穩定同位素質量平衡混合模型的性能評估
2022-04-13 10:26:56祝孔豪郭鈺倫王維康
水生生物學報 2022年3期
祝孔豪 李 斌 王 康 郭鈺倫 王維康 徐 軍
(1. 中國科學院水生生物研究所,武漢 430072; 2. 內江師范學院,內江 641100; 3. 深圳市利源水務設計咨詢有限公司,深圳 528031)
穩定同位素技術是研究食物網生態學的重要技術手段[1—4]。與直接觀察攝食或胃腸含物分析等技術手段相比,穩定同位素技術能反映較長時間尺度內消費者營養來源的整合特征[1,5]。基于穩定同位素質量平衡模型,穩定同位素技術可用于消費者營養溯源,即確定多種營養來源對消費者的貢獻比重[6—8]。作為穩定同位素質量平衡模型的重要分支,貝葉斯混合模型考慮了營養來源的不確定性,并允許納入協變量,所以近十多年來得到了廣泛的應用[9]。通常使用貝葉斯混合模型來估計不同營養來源的貢獻; 此類模型在貝葉斯混合模型輸出了每個營養來源對消費者貢獻比例的概率分布特征[10],因此其假設之一就是營養來源對消費者貢獻比重滿足(0,100%)的條件。當引入某種營養來源進入模型時,就存在了消費者確實依賴了這種營養來源的先驗假設; 一個營養來源的貢獻比例高,必然會降低其他營養來源的貢獻比例,導致營養來源貢獻比例不確定性增加[11]。因此,評估貝葉斯混合模型性能,就需要評價貝葉斯混合模型擬合結果的優劣,及其與生態學理論和研究背景的匹配程度。
本文基于實測同位素數據集(蒙古鲌Culter mongolicus mongolicus同位素數據集),通過識別消費者營養功能類群特征、改變營養來源先驗信息特征,構建系列貝葉斯模型; 通過比較模型總體性能、實測值與預測值差異,及先驗信息和后驗信息差異等多種模型性能評價方法,來描述模型性能評價的方法和過程,以此為應用穩定性同位素技術開展消費者營養溯源研究,提供模型性能評估體系。
1 穩定同位素數據
1.1 鲌穩定同位素數據集
本研究中蒙古鲌數據引自李斌等[12]。實驗材料于2010年7月采自三峽庫區腹地北岸支流小江。同位素樣品在西南大學地理科學學院地球化學與同位素實驗室(設備型號: Flash EA112HE DELT plus XP)完成測試,其分析精度δ13C<0.02‰,δ15N<0.03‰。樣品的收集、處理和保存方法如徐軍等[13]所描述。
1.2 種群營養功能群
采用K-means聚類對消費者穩定同位素值進行聚類和種群營養功能群劃分。K-means聚類屬于無監督學習聚類。基本原理是從n個數據對象任意選擇k個對象作為初始聚類中心點[14]; 根據每個聚類對象的中心點,計算每個數據對象與這些中心點的距離; 并根據最小距離重新對相應數據對象進行劃分; 重新計算每個聚類中心點,反復循環至每個聚類不再發生變化[14,15]。
較為常見的聚類效果評估方法是總體類內誤差平方和(Total within sum of the squared errors)評估(公式 1),即肘部法則(Elbow Method)[14,15]。
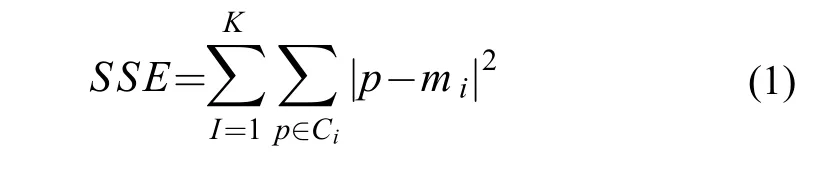
式中,Ci是第i個簇;p是Ci中的樣本點;mi是Ci的質心(Ci中所有樣本的均值);SSE是所有樣本的聚類誤差[14]。隨著聚類數k的增大,總體類內誤差平方和減小,SSE隨著分組增加而降低; 在達到某個臨界點時,SSE得到極大改善,之后緩慢下降,形成一個“肘部”形狀的關系; 這個臨界點附近的聚類數k即可作為聚類性能較好的分組[14,15]。
本研究分析表明,在對消費者蒙古鲌的穩定同位素值進行聚類過程中,發現在k=4、5、6時,SSE值形成的“手肘”形狀關系; 但是分組的增加所獲得的SSE值下降的回報不高(圖 1A)。結合湖泊生態學基本理論和消費者種群內營養功能群的特點[16—18],本文設置了一個聚類k值的選擇條件,即某k值(k>1)聚類所獲得的SSE值與k=1時SSE值的比值小于15%時,則分組回報不足。基于這個聚類原則,對消費者蒙古鲌的穩定同位素值進行聚類,最佳聚類數選3(圖 1A),分別代表魚類食性為主(Piscivorous)、浮游動物食性為主(Planktivorous)和底棲動物食性為主(Benthivorous)等食物網功能類型(圖 1B)。種群營養功能群的識別,既有助于減小消費者同位素變異所帶來的不確定,又有助于理解消費者在食物網的功能[19,20]。
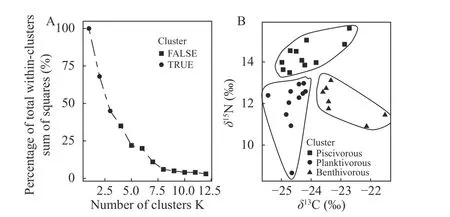
圖1 種群內營養功能群的確定Fig. 1 Within-population trophic functional groupsA. K-means聚類與總體類內誤差平方和百分比特征; B. 魚類食性為主、浮游動物食性為主和底棲動物食性為主的3個功能類型A. K-means cluster and percentage of total within sum of the squared errors; B. Three trophic functional groups,including piscivorous,planktivorous,and benthivorous
1.3 營養富集因子與源矯正
構建貝葉斯混合模型的一個重要前提條件是消費者與營養來源間的同位素的差異[21,22]。這種差異由消化和代謝過程中同位素分餾引起,被稱為營養富集因子(Trophic enrichment factor,TEF,Δ),其定義為Δ =δtissue–δdiet(δ代表樣品的同位素比值與標準物質的同位素比值之間的相對差異)[23]。由于TEF受到從生理到營養來源的多種因素影響,實際研究中多采用營養級富集因子的統計平均值(或多個統計平均值)進行分析,以獲得最接近富集因子真實值的近似值,從而更好地估算該種類的食源組成[21,22]。例如,δ15N在相鄰兩個營養級間所產生的富集因子(Δδ15N)在3‰—5‰[24],而δ13C在相鄰營養級間富集因子(Δδ13C)為0.4‰—1.0‰[25]。
在本研究中,消費者蒙古鲌是典型的肉食性消費者,本研究使用Δδ15N=(3.4±0.99)‰和Δδ13C=(0.39±1.14)‰對營養來源的穩定碳氮同位素進行矯正,即Δ+δdiet[21,22]。結合蒙古鲌食性對食物來源進行整合,形成四類營養來源用于模型構建,包括浮游動物、底棲動物、浮游魚類和底棲魚類(圖 2,食物來源δ值數據來自李斌等[12]的實測數據)。TEF的不確定性(標準誤差),通過統計平方公差法(Root-Sum-Squares Error),整合到食物來源同位素的誤差中(公式2),用來反映數據誤差的整體特征[26]。

式中,σ為標準差。
同位素混合空間中(圖 2)營養來源和消費者同位素之間的共線性,及不同營養來源之間的差異水平等情況,可會導致統計上多種營養來源貢獻的等效解決方案,也需盡量避免[27]。結合多元方差分析(Multivariate analysis of variance,MANOVA),結果表明4種潛在食物來源表現出一種或一種以上的穩定同位素顯著差異(P<0.05),且共線性特征不顯著(圖 2),適合進一步分析消費者的食物來源。
1.4 建模數據質量檢驗
TEF的選擇及源矯正的合理性,對穩定同位素質量平衡混合模型的結果影響很大[21]。混合模型的基本假設之一就是,消費者的穩定同位素必須屬于多種食物來源穩定同位素所定義的同位素混合空間[9]。特別需要指出的是,本研究案例中的貝葉斯混合模型,其數學性質是即使數據不符合穩定同位素混合的基本假設,也會獲得方程的解[9,10]。因此,必須檢查消費者穩定性同位素數據是否絕大多數落入多種營養來源確定的同位素混合空間中[28]。
盡管通過營養富集因子校正后的穩定同位素混合空間(圖 2),可以初步進行判斷; 但直觀觀察很難準確確定哪些樣本屬于混合多邊形。由于貝葉斯建模包含不確定性(本例中為均值和標準偏差),需要借助一定的統計學方法來判斷哪些消費者在模型求解過程中產生錯誤的風險較高。本研究采取混合多邊形迭代模擬的方法來判別數據落入混合多邊形的可能性。基本方法是,基于TEF校正后的各種營養來源的同位素均值和標準偏差,迭代生成10000次穩定同位素混合多邊形; 進一步計算消費者穩定同位素落入這些混合多邊形的頻次; 消費者穩定同位素落在>0.05可能性區域,為數據質量符合建模需要(圖 3A、3B和3C)。

圖2 營養富集因子校正后的穩定同位素混合空間Fig. 2 Trophic enrichment factor corrected isospace
如前文所述,同位素混合空間中營養來源和消費者之間的共線性,可為營養來源貢獻提供多種在統計上等效的解決方案[9,10]。引起這種不確定性的主要特點是,當消費者的穩定同位素處于由營養來源所構成的同位素空間中心區域時,模型無法確定營養來源比例。因此,當穩定同位素混合空間質心區域消費者樣本過多時,共線性增加,穩定同位素混合空間模型求解不會收斂或預測值與觀測值不能較好匹配[29]。本研究采取混合多邊形迭代模擬的方法來判別數據質量。基本方法是,基于TEF校正后的各種營養來源的同位素均值和標準偏差,迭代生成10000次高風險混合同位素空間(以質心為中心的50%不規則多邊形面積內)[28,29],進一步計算消費者同位素落入風險高的混合空間的次數; 通過計算落入混合空間次數與迭代次數的比值,基于統計學頻次計算落入高風險穩定同位素混合空間的概率,來檢驗數據建模的質量; 消費者穩定同位素落在<0.95可能性區域,為數據質量符合建模需要(圖 3D、3E和3F)[28,29]。
由圖 3所示(等值線顏色深淺顯示了概率輪廓),本研究數據總體質量較高。圖 3A、3B和3C則顯示了消費者蒙古鲌同位素值的變化將如何影響營養來源混合模型合理求解的概率[28]。95%概率輪廓內的消費者蒙古鲌樣品可用于混合模型使用,也就是說其中一個樣本(16號個體)位于營養來源之外,因此模型解釋程度低,在后續建模分析中予以剔除。圖 3D、3E和3F則顯示了消費者蒙古鲌同位素值的變化將如何影響營養來源混合模型低估風險的概率[29]。消費者蒙古鲌樣品落入風險區的概率總體低于50%,未出現高于95%概率的樣本。

圖3 混合多邊形迭代模擬Fig. 3 Mixing polygon simulation
需要強調的是,如果在上述統計方法檢驗過程中,發現較多的樣本不適用于建模,則必須考慮研究假設中是否存在1)測量過程的錯誤、和/或2)消費者的重要食物來源被忽略、和/或3)營養富集因子使用不合理等問題。
2 貝葉斯質量平衡混合模型
2.1 先驗信息
“從先驗信息中獲益(Profiting from prior information)”是貝葉斯建模中的一個常見想法[30,31]。因此,先驗信息的確定是穩定性同位素質量平衡混合模型的一個重要條件。為特定研究設計建立合理的信息先驗是建立貝葉斯模型的最佳方案。因此,在開展研究前,需要投入大量的時間和精力進行數據收集和分析,了解哪些數據滿足了前期的假定條件,提升進一步建模分析的準確性[32]。當觀測樣本量或代表性有限時,貝葉斯模型將觀測值與先驗信息相結合,提升模型預測的準確性。在消費者營養溯源研究中,盡管使用胃腸含物來評估營養來源具有一定的局限性[33],但為同位素技術的研究提供了較好的先驗信息,可以提高混合模型預測的準確性[34]。此外,環境中潛在食物來源豐度、生物量和消費者攝食行為習性等,均可作為重要的先驗信息,以提高混合模型預測的準確性[34]。
本研究展示了3個營養來源貢獻的先驗信息,包括默認先驗(Uninformative)、信息先驗(Informative)和高信息先驗(Informative with SD; 圖 4)。針對4種營養來源,包括浮游動物、底棲動物、浮游魚類和底棲魚類,默認先驗的營養來源貢獻由均值為零、標準偏差為1的正態分布混合確定,并進行中心化對數比轉換(Centralized logarithm ratio transformation)[35],從而產生均值為0.25且營養來源邊際貢獻大的分布特征(SD≈0.2)。信息先驗是基于蒙古鲌的食性分析數據,4種來源質量比例均值分別為16.7%、28.3%、20.6%和34.4%,依據上述方法獲得營養來源邊際貢獻水平較大的分布特征(SD≈0.2)。高信息先驗的情景則是在此基礎上,結合食性數據變化的標準偏差特點,在均值不變的條件下,對所有營養來源使用了SD ≈ 0.06的標準偏差(圖 4)。在進一步建模分析中,本研究采用高信息先驗的情景來分析蒙古鲌數據集。
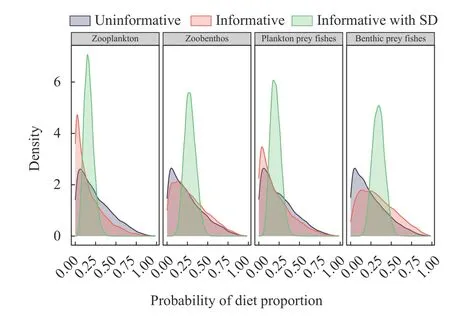
圖4 先驗信息的不同情景Fig. 4 Priori information of three scenarios
2.2 模型構建
本研究使用R包simmr來擬合所有的同位素貝葉斯混合模型(iter=50000,burn=1000,thin=10,n.chain=4),并使用JAGS(Just Another Gibbs Sampler)從后驗分布中提取樣本。通過馬氏鏈(Markov chain,MCMC)軌跡圖檢驗法、Geweke檢驗法和Gelman檢驗法等多種方法診斷了馬氏鏈的收斂性,進一步估計有關參數或者進行其他統計推斷。模型結果表明(表 1),蒙古鲌魚食性功能群的浮游餌料魚的比重最高,其次為底棲餌料魚; 蒙古鲌浮游動物食性功能群的浮游動物和浮游餌料魚的比重高; 蒙古鲌底棲動物食性功能群的底棲動物能量貢獻比例最高,結果整體符合預期。
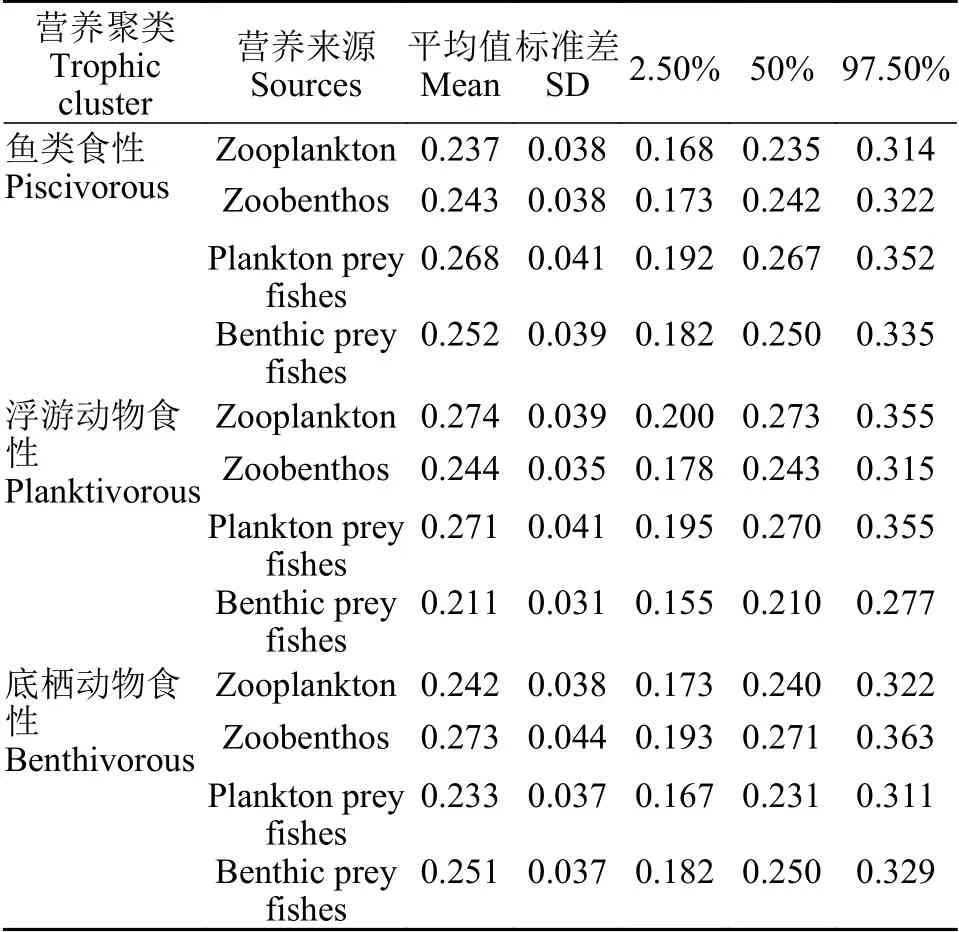
表1 模型結果Tab. 1 Model results
3 模型性能評價
3.1 整體性能
在模型選擇階段,常見指標為偏差信息量準則(Deviance information criterion,DIC)。DIC是等級模型化的赤池信息量準則(Akaike information criterion,AIC),被廣泛應用于由馬爾可夫鏈蒙特卡洛(MCMC)模擬出的后驗分布的貝葉斯模型選擇問題[36]。和赤池信息量準則一樣,偏差信息量準則是隨樣本容量增加的漸近近似,只應用于后驗分布呈多元正態分布的情況[11,37]。一般而言,偏差信息量準則的值越小,模型越好。這一準則的優點是它很容易從馬爾可夫鏈蒙特卡洛(MCMC)模擬產生的樣本中計算出來[36]。在一組供選擇的模型中,如果觀測值樣本數不同的時候,可使用校準的DIC(DICcor)進行比較(公式3)[11,37],公式如下:
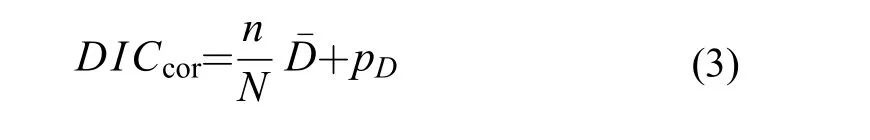
式中,N表示每個模型的樣本數,n為比較的模型中樣本數最低的數據。
例如,本研究中蒙古鲌魚食性功能群、浮游動物食性功能群和底棲動物食性功能群的3個模型的樣本數分別為11、10和7; 因此,計算DICcor的時候,取值n=7。由此模型整體性能評價結果表明(表 2),蒙古鲌魚食性功能群、浮游動物食性功能群和底棲動物食性功能群的擬合總體較好(90% Coverage均為100%,90% Coverage為觀測值落入90%后驗分布中的比例)。但3個模型比較看,魚食性功能群的擬合模型性能相對較差(DIC和DICcor最高)。需要特別指出的,在一組供選擇的模型中,最優化的模型的選擇都是具有相對性的,并不是說所選擇的模型就一定足夠精確。
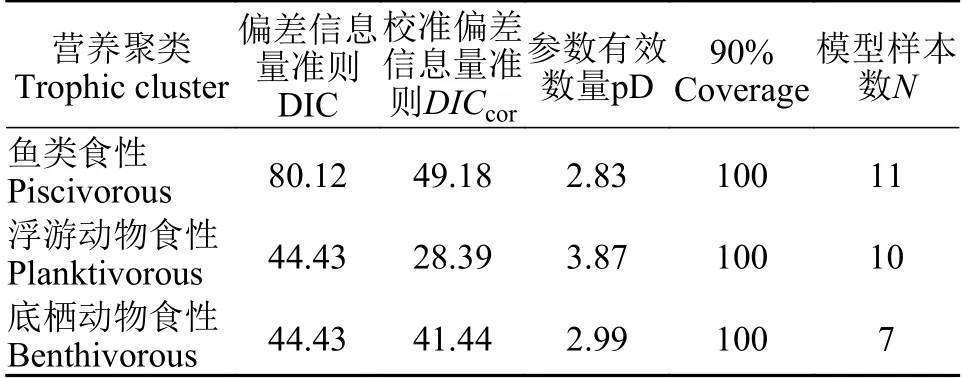
表2 模型整體性能評價Tab. 2 Model performance
3.2 預測值與觀測值
針對消費者營養來源研究,模型性能核心是指營養來源比例在不同方法下的預測效果,但是實踐中很難獲得消費者營養來源貢獻的合理觀測值。因此,通過評估消費者同位素的觀測值(y)與預測值之間的匹配程度,可以間接評估不同食物來源比例的預測效果[41]。消費者穩定同位素預測值可通過模型中各種營養來源貢獻比例和營養來源的穩定同位素來計算獲得(公式4)[42]:
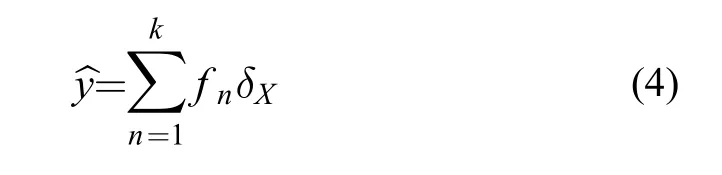
式中,n表示消費者使用的第n種食物來源,k是食物來源的數量(本研究中k=4),f代表通過食物來源分配方法預測的食物來源對消費者的比例貢獻。δX表示食物來源中測得的同位素組成。
結合模型的特點,通常計算一個或多個基于預測值與測量值的指標來進行評價(表 3)。例如,均方根誤差(RMSE),總結了測得值和預測值之間的平均差異,用來評估預測值的準確程度; 較低的RMSE值表明該模型具有較小的誤差和更準確的預測。預測優度統計數據(G)也用于衡量模型的有效性。G值為1表示理想的預測。G值越接近1,模型的可靠性越高。G值為負表示該模型不太可靠。
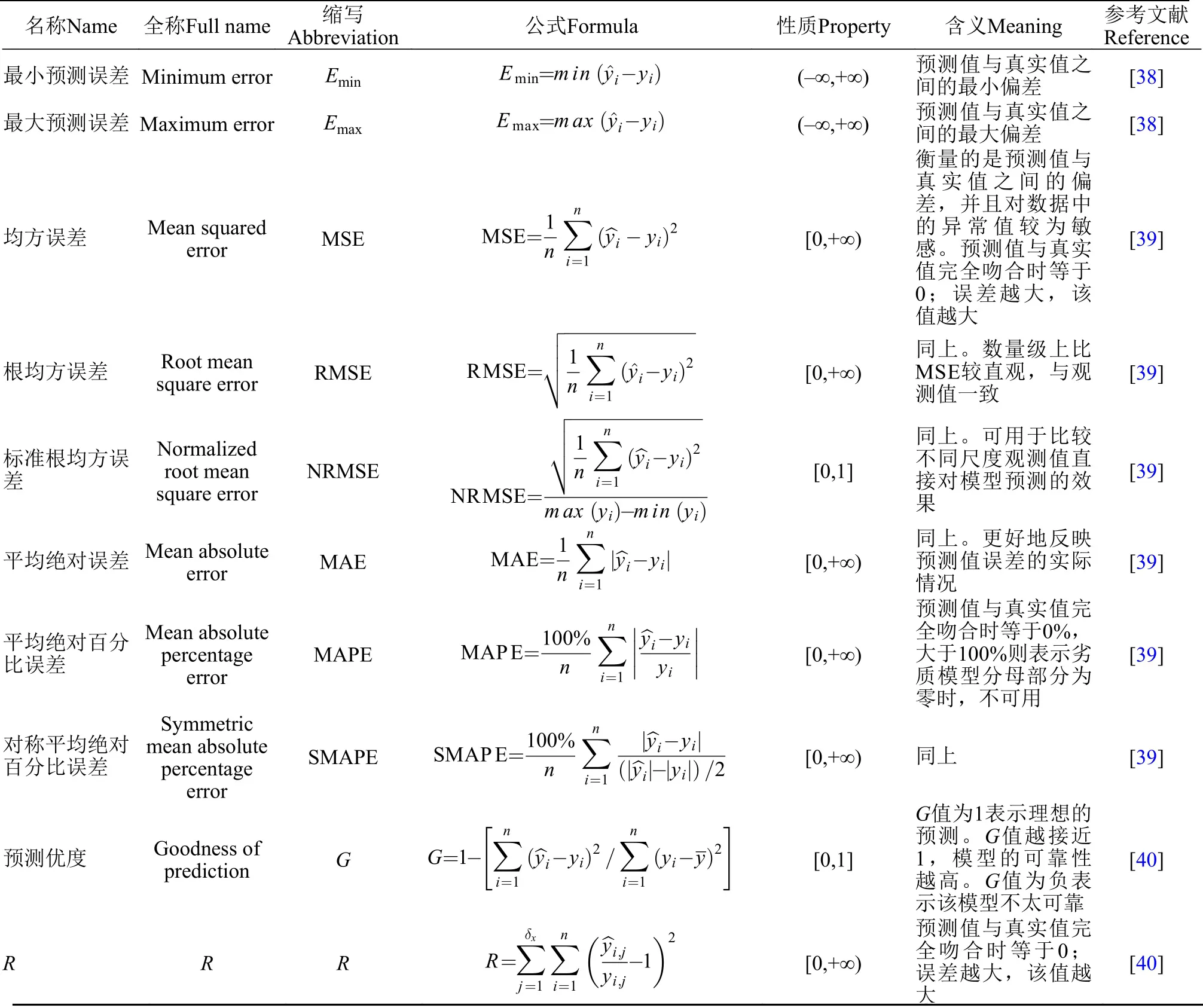
表3 基于預測值與測量值的模型評價方法Tab. 3 Evaluation methods for the difference between model predicts and observations.
衡量模型的擬合程度(模型質量好壞),沒有固定的標準。例如,MAE和RMSE一樣,衡量的是真實值與預測值的偏離的絕對大小情況,需要結合真實值的量綱才能判斷差異; 而MAPE衡量的是偏離的相對大小(即百分率)。相對來說,MAE和MAPE不容易受極端值的影響; 而MSE和RMSE采用誤差的平方,會放大預測誤差,所以對于離群數據更敏感。MAPE使用百分率來衡量偏離的大小,容易理解和解讀。而MAE/RMSE需要結合真實值的量綱才能判斷差異。
本研究的模型評價結果表明(表 4),蒙古鲌魚食性功能群、浮游動物食性功能群和底棲動物食性功能群的擬合總體較好(G>0.8),但3個模型比較看,魚食性功能群的擬合模型性能相對較差。不管用哪個指標,評估模型的好壞都不能夠脫離具體的應用場景和具體的數據集。單純地評判哪個模型好壞,是基本上沒有意義的。

表4 模型預測值與觀測值差異評價Tab. 4 Evaluation of the difference between model predicts and observations
3.3 先驗信息與后驗信息
貝葉斯混合模型的主要統計數據是消費者營養來源的概率分布,而不是消費者同位素值的預測,因此評估混合模型對消費者營養來源貢獻估計的后驗信息及其受先驗信息的影響(圖 5)。后驗信息與先驗信息的本質是營養貢獻量的概率分布,因此可通過信息理論的相關概念和方法進行評價(表 5)。
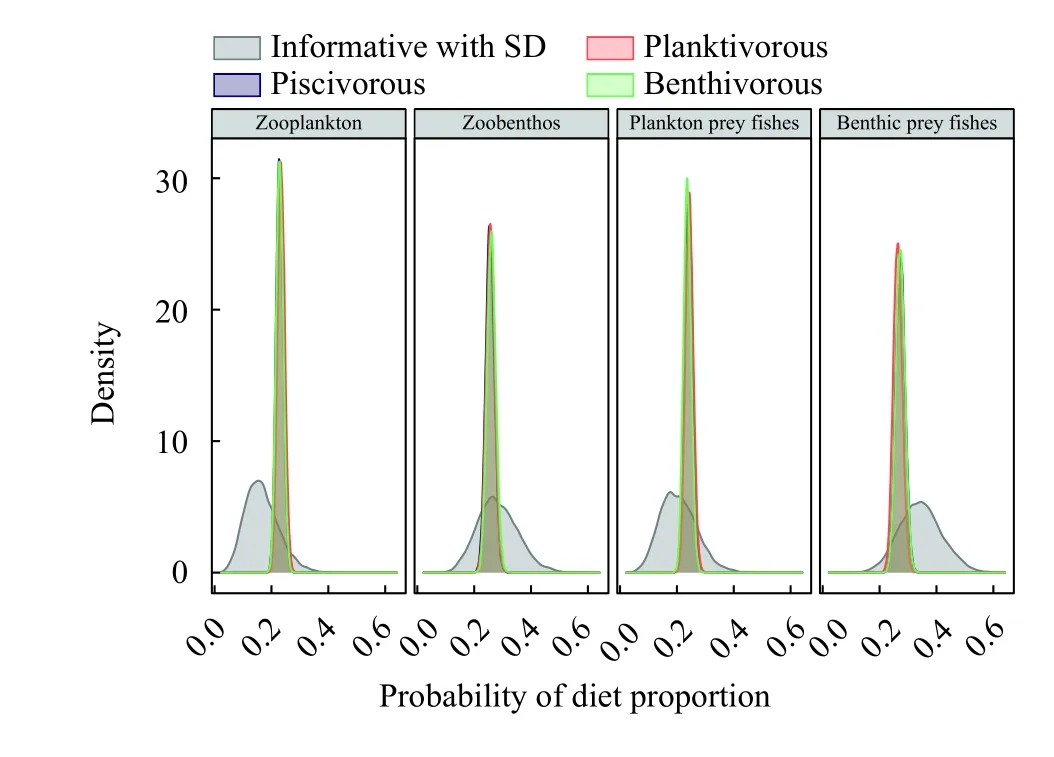
圖5 消費者不同營養功能群營養來源貢獻的先驗信息與后驗信息Fig. 5 Priori information and posteriori information of trophic groups

表5 主要信息理論度量與統計Tab. 5 The important information theory measures and statistics
信息量用來度量一個信息的多少,而信息熵(Shannon Entropy)則用來描述一個來源信息的不確定度,也是信息來源的信息量期望[44]。基于信息理論的方法,可以衡量不同營養來源概率分布之間的先驗信息與后驗信息的異同。進一步可評估營養來源數據的改變、消費者功能群的改變和營養來源強度的改變等對消費者營養來源信息確定和解釋的影響。例如,相對熵可以衡量先驗信息與后驗信息之間的距離,當先驗信息與后驗信息分布相同時,它們的相對熵為零[43]。在混合模型中,先驗信息通常較后驗信息豐富,因此當計算KL散度(Kullback-Leibler divergence),可獲得比最大熵更高的信息增益,即后驗與先驗信息相差很大時,就會出現較高的值[43],而信息熵則代表了信息增益的有限上界。KL散度(信息增益)增高由后驗信息與先驗信息不同的均值和置信區間的差異變大決定(后驗信息不支持先驗信息或者后驗信息強烈支持先驗信息但置信區間較窄),因此需結合分布信息圖一同解釋(圖 5)。
本研究依據主要信息理論度量與統計方法,評估了鲌貝葉斯混合模型的先驗信息和后驗信息結果(表 6),先驗信息和后驗信息不同的信息熵值、不為0的相對熵值及較大的交叉熵值表明鲌貝葉斯混合模型的先驗信息和后驗信息存在一定程度差異。首先,估計每個信息源的邊際(Marginal)貢獻所占的比例,以反映文獻中混合模型是如何解釋的(例如大多數混合模型程序的輸出包括邊際均值和可信度區間)。營養來源1%水平貢獻信息測量應在0.01的離散區間內計算。其次,通過所有來源貢獻的聯合后驗分布計算的,說明了關于來源相互間有條件依賴的信息增益,如食性組成權衡,及邊際貢獻的變化。我們通過比較食性組成貢獻的先驗分布和后驗分布的樣本來計算總體測量值,并使用The isometric logratio transformation等軸測對數比進行轉換[48]。等軸測對數比率將比例轉換為變量,這些變量根據多元正態分布近似分布,使我們能夠使用2個多元正態分布散度的分析方程來計算信息增益。從概念上來說,我們可以把等軸測對數比變換看作是將食性組成比例延伸到一個可能有無限邊界的坐標空間。等長對數比變換意味著KL散度可以無限增加,食性組成比例的變化非常微小。因此,我們在log2尺度上用KL散度來表示信息增益[11,37]。
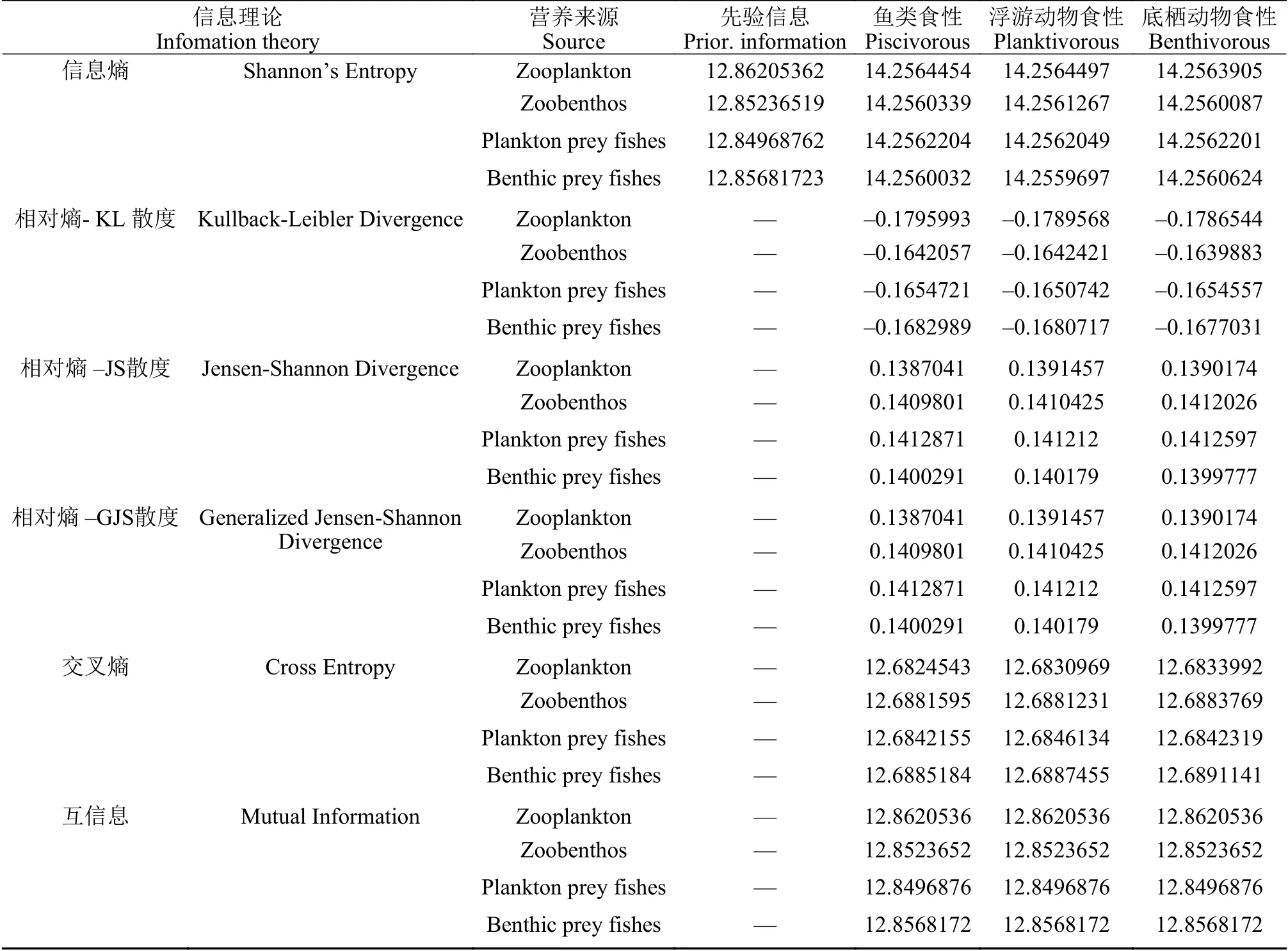
表6 先驗信息與后驗信息的信息理論統計結果Tab. 6 The important information theory measures and statistics
此外,度量2個概率分布之間的距離,還有一些其他通用的散度指標可供參考(表 7)。例如Hellinger distance[49]可量化先驗分布和后驗分布之間差異。如果先驗分布和后驗分布在其參數空間中具有相同的密度,則為零。如果一個分布在任何地方都是零密度,而另一個分布是正密度,那么Hellinger distance為1[45]。

表7 概率分布相似度評價的幾種距離法Tab. 7 Some distance methods to evaluate similarity of probabilistic distribution
4 結論
本文綜述了在擬合和評估貝葉斯混合模型時遵循的最佳實踐(圖 6),及如何直接避免同位素構建消費者營養溯源分析中的諸多技術問題[9]。種群營養功能群的識別,有助于減小消費者同位素變異所帶來的不確定性[19,20]; 營養來源矯正可以避免營養來源和消費者同位素之間的共線性,及不同營養來源之間的差異水平等情況[27]; 數據質量檢驗可以幫助剔除異常數據、提高數據總體質量、檢驗數據質量是否符合建模需要[28,29]。動態的生態系統與消費者相對快速的能量需求調整,可強烈地影響食物網結構與功能[50]。因此,在開展食物網研究前,需要投入大量的時間和精力進行數據收集和分析,了解野外調查過程中哪些數據滿足了前期的假定條件,以確保建模分析的準確性[32]。在嘗試數據建模之前,必須考慮環境中潛在食物來源的豐度、生物量、消費者的攝食行為習性、胃腸含物等重要的先驗信息[33]。完整重現模型選擇和模型評價的過程,是建模、訓練、驗證、評價的必要條件。模型選擇是根據一組不同復雜度的模型表現,從中挑選最好的模型; 模型評價則是在選擇模型后,評價其預測誤差[11,37]。根據具體研究,在實踐過程中,評價指標多種多樣,且分別刻畫了相對“真實模型”的信息損失。由于真實模型的未知性,這些評價僅反應現有模型構建過程中相對較好的性能,所以具體問題仍需具體分析。
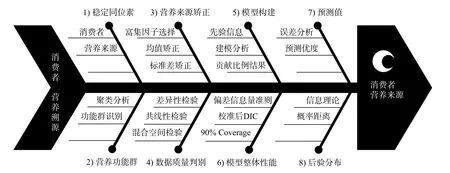
圖6 模型構建與性能評估流程圖Fig. 6 Fishbone diagram of quantifying the quality of model construction and prediction
通過側重于模型預測攝食者同位素值能力的評估方法,可以判斷模型的擬合質量。此外,鑒于貝葉斯模型的特點,即如果先驗信息誤差較低,則信息混合模型的后驗分布趨同于先驗信息,進一步進行了基于信息理論和概率距離統計方法的評估,為同位素混合模型的輸出結果的質量提供互補的評估方法[37]。這些方法的綜合運用,將進一步提高消費者營養溯源準確性,為更深刻地認識食物網規律提供科學支撐[11,37]。
猜你喜歡
今日農業(2021年11期)2021-08-13 08:53:34
今日農業(2020年20期)2020-12-15 15:53:19
中國生殖健康(2019年8期)2019-01-07 01:18:24
幸福(2018年33期)2018-12-05 05:22:46
瞭望東方周刊(2017年34期)2017-09-13 17:13:26
中華手工(2017年2期)2017-06-06 23:00:31
發明與創新(2016年16期)2016-08-21 13:56:16
發明與創新(2016年21期)2016-05-17 03:57:29
海峽姐妹(2016年5期)2016-02-27 15:20:20
中外會展(2014年4期)2014-11-27 07:46:46
