基于加權共享近鄰與累加序列的密度峰值算法
2022-04-18 10:56:16王芙銀張德生肖燕婷
計算機工程 2022年4期
關鍵詞:定義
王芙銀,張德生,肖燕婷
(西安理工大學 理學院,西安 710054)
0 概述
聚類作為一種無監督學習方法,是數據挖掘領域[1]的重要技術之一。聚類的主要目的是依照所定義的聚類準則,將一組雜亂的數據中具有相似特征的數據點劃歸為一個類簇,同時使得不同類簇之間具有顯著差異[2]。在如今萬物互聯、大數據蓬勃發展的當下,所產生的數據量也正在爆炸式增長,因此,尋求一種高效的數據聚類方法顯得尤為重要。近年來,許多學者相繼提出了多種不同的聚類算法,按照不同的算法原理可將其分為基于劃分的聚類、基于層次的聚類、基于網格的聚類、基于密度的聚類、基于模型的聚類這五大類,這幾類不同的聚類算法各自都具有獨特的優勢并得到了廣泛研究與應用。
DBSCAN[3]作為一種典型的基于密度的聚類算法,能夠有效識別任意形狀的數據,且具有較好的聚類效果,但該算法在聚類過程中易受鄰域參數的影響,其結果往往需要反復調參才能確保精確。RODRIGUEZ 等[4]于2014 年提出一種新的基于密度的聚類(DPC)算法,該算法因具有原理簡單、高效等優點,自提出以來便引起許多學者的關注,且被廣泛應用于圖像處理[5]、生物醫學[6]、文檔處理[7]等領域,但是,DPC 算法也存在一些缺陷,如聚類結果受局部密度及其相對距離的影響、截斷距離需要人為設定且參數的選取較為敏感、聚類中心的選取需人為參與決策、算法難以處理密度分布差異較大和復雜的流形結構數據,這些問題提高了算法在聚類過程中的主觀性與不穩定性。
為提高DPC 算法的適用性,很多學者都對其做了相應的改進。DU 等[8]提出一種基于KNN 的改進密度峰值聚類(DPC-KNN)算法,將KNN 與主成分分析法引入局部密度的計算過程,充分考慮數據的鄰域分布特征,從而更好地識別邊界點的類別。PARMAR 等[9]采用殘差來測量鄰域內的局部密度,提出一種基于殘差的密度峰值聚類(REDPC)算法,其能夠更好地處理包含各種數據分布模式的數據集。LIU 等[10]指出DPC 算法中如局部密度及最短距離度量方法、剩余點分配策略等所存在的一些問題,提出一種基于共享近鄰的聚類方法,該方法通過共享近鄰重新定義密度及其距離的計算方式,最后設計兩步分配方式對剩余點進行分配,其有效提高了算法的聚類性能。XIE 等[11]提出一種基于模糊加權K 近鄰的改進DPC(FKNN-DPC)算法,利用K個最近鄰個體之間的距離之和來衡量密度,并用一種新的分配方式對剩余點進行分配。CHENG 等[12]提出一種新的基于自然鄰居優化的DPC 算法,該改進算法可以很好地反映數據的分布,且無需任何參數。HOU 等[13]提出僅基于相對密度關系的聚類中心識別準則,以增強密度峰值聚類算法的聚類效果。FLORES 等[14]通過檢測一維決策圖中數據點之間的間隙來自動確定聚類中心。LIANG 等[15]提出一種基于分治法的改進DPC 算法,該算法在不需要任何先驗條件的情況下能夠自動尋得聚類中心。QIAO等[16]引入一種新的不對稱度量指標,增強了算法查找邊界點的能力,解決了DPC 算法在分布不均的數據上聚類效率不高的問題。XU 等[17]提出一種具有密度敏感相似性的密度峰值聚類(RDPC-DSS)算法,其有效提高了流形數據的聚類精度。
本文提出一種基于加權共享近鄰與累加序列的密度峰值(DPC-WSNN)算法。定義一種新的基于加權共享近鄰的局部密度度量公式,替代DPC 中根據截斷距離dc所定義的密度公式,避免因dc選取不當而影響聚類效果,同時,利用加權共享近鄰并進一步考慮全局一致性,以有效處理不同類簇數據集分布不均的情況。在選取聚類中心的過程中,在原有決策值γi=ρiδi的基礎上,重新定義γ的計算方式,借鑒ZHOU 等[18]在灰色預測模型中所定義的一階累加序列生成方式,產生一組γ的累加序列,根據所產生的累加序列數值變化情況來實現類簇中心的自動選取,從而避免手動選取聚類中心所帶來的誤差。
1 密度峰值聚類算法
DPC 算法在實現過程中主要基于以下2 個假設:
1)聚類中心被一群密度較低的點包圍。
2)聚類中心與其他高密度點之間的最短距離足夠遠。
基于上述2 個假設,選取一個合適的截斷距離參數dc,用來求解數據點的局部密度ρ及其相對距離δ值,最后根據決策圖找出聚類中心并分配剩余點。對于數據集X={x1,x2,…,xn},dij表示數據點i與點j間的歐氏距離。數據點的局部密度有2 種不同的定義方式:
1)在截斷核的定義下,點i的局部密度ρi定義為:

當dij<dc時,χ(dij-dc)=1;否則,χ(dij-dc)=0。
2)在高斯核的定義下,ρi如式(2)所示:

點i到其他高密度點間的最短距離δi定義為:

當計算出所有點的局部密度ρi以及相對距離δi后,選擇ρi與δi均較大的點作為聚類中心,將剩余點分配給與之較近的高密度點所在的類簇中從而完成聚類。
2 DPC 算法改進
2.1 基于加權共享近鄰的局部密度改進
DPC 算法定義了2 種密度計算方式,2 種方式都是以歐幾里得距離來衡量數據點的密度,但是歐幾里得距離只考慮數據點之間的局部一致性特征,忽略了全局一致性特征,因此,當數據樣本點分布不均時,基于歐幾里得距離得到的密度通常不能準確地捕捉到固有的數據結構,最終導致聚類性能下降。為了適應更多復雜且分布不均的數據集,本文將共享近鄰引入密度計算中,充分考慮樣本的整體分布,以更好地平衡樣本點的全局一致性與局部一致性。共享近鄰[10]與樣本間的相似度定義如下:
定義1(共享近鄰)對于數據集X中的樣本點xi與xj,點xi的K 近鄰記為Γ(xi),點xj的K 近鄰記為Γ(xj),則點xi與xj的共享近鄰SNN(xi,xj)定義為:
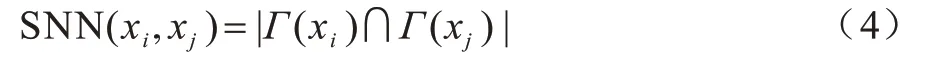
定義2(樣本間的相似度)根據共享近鄰的定義,樣本點xi與xj間的相似度sij定義為:
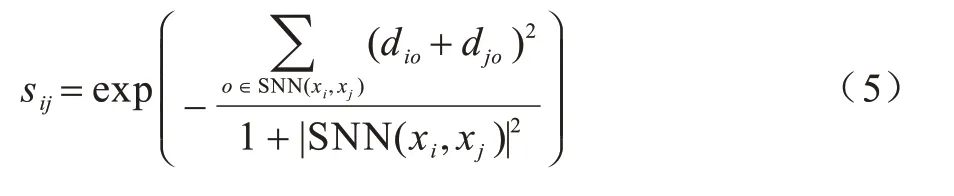
其中:ο為共享近鄰中所取的樣本點;|SNN(xi,xj)|表示屬于共享近鄰的樣本數目,其值越大,表明點i、j的相似度越大,(diο+djο)越小,點i、j之間的相似度也越大。當2 組樣本的共享近鄰數目相等時,如圖1 所示,點i和j、點i和k的共享近鄰個數 都為1,且 此時dij=dik,根據三角形的三邊關系可知,有根據式(5)所定義的相似度,則認為點i與點k間的相似度大于點i與點j間的相似度,這樣更能反映空間中樣本點的分布特征。
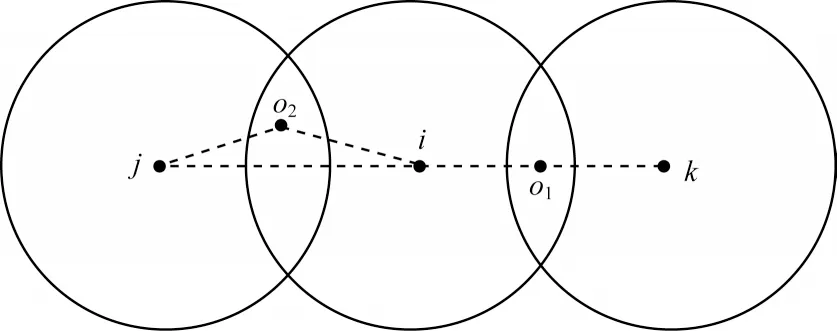
圖1 共享鄰居示意圖Fig.1 Schematic diagram of shared neighbors
此外,在面對不同密度和大小的類簇時,位于數據密集區域的樣本點和位于數據稀疏區域的樣本點對聚類中心選取的貢獻度不一樣,因此,在解決數據分布不均的問題上,除對數據進行過采樣和欠采樣調節外,對樣本點的貢獻度進行加權處理也可以起到很好的平衡作用。本文以樣本點間的共享近鄰數作為密度的重要衡量指標,以對每個樣本點所在的區域相似度進行權重調整,為此,引入圖2 所示的sigmoid 函數,其定義如下:


圖2 sigmoid 函數圖像Fig.2 Image of the sigmoid function
相比于一元一次函數,sigmoid 函數在一定程度上可以對數據相似度進行權重調整,減少了因數據分布不均而帶來的誤差。本文將sigmoid 函數引入密度計算中,以互近鄰點的數目作為變量x值,分析可知,在式(6)中,當共享近鄰數目較多時,表明2 個樣本點間的相似度較高,有較大的可能性會被聚為一類,通過圖2 函數變化圖像可知,當互近鄰點的數目足夠多時,其函數值為1,這表明在處理高密度區域的點時,所加權重接近1,對于高密度樣本點而言,其本身就有較大概率被選作聚類中心,此時可令其相似度的權重為1,當互近鄰點的數目不斷減少或為0 時,其權重則由1 非線性遞減到0.5,這時非聚類中心點與聚類中心有了更加明顯的區分,能夠使得式(5)所定義的相似度更具合理性和準確性。經過加權后,局部密度ρi如定義3 所示。
定義3(局部密度)對于樣本點i,根據其相似度定義密度ρi為:
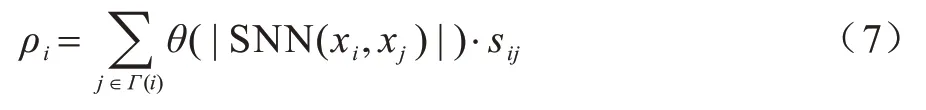
通過定義3 所給出的密度度量公式,可計算出數據集中所有點的局部密度及相對距離。
為了進一步說明所改進的密度在處理分布不均數據集時的有效性,以Pathbased 數據集為例,DPC算法與加權共享近鄰的改進DPC 算法的決策圖如圖3 所示。從圖3(a)可以看出,DPC 的決策圖在確定聚類中心時很容易將第3 個聚類點處理為噪聲點,從而導致最終聚類結果出現偏差;從圖3(b)可以看出,對密度進行改進后,決策圖中聚類中心分布在右上角,均位于高密度區域,通過該決策圖可以準確選出目標聚類中心。實驗結果表明,改進DPC 可以對數據進行全局考慮,解決數據集中的分布不均問題,從而確定正確的聚類中心。
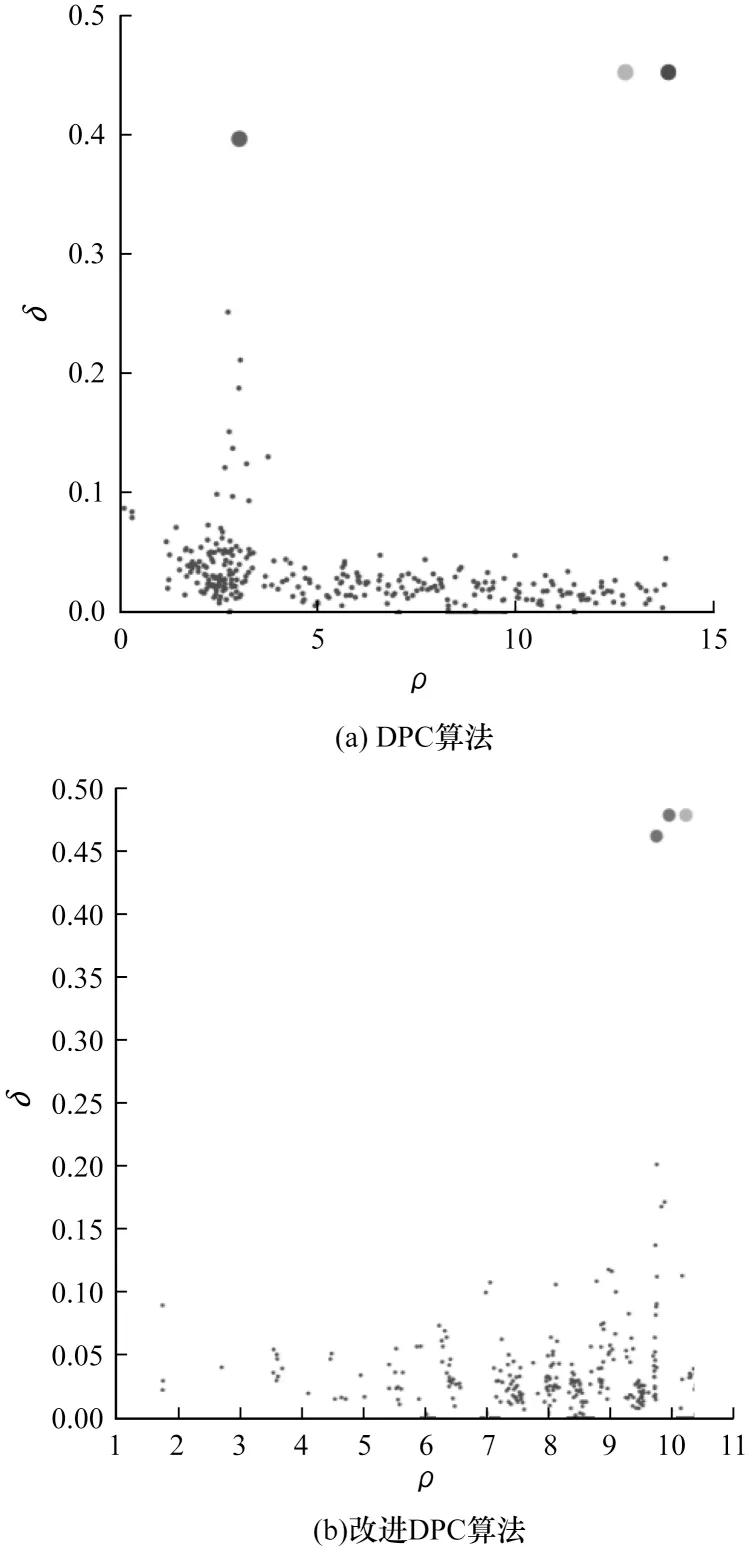
圖3 2 種算法的決策圖對比Fig.3 Comparison of decision diagrams of two algorithms
2.2 聚類中心選取方法改進
DPC 算法在選取聚類中心時,需要人為參與決策,通過決策圖來選取ρ與δ均較大的點,但對于聚類中心較多的數據集,這種方法顯得復雜低效,而且出現錯選的概率較大。本文提出一種新的聚類中心選取方法,首先定義決策值γi如下:

為消除ρi與δi量綱不同而造成的誤差,對ρi與δi進行歸一化處理,將歸一化后結果的乘積作為決策值γi。本文將γi進行降序排列得到一組降序值,將其記為γ′,根據聚類中心的性質可知,在γ′=[γ1,γ2,…,γn]中,只有前面幾個較大值所對應的點應被選作聚類中心。對此,本文參考文獻[18]所定義的一種新的非負序列累加生成方法,對于非負序列定義其累加序列為其中:
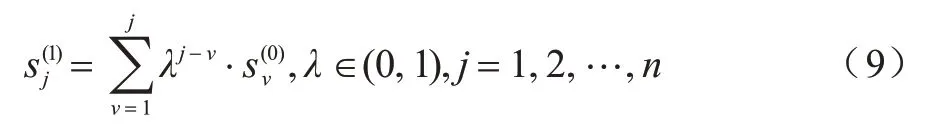
觀察式(9)可知,由于λ∈(0,1),因此該序列在累加過程中,靠前位置信息的影響權重在不斷降低,而信息越靠后,權值越大。
對于γ′而言,需要保留前面一部分較大的值,因此,本文對式(9)進行調整,使其在累加過程中不斷降低序列靠后位置信息的權值,而增大靠前位置信息的權重,使其更好地滿足本文的需求。修改后的累加定義如下:

由于γ′為降序排列的序列,因此在逐步累加的過程中,累加序列的值也越來越接近,最終大量的點會不斷地集中在一起。在累加序列γ(t)中,定義均值μ為:

在選取聚類中心時,只需在γ(t)序列中挑選比均值μ小的點,將其作為聚類中心。以類別數為7 的Aggregation 數據集為例,圖4 展示了其γ′的累加序列分布情況(彩色效果見《計算機工程》官網HTML版),圖4(b)是圖4(a)中方框線內的局部放大圖,以便更好地觀察均值μ的位置分布。從圖4(b)可以看出,在累加過程中,大量的點不斷地集中在一起,紅色點u表示這組序列的均值μ,其也位于堆積點附近,而聚類中心點對應的累加值則位于均值的前方,此時只需選取那些累加值小于均值的點作為中心進行聚類即可,即將前7 個γ′所對應的點選取為聚類中心。因此,將累加序列γ(t)的均值作為聚類中心和非聚類中心的臨界點,可以準確選取聚類中心,從而實現聚類中心的自適應。

圖4 Aggregation 數據集的γ(t)序列分布Fig.4 γ(t)sequence distribution of Aggregation dataset
綜上,聚類中心選取策略步驟為:
1)根據式(8)和式(11)得到累加序列γ(t),并求得其均值μ,將小于均值μ的γ′個數作為聚類中心數目m。
2)將前m個γ′值所對應的點選取為聚類中心。
2.3 算法描述
改進DPC 算法描述如算法1 所示:首先,計算樣本點間的距離矩陣;然后,根據式(3)、式(7)分別計算相對距離與局部密度,在求得每個點的距離與密度后,根據式(11)、式(12)自動選擇聚類中心;最后,按照DPC 的分配策略對剩余點進行分配聚類。
算法1DPC-WSNN 算法


2.4 算法復雜度分析
對于含有N個樣本點的數據集,DPC 算法的時間復雜度為O(N2)。對于本文所提的DPC-WSNN 算法,設近鄰數為K,其計算局部密度ρi是基于共享近鄰的,時間復雜度為O(KN);在選取聚類中心時,需多計算一個決策值γi,其時間復雜度為O(N)。綜上,本文所提DPC-WSNN 算法的時間復雜度為(O(N2)+O(KN)+O(N))~O(N2)。因此,相較于DPC 算法,DPC-WSNN算法的時間復雜度并未增加。此外,在相關算法中,FKNN-DPC 算法的時間復雜度為O(N2),DBSCAN 算法的時間復雜度為O(N2),AP 算法與K-Means 算法的時間復雜度分別為O(N2lbN)與O(N)。
3 實驗結果及分析
3.1 實驗數據集
為了評估本文所提算法的有效性,采用如表1、表2 所示的8 個合成數據集和8 個UCI 數據集對其進行驗證。

表1 合成數據集Table 1 Synthetic datasets
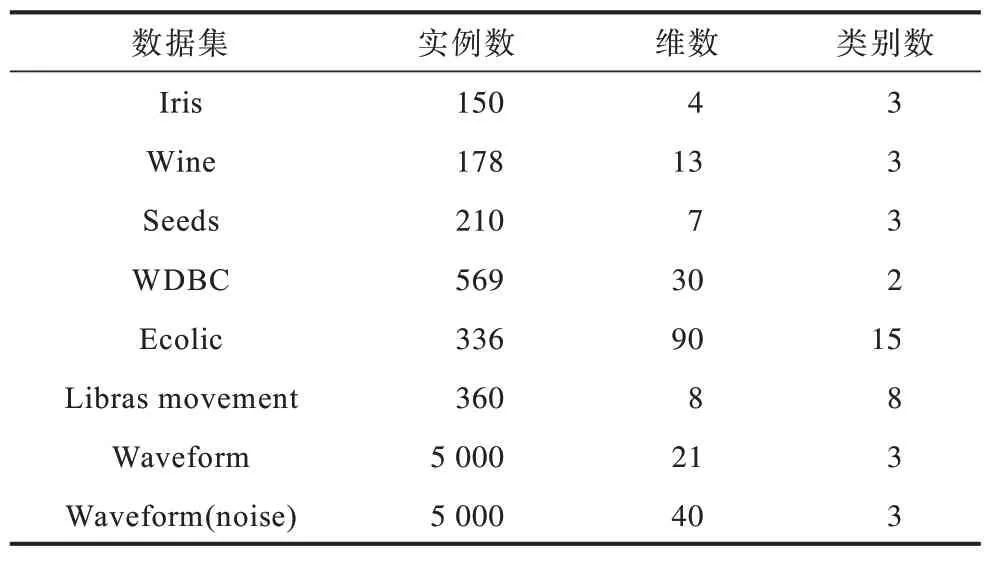
表2 UCI 數據集Table 2 UCI datasets
3.2 評價指標
在實驗中,本文將DPC-WSNN 算法的聚類結果與FKNN-DPC、DPC、DBSCAN、AP、K-Means 的聚類結果進行比較,評價指標選取FM 指數(FMI)[19]、調整蘭德指數(Adjusted Rand Index,ARI)[20]和調整互信息(Adjusted Mutual Information,AMI)[21]。各指標具體如下:
1)FMI 指標。FMI 是成對精度與召回率的幾何均值,定義如下:
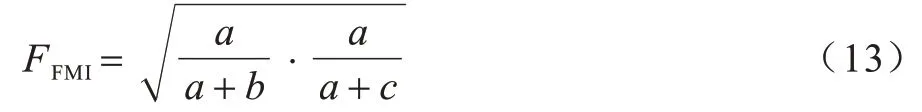
其中:a表示在C和C*中都屬于同一類的數據點對數;b表示在C中屬于同一類但在C*中不屬于同一類的數據點對數;c表示在C*中屬于不同類但在C中屬于同一類的數據點對數。FMI 指標的取值范圍是[0,1],數值越大表示聚類效果越好。
2)ARI 指標。蘭德指數(RI)的定義式為:

其中:a代表在C和C*中都屬于同一類的數據點對數;b代表在C*中屬于不同類但在C中屬于同一類的數據點對數代表數據集中可組成總元素的對數。在使用RI 指標時,不能保證類別標簽在隨機分配的情況下其值接近0。因此,本文引入ARI[20]來解決這一問題,ARI 指標的定義式為:
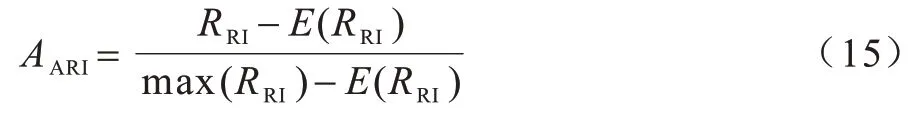
其中:E(RRI)表示RI 的數學期望。ARI 的取值范圍為[-1,1],值越大表示聚類結果越精確。
3)AMI 指標。與ARI 相似,AMI 也是一種常見的聚類評價指標,其定義式為:

其中:H(A)、H(B)表示2 個類別標簽的熵。AMI 是基于互信息(MI)來衡量聚類效果的類別信息,E(MMI)表示MI 的數學期望。AMI 的取值范圍是[-1,1],值越接近1 表示聚類結果越好,即與真實結果越吻合。
3.3 算法參數設置
為了更好地測試算法的聚類效果,對各對比算法進行參數調優。DPC-WSNN 算法和FKNN-DPC算法需要設定樣本近鄰數K,該參數可根據不同數據集在5~30 之間擇優選取。DBSCAN 算法需要設定鄰域半徑ε和鄰域內包含的最少樣本數Minpts,其中,鄰域半徑ε以0.01 為步長,在0.01~1 之間選取,鄰域內包含的最少樣本數Minpts 在5~30 之間選取。AP 算法沒有通用的規則來選取參數,本文考慮將參數搜索上限設置為最大相似度的幾倍,逐漸縮小搜索范圍[10]。由于K-Means 算法中類簇中心的選取對聚類結果有較大影響,因此對每個數據集進行30 次重復實驗,取最優結果。
3.4 結果分析
選取8 種合成數據集和8 種UCI數據集,對本文所提算法進行測試和評價,并將其實驗結果與FKNN-DPC、DPC、DBSCAN、AP、K-Means 進行對比,各算法的3 種評價指標值如表3~表6 所示,其中,加粗值表示最好的聚類結果。從表3、表4可以看出,本文所提DPC-WSNN算法相比其他對比算法具有更好的聚類表現,尤其對于Jain 數據集,本文算法的聚類準確率較對比算法具有大幅提升。從表5、表6 可以看出:對于維度高且樣本點密度變化大的數據集,DPC、DBSCAN、AP、K-Means的聚類效果都不理想,無法得到較高的聚類指標值;FKNN-DPC 算法在Wine 數據集上達到最優,而在其他數據集上的聚類效果略差于DPC-WSNN 算法,由于DPC-WSNN 算法在DPC 的基礎上引入SNN 來對密度公式進行改進,充分考慮了數據分布稀疏的情況,進而可以得到更準確的密度。DPC-WSNN 在UCI 數據集上的聚類指標值整體更高,在所有對比算法中,其聚類表現最優,在其他數據集上也能達到較好的聚類效果。相比DPC 算法和其他幾種對比算法,DPC-WSNN 算法在處理大部分問題上均能達到較好的效果。

表3 6 種算法在前4 個合成數據集上的聚類結果比較Table 3 Comparison of clustering results of six algorithms on first four synthetic datasets
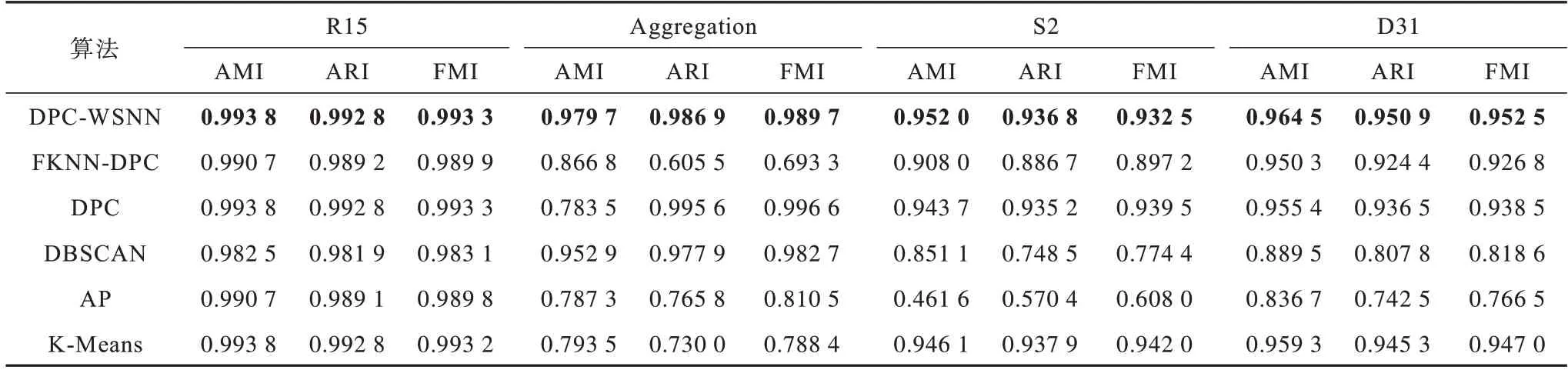
表4 6 種算法在后4 個合成數據集上的聚類結果比較Table 4 Comparison of clustering results of six algorithms on last four synthetic datasets
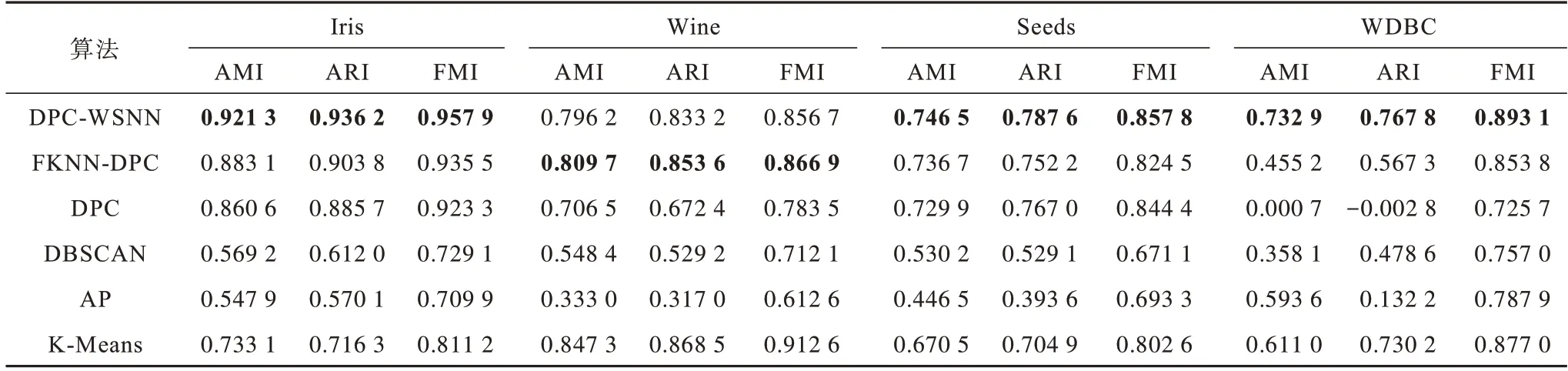
表5 6 種算法在前4 個UCI 數據集上的聚類結果比較Table 5 Comparison of clustering results of six algorithms on first four UCI datasets
圖5~圖7分別為DPC-WSNN、FKNN-DPC、DPC、DBSCAN、AP、K-Means 這6 種對比算法在Jain 數據集、Flame 數據集、Pathbased 數據集上的聚類效果(彩色效果見《計算機工程》官網HTML 版),圖中不同顏色的點被分配到不同的類簇中,其中,藍色星形代表聚類中心點,叉形代表噪聲點。
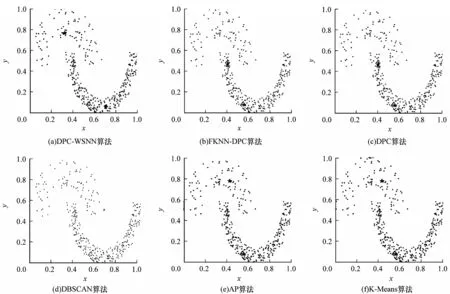
圖5 6 種算法在Jain 數據集上的聚類效果Fig.5 Clustering effects of six algorithms on Jain dataset
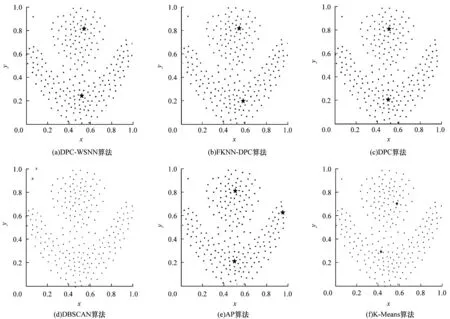
圖6 6 種算法在Flame 數據集上的聚類效果Fig.6 Clustering effect of six algorithms on Flame dataset

圖7 6 種算法在Pathbased 數據集上的聚類效果Fig.7 Clustering effects of six algorithms on Pathbased dataset
從圖5 可以看出:本文DPC-WSNN 算法不僅可以找到正確的聚類中心,而且聚類結果也完全正確;DPC-KNN 算法、DPC 算法、AP 算法、K-Means 算法都將本該屬于下半部分的類簇錯誤地分配到了上半部分,從而出現了錯誤的聚類結果;DBSCAN 算法下半部分類簇的聚類結果正確,但上半部分左端幾個數據點被錯誤分配。
從圖6 可以看出:DPC-WSNN 算法、DPC-KNN算法、DPC 算法、DBSCAN 算法均得到了正確的類簇數目,其中,DBSCAN 算法將左上角的2 個點識別為噪聲點,導致聚類準確率有所降低,AP 算法錯誤地識別類簇數目,導致將聚類結果分為了3 類,而K-Means 算法將本該屬于紅色類簇的點錯誤地分配給了藍色類簇。
從圖7 可以看出:本文DPC-WSNN 算法聚類準確度較高;AP 算法不能準確識別出類簇中心,導致聚類結果出現明顯偏差;DPC-KNN 算法、DPC 算法和K-Means 算法雖能正確識別類簇中心,但將半環部分的類簇點進行了錯誤分配;在DBSCAN 算法中,雖然2 個類簇被正確分配,但半環部分被識別為噪聲點,導致聚類準確率大幅降低。
3.5 參數敏感性分析
DPC-WSNN 算法在運行過程中,需要人為設置參數K值,為了驗證該參數對算法聚類結果的影響,通過改變參數K值大小來探索DPC-WSNN 算法在不同數據集上的聚類結果變化。實驗選取3 個合成數據集和3 個UCI 數據集,以AMI 值作為穩定性衡量指標,K在5~30之間取值,所得的AMI指標值結果如圖8所示。從圖8 可以看出:對于合成數據集而言,不同的K值所得到的結果較為穩定,波動較小,具有很好的魯棒性;對于UCI 數據集,前期當K取值較小時,聚類值有一定的波動,但隨著K的不斷增大,其波動逐漸減小,結果趨于穩定,這意味著當K近鄰個數增大時,所設計的加權共享近鄰的密度度量具有更好的優勢,因此,聚類實驗驗證了DPC-WSNN 算法對參數K的敏感性較低,算法具有較強的魯棒性。

圖8 K 值對DPC-WSNN 算法聚類效果的影響Fig.8 Influence of K values on clustering effect of DPC-WSNN algorithm
4 結束語
本文對DPC 算法進行改進,提出一種基于加權共享近鄰與累加序列的密度峰值算法DPCWSNN。該算法考慮各數據點的鄰域分布情況,利用加權共享近鄰重新定義局部密度的度量方式,同時使用γ的累加序列來實現聚類中心的自動選取。實驗結果表明,相比DPC、AP 等算法,DPC-WSNN算法具有較高的聚類準確度。本文算法執行過程中涉及參數K,雖然參數K相較截斷距離dc更容易確定,但其仍然需要人為決策。此外,DPC 算法對剩余點的分配方法也可能會影響DPC-WSNN 的聚類效果。因此,實現參數K的自適應以及對DPC 算法中剩余點分配策略進行改進,將是下一步的研究方向。
猜你喜歡
幼兒教育·父母孩子版(2022年4期)2022-05-08 21:35:35
中學生數理化(高中版.高考數學)(2021年3期)2021-06-09 06:09:14
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:38
中學生數理化(高中版.高二數學)(2021年2期)2021-03-19 08:54:04
海峽姐妹(2020年9期)2021-01-04 01:35:44
華人時刊(2020年13期)2020-09-25 08:21:32
VOGUE服飾與美容(2020年9期)2020-09-02 14:47:26
山東青年(2016年1期)2016-02-28 14:25:25
汽車維護與修理(2015年6期)2015-02-28 12:16:55
當代修辭學(2014年3期)2014-01-21 02:30:44
