改進DDPG無人機航跡規劃算法
2022-04-21 05:24:12高敬鵬胡欣瑜江志燁
計算機工程與應用 2022年8期
高敬鵬,胡欣瑜,江志燁
1.電子信息系統復雜電磁環境效應國家重點實驗室,河南 洛陽 471003
2.哈爾濱工程大學 信息與通信工程學院,哈爾濱 150001
3.北京航天長征飛行器研究所 試驗物理與計算數學國家級重點實驗室,北京 100076
航跡規劃是無人機(unmanned aerial vehicle,UAV)完成電子對抗作戰任務的有效技術手段。面對地形及敵方雷達威脅,UAV飛行時亟需合理的規劃算法獲取航跡以規避危險并完成任務。實際飛行過程存在未知動態威脅,更要求UAV具備實時決策能力[1],因此在未知威脅環境如何實時規劃UAV航跡是亟待解決的難題。
群智能算法是當前規劃航跡的主要手段,結合約束條件,設計目標函數,利用迭代技術解算最優航跡。文獻[2]提出一種自適應遺傳算法實現UAV低空三維航跡規劃,可以有效適用于靜態地形威脅環境,然而其忽略了未知威脅對實際飛行過程的影響。文獻[3]提出一種基于改進蟻群的UAV三維航跡重規劃算法,相較其他算法,減少了規劃時間,然而隨著威脅數目增多,算法迭代計算復雜度升高,處理速度下降,難以滿足無人機飛行航跡實時控制的需求。另外,若以離散航點兩兩連接形成的直線段為航跡,無人機在航點切換處飛行,不符合自身飛行動力學原理,將導致飛行誤差,故在航跡規劃的基礎上,利用航跡優化技術將離散航點優化為一條滿足無人機運動約束的飛行航跡[4]。文獻[5]利用改進A*算法完成離散航跡點的規劃,并通過插值平均處理優化航跡,卻也增大了解算航跡的時間成本。文獻[6]提出一種改進RRT航跡規劃算法,在得到航跡節點的基礎上,采用B樣條曲線平滑方法生成曲率連續的航跡,也造成整體耗時增多。雖然傳統以及基于群智能優化的航跡規劃算法均能夠獲得最優航跡,但依賴于航跡優化技術配合且解算目標函數速度慢加大了實時規劃難度。因此現階段選擇高效算法對于實現UAV航跡實時規劃尤為重要。
近年來,隨著機器學習的發展,深度強化學習因其出色的泛化性和適配性被成功應用于規劃領域[7]。2013年,DeepMind團隊[8]提出基于深度Q網絡(deep Q-network,DQN)的深度強化學習(deep reinforcement learning,DRL)方法,利用神經網絡擬合Q值函數,能夠解決高維狀態空間的離散動作決策問題。文獻[9]設計一種改進DQN算法,在三維空間規劃移動機器人路徑,控制智能體輸出離散動作,但無人機實際飛行是需要連續精準控制的,故其方法無法拓展至航跡規劃領域。2015年,Lillicrap等人[10]提出基于連續控制模型的深度確定性策略梯度(deep deterministic policy gradient,DDPG)算法,使智能體能在復雜環境根據自身狀態決策輸出連續動作。文獻[11]利用DDPG算法決策無人機機動著陸的連續動作,這與航跡規劃中無人機連續飛行需求不謀而合,故DDPG算法可用于無人機航跡規劃。然而DDPG算法收斂性能受網絡權重參數影響較大[12],適配網絡參數及優化模型將導致訓練耗時長。文獻[13]提出混合噪聲優化DDPG算法實現無人機對機動目標的連續跟蹤,DDPG算法收斂性能得以提升,但仍存在訓練耗時長的弊端。因此實際應用中如何降低網絡訓練時間成本成為DDPG算法仍待解決的問題。
為解決在未知威脅環境無人機難以實時規劃航跡且模型訓練機制冗余的問題,本文提出一種改進DDPG無人機航跡規劃算法。結合實際環境,搭建飛行場景模型,將DRL方法引入航跡規劃領域,根據任務和飛行需求,設計狀態空間、動作空間和獎勵函數,利用人工蜂群改進DDPG算法,更新網絡模型參數,訓練并應用改進DDPG網絡模型,實現無人機航跡實時規劃。
1 無人機航跡規劃系統模型
為完成無人機航跡實時控制,并提升DDPG算法訓練效率,本文提出改進DDPG無人機航跡規劃算法,其系統模型如圖1所示。首先,構建環境空間,包括靜態地形以及雷達探測威脅。其次,設計航跡規劃問題的強化學習要素,根據無人機運動模型設計狀態空間,依據飛行動力學理論設計動作空間,結合非稀疏化思想,考慮無人機與環境的交互情況設計獎勵函數。隨后,結合所設計的強化學習要素,構成經驗數組,利用人工蜂群算法,優化DDPG算法網絡參數更新機制,訓練改進DDPG無人機航跡規劃網絡模型。最后,應用改進DDPG算法,實現無人機從實時飛行狀態到實時飛行動作的決策映射,形成航跡。
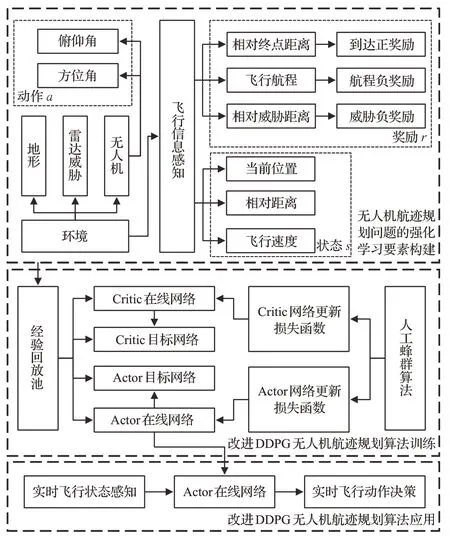
圖1 無人機航跡規劃系統模型Fig.1 Model of UAV track planning system
2 強化學習與航跡規劃
無人機與環境發生交互得到飛行動作的航跡規劃過程可以視為序列決策過程,使用馬爾科夫決策過程可以對其建模,利用強化學習算法能夠對其求解。
2.1 馬爾科夫決策過程模型
馬爾科夫決策過程中每個t時刻狀態的變化都只與t-1時刻狀態和動作有關,與t-1時刻之前的狀態和動作無關,其定義為一個四元組集合:

式中,S表示智能體在環境中的所有狀態集合,A表示智能體在對應狀態下可執行的動作集合,P表示智能體的狀態轉移概率矩陣,R表示智能體得到的獎勵回報集合,r t(st,at,st+1)∈R表示智能體通過動作at,從狀態st轉移至狀態st+1獲得獎勵回報值。
2.2 無人機飛行環境設計
為更好地模擬無人機實際飛行,本節設定規劃空間,搭建空間中靜態地形和雷達威脅模型,將其作為無人機執行任務應考慮的威脅因素,為無人機飛行構建環境基礎。
2.2.1規劃空間
在規劃空間中,無人機以原點為起點,依據實時規劃的航跡,避開地形威脅和雷達探測威脅,到達任務目的地。設定無人機在三維飛行空間的位置坐標(x,y,z),x和y分別表示無人機在經緯方向的坐標點,z表示其在空間的海拔高度,則無人機的三維規劃空間數學模型C可表示為:
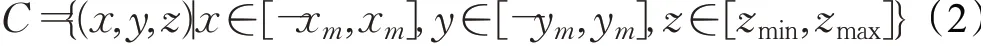
式中,x m和ym分別為無人機在經緯方向最大飛行范圍,zmin和zmax分別為其在空間中最小和最大飛行高度。
2.2.2地形和雷達威脅
考慮到無人機實際飛行環境存在地形威脅和未知位置雷達探測威脅,所以需要模擬靜態地形以及不同位置的雷達威脅數學模型。靜態地形模型可表示為:
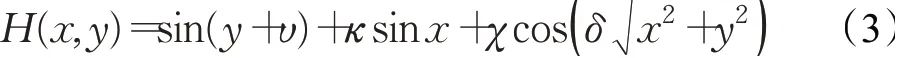
式中,H(x,y)為地形起伏高度,x和y表示地面水平方向的點坐標,υ、κ、χ、δ是模型的常系數,通過改變這些系數數值大小即能模擬起伏地貌的實際地形。
威脅輻射源的探測范圍決定了其對無人機的威脅程度,常用的方法通過計算威脅高度數據,將其等效為地形模型[14]。雷達對不同距離的目標有不同的探測能力,因而在建立雷達威脅模型時,應將雷達與目標間距離D和檢測概率Pd納入考慮范圍。基于此,本文結合雷達原理,依據文獻[15]推導目標和雷達間任意距離與檢測概率的關系Pd(D)為:
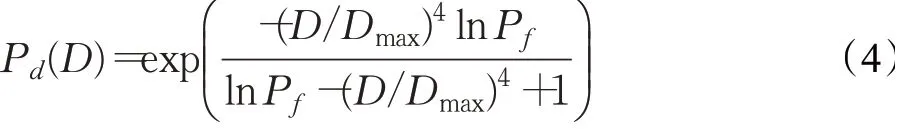
式中,Dmax表示雷達最大探測距離,Pf表示虛警概率。
利用上述將威脅源等效為地形模型的方法,把雷達威脅范圍處理為地形高程數據后數學表達式為:
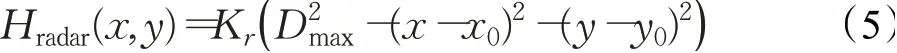
式中,Hradar(x,y)為整合后的雷達威脅高程,K r表示與雷達相關的性能系數,Dmax為雷達的最大作用半徑,(x0,y0)為雷達中心坐標。最后,將靜態地形和雷達威脅模型疊加后得:
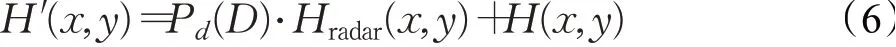
式中,H′(x,y)表示整體高程數據。
2.3 航跡規劃問題的強化學習要素設計
無人機航跡規劃問題的強化學習基本要素主要體現為其在飛行空間的狀態,由一個狀態轉換到下一狀態對應的動作以及執行動作后與環境交互所得獎勵。
2.3.1狀態空間
無人機在飛行時,應具有實時感知環境信息并決策航跡的能力,從而避開地形和未知雷達威脅。考慮到以上需求,利用無人機能夠根據傳感器和情報等途徑獲取飛行信息的特點,本文設計無人機當前位置、相對威脅距離和飛行速度方向三方面信息為狀態,將其在任意時刻狀態信息聯合,用公式表示為:
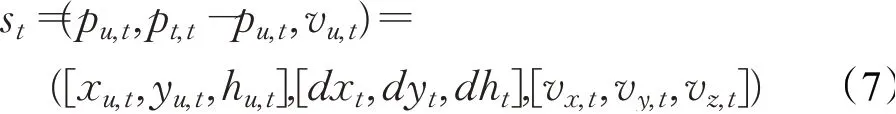
式中,pu,t和pt,t分別為終點和無人機位置,vu,t為無人機速度,[x u,t,yu,t,zu,t]為t時刻無人機在飛行空間的坐標位置,[dx t,dyt,dzt]為無人機和終點的相對距離,[vx,t,vy,t,vz,t]為無人機飛行時三個方向的分速度。
2.3.2動作空間
從無人機飛行動力學角度出發,為避開地形和雷達威脅并安全到達終點,其需要在飛行時改變速度方向。本文設定無人機按照恒定速率飛行,因而調整其飛行角度即可改變速度方向,并規定飛行角度精度,以期形成平滑的航跡,滿足飛行動力學要求。所以將其在任意時刻的動作信息聯合,用公式表示為:

式中,φt和?t分別表示無人機飛行的方向角和俯仰角。
2.3.3獎勵函數
強化學習算法的收斂性依賴于合理的獎勵設置,本文結合非稀疏思想設計獎勵函數,使無人機執行每一步到達終點的趨勢更加明顯。無人機在規劃空間內飛行的首要目的是到達任務終點,其航程受到自身攜帶燃料限制,同時飛行過程要避免被雷達探測,因此本文獎勵函數的設計主要考慮以下3個方面。
(1)到達正獎勵rappr。無人機航跡規劃的首要任務是成功到達任務目的地,因而當任務終點在無人機的探測范圍內時,系統反饋正獎勵以使到達趨勢更加明顯,具體表示為:
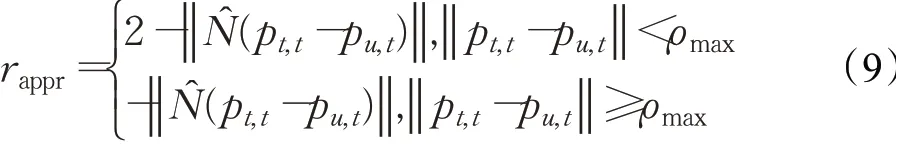
式中,N^(·)表示歸一化,‖‖·表示取模長,ρmax為無人機最大探測距離。
(2)航程負獎勵rpath。實際飛行時,無人機飛行航程受到燃料等能源限制,所以設置航程負獎勵rpath,使無人機經歷越短的航程便能到達終點,具體表示為:式中,d表示無人機已經飛過的航程,Lmax表示無人機攜帶燃料對應的最大飛行航程。
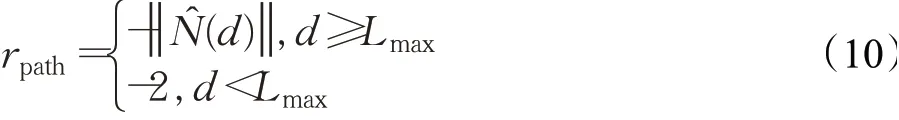
(3)威脅負獎勵rthreat。依據前文建立的威脅模型,若無人機進入雷達威脅區域則視為被敵方雷達發現,因此設置威脅負獎勵rthreat,以降低無人機進入雷達探測區域的概率,具體表示為:
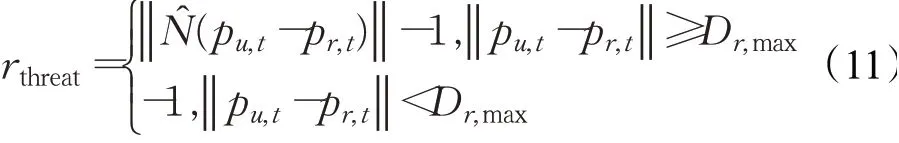
式中,pr,t表示雷達位置坐標,Dr,max表示雷達最大探測距離。
將任意時刻獎勵綜合表示為:

綜上所述,本文結合無人機實際飛行需求,設計基于航跡規劃問題的強化學習基本要素,為構建網絡訓練經驗集奠定基礎。
2.4 DDPG與航跡規劃
在眾多強化學習算法中,DDPG算法因其能在連續動作空間確定性選擇唯一動作的優點受到青睞。又由前文設計的強化學習基本要素可知,航跡規劃問題是基于高維狀態空間以及連續動作決策的,因此采用DDPG算法可以很好地完成無人機航跡決策。
DDPG網絡中包含Actor策略網絡和Critic值函數網絡。Actor網絡用來擬合策略函數,進而提取可執行的動作,其網絡權重參數為θ,輸入為狀態st,輸出為動作at;Critic網絡通過內部的值函數信息估計Actor策略網絡中對應梯度更新的方向,其網絡權重參數為ω,輸入為狀態st和動作at,輸出為評估值Q。
Actor網絡更新采用策略梯度下降法,具體表示為:

式中,m為經驗數據(s,a,r,s′)的采樣個數。Critic網絡采用均方誤差損失函數進行參數更新:
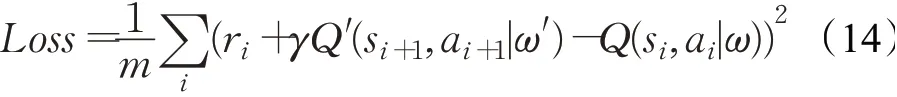
式中,γ為獎勵折扣因子。
另外,DDPG算法分別復制Actor策略網絡和Critic值函數網絡作為目標網絡,使智能體對任務策略進行穩定學習,其網絡權重參數分別表示為θ′和ω′。結合軟迭代思想,緩慢更新目標網絡,使智能體在訓練時,學習過程穩定性大幅度增強。Actor目標網絡具體更新方式為:

式中,τ用來控制Actor目標網絡權重θ′的更新速度。同樣,利用式(15)的方式更新Critic目標網絡參數ω′。
此外,DDPG算法利用隨機噪聲,增加Actor策略網絡在連續動作空間的探索能力,形成策略映射μ′:

式中,N為該噪聲隨機過程。
本文設計Actor策略網絡和Critic值函數網絡均由兩個全連接層FC構成,網絡結構簡單且運算方便,時間復雜度低。故結合Actor網絡輸入狀態,輸出動作,Critic網絡輸入狀態和動作,輸出Q值的特點,根據上文選定的9維狀態和2維動作,設計DDPG網絡結構如表1所示。表中ReLu和tanh為神經網絡常用的兩種非線性激活函數。

表1 DDPG網絡結構Table 1 Network structure of DDPG
依據DDPG網絡訓練原理,采用表1設計的網絡結構,根據式(13)至式(16),訓練DDPG網絡。訓練完成后,獲取從飛行狀態到飛行動作端到端的決策映射,其Actor在線網絡策略映射公式如下:

式中,μθ(·)為已訓練Actor在線網絡的策略映射關系,θ是其網絡權重參數,st為無人機實時飛行狀態,at即為由映射關系μθ(·)得到的實時飛行動作。
在實際應用中,無人機實時采集飛行狀態,遷移已訓練Actor在線網絡,即可得到實時飛行動作,實現航跡規劃。
3 基于改進DDPG的無人機航跡規劃算法
DDPG網絡訓練過程中,學習率的改變會直接影響網絡收斂性能,傳統方法通過調試學習率,直至網絡具有較好的收斂效果,但調整至合適的學習率將會耗費大量時間成本。群智能算法通過不斷迭代更新求解適應度函數最優值的思想,與神經網絡優化權重參數的思想異曲同工,因此結合群智能算法尋優DDPG網絡權重參數能夠避免學習率對網絡收斂性能的影響,最終解決網絡訓練時間長的問題。
3.1 改進人工蜂群算法
人工蜂群(artificial bee colony,ABC)算法具備尋優能力強以及收斂速度快等優點,故本文采用ABC算法優化DDPG網絡更新機制。但直接采用ABC算法需在一次完整DDPG網絡訓練中,利用不同的蜂群尋優策略和值函數兩類網絡的最佳更新方式,必然導致計算冗余。為彌補該缺陷,本文設計一種二維人工蜂群(two dimensional artificial bee colony,2D-ABC)算法,改進初始解和位置更新公式,共享種群行為機制,減少計算復雜度,提升訓練效率。
2D-ABC算法將蜂群分為二維開采蜂、二維隨從蜂和二維偵察蜂,二維蜜源每一維位置分別對應兩個優化問題可能解,每一維蜜源花粉量分別對應兩個解的適應度。二維蜂群采蜜的行為機制有以下三種,
(1)初始化種群。蜜蜂群體派出SN個二維開采蜂,開采蜂和隨從蜂各占蜂群總數的一半,蜜源數與開采蜂相同,依據式(18)隨機產生SN個二維初始解:

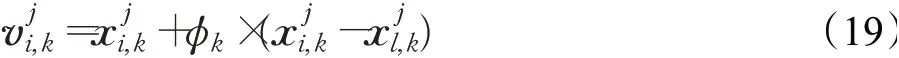
式中,φk為第k維中區間[0,1]的隨機數。
(3)隨從蜂采蜜。二維隨從蜂根據對應維蜜源花蜜量的多少選擇每一維較優的標記蜜源,并在其附近按照式(20)探索第k維新蜜源,選擇概率表達式為:

本文提出2D-ABC算法流程如圖2所示,其改進DDPG算法具體步驟描述如下:
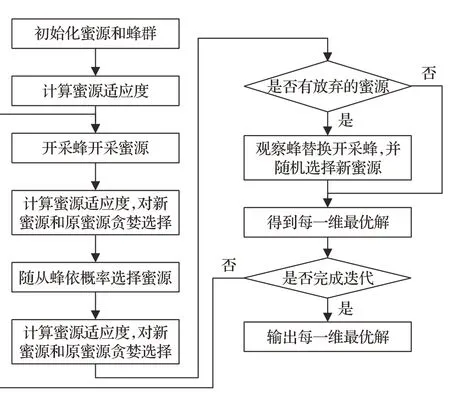
圖2 2D-ABC算法流程圖Fig.2 Flow chart of 2D-ABC algorithm
步驟1初始化二維蜜源和二維蜂群。根據式(18),在M維空間隨機初始化SN個二維蜜源位置,第一維和第二維蜜源位置分別代表Actor在線網絡和Critic在線網絡權重參數。同時,設置開采蜂和隨從蜂數目均為2×SN,第一維和第二維蜂群的工作對象分別為第一維和第二維蜜源。
步驟2計算二維適應度。將Critic在線網絡權重更新的均方誤差損失函數,即式(14)作為第一維適應度函數,得到第一維蜜源評價值;將Actor在線網絡權重更新的策略梯度下降函數,即式(13)作為第二維適應度函數,得到第二維蜜源評價值。
步驟3二維開采蜂開采蜜源。根據式(19),開采蜂分別在每一維蜜源位置附近開采,獲得新蜜源位置。
步驟4根據式(13)和式(14),再次分別計算每一維新位置蜜源評價值,并與原位置蜜源評價值相比較,進行貪婪選擇,保留更優的二維蜜源。
步驟5隨從蜂選擇蜜源。二維隨從蜂依據式(20)得到的概率,選擇每一維新蜜源。
步驟6再次執行步驟4。
步驟7在Limit次蜜源位置更新后,若每一維有放棄的蜜源則利用觀察蜂替換開采蜂,并隨機選擇新蜜源,若無則從已保留的優質蜜源得到每一維最優蜜源位置,即最優的Actor網絡和Critic網絡權重參數。
3.2 改進DDPG算法模型訓練及應用
本文融合2D-ABC算法尋優與DDPG算法模型更新機制,將Actor在線網絡權重更新的策略梯度下降函數和Critic在線網絡權重更新的均方誤差損失函數作為適應度函數,利用2D-ABC算法分別尋優每一回合DDPG算法Actor和Critic在線網絡權重參數,完成改進DDPG算法模型的訓練,從而提升網絡訓練效率,降低總體的訓練時間成本。改進DDPG算法模型訓練及應用結構框圖如圖3所示,具體訓練步驟如下:
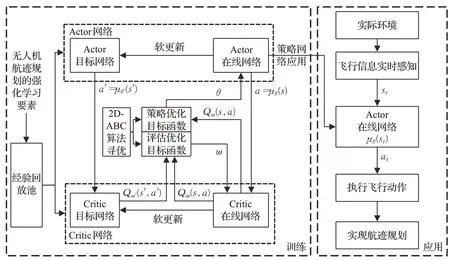
圖3 改進DDPG算法模型訓練及應用結構框圖Fig.3 Training and application structure diagram of improved DDPG algorithm model
步驟1結合式(7)至式(12),設計航跡規劃問題的強化學習要素。
步驟2初始化狀態s,清空經驗回放池。
步驟3根據狀態s,Actor在線網絡得到對應動作a,智能體執行動作a,并得到新狀態s′以及與環境交互后的獎勵r。
步驟4將經驗數組存入經驗回放池,并從經驗回放池中采樣m個經驗數組,送入Critic值函數網絡,計算得在線Q值Qω(s,a)和目標Q值Qω′(s′,a′)。
步驟5根據式(13)和式(14),結合Critic值函數網絡的在線Q值和目標Q值,利用2D-ABC算法求得最優Actor網絡權重參數和最優Critic網絡權重參數。
步驟6根據式(15),通過軟迭代更新Actor網絡以及Critic網絡權重參數。
步驟7判斷是否滿足DDPG網絡訓練結束條件,結束訓練。
最后,與改進前方法相同,無人機實時采集飛行狀態,根據式(17),獲取該狀態下的決策映射,執行飛行動作,實現航跡規劃。
4 仿真與分析
對本文提出的改進DDPG無人機航跡規劃算法進行仿真分析,無人機飛行約束參數、相關威脅仿真參數和改進DDPG算法參數分別如表2、表3和表4所示。本文設定無人機航跡規劃空間大小為15 km×15 km×7.5 km,且假設無人機飛行恒定速率,同時設置算法測試500次,另外忽略自然環境干擾因素影響。本文涉及仿真的實驗設備及環境滿足:Intel?CoreTMi7-9700k CPU,32 GB雙通道內存,Windows 10 64位操作系統,Python 3.5,TensorFlow 1.7.0。

表2 無人機飛行約束參數Table 2 Fight constraint parameters of UAV
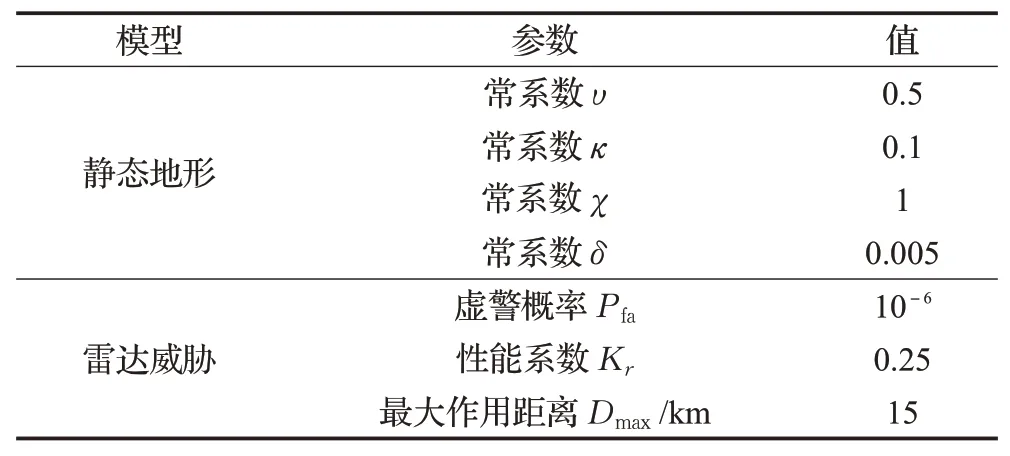
表3 相關威脅仿真參數Table 3 Simulation parameters of related threat
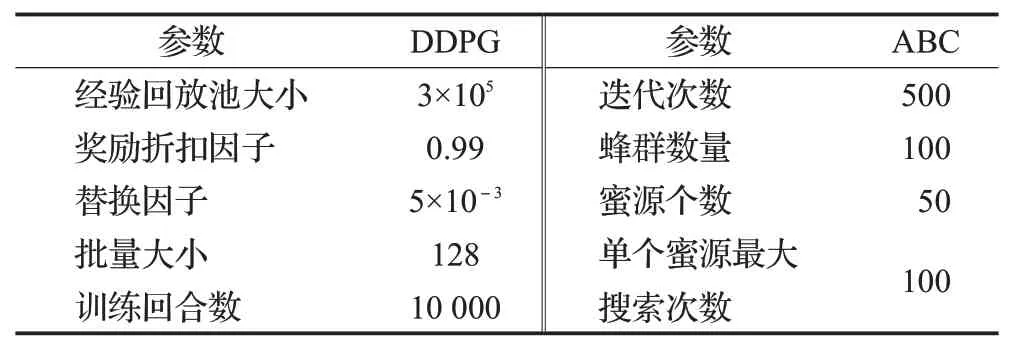
表4 改進DDPG算法參數Table 4 Parameters of improved DDPG
為驗證改進DDPG算法有效性和在未知環境的適應性,本文選取網絡訓練時長、測試成功率和航跡偏差率為評估指標,評估算法的訓練和測試結果。其中,網絡訓練時長用于評估算法訓練效率,測試成功率用于評估無人機滿足航程約束情況下依照航跡決策順利達到終點的能力,其計算公式為:

航跡偏差率TE用于評估無人機在成功到達終點前提下的航跡質量,其計算公式為:

式中,F為測試次數,αi和βi分別為設定相同條件下用智能算法解算得第i條航跡長度和改進DDPG算法決策得第i條航跡長度,航跡偏差率越低航跡質量越高,本文設定航跡偏差率低于7.5%時航跡質量達標。
由于訓練次數多,且算法隨機波動較大,直接顯示所有訓練回合獎勵收斂曲線效果不佳,為更好展示算法訓練效果,本文將每20個訓練回合所得獎勵和取平均并作歸一化處理,將10 000次迭代收斂曲線等效處理為500次迭代收斂曲線。圖4和表5分別給出了在網絡結構設置如表1,超參數設置如表4,設定4組不同Actor網絡和Critic網絡學習率情況下,DDPG算法的獎勵收斂曲線和訓練時長表。
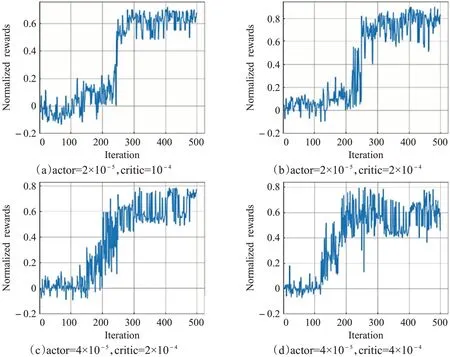
圖4 四種不同學習率情況下DDPG算法的獎勵收斂曲線Fig.4 Reward convergence curve of DDPG under four different learning rates
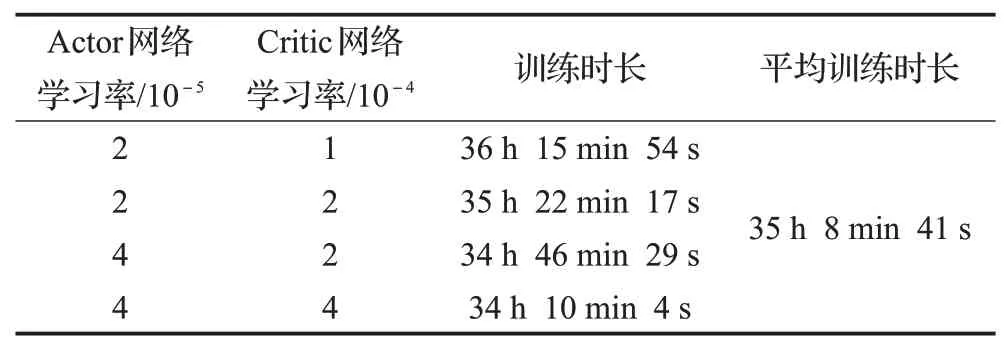
表5 四種不同學習率情況下DDPG網絡訓練時長Table 5 Network training duration under four different learning rates
由圖4可知,隨著學習率的增大,DDPG算法收斂速度明顯加快,當Actor網絡和Critic網絡學習率分別為2×10-5和10-4時,歸一化獎勵值在5 600次訓練回合左右才趨于穩定,而當Actor網絡和Critic網絡學習率分別為4×10-5和4×10-4時,歸一化獎勵值在3 800次訓練回合左右即逐漸收斂。另外,不同學習率情況下,歸一化獎勵最終收斂值也不同,當Actor網絡和Critic網絡學習率分別為2×10-5和2×10-4時,歸一化獎勵值在0.8上下波動,而當Actor網絡和Critic網絡學習率分別為4×10-5和4×10-4時,歸一化獎勵值在0.6上下浮動,且浮動幅度較大。這是因為學習率是強化學習算法學習能力的數值體現,過高會導致算法早期樣本過擬合,過低會導致樣本利用率低使算法收斂慢,因此降低學習率對網絡性能的影響尤為重要。
由表5可知,僅調試4組學習率情況下網絡總訓練時間累計140 h 34 min 44 s,訓練耗時長,而調整至合適的學習率需要大量的訓練時間,本文提出改進DDPG算法優化網絡更新機制,提升算法訓練效率。
圖5給出了網絡結構和參數設置分別如表1和表4情況下改進DDPG算法歸一化獎勵收斂曲線。
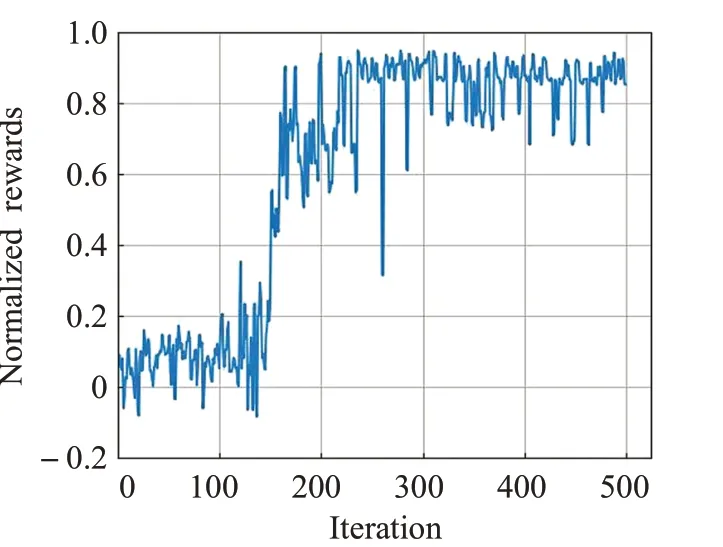
圖5 改進DDPG算法獎勵收斂曲線Fig.5 Reward convergence curve of improved DDPG
由圖5可知,改進DDPG算法歸一化獎勵值在4 400次訓練回合左右即趨于收斂,且穩定在0.9左右。另外,記錄其經歷10 000次訓練回合耗費時長為69 h 40 min 34 s,對比表5結果可知,改進DDPG算法整體訓練時長僅為原算法在表5所設4組學習率情況下平均訓練時長的1.98倍。這是因為所提算法每個訓練回合內利用ABC算法迭代更新尋優網絡參數,導致網絡訓練復雜度增加,引起單個訓練回合耗時增長的代價。得益于改進DDPG算法網絡訓練不依賴于學習率的優勢,僅一次訓練就能完成對模型權重參數的尋優,因此總體上網絡訓練時長大幅度減少,所提算法具有一定的有效性。
圖6給出了在無人機仿真參數設置如表2,威脅模型仿真參數設置如表3的情況下,在兩種隨機位置多雷達環境中,無人機利用改進DDPG算法航跡規劃測試效果圖。
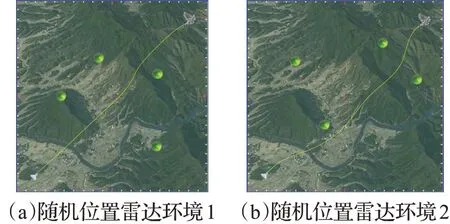
圖6 改進DDPG算法航跡規劃效果圖Fig.6 Track planning effect chart by using improved DDPG
由圖6可知,無人機能以連續平滑的航跡飛行,有效避開實際環境地形和不同位置未知雷達探測威脅,成功到達任務終點,驗證了所提算法應用的可行性。
盡管智能算法解算航跡速率慢導致測試成功率不盡如人意,但迭代計算的特點決定了其能在不限時間內得到更優航跡。本文以智能算法在測試回合內解得航跡為參照,用航跡偏差率評估改進DDPG算法每次測試形成航跡的質量。蟻群算法具有啟發式概率搜索特點,易于找到全局最優解,在規劃領域廣泛應用,因此選擇蟻群算法作為對比算法。表6給出在相同飛行環境內無人機利用改進DDPG算法進行航跡決策和用蟻群算法解算航跡的測試結果對比。其中蟻群算法種群數量為40,全局信息素濃度更新率為0.5,局部信息素濃度更新率為0.4,信息素濃度重要程度因子為1.5,啟發值重要程度因子為5。

表6 不同算法航跡規劃測試結果Table 6 Test results of different algorithms for track planning %
由表6可知,500次測試中,用蟻群算法解算航跡無人機測試成功率僅48.2%,而改進DDPG算法成功率高達97.2%。這是由于大量的訓練增強了改進DDPG算法學習能力,能夠實時決策無人機飛行航跡,獲得較高飛行成功率。同時,以蟻群算法獲得最優航跡為參照,改進DDPG算法所得航跡偏差率僅為3.78%,其原因是所提算法采取的航跡決策使無人機飛行航跡有效且平滑,形成的航跡滿足航跡質量需求,進一步驗證了所提算法在工程應用的可行性。
5 結語
本文提出一種改進DDPG無人機航跡規劃算法,解決了用傳統算法解算航跡速度慢的問題,同時優化了DDPG網絡權重參數更新過程。所提算法將深度強化學習應用于航跡規劃領域,為無人機飛行提供連續確定性動作決策,并設計2D-ABC算法,改進DDPG算法模型更新機制。仿真結果表明,所提算法無需調整學習率的過程,提升了無人機在未知威脅環境飛行的實時反應能力,降低了訓練的時間成本,且在達到97.2%飛行成功率前提下,保證了航跡質量。忽略自然干擾因素影響,所提算法相比典型智能算法,憑借連續飛行動作輸出和實時航跡決策的優勢,在無人機航跡規劃領域更具可行性。面對實際環境天氣、風力和氣流等變化影響,可聯合卡爾曼濾波等技術完善飛行動作,使得所提算法在自然環境應用可行。下一步工作,本團隊將研究所提算法的優化技術,同時探討超參數對于深度強化學習網絡模型性能的影響。
猜你喜歡
動漫界·幼教365(大班)(2021年4期)2021-05-23 21:33:16
公民與法治(2020年11期)2020-07-25 02:02:06
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
領導決策信息(2018年50期)2018-02-22 06:17:16
商周刊(2017年5期)2017-08-22 03:35:26
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文周刊·小學一年級版(2016年28期)2017-06-03 00:28:49
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
中國衛生(2016年2期)2016-11-12 13:22:16
華東科技(2016年10期)2016-11-11 06:17:41
