基于低分辨率紅外傳感器的深度學習動作識別方法
2022-04-08 08:43:20張昱彤翟旭平
紅外技術 2022年3期
關鍵詞:動作
張昱彤,翟旭平,聶 宏
基于低分辨率紅外傳感器的深度學習動作識別方法
張昱彤1,翟旭平1,聶 宏2
(1. 上海大學 特種光纖與光接入網重點實驗室,上海 200444; 2. 美國北愛荷華大學 技術系,愛荷華州 錫達福爾斯市)
近年來動作識別成為計算機視覺領域的研究熱點,不同于針對視頻圖像進行的研究,本文針對低分辨率紅外傳感器采集到的溫度數據,提出了一種基于此類紅外傳感器的雙流卷積神經網絡動作識別方法。空間和時間數據分別以原始溫度值的形式同時輸入改進的雙流卷積神經網絡中,最終將空間流網絡和時間流網絡的概率矢量進行加權融合,得到最終的動作類別。實驗結果表明,在手動采集的數據集上,平均識別準確率可達到98.2%,其中彎腰、摔倒和行走動作的識別準確率均達99%,可以有效地對其進行識別。
動作識別;雙流卷積神經網絡;低分辨率紅外傳感器;深度學習
0 引言
隨著世界各國人口老齡化問題越來越嚴重,在日常生活中,高齡獨居老人極易因為發生跌倒等意外情況卻得不到及時的救治而殘疾甚至死亡[1],因此對室內跌倒檢測算法的研究成為了熱點。目前,已有許多相關研究,根據采集數據的裝置分為攝像裝置和傳感裝置,傳感裝置可以細分為需穿戴傳感器和無需穿戴傳感器。在日常生活中,攝像裝置[2]不僅會暴露用戶的日常隱私,且極易受到光照影響。加速度傳感器[3]等需穿戴傳感裝置需要老人時刻穿戴在身,一定程度上也造成了不便,而壓力傳感器[4]、二值傳感器[5]等無需穿戴傳感裝置也往往受到使用環境的約束和影響,系統魯棒性較差。為了減少以上因素的影響,有人提出使用被動紅外傳感器采集數據。此類傳感器通過接收外界的紅外輻射工作,采集的數據為探測區的溫度,這樣既保護了用戶的隱私,不易受光線影響,也易于安裝且不約束老人的行為。
基于此類傳感器的動作識別方法主要有傳統計算機視覺方法和深度學習方法兩種,傳統計算機視覺方法[6-8]需要人為地提取特征進行可靠的識別,這就要求對采集的數據有很深的了解,此類方法同時也需要設置很多的閾值,閾值的選取一定程度上影響了算法的性能。隨著深度學習的提出和實驗平臺的更新加強,卷積神經網絡(convolutional neural network,CNN)被越來越多的應用在動作識別領域,CNN可以自行從輸入集數據中學習特征,免去了人為提取時帶來的不確定性。Aparna團隊[9]基于LeNet構建網絡,對通過紅外攝像頭的隨機采樣采集數據送入網絡學習,并與傳統方法進行對比,識別率較高。王召軍[10]等人基于VGGNet搭建網絡,不僅進行了動作識別還進行了身份識別,都取得了較高識別率。在許多方法中,還將CNN與長短期記憶模型(long short term memory,LSTM)進行結合搭建網絡,也取得了不錯的效果。Takayuki團隊[11]用16×16的紅外陣列傳感器采集數據,將紅外幀差圖像序列和原始紅外圖像序列一起放入網絡進行學習,并且全連接層后加上了LSTM提高準確率。Xiuyi Fan團隊[12]用多個紅外傳感器采集數據放入到網絡進行訓練學習,并對比了門控循環單元與LSTM、MLP(Multilayer Perceptron)的結果。Felix POLLA團隊[13]采用了C3D網絡對連續幀序列進行處理,同時也加上了LSTM網絡充分利用了時間關聯信息。但是以上方法考慮了動作的時間信息,卻沒有過多捕捉運動特征,在可見光領域中,雙流CNN得到了廣泛的研究。2014年Simonyan團隊[14]提出了雙流CNN網絡結構,將單幀圖像和光流圖分別作為空間和時間流一起放入網絡訓練,同時對時間與空間特征進行提取。Christoph團隊[15]則提前進行了空間和時間特征的融合,可以保證更好地從空間到時間的映射關系,極大地發展了雙流CNN網絡。
為了結合時空信息和動作特征,本文將雙流CNN網絡結構應用在基于低分辨率紅外傳感器的人體動作識別中。采用HEIMANN型號為HTPA80x64 dR1L5.0/1.0的紅外陣列傳感器采集彎腰、坐下、站起、行走和摔倒5種日常動作的溫度數據,分別構建空間和時間數據。常見深度學習動作識別方法以單幀RGB圖像或者連續幀視頻圖像作為輸入,本文方法中以原始溫度數據作為輸入,為了增加樣本多樣性,提高模型泛化能力,本文通過隨機裁剪、翻轉操作進行數據增強。在網絡模型方面,首先根據雙流的輸入尺寸在原始雙流CNN的基礎上調整網絡的層次,搭建時間流和空間流網絡,接著對雙流的輸出進行加權融合,得到最終的分類結果。將雙流網絡分別與時、空單流網絡的結果進行比較,并與原始雙流CNN網絡、基于預訓練網絡遷移學習以及兩種手工提取特征方法的識別結果進行對比,以驗證所提出方法的性能。
1 動作識別方法設計
本文提出的基于低分辨率紅外傳感器深度學習動作識別方法分為訓練流程和識別流程。訓練時,分別構建單個訓練數據樣本的空間數據和時間數據。在構建樣本空間數據時,首先進行前景提取,本文針對多數前景提取方法采用經驗值設置閾值的問題,提出一種基于奈曼-皮爾遜準則設置最佳閾值的前景提取方法,較為完整干凈地提取出前景,對各個像素點時域上累加運動幀內的數據,得到累計溫度矩陣作為該樣本的空間數據。在構建時間數據時,將代表運動過程的9個單幀數據按照時序順序以3×3的形式拼接成總溫度矩陣,并分別一一對應保存樣本的空間數據和時間數據。數據類型轉換之后,通過隨機位置裁剪固定尺寸、隨機水平翻轉進行數據增強,提高樣本多樣性,改進原始的雙流CNN網絡的空間流網絡結構,將構建的時空訓練數據送入改進的雙流CNN網絡中進行訓練,得到訓練數據的分類結果,將其與訓練數據的標簽,即訓練數據的真實動作類別進行比較,分類結果的誤差由損失函數量化。上述訓練過程經不斷迭代后,分類結果和數據標簽之間的誤差將不斷縮小,訓練誤差值每次減少時,進行網絡的權值更新,保存誤差值最小時的網絡模型作為最優模型。在進行識別時,將待識別數據通過以上方法構建空間數據和時間數據之后首先轉換數據類型,按照與訓練數據相同的輸入尺寸進行裁剪預處理操作后送入最優模型中,得到待識別數據的動作識別結果,方法流程如圖1所示。
2 時空數據的構建
本文基于紅外傳感器采集到的溫度數據,構建時空數據,將原始溫度值輸入到提出的雙流CNN網絡中完成訓練和識別。
2.1 空間數據的構建
首先采取背景減除法提取前景,為了解決根據經驗值選取閾值[16]的問題,本文方法基于奈曼-皮爾遜準則選取每幀的最佳分割閾值。設像素點為背景點的狀態設為0,為前景點的狀態設為1,該準則是在(1/0)=的約束條件下,使得檢測概率達到最大。
可以利用拉格朗日乘子構建目標函數:
=(0/1)+[(1/0)-] (1)
根據要求,即求目標函數的最小值,將公式(1)轉化為積分運算,且由于:
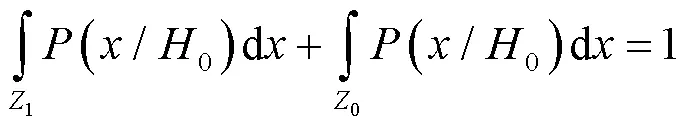
式中:Z0和Z1分別為判決區域,公式(1)可寫為以下形式:

若要求得公式(3)的最小值,被積函數部分應該取負,可得以下關系:
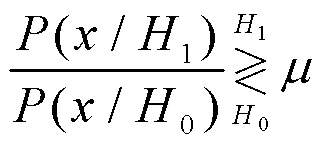
式中:判決門限可由約束條件得到:
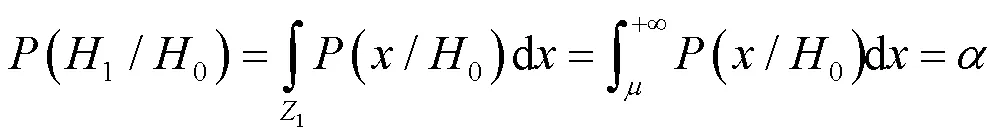
通過每幀數據得到的判決門限即為每幀的最佳判決閾值xth。本文采用虛警率為0.01約束下獲得每幀的最佳判決閾值kth,前景提取公式如下:
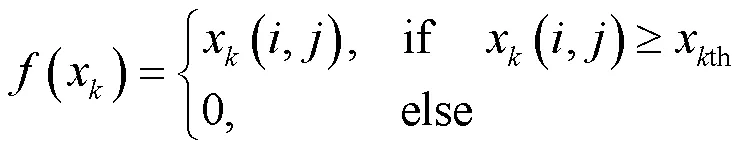
得到每一幀的前景之后,對各個像素點時域上累加運動幀內的數據,得到累計溫度矩陣(),其二維熱圖如圖2所示。
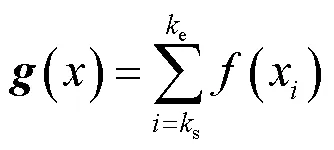
由圖2可以發現,空間數據僅僅展現了運動目標的位置,而不包含位置變化的時序信息。公式(7)中的s、e分別代表運動開始和結束幀,由如下算法確定。探測區無人活動時,溫度值在時域上波動較小,而探測區中存在活動時,時域溫度波動較大。根據這一特點,可以通過提取每幀的最大溫度方差得到s和e。
a為第幀的第(,)個像素點的溫度值。第幀每個像素點的方差計算公式為:
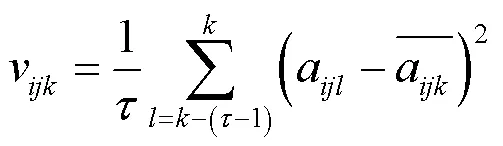
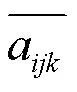
經過公式(8),可以得到每一幀的溫度方差分布矩陣,根據之前的分析,通過公式(9)提取每幀的最大溫度方差:
vmax=max() (9)
每幀最大溫度分布方差vmax大于等于閾值th時,則表明運動開始,該幀計為s,否則視為運動結束,計為e。本文確定閾值th的方法為在無人的環境下,在實驗前、實驗中和實驗后運行裝置至最大幀,重復3次,分別計算9組數據的最大溫度方差,選取最大值作為閾值th。為了研究環境溫度和傳感器安裝場景對閾值的影響,由于實驗的限制,在如表1所示的環境溫度和場景下進行了對比試驗。
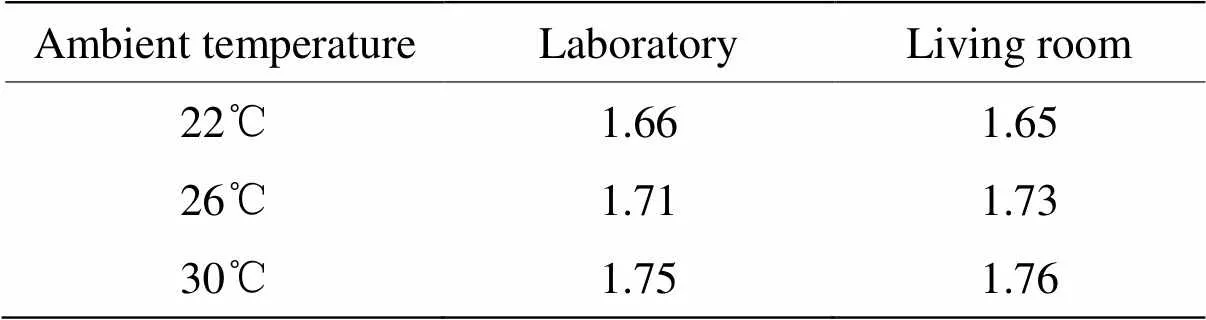
表1 不同環境溫度、安裝場景下的閾值對比
經對比實驗后發現,相對而言,傳感器安裝空間對閾值變化影響很小,環境溫度變化對其影響更大,根據實驗時的環境溫度,最終閾值設為1.7。
2.2 時間數據的構建
不同于基于視頻圖像的雙流CNN識別方法,本文采用的數據是從紅外陣列傳感器中獲得如公式(10)所示的溫度分布數據矩陣:
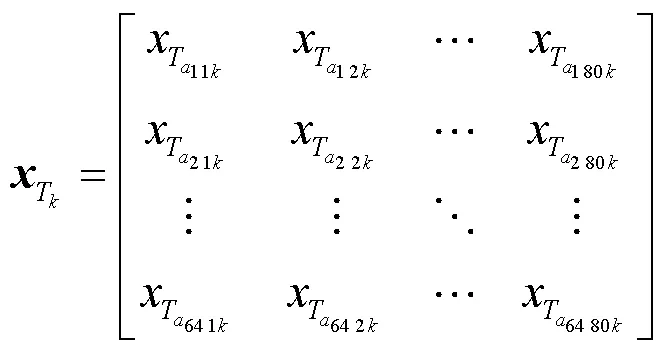
上式表示第個樣本第幀的溫度分布數據。基于視頻圖像的雙流CNN方法往往使用光流圖作為時間流網絡的輸入,在本文的方法中,為了減少網絡計算量,提升網絡的有效性,將代表運動過程的9個原始單幀數據按照時序順序以3×3的形式拼接成總溫度矩陣作為時間流網絡的輸入。
在構建空間數據時可以求得動作過程的開始幀s和結束幀e,由于要選取9幀數據,所以幀間隔為:
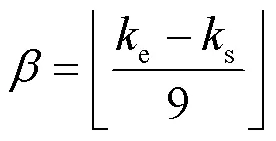
將9幀數據以公式(12)的形式進行拼接成像素數為192×240的()作為時間數據,其二維熱圖如圖3所示。

3 網絡設計
由于樣本數量有限,為了提高模型泛化能力,在訓練前需要進行數據增強,訓練數據在數據類型轉換之后,進行隨機位置裁剪固定尺寸、隨機水平翻轉操作。裁剪操作既可以增加原始樣本的多樣性,也可以減少網絡的訓練計算量,確定固定尺寸大小時,需盡可能保留數據中的重要信息,原始空間數據大小為64×80,時間數據大小為192×240,經過實驗對比,空間數據裁剪為60×60的大小輸入空間流網絡,時間流網絡輸入尺寸則為180×180。原始雙流CNN的網絡結構[14]使用的是基本上與AlexNet同一種思路設計的CNN_M網絡結構,時間流與空間流網絡結構均包含5層卷積層和2層全連接層。由于本文空間數據輸入尺寸較小,所以空間流網絡采用VGG網絡的設計思路基于原始CNN_M空間網絡結構進行改進,最終將時間流與空間流網絡的Softmax結果進行加權融合,得到最終的識別結果。
3.1 空間流網絡
空間流輸入數據的原始大小為64×80,尺寸較小,若采用原始網絡中尺寸較大的卷積核,網絡的深度會受到限制,VGG網絡[17]用多個較小的卷積核代替單個較大卷積核,該方法不僅可以加深網絡深度以學習更高級的特征,也降低了計算復雜度,因此本文采用此設計思路用2個3×3的卷積核代替原始較大尺寸的卷積核,增加網絡的深度提取深層空間特征,本文采用的空間流網絡結構如圖4所示。

圖4 空間流網絡結構圖
改進后的空間流網絡結構主要包括6層卷積層和3層最大池化層以及2層全連接層。空間流的輸入通道數為1,由于輸入尺寸較小,尺寸較大的卷積核會導致輸出的特征圖較小,不利于特征的學習,因此卷積層均采用大小3×3,步長為1的卷積核,第1、2卷積層通道數均為16,第3、4卷積層通道數均為32,第5卷積層通道數為64,第6卷積層通道數為128,一定程度上加深網絡的深度和寬度,在學習更加豐富的深層特征的同時,降低了參數的個數以及計算復雜度。池化層采用尺寸為2×2的窗口,步長為2,以篩選特征,降低特征圖的維度,保存主要特征。最后經過2層全連接層,全連接層中采用dropout為0.5的操作防止網絡過擬合。卷積層和全連接層均采用整流線性單元(Rectified Linear Units,ReLU)作為激活函數。采用softmax函數計算空間流網絡的最終結果。
3.2 時間流網絡
時間流網絡基于原始雙流CNN時間流網絡[14],為了減少參數量,防止過擬合,在原始網絡基礎上減少了一層卷積層,時間流網絡結構如圖5所示。
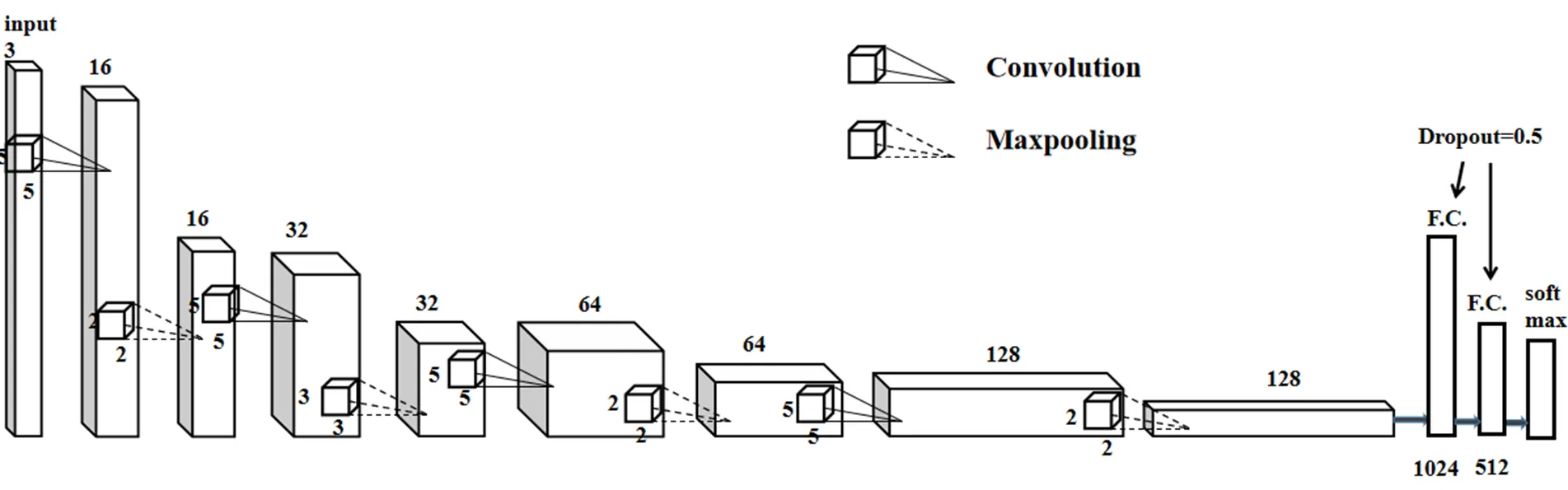
圖5 時間流網絡結構圖
時間流網絡結構主要包括4層卷積層、4層最大池化層以及2層全連接層。卷積層均采用尺寸為5×5的卷積核,步長為1。第1層卷積層通道數為16,第2層通道數為32,第3層通道數為64,第4層通道數為128,每個卷積層之后均進行最大池化操作,在第1、3、4池化層選用大小為2×2的窗口,步長為2,第2池化層采用大小為3×3的窗口,步長為3。經過卷積和最大池化操作后經過2層dropout均為0.5的全連接層。卷積層和全連接層均采用ReLU函數為激活函數,softmax函數計算時間流結果。
3.3 雙流CNN網絡
最終需要將時間流網絡和空間流網絡的概率向量經過下式加權融合后得到最終結果:
()=×s()+(1-)×t(),0≤≤1 (13)
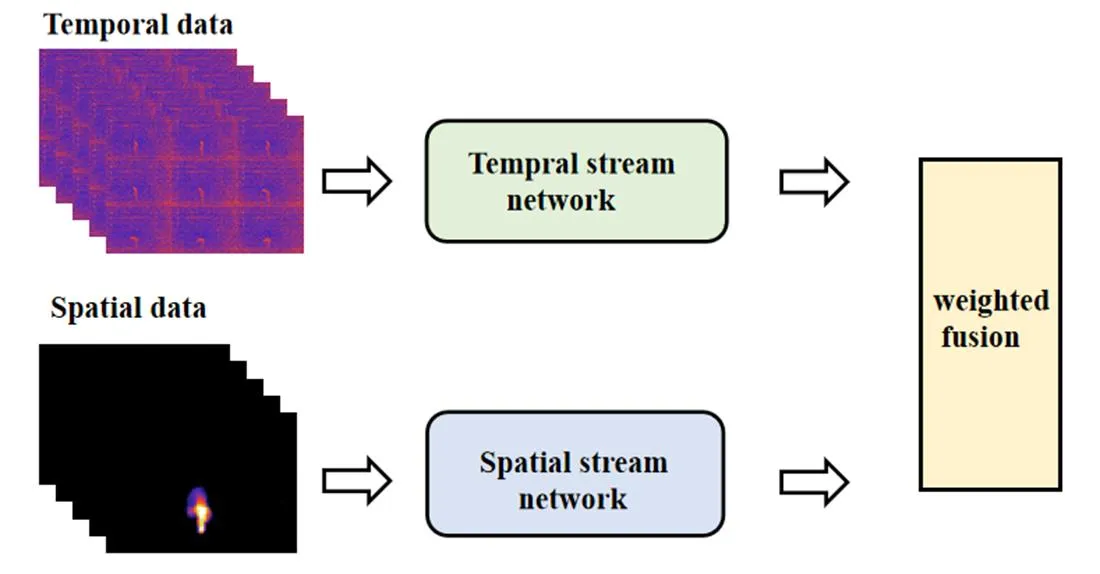
圖6 雙流CNN網絡
訓練過程中模型的損失函數采用交叉熵函數進行計算,優化算法采用隨機梯度下降(stochastic gradient descent,SGD)算法[18],SGD算法進行一次更新操作時,會對每個樣本進行梯度更新,樣本較多時,不會產生冗余,且速度較快。經過對比試驗后,模型的學習率初始化為0.01,動量為0.5,不進行學習率的更新。
網絡的訓練輪數為100輪,訓練時,每批次從頭到尾讀取20組數據載入內存訓練,空間和時間流的數據必須保持一一對應,即每次讀取的空間、時間數據均來源于同一樣本。一次迭代結束后將訓練數據隨機打亂再進行下一次的讀取數據和訓練。所有輪數訓練完成后,保存損失值最小的模型作為最終的模型,將測試數據放入該模型得到最終的分類結果。
4 實驗與性能分析
4.1 實驗平臺及數據采集
本文實驗基于Pytorch深度學習框架和型號為NVIDIA GeForce GTX 1050Ti的GPU,計算框架為CUDA。采用德國HEIMANN型號為HTPA80x64 dR1L5.0的熱電堆陣列傳感器,在校內普通實驗室采集數據。室溫為26℃,將傳感器置于墻壁,距離地面2.6m。測試人員共10名(7男3女),被測人員在探測區依次完成彎腰、站起、坐下、摔倒和行走5種動作,每種動作重復30次,最終每個動作獲得300組數據,一共1500組,按照2:1的比例劃分為訓練集和測試集,進行實驗,訓練集為1000組,測試集為500組。
4.2 實驗結果與對比
本文的空間流網絡不同于原始雙流CNN的空間流網絡,基于VGG網絡的設計思想,采用多個小卷積核代替中的大卷積核,在加深網絡的同時,降低計算復雜度。訓練集在本文改進的空間流網絡與原始雙流CNN空間流在訓練過程中訓練誤差值對比如圖7所示。
如圖7所示,實驗證明改進后的空間流網絡比原網絡收斂速度更快,損失值下降得更低。空間流和時間流兩路的輸出最終進行加權融合得到最終的分類結果,不同權重的識別準確率如圖8所示,最終選擇權重為0.5,即平均融合。
為了驗證所提出的雙流CNN的網絡性能,將雙流CNN與空間單流、時間單流進行對比,不同動作的識別率如表2所示。
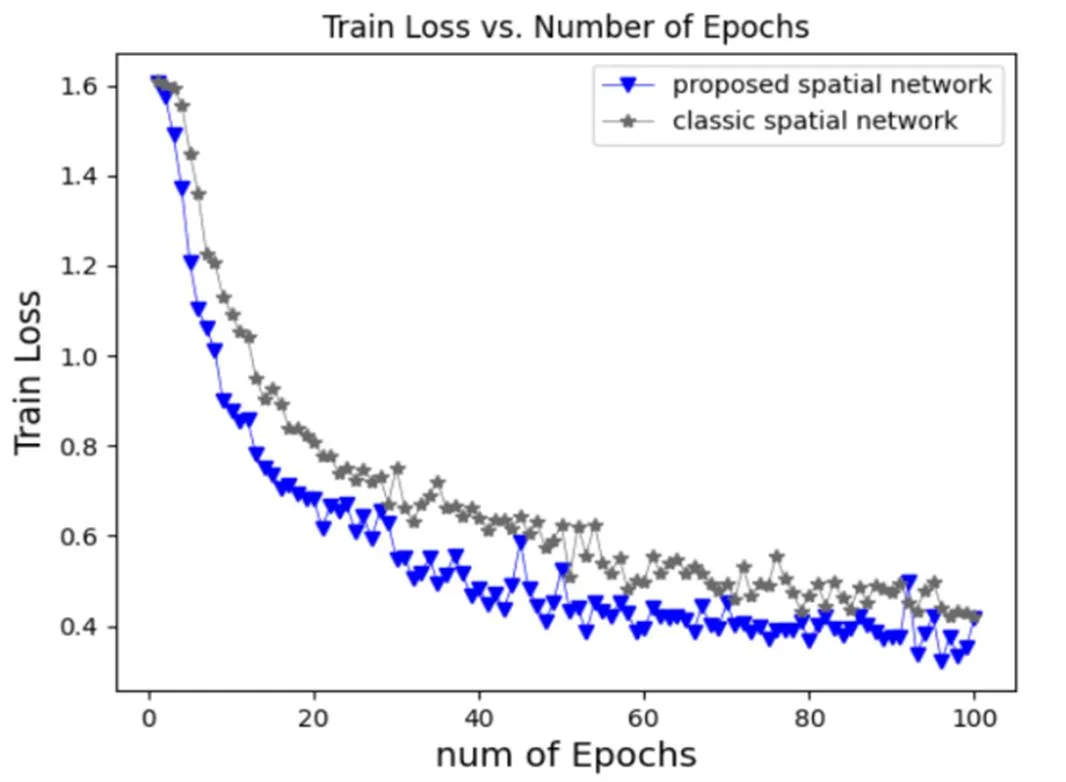
圖7 兩種空間流網絡訓練誤差值對比

圖8 不同權重的識別準確率
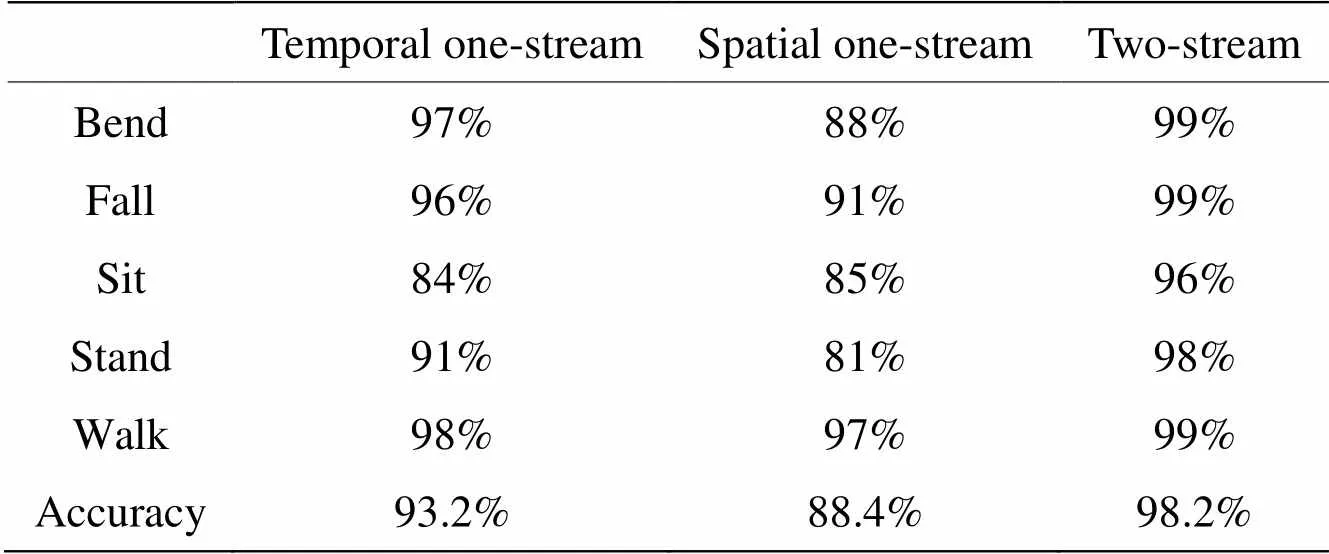
表2 單流、雙流CNN識別準確率
由表2可以發現,對于采集的數據,雙流CNN的準確率較單流CNN網絡有了較高的提升,彎腰、行走和摔倒動作準確率均達到99%,由圖9的混淆矩陣圖可以發現,彎腰動作有1個測試樣本錯判成了站起,摔倒動作有1個測試樣本錯判成了彎腰,行走動作有1個測試樣本錯判成了摔倒,且由于傳感器放置位置的原因,在坐下和站起的時間數據二維成像圖中可以發現,兩種動作較大的差別僅在9幀數據的中間2幀中,其他幀數據的差別很小,而在空間數據的構建過程中,溫度值得到了疊加,呈現出的兩個動作變化的趨勢差別較為細微,所以相比于其他的動作來說,坐下有4個測試樣本錯判為站起,而站起有2個測試樣本錯判為坐下,誤判率較高。
為了進一步驗證模型性能,將數據在本文模型的結果與文獻[14]提出的原始雙流CNN模型、在ImageNet上預訓練的VGG19[17]和ResNet[19]這兩種模型上進行遷移學習的表現結果進行對比。預訓練的VGG和ResNet網絡輸入為3通道,輸出類型也與本文類別不同,所以僅僅改變了第一層卷積層輸入通道為1,以及最后的輸出層為5。除此之外,還將本文結果與文獻[6]以及文獻[7]提出的兩種人工設計特征方法的識別結果進行了對比,結果如表3所示。
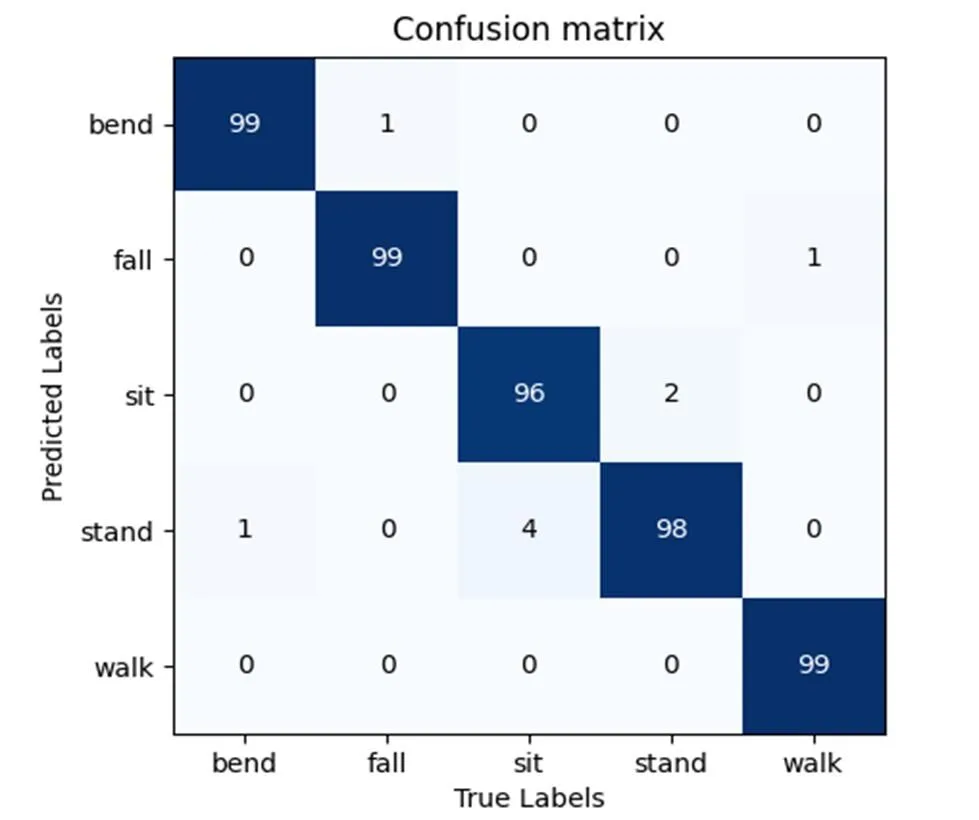
圖9 雙流CNN混淆矩陣圖
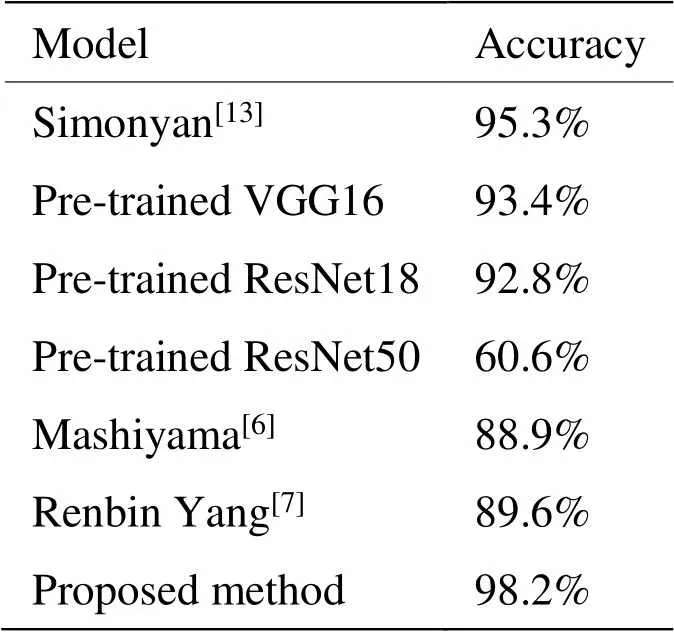
表3 不同網絡與方法結果對比
由表3可以看出,采集的數據在本文模型上有著較高的識別率,由于空間數據的尺寸較小,層數較深的網絡模型最終的識別準確率反而降低。相比于文獻[6]和文獻[7]兩種人工設計特征的傳統方法,本文提出的深度學習方法的識別率有了較高的提升。經過以上的實驗對比充分說明本文所提出的雙流CNN模型能夠較好地區分所采集的5種動作,達到了實驗設計初期的要求。
5 結論
本文針對通過低分辨率紅外傳感器采集的溫度數據提出一種基于雙流CNN的人體動作識別方法。不同于常見深度學習方法中以圖像的形式作為輸入,本文方法以原始溫度數據作為輸入。采用背景減除法提取前景,基于奈曼-皮爾遜準則確定最佳判決閾值,減少了虛警率,疊加運動幀內的前景數據,將得到的累計溫度矩陣作為空間數據。將代表動作整體過程的9幀數據,按照時序順序拼接得到192×240的溫度數據矩陣作為時間數據。采用數據增強的方式提高樣本的多樣性,改進了原始的雙流CNN網絡結構,調整超參數,最終通過加權融合的方式融合時空特征得到最終輸出的結果。結果表明在本文采用的數據上,5種動作平均識別準確率為98.2%,相比于其他網絡及人工設計特征方法準確率有了較高的提升,其中彎腰、摔倒和行走這3個動作準確率均達99%。由于傳感器放置位置的原因,相較與其他動作,站起和坐下這兩種易錯分的動作的誤判率還是很高。未來,可采用多個紅外傳感器從多角度采集數據,進一步提升這兩種動作的識別準確率。
[1] 張艷梅, 馬曉霞, 赫繼梅, 等. 失能老人跌倒的影響因素及長期照護服務需求[J].中國老年學雜志, 2019, 39(17): 4355-4357.
ZHANG Yanmei, MA Xiaoxia, HE Jimei, et al. Influencing factors of falls and demand for long-term care services in the disabled elderly[J]., 2019, 39(17): 4355-4357.
[2] Hsieh Chungyang, LIN Weiyang. Video-based human action and hand gesture recognition by fusing factored matrices of dual tensors[J]., 2017, 76(6): 7575-7594.
[3] 王玉坤, 高煒欣, 王征, 等. 基于加速度傳感器的人體姿態實時識別[J].計算機工程與設計, 2016, 37(11): 3092-3096.
WANG Yukun, GAO Weixin, WANG Zheng, et al. Real-time human activity pattern recognition based on acceleration[J]., 2016, 37(11): 3092-3096.
[4] 杜英魁, 姚俊豪, 劉鑫, 等. 基于電阻式薄膜壓力傳感器組的人體坐姿感知終端[J].傳感器與微系統, 2020, 39(1):78-81.
DU Yingkui, YAO Junhao, LIU Xin, et al. Human body sitting posture sensing terminal based on resistive thin film pressure sensor groups[J]., 2020, 39(1): 78-81.
[5] Kobiyama Yuta, ZHAO Qiangfu,Omomo Kazuk, et al. Analyzing correlation of resident activities based on infrared sensors[C]//, 2015: 1-6.
[6] Mashiyama S, HONG J, Ohtsuki T. Activity recognition using low resolution infrared array senso[C]//, 2015: 495-500.
[7] 楊任兵, 程文播, 錢慶, 等. 紅外圖像中基于多特征提取的跌倒檢測算法研究[J]. 紅外技術, 2017, 39(12): 1131-1138.
YANG Renbin, CHEN Wenbo, QIAN Qing, et al. Fall detection algorithm based on multi feature extraction in infrared image[J]., 2017, 39(12): 1131-1138.
[8] 張昱彤, 翟旭平, 汪靜. 一種基于低分辨紅外傳感器的動作識別方法[J]. 紅外技術, 2022, 44(1): 47-53.
ZHANG Yutong, ZHAI Xuping, WANG Jing. Activity recognition approach using a low-resolution infrared sensor[J]., 2022, 44(1): 47-53.
[9] Akula A , Shah A K , Ghosh R . Deep learning approach for human action recognition in infrared images[J]., 2018, 50(8): 146-154.
[10] 王召軍, 許志猛. 基于低分辨率紅外陣列傳感器的人體身份和動作識別[J]. 電氣技術, 2019, 20(11): 6-10, 26.
WANG Zhaojun, XU Zhimeng. Human identity and motion recognition based on low resolution infrared array sensor[J]., 2019, 20(11): 6-10,26.
[11] Takayuki Kawashima, Yasutomo Kawanishi, IchiroIde Hiroshi Murase. Action recognition from extremely low-resolution thermal image sequence[C]//, 2017: 1-6, Doi: 10.1109/AVSS.2017.8078497.
[12] FAN Xiuyi, ZHANG Huiguo, LEUNG Cyril, et al. Robust unobtrusive fall detection using infrared array sensor[J].(MFI), 2017, 5(4): 194-199.
[13] Polla F, Laurent H, Emile B. Action recognition from low-resolution infrared sensor for indoor use: a comparative study between deep learning and classical approaches[C]// 2019 20th(MDM), 2019: 409-414.
[14] Simonyan K, Zisserman A. Two-stream convolutional networks for action recognition in videos[J]., 2014, 1(4): 568-576.
[15] Feichtenhofer C, Pinz A, Zisserman A. Convolutional two-stream network fusion for video action recognition[C]//, 2016: 1933-1941.
[16] Tro?mova A A, Masciadri A, Veronese F, et al. Salice, indoor human detection based on thermal array sensor data and adaptive background estimation[J]., 2017, 5(4): 16-28.
[17] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[C]//, 2015: 1-14.
[18] WANG L, ZANG J, ZHANG Q, et al. Action recognition by an attention-aware temporal weighted convolutional neural network[J]., 2018, 18(7):1979.
[19] HE K, ZHANG X, Ren S, et al. Deep residual learning for image recognition[C]//, 2016: 770-778. Doi: 10.1109/CVPR.2016.90.
Deep Learning Method for Action Recognition Based on Low Resolution Infrared Sensors
ZHANG Yutong1,ZHAI Xuping1,NIE Hong2
(1. Key Laboratory of Specialty Fiber Optics and Optical Access Networks, Shanghai University, Shanghai 200444, China; 2. Department of Technology, University of Northern Iowa, Cedar Falls 50614-0507, USA)
In recent years, action recognition has become a popular research topic in the field of computer vision. In contrast to research on video or images, this study proposes a two-stream convolution neural network method based on temperature data collected by a low-resolution infrared sensor. The spatial and temporal data were input into the two-stream convolution neural network in the form of collected temperature data, and the class scores of the spatial and temporal stream networks were late weighted and merged to obtain the final action category. The results indicate that the average accuracy of recognition can reach 98.2% on the manually collected dataset and 99% for bending, falling, and walking actions, indicating that the proposed net can recognize actions effectively.
action recognition, two-stream CNN, low resolution infrared sensor, deep learning
TP319.4
A
1001-8891(2022)03-0286-08
2021-04-21;
2021-06-02.
張昱彤(1996-),男,江蘇鹽城人,碩士研究生,主要從事基于紅外圖像的人體動作識別算法研究工作,E-mail:zyt164819285@163.com。
猜你喜歡
作文周刊·小學一年級版(2022年16期)2022-05-07 11:28:30
作文周刊·小學一年級版(2021年8期)2021-07-07 11:00:47
動漫界·幼教365(大班)(2021年4期)2021-05-23 21:33:16
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文周刊·小學一年級版(2016年28期)2017-06-03 00:28:49
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
少兒科學周刊·少年版(2015年4期)2015-07-07 20:56:37
電影故事(2015年30期)2015-02-27 09:03:12
七彩語文·低年級(2014年10期)2015-01-14 14:46:27
