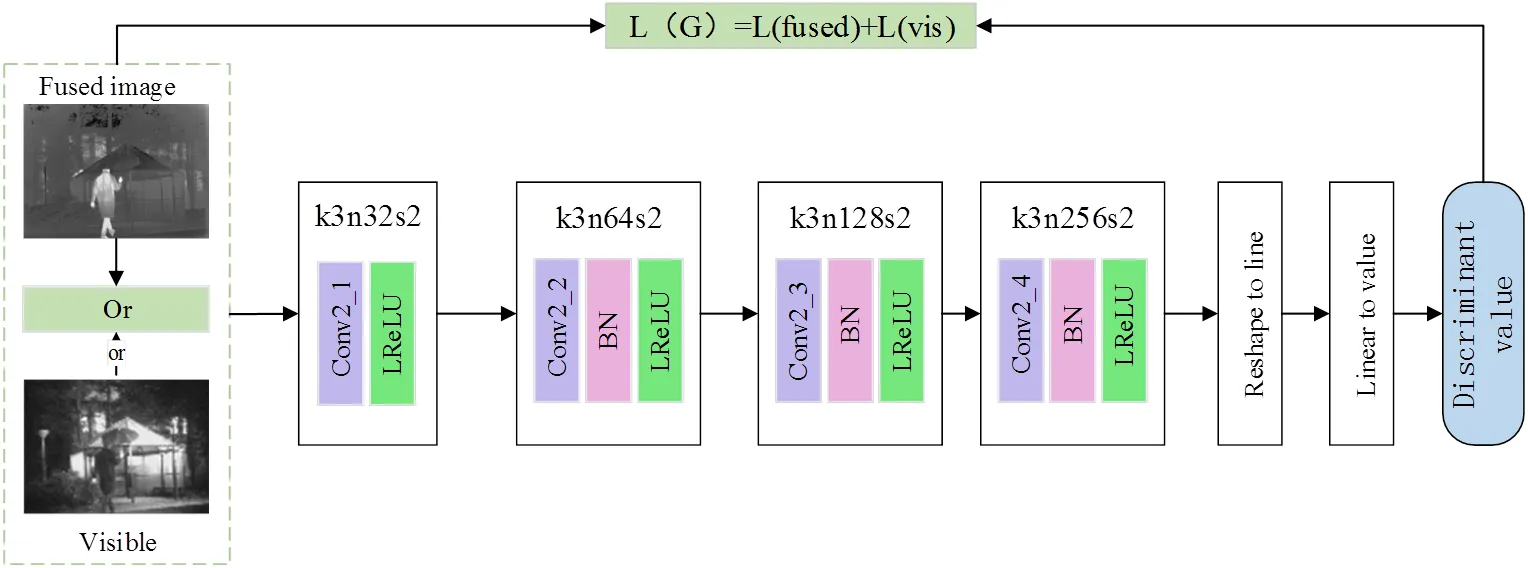
圖3 判別器網絡結構圖
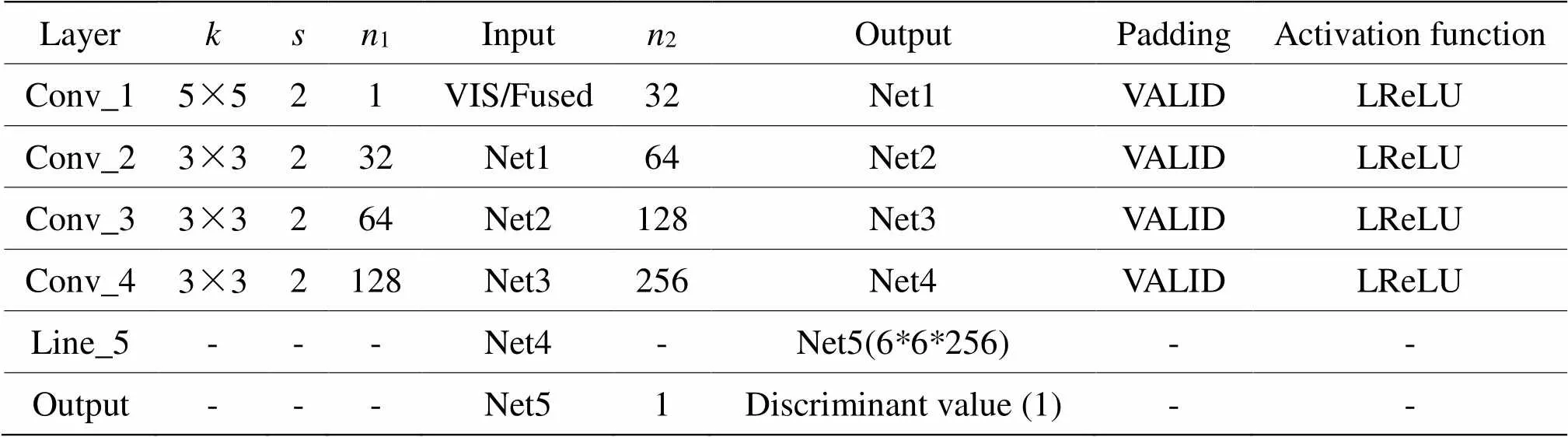
表2 判別器網絡整體結構
表中字母縮寫定義如下:VIS代表可見光圖像,Fused代表融合圖像,表示卷積核大小,表示移動步長,1表示輸入通道數,2表示輸出通道數。
2.2 自適應加權模塊
為了在融合圖像中充分利用紅外圖像目標區域的熱輻射信息,保留可見光圖像有利的紋理信息,抑制噪聲等干擾信息引入融合圖像,提出自適應加權模塊來根據環境變化為兩個模態分配合理的權重值,將源圖像在當前環境條件下的優勢充分體現出來。在生成器中,將該模塊嵌入紅外圖像與可見光圖像輸入之后,最終得到一個包含兩模態重要特征的融合特征圖。其網絡結構圖如圖4所示。

圖4 自適應加權模塊結構圖
該模塊以前一階段得到的紅外與可見光各自特征圖Concat作為輸入,首先通過一個3×3卷積分離兩類特征,然后通過sigmoid函數計算當前環境下的紅外圖像與可見光圖像所占的比例,紅外權重矩陣ir和可見光權重矩陣vis的計算公式如式(2)所示:

式中:1和2表示卷積權重;1和2為卷積偏置;ir和vis通過自主學習得來。最后將獲得的權重與原始特征圖像在通道維相乘,再與源圖像相加以避免特征丟失,從而得到兩個模態的優勢特征,干擾信息被很好地抑制。
2.3 殘差塊與跳躍殘差塊
為解決由于網絡過深導致反向傳播時梯度消失的問題,本文方法引入了殘差塊,學習到的殘差信息有助于補充多尺度特征。同時,為了增加特征圖前后層的關聯性,降低網絡訓練復雜性,在殘差塊的輸入與其后卷積層的輸出通過跳躍連接相連,構建了一個跳躍殘差模塊。殘差塊與跳躍殘差塊的結構圖如圖5所示。
2.4 損失函數與優化方法
MAFusion的損失函數包括兩部分:生成器損失和判別器損失。生成器損失計算融合圖像與源圖像之間的差別;判別器損失以可見光圖像作為標簽,訓練辨別可見光圖像與融合圖像的能力。
1)生成器損失函數
生成器損失G包含對抗損失Adv及內容損失con,其定義如式(3)所示:
G=Adv+con(3)
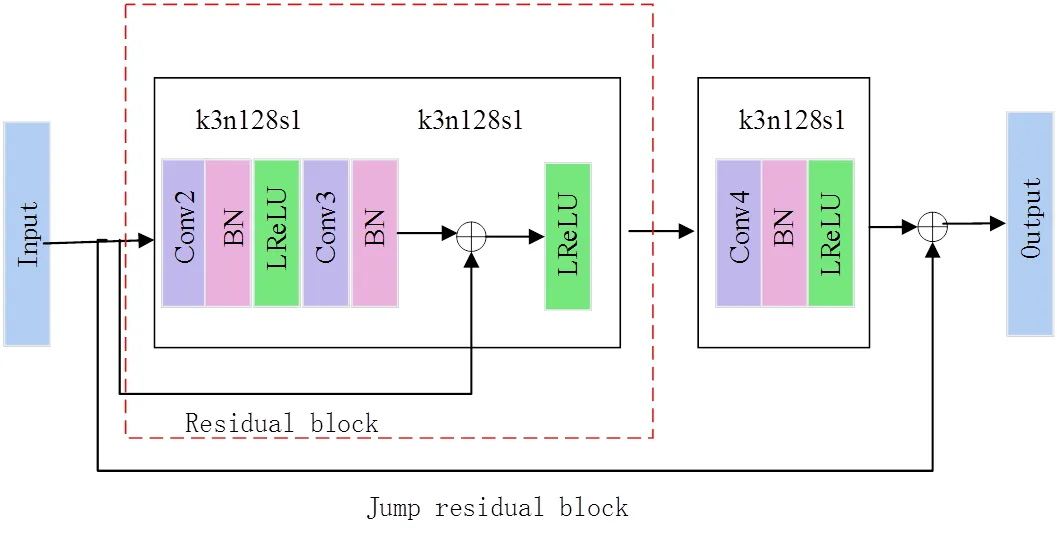
圖5 殘差塊及跳躍連接組合模塊
內容損失con是生成器的主要損失函數,約束了融合圖像與源圖像間的相關性及重點提取紅外圖像與可見光圖像的有利信息。內容損失越小,融合圖像中源圖像的特征越多,其定義如式(4)所示:
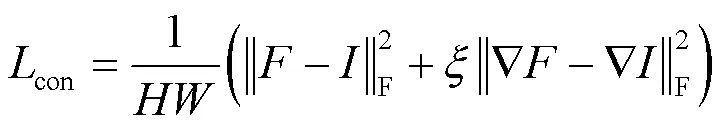
對抗損失Adv是生成器與判別器交互的損失函數,其定義如式(5)所示:
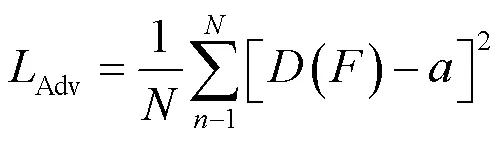
式中:()為判別器對融合圖像的判別結果,在(0,1)之間;為軟標簽(取值不確定的標簽)。判別器希望融合圖像向可見光圖像靠近,其值越大越好,又要保證損失最小,根據文獻[14]將軟標簽的取值范圍設置為(0.7, 1.2)。
2)判別器損失函數
判別器損失D的目的是約束判別器網絡反向傳播參數更新,使判別器在訓練后具有分辨可見光圖像和融合圖像的能力,其定義如式(6)所示:
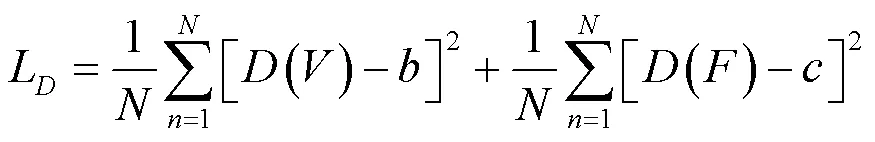
式中:()表示判別器對可見光圖像的判別結果;()表示判別器對融合圖像的判別結果,、為軟標簽(取值不確定的標簽),根據文獻[14]將的范圍設置為(0.7, 1.2),將的范圍設置為(0, 0.3)。
3 實驗及結果分析
實驗在Windows10操作系統和NVIDIA GTX 1080Ti GPU上完成,框架為TensorFlow 1.12.0,訓練與測試平臺為PyCharm。本文方法的訓練集是在TNO[21]數據集中選擇了39對不同場景的紅外和可見光圖像,以步長15將39對圖像分成30236對120×120的紅外圖像與可見光圖像,最后的融合圖像為生成器輸出圖像的拼接。判別器訓練次數設置為2,學習率設為0.00001,將batch_size設置為32,訓練迭代次數設置為20次。本節采用TNO數據集的18對白天圖像和KAIST[22]數據集的14對夜間圖像評估MAFusion的性能。選擇ADF[6]、CBF[7]、WLS[8]、FusionGAN[14]、Densefuse[16]和U2Fusion[18]6種方法與MAFusion作對比實驗,對融合圖像進行主觀評價和客觀評價。對比實驗圖片由MATLAB及PyCharm程序生成,客觀評價指標計算通過MATLAB軟件編程實現。
3.1 主觀評價
MAFusion與對比方法在KAIST數據集中夜晚路燈下的“道路與行人”實驗結果如圖6所示。
從圖6的實驗結果可以看出:圖6(c)中,道路右邊的車輪廓模糊,整幅圖像清晰度較低;圖6(d)中,整體噪聲大,路燈中心有明顯的黑塊;圖6(e)中,道路右邊的人邊緣不清晰,整體紋理細節信息少;圖6(f)中,人和車的輪廓模糊;圖6(g)中,整體背景偏暗,視覺效果較好;圖6(h)中,圖像整體較為平滑,路燈周圍有光暈;圖6(i)中,整體背景較亮且清晰,目標突出,抑制路燈周圍的光暈,能清楚地識別樓層、路燈、行人和車輛等目標。

圖6 KAIST數據集中“道路與行人”融合結果
MAFusion與對比方法在TNO數據集中的“煙霧中的士兵”實驗結果如圖7所示。

圖7 TNO數據集中“煙霧中的士兵”融合結果
從圖7的實驗結果可以看出:圖7(c)、(h)中,能看到士兵與樹木,但輪廓較模糊;圖7(d)中,圖像整體上被煙霧籠罩,無法識別士兵,圖像整體噪聲較大,且有不連續的黑塊;圖7(e)中,士兵輪廓不清晰,煙霧的干擾信息較多,圖像不平滑;圖7(f)中,人與汽車的輪廓都比較模糊,圖像較平滑,仍有煙霧的干擾信息;圖7(g)中,圖像較清晰,但沒有抑制煙霧的干擾,士兵輪廓不清晰;圖7(i)中,士兵與樹木輪廓清晰可見,抑制了煙霧的干擾,重點目標突出,圖像整體平滑,有利信息得到了良好地體現。
MAFusion與對比方法在TNO數據集中的“士兵與車輛”實驗結果如圖8所示。

圖8 TNO數據集中“士兵與車輛”融合結果
從圖8的實驗結果可以看出:圖8(c)中,背景較暗,圖像整體不夠平滑;圖8(d)中,整體呈現顆粒狀,有不連續的黑塊,視覺效果差,整體噪聲較大;圖8(e),圖像整體較模糊,窗戶與左側暗處的樹木輪廓不清晰;圖8(f)中,人的輪廓信息不清楚,部分可見光圖像細節信息丟失;圖8(g)中,整體偏暗,人、車、樹木、房屋均較清晰,但天空中的云輪廓較模糊;圖8(h)中,圖像較平滑,但房屋的窗戶、車窗與左側樹木的輪廓不清晰;圖8(i)中,整體較清晰,圖像平滑,可以清晰看到房屋窗戶的輪廓,車輛、房屋、士兵、地面、路燈和樹木都清晰可見,細節信息豐富,熱輻射信息也得到了較好的體現。
3.2 客觀評價
為了進一步評價融合圖像的融合效果,使用客觀評價方法進行評估。選擇信息熵EN、互信息MI和基于噪聲評估的融合性能abf為測評指標,從圖像信息豐富度、信息互補性和噪聲等不同角度對融合圖像進行評價。以下為測評指標的計算公式。
1)信息熵[23]EN。其值大小能夠體現融合圖像中平均信息量的多少,其定義如式(7)所示:
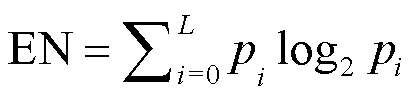
信息熵越大越好,表明圖像所含信息越豐富。
2)互信息[24]MI。該指標表示融合圖像包含源圖像的信息量大小,其值越大越好,計算方法如式(8)所示:
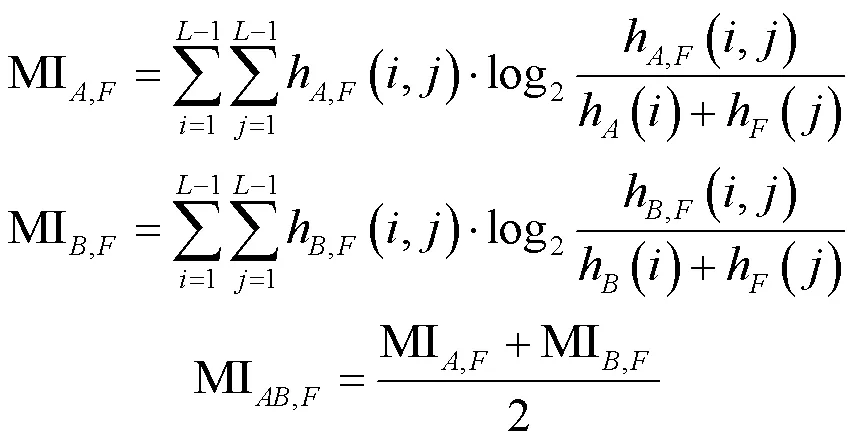
式中:、為源圖像;為融合圖像。
3)基于噪聲評價的融合性能[25]abf。該指標反映了圖像中包含的不必要或冗余的干擾信息的多少,其值越小,圖像噪聲越少。
首先,在照明條件差且行人較小的KAIST數據集上選取14對紅外與可見光圖像對進行實驗,圖片“道路與行人”的融合效果如圖6所示,CBF方法得到的融合圖像視覺效果差,所以直接由其他5種方法與MAFusion分別生成的融合圖像進行測評,“道路與行人”的測評結果見表4。EN和MI指標的值越大越好,abf的值越小越好。
由表4可見,MAFusion在“道路與行人”的融合圖像在EN和MI兩個方面都是最優的,abf值也接近于最優值。KAIST數據集中圖像偏暗,MAFusion中模態自適應權值學習功能很好地感知了光照條件,為兩個模態分配合適的權值,在目標區域保留紅外圖像的熱輻射信息,背景區域保留可見光圖像的紋理信息,使融合圖像測評指標值進一步優化。
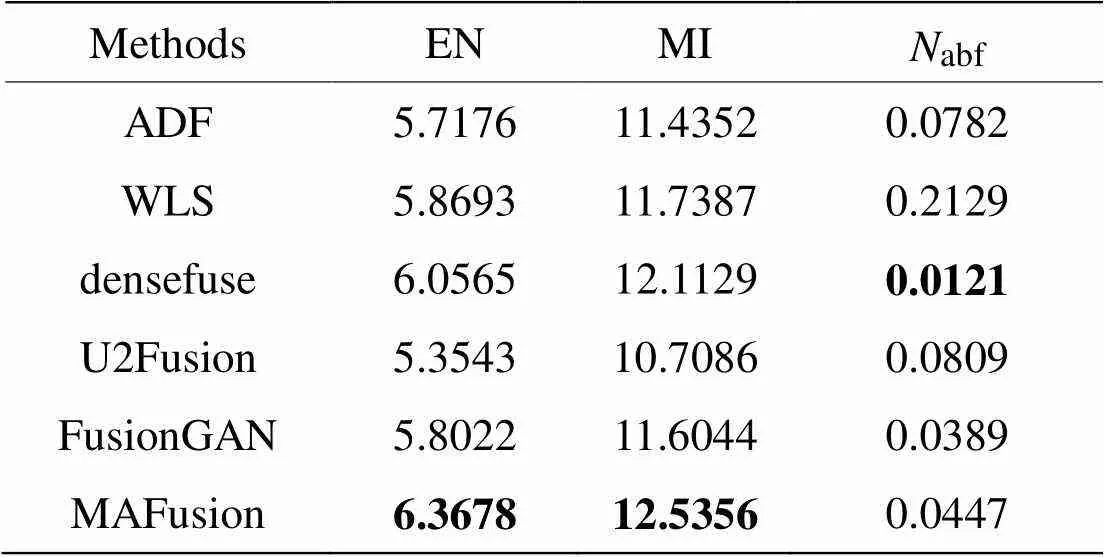
表4 KAIST數據集“道路與行人”融合圖像客觀評價
Note:Bold font is the best value
以KAIST數據集中14對紅外與可見光圖像為源圖像,MAFusion與6種對比方法的測評結果見表5。表中數值均為每種方法生成的14張融合圖像在EN、MI和abf指標上測評結果的平均值,EN和MI指標的值越大越好,abf的值越小越好。
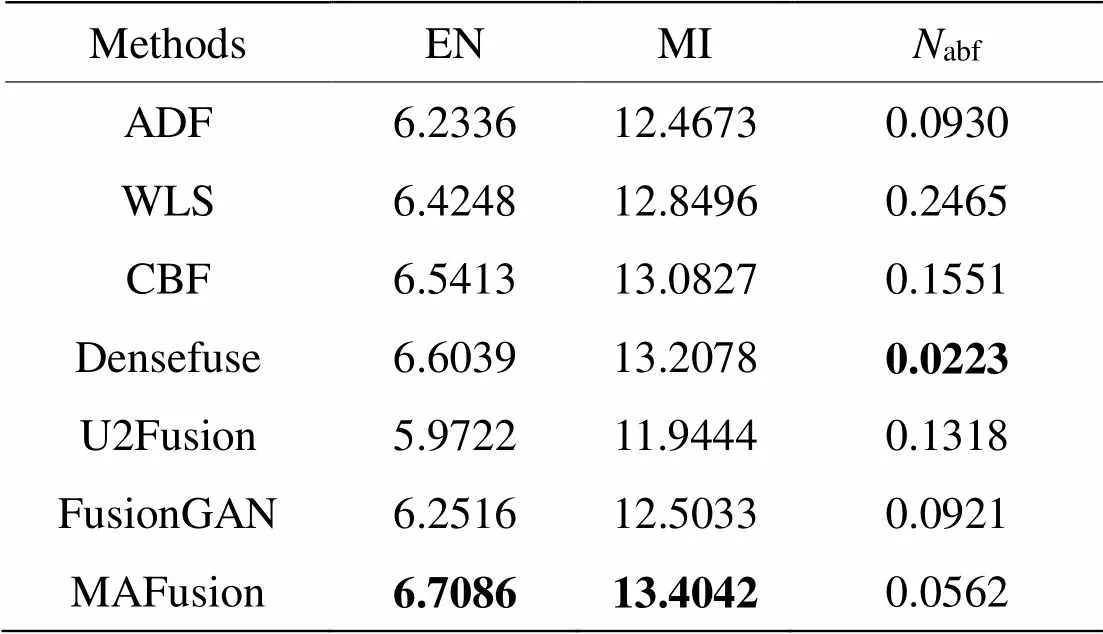
表5 KAIST數據集14組融合圖像客觀評價指標均值
Note:Bold font is the best value
由表5可見,MAFusion在KAIST數據集上的融合圖像在EN和MI兩個方面都是最優的,abf也與對比方法最優值相近,算法性能良好。
然后,在TNO數據集上選取18對紅外與可見光圖像進行實驗,由MAFusion與6種對比方法分別生成融合圖像進行測評,圖片“煙霧中的士兵”的融合結果如圖7所示,其中CBF與WLS方法得到的融合圖像視覺效果差,DenseFuse與U2Fusion有大量煙霧干擾信息,無法識別圖中目標,所以直接由ADF、FusionGAN與MAFusion這3種方法分別生成的融合圖像進行測評,“煙霧中的士兵”的測評結果見表6。EN和MI指標的值越大越好,abf的值越小越好。
由表6可見,MAFusion在“煙霧中的士兵”的融合圖像在EN和MI兩個指標中取得最大值,相比其他方法有明顯地提高,說明得到的融合圖像信息更豐富,源圖像轉移到融合圖像的信息量較大。abf值最低,說明融合圖像與對比方法相比噪聲最小,抑制干擾信息引入融合圖像。
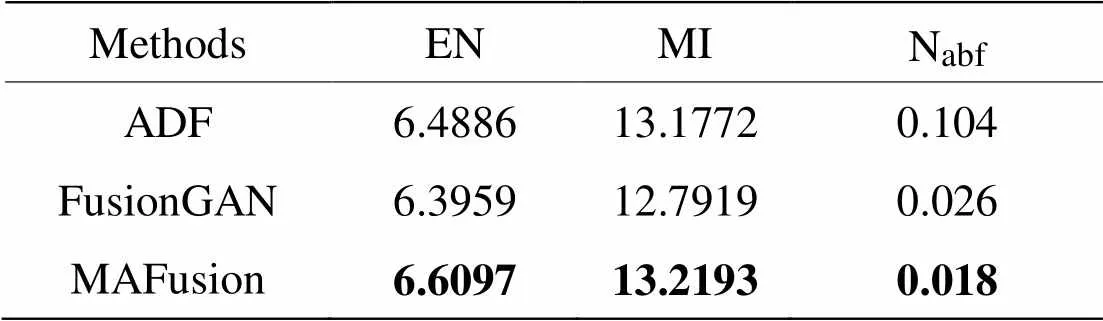
表6 TNO數據集“煙霧中的士兵”融合圖像客觀評價
Note:Bold font is the best value
TNO數據集中圖片“士兵與車輛”的融合結果如圖8所示,其中由CBF方法生成的融合圖像含有大量不連續的黑塊,圖像視覺效果差,所以直接由其他5種方法與MAFusion分別生成的融合圖像進行測評,“士兵與車輛”的測評結果見表7。EN和MI指標的值越大越好,abf的值越小越好。
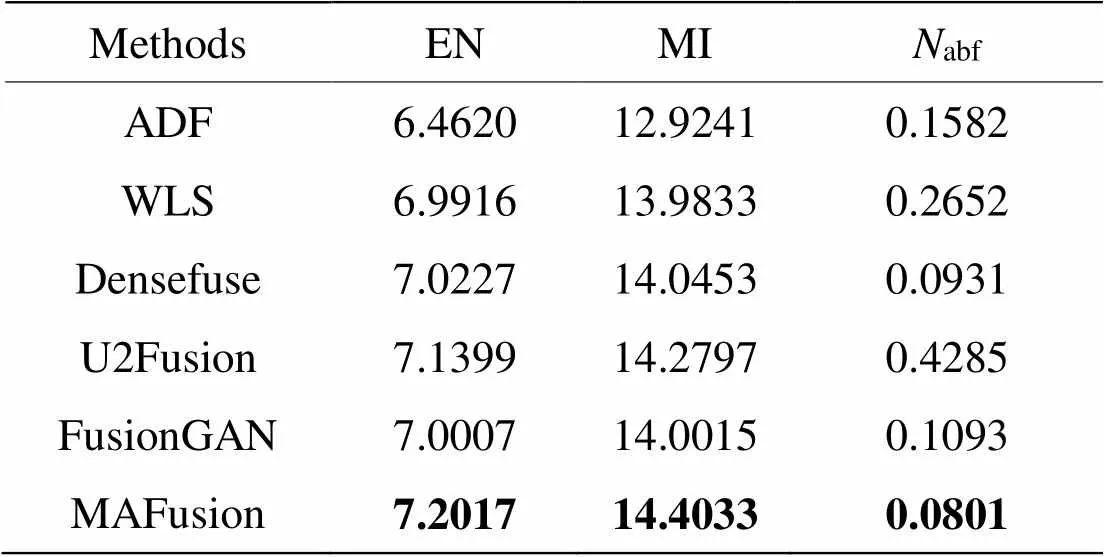
表7 TNO數據集“士兵與車輛”融合圖像客觀評價
Note:Bold font is the best value
由表7可見,MAFusion在“士兵與車輛”的融合圖像在EN和MI兩個指標中取得最大值,abf取得最小值,相比其他方法的性能有明顯提高,說明MAFusion得到的融合圖像信息更豐富,噪聲較小,融合質量較好。
以TNO數據集中的18對紅外與可見光圖像為源圖像,由MAFusion與6種對比方法分別生成融合圖像進行測評,測評結果見表8。表中數值均為每種方法生成的18張融合圖像在EN、MI和abf指標上測評結果的平均值,EN和MI指標的值越大越好,abf的值越小越好。
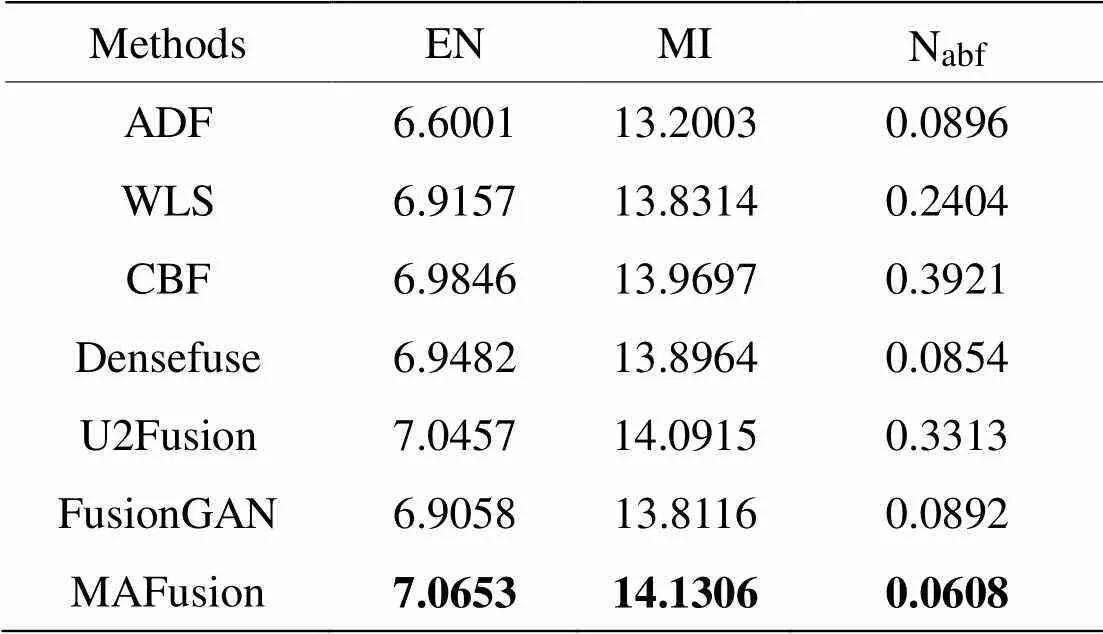
表8 TNO數據集18組融合圖像客觀評價指標均值
Note:Bold font is the best value
由表8可以看出,MAFusion在EN和MI兩個指標中取得最大值,較對比方法有提高,說明得到的融合圖像有利信息更多,源圖像轉移到融合圖像的信息量較大,噪聲較小。
為驗證MAFusion中雙路特征提取與自適應加權模塊、殘差塊及跳躍殘差塊的作用,使用KAIST數據集中的14對典型紅外與可見光圖像做消融實驗,采用客觀評價對所有方法生成的融合圖像進行測評,測評結果見表9。表中數值均為每種方法生成的14張融合圖像在EN、MI和abf指標上測評結果的平均值,EN和MI指標的值越大越好,abf的值越小越好。
在表9中,方法①為FusionGAN方法,其采用直接堆疊策略將紅外與可見光圖像Concat后輸入特征提取網絡,特征提取階段也使用普通卷積完成;方法②在FusionGAN的基礎上,在特征提取階段采用殘差塊與跳躍殘差塊,得到的圖像經測評后3個指標值均優于方法①,體現了殘差塊和跳躍殘差塊恒等映射的優勢,加強淺層特征與深層特征的聯系,獲得的融合圖像能較好地兼顧不同種類源圖像信息。方法③在方法②的基礎上,將紅外與可見光圖像送入雙路特征提取網絡并進行權值自適應學習,得到的圖像測評后的指標值均優于方法②。方法③即MAFusion生成的融合圖像如圖6、圖7和圖8所示,圖像中的信息更豐富,視覺效果良好。

表9 KAIST數據集消融實驗客觀評價
Note:Bold font is the best value
4 結論
針對惡劣環境條件下紅外與可見光圖像融合效果較差且容易引入噪聲的問題,本文提出了一種模態自適應的紅外與可見光圖像融合方法。該方法使用雙路特征提取及權值學習融合網絡,自適應提取兩個模態的重要信息,并分配權重,強化對重要信息的學習。同時,在生成器特征提取階段加入殘差塊與跳躍殘差塊,使得深層網絡特征提取能力增強,反向傳播也更加容易,增強模型學習能力。實驗結果表明,提出的方法在圖像的視覺觀察、目標清晰度、圖像信息豐富性和抑制噪聲等方面具有良好的性能。
[1] 段輝軍, 王志剛, 王彥. 基于改進YOLO網絡的雙通道顯著性目標識別算法[J]. 激光與紅外, 2020, 50(11): 1370-1378.
DUAN H J, WANG Z, WANG Y.Two-channel saliency object recognition algorithm based on improved YOLO network[J]., 2020, 50(11): 1370-1378.
[2] 李舒涵, 宏科, 武治宇. 基于紅外與可見光圖像融合的交通標志檢測[J]. 現代電子技術, 2020, 43(3): 45-49.
LI S H, XU H K, WU Z Y. Traffic sign detection based on infrared and visible image fusion[J]., 2020, 43(3): 45-49.
[3] Reinhard E, Adhikhmin M, Gooch B, et al. Color transfer between images[J]., 2001, 21(5): 34-41.
[4] Kumar P, Mittal A, Kumar P. Fusion of thermal infrared and visible spectrum video for robust surveillance[C]//, 2006: 528-539.
[5] 常新亞, 丁一帆, 郭夢瑤. 應用整體結構信息分層匹配的紅外與可見光遙感圖像融合方法[J]. 航天器工程, 2020, 29(1): 100-104.
CHANG X Y, DING Y F, GUO M Y. Infrared and visible image fusion method using hierarchical matching of overall structural information[J]., 2020, 29(1): 100-104.
[6] Bavirisetti D P, Dhuli R. Fusion of infrared and visible sensor images based on anisotropic diffusion and karhunen-loeve transform[J]., 2016, 16(1): 203-209.
[7] Kumar B S. Image fusion based on pixel significance using cross bilateral filter[J]., 2015, 9(5): 1193-1204.
[8] MA J, ZHOU Z, WANG B. Infrared and visible image fusion based on visual saliency map and weighted least square optimization[J]., 2017, 82: 8-17.
[9] LIU Y, WANG Z. Simultaneous image fusion and denoising with adaptive sparse representation[J]., 2014, 9(5): 347-357.
[10] Burt P, Adelson E. The Laplacian pyramid as a compact image code[J]., 1983, 31(4): 532-540.
[11] 馬雪亮, 柳慧超. 基于多尺度分析的紅外與可見光圖像融合研究[J]. 電子測試, 2020, 24(4): 57-58.
MA Xueliang, LIU Huichao. Research on infrared and visible image fusion based on multiscale analysis[J]., 2020, 24(4): 57-58.
[12] LI S, YIN H, FANG L. Group-sparse representation with dictionary learning for medical image denoising and fusion[J]., 2012, 59(12): 3450-3459.
[13] Prabhakar K R, Srikar V S, Babu R V. DeepFuse: A deep unsupervised approach for exposure fusion with extreme exposure image[C]//the 2017, 2017: 4724-4732.
[14] MA J Y, YU W, LIANG P W, et al. FusionGAN: A generative adversarial network for infrared and visible image fusion[J]., 2019, 48: 11-26.
[15] LI H, WU X J, Kittler J. Infrared and visible image fusion using a deep learning framework[C]//The 24(ICPR), 2018: 2705-2710.
[16] LI H, WU X. DenseFuse: A fusion approach to infrared and visible images[J]., 2019, 28(5): 2614-2623.
[17] 董安勇, 杜慶治, 蘇斌, 等. 基于卷積神經網絡的紅外與可見光圖像融合[J]. 紅外技術, 2020, 42(7): 660-669.
DONG Anyong, DU Qingzhi, SU Bin, et al. Infrared and visible image fusion based on convolutional neural network[J].2020, 42(7): 660-669.
[18] XU Han, MA Jiayi, JIANG Junjun, et al. U2Fusion: A unified unsupervised image fusion network[J]., 2020, 44: 502-518.
[19] Goodfellow I, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets[C]//27, 2014: 2672-2680.
[20] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]//(CVPR), 2016:770-778.
[21] Figshare. TNO Image Fusion Dataset[OL]. [2018-09-15]. https://flgshare. com/articles/TNO Image Fusion Dataset/1008029.
[22] Hwang S, Park J, Kim N, et al. Multispectral pedestrian detection: benchmark dataset and baseline[C]//2015(CVPR), 2015: 1037-1045.
[23] Roberts J W, Aardt J V, Ahmed F. Assessment of image fusion procedures using entropy, image quality, and multispectral classification[J]., 2008, 2(1): 023522-023522-28.
[24] QU G, ZHANG D, YAN P. Information measure for performance of image fusion[J]., 2002, 38(7): 313-315.
[25] Kumar B K S. Multifocus and multispectral image fusion based on pixel significance using discrete cosine harmonic wavelet transform[J]., 2013, 7(6): 1125-1143.
Mode Adaptive Infrared and Visible Image Fusion
QU Haicheng,WANG Yuping,GAO Jiankang,ZHAO Siqi
(School of Software, Liaoning Technical University, Huludao 125105, China)
To solve the problems of low contrast and high noise of fused images in low illumination and smoky environments, a mode-adaptive infrared and visible image fusion method (MAFusion) is proposed. Firstly, the infrared and visible images are input into the adaptive weighting module in the generator, and the difference between them is learned through two streams interactive learning. The different contribution proportion of the two modes to the image fusion task in different environments is obtained. Then, according to the characteristics of each modal feature, the corresponding weights of each modal feature are obtained independently, and the fusion feature is obtained by weighted fusion. Finally, to improve the learning efficiency of the model and supplement the multi-scale features of the fused image, a residual block and jump connection combination module are added to the image fusion process to improve the network performance. The fusion quality was evaluated using the TNO and KAIST datasets. The results show that the visual effect of the proposed method is good in subjective evaluation, and the performance indexes of information entropy, mutual information, and noise-based evaluation are better than those of the comparison method.
image fusion, mode adaptive, GAN, ResNet
遼寧省教育廳一般項目(LJ2019JL010);遼寧工程技術大學學科創新團隊資助項目(LNTU20TD-23)。
TP391
A
1001-8891(2022)03-0268-09
2021-07-18 ;
2021-09-23.
曲海成(1981-),男,博士,副教授,主要研究方向:圖像與智能信息處理。E-mail:quhaicheng@lntu.edu.cn。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學院學報(2015年4期)2015-02-28 14:30:00
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
計算物理(2014年2期)2014-03-11 17:01:39
河南科技(2014年23期)2014-02-27 14:19:15
