
基于深度學(xué)習(xí)的聚類綜述
2022-05-07 07:07:04董永峰鄧亞晗王雅琮
計(jì)算機(jī)應(yīng)用 2022年4期
董永峰,鄧亞晗,董 瑤*,王雅琮
(1.河北工業(yè)大學(xué)人工智能與數(shù)據(jù)科學(xué)學(xué)院,天津 300401;2.河北省大數(shù)據(jù)計(jì)算重點(diǎn)實(shí)驗(yàn)室(河北工業(yè)大學(xué)),天津 300401;3.河北省數(shù)據(jù)驅(qū)動(dòng)工業(yè)智能工程研究中心(河北工業(yè)大學(xué)),天津 300401)
0 引言
聚類任務(wù)是機(jī)器學(xué)習(xí)、計(jì)算機(jī)視覺、數(shù)據(jù)壓縮等領(lǐng)域的一個(gè)基本問題。傳統(tǒng)聚類方法已經(jīng)發(fā)展得較為成熟,但人類活動(dòng)的幾何式增加導(dǎo)致存儲(chǔ)的數(shù)據(jù)量及復(fù)雜性提升,數(shù)據(jù)之間的連接以及數(shù)據(jù)本身的特征也變得愈發(fā)復(fù)雜,聚類任務(wù)的難度也隨之提升,面臨著計(jì)算復(fù)雜度高、降維效果差、聚類效果下降的問題。數(shù)據(jù)的意義不僅在于數(shù)據(jù)本身,更在基于數(shù)據(jù)之上所進(jìn)行的一系列分析活動(dòng),幫助人們發(fā)掘潛在信息,產(chǎn)生有價(jià)值的深層信息。
近年來(lái),深度學(xué)習(xí)得益于強(qiáng)大的特征的提取和表示能力,它與聚類任務(wù)的結(jié)合受到了廣泛的關(guān)注,基于深度學(xué)習(xí)的聚類,也稱深度聚類(Deep Clustering,DC)逐漸興起。DC本質(zhì)上是通過深度學(xué)習(xí)強(qiáng)大的表示能力來(lái)提升聚類結(jié)果的一類較為領(lǐng)先的聚類方式,關(guān)鍵在于抽取數(shù)據(jù)的表達(dá)——要求既能利用神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)適宜聚類的數(shù)據(jù)的低維表達(dá),又能夠體現(xiàn)原數(shù)據(jù)的信息特征及結(jié)構(gòu)特征,從而實(shí)現(xiàn)更好的聚類效果。文獻(xiàn)[1]在傳統(tǒng)聚類的發(fā)展基礎(chǔ)上對(duì)大數(shù)據(jù)聚類和小數(shù)據(jù)聚類進(jìn)行了分析與總結(jié),文獻(xiàn)[2]則結(jié)合近些年的發(fā)展,總結(jié)了深度聚類早期一些卓有成效的代表性算法,但其缺乏對(duì)于圖神經(jīng)網(wǎng)絡(luò)(Graph Neural Network,GNN)的深度聚類的研究。隨著人工智能技術(shù)的不斷滲透,GNN 的機(jī)器學(xué)習(xí)越來(lái)越受到研究者和實(shí)踐者的關(guān)注,且在分類、聚類、鏈接預(yù)測(cè)等任務(wù)中的應(yīng)用越來(lái)越廣泛。本文以提取聚類特征的不同網(wǎng)絡(luò)結(jié)構(gòu)為標(biāo)準(zhǔn),介紹基于自動(dòng)編碼器(AutoEncoder,AE)、基于損失的深度神經(jīng)網(wǎng)絡(luò)(Deep Neural Network,DNN)、基于生成對(duì)抗網(wǎng)絡(luò)(Generative Adversarial Network,GAN)、基于變分自動(dòng)編碼器(Variational Auto-Encoder,VAE)、基于GNN 的深度聚類五類不同方法,特別研究基于GNN 的深度聚類方法,歸納為基于結(jié)構(gòu)化和多視角的GNN的深度聚類。在此基礎(chǔ)上,總結(jié)歸納深度聚類的存在問題、評(píng)價(jià)指標(biāo)、應(yīng)用領(lǐng)域及后續(xù)研究方向。
1 深度聚類方法
聚類方法的發(fā)展和研究為深度聚類的產(chǎn)生提供了強(qiáng)有力的鋪墊。得益于深度學(xué)習(xí)強(qiáng)大的非線性映射和特征提取能力,近年來(lái),將深度學(xué)習(xí)應(yīng)用于聚類的方法成為了一個(gè)研究的趨勢(shì)。深度聚類根據(jù)提取特征的網(wǎng)絡(luò)結(jié)構(gòu)可以分為基于AE、基于損失的DNN、基于GAN、基于VAE、基于GNN 五大類,如表1 所示。

表1 深度聚類算法總結(jié)Tab 1 Summary of deep clustering algorithms
1.1 基于AE的深度聚類
AE 是無(wú)監(jiān)督表示學(xué)習(xí)中最重要的算法之一,由Rumelhart 于1986 年首次提出。它是一種典型的無(wú)監(jiān)督式機(jī)器學(xué)習(xí)方法,能夠有效地訓(xùn)練映射函數(shù),盡可能保證編碼層與重構(gòu)層的誤差達(dá)到最小。由于隱藏層的維度通常比輸入數(shù)據(jù)的維數(shù)更小,它可以幫助找到數(shù)據(jù)最顯著的特征。
AE 主要由編碼器和解碼器兩部分組成,其整體結(jié)構(gòu)如圖1 所示。輸入層與輸出層維數(shù)相同,隱藏層維數(shù)小于輸入層及輸出層。從輸入層映射到隱藏層的編碼器h
=f
(x
)用來(lái)映射原始的數(shù)據(jù)x
到隱藏層表示h
;解碼器y
=g
(h
)用來(lái)生成重構(gòu)表示,且要求重構(gòu)后的數(shù)據(jù)盡可能地接近原始數(shù)據(jù)x
,一般取Sigmoid 作為解碼器的激活函數(shù)。圖1 顯示了在基于AE 的深度聚類中,損失函數(shù)由兩部分構(gòu)成:橫向得出的重構(gòu)損失L
保證了網(wǎng)絡(luò)可以強(qiáng)制學(xué)習(xí)到原始數(shù)據(jù)的可行表示;縱向得出的聚類損失L
是隱藏層在聚類任務(wù)中造成的損失。因此基于AE 的聚類整體損失函數(shù)為:
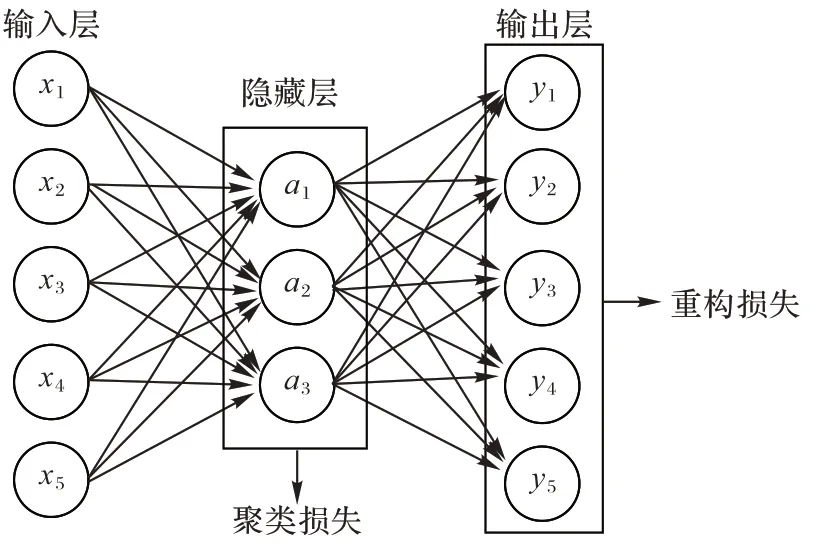
圖1 基于AE的深度聚類Fig.1 Deep clustering based on AE
DEN(Deep Embedding Network)是一個(gè)較為經(jīng)典的基于AE 的深度聚類模型。該模型利用AE 學(xué)習(xí)隱藏表示,應(yīng)用局部保留約束保留原始數(shù)據(jù)的局部結(jié)構(gòu)屬性,與結(jié)構(gòu)損失共同進(jìn)行優(yōu)化,提升了聚類效果。
AE 最大的優(yōu)勢(shì)就是幾乎可以與任何聚類方法相結(jié)合,普適性較高且簡(jiǎn)單易行;但是,由于編碼器的對(duì)稱結(jié)構(gòu),其網(wǎng)絡(luò)的深度限制了計(jì)算的可行性;此外,平衡聚類損失和重構(gòu)損失的參數(shù)λ
也需根據(jù)實(shí)際應(yīng)用的不同需求,依賴人工進(jìn)行調(diào)節(jié)。1.2 基于損失的DNN的深度聚類
神經(jīng)網(wǎng)絡(luò)是受到生物神經(jīng)元間的鏈接方式的啟發(fā)而出現(xiàn)的,逐漸發(fā)展為卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)。如圖2 所示,一個(gè)完整的CNN 一般由輸入層、卷積層、池化層、全連接層和Softmax 層5 部分組成,深度聚類任務(wù)與其結(jié)合時(shí)可以只考慮聚類損失。
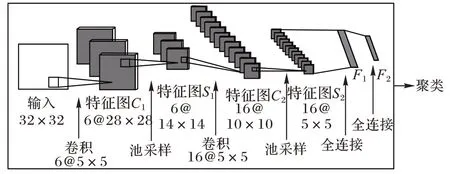
圖2 CNN與聚類的結(jié)合Fig.2 Combination of CNN and clustering
隨著研究的深入,深度卷積神經(jīng)網(wǎng)絡(luò)(Deep CNN,DCNN)在保留神經(jīng)網(wǎng)絡(luò)的層級(jí)結(jié)構(gòu)的基礎(chǔ)上,在層的功能和形式上進(jìn)行變化,通過局部感知、共享權(quán)值、池采樣等方式充分利用數(shù)據(jù)的局部特性優(yōu)化網(wǎng)絡(luò)結(jié)構(gòu),與聚類任務(wù)再次結(jié)合時(shí),效果得到了進(jìn)一步提升。這類DNN 同樣可以只利用聚類損失去訓(xùn)練網(wǎng)絡(luò),其中使用的網(wǎng)絡(luò)可以替換為全卷積神經(jīng)網(wǎng)絡(luò)(Fully Convolutional Neural network,F(xiàn)CN)或深度置信網(wǎng)絡(luò)(Deep Belief Network,DBN)等。
因?yàn)樵擃惿疃染垲惖膿p失均由聚類產(chǎn)生,因此它的損失函數(shù)為:

由于不像AE 一樣存在重構(gòu)損失,應(yīng)著重設(shè)計(jì)聚類任務(wù)與網(wǎng)絡(luò)的適配性,使得神經(jīng)網(wǎng)絡(luò)提取的數(shù)據(jù)特征更加適應(yīng)聚類任務(wù)的需求。當(dāng)提取的特征數(shù)據(jù)簇間區(qū)別不大時(shí),聚類損失會(huì)大幅度減小,這對(duì)于深度聚類實(shí)際使用是十分不利的。
針對(duì)這個(gè)問題,可以從網(wǎng)絡(luò)初始化進(jìn)行改善,獲得適宜聚類的數(shù)據(jù)。根據(jù)網(wǎng)絡(luò)初始化方式的不同,可分為無(wú)監(jiān)督的預(yù)訓(xùn)練,如DEC(Deep Embedded Clustering);有監(jiān)督的預(yù)訓(xùn)練,如CCNN(Clustering CNN);隨機(jī)初始化,如DAC(Deep Adaptive Clustering)。
基于損失的DNN 的深度聚類優(yōu)勢(shì)在于,因?yàn)樗会槍?duì)聚類損失進(jìn)行優(yōu)化,所以網(wǎng)絡(luò)的深度不受限制。通過有監(jiān)督的預(yù)訓(xùn)練可以促使網(wǎng)絡(luò)提取出更多顯著特征,優(yōu)化聚類效果,從而能夠?qū)Υ笠?guī)模圖像數(shù)據(jù)集進(jìn)行聚類。
1.3 基于GAN的深度聚類
GAN 是一種生成式學(xué)習(xí)框架,由一組生成器和鑒別器組成,它的原理是在生成網(wǎng)絡(luò)G
和鑒別網(wǎng)絡(luò)D
這兩個(gè)神經(jīng)網(wǎng)絡(luò)之間建立了一個(gè)最小最大的對(duì)抗性博弈,目標(biāo)是實(shí)現(xiàn)發(fā)生器和鑒別器之間的平衡。其結(jié)構(gòu)如圖3 所示,生成網(wǎng)絡(luò)將隨機(jī)噪聲z
作為輸入,輸出生成的偽造數(shù)據(jù)G
(z
)。鑒別網(wǎng)絡(luò)的輸入為真實(shí)數(shù)據(jù)x
或生成數(shù)據(jù)G
(z
),輸出其來(lái)自真實(shí)數(shù)據(jù)的概率,即讓鑒別網(wǎng)絡(luò)試圖根據(jù)數(shù)據(jù)分布計(jì)算輸入是真實(shí)樣本的概率。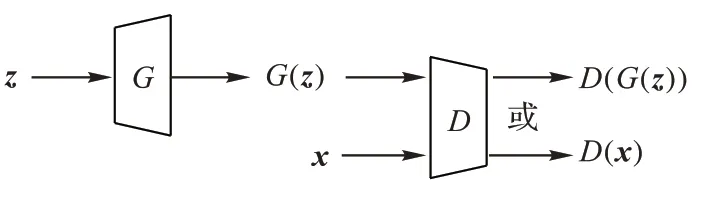
圖3 GAN的結(jié)構(gòu)Fig.3 Structure of GAN
GAN 的目標(biāo)表述如下:

InfoGAN(Information maximizing GAN)在GAN 框架的基礎(chǔ)上,可以分解離散的和連續(xù)的潛在因素,并擴(kuò)展到復(fù)雜的數(shù)據(jù)集。InfoGAN 在聚類效果上的高效率主要來(lái)自最大化噪聲變量的固定小子集和觀測(cè)數(shù)據(jù)之間的互信息。
基于GAN 的優(yōu)化算法在基礎(chǔ)框架上可以施加多類先驗(yàn)性,使得框架更靈活、更多樣化,但它存在模態(tài)易崩潰、難以收斂等缺點(diǎn)。
1.4 基于VAE的深度聚類
和GAN 相似,VAE 也是一種強(qiáng)大的生成式學(xué)習(xí)框架,區(qū)別在于VAE 試圖最大限度地提高數(shù)據(jù)對(duì)數(shù)似然的下限,結(jié)構(gòu)如圖4 所示。
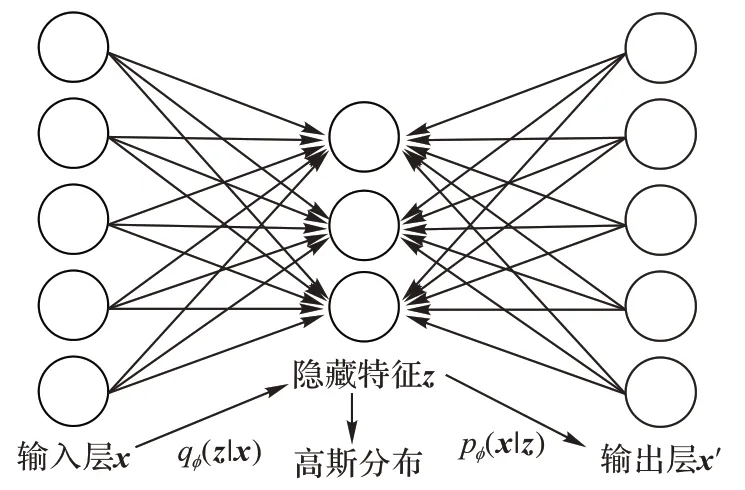
圖4 VAE的結(jié)構(gòu)Fig.4 Structure of VAE
VAE 的整體結(jié)構(gòu)上類似于AE,都含有編碼與解碼的過程,但本質(zhì)上并不相同。VAE 的強(qiáng)大之處在于它引入了神經(jīng)網(wǎng)絡(luò)以適應(yīng)條件后驗(yàn),通過變分下界的重新參數(shù)化得到一個(gè)下界估計(jì)器,該估計(jì)器可以使用標(biāo)準(zhǔn)隨機(jī)梯度方法直接優(yōu)化,可用于幾乎任何具有連續(xù)潛在變量的模型中的有效近似后驗(yàn)推斷。VAE 的目標(biāo)函數(shù)表述為:

q
(z
|x
)是一個(gè)概率編碼器,p
(x
|z
)是一個(gè)概率解碼器。q
(z
|x
))利用深度網(wǎng)絡(luò)來(lái)實(shí)現(xiàn),而隱藏層z
本身服從高斯分布,可以理解為讓生成網(wǎng)絡(luò)(編碼器)部分的輸出盡可能服從高斯分布,這也是VAE 與AE 的區(qū)別,AE 中的隱藏層則沒有分布要求。除此以外,AE 只能重構(gòu)輸入數(shù)據(jù),而VAE 可以生成含有輸入數(shù)據(jù)特征與參數(shù)的新數(shù)據(jù)。GMVAE(Gaussian Mixture VAE)和VaDE(Variational Deep Embedding)均是在VAE 的基礎(chǔ)上,優(yōu)化了觀察樣本x
的生成,進(jìn)而提升了聚類的效果。總的來(lái)看,VAE 施加了高斯混合模型先驗(yàn),保證了理論上的優(yōu)勢(shì),但是其計(jì)算復(fù)雜度較高。
1.5 基于GNN的深度聚類
傳統(tǒng)的深度學(xué)習(xí)方法在提取歐氏空間數(shù)據(jù)的特征方面取得了巨大的成功,但許多實(shí)際應(yīng)用場(chǎng)景中的數(shù)據(jù)是由非歐氏空間生成的。圖的復(fù)雜性使得現(xiàn)有的深度學(xué)習(xí)算法在處理聚類問題時(shí)面臨著巨大的挑戰(zhàn)。這是因?yàn)閳D是不規(guī)則的,每個(gè)圖都有一個(gè)大小可變的無(wú)序節(jié)點(diǎn),圖中的每個(gè)節(jié)點(diǎn)都有不同數(shù)量的相鄰節(jié)點(diǎn)。此外,現(xiàn)有深度學(xué)習(xí)算法的一個(gè)核心假設(shè)是數(shù)據(jù)樣本之間彼此獨(dú)立。然而,對(duì)于圖來(lái)說(shuō),情況并非如此,圖中的每個(gè)數(shù)據(jù)樣本(節(jié)點(diǎn))都會(huì)有邊與圖中其他實(shí)數(shù)據(jù)樣本(節(jié)點(diǎn))相關(guān),這些隱藏信息對(duì)于聚類任務(wù)來(lái)說(shuō)同樣重要。
GNN 是一種直接在圖結(jié)構(gòu)上運(yùn)行的神經(jīng)網(wǎng)絡(luò)。圖數(shù)據(jù)結(jié)構(gòu)因?yàn)槠涮匦浴劝畔ⅲ职畔㈤g的關(guān)聯(lián)結(jié)構(gòu),是近幾年在各個(gè)領(lǐng)域廣泛使用的信息量最大、但也最具挑戰(zhàn)性的數(shù)據(jù)結(jié)構(gòu)之一。在傳統(tǒng)的聚類任務(wù)中,深度聚類的算法都遵循先學(xué)習(xí)特征表示再進(jìn)行聚類的步驟,因此聚類效果并不理想,且學(xué)習(xí)到的特征表示也并非任務(wù)導(dǎo)向的。基于GNN 的深度聚類可以在GNN 的基礎(chǔ)上,一邊學(xué)習(xí)特征節(jié)點(diǎn)的表示、一邊充分利用圖中信息以及圖本身的結(jié)構(gòu),以自訓(xùn)練的方式增強(qiáng)圖聚類的內(nèi)聚性,是提升聚類的有效方式。
1.5.1 結(jié)構(gòu)化的GNN的深度聚類
現(xiàn)有的許多GNN 的深度聚類方法主要是利用圖的結(jié)構(gòu)化數(shù)據(jù),使劃分出的每個(gè)簇實(shí)現(xiàn)內(nèi)部的緊密結(jié)構(gòu),專注于處理圖的結(jié)構(gòu)信息,但這些方法沒有充分利用GNN 中的節(jié)點(diǎn)特征信息。這些方法的經(jīng)典代表包括基于歸一化切割、模塊化和結(jié)構(gòu)密度的聚類。
若將經(jīng)典的聚類方法,如K
-Means 等,直接應(yīng)用于深度聚類,大多情況下只能專注于處理圖的數(shù)據(jù)信息,卻沒有充分利用圖的結(jié)構(gòu)信息,致使聚類結(jié)果依舊不夠理想。基于GNN 的深度聚類方法應(yīng)同時(shí)利用圖的結(jié)構(gòu)信息和內(nèi)容信息,考慮結(jié)構(gòu)相似性和節(jié)點(diǎn)屬性相似性,生成具有內(nèi)聚結(jié)構(gòu)和同構(gòu)節(jié)點(diǎn)屬性的簇。文獻(xiàn)[19-23]在不單純地處理圖的結(jié)構(gòu)信息的同時(shí),又考慮了圖的節(jié)點(diǎn)信息、特征信息,并將聚類的結(jié)果與特征信息的提取通過神經(jīng)網(wǎng)絡(luò)進(jìn)行反復(fù)優(yōu)化,形成了結(jié)構(gòu)化GNN 的深度聚類。1.5.2 多視角的GNN的深度聚類
GNN 的深度聚類大部分結(jié)構(gòu)化算法僅適用于單視圖數(shù)據(jù),即首先將數(shù)據(jù)集中的所有視圖連接合成為單視圖,再在該單視圖上采用結(jié)構(gòu)化聚類算法,但這樣也無(wú)法更好地提高聚類性能,因?yàn)槊總€(gè)視圖都具有其數(shù)據(jù)上特定的統(tǒng)計(jì)特性,所以該方式在物理上沒有意義。由此,多視角聚類(Multi view Clustering,MvC)通過對(duì)不同視圖的多樣性和互補(bǔ)性的結(jié)合,作為一種更加先進(jìn)、全面的深度聚類方式受到越來(lái)越多學(xué)者關(guān)注。表2 介紹了多視角聚類的一些典型算法,可以與GNN 進(jìn)行結(jié)合,優(yōu)化聚類效果。

表2 經(jīng)典多視角聚類算法的優(yōu)缺點(diǎn)比較Tab 2 Advantage and disadvantage comparison of classical multi-view clustering algorithms
2 深度聚類目前存在的問題
2.1 聚類輸入環(huán)境較差
機(jī)器學(xué)習(xí)的成功很大程度上取決于數(shù)據(jù)的質(zhì)量,但是高質(zhì)量的標(biāo)記數(shù)據(jù)通常難以獲得,尤其是對(duì)于訓(xùn)練參數(shù)較多的模型。
為了解決標(biāo)注數(shù)據(jù)較少的問題,一個(gè)常規(guī)的做法是進(jìn)行自監(jiān)督的預(yù)訓(xùn)練,使得模型能從無(wú)標(biāo)注數(shù)據(jù)里學(xué)得數(shù)據(jù)的信息,作為初始化數(shù)據(jù)提供給下游的聚類等任務(wù)中。Hu 等提出了GPT-GNN(Generative Pre-Training of GNN)模型,該模型用生成模型來(lái)對(duì)圖分布進(jìn)行建模,逐步預(yù)測(cè)出一個(gè)圖中的新節(jié)點(diǎn)會(huì)有哪些特征,與哪些節(jié)點(diǎn)相連。作者將每個(gè)節(jié)點(diǎn)的條件生成概率分解為特征生成及圖結(jié)構(gòu)生成,確保圖結(jié)構(gòu)及圖信息的完整性。特別地,對(duì)于預(yù)訓(xùn)練中避免信息泄露、大圖處理及增加負(fù)樣本采樣的準(zhǔn)確性均做了相應(yīng)的模型設(shè)計(jì)。
為了改善聚類步驟的輸入數(shù)據(jù),Lim 等改進(jìn)了Song等提出的方法,提出了一種帶距離的VAE(VAE with Distance,VAED)。VAED 將AE 的距離誤差函數(shù)的輸入從潛在空間中的點(diǎn)轉(zhuǎn)變?yōu)楦怕史植迹⑶覒?yīng)用距離誤差函數(shù)將VAE 和高斯混合模型(Gaussian Mixed Model,GMM)進(jìn)行優(yōu)化,再利用貝葉斯GMM 改進(jìn)了聚類結(jié)果,使得更多隱藏變量和超參數(shù)可以更好地在K
-Means 方法中捕捉潛在空間。2.2 無(wú)監(jiān)督學(xué)習(xí)效率較低
在深度學(xué)習(xí)與傳統(tǒng)聚類進(jìn)行結(jié)合的時(shí)候,需要對(duì)傳統(tǒng)的聚類方法進(jìn)行適當(dāng)?shù)母倪M(jìn),以解決無(wú)監(jiān)督學(xué)習(xí)效率低的問題。
Huang 等對(duì)于需要特定的聚類任務(wù),提出一種深度子空間聚類框架,聯(lián)合嵌入神經(jīng)網(wǎng)絡(luò)的提取特征進(jìn)行子空間學(xué)習(xí)。該框架包含AE、自我表達(dá)層和監(jiān)督競(jìng)爭(zhēng)特征學(xué)習(xí)三個(gè)模塊。為了達(dá)到最佳的聚類結(jié)果,作者首次提出使用一個(gè)Softmax 函數(shù)(軟標(biāo)簽)來(lái)預(yù)測(cè)樣本的聚類效果,并提出聯(lián)合最小損失函數(shù),競(jìng)爭(zhēng)監(jiān)督聚類效果。利用軟標(biāo)簽去近似目標(biāo)置信分配,引導(dǎo)模型在每次迭代中學(xué)習(xí)任務(wù)的目標(biāo)表示。
不同于以上通過軟標(biāo)簽來(lái)預(yù)測(cè)聚類效果的監(jiān)督學(xué)習(xí)方法,F(xiàn)alcon 等研 究 了對(duì)比自監(jiān)督學(xué)習(xí)(Contrastive Selfsupervised Learning,CSL)的優(yōu)勢(shì),并提出了一個(gè)描述CSL 方法概念框架,它包含數(shù)據(jù)擴(kuò)充管道、編碼器選擇、表示提取、相似性度量和損失函數(shù)五個(gè)方面。本文借此設(shè)計(jì)了YADIM(Yet Another variant Deep InfoMax)模型來(lái)展示其框架的實(shí)用性,在CIFAR-10、STL-10 和ImageNet 上都取得了更好的結(jié)果,并且使得編碼器的選擇和表示提取策略更有魯棒性。
Kang 等則基于半監(jiān)督分類算法提出了一種圖的學(xué)習(xí)框架SGMK(Structured Graph learning framework with Multiple Kernel),通過考慮秩約束——如果有c
個(gè)簇或c
個(gè)類,則得到的圖將恰好有c
個(gè)連通的組件來(lái)保存數(shù)據(jù)的局部和全局結(jié)構(gòu)。該框架能從數(shù)據(jù)中自適應(yīng)地學(xué)習(xí)相似圖和標(biāo)簽,但時(shí)間復(fù)雜度仍然較高。為了達(dá)到深度聚類的無(wú)監(jiān)督學(xué)習(xí)的目的,Zhu 等在沒有監(jiān)督的情況下,直接從圖數(shù)據(jù)的屬性和結(jié)構(gòu)中學(xué)習(xí)區(qū)分特征,提出了一種無(wú)監(jiān)督感知GNN 模型CAGNN(Cluster-Aware GNN)。其主要思想是在節(jié)點(diǎn)上執(zhí)行聚類,并通過預(yù)測(cè)聚類分配來(lái)更新模型參數(shù)。作者細(xì)化了圖的拓?fù)浣Y(jié)構(gòu),通過加強(qiáng)類內(nèi)邊緣和基于類的標(biāo)簽減少不同類之間的節(jié)點(diǎn)連接,更好地保留了嵌入空間中的類結(jié)構(gòu)。
2.3 圖信息處理不當(dāng)
以下兩個(gè)問題主要針對(duì)GNN 的深度聚類提出:
為了解決圖隱藏信息抽取不全的問題,Wang 等提出了以目標(biāo)為導(dǎo)向的深度學(xué)習(xí)算法DAEGC(Deep Attentional Embedded Graph Clustering),該算法由圖注意力網(wǎng)絡(luò)自動(dòng)編碼器和自訓(xùn)練聚類兩部分構(gòu)成。第一次提出基于圖注意力的AE,通過衡量每個(gè)節(jié)點(diǎn)的鄰居來(lái)學(xué)習(xí)每個(gè)節(jié)點(diǎn)的隱藏表示,將屬性值與潛在表示中的圖結(jié)構(gòu)結(jié)合起來(lái)。同時(shí),為了解決無(wú)監(jiān)督的圖聚類任務(wù)所學(xué)習(xí)到的嵌入是否達(dá)到最優(yōu)化的問題,作者除了優(yōu)化重構(gòu)誤差外,還將隱藏的嵌入內(nèi)容輸入到自優(yōu)化聚類模塊中,降低聚類損失,幫助AE 利用嵌入自身的特征和分散嵌入點(diǎn)來(lái)操縱嵌入空間以獲得更好的聚類性能。
Jia 等為了解決圖中鄰居信息重復(fù)聚集導(dǎo)致計(jì)算低效的問題,提出了層次聚合計(jì)算圖搜索算法HAG(Hierarchically Aggregated computation Graph),該算法是新的GNN 表示形式,提出通過分層管理中間的聚合結(jié)果來(lái)避免信息冗余,從而消除不必要的計(jì)算及數(shù)據(jù)傳輸;引入了一個(gè)精確的成本函數(shù)來(lái)定量評(píng)估不同HAG 的運(yùn)行時(shí)性能,并使用新穎的HAG 搜索算法來(lái)查找最優(yōu)的HAG,使得最終結(jié)果大幅優(yōu)于傳統(tǒng)GNN 的表示。
2.4 圖結(jié)構(gòu)信息丟失
為了解決數(shù)據(jù)結(jié)構(gòu)被忽略的問題,Bo 等受到圖卷積網(wǎng)絡(luò)(Graph Convolutional Network,GCN)成功編碼圖結(jié)構(gòu)的啟發(fā),提出了一個(gè)結(jié)構(gòu)化的深度聚類網(wǎng)絡(luò)(Structural Deep Clustering Network,SDCN)算法,該算法由K
NN 模塊(有監(jiān)督學(xué)習(xí)的K
近鄰的機(jī)器學(xué)習(xí)算法模塊)、DNN 模塊(AE 學(xué)習(xí)模塊)、GCN 模塊(圖卷積模塊)以及雙重自我監(jiān)督模塊構(gòu)成。作者在該算法的GCN 模塊中引入了一個(gè)傳遞算子,將表征進(jìn)行加權(quán)求和,然后再傳入標(biāo)準(zhǔn)圖卷積層中學(xué)習(xí)結(jié)構(gòu)信息,從而為AE 中每一層學(xué)習(xí)到的表征都加入結(jié)構(gòu)信息,同時(shí)保留AE 學(xué)習(xí)數(shù)據(jù)自身特性的作用。與SDCN 算法類似,Zhang 等則提出一種屬性圖聚類的自適應(yīng)的圖卷積(Adaptive Graph Convolution,AGC)算法,利用了多層GNN 來(lái)提升聚類的效果。主要提出了自適應(yīng)的k
階圖卷積,當(dāng)類內(nèi)距離開始變小時(shí),停止搜索并確定k
值,達(dá)到自適應(yīng)的目的。與SDCN 不同的是,AGC 是從圖信號(hào)處理譜圖理論的角度來(lái)理解GNN 并增強(qiáng)了聚類效果,優(yōu)勢(shì)在于AGC 可以自適應(yīng)地確定階數(shù)k
,而SDCN 則需要手動(dòng)指定權(quán)重及階數(shù)。3 深度聚類評(píng)價(jià)指標(biāo)
目前對(duì)于深度聚類的評(píng)價(jià)指標(biāo),主要使用以下常用的關(guān)鍵評(píng)價(jià)指標(biāo):準(zhǔn)確率(Accuracy,Acc)、標(biāo)準(zhǔn)互信息(Normalized Mutual Information,NMI)、調(diào)整互信息(Adjusted Mutual Information,AMI)、蘭德指數(shù)(Rand Index,RI)和調(diào)整蘭德指數(shù)(Adjusted Rand Index,ARI)。
準(zhǔn)確率定義如下:
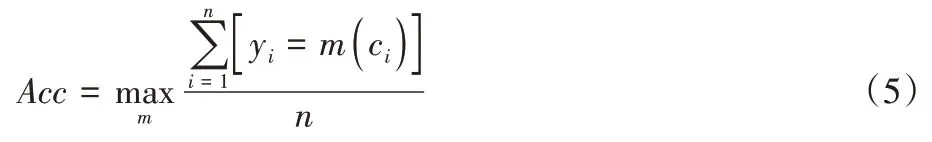
y
是真標(biāo)簽,c
是算法生成的聚類賦值,m
是一個(gè)賦值與標(biāo)簽之間一對(duì)一的映射函數(shù)。NMI 定義如下:

MI
(X
,Y
)為變量X
、Y
間的互信息,H
(X
)為變量X
的熵。AMI 定義如下:
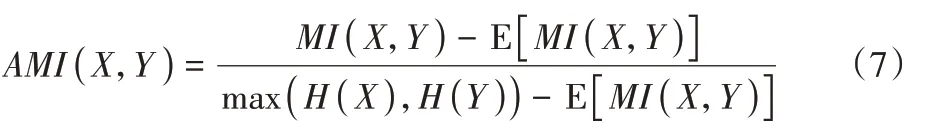
MI
(X
,Y
)]為互信息MI
(X
,Y
)的期望。RI 定義如下:
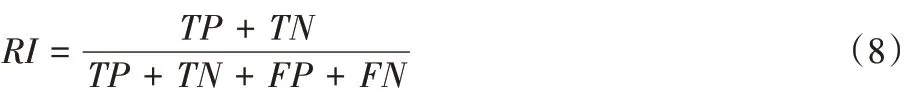
TP
表示兩個(gè)同類樣本在同一簇中的數(shù)量,TN
表示兩個(gè)非同類樣本在不同簇中的數(shù)量,TP
、TN
代表正確的聚類決策;FP
表示兩個(gè)不同類樣本在同一簇中的數(shù)量,FN
表示兩個(gè)同類樣本在不同簇中的數(shù)量,FP
、FN
代表錯(cuò)誤的聚類決策。RI
的取值范圍為[0,1],值越大代表聚類結(jié)果與真實(shí)情況越吻合。但因RI
無(wú)法保證隨機(jī)劃分的聚類結(jié)果的值接近0,因此產(chǎn)生了ARI
,取值范圍為[-1,1],值越大代表聚類越好。
4 深度聚類應(yīng)用方向
深度聚類早期主要應(yīng)用于圖像的識(shí)別,但隨著其技術(shù)的逐步成熟,短短幾年內(nèi)就推廣到了各個(gè)領(lǐng)域,并均有了較好的效果。深度聚類目前主要應(yīng)用在識(shí)別檢測(cè)、圖像處理、事件分析、數(shù)據(jù)預(yù)測(cè)、優(yōu)化處理等。
4.1 識(shí)別檢測(cè)
深度聚類可以完成對(duì)目標(biāo)的識(shí)別與檢測(cè),如對(duì)混凝土結(jié)構(gòu)施工與使用過程中產(chǎn)生的裂縫進(jìn)行識(shí)別。通過將裂縫圖片應(yīng)用到卷積神經(jīng)網(wǎng)絡(luò)中,除去圖片的噪點(diǎn),進(jìn)行裂縫特征的提取與學(xué)習(xí),再結(jié)合聚類的方法,對(duì)圖片進(jìn)行分割、再進(jìn)行識(shí)別、分類,可以實(shí)現(xiàn)復(fù)雜背景下混凝土表面裂縫圖像的精準(zhǔn)識(shí)別,為該結(jié)構(gòu)的維護(hù)、保養(yǎng)和安全檢測(cè)提供了一定的參考依據(jù)。
4.2 圖像處理
圖像處理是聚類任務(wù)的經(jīng)典應(yīng)用,Xie 等提出了一種新的深度多視圖聯(lián)合聚類框架,該框架可以同時(shí)學(xué)習(xí)圖像中的多個(gè)深度嵌入特征、多視圖融合機(jī)制和聚類分配。通過聯(lián)合學(xué)習(xí)策略,可以有效地利用聚類友好的多視圖特征和有用的多視圖互補(bǔ)信息,提高聚類性能。
4.3 事件分析
在事件分析中,可以利用深度聚類對(duì)微博情感、地震特征、社會(huì)事件、學(xué)術(shù)論文等具體事例進(jìn)行內(nèi)容分析。
利用深度聚類也可以對(duì)語(yǔ)音通話內(nèi)容進(jìn)行分析。當(dāng)有多人同時(shí)說(shuō)話時(shí),如何將這些人聲區(qū)分開來(lái)的問題,被稱為雞尾酒會(huì)問題。電力調(diào)度通信系統(tǒng)中,通話雙方的語(yǔ)音內(nèi)容被存儲(chǔ)在單個(gè)錄音文件中,基于注意力機(jī)制的深度聚類網(wǎng)絡(luò)可以很好地解決通話雙方的人聲區(qū)分問題。當(dāng)多個(gè)麥克風(fēng)可用時(shí),可以利用空間信息來(lái)區(qū)分來(lái)自不同方向的信號(hào)。因此將語(yǔ)音光譜和空間特征結(jié)合在一個(gè)深度聚類框架中,同時(shí)利用光譜和空間的互補(bǔ)信息來(lái)改善語(yǔ)音分離。在深度聚類過程中,即使是在隨機(jī)傳聲器陣列的情況下,簡(jiǎn)單地將傳聲器間相位模式編碼為附加的輸入特性,就可以顯著提高語(yǔ)音分離性能。
4.4 數(shù)據(jù)預(yù)測(cè)
深度聚類同樣可以應(yīng)用于數(shù)據(jù)預(yù)測(cè)任務(wù)。現(xiàn)有集群預(yù)測(cè)方法并未考慮集群內(nèi)各風(fēng)電場(chǎng)數(shù)值天氣預(yù)報(bào)信息在時(shí)間序列上的差異性波動(dòng),楊子民等據(jù)此提出了基于天氣過程動(dòng)態(tài)劃分的風(fēng)電集群短期功率預(yù)測(cè)方法,首先對(duì)每份子樣本分別進(jìn)行深度聚類與劃分,構(gòu)建訓(xùn)練集,再通過雙向長(zhǎng)短期記憶人工神經(jīng)網(wǎng)絡(luò)對(duì)各子集群進(jìn)行功率預(yù)測(cè)。
4.5 優(yōu)化處理
利用深度聚類的優(yōu)勢(shì),可以進(jìn)對(duì)視頻圖像、社區(qū)網(wǎng)絡(luò)和多頻網(wǎng)絡(luò)進(jìn)行優(yōu)化。如針對(duì)網(wǎng)絡(luò)社區(qū)發(fā)現(xiàn)這一具體應(yīng)用場(chǎng)景,李亞芳等提出結(jié)合社區(qū)結(jié)構(gòu)優(yōu)化進(jìn)行節(jié)點(diǎn)低維特征表示的深度自編碼聚類模型CADNE(Community-Aware Deep Network Embedding),該模型通過保持網(wǎng)絡(luò)局部及全局鏈接的拓?fù)涮匦詫W(xué)習(xí)節(jié)點(diǎn)低維表示,然后利用網(wǎng)絡(luò)聚類結(jié)構(gòu)對(duì)節(jié)點(diǎn)低維表示進(jìn)一步優(yōu)化,同時(shí)學(xué)習(xí)節(jié)點(diǎn)的低維表示和節(jié)點(diǎn)所屬社區(qū)的指示向量,使節(jié)點(diǎn)的低維表示不僅保持原始網(wǎng)絡(luò)結(jié)構(gòu)中的拓?fù)浣Y(jié)構(gòu)特性,而且保持節(jié)點(diǎn)的聚類特性。
5 結(jié)語(yǔ)
基于深度學(xué)習(xí)的聚類目前取得了一定的進(jìn)展,已成為深度學(xué)習(xí)與機(jī)器學(xué)習(xí)結(jié)合的有效范本,在很多公開數(shù)據(jù)集上都達(dá)到了較為良好的性能,故下一步研究可以從以下幾個(gè)方面入手:
1)無(wú)論使用哪種深度聚類方法,首先需要解決的是數(shù)據(jù)的問題。面對(duì)不同的應(yīng)用問題需要使用不同的模型,而能否通過數(shù)據(jù)的預(yù)處理,或者在特征提取的過程中構(gòu)造出適宜聚類使用的數(shù)據(jù)則顯得尤為重要。
2)伴隨著信息的海量增長(zhǎng),現(xiàn)有的工作依舊面臨著聚類過程中計(jì)算復(fù)雜度高、降維效果差導(dǎo)致聚類效果下降的根本問題。未來(lái)可以探索如何依靠無(wú)監(jiān)督、半監(jiān)督、自監(jiān)督等方法幫助神經(jīng)網(wǎng)絡(luò)進(jìn)行反復(fù)優(yōu)化,如利用對(duì)比學(xué)習(xí)的方式對(duì)數(shù)據(jù)進(jìn)行更好的表示學(xué)習(xí),或者在復(fù)雜問題中通過設(shè)計(jì)優(yōu)良的模型架構(gòu)輔助完成聚類任務(wù)的拆解。
3)在GNN 的深度聚類中,如何對(duì)圖信息以及圖結(jié)構(gòu)的性質(zhì)和特征加以充分利用,仍舊缺乏一個(gè)合理的、整體性的解決方法或思想。對(duì)如何在大規(guī)模的數(shù)據(jù)集或者跨方向的數(shù)據(jù)集中充分提取信息的問題,或可以通過構(gòu)建知識(shí)圖譜解決。
4)圖數(shù)據(jù)的結(jié)構(gòu)極為不同,具有異構(gòu)性、動(dòng)態(tài)性,因此如何根據(jù)關(guān)鍵的子圖結(jié)構(gòu),解決圖的異構(gòu)性、動(dòng)態(tài)性問題,是值得探索的方向。
本文介紹了近年來(lái)深度聚類的方法、歸納闡述了研究過程中普遍存在的問題及應(yīng)用方向。總的來(lái)看,要想得到更好的聚類效果,就要在聚類任務(wù)執(zhí)行前處理得到有效且合適的數(shù)據(jù),獲得數(shù)據(jù)精準(zhǔn)的特征表達(dá)及數(shù)據(jù)之間的關(guān)聯(lián),優(yōu)化所使用的網(wǎng)絡(luò)模型及聚類方法。
