面向高光譜顯微圖像血細胞分類的空-譜可分離卷積神經網絡
2022-04-28 04:18:44時旭,李遠,黃鴻
光學精密工程 2022年8期
關鍵詞:分類
時 旭,李 遠,黃 鴻
(重慶大學 光電技術與系統教育部重點實驗室,重慶 400044)
1 引 言
紅細胞、白細胞是人體血細胞的主要組成部分。它們在血液中的數量與人體的生理狀態息息相關。如紅細胞數量過少會導致貧血,白細胞數量過少會引發免疫力缺失[1-3]。血細胞的計數和分類是病灶臨床檢查的常用方法之一,也是血常規檢驗的基本內容[4]。對血細胞進行分類,有助于血液學家診斷疾病,如白血病、血液癌癥等[5]。因此,在臨床診斷中,如何對紅、白細胞進行計數具有十分重要的價值。早期通過顯微鏡計數以及利用血細胞的電阻率來嘗試血細胞自動計數,但其精度和效率受限。隨著信息技術的蓬勃發展,計算機自動計數以其高效、快速的特點廣泛應用于血液細胞分類。
傳統計算機自動計數方法可分為幾何計數法和統計計數法。其中,典型幾何方法包括距離分類器和線性分類器等,但這些方法對具有非線性分布的顯微圖像效果不佳。統計分析法包括參數估計法、梯度法、貝葉斯準則法、最大似然法和支持向量機(Support Vector Machine,SVM)等。這些方法在樣本數較多的情況下具有較好分類能力,但對結構復雜的數據需要先獲取樣本統計分布得到先驗概率和類分布概率密度函數等,才能取得較好的效果,且SVM方法存在核函數和參數選擇問題[6]。
深度神經網絡在圖像分類中的優異表現給醫學圖像處理帶來巨大機遇。卷積神經網絡(Convolutional Neural Network,CNN)尤為突出,其使用局部連接有效提取特征,并通過共享權值顯著減小參數量,為在醫學圖像分類任務中奠定了基礎。鄭婷月等[7]將一種多尺度全卷積神經網絡應用在視網膜血管分割任務上,在兩個公開眼底數據集上均可達到96%左右的準確率。Raunak等[8]使用雙流神經網絡,對肺結節CT圖像進行良惡性分類,取得了90.04%的分類精度。Khashman等[9]對比了三種不同的神經網絡方法,在RGB圖像血細胞亞型識別任務中,取得99.17%的分類效果。
但是,上述方法都是針對傳統顯微光學圖像,只包含紅、綠、藍三通道信息,不能有效反映血細胞內在復雜的生化性質。與此同時,高光譜成像技術擁有無接觸、非電離、無傷害和光譜信息豐富等優點,且具有“圖譜合一”特性。因此,物質間的細微差異可更好地由其連續的光譜曲線表達,在醫學圖像處理領域,被用于腦癌[10]、乳腺癌[11]、舌癌[12]檢測 等,并取得了較好效果。Huang等[13]提出一種調Gabor濾波卷積神經網絡(MGCNN)模型,將調制Gabor濾波與卷積神經網絡相結合,取得了比傳統神經網絡更好的血細胞分類結果。Wei等[14]開發了一種雙通道CNN,將典型CNN特征和EtoE-Net特征相融合,取得了更好的分類表現。然而這些方法訓練時間較長,在實際應用中對硬件條件要求頗高。此外,上述模型需要較多數量的標記樣本以保證模型分類性能,且高光譜醫學圖像標記需要大量人工成本。
基于此,本文提出了一種空-譜可分離卷積神經網絡(Spatial-Spectral Separable Convolution Neural Network,S3CNN),該網絡通過有效利用高光譜圖像中的空間-光譜特征信息來提升分類效果,并利用可分離卷積結構對模型復雜度進行優化,減少訓練時間。S3CNN主要思路是利用空-譜聯合距離(spatial-spectral combined distance,SSCD)得到訓練集中各像素點的空-譜近鄰,并對這些近鄰點賦予與相應中心像素點相同的標簽,進行樣本擴充,然后用可分離卷積優化經典卷積,減少訓練時間。在Bloodcells1-3和Bloodcells2-2高光譜數據集上的實驗結果表明,本文方法能夠有效改善高光譜顯微圖像的細胞分類性能,且在模型訓練時間上具有優勢。
2 空-譜可分離卷積神經網絡(S3CNN)
為表述方便,文中高光譜醫學數據集表示為X={x1,x2,…,xN}∈RN×b,其中N為樣本數,b為波段數,li∈{1,2,…,c}為標簽,c為類別數。
本文所提出空-譜可分離卷積神經網絡的算法流程圖如圖1所示,其主要包括空-譜聯合訓練集構建和可分離卷積神經網絡,下面對其進行一一介紹。
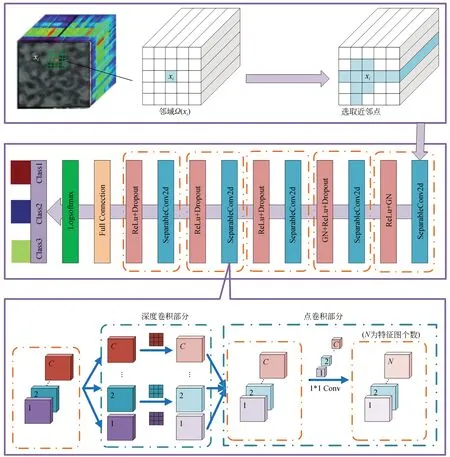
圖1 空-譜可分離卷積神經網絡流程圖Fig.1 Flow chart of spatial-spectral separable convolution neural network
2.1 空-譜聯合訓練集構建
在高光譜血細胞圖像中,各個像素在空間分布上具有一定的相關性[15-16],在同一個空間鄰域內的像素點通常屬于同一類別[17-20]。基于此,本文利用鄰域空間像素中的空-譜聯合信息來衡量像素間的相似性,并提出一種空-譜聯合距離(SSCD)來更好地選擇空-譜近鄰點,以擴充訓練樣本,具體如圖2所示。
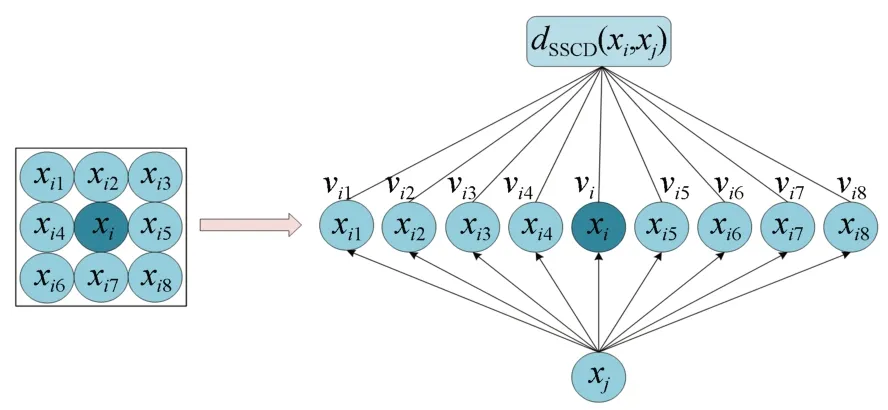
圖2 計算空-譜聯合距離過程Fig.2 Process of calculating the spatial-spectral combined distance
對于血細胞高光譜顯微圖像中的像素點xi和xj,Ω(xi)和Ω(xj)分別為xi和xj的近鄰空間,空-譜聯合距離SSCD可以定義為:
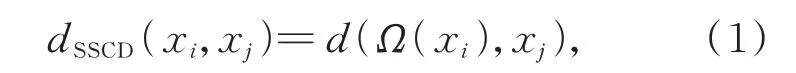
其中,d(Ω(xi),xj)為xj和近鄰空間Ω(xi)之間的距離,它可以表示為:
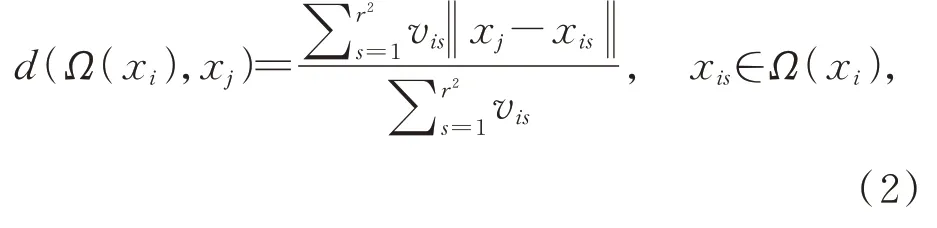
式中vis是xis的權重,可通過核函數來計算:
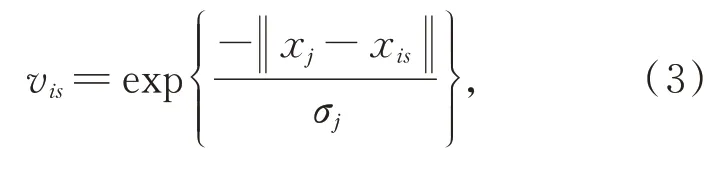
其中,σj為‖xj-xis‖的均值,可定義為:
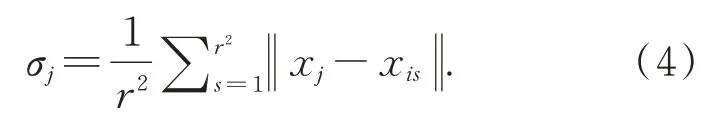
對于有標簽的高光譜圖像數據,在其周圍r×r的方形鄰域內根據空-譜聯合距離選擇離其最近的k個像素點,可認為它們與中心像素的標簽相同,擴充到訓練樣本集,通過利用少量標記樣本和一定數量近鄰樣本進行深度神經網絡模型訓練。
2.2 可分離卷積神經網絡
通過空-譜近鄰得到空-譜近鄰樣本訓練集后,如何高效的進行訓練是一個關鍵問題。神經網絡大多是由不同尺度的卷積核堆疊而成,伴隨著模型精度的不斷提高,神經網絡的深度和模型參數量也在不斷增加[21]。然而,過多的參數給模型的訓練帶來極大的挑戰。
可分離卷積是解決這一問題的有效方法[22],如圖3(b)所示。其主要思想是將標準卷積轉化為一個深度卷積和一個1×1的點卷積。在正向傳播過程中,可分離卷積首先在每個圖像通道上進行二維卷積,其次對輸出的特征圖進行點卷積。
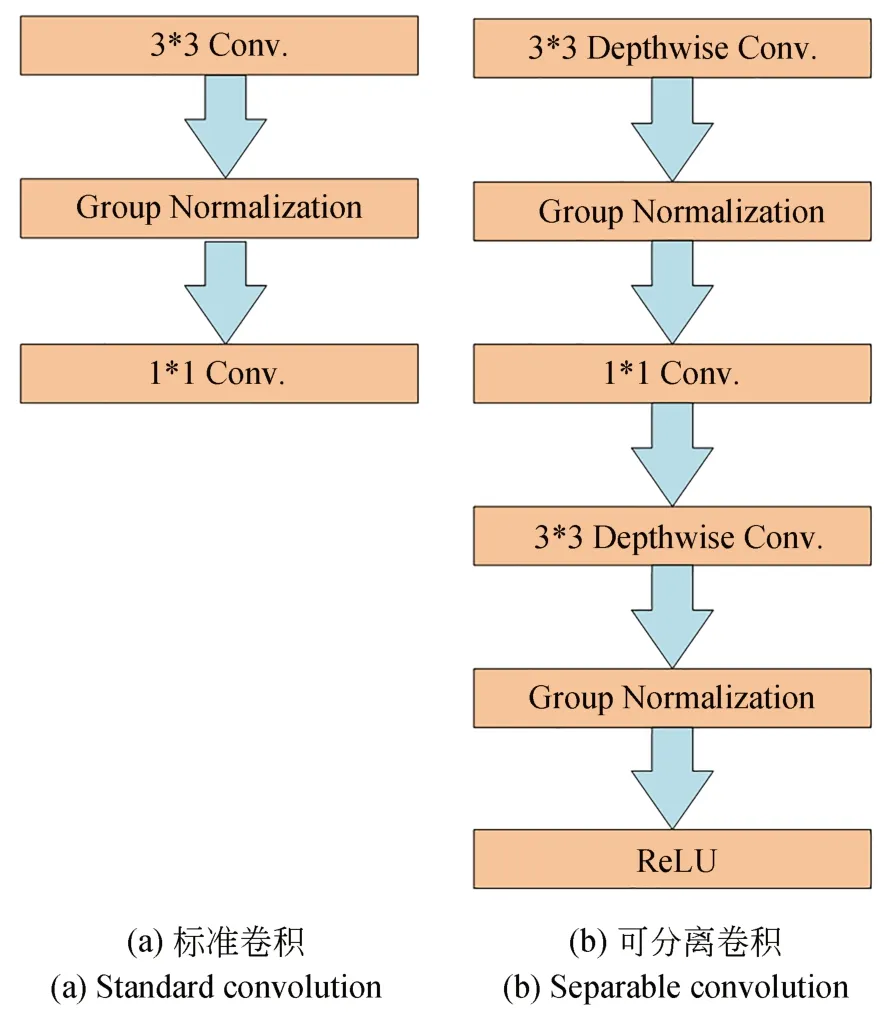
圖3 標準卷積與可分離卷積結構對比Fig.3 Comparison of standard convolution and separable convolution
在可分離卷積提取特征后,采用平均池化操作以有效降低空間維度,減少計算量。然后采用Group Normalization(GN)歸一化,最后采用如下形式的ReLU激活函數:
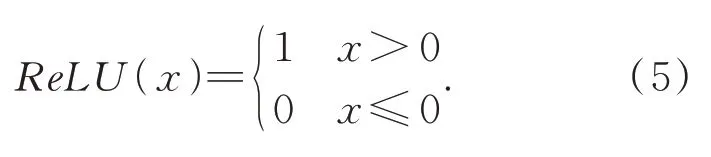
ReLU激活函數有單側抑制的作用,使得模型在訓練過程中的梯度值和收斂狀態處于穩定,有助于解決梯度消失的問題。經計算得,最終網絡模型參數量params約32M,計算量flops約0.047 G。
3 實驗分析
3.1 實驗數據集介紹
本文算法主要通過兩個不同場景下的高光譜血細胞數據集Bloodcells1-3和Bloodcells2-2進行實驗驗證。該數據由顯微鏡和硅電荷耦合器件(CCD)組成VariSpec液晶可調諧濾波器收集,波長范圍為400~720 nm,共包含33個波段,其中Bloodcells1-3數據集像素大小為973×699,Bloodcells2-2數據集像素大小為462×451。圖4(a)為兩個數據集第10個波段的圖像,圖4(b)為兩個數據集的真值圖。在真值圖中,紅色代表白細胞,藍色代表紅細胞,綠色代表背景。

圖4 高光譜顯微圖像Fig.4 Hyperspectral microscopy image
3.2 實驗設置
實驗的硬件環境采用PANYAO 7048G服務器,其搭載6張TITAN RTX以及256G內存;軟件環境是基于Ubuntu 18.04系統的Py Torch深度學習框架(PyTorch 1.6版本),編程語言為Python 3.7。
在實驗中,首先按波段對高光譜血細胞數據進行歸一化處理。在每次實驗中,高光譜血細胞數據集被隨機劃分為訓練樣本和測試樣本,利用訓練數據得到空-譜聯合訓練集后,將其送入可分離卷積網絡進行訓練。訓練過程中,優化器為Adam,batchsize為1 000,初始學習率設置為0.001。采取“Early Stopping”策略終止訓練,即在訓練集上若連續10個epoch損失函數的值都不減小就自動停止訓練。訓練結束后,將測試集送入網絡以評估模型。對于分類結果,采用總體分類精度(Overall Accuracy,OA)系數進行評價。為了保證實驗結果的可靠性,每種條件下的實驗均重復進行10次,并取10次結果的平均值作為最終實驗結果。
為了證明本文方法在高光譜顯微圖像分類上有效性,實驗中選取Nearest Neighbor(1-NN)、SVM、1D CNN、2DCNN、3D CNN、Separable Convolution Network(SCN)作為對比方法。其中,1D、2D、3D分別代表卷積方式,SVM核函數采用徑向基函數(Radial Basis Function,RBF)。
3.3 Bloodcells1-3實驗結果
為研究窗口大小r和近鄰數k對算法性能的影響,首先選擇Bloodcells1-3數據集進行實驗。在紅細胞、白細胞、背景三個類別中,每類隨機選取40個樣本用于訓練,2 000個樣本用于測試。窗口大小r的取值范圍為{1,3,5,7,9,11,15},空-譜近鄰數k的取值范圍為{2,4,6,8,10,14,18,20}。圖5為算法在不同窗口大小和空-譜近鄰數下的分類精度。
由圖5可知,分類精度隨著窗口r的增大先有所提升后下降,這是由于當空間窗口包含了更多的空間近鄰時,可利用的空間信息更加豐富,因而能夠更好地區分紅、白血細胞以及背景,提高分類精度。同時,近鄰數k增加會選擇更多無標記空-譜近鄰樣本參與訓練,提高分類性能,但k過大時導致近鄰點中可能包含較多來自于其他類別的像素點,進而影響模型訓練效果。基于上述因素,本文選取k=10,r=9。
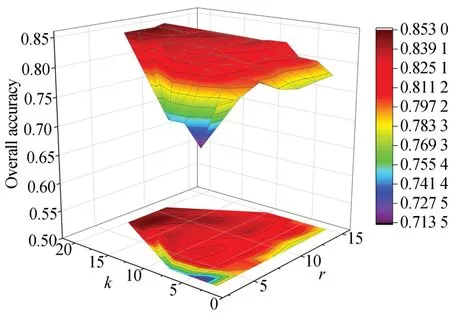
圖5 Bloodcells1-3數據集中S3CNN在不同r和k下的分類結果Fig.5 Classification results of S3 CNN with different r and k on Bloodcells1-3 dataset.
為評估不同算法在不同數目訓練樣本下的分類性能,從Bloodcells1-3數據集中的每類中分別隨機選取5、10、20、40、60、80個樣本用于訓練,選取2 000個樣本作為測試,實驗結果如表1所示。
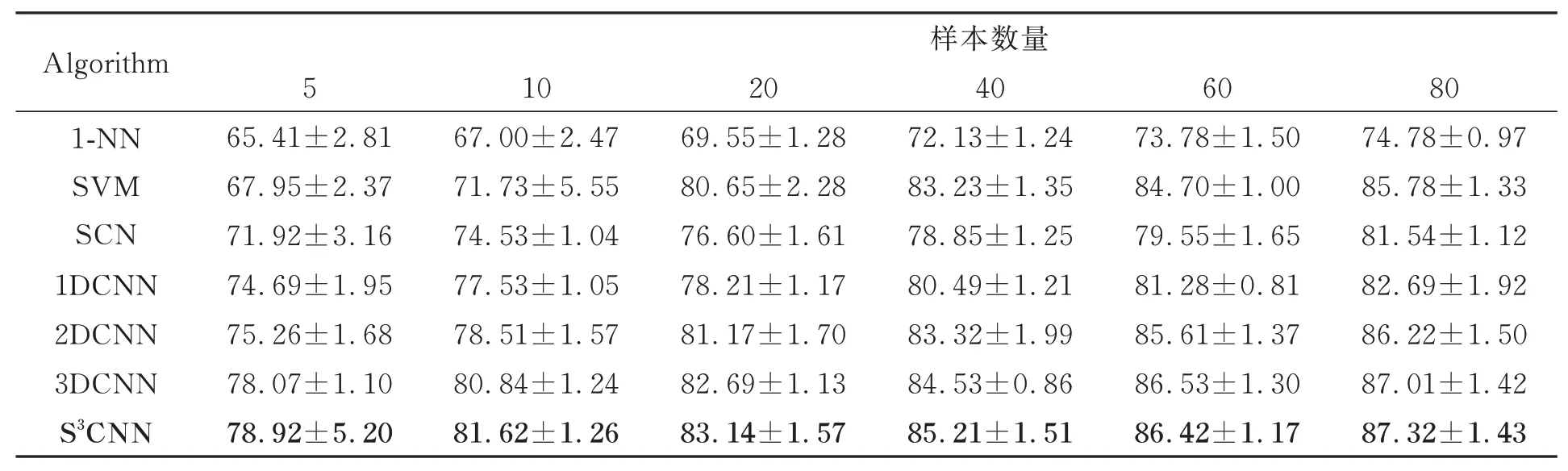
表1 Bloodcells1-3數據集上不同算法的分類結果(總體分類精度±標準差)Tab.1 Classification results of different algorithms on Bloodcells1-3 dataset(overall accuracy±STD) (%)
由表1可知,對于每種分類算法,隨著訓練樣本數量的增加,其分類精度隨之提升。這是由于更多的訓練樣本包含了更豐富的先驗信息,更有利于模型提取信息。相比1-NN、SVM等傳統方法,所有的深度學習方法都取得了更好的分類結果,這是因為深度學習方法可以更好提取高光譜數據高層特征,有利于分類。在CNN方法中,3DCNN方法的分類性能要優于1DCNN和2DCNN方法,這是因1DCNN只提取光譜特征,而2DCNN提取空間特征但未能充分利用光譜信息,而3DCNN同時利用利用光譜-空間信息,因此分類性能更好。本文提出的S3CNN在多數訓練情況下都取得了最好的分類結果,僅在訓練樣本為60時精度略低于3DCNN約0.001 1,這是因為該網絡通過利用空-譜聯合距離選擇近鄰點參與訓練,從而有更多的訓練樣本參與模型訓練,可更好的表征不同血液細胞的高層特征,提高模型的魯棒性,提升了模型分類效果。
圖6為各算法的分類結果圖。由圖可知,本文算法的分類結果圖更加平滑,因為相比其他算法,該算法能夠更好提取不同血液細胞的空-譜信息,具有更好的分類性能。

圖6 各算法在Bloodcells1-3數據集上的分類結果圖Fig.6 Classification maps for different methods on Bloodcells1-3 dataset.

為比較S3CNN與3DCNN的差異性,論文引入McNemar統計檢驗。McNemar檢驗是一種基于統計學原理的顯著性評價方法[23],算法1以及用于比較的算法2的檢驗統計量可定義為:其中,f12表示被算法2分錯而被算法1正確分類的樣本數,f21表示被算法1分錯而被算法2分對的樣本數。一般設置顯著性閾值為0.05,Z大于該值時表示算法1優于算法2的性能,且當Z大于2.58和1.96時,分別表示兩種算法在99%和95%置信水平下具有統計顯著性。對于S3CNN與3DCNN兩種算法,計算得Z值為6.68,表明兩種算法在統計學意義下具有顯著差異性。
3.4 Bloodcells2-2實驗結果
實驗中,分別從Bloodcells2-2數據集每類中隨機選取200個樣本用于訓練,2000個樣本用于測試。對窗口大小r和空-譜近鄰數k進行實驗,其取值范圍與Bloodcells1-3參數實驗一致。由圖7的實驗結果可知,其結果與圖5相似,S3CNN方法的分類精度隨著r和k增加而增加,而后逐漸穩定,綜合考慮分類精度以及算法的運行效率,k設置為10,r值取7。
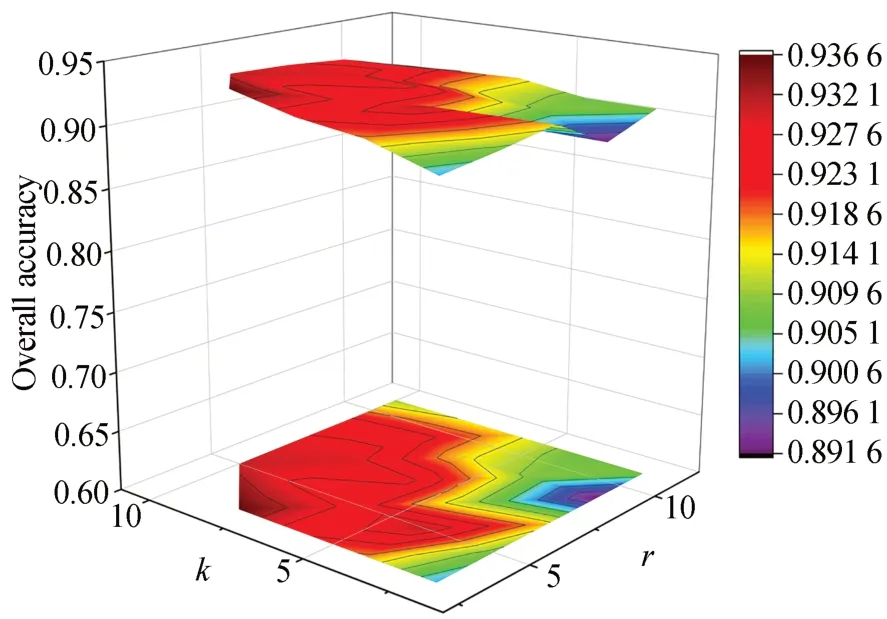
圖7 Bloodcells2-2數據集中S3CNN在不同r和k下分類結果Fig.7 Classification result of S3CNN with different r and k on Bloodcells2-2 dataset.
為評估不同數目訓練樣本下不同算法的分類性能,從Bloodcells2-2數據集中的每類中分別隨機選取5、10、20、40、60、80個樣本用于訓練,選取2000個樣本作為測試,實驗結果如表2所示。
從表2可以看出,對于每種分類算法,其分類精度隨著訓練樣本個數的增加而遞增。與此同時,本文算法始終取得了最好的分類效果。在標記樣本數較小時,S3CNN比其他對比方法分類優勢更明顯。這是由于1DCNN、2DCNN、3DCNN在訓練樣本不足時,模型訓練效果受限,導致分類效果不理想,而S3CNN充分利用高光譜圖像的空間一致性原則,有效選取標記樣本點的無標記空-譜近鄰樣本,大大擴充了訓練樣本,可以滿足網絡模型對于訓練樣本的需求,從而可更好的提取不同血液細胞的高層特征,取得更高的分類精度。
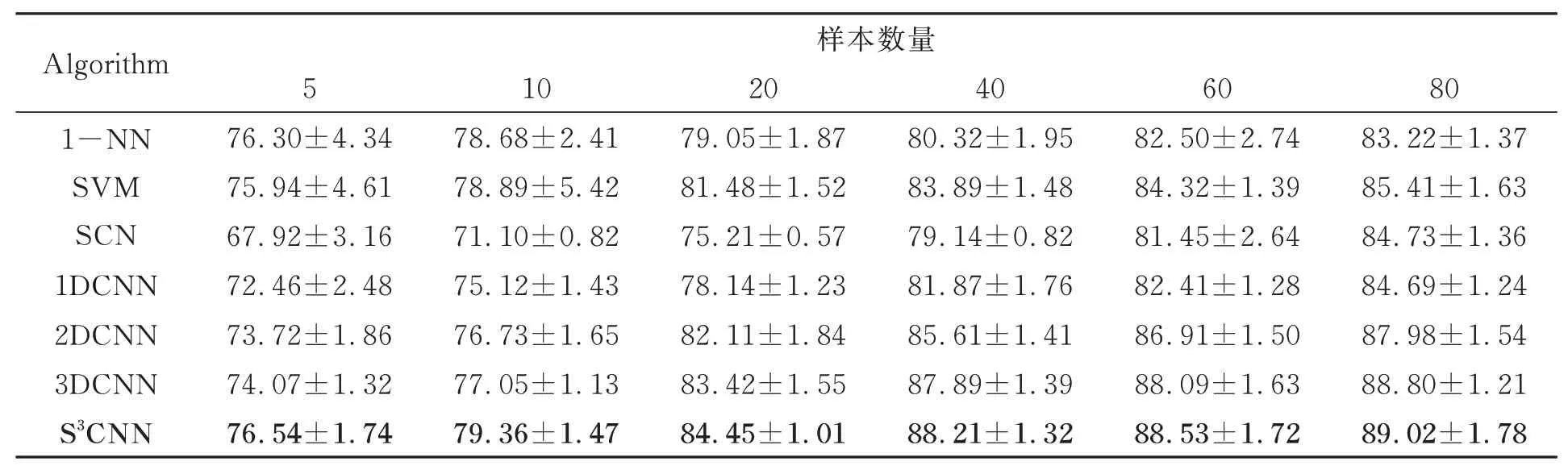
表2 Bloodcells2-2數據集上不同算法的分類結果(總體分類精度±標準差)Tab.2 Classification results of different algorithms on Bloodcells2-2 dataset(overall accuracy±STD) (%)
圖8為各算法的分類結果圖。由圖可知,各算法中S3CNN效果更好,這是因為S3CNN有效地重構了訓練樣本的空-譜近鄰點,充分挖掘了空-譜信息,因此整體準確率更高,具有更好的分類效果。
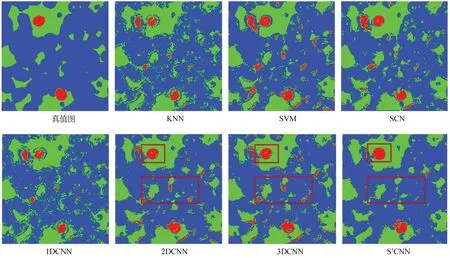
圖8 各算法在Bloodcells2-2數據集上的分類結果圖Fig.8 Classification maps for different methods on Bloodcells2-2 dataset.
為了探究S3CNN算法的時間復雜度,在Bloodcells2-2數據集上對所采用的可分離卷積與經典卷積算法進行訓練時間對比實驗。實驗中選取6 000個樣本點進行訓練,訓練時間結果如表3所示。
由表3可知,可分離卷積模型和經典卷積相比,可分離卷積模型減少27%訓練時間,這是因為可分離卷積使用了一個深度卷積和一個點卷積優化經典卷積,使得參數減少,降低了模型復雜度,更有利于實際應用。

表3 不同卷積方式的訓練時間對比Tab.3 Comparison of training time of different convolution methods on Bloodcells2-2 dataset (min)
4 結 論
在高光譜血細胞分類計數任務中,傳統深度學習方法需要大量不易獲取的標記數據,也未考慮高光譜圖像內部空間結構,對高光譜像素特征提取不夠充分。本文基于可分離卷積方法和空間一致性原則,提出一種空-譜可分離卷積神經網絡(S3CNN)。該方法能有效提取高光譜圖像中的空間-光譜信息,通過空-譜聯合距離選擇各像素點的空-譜近鄰,并對這些近鄰點賦予中心像素點相同的標簽作為訓練集的擴充。此外,考慮到傳統深度學習網絡參數量巨大、對運算硬件要求頗高,采用可分離卷積代替經典卷積,通過降低卷積核參數數量,優化模型的訓練時間。在Bloodcells1-3和Bloodcells2-2高光譜數據集上的實驗結果表明,本文算法可有效挖掘高光譜血細胞顯微圖像中各類成分的內蘊空-譜信息,改善了分類性能,同時減少了訓練時間。然而,S3CNN只考慮高光譜圖像局部空-譜聯合信息,未能有效探索高光譜圖像非線性復雜結構。因此下一步研究工作考慮將圖卷積神經網絡用于高光譜血細胞圖像分類上,構建空-譜聯合圖神經網絡模型,以進一步提升分類效果。
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
