基于深度強化學習的金融交易算法研究
2022-04-08 03:43:08祝玉坤邢春曉
計算機工程與應用 2022年7期
關鍵詞:動作
許 杰,祝玉坤,邢春曉
1.清華大學 五道口金融學院,北京 100084
2.清華大學 北京信息科學與技術國家研究中心,北京 100084
如何獲得經風險調整后的金融資產交易回報是現代金融關鍵研究熱點之一。1964年,提出了資本資產定價模型(capital asset pricing model,CAPM),指出回報只與系統性風險有關,投資組合的目標為消除非系統性風險,成為金融市場交易重要基礎理論。隨后,1970年提出了有效市場假說理論,認為價格完全反映了所有市場公開信息,任何股票技術分析是無效的。然而許多實際市場交易現象并非遵守有效市場假說理論,出現了如羊群效應、股權溢價之迷等一系列金融異象。傳統的金融交易方法主要基于價格預測方法,從影響證券價格變動的因子出發,分析研究證券市場的價格變動一般規律。但基于預測的方法存在以下挑戰:(1)金融時間序列一般是非平衡數據且噪聲大量存在,為了減少數據噪音和不確定性,通常手工抽取金融特征,難度較大且不全面。(2)變量因子間存在普遍的相關關系與多重共線性,導致權重參數估計失真。(3)由過去的時間序列生成的模型只能表明歷史發生的事實,不能完會解釋未來金融市場變化規律,模型樣本外泛化能力弱。(4)在傳統的預測方法中,當市場出現牛熊市轉換、動量轉換時,原有擬合模型可能不再匹配新數據。
近年來,人工智能呈爆發式發展,利用人工智能算法研究金融數據趨勢與規律,建立金融交易策略越來越普遍,其中比較典型是深度學習(deep learning,DL)方法、強化學習[1-2](reinforcement learning,RL)方法。深度學習具有端到端的表示能力,具有強大特征提取能力和非線性函數擬合能力,可以部分消除復雜內部邏輯設計,提高數據來源多樣性,主要應用于算法交易、風險管理、欺詐檢測、投資組合管理等領域。然而,使用深度學習預測股票價格或趨勢運動時,算法效果主要取決于預測準確度,容易出現過擬合現象,并且在存在交易成本的情況下,高預測準確度并不完全代表高最終收益率,未能捕捉到由于股票交易活動而引起的未來懲罰或獎勵回報[2-3]。
強化學習與心理學中的行為主義相類似,事先未給定數據以及數據標簽,具有探索-利用(explorationexploitation)特征。相比基于預測的方法,強化學習實現狀態空間到動作空間映射轉換,通過智能體與金融市場環境不斷實時交互學習策略,從市場反饋中不斷積累經驗,在抑制風險的同時最大化累積回報,與人類認知與思考進程一致,被應用于股票自動化交易、資產組合配置、債權的定價與套期保值等領域。但傳統強化學習方法存在感知狀態與提取特征能力不足、狀態空間與動作空間大小有限、不能捕捉前序時間序列特征等缺點。
融合了深度學習和強化學習的深度強化學習(deep reinforcement learning,DRL)在解決復雜序列決策問題上取得了顯著的成功,深度強化學習集成了深度學習感知能力和強化學習決策能力[4-5]。DRL具備非凸性質,能夠直接從高維原始數據中學習和控制策略,允許在一個整體中同時考慮價格預測和計算投資收益目標,擴大了策略函數的應用范圍,提高了數據驅動自監督學習能力,交易成本、市場流動性、投資者的風險厭惡程度等重要制約因素可以被隱式表達,不需要另外建立新的總體投資收益函數模型,降低了模型建立與訓練難度。主要應用領域有債權的定價和跨期套期保值、投資和組合配置、資產組合、資產負債管理等[6-12]。
基于以上討論,本文中提出一種融合CNN與LSTM的端到端深度強化學習方法(CLDQN算法)尋找最佳交易策略,主要貢獻如下:(1)將股票價格數據轉換成對應的二維矩陣圖,使用CNN模塊抽取股票動態市場特征。(2)使用LSTM模塊學習復雜的動態時間變化序列規律。(3)在動態股票市場中使用deep Q learning(DQN)方法獲取累積回報并依此做出交易決策。(4)在真實股票數據集上的實驗結果顯示CLDQN顯著優于其他基準算法,魯棒性更好。
1 相關工作
使用深度學習方法預測股票價格主要有兩類:一類是專注于提取時間序列規律,如RNN、GRU、LSTM等;一類是專注于融合不同數據,提取廣泛的特征,如CNN、反卷積神經網絡(deconvolutional neural network,DNN)等。下面分別介紹這兩類算法。長短期記憶(long short-term memory,LSTM)應用于股票研究。LSTM是解決梯度消失一種特殊的循環神經網絡,解決了RNN邏輯單元距離增加而出現的長期性依賴問題,被廣泛地應用于時間序列數據并取得了顯著的成果。Borovkova等[13]提出集成在線LSTM模型,將大量的技術性分析指標作為網絡輸入,根據每時段數據近期表現按貢獻重要程度分別加權,以此處理非平穩高頻股票市場數據,模型包括了兩組不同規格的LSTM,第一層能夠處理時間序列整體規律,第二層則針對具體特定特征。Cipiloglu等[14]提出LSTM模型學習股票月收盤價,介紹了5種不同資產組合構建策略,根據每個股票月度歷史數據作為模型輸入,預測每月的收盤價,產生了對成份股進行篩選或對成份股權重重新配置的不同聰明貝塔(smart Beta)變種,最終輸出不同組合股票收益。Tiwari等[15]調研了LSTM在股票價格預測、指數建模、風險評估、收益回報的應用。Hiew等[16]使用金融情緒指數與LSTM融合預測股票收益,通過不同來源的情緒指數,如微博上關于不同股票的討論,計算市場關注程度與情緒指數。也有使用LSTM與其他方法融合的方法,BAO等[17]將小波變換、堆棧式自編碼器(SAEs)和LSTM相結合,首先對股票價格時間序列進行小波變換分解以消除噪聲,接著應用SAEs生成深層高階特征,輸入至LSTM中預測第二天的收盤價,這種通過額外增加特征提取的方法在金融數據處理中比較常見。
卷積神經網絡(convolutional neural network,CNN)應用于股票研究。CNN可以融合不同來源數據,淺層網絡提取一些低級的局部特征,深層抽取更為復雜的全局特征,可用于交易價格預測、大盤趨勢分類、資產投資組合等問題。Gudelek等[18]提出一種利用CNN預測交易型開放式指數基金(exchange traded fund,ETF)收益,首先在滑動窗口時間內生成不同ETF快照,使用卷積操作提取趨勢指標以及基本面特征,包括RSI、SMA、MACD等特征,進而生成向量矩陣作為CNN的圖形輸入。為了考察不同市場之間的相關性,Hoseinzade等[19]使用2DCNN與3DCNN聚合對齊不同來源變量,包含S&P 500、納斯達克、道瓊斯NYSE,道瓊斯DJI、羅素指數,模型由4部分組成,包括輸入數據表示、日常數據特征提取、持續特征提取、預測部分。2DCNN使用單個市場與單個股票數據訓練預測,3DCNN將所有可用的市場數據作為輸入統一訓練模型,這兩種結構可提高3%~11%預測性能。Cai等[20]提出了一種融合CNN和LSTM框架,金融新聞和股票市場歷史數據作為輸入,構建了7個不同的預測模型分類器變種,組合成更強大的分類器。總體而言,CNN的優勢在于特征提取平移不變性,不會破壞信號頻譜,可并行處理不同時間節點數據。
區別于上述直接預測股票價格方法,基于強化學習方法將預測結果和投資動作結合在一起,直接以投資收益目標作為優化目標。強化學習價值函數可以具有不可微性質,因此可以較靈活地設計回報函數、增加數據來源與環境狀態,模型泛化能力較好[21-22]。但當狀態與動作連續時,動作價值表空間過大,導致查表狀態(state)和動作(action)過于復雜,因而提出了使用神經網絡擬合動作價值表方法[23]。Deng等[24]首次使用深度強化學習方法用于金融市場,深度學習部分自動感知動態市場條件,提取信息特征,強化學習模塊與環境互動并做出交易決策,為進一步提高市場魯棒性,引入模糊學習來減少輸入數據不確定性,實證結果較好,此后基于該方法的文章大量出現。Zarkias等[6]使用一種價格追蹤方法,通過將交易動作定義為包含市場噪音價格跟蹤智能體,可密切跟蹤價格,自動調整交易保證金,使用DDQN(double deep Q network)訓練模型。Jeong等[25]針對交易數據不足的問題,提出遷移學習融合Q-learning處理高波動金融數據帶來的過擬合問題,使用領域遷移方法將訓練好的模型遷移到其他股票,逐步迭代減少搜索空間,該方法也可以應用到對沖策略、資產組合優化等場景。Carta等[26]提出了使用相同訓練數據多次訓練DQN集成方法,在不顯著影響預期回報的情況下降低策略風險。Liu等[27]采用GRU與DQN結合方式,使用GRU抽取隱狀態特征值與觀察到的狀態融合之后,共同做為強化學習狀態表示內容。這種通過增加循環神經網絡中間層的方式,降低了連續性時間序列噪音,使得DRL能獲得較高穩定的輸入特征,是一種處理噪音較好的解決思路。
2 基于CNN與LSTM的DQN方法
2.1 模型原理
強化學習過程可以使用馬爾可夫決策過程(markov decision process,MDP)表示[21,28],通常將MDP定義為一個四元組(S,A,p,R),即(狀態,動作,狀態轉移概率分布,回報)。強化學習算法主要步驟包括:(1)定義回報函數;(2)定義狀態空間;(3)設計不同狀態之間的轉移概率分布表;(4)尋找最優化操作策略。本文關于金融強化學習的問題描述如下:
狀態(state),是對金融市場環境的一種描述,代表投資者所能獲取到的信息,狀態設計需要滿足兩個條件:盡可能多包含影響因子信息;盡可能減少噪音因子信息。金融市場狀態主要包括技術面、基本面、信息面。技術面包括交易量、價格最高點與最低點等;信息面包括市場外部信號、管理部門與上市公司等信息;基本面信息以股票內在價值為依據,包括公司經營分析、市場狀況、行業地位分析等。
動作(action),是對智能體(agent)與環境實時交互可執行動作的描述,動作可分為連續型動作與離散型動作,包括三種動作,a∈{-1,0,1},分別代表證券賣出qt+1=q t+k,無操作,買入qt+1=q t+k,q t代表t時間股票份額,k∈Z(Z為整數集)。
策略(policy),π(s),狀態空間到動作空間映射,表示在狀態s下以一定的概率p(s,a)執行下一步動作a t,并轉移到新的狀態at+1。
回報(reward),r(s,a,s′),在智能體的動作下,從t時間開始到T時間結束,累積執行動作獲得的回報值。在本文中,強化學習的最終目標是指定時間內累積折扣回報最高,學習過程是尋找使期望累積折現獎勵R t最大化的策略π(s),形式化定義如下:
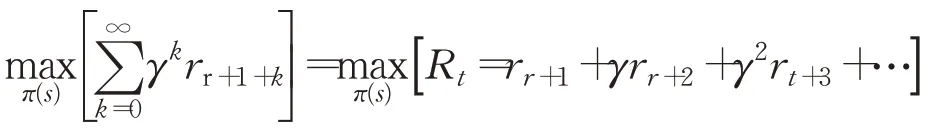
其中γ∈(0,1)是折扣因子,r t代表t時刻獎賞值。
評價策略π的期望使用狀態值函數Vπ(s)表示,定義為。狀態動作價值函數也稱為Q函數,是對狀態-動作對的評估,定義為Qπ(s,a)=,表示在狀態s下根據策略π執行動作a獲得累計期望價值。對一個指定的動作,如果其回報值大于其他所有動作的回報值,則稱π為最優動作,表示為。最優狀態動作價值函數Q*(s,a)通過貝爾曼方程求解[23],。實際上,Qlearning的目標是直接逼近最優狀態-動作值函數,假定Q(s,a;θ)是參數為θ狀態動作值的值函數,具體而言,對于第i+1狀態下的狀態-動作函數為Q i+1(s,a)=。此外,Q網絡的迭代目標函數為是目標網絡參數,通過迭代最小化損失函數L i(θi)學習參數,其中L i(θi)定義為
由于可行交易行為是一個離散集合,股票價格變化屬于連續變化且沒有邊界,Q-learning中狀態空間大小呈指數級增長,表格存儲空間成本和貝爾曼迭代計算量過大,阻礙了Q-learning的發展。Mnih等[29]提出深度學習與強化學習結合的DQN網絡,在Atari2006游戲中超過了人類的水平。DQN使用神經網絡非線性近似表示值函數或策略,Q-learning表格替換成基于神經網絡的Q-network[30-31],將深度學習與Q學習結合輸出最優值。包含4個步驟:(1)初始化狀態、環境、經驗池、策略、神經網絡等參數;(2)確定概率ε,將探索數據存入經驗池;(3)根據采樣規則從經驗池取出數據訓練,使用深度學習方法更新網絡參數;(4)重新評估策略回報值,循環以上步驟直至收斂。
2.2 模型框架
本文提出的框架主要由三部分組成,如圖1所示。(1)外部環境動態特征提取CNN部分。(2)時間序列規律分析LSTM部分。(3)交易動作決策部分。首先根據股票價格數據產生每支股票二維時序圖,將單位時間內開盤價、最高價、最低價、收盤價組成蠟燭數據圖,此外,新生成6組指數蠟燭數據圖,包括上證指數、深證綜合股票指數、上證50指數、滬深300指數、中證500指數、深證100指數。按照每28分鐘價格波動曲線生成一個矩陣向量,行向量值為每分鐘單位時間,t=k+1,k+2,…,k+28,列向量值為價格指數軌跡經過max-min方法調整后的價格浮動值,即矩陣T i∈R28×28,共7組向量矩陣,i∈(0,7),共同作為CNN輸入[32]。
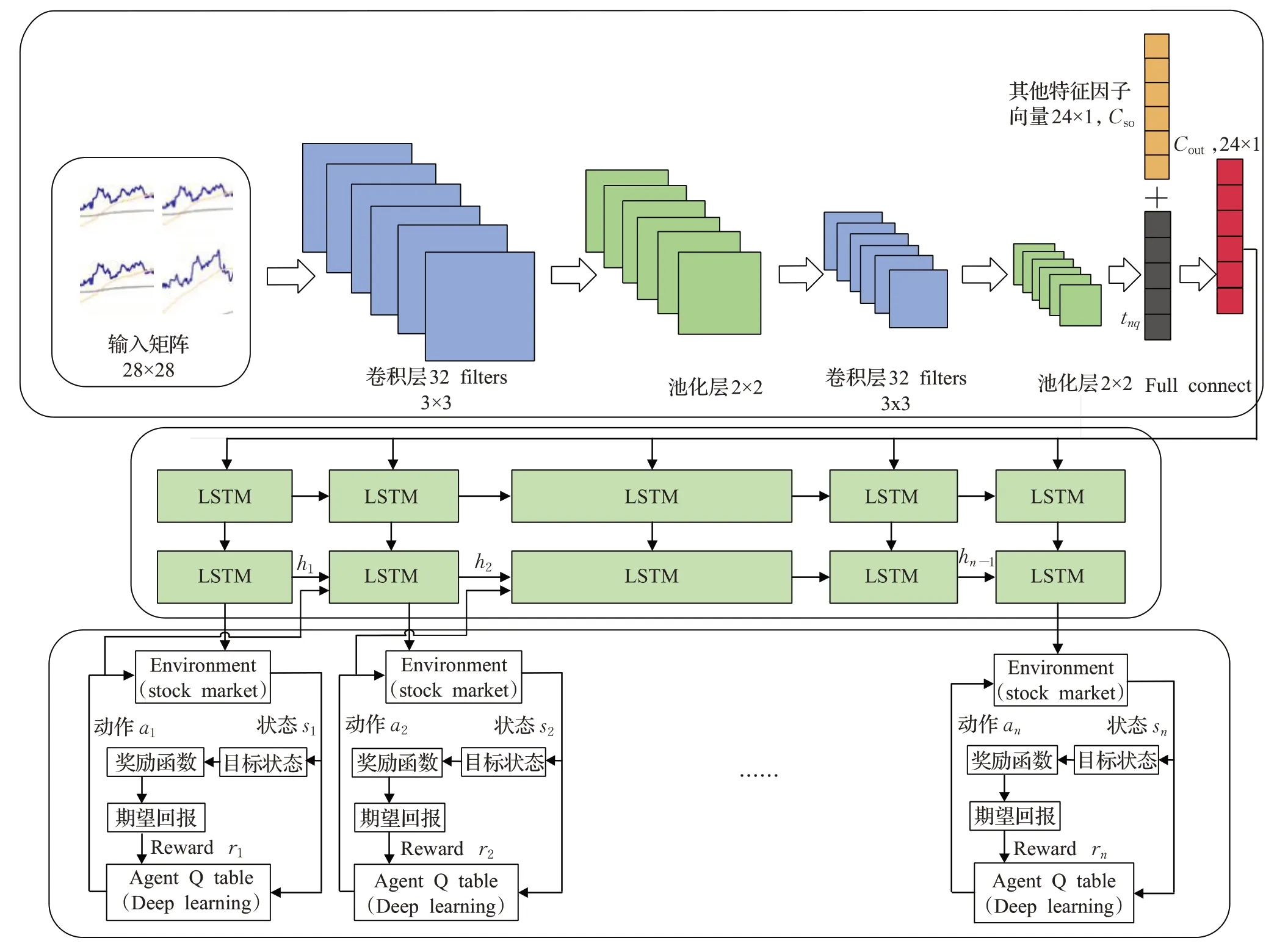
圖1 CLDQN模型框架Fig.1 CLDQN model framework
此外,為了更充分挖掘股票價格信息,按照資產定價研究常用方法,將影響股票價格因子分為4類:流動性類因子、波動類因子、動量類因子、基本面因子。具體如下,流動性類因子:換手率、單日成交量;波動類因子:6個月波動率、9個月波動率、基于CAPM的過去30天特質波動率、基于Fama-French的過去30天特質波動率、平滑異同移動平均線(moving average convergence divergence,MACD)、移動平均線(moving average,MA)、過去30天日收益率標準差、30天內最大日度回報、隨機指標KDJ、前1個月漲跌幅、前3個月漲跌幅、前6個月漲跌幅;動量類因子:相對強弱指數(relative strength index,RSI)、威廉指數(%R);基本面因子:賬面市值、銷售凈利率、市盈率、市凈率、股息率、凈資產收益率、現金流資產比和資產回報率之差、非經常性損益比,共24種因子,每一類因子經數據歸一化后,形成一個24維向量Cso。
減少原始數據中的不確定性是提高金融信號分析效果與算法魯棒性的重要途徑,CNN屬于一種前饋式神經網絡,具有局部感受野、權值共享特性,淺層卷積操作提取一些低級的局部特征,深層卷積操作提取潛在全局特征。卷積神經網絡主要包括輸入層、卷積層、激活層、池化層、損失函數層,卷積層與池化層交替成組出現,減少了特征維度,保證了卷積操作對位移、縮放和形放不變性。選取窗口大小為w∈Rk×k,步長為1的卷積過濾器作用在x i到x i+k-1的向量矩陣上,進行元素內積操作,元素積相加后得到新的空間特征,從窗口xi到x i+k-1得到特征為:

Conv是卷積操作,w i是權重參數,b i是偏置。將c個不同的過濾器分別作用矩陣上,可以得到輸出c個卷積層矩陣t nq∈R(28-L+1)×(28-k+1)。池化層起二次提取特征的作用,通過降低二維圖形分辨率降低特征維度,,fsub表示平均池化方式。最后一層池化層的輸出與其他特征因子向量融合后(Cso,t nq),經過全連接層(fully connected layers,FC)輸出Cout,作為LSTM的輸入。LSTM具有抽取時間特征作用,通過遺忘門控制歷史狀態,第t層信號經輸入門后仍可保留原有信息。本文LSTM結構定義如下:
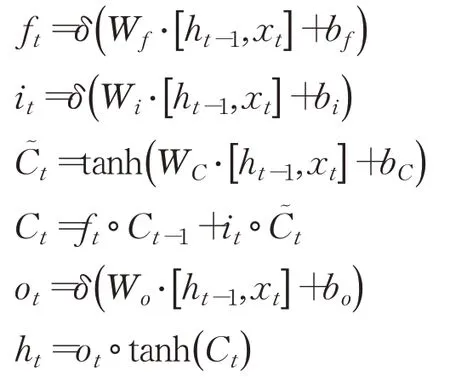
其中h t是LSTM單元的隱藏狀態,表示來自前一個時間步長的信息,x t表示外部輸入像信號,本文中為Cout,W f,Wi,Wc,Wo是對應門輸入權重參數,f t選擇忘記過去某些信息,i t記憶現在某些信息,C t將過去與現在信息合并,ot輸出門輸出,b f、b i、b c、b o是偏置,δ是非線性函數,符號“·”代表向量點乘,tanh是雙曲正切函數,每個單元的相同門的輸入參數共享。兩層LSTM被證明效果一般較好,本文也采用兩層LSTM架構[13]。
當智能體執行一個交易動作后,將獲得股票市場返回的獎勵Rt和狀態ot,以及經LSTM處理后的前序ht,作為下一次神經元的輸入,智能體動作可改寫為at=μθ(h t,s t),Q函數可改寫為
更新后的網絡損失函數定義為:

對損失函數求偏導:
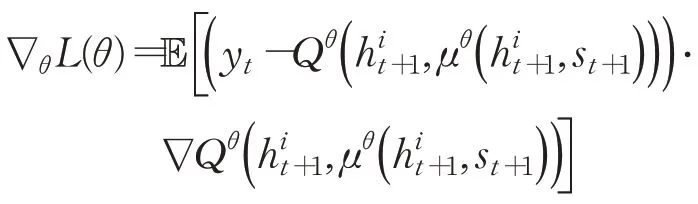
求解以使得損失函數最小,其中為t+1時刻LSTM輸出,s t+1為t+1時刻環境狀態,θi和是值函數Q的訓練過程參數和目標網絡參數,訓練過程中間斷更新。采用e-greedy貪婪策略,e-greedy是一個不確定性的策略,平衡了利用和探索部分,選取執行動作值函數最大部分為利用部分,仍存在一定概率尋找全局最優解為探索部分。采用經驗回放(experience replay)方式隨機抽取小批量樣本訓練,處理數據相關和非平穩分布引起的問題,增加樣本多樣本,防止程序陷入局部最優值,學習到的經驗可以共享。
2.3 模型學習過程
Q-learning使用探索(exploration)和利用(exploitation)尋找新的最優策略。首先設定訓練集窗口大小、驗證集窗口大小、測試集窗口大小、經驗池大小、折扣因子、學習率以及隨機初始化神經網絡權值θ和,初始化訓練集狀態、動作,以ε的概率從所有的動作中隨機抽取一個執行動作A,記錄即時回報R和轉移到的新狀態S,以1-ε概率使用神經網絡決策獲得下一步的動作,即令Q值最大的動作。在線處理得到的轉移樣本e t=(s t,at,r t,s t+1)存入經驗池D中去除采樣數據相關性。與傳統的DQN經驗池不相同,因為LSTM需要一次輸入多個相關的時間步長,而不是隨機采樣的單個時間步長,需要對相當長的軌跡片段進行采樣,用作向DQN提供狀態s。經驗池需要重新更改,(s,a,r,s′)~U(D)修改為
為了優化CNN網絡,本文采用Adam優化算法求解損失函數優化極值,Adam是隨機梯度下降算法的擴展式,通過計算一階梯度加權平均和二階梯度加權移動平均設計不同參數自適應性學習率。
從經驗池中隨機選取指定個數n的樣本作為batches進行訓練,Adam算法更新網絡參數θ,通過N輪迭代后,將訓練網絡參數延遲賦值給目標網絡參數,使目標網絡與訓練網絡參數盡可能接近。
在各時間節點,有一個隱藏的假設,即各個時間點的狀態是對環境的完整觀察,但金融市場充滿了大量噪音,使得狀態s不能完全描述市場交易環境真實情況,為了增加探索行為,一個隨機過程ξ~N( 0,σ2)噪聲添加到環境網絡,擾動后的動作更新為a t=μθ(h t,s t)+ξ。推進滑動窗口,重復以上過程,直到遍歷完所有數據集。
CLDQN學習過程如下:
算法1CLDQN算法
初始化動作狀態值Q函數參數θ,目標Q函數參數θ-,ε參數,經驗池D大小,minibatch。
While循環數據集次數小于指定Ldo
Forepisode=1→Mdo:
初始化噪音隨機過程N(0,σ2),更新參數θ和θ-,初始化超始狀態s
fort=1→Tdo:
根據概率ε選擇一個隨機動作at,或根據argrmaxaQ*(h t,a;θ)值選擇動作at
執行股票交易動作a t,獲得獎勵r t
將t時刻LSTM輸出h t,at,cout融合后生成新的h t+1=LSTM(a t,cout,h t),將結果(h t,a t,r t,h t+1)存入D中
隨機從D中隨機取出minibatch個狀態,設置y i

梯度下降更新θ,在損失函數(yi一Q(h t,a j;θ))2上執行對θ的梯度更新,每經過N步,更新目標網絡參數
End for
End for
End while
目標網絡更新如下:
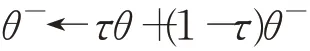
τ表示學習速率。
正則化與Dropout,金融市場本質上是嘈雜的,深度學習具有強大的學習能力,為避免神經網絡過擬合,使用Dropout正則化技術處理,Dropout在神經網絡中以概率1-p舍棄部分神經元,在訓練階段降低神經網絡規模,減少特征隱層節點間相互作用。
3 實驗與與結果分析
3.1 實驗平臺與工具
本文采用Python3.4實現算法模型,Tensorflow函數模塊開發深度學習網絡。使用Python matplotlib 3.1庫實現數據可視化,內存64 GB,CPU i7 4790,GPU GTX 1070,采用CUDA 9.0與CUDNN 7.1加速計算。交易成本設定交易金額的0.05%。mini-batch size等于512,初始學習率是0.01。
3.2 實驗設置
實驗數據來自wind終端,包括滬深市股票,特別選取4支股票:三一重工、格力電器、招商銀行、紫光股份,主要原因有:(1)不同市值的股票受宏觀市場的影響不同;(2)不同產業股票的周期性不同;(3)股民的關注度與股票價格具有相關關系,分別代表緩慢增長型、長期藍籌型、穩定型、科技型公司。三一重工代表受宏觀因素較深股票,格力電器、招商銀行分別代表高市值股票,紫光股份代表科技成長型中小股票。對于股票中的斷點,采用前序數據線性回歸補全開盤價、收盤價、成交量等值。上證50指數代表大盤行情,流動性更強,藍籌股與白馬股占主要成份,滬深300為滬深股市市值最高的300支股票,對整體市場的影響力最大,屬于大盤股股票,中證500指數代表滬深股市的中小盤股票,深證100指數代表多層次市場體系指數,為深市成交最活躍100支股票。使用2005年12月至2016年12月為訓練數據,2017年1月至2020年1月為測試數據,采用數據標準化方法對經后復權后的交易數據進行數據標準化,如表1所示。為了進行比較,基準算法分別為LSTM模型、RRL算法[33]、決策樹(decision tree);此外,CLDQN允許有兩個變種:CLDQN-L代表CLDQN中去除CNN部分,CLDQN-C代表CLDQN去除LSTM部分,股票的特征輸入采用特征向量直接作為LSTM的輸入。使用4個不同的評價函數,即累計收益率(cumulative return,(末期資產-初期資產)/初期資產)、年化夏普比率(annual sharpe ratio,(收益率-無風險利率)/收益率波動)[34]、年收益標準差(annual standard deviation)、最大回撤率(maximum drawdown,max(1-賬戶當日價值/當日之前賬戶最高價值))等。

表1 實驗數據特征Table 1 Experimental data characteristics
CLDQN各參數的設置如下:CNN filter為3×3,數量為32,步長為1,pool size為2×2,dropout設置為0.5。LSTM的input size為24,每層number of unit為128,所使用的激活函數為ReLU,Epochs=50,L=50。貝爾曼折扣因子0.9,經驗回放池大小設置為100 000,貪心策略ε=0.9,終止值0.001。訓練過程中采用off policy的方法,θ隨深度學習梯度更新,目標只做周期性的拷貝更新,目標網絡每100步更新一次。CNN、LSTM、DQN模塊均使用Python和帶有TensorFlow的Keras包實現。
3.3 實驗結果
3.3.1 不同股票收益曲線
如圖2為6種算法在4支不同股票數據下的收益曲線,圖中縱坐標表示資產累計收益率,橫坐標為樣本外測試時間。從圖中可以看出:
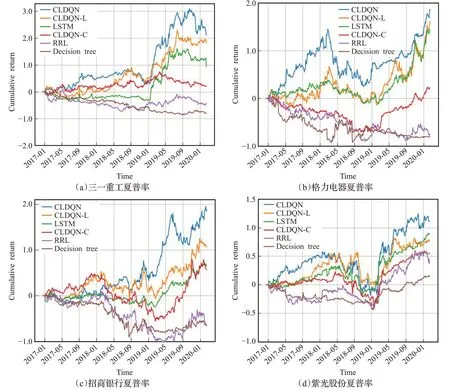
圖2 股票累積收益率評測Fig.2 Stock cumulative return evaluation
(1)本文提出的CLDQN收益率曲線明顯領先LSTM、RRL、決策樹方法。在2018年,基準算法有一個比較大的跌幅,CLDQN算法收益則較為平衡。決策樹的收效表現最低,LSTM算法處于居中位置。此外,對比CLDQN與CLDQN-L、CLDQN-C算法,同時考慮時間與變量交互特征的CLDQN效果比CLDQN-C算法最高約提高5.5倍左右(招商銀行,2019-06),單支股票與整體市場的關聯關系充分被捕捉,提高了算法精度。
(2)實驗結果表明CLDQN-C算法一般,說明通過卷積抽取外部環境狀態的方法對于算法性能增加影響有限。這是因為區別于圖像特征提取,同一時間序列在同一時間上不會出現兩個y軸像素,進一步地,取消了LSTM的CLDQN-C算法性能下降程度較高,說明LSTM可以發現隱藏在股票時間相關序列中歷史價格規律,過去的歷史數據影響因子可能會在未來股票市場變化中重現,有效地提高了模型收益能力。
(3)動量反轉效應。通過對2018年股票的動量收益情況分析,可以發現市場整體環境對個股收益有著不同的影響,對于大盤股和小盤股的影響存在明顯差異,小盤股對動量反轉反應比大盤股更明顯,紫光股份的動量效應比招商銀行的動量效應更明顯,市場處于上升階段時CLDQN動量效應的表現優于熊市。
(4)從整體上看,凈月平均收益(月平均收益-大盤月平均收益)在2017年、2018年、2019年逐年下降,可以認為算法在近期時間點表現優于遠期時間點,可能的原因是由于訓練集為2005年12月年至2016年12月,從經驗回放池中的抽取的樣本數據趨向于近期時期產生的數據,神經網絡參數發生了迭代更新,當被應用于2019年時,由于距初始訓練數據時間間隔變長,市場情況發生了變化,模型不再適應新的市場變化規律,導致CLDQN在距離訓練數據時間較近的2017年效果優于遠期2019年。
(5)決策樹算法。從模型的邏輯上來看,決策樹方法更符合價值投資理念,股票的基本特征,如市盈率、市凈率、凈資產收益率等指標對決策樹影響更大,微觀層面影響投資意愿,更傾向于長期投資,然而由于中國股市散戶投資者多,交易頻率高,風險承受能力較差,追漲殺跌現象嚴重,導致決策樹算法效果不佳。
3.3.2 年化夏普率
如圖3顯示了不同的交易策略年化夏普率(描述資產收益對投資者所承擔風險的補償程度),年收益標準差(收益率的變動大小,描述股票投資的風險程度)、最大回撤率(描述投資者可能面臨的最大虧損與抗風險能力)的評測結果,從圖中可以發現以下規律:
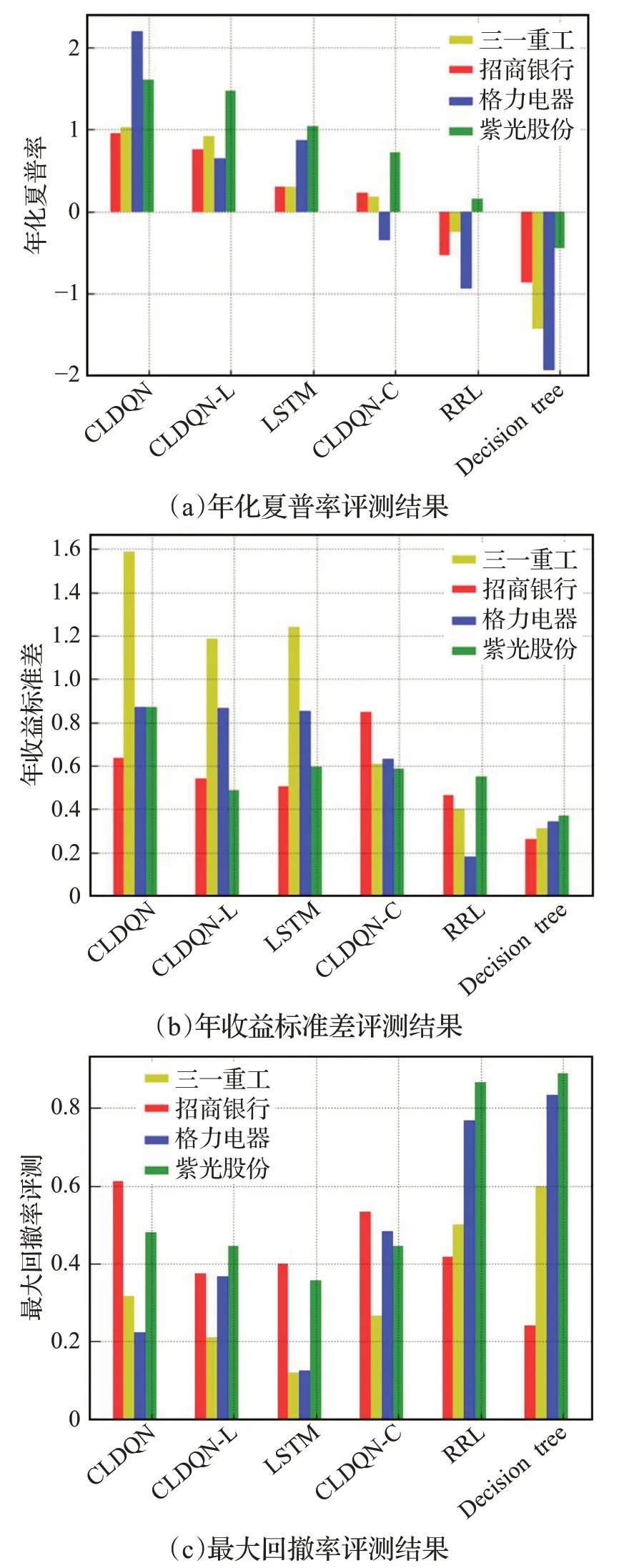
圖3 年化夏普率、年收益標準差和最大回撤率評測Fig.3 Evaluation of annual sharp rate,annual return standard deviation and max dawndown
(1)本文提出的CLDQN算法整體上年化夏普率、最大回撤率都優于基準算法,CLDQN-C與LSTM算法的年收益標準差相近,可能原因在于LSTM對短期的時序數據規律敏感,能夠快速捕捉到新變化的市場規律。決策樹算法對動量因子的反應較為激烈,由于中國股市的透明性與不確定性比一般市場高,導致下一輪的回撤率更高。
(2)CNN作用。從圖中可以看到,CNN模塊對算法收益的重要性不如LSTM模塊,但是CLDQN-C年收益標準差較低,說明CNN能夠多角度融合不同來源影響因子,有效地穩定模型,提高魯棒性。
(3)市值效應。紫光股份的最大回撤率最大,年化夏普率最低,原因在于紫光股份股票流動性較好,流動性與公司規模在截面上高度相關,對賬面市值比的影響是長期的,市場對股票價格沖擊大,公司規模與賬面市值具有反向替代作用。
3.3.3 交易費用作用
影響股票投資收益主要有兩部分,包括對行情規律的準確描述,以及交易成本對收益的影響。接下來討論交易成本(ρ=0.000 5,0.001,0.001 5,0.002)對整體收益的影響。以CLDQN為例,結果如表2所示。
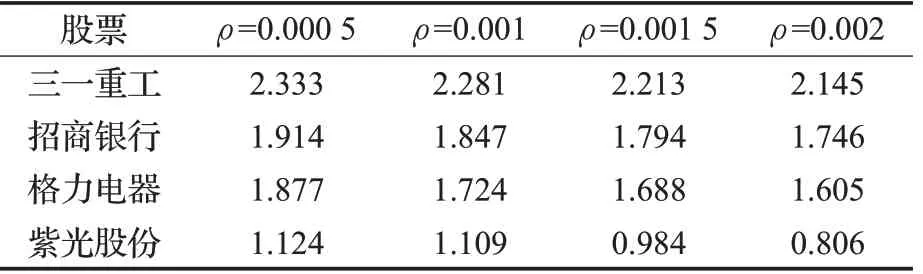
表2 交易成本對交易回報影響評測Table 2 Impact evaluation of transaction cost on return
從表中可以看出,隨著交易成本增加,交易量明顯減少,總回報收益逐步下降,在市場混亂時期,買賣雙方的比例相對不平衡,降低交易成本會提高換手率,預期回報表現較好;當交易成本過高時,抑制金融市場過度投機,高流動性資產比低流動性資產所吸引的風險更高,市場波動性下降以減小市場風險,個體交易者的交易成本增加與價格下滑效應結合,總收益下降可以部分地由總交易成本過高來解釋。此外,由于A股為散戶型市場,交易費用提高不會降低風險資產流動性,總交易成本上升,因此從表中可以看出紫光股份的總收益的下降趨勢最為明顯。
3.3.4 證券指數對夏普率作用
為研究各證券指數對夏普率的影響,在產生蠟燭數據圖階段,依次剔除不同指數(包括上證50指數、滬深300指數、中證500指數、深證100指數)數據,此時CNN的輸入只包含6組向量矩陣。實驗結果如表3所示。
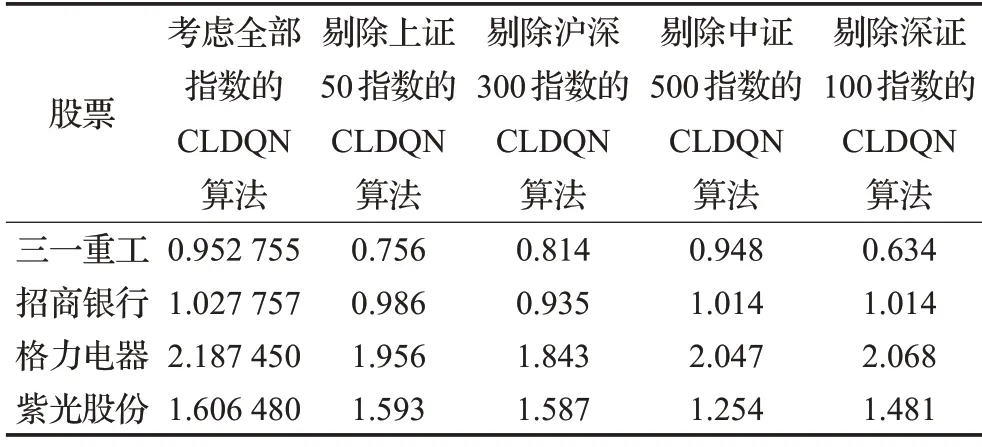
表3 證券指數對夏普率影響評測Table 3 Impact evaluation of stock index on sharp rate
從表中可以看出,不同指數對股票的夏普率影響程度不同,上證50指數對三一重工影響程度最高,其夏普率下降最快,滬深300指數對格力電器影響程度較高,中證500指數對紫光股份影響程度較高,說明外在消息面與投資者情緒產生的影響較大,深證100指數對三一重工影響較高。以上現象原因主要有兩點:(1)深證100指數成分主要由交易活躍的股票組成,三一重工有相對較高成交量,因而所受影響最大。(2)對于市值較高的股票,如招商銀行,股票趨勢與大盤指數有較高關系,當市場變化劇烈時,高市值股承受的風險更高,夏普率下降明顯。一般而言,個股的預測結果誤差較大,夏普率較低,而大盤指數的預測精度一般較高,總體上的夏普率也更高。整體上,本文采取的多因子模型有較好的適性,夏普率更高,平均收益標準差更低,效果較好。
4 總結與展望
本文提出了一種融合了CNN與LSTM的深度強化學習股票策略交易算法CLDQN,深度強化學習算法性能很大程度上取決于所能表達的完整環境狀態特征,CLDQN使用價格曲線、股指曲線、技術、信息、市場因子組成的向量作為CNN全局輸入,利用LSTM尋找時間序列規律,引入隨機噪音與模型訓練正則化增加魯棒性,降低模型過擬合,在真實數據集上比對了不同基準算法的累積收益率、年化夏普率、年收益標準差、最大回撤率,實證結果表明CLDQN算法的累積收益率更高,魯棒性更好,擴展性強。
深度強化學習算法的基本邏輯與人類思維邏輯相似,代表了自動化交易最有可能的發展方向。未來工作可以從以下幾個方面考慮:(1)大多數金融RL使用探索-利用模式,外界非常變性數據有重要價值,考慮引入行為金融學理論,將市場情緒與投資者情況納入到影響因子中。(2)可解釋性,投資者希望投資邏輯有明確的解釋,以處理不斷變化的市場狀況,考慮加強認知科學對深度強化學習投資組合優化解釋作用。(3)引入遷移算法應用到DRL中,以解決真實市場中的有效數據稀缺性問題。
猜你喜歡
作文周刊·小學一年級版(2022年16期)2022-05-07 11:28:30
作文周刊·小學一年級版(2021年8期)2021-07-07 11:00:47
動漫界·幼教365(大班)(2021年4期)2021-05-23 21:33:16
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文周刊·小學一年級版(2016年28期)2017-06-03 00:28:49
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
少兒科學周刊·少年版(2015年4期)2015-07-07 20:56:37
電影故事(2015年30期)2015-02-27 09:03:12
七彩語文·低年級(2014年10期)2015-01-14 14:46:27
