基于DSR和BGRU模型的聊天文本證據分類方法
2022-04-18 01:23:40張宇李炳龍李學娟張和禹
網絡與信息安全學報 2022年2期
張宇,李炳龍,李學娟,張和禹
(1. 信息工程大學,河南 鄭州 450001;2. 河南理工大學,河南 焦作 454003)
0 引言
隨著移動互聯網的快速發展,智能手機的使用頻率也在快速增長。但智能手機在給人們帶來便利的同時,也給犯罪帶來了便利。利用智能手機犯罪的記錄在不斷增長。以往的手機取證主要關注手機保存的地理信息數據、短信、通話記錄等。但隨著社交軟件的發展,社交軟件所保留的聊天記錄已經成為新的取證來源。根據CNNIC發布的調查報告顯示[1],截至2021年1月,我國社交軟件的使用人數已經達到96 012萬。正是由于社交軟件的流行,社交軟件上的聊天記錄具有重要的取證意義。
取證人員通過對聊天記錄進行分析來找到與案情相關的數據,但問題在于聊天記錄大量繁雜,而取證人員采用的方式是手動搜索或者通過設置過濾器的方法,這樣的方法低效而且很可能會遺漏關鍵證據。此外,近年來,犯罪分子的反取證意識不斷提高,在使用社交軟件時往往采用“黑話”來傳遞犯罪信息。例如,在非法借貸中“高炮”指一種超高息的短期借款;電信詐騙中“金主”指實施詐騙者,“水房”指洗錢機構;毒品交易中“豬肉”“蘋果”等指冰毒,“溜冰”指吸食冰毒。“黑話”影響了取證的效率。因此需要一種文本分類方法來從犯罪領域的聊天記錄中篩選出關鍵數據。
將文本分類技術應用到聊天記錄中仍有許多問題需要解決。
第一,犯罪領域的聊天文本具有鮮明的犯罪特征,常用的聊天記錄預處理方法會丟失這些特征。
第二,隨著時間的移動,“黑話”不斷出現并更新。出現新單詞會降低分類器的準確性,某些語義信息會在文本量化期間被忽略。
第三,“黑話”,如“豬肉”“蘋果”等涉毒詞,往往與涉及的領域無關,這需要結合上下文信息才能被認為與犯罪行為有關。這種“一詞多義”問題影響分類器的效果。
為了將文本分類技術應用到聊天記錄來篩選與犯罪有關的文本,本文提出了一種聊天記錄犯罪證據分類方法。該方法通過更新文本特征表示和文本特征提取技術來提高分類性能。
針對犯罪相關的文本分類主要應用于社交平臺所產生的聊天記錄。文獻[2]提出ARPR(AHP-relation-PageRank)算法。該算法采用TF-IDF(term frequency-inverse document frequency)方法對涉毒關鍵詞進行提取并對其詞向量加權,然后以好友關系為鏈接建立關系網絡作為PageRank的入度與出度來計算相對應的PageRank權值。ARPR算法結合TF-IDF方法和PageRank方法對聊天文本進行處理,使其能根據禁毒領域的業務需求,篩選出聊天文本中涉及的重點嫌疑人員。
與其他文本分類任務相比,與犯罪相關的文本特點是存在大量的“黑話”(一詞多義)現象。有不少研究者將深度學習用于解決文本分類中的一詞多義問題[3-4]。文獻[5]引入RNN(recurrent neural network)抽取詞語特征,其中詞語的特征不僅與當前詞有關還與它的上文有關。這種做法使得詞語的特征表示會隨著上文的變化而變化,具有語義的特性。但RNN循環機制過于簡單,在梯度反向傳播時會產生梯度爆炸或梯度消失等錯誤狀況,從而造成訓練過程停滯。LSTM(long short-term memory)和GRU(gated recurrent unit)在傳統RNN的基礎上引入“門機制”,在一定限度上避免了RNN的失誤。以此為基礎,大部分模型對GRU和LSTM模型實施改良。文獻[6]為了增強模型中上下文信息的處理效果,在LSTM模型的基礎上新增了外部記憶單元。但外部記憶單元參數量大,容易影響準確度。Tang等[7]提出CLSTM模型來解決一詞多義問題,該模型在LSTM的基礎上,引入注意力機制,取得了不錯的效果。文獻[8]在文獻[9]的基礎上進行改進,引入注意力機制來聚焦文本中的重要信息。文獻[10]與文獻[8]類似,區別在于,其引入BGRU來代替LSTM,相比文獻[8],文獻[10]提出的模型在時間性能上有較大提升。
以上的研究將RNN、CNN這樣的模型結構串聯起來用于文本分類,但這種層疊串聯的模型結構會隨著層次的加深丟失特征信息。針對這一問題,文獻[11]提出一種雙通道深度學習模型,該模型并行采用 CNN和LSTM分別從字、詞角度對不同嵌入方式下的文本進行特征提取,并將雙通道提取出的特征進行融合,從而進行分類。文獻[12]將CNN和LSTM并聯起來,并在模型的后端綜合各通道提取的特征進行分類。
總而言之,本文的研究技術流程如圖1所示。
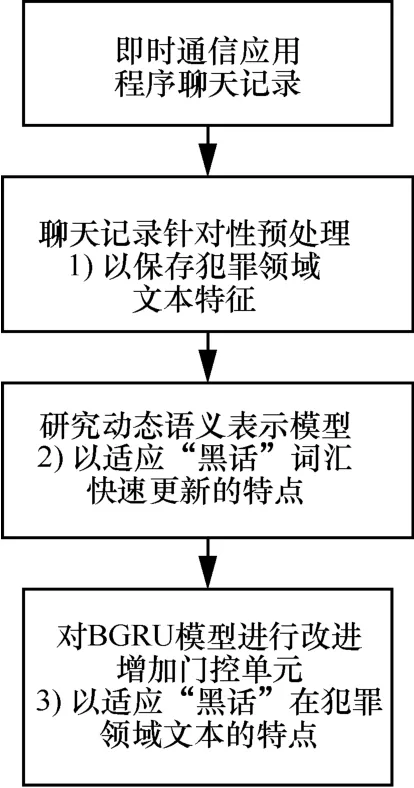
圖1 研究技術流程 Figure 1 Research technology process
本文的主要貢獻如下。
1) 提出犯罪領域的聊天文本預處理的手段,使其保存犯罪領域特征。
2) 提出動態語義表示模型(DSR)對詞進行特征表示。該模型首先在預訓練好的詞向量上使用聚類算法選擇語義詞。然后采用稀疏約束訓練語義詞對新單詞進行稀疏表示。采用DSR模型能有效降低新單詞對分類器準確性的影響。
3) 采用BGRU模型[13]從詞向量組成的文本中進行上下文特征提取,并對其改進使其能適應“黑話特點”從而能根據上下文變化來解決“黑話”一詞多義問題。
1 模型設計
為從犯罪領域的聊天記錄中篩選出關鍵數據,本文提出結合DSR模型和BGRU模型的聊天記錄文本分類方法。其中,DSR模型用于捕獲語義層次的信息,BGRU模型提取詞向量的文本特征并用于分類。首先對聊天記錄進行分類,分為訓練集和測試集,在預處理后,先訓練訓練集,而后對結果進行測試,通過反饋的正確率驗證模型的準確率,來看模型是否有效。DSR-BGRU模型結構如圖2所示,主要分為4個模塊:聊天記錄預處理;DSR模型進行文本特征表示;BGRU提取文本特征;實施文本分類。
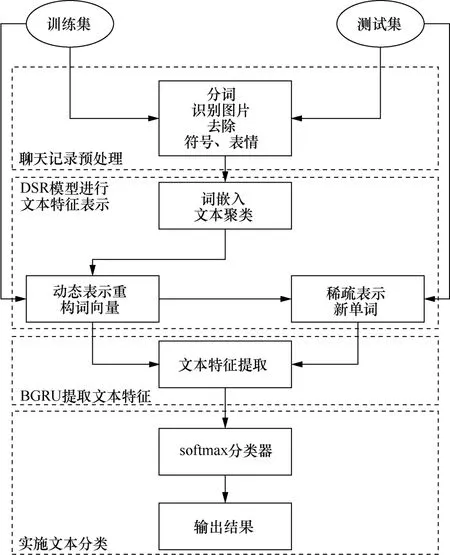
圖2 DSR-BGRU模型結構 Figure 2 The structure of DSR-BGRU model
1.1 聊天記錄預處理
1) 在聊天記錄中,除了文本數據外,還存在符號、表情、圖片、語氣詞等非文本數據,這些非文本數據將會變成亂碼而影響數據處理的結果,因此應先去除這類數據。但犯罪領域的聊天記錄中的圖片內容往往是展示用于犯罪的道具,或者觸犯法律的物品。這類圖片具有較高的取證價值以及鮮明的犯罪領域特征。DSR模型采用識圖工具識別圖片內容,并將其輸出為文本替代聊天記錄中的圖片。
2)犯罪分子在聊天記錄中會用“黑話”來掩蓋自己的犯罪意圖,這類詞往往具有名詞的特性。DSR模型對聊天記錄分詞切割后標注詞性用于后續的加權,標注結果如表1所示,詞性對應含義如表2所示。

表1 分詞及詞性標注結果Table 1 Word segmentation and speech tagging results

表2 詞性對應含義Table 2 Corresponding meaning of word
1.2 文本特征表示
本文提出DSR模型對文本進行特征表示。DSR模型通過聚類算法篩選出語義詞,并通過單詞屬性與語義詞的加權組合對非語義詞詞向量進行特征表示,且將語義詞用于對新單詞進行稀疏表示。
1.2.1 語義詞篩選與重構
語義詞的篩選基于已經預訓練好的詞向量。采用預訓練的詞向量,模型將每個單詞的嵌入向量w組成矩陣。然后對聊天信息T進行聚類分析,將具有相似語義的單詞劃分為同一類。在每個聚類過程中,提取聚類中心作為文本的語義詞。
本文使用AP聚類算法計算文本的聚類中心并作為語義詞,假設文本的嵌入向量集為,將S定義為詞向量之間的相似矩陣,s(i,j)表示wi和wj兩個詞向量之間的相同程度,值為兩個詞向量之間的歐式距離。信息矩陣用A來表示,而吸引信息矩陣用R來表示,R中r(i,j)描述wj適合作為wi的聚類中心的適用性,A中a(i,j)描述wi選擇wj作為其聚類中心的適用性,如式(1)~式(4)所示。
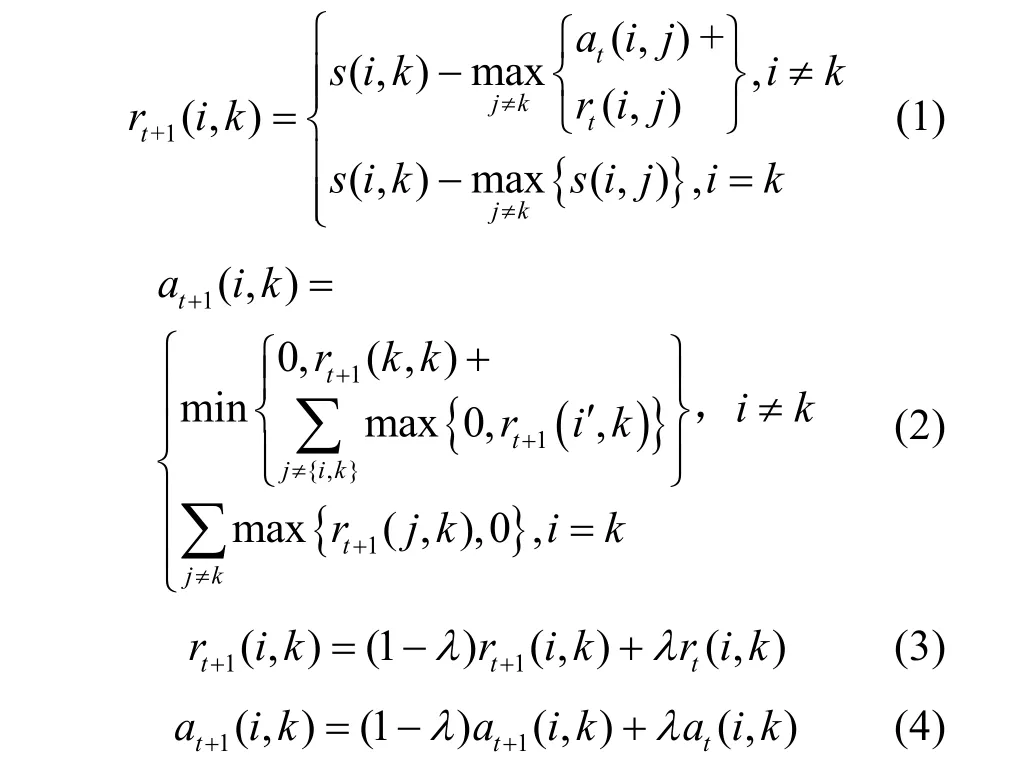
若在多次迭代后聚類中心保持不變或迭代次數超過了設置的迭代次數,將停止計算,并將計算出的聚類中心作為語義詞,最終取A+R最大的wk作為聚類中心。
基于上述方法,DSR模型可以將文本中相似的詞語替換為相應的語義詞并且對訓練集中的每個文本都生成了語義詞集合 SW 。該集合包含m個語義詞 {sw1,sw2,… , swm}。訓練集中文本的語義詞集合會組成詞庫,用于對測試集中的新單詞進行表示,從而進一步提高了模型的自適應能力。
模型結合詞的各項特征以及與詞相近的語義詞來表示訓練集中的非語義詞詞向量。采用式(5)對語義詞集合的詞進行特征融合。
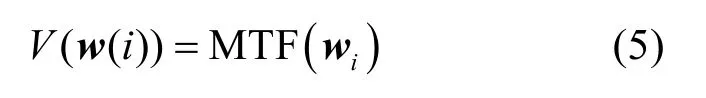
其中,MTF()是特征融合函數。不同于僅使用統計特征來表示所有單詞的傳統單詞袋(BoW),DSR模型結合單詞頻率、單詞詞性、單詞位置這3個特征來重構詞向量。
單詞頻率是單詞在文本中出現的次數。單詞頻率越高,單詞越重要。它是統計功能中常用的詞屬性之一。模型運用函數來計算詞頻因子 frei,如下所示。
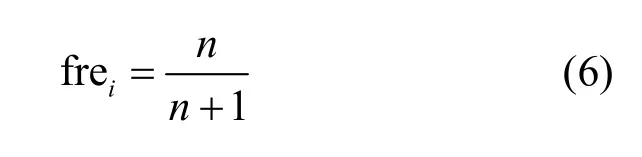
n是單詞wi在文章中的出現次數。非線性函數有兩個優點:一是詞頻因子與詞頻成正比;二是詞頻因數與詞頻成正比。當詞頻增加到一定程度時,詞頻因子的值會減小,符合語言現實。
詞性因子是詞性的量化。對文本語義有較大影響的語義詞大多數是名詞。與名詞相比,形容詞和動詞對句子不會產生太大的影響。在對文本的分類中,詞性的不同產生的影響也不一樣,因此根據詞性將詞分為3類:

單詞在文本中的位置在判斷其重要性方面也具有重要價值。不同的單詞出現在文本的不同位置,對語義的影響也不同。根據如下公式定義位置的影響力:
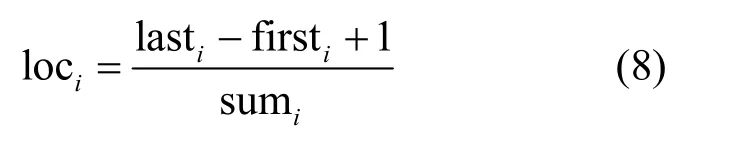
firsti是wi首先出現的位置, lasti是wi最后出現的位置,sumi是文本中單詞的總數。
這里,構造融合特征來表示語義詞,計算如下。
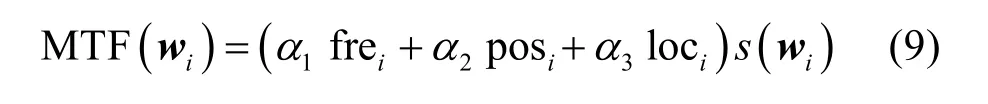
其中,frei是單詞頻率因子,posi是詞性因子,loci是單詞位置因子,α1、α2和α3是特征因子的權重,S(wi)表示 SW 中與wi相近的語義詞。因此,根據式(5),可以使用{V(w( 1)),V(w( 2)),… ,V(w(i) )}j來表示具有i個詞的文本Tj。
1.2.2 稀疏表示
由于訓練集和測試集是隨機分配的,并且詞庫中的語義詞由訓練集中的詞組成,而從測試集提取的詞可能不會出現在詞庫中。如果從測試文本中提取的詞未出現在詞庫中,則將使用其他語義詞來稀疏地表示這些詞。目標函數如下。

或者
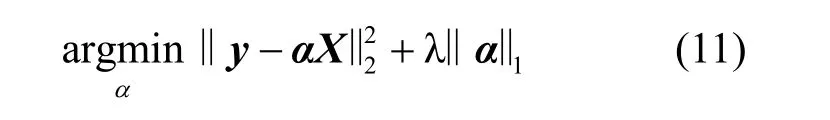
y是需要重建的樣本,X是嵌入向量的矩陣,ε和λ都是小的正常數。
盡管L_1范數在回歸訓練樣本的選擇中起著隱性作用,但迭代解的計算成本很高,用L_2范數代替正則化項。目標函數可以表示為
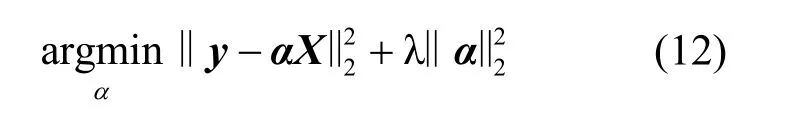
稀疏表示為:
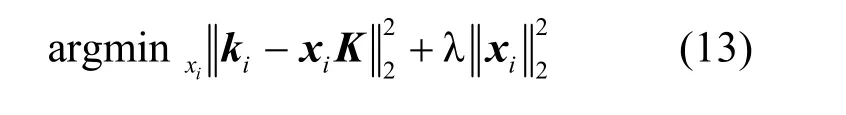
其中,λ是權重參數,ki是測試文本中的第i個新單詞對應的詞向量,xi∈Rm是重構向量,K∈Rm×n由詞庫中的m個語義詞向量組成,n是詞向量維度,最后將被稀疏表示過的新語義詞添加到詞庫中,用來提高模型的適應性。
1.3 文本特征提取
本文使用BGRU模型從訓練的詞向量組成的文本向量矩陣提取文本特征。
聊天記錄中的“黑話”與原有的語義有較大的差別,需要根據上下文才能理解“黑話”的歧義。本文在BGRU模型上進行改進來適應這一特點。BGRU模型由兩個反向的GRU模型組成,GRU模型結構如圖3所示。
圖3中,Zt為更新門,rt為重置門,xt表示t時刻的輸入;ht?1為隱藏層,表示t?1時刻的輸出;σ為Sigmoid函數;ht為隱藏層,表示t時刻的輸出;在xt和ht?1輸入GRU之前分別添加固定值β和1 ?β作為權重來控制xt和ht?1的輸入影響。GRU 模型中各個門計算如式(14)~式(17)所示。
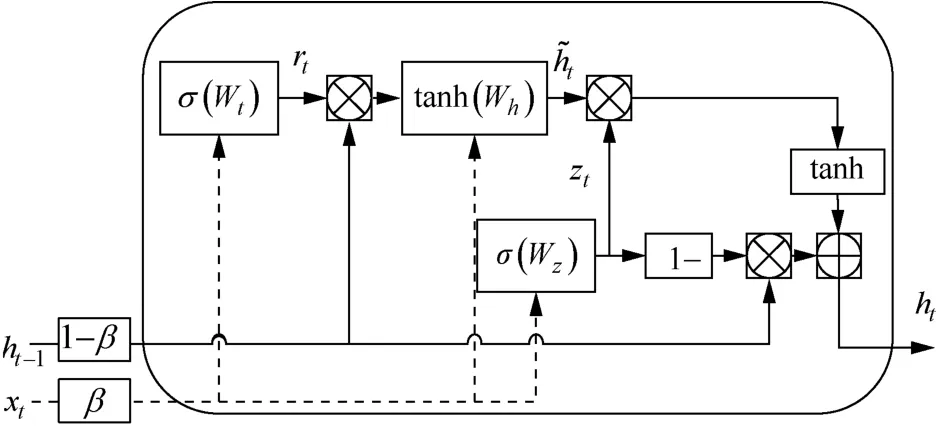
圖3 GRU模型結構 Figure 3 Structure of GRU model
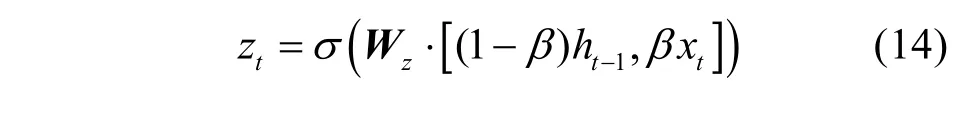
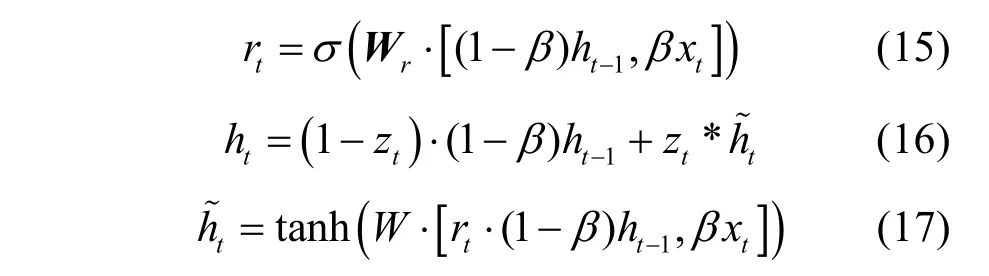
其中,Wz表示更新門連接的權重矩陣,Wr表示重置門連接的權重矩陣,“?”表示兩個矩陣元素的相乘。
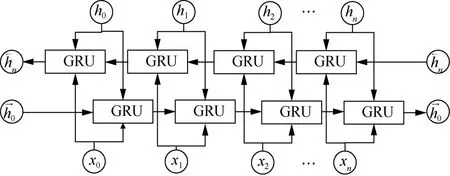
圖4 BGRU模型結構 Figure 4 Structure of BGRU model
BGRU模型中每一個時刻狀態計算如式(18)、式(19)所示。輸出則由這兩個方向的GRU的狀態共同決定,如式(20)所示。
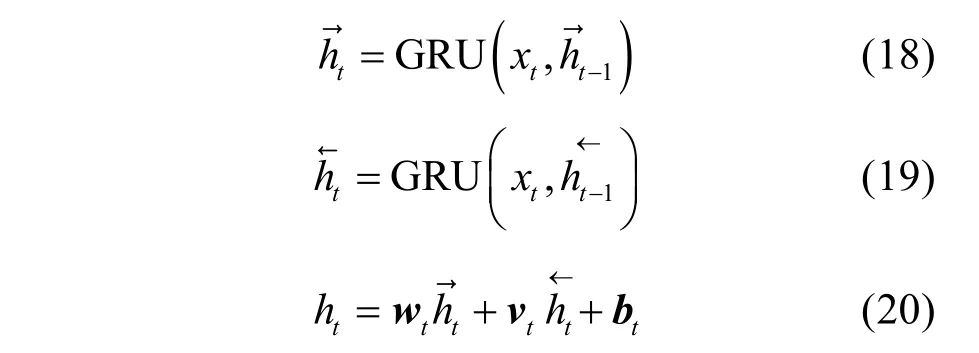
其中,wt表示正向輸出的權重矩陣,vt表示反向輸出的權重矩陣,bt表示t時刻的偏置矩陣。
經過反復測試,β為0.2時,分類效果最好,這時,BGRU模型提取的文本特征受到上下文的影響較大,這也符合聊天記錄中的“黑話”特點。
1.4 文本分類
本文通過Keras框架搭建BGRU模型來提取文本特征,其中模型的組成部分有:輸入層使用DSR模型進行詞的向量表示組成的文本矩陣;大小為64的BGRU隱藏層;從模型的兩個方向輸入的輸入序列;通過隱藏層提取文本的上文信息特征和文本的下文信息特征;用式(21)結合隱藏層的兩個方向。

其中,Tijt表示在t時刻輸入的第j個文本的i個詞向量組成的文本矩陣;hijt表示在t時刻BGRU的輸出。
輸出層softmax的大小與文本分類的類別一致,數據二分類后結果存在兩個神經元,分別代表正常與異常。
通過softmax函數進行文本分類,分類函數如式(22)所示。
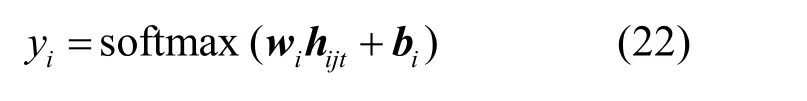
其中,wi表示特征提取層到輸出層的權重系數矩陣,bi表示相應的偏置,hijt表示在t時刻特征提取層的輸出向量。
2 實驗分析
本文實驗的目的如下。
1) 分析DSR模型中不同單詞屬性加權方法對分類效果的影響以及對新單詞的稀疏表示方法的效果。
2) 分析犯罪領域的聊天記錄存在的“黑話”現象特點。
3) 比較不同文本分類模型的性能。
2.1 實驗環境
本文實驗環境為x86平臺,Intel CPU,內存16 GB,硬盤100 GB。操作系統Windows10家庭版,使用TensorFlow的深度學習庫 Keras 進行模型搭建與測試。
2.2 數據集
實驗數據來自實驗所用Android智能手機。手機中有與1 000個微信好友的聊天記錄,這1 000個會話內容包括正常聊天和與犯罪相關的聊天。正常聊天和與犯罪相關的聊天主題如表3所示。本文將正常聊天內容標注為“正常文本”,與犯罪相關的文本標注為“異常文本”,這些聊天記錄共包含24 100條聊天短文本。從聊天記錄中隨機抽取一些數據集,包括正常、異常兩類,每個類別的數據集按4:1的比例分為訓練集、測試集兩部分。數據結果用csv格式進行存儲,如表4所示。

表3 聊天記錄主題Table 3 The topic of chat record
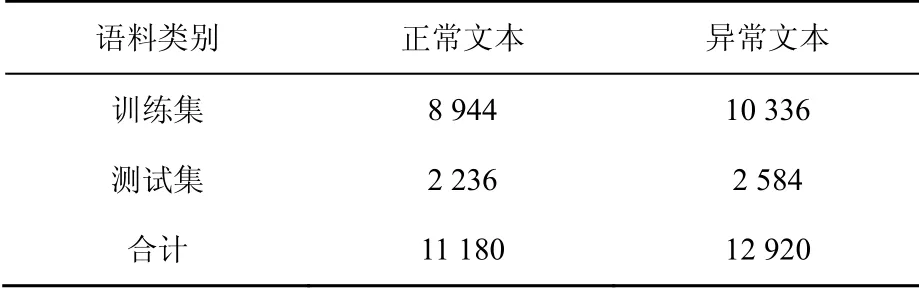
表4 數據集劃分Table 4 Data set division table
另外,如表5所示,本文使用4個數據集來評估DSR模型的性能,其中ChnSentiCorp_htl_all來自譚松波的“酒店評論數據集”,waimai_10k是Github網站“某外賣平臺收集的用戶評價數據集”,online_shoping_10_cats是Github網站“各電商平臺的用戶評價數據集”,weibo_senti_100k來自于新浪微博評論數據集。由于關于異常文本分類的數據集較少,因此本文挑選常見的用于文本情感傾向判別的中文數據集。數據集中80%為訓練集,其余文本為測試集。
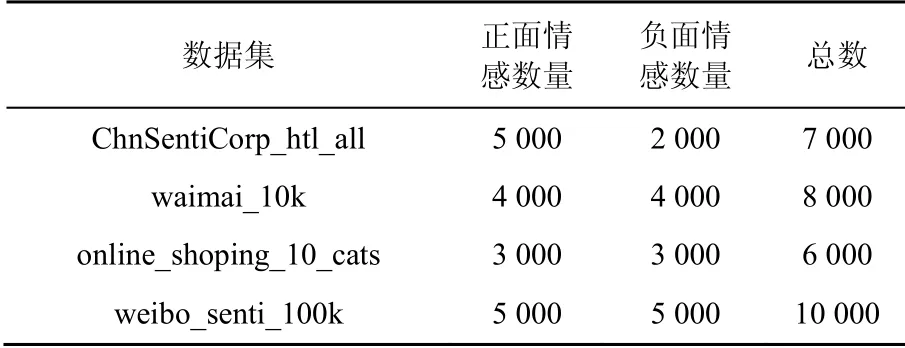
表5 中文數據集Table 5 Chinese data set
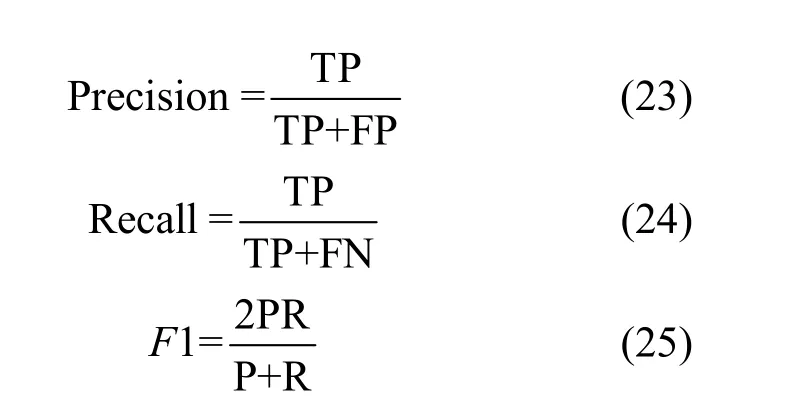
2.3 模型評估
本文采用精確率、召回率和F1值對分類結果進行評估。其中,FN(false negative)、FP(false positive)和TP(true positive)分別表示正常文本預測為異常文本數量,異常文本預測為正常文本數量,正常文本預測為正常文本數量。計算如下所示。
2.4 BGRU模型超參數
實驗采用參數固定法,確定BGRU模型的超參數,如優化器、損失函數、激活函數等。
本文使用的是BGRU模型訓練超參數如表6所示。

表6 BGRU模型訓練超參數Table 6 BGRU model training super-parameter
經過反復實驗測試,當采用表6的超參數,以準確率作為評估標準,訓練輪數達到27時,實驗效果最好。精確率隨輪數變化如圖5所示。
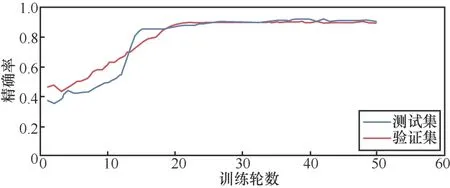
圖5 精確率隨輪數變化 Figure 5 The graph of accuracy with the number of rounds
2.5 DSR模型性能評估
在NLP中有很多量化單詞權重的方法,常見的有TF-IDF加權和單詞頻率加權。本文將單詞的位置、頻率、詞性特征相結合來量化單詞權重。在實驗中,本文研究比較了這些量化單詞權重方法的效果。圖6中的結果表明,加權組合比其他加權方法更有效。
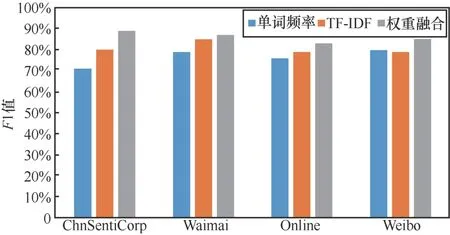
圖6 不同單詞屬性加權方法的影響 Figure 6 Influence of different word attribute weighting methods
為了驗證稀疏表示方法的有效性,本文在4個數據集上測試了去掉稀疏表示方法的情況下,各方法的F1值。
如圖7所示,稀疏表示方法提高了大多數數據集上分類器的性能。ChnSentiCorp數據集上的優化性能較差,原因是訓練集與測試集中的詞重合比較大,因此動態表示添加的新詞較少。其他數據集上訓練集和測試集詞語重合較少,但詞義相近。這提高了稀疏表示的效果。
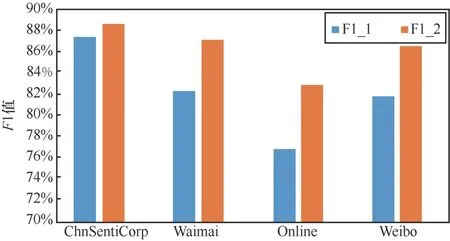
圖7 稀疏表示的影響 Figure 7 The influence of sparse representation
圖7中F1_1展示的是去掉稀疏表示的分類結果的F1值,F1_2展示的是加上稀疏表示的分類結果的F1值。
2.6 “黑話”現象探討
犯罪領域的聊天記錄存在“黑話”現象。本文比較了被用作“黑話”的單詞在數據集中正常文本和異常文本中的特征表示。由于單詞的特征表示維度較高,本文使用sklearn算法庫中的T-SNE算法進行降維可視化,結果如圖8所示。
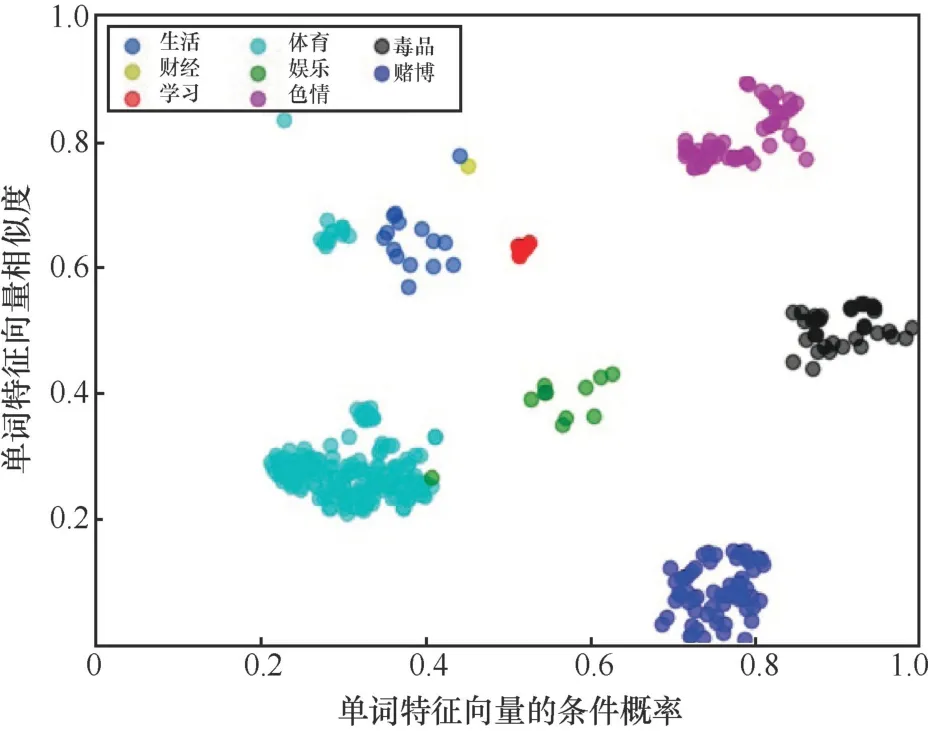
圖8 “黑話”足球在不同文本領域的特征表示 Figure 8 Feature representation of "slang" football in different text fields
如圖8所示,“黑話”在異常文本領域中分布較廣,在正常文本中集中為特定領域。而且不同領域的“黑話”特征表示相近,異常文本中不同領域的“黑話”特征表示相距較遠。這說明“黑話”在犯罪領域中語義不固定,且與原義有較大偏差。“黑話”的歧義問題也是自然語言處理中經典的“一詞多義”問題,所以利用上下文識別其真實意義是解決這一問題的方法。但在應用時應根據“黑話”的特點,進行特征表示時減小詞本身的含義影響,放大上下文的影響。
2.7 模型對比
為了充分驗證DSR-BGRU文本分類模型的有效性、增強對比性,本文不僅與其他犯罪文本分類研究進行對比,而且采取目前比較流行的面向社交媒體的文本分類模型進行比較分析。這些研究的詳細信息如下。
1) DSR-BGRU:本文提出的文本分類模型,分別運用DSR模型和BGRQ模型對文本進行特征表示及提取。
2) 文獻[2]:文獻[2]將PageRank算法和關系網絡相結合,提出一種ARPR算法。該算法采用TF-IDF方法提取群聊人員的群聊涉毒關鍵詞,并對涉毒關鍵詞在涉毒嫌疑程度排序中的貢獻進行度量;然后以層次分析法引導聚合各維度信息計算得到的嫌疑人員權重為權重系數,以好友關系為鏈接建立關系網絡作為PageRank的入度與出度來計算相對應的PageRank權值。
3) 文獻[14]:文獻[14]對單詞的特征表示訓練方法進行了改進,根據分類任務目標對預訓練的詞嵌入基于對應領域的詞庫進行針對性的重構來增強分類效果。
4) 文獻[15]:文獻[15]提出了BLS(broad learning system)模型用于文本分類,該模型在LSTM的基礎上進行了改進,引入了注意力機制來關注重點單詞,并且增加了遺忘門來控制上下文信息的傳遞。
5) 文獻[16]:文獻[16]提出了一種被稱為DE-CNN的神經網絡,該網絡可以將與上下文相關的概念合并到卷積神經網絡中,以進行短文本分類。模型首先利用兩層分別提取概念和上下文,使用關注層提取與上下文相關的概念;然后,將這些概念合并到文本特征表示中以進行短文本分類。
6) 文獻[17]:文獻[17]使用BERT預訓練語言模型對短文本進行句子層面的特征向量表示,并使用softmax對其進行分類。
由表7可以看出,本文提出的模型在準確率、召回率、F1這3個指標上都有較明顯的優勢。文獻[2]采用的模型各項指標均最低,原因在于它采用TF-IDF方法提取群聊人員的群聊涉毒關鍵詞,對于“黑話”的一詞多義、更新速度快的特點難以適應,盡管是適用于分類涉毒領域的聊天文本,但在其他犯罪領域的聊天文本上表現較差。文獻[14]與文獻[2]在數據集上表現效果相近,是因為采用類似的方法強化在單一文本領域的表現能力,適應性較弱。文獻[17]與文獻[15]相比,性能較弱。是因為相比文獻[17]引入的注意力機制,文獻[15]根據分類目標對預訓練的詞嵌入能更增強模型的特征表示能力。文獻[16]相比文獻[15]和文獻[17],將注意力機制結合卷積層神經網絡,有效捕捉上下文語法語義以及更深層次的信息,從實驗結果來看性能表現較好。
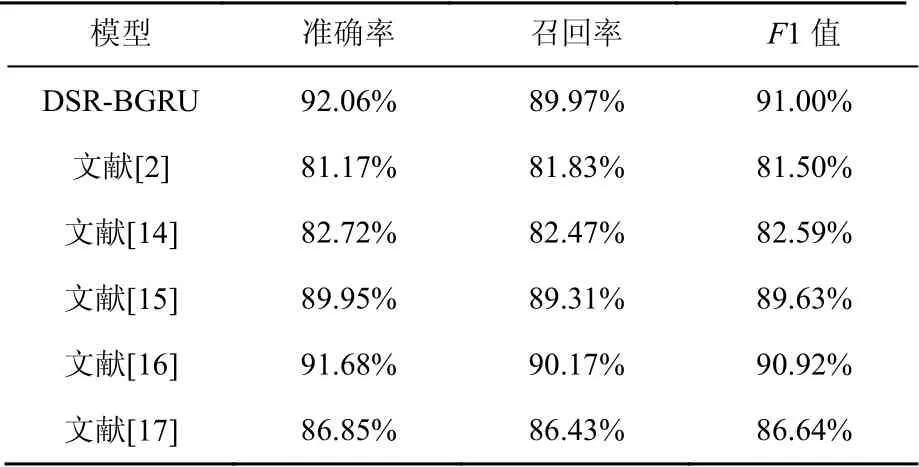
表7 對比實驗結果Table 7 Results of the compare experiment
從對比實驗的結果來看,能有效捕捉句子中的序列、上下文、語法語義以及更深層次的信息的模型在犯罪領域的聊天文本分類上有不錯的表現能力。這是因為犯罪領域中“黑話”一詞多義的特點要求模型從上下文語境中提取深層次信息的能力。本文提出的DSR-BGRU模型針對BGRU模型做的改進使得在犯罪領域的聊天文本分類上具有一定優勢。
2.8 模型缺點
本節對數據集中分類錯誤的聊天文本進行了探討。在分類錯誤的聊天文本中,表情符、特殊符號作為“黑話”來掩蓋真實的犯罪意圖。本文研究提出的模型在預處理環節丟棄了表情符和特殊符號,這可能會丟棄潛在的“黑話”,從而造成誤判。
此外,本文針對BGRU模型做的改進是添加了固定參數β來控制輸入單詞與上下文對語義的影響。這種單一權重的使用降低了“黑話”單詞對語義的影響,也降低了其他單詞對語義的影響。
3 結束語
本文提出一個文本分類模型用于解決數字取證時遇到的聊天文本分類難題。本文提出DSR模型將語料中的詞語用高維的詞向量表示,接著將詞向量輸入改進后的BGRU模型中提取特征,最后連上一個softmax輸出層,這樣就建立了一個文本分類模型。該模型使用DSR對文本預訓練來從語義層面對聊天文本進行特征表示,再使用改進后的BGRU對使用這些詞向量組成的文本提取上下文特征,從而能夠更好地準確理解評論文本的語義信息。實驗結果表明,使用DSR-BGRU模型能夠更加準確地完成識別和提取與犯罪事件有關聊天證據。
但DSR-BGRU模型存在一定不足,其無法處理聊天文本中的表情符和特殊符號以及使用固定參數控制輸入單詞與上下文對語義的影響。針對這些不足,可以對所有表情符號與特殊符號生成獨特的特征向量后再引入文本分類中以及引入注意力機制[8],根據單詞詞義或其他屬性變化參數值來控制輸入單詞與上下文對語義的影響。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
開放教育研究(2020年2期)2020-03-31 01:54:14
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
七彩語文·低年級(2011年19期)2011-04-12 00:00:00
