改進深度Q網絡的無人車換道決策算法研究
2022-04-08 03:43:04張鑫辰劉元盛謝龍洋
計算機工程與應用 2022年7期
張鑫辰,張 軍,劉元盛,路 銘,謝龍洋
1.北京聯合大學 北京市信息服務工程重點實驗室,北京 100101
2.北京聯合大學 機器人學院,北京 100101
3.北京聯合大學 應用科技學院,北京 100101
無人駕駛技術可以使人們的出行更加方便、安全,同時也可以減少因人為因素導致的交通事故。而無人車換道決策問題是無人駕駛技術中的重要問題之一[1],因此,如何在保證安全的前提下使無人車更有效率的行駛成為了研究者聚焦的重點[2]。目前,無人車換道決策算法主要分為兩部分:基于規則的算法和基于機器學習的算法。基于規則的換道決策算法模型主要有間隙接受模型[3]、勢場模型[4-5]、模糊邏輯模型[6]等,這些算法較基于機器學習的算法相比,泛化能力較弱,且往往得到二元的換道決策結果(換道、不換道),無法處理較為復雜和隨機的動態道路場景中的問題。
針對基于規則換道決策算法存在的不足,基于機器學習的算法被逐漸應用于無人車換道決策的研究中。文獻[7-8]使用支持向量機將數據集中無人車和無人車周圍的環境車的車輛參數作為模型輸入,最終對無人車的換道行為決策結果進行分類,這種方法雖然可以解決在高維的數據下的輸入問題,但是由于數據量較大,算法的時間復雜度較高,導致效率較低。文獻[9]使用隨機森林和決策樹對數據集進行分析,并分別輸出了直行和換道的決策結果,然而這種方法需要收集車輛駕駛員的標簽數據,這種標簽數據的采集十分困難并且數據中的噪聲會直接影響分類結果的準確性。當使用以上監督學習算法來解決無人車換道決策問題時,往往需要大規模數據集作為算法輸入,導致算法訓練時間較長,同時在訓練時將數據集的標簽數據當作“真值”,使得算法缺乏探索能力。文獻[10]使用進化策略(evolution strategy,ES)對無人車換道決策算法進行研究,提出了基于ES的神經網絡算法,使用并輸出了保持原道,左換道,右換道三種結果。此方法雖然解決了梯度下降法易使模型收斂到局部最優的問題,但是優化速度較慢,計算成本較高。上述算法與基于強化學習的換道決策方法相比,往往需要大量的數據集作為輸入用于模型訓練,同時數據集中的噪聲會直接影響模型訓練的準確性,最終影響模型的測試結果。針對上述問題,研究者提出基于強化學習的無人車換道決策算法。該方法現已成功應用在人工智能領域中,例如Atari游戲[11-12]、圍棋比賽[13]、機器人路徑規劃[14]、無人車車道保持問題[15]等。文獻[16]使用Q-learning對高速公路車輛的換道決策進行研究,但該研究僅考慮簡單的雙車道場景,且當輸入狀態維數過高時,該算法會消耗大量時間,計算效率很低。文獻[17-19]使用DQN對高速公路場景中的車輛建模,并對決策成功率和平均獎勵等評價指標進行了分析,但由于DQN存在過度估計的問題,使得估計的Q值大于真實Q值,使得在模型測試時不能得到準確的結果,算法往往會收斂到局部最優,同時DQN每次都是從經驗回放單元中等概率抽樣,導致一些重要的經驗樣本被忽略,進而降低了算法的收斂速度和網絡參數更新的效率。
為了更好地解決無人車換道決策問題,本文提出了一種基于改進深度Q網絡的無人車換道決策模型。首先將算法的狀態值輸入到兩個結構相同的神經網絡中,并分別計算出估計值和目標值,以此來減少經驗樣本之間的相關性,進而提升算法的收斂性;然后將隱藏層輸出的無人車狀態信息同時輸入到狀態價值函數流和動作優勢函數流中,更好地平衡了無人車狀態與動作的關系;最后采用PER的方式從經驗回放單元中抽取經驗樣本,以此提升樣本的利用率,使得無人車更好地理解周圍環境變化,進而得到更加合理的換道決策結果。
1 改進深度Q網絡的換道決策模型
1.1 雙深度Q網絡
雙深度Q網絡[20](double deep Q network,DDQN)針對DQN過度估計的問題,將動作的選擇和評估進行解耦。首先通過參數為w的主網絡選擇最大的Q值對應的動作,再使用參數為w′的目標網絡計算此動作所對應的目標值,進而對選擇的動作進行評估,再根據評估值Q(s j-1,a j-1,w)和目標值計算損失函數L j(w),并通過誤差反向傳遞的方式更新主網絡的參數w,如公式(1)和(2)所示:
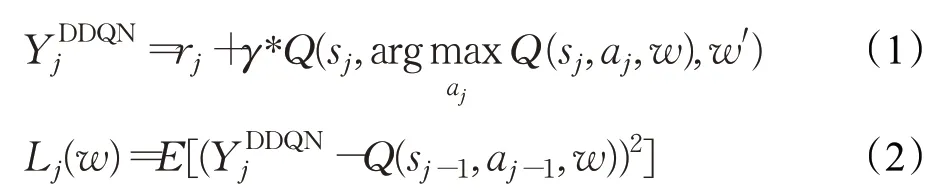
其中為目標值,Q(s j-1,a j-1,w)為評估值,γ為衰減因子,r j為獎勵值,損失函數L j(w)根據評估值和目標值的均方誤差(mean square error,MSE)計算得到。
1.2 競爭網絡結構
基于競爭結構的深度Q網絡(dueling deep Q network,dueling DQN)[21]和基于競爭結構的雙深度Q網絡(dueling double deep Q network,dueling DDQN)分別從DQN和DDQN的基礎上在主網絡和目標網絡中加入競爭網絡結構(dueling network architecture),以便更準確的估計Q值,上述兩個模型的主網絡結構如圖1所示。
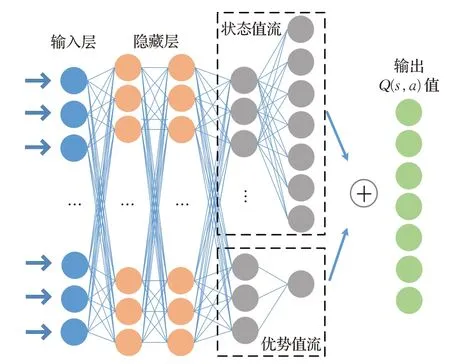
圖1 競爭網絡結構Fig.1 Dueling network structure
無人車在行駛過程中從周圍環境獲取狀態值作為網絡輸入,通過隱藏層的狀態信息分別被輸入到狀態價值函數流和動作優勢函數流中進行進一步的數據處理,然后將兩個函數流的輸出相加,最后輸出Q(s,a)的值。Q(s,a)的計算方式如公式(3)所示:

其中Q(s,a|θ,α,β)為輸出的Q值,V(s|θ,β)為狀態價值函數,A(s,a|θ,α)為動作優勢函數,θ為公共隱藏層的網絡參數,α為動作優勢網絡的參數,β為狀態價值網絡的參數,a′為所有可能采取的動作,average則是對所有動作優勢函數取均值。
1.3 優先級經驗回放
在無人車與環境不斷交互的過程中,經驗樣本被不斷的存儲到經驗回放單元中用于模型的訓練,但不同經驗樣本之間的重要性是不同的,隨著經驗回放單元中樣本的不斷更新,如果采取均勻隨機取樣的方式從經驗回放單元中抽取小批量樣本作為模型輸入,那么一些重要性較高的經驗樣本就無法被充分利用甚至被直接覆蓋,導致模型訓練效率降低。為提升模型的訓練效率,使用一種優先級經驗回放[22]的方式從經驗回放單元中抽取樣本,以此增加重要性較高的樣本被抽取的概率。即用δj表示樣本j的時間差分誤差(temporal differenceerror,TD-error),并以此來衡量每個經驗樣本的重要性,如公式(4)所示:

其中p j為樣本j的優先級,ε為很小的正常數進而保證TD-error幾乎為0的樣本也有較低的概率被抽取。P(j)為樣本j的優先級權重,α為經驗回放時優先級權重所占的比例,若α為0,則采用均勻隨機抽樣,否則根據歸一化后的權重w j抽樣。如公式(5)~(7)所示,N為經驗回放單元的大小,β為抽樣權重系數,取值范圍為β∈[0,1]。在抽取樣本時通過采用優先級經驗回放的方式,提升了主網絡誤差反向傳遞時更新參數的效率以及網絡的收斂速度。
1.4 改進的深度Q網絡
為了使無人車在決策過程中得到更優的駕駛策略,使用改進的深度Q網絡建立換道決策算法。此算法先將DDQN與競爭結構結合,并用于主網絡和目標網絡中來解決DQN過度估計問題,同時更好地平衡了狀態價值函數和動作優勢函數的關系。然后采用優先級經驗回放的方式抽取小批量數據作為模型輸入,進一步提升了TD-error的絕對值較大的樣本利用效率。基于改進深度Q網絡的無人車換道決策算法結構圖如圖2所示,在無人車的行駛過程中,首先無人車獲取自身以及周圍車輛的參數信息作為當前時刻的狀態值,同時將動作值、無人車與環境交互得到的獎勵值、以及下一時刻的狀態值作為一個元組,即(s,a,r,s′),存儲到經驗回放單元D中,然后使用優先級經驗回放的方式進行抽取樣本,并將狀態值分別輸入到主網絡和目標網絡中,根據兩個網絡的輸出結果以及獎勵值r對損失函數進行計算,進而更新主網絡的網絡參數,直到算法完成迭代。
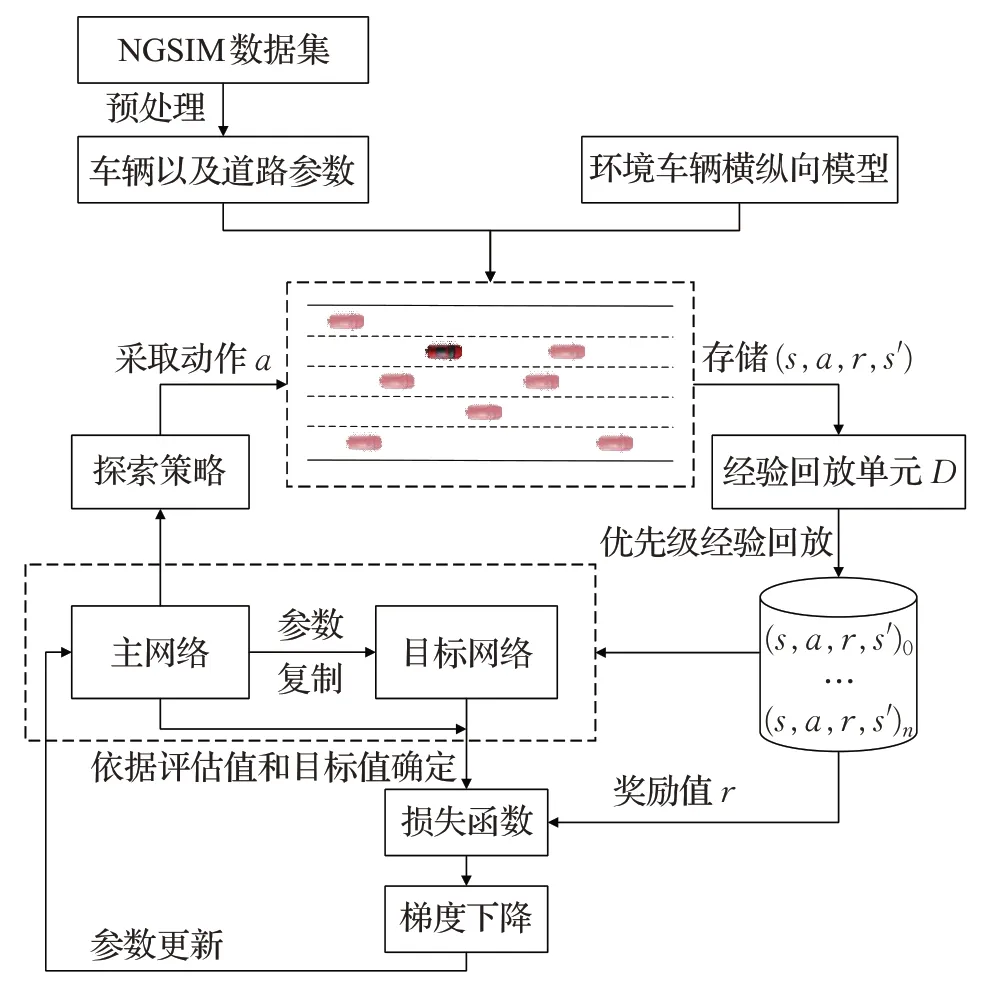
圖2 改進深度Q網絡的無人車換道決策算法結構Fig.2 Structure diagram of autonomous vehicle lane change strategy algorithm based on improved deep Q network
2 實驗場景搭建
實驗場景搭建分為數據預處理和環境車輛模型搭建兩部分。如圖3所示,通過數據預處理對道路環境中的車流量、車輛速度及初速度范圍、車輛初始位置進行提取,同時結合環境車輛模型,對真實道路環境進行還原,并將此場景作為算法的訓練和測試場景。
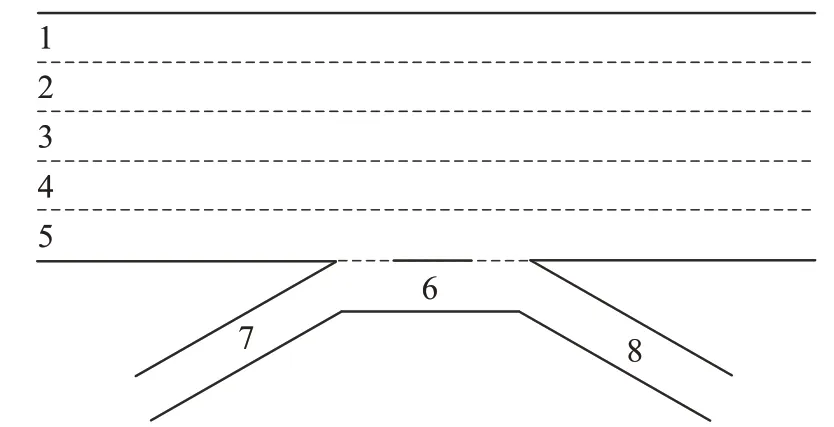
圖3 US-101高速場景Fig.3 US-101 highway scene
2.1 數據預處理
實驗中選用NGSIM數據集中US-101高速公路的車輛數據進行車輛及道路參數的提取。US-101高速公路場景如圖3所示,高速路全長約640 m,共有8條車道,其中1~5號車道為主車道,6號車道為輔路道,7、8號車道分別為車流匯入車道和匯出車道。實驗中選用主車道(1~5號)中的車輛數據搭建5車道道路實驗場景。
首先對主車道車輛數據進行預處理,剔除轎車外的其他車輛類型數據,并篩選出主車道前300 m的車輛數據,該段數據對應的道路中的車流量適中。由于5號車道中的車輛受6~8號車道內車輛匯入和匯出的影響,故分別統計1~4號車道的車輛與5號車道的車流量、車輛速度及初速度范圍、車輛初始位置等參數,以便更好地還原真實環境中的道路場景。統計后的車輛數據信息如表1所示,1~5車道車輛速度分布如圖4所示,車輛初速度分布如圖5所示。

表1 車輛數據信息Table 1 Information of vehicle data

圖4 車輛速度分布Fig.4 Vehicle speed distribution
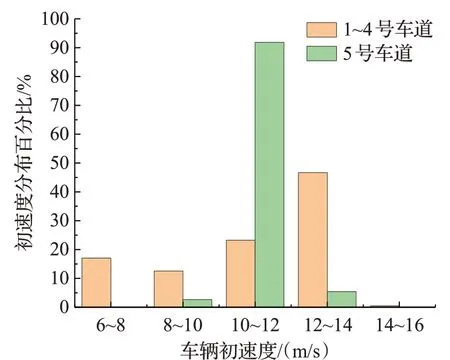
圖5 車輛初速度分布Fig.5 Initial vehicle speed distribution
根據表1可知,在900 s內,1~4號車道共有1 502輛車,即車流量約為每分鐘100輛;5號車道共有389輛車,即車流量約為每分鐘26輛。
根據圖4、5可知,1~4號車道的車輛速度范圍和初速度范圍主要分布在7~19 m/s和6~14 m/s,比例分別達到99.75%和99.51%;5號車道的車輛速度范圍和初速度范圍主要分布在1~19 m/s和10~12 m/s,比例分別達到99.98%和91.89%。為適應絕大多數車輛的駕駛規律,故使用上述車輛的初速度和速度范圍作為車輛仿真環境參數。車輛初始位置可通過數據集直接獲取。同時,對主車道車輛的長度寬度進行統計,統計結果為:長度為12 ft(約3.6 m),寬度為6 ft(約1.8 m)的車輛所占比例最大,故選用長3.6 m、寬1.8 m的車輛作為實驗仿真車輛。仿真車輛參數如表2所示。
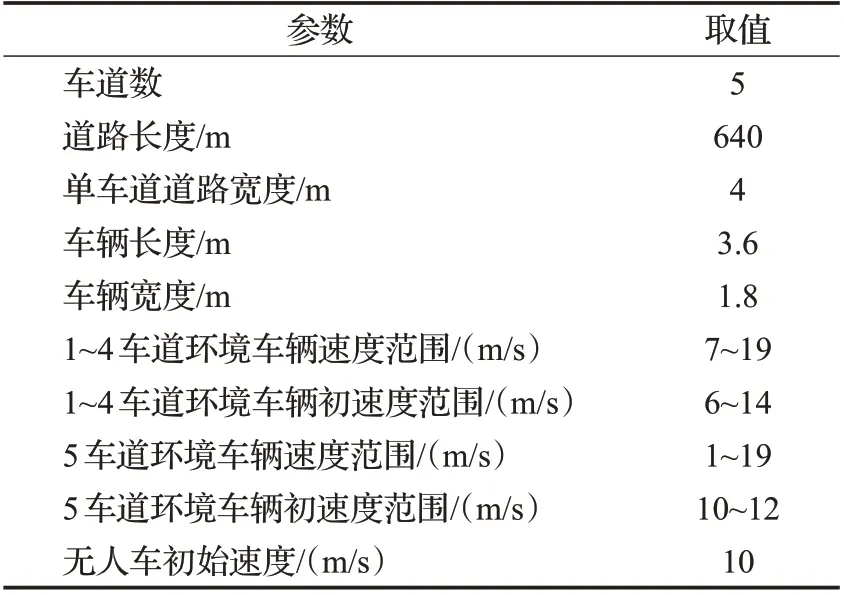
表2 仿真環境參數設定Table 2 Simulation environment parameters setting
2.2 環境車輛模型搭建
為了更好地模擬真實道路環境中車輛的駕駛行為,分別使用車輛橫向和縱向模型對實驗場景中的環境車輛進行建模。其中橫向模型采用MOBIL(minimizing overall braking induced by lane change)模型,使用此策略模型對環境車輛的換道行為進行建模,如公式(8)~(10)所示:


上述公式中,Δa為加速度增益,alc、aold、anew分別為執行換道車輛、換道前原車道的后方車輛以及目標車道后方車輛的加速度,alc'、aold'、anew'分別為以上換道車輛換道后的加速度,p為禮貌因子,該參數描述了環境車輛駕駛的激進程度,取值范圍為0~1,b s為保證安全的最大減速度,Δath為決策閾值。若anew'大于-b s,同時加速度增益Δa大于決策閾值Δath時,環境車輛進行換道操作。
車輛縱向模型采用IDM(intelligent driver model),此模型描述了環境車輛的跟車行為,如公式(11)和(12)所示:

上述公式中,d×(v,Δv)為最小期望間距,d0為最小安全間距,v為車輛當前速度值T為期望安全時距,Δv為同車道當前車輛與前車的速度差,amax為期望最大加速度值,b為期望減速度值,vd為期望速度值,δ為加速度指數。
3 實驗結果與分析
3.1 實驗環境與參數設定
實驗中環境采用Python3.7語言作為編程語言,使用gym庫創建實驗場景,神經網絡框架使用PyTorch1.4.0;計算機配置為:顯卡NVIDIA GTX1060,操作系統為Ubuntu16.04,處理器為i7-8750H,內存為16 GB。
設定訓練最大回合數為10 000,單回合最大步長為30,道路環境刷新周期為1 s,同時根據上一章節2.1中主車道車流量信息,可知1~4車道的單回合車流量為每回合50輛,5車道的單回合車流量為每回合13輛,單回合終止條件為無人車單回合執行步數達到最大或無人車與環境車發生碰撞,且在實驗過程中設定無人車均保持在可行使區域內行駛。算法參數設定如表3所示。

表3 算法參數設定Table 3 Algorithm parameters setting
表3中的衰減因子γ描述的是未來得到的獎勵值對當前狀態的影響,通過分析實驗所有回合中累計步數的分布確定當γ=0.98時,算法的收斂性最好,同時平均獎勵值達到最大。學習率的選取通過網絡誤差和網絡的收斂速度確定,實驗結果顯示當學習率為2.5×10-4時網絡的收斂速度最快(算法的平均獎勵值在訓練2 400回合左右基本穩定),同時算法的成功率最高。記憶庫容量和批尺寸的大小通過獲得的平均獎勵值的網絡收斂速度確定,記憶庫容量的大小會對網絡參數更新效率產生影響;而在批尺寸的大小選取方面:若采取較大的批尺寸則算法容易收斂到局部最小值,若較小時則不利于算法的收斂。實驗中分別采用了批尺寸為16、32、64這3個超參數分別進行網絡的訓練,結果表明當記憶庫容量大小為8×104,批尺寸為32時,算法的收斂速度最快,同時獲得的平均獎勵值最高。優先級權重占比α用來確定從經驗回放單元中抽取樣本時樣本優先級所占的比例,而抽樣權重β用來修正優先級回放所帶來的誤差,實驗結果顯示當α=0.8,β=0.5時,算法的魯棒性最好,此超參數組合增加了重要性樣本被采樣的概率,同時模型的魯棒性也得到提升。
3.2 實驗約束條件設定
結合具體的換道決策場景,分別設定狀態空間、動作空間以及獎勵函數如下所示。
狀態空間:狀態空間S描述了無人車與周圍環境車輛的駕駛行為信息,以無人車和無人車感知范圍內最近的6輛環境車狀態值的集合作為狀態空間,具體定義如公式(13)所示:

其中vhost為無人車的速度,s1~s6為無人車周圍環境車輛的狀態值,s={exist,x,y,v x,v y},exist表示為是否存在此環境車輛,若此車存在,則exist=1,否則exist=0。x為無人車相對于此環境車的橫向距離,y為無人車相對于此環境車的縱向距離,v x為無人車相對于此環境車的橫向速度,v y為無人車相對于此環境車的縱向速度。
動作空間:動作空間描述了無人車行駛過程中可以采取的動作,具體描述如表4所示。

表4 動作空間表示Table 4 Action space representation
獎勵函數:為使無人車學習到最佳的換道決策策略,獎勵函數定義如下所示。
若無人車與環境車發生碰撞,則設定碰撞懲罰函數:

設定速度獎勵函數:
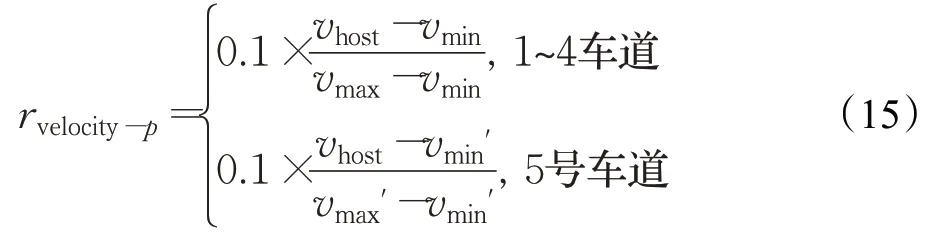
其中vhost為無人車速度,vmax和vmin分別為1~4號車道的最高速度(19 m/s)和最低速度(7 m/s),vmax'和vmin'分別為5號車道的最高速度(19 m/s)和最低速度(1 m/s),即若無人車行駛在1~4車道,則取1~4號車道對應的速度獎勵值;若無人車行駛在5車道,則取5號車道對應的速度獎勵值。
為避免無人車在行駛過程中頻繁的變更車道,設定換道懲罰函數:

如果無人車在單個步長內未發生碰撞,則設定單步獎勵函數:

如果無人車在整回合內未發生碰撞,則設定回合獎勵函數:

單回合總獎勵函數R為:

上述公式中,T為單回合執行總步數,p為執行步數。
3.3 算法訓練與分析
分別使用DQN、DDQN、Dueling DDQN與本文算法進行實驗對比,且4種算法的狀態空間、動作空間、獎勵函數以及實驗參數均保持一致,訓練過程中設定環境車輛橫向模型參數的禮貌因子p=1。通過分析決策成功率、平均獎勵、平均累計步數來描述模型訓練結果,4種算法訓練的結果隨回合數變化趨勢如圖6~8以及表5所示。
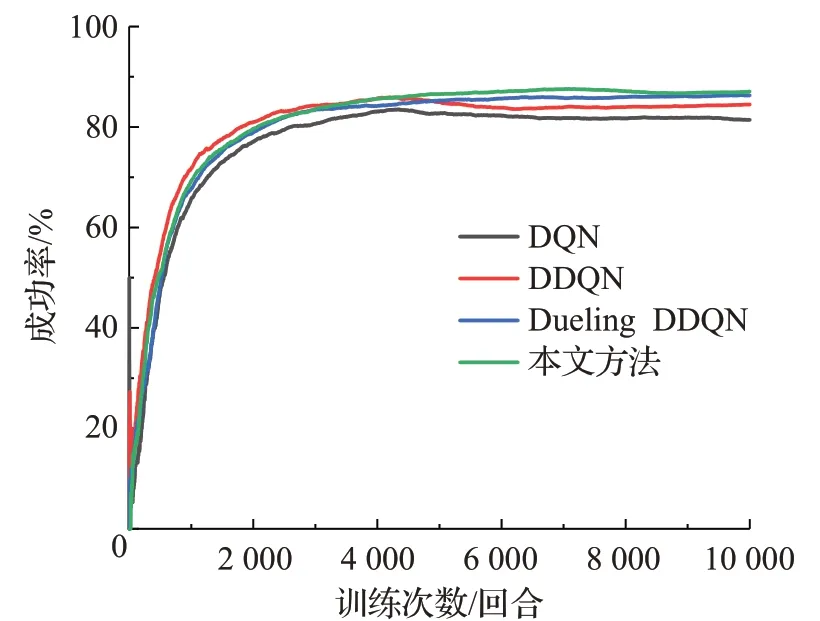
圖6 訓練過程中各算法的決策成功率對比Fig.6 Comparison of strategy success rate of each algorithm during training process
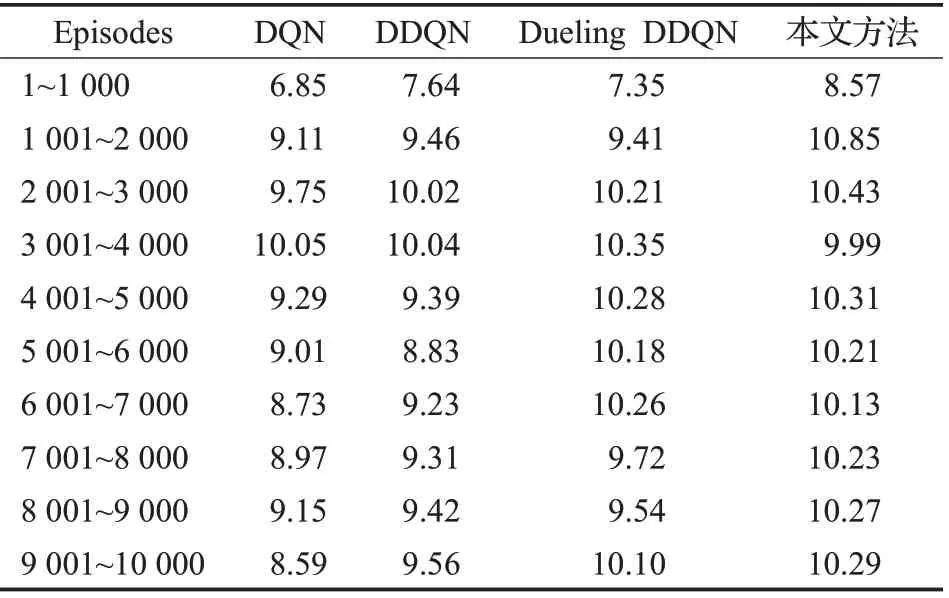
表5 訓練過程中各算法平均獎勵分布對比Table 5 Comparison of average reward distribution of each algorithm training process
由圖6可知,在算法訓練開始階段,4種算法的成功率不斷增加,訓練10 000回合后,DQN、DDQN、Dueling DDQN、本文方法的成功率依次為:81.43%、84.48%、86.30%、87.09%。本文方法在訓練過程中的決策成功率更高。
結合圖7和表4可知:在算法訓練過程中所獲得的平均獎勵方面:本文方法在訓練結束后的得到的總平均獎勵最高,為10.14,且平均獎勵值在2 400回合左右基本穩定,而其他方法均在5 500回合后逐漸趨于穩定狀態,算法穩定時的回合數約為本文方法的2.29倍。同時該方法在1 001~2 000回合內的平均獎勵達到最高,為10.85,Dueling DDQN、DDQN、DQN依次降低,分別為9.74、9.29、8.95,且平均獎勵峰值均分布在3 001~4 000回合范圍內。由此可見,本文方法可以在更少的訓練回合數內完成對算法的訓練并獲得更高的平均獎勵值。同時由于改進的深度Q網絡在經驗回放時提高了重要程度較高的樣本的利用率,增加這些樣本的抽樣概率。本文方法與DQN、DDQN、Dueling DDQN相比提升了網絡的收斂速度和參數更新的效率,同時提高了智能體的學習速度。

圖7 訓練過程中各算法的平均獎勵對比Fig.7 Comparison of average reward of each algorithm during training process
由圖8可知,在1 000回合訓練后,本文方法的平均累計步數均高于DQN等網絡模型,說明本文方法單回合執行步數最高,同時結合圖6可知,本文方法在保持決策成功率最高的同時,平均累計步數較DQN、DDQN、Dueling DDQN分別高出3.14、2.17、1.60,由此說明本文方法具有更好的學習能力和更強的適應性。
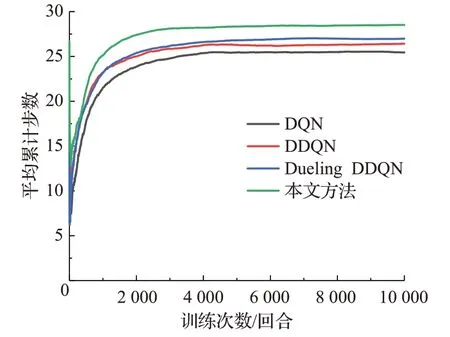
圖8 訓練過程中各算法的平均累計步數對比Fig.8 Comparison of average cumulative steps of each algorithm during training process
3.4 算法測試與分析
針對不同道路場景中環境車輛,通過改變環境車輛車流量,以及環境車輛橫向模型中的禮貌因子p,進而搭建車輛環境不同的實驗場景,設定測試回合數為1 000,同時保持其他仿真環境參數和網絡參數不變。其中p∈[0,1],該參數越接近0說明環境車輛駕駛風格越激進。通過改變上述兩個參數,設定兩個道路環境不同的測試場景,具體描述如下所示。
3.4.1 算法測試場景一
測試場景一使用與算法訓練時相同的場景,即1~4車道和5車道的單回合車流量分別為50輛/回合,和13輛/回合,禮貌因子p=1。4種算法在場景一中測試成功率和平均獎勵如圖9、10所示,測試1 000回合后的結果如表6、7所示。

圖9 場景一測試過程中各算法的決策成功率對比Fig.9 Comparison of strategy success rate of each algorithm during test processin scenario one
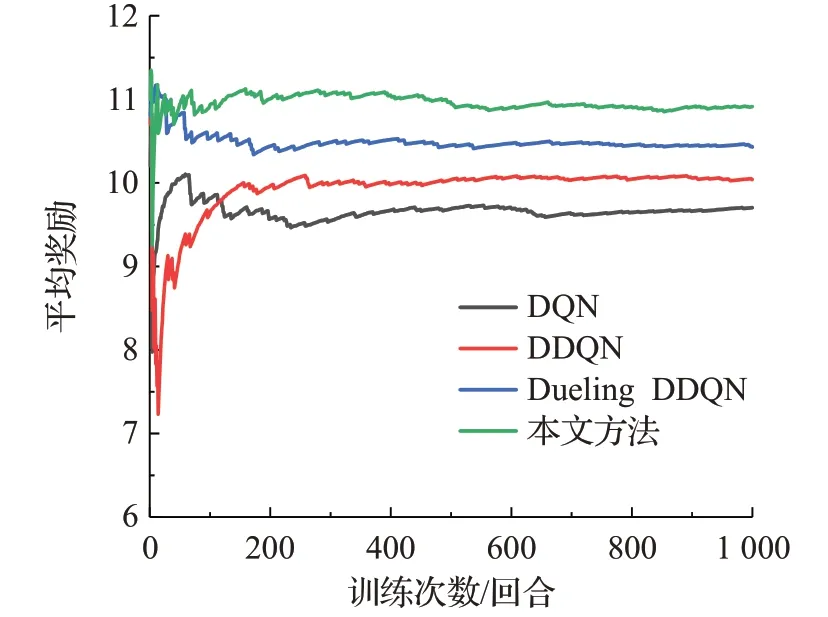
圖10 場景一測試過程中各算法的平均獎勵對比Fig.10 Comparison of average reward of each algorithm during test processin scenario one
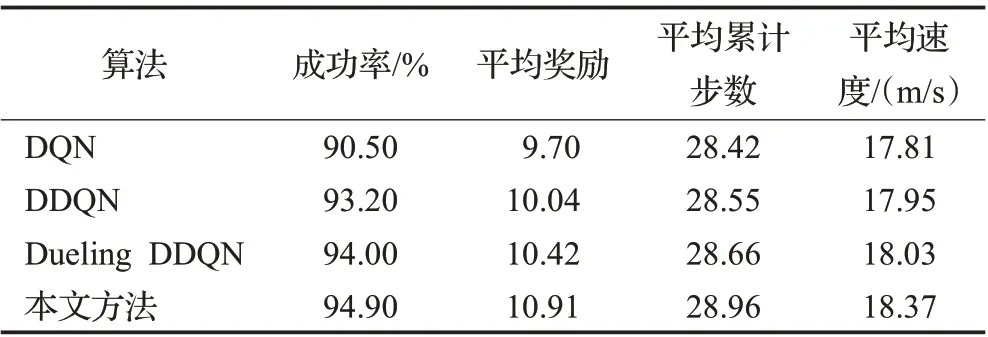
表6 場景一各算法測試結果對比Table 6 Comparison of test results of each algorithm in scenario one
由圖9、10和表6可知,在場景一的測試過程中,本文方法較Dueling DDQN、DDQN、DQN在成功率方面分別高出0.9、1.7、4.4個百分點,在平均獎勵、平均累計步數、平均速度方面本文方法也均高于其他方法。4種算法在測試1 000回合中的成功次數分別是:DQN為905次、DDQN為932次、Dueling DDQN為940次、本文方法為949次;同時結合表7分析可得:在各算法測試成功回合中,本文方法的單回合獎勵值高于11.3的回合所占百分比最高,為78.29%。而單回合獎勵值低于11.3的原因是由于無人車在一段時間內為避免碰撞而保守行駛,使得在單回合內獲得的獎勵值較低。由此說明本文方法可以更好地根據經驗回放單元中的經驗樣本來理解測試環境中車輛的狀態變化,在保證決策成功率的前提下減少了保守行駛的回合數,使得無人車獲得更優的決策策略。
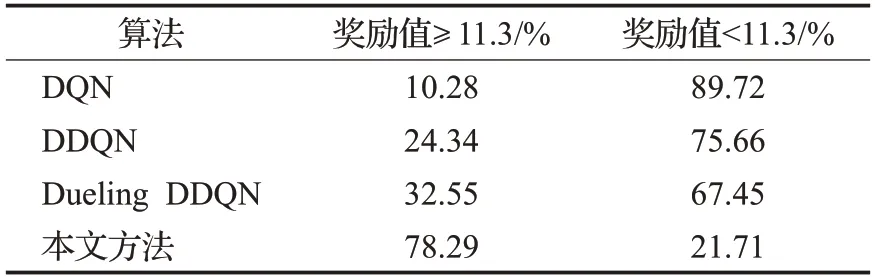
表7 場景一各算法成功回合中獎勵值分布比例Table 7 Proportion of reward value distribution in successful rounds of each algorithm in scenario one
3.4.2 算法測試場景二
測試場景二設定禮貌因子p=0.4,環境車輛的車流量采用US-101道路中車流量較大的部分,即1~4號車道和5號車道的車流量分別約為126輛/min和48輛/min,即單回合車流量分別為63輛/回合和24輛/回合。4種算法在場景二中測試成功率和平均獎勵如圖11、12所示,測試1 000回合后的結果如表8、9所示。
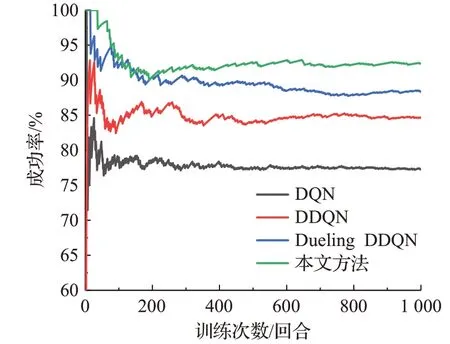
圖11 場景二測試過程中各算法的決策成功率對比Fig.11 Comparison of strategy success rate of each algorithm during test processin scenario two
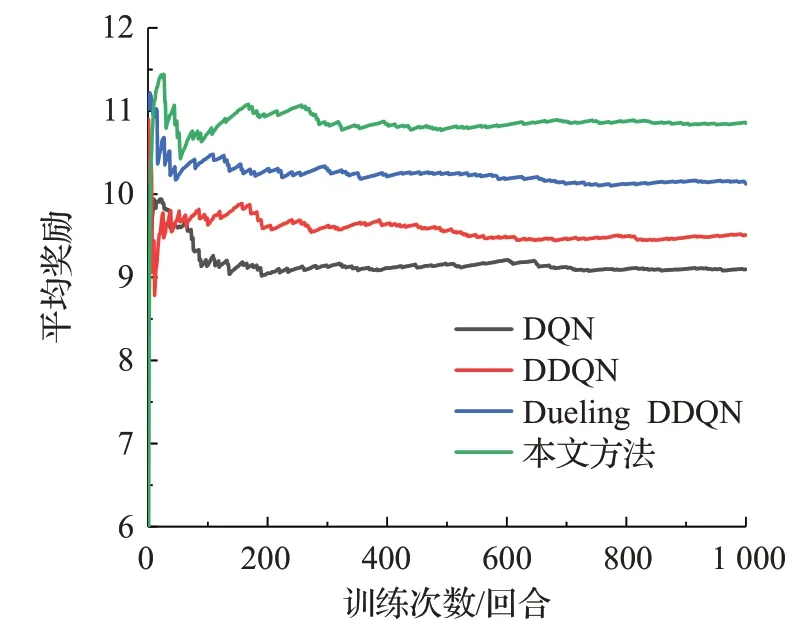
圖12 場景二測試過程中各算法的平均獎勵對比Fig.12 Comparison of average reward of each algorithm during test processin scenario two
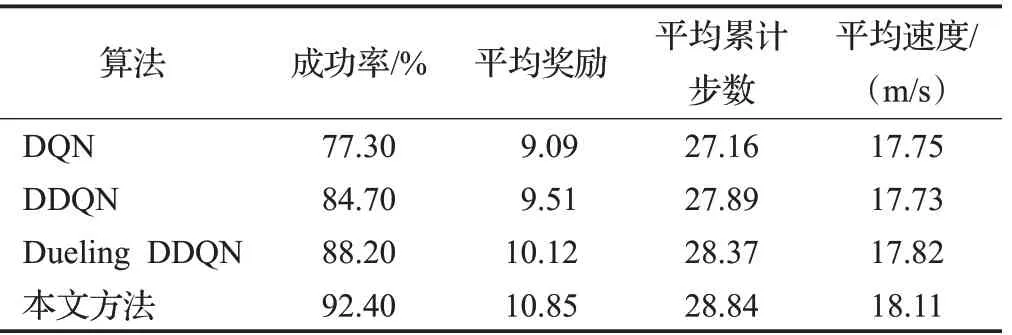
表8 場景二各算法測試結果對比Table 8 Comparison of test results of each algorithm in scenario two
結合圖11、12和表8分析可知,在場景二的測試過程中,本文方法較Dueling DDQN、DDQN、DQN在成功率方面分別高出4.2、7.7、15.1個百分點,在平均獎勵、平均累計步數、平均速度方面本文方法也均高于其他方法,且4種算法在測試1 000回合后的平均獎勵為10.85、10.12、9.51、9.09,與場景一中的測試結果相比,各算法的平均獎勵分別下降了0.06、0.30、0.53、0.63,成功率分別下降了2.5、5.8、8.5、13.2個百分點。其中DQN下降幅度最大,原因是DQN使用最大化的方法來計算目標值,這樣的計算方式往往使得算法得到次優的決策策略,同時DQN等概率的抽樣方式使得一些重要性較高的經驗樣本被忽略,從而降低了訓練過程中網絡參數的更新效率,最終導致DQN在更復雜的場景中的測試結果的成功率和平均獎勵較低。
由表9可知,在各算法發生碰撞的回合中,本文方法單回合執行步數小于10的回合數(單回合執行步數為30)所占比例最低,為6.58%,Dueling DDQN、DDQN、DQN依次升高,為16.10%、59.48%、66.08%。其中DQN和DDQN單回合執行步數小于10的比例分別是本文方法的10.04倍和9.04倍,由此可見,DDQN和DQN的碰撞相對集中發生測試過程的前三分之一階段,說明這兩種算法的適應性較差,無法根據測試過程中環境車輛的狀態變化做出最優的動作。

表9 場景二各算法碰撞回合中單回合步數分布比例Table 9 Proportion of reward value distribution in successful rounds of each algorithm in scenario two%
對比場景一和場景二的測試結果可知,4種算法的得到平均獎勵均有所下降,原因是隨著測試場景的復雜程度增加,導致無人車換道決策的成功率和平均速度的下降,同時無人車發生碰撞的次數增多,使得單回合內獲得的步數獎勵減少,最終導致平均獎勵的下降。
3.4.3 算法測試場景三
測試場景三設定禮貌因子p=0,環境車輛的車流量采用US-101道路中車流量最大的部分,即1~4號車道和5號車道的車流量分別約為144輛/min和64輛/min,即單回合車流量分別為72輛/回合和32輛/回合。4種算法在場景三中測試1 000回合后的結果如表10所示。
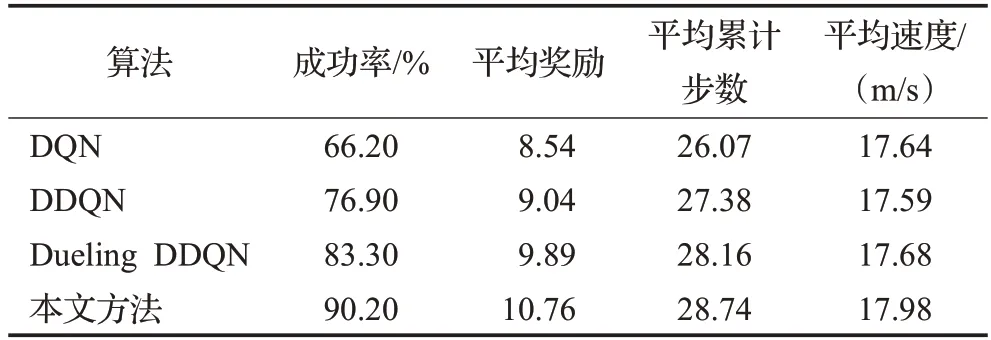
表10 場景三各算法測試結果對比Table 10 Comparison of test results of various algorithm in scenario three
由表10可知,在場景三的測試過程中,本文方法較Dueling DDQN、DDQN、DQN在成功率方面分別高出6.9、13.3、24.0個百分點,在平均獎勵、平均累計步數、平均速度方面本文方法也均高于其他方法,且4種算法在測試1 000回合后的平均獎勵為10.76、9.89、9.04、8.54,與場景二中的測試結果相比,各算法的平均獎勵分別下降了0.09、0.23、0.47、0.55,成功率分別下降了2.2、4.9、7.8、11.1個百分點。隨著測試場景環境車輛車流量的增大,場景的復雜程度增加,本文方法的成功率和平均獎勵下降幅度最小,說明該方法對于復雜環境的適應性更強,這是由于加入了優先級經驗回放的機制,使得重要性更高的樣本被抽取的概率增加,進而增加了算法訓練時的網絡參數的更新效率,同時競爭結構的存在使得該算法在更新主網絡參數時價值函數被優先更新,導致在當前狀態下所有的Q值均被更新,從而更準確地得到了每個動作所對應的Q值。
對比3種場景中各算法的測試結果,如表11所示。

表11 3種場景中各算法測試的平均結果對比Table 11 Comparison of average results of each algorithm test in three scenarios
由表11可知,在3種場景的平均測試成功率方面,本文方法最高,為92.50%,比Dueling DDQN、DDQN和DQN算法的分別高出4.0、7.6、14.5個百分點;在平均獎勵方面,本文方法最高,為10.84。由此說明,本文方法可以更好地理解外部環境狀態的變化,同時具有更好的魯棒性和更強的適用性。
4 結束語
針對傳統DQN在高速公路場景下的無人車換道決策中存在過估計且收斂速度較慢的問題,本文提出一種基于改進深度Q網絡的無人車換道決策模型。首先將得到的無人車與環境車的狀態值分別輸入到主網絡和目標網絡中,進而將動作的選擇和評估解耦,提高了網絡的穩定性,解決了網絡的過估計問題;然后在網絡中加入競爭結構,使模型對動作價值的估計更加準確;最后通過增加重要樣本被回放的概率,提升網絡的更新效率和收斂速度。實驗結果表明,相比于傳統DQN等算法,改進的深度Q網絡在訓練和測試的決策成功率、平均獎勵、平均累計步數方面上均有提升;測試結果也表明,該方法的魯棒性更強,在車流量更大、環境車輛駕駛風格更激進的測試場景中仍能保持92%以上的換道決策成功率。
雖然本文算法在不同場景的測試結果中均能保持較高的換道決策成功率,但只能應對離散的動作空間問題,接下來的研究將聚焦于使用Actor-Critic的強化學習方法,以此來應對連續動作空間中的無人車換道決策問題。
