
基于無采樣協作知識圖網絡的推薦系統
2022-05-07 07:07:10蔣雯靜李中志李斌勇
計算機應用 2022年4期
蔣雯靜,熊 熙,3*,李中志,李斌勇
(1.成都信息工程大學網絡空間安全學院,成都 610255;2.先進密碼技術與系統安全四川省重點實驗室(成都信息工程大學),成都 610225;3.四川大學空天科學與工程學院,成都 610065)
0 引言
隨著網絡應用程序的規模日漸擴張,互聯網平臺上的在線內容也呈指數級增長,由此產生的信息超載問題有效地推進了推薦系統的應用:電影推薦、產品推薦、新聞推薦等。在大量面向用戶服務的在線平臺中,信息消費者追求精準推薦的消費快感,信息生產者則希望推送內容能最大限度匹配用戶需求。而推薦系統正是通過充當兩者的媒介,一舉兩得解決了問題。在各種推薦策略中,經典的協同過濾(Collaborative Filtering,CF)方法因其良好的性能被廣泛關注,它基于用戶歷史交互進行偏好分析,為指定用戶提供推薦列表或喜好預測。盡管CF 能獨立于領域知識自動學習嵌入向量,但其受限于數據稀疏性和冷啟動問題。因此,研究者常結合輔助信息來優化推薦性能。
知識圖譜(Knowledge Graph,KG)是一種新興的知識載體,它將文檔數據整合成簡單易懂的三元組形式,并通過節點之間深層次的語義關聯來補償數據稀疏性。例如,(王家衛,導演,阿飛正傳)表明王家衛是《阿飛正傳》的導演。KG作為一種有向異構圖,節點和邊分別對應于不同類型的實體和語義關系。這樣的圖結構意味著KG 具有很強的關系表示能力和建模靈活性,近年來已經被成功應用于許多領域,如KG 補全、問答系統等。
基于知識圖譜的推薦系統正是在這一背景下所提出的新研究問題,強調學習物品(用戶)之間的關聯性,實現KG輔助優化推薦系統。將KG 集成到推薦系統具有以下優勢:1)有利于發現用戶深層次的潛在興趣,進而提升推薦結果的準確性;2)KG 中豐富的關系類型有效避免了推薦結果的單一性;3)用戶和物品之間的連通性為推薦結果提供了合理的解釋。盡管有以上好處,但將KG 中的高維異構信息有效融合到推薦系統具有很大的困難性。一種可取的建模方法是基于知識圖嵌入(Knowledge Graph Embedding,KGE)對KG 中的組件進行預處理,學習實體和關系的低維向量,進而直接應用于推薦任務中。但KGE 忽視了圖結構信息且學習到的向量不足以描述推薦任務。另一種更直觀的方法是基于路徑的推薦,直接利用KG 圖結構建模關聯路徑表示。由于需要手動設計元路徑,這類方法很難達到最優。
近年來,圖神經網絡(Graph Neural Network,GNN)及其變體在以知識圖譜作為額外信息的推薦任務中取得了巨大了成功。借鑒于GNN 中信息傳播的思想,這類方法同時從內容信息和圖結構兩個方面建模數據,有效克服了以往方法的缺陷。因此,目前針對KG 結合推薦的代表性研究很多沿襲了基于GNN 的技術路線。然而,引入GNN 同樣面臨以下問題:1)信息傳播過程中指數級增長的節點數量導致了巨大的內存和時間成本。為了緩解這種情況,現有的方法通常使用采樣策略在訓練時保留節點鄰居或子圖的子集來減輕計算成本。然而,采樣操作可能在優化過程引入誤差。2)深度圖神經網絡架構中固有的梯度消失和特征平滑等問題,導致模型訓練難度較大。盡管最近一些工作表明能在一定程度上改善這些問題,但廣泛的實驗證明深度往往不會帶來顯著的收益性。平衡模型的深度和效率,使圖神經網絡能處理大規模的網絡是現階段的挑戰。
為了緩解上述解決方案的局限性,本文認為開發一個兼具簡單性和表達性的基于知識圖譜的推薦模型是至關重要的。為此,本文從GNN 的研究中獲得靈感,無采樣的單個圖卷積層有潛力實現本文的目標,但在基于KG 的推薦中還沒有得到足夠的探索。因此,本文提出了一種名為無采樣協作知識圖網絡(Non-sampling Collaborative Knowledge graph Network,NCKN)的方法。NCKN 配備了協作傳播和無采樣知識傳播兩種核心設計來分別學習用戶交互中的協作信號和知識嵌入。具體來說:1)在協作傳播模塊中編碼用戶交互中的潛在協作信號,并將其同KG 中的輔助信息結合,以獲得更具表達性的嵌入向量;2)鑒于傳播過程中的采樣誤差問題,設計了無采樣知識傳播層,它通過在單個卷積層使用不同大小的線性聚合器來捕捉深層次的信息,實現高效的無采樣預計算。
本文工作的安排如下:
1)提出了一種NCKN 方法,它通過協作傳播和無采樣知識傳播層,將用戶交互中的協作信號與KG 中的高階信息相結合。
2)將NCKN 應用于三種現實世界的音樂推薦、書籍推薦、電影推薦場景。
1 相關工作
1.1 基于知識圖譜的推薦方法
將知識圖譜作為輔助信息集成到推薦系統已被證明有利于緩解數據稀疏性和冷啟動問題。一些研究利用KG 中實體的關聯性進行嵌入學習,例如:Zhang 等采用TransE(Translating Embedding)學習項目結構信息、內容信息的特征嵌入,并將其統一集成到CF 框架中。Wang 等在DKN(Deep Knowledge aware Network)中將實體嵌入和單詞嵌入視為不同的渠道,并通過TransD(Translating embedding via Dynamic mapping matrix)生成新聞嵌入以供推薦。鑒于推薦任務和KGE 任務的高度相關性,Wang 等提出了一種交替學習兩種任務的推薦框架。和基于嵌入的方法直接利用KG 中的內容信息不同,另一類研究強調學習KG 中的結構信息,例如:PER(Personalized Entity Recommendation)引入元路徑來定義圖中路徑表示,并利用實體間的連接相似性來提供推薦。Hu 等在FMG(Factorization Machine with Group least absolute shrinkage and selection operator)中建議使用元圖來替代元路徑,以提供更豐富的連接信息。
綜合上述方法,為了充分發揮KG 的有效性,研究者提出了結合內容信息和結構信息的統一方法。這類方法最早在Wang 等的RippleNet(Ripple Network)中得到探索,其借鑒GraphSAGE(Graph SAmple and aggreGatE)中的消息傳遞模式,首次提出了偏好傳播的概念。具體來說,RippleNet 以用戶的歷史交互節點作為種子集,在KG 中向外擴散并吸收多跳的鄰居信息,最終得到更深層次的用戶潛在興趣。同樣基于傳播的思想,Wang 等提出了一種融合KG 特征與圖卷積網絡的模型,采用圖卷積網絡通過KG 中的鄰居獲得項目嵌入,這使得鄰居的信息能夠導致推薦任務完成質量的巨大提升。KGAT(Knowledge Graph Attention Network)提出了協作知識圖,將用戶項二部圖與知識圖結合在一起,通過GNN 和注意機制在KG 上遞歸地執行傳播來優化實體嵌入。Wang 等通過異構傳播分別編碼用戶交互和輔助信息。鑒于GNN 在信息傳播和推理上的自身優勢,這類方法能更有效地在推薦任務中引入KG 中的信息。
本文在利用圖卷積來優化實體嵌入的基礎之上,提出了無采樣策略,并與用戶交互中的協作信號相結合,以提升推薦結果的準確性。
1.2 圖神經網絡的應用
本文的方法在概念上啟發于圖神經網絡,并將其擴展為適用于知識圖譜的無采樣圖模型。圖神經網絡作為當下熱門的深度學習模型,在處理復雜的圖結構數據時顯示出巨大的優勢。在早期的關于圖神經網絡的研究中,諸如圖卷積網絡(Graph Convolution Network,GCN)、圖注意網絡(Graph Attention Network,GAT)等模型在訓練時使用全批次梯度下降的方法,圖中數量龐大的鄰居信息和節點特征導致了巨大的內存成本和計算復雜度。為了解決傳統方法中可擴展性問題,Hamilton 等在GraphSAGE 中首次提出了結合鄰域采樣和小批次訓練的策略。其核心思想是從訓練節點開始,在每一跳隨機采樣固定數量的鄰居節點,持續L
跳,并以節點為中心進行小批次訓練。然而,GraphSAGE 在隨機采樣時部分節點重復出現,可能會增加冗余計算量。為了解決這個問題,不少后續模型集中于研究先進的采樣策略,如ClusterGCN(Cluster Graph Convolution Network)和RSage(Recurrent Sampling to gather neighbor nodes)。盡管采樣策略有效降低了模型的計算復雜度,但同時也引入了額外的誤差,這也是本文的模型重點關注的問題。2 問題定義
在一個主流的推薦系統中,假設用戶集合U
={u
,u
,…,u
}和項目集合V
={v
,v
,…,v
}。根據用戶和項目的歷史交互,定義用戶反饋矩陣為Y
,其中y
=1 表明用戶與項目間存在反饋行為,如點擊、轉發、評分等,否則為0。但是需要注意,y
為0 并不完全意味著用戶對該項目不感興趣。此外,給定項目知識圖譜G
={(h
,r
,t
)|h
,t
∈K
,r
∈R
},其中每個三元組表示實體h
和實體t
間存在關系r
,K
和R
分別對應于實體和關系集合。例如,三元組(劉亦菲,演員,花木蘭)陳述了劉亦菲是電影《花木蘭》的演員的事實。在實際推薦場景中,項目V
可能與G
中的一個或多個實體存在映射關系。例如,圖書《傲慢與偏見》與KG 中的一個實體同名,而標題為“劉亦菲出席花木蘭首映禮”的新聞則于“劉亦菲”和“花木蘭”多個實體有關。使用A
={(v
,e
)|v
∈V
,e
∈K
} 來表示存在映射關系的集合,其中(v
,e
)表明項目v
可以與知識圖中的實體e
對齊。
3 本文方法
3.1 整體框架
本節詳細介紹了所提出的NCKN 模型的架構,如圖1 所示,模型分為四個模塊:1)嵌入層:通過知識圖嵌入方法學習KG 中實體和關系的嵌入向量;2)無采樣知識傳播層:在KG傳播過程不進行選擇性采樣,利用單個圖卷積層預聚合全部的鄰居信息,更新節點特征;3)協作傳播層:將用戶交互中的關鍵協作信號編碼為用戶和項目的初始偏好,并同KG 中的輔助信息相結合;4)預測層:依據最終的用戶和項目向量,輸出預測結果。

圖1 NCKN模型框架Fig.1 Model framework of NCKN
3.2 嵌入層
在保持原有圖結構的前提下,利用知識圖嵌入方法將KG 中的實體和關系轉換為低維的向量表示。在該模塊,本文使用了具有良好表現的TransR方法。具體來說,對于每個三元組(h
,r
,t
),考慮到同一關系對應的實體具有不同層面的信息,它將實體和關系分別建模到兩個不同空間。其可信度評分函數如式(1)所示:
e、e
、e
分別是h
、r
、t
的嵌入向量表示;W
為關系r
的轉換矩陣。g
(h
,r
,t
)的值越低意味著三元組的可信度越高;反之,三元組的可信度越低。損失函數如式(2)所示:

h
,r
,t
′)為對真實三元組(h
,r
,t
)進行隨機替換生成的負樣本;σ
(·)為Sigmoid 函數。3.3 無采樣知識傳播層
接下來,本文基于圖卷積網絡的架構,將不同大小且固定的線性聚合器結合在單個卷積層,便于進行高效的無采樣預計算。此外,考慮到實體之間連通性的重要性不同,在傳播過程中引入了注意力機制。
請注意,不同于堆疊多個卷積層的深度圖神經網絡,本文的方法僅通過單個卷積層進行預計算。盡管只使用了淺層的網絡,NCKN 通過設計更有效的傳播矩陣且考慮所有鄰居信息,實現了和深層網絡相當的性能。具體來說,該層由三個組件組成:注意力、信息傳播、鄰居聚合。
3.3.1 注意力
通過關系注意力機制實現π
(h
,r
,t
),如式(3)所示。tanh 是非線性激活函數,注意力分數由關系空間中e
和e
的距離決定。
N
為以實體h
為頭節點的三元組集合。
值得注意的是,為了不破壞圖聚合操作時高效的預計算,本文方法僅通過訓練圖的一個小子集來預先確定注意力參數,然后固定它們計算出訓練中所使用的傳播矩陣。對于注意力模塊的進一步改進將作為未來需探索的工作。
3.3.2 信息傳播
KG 中的實體和鄰居之間有著不同程度的關聯性,為了有效擴展用戶和項目的潛在偏好,本文在傳播過程中考慮節點的高階鄰居信息。如式(5)所示,根據固定的注意力參數,計算出初始傳播矩陣。

B
,圖操作有效地獲取n
跳以內的鄰域信息。為了權衡實體鄰接信息的完整度與計算鄰接矩陣所需時間,設置n
最大值為3。3.3.3 鄰域聚合
如式(6)所示,通過在單個卷積層使用不同大小的線性聚合器來捕捉深層次的信息,實現高效的無采樣預計算。例如,在線性聚合器CX
中(X
為節點特征矩陣),設置不同冪級數的傳播矩陣(C
=B
,C
=B
,…,C
=B
),并將其連接。這個思想類似于卷積神經網絡中的初始模塊(在同一卷積層結合不同大小的卷積核)。由于CX
可以預計算,該方法考慮傳播過程中的所有鄰居信息而不進行選擇性采樣。
3.4 協作傳播層
與傳統推薦算法中使用獨立的潛在向量不同,本文在協作傳播層中同時獲取用戶和項目的初始偏好,以便于同知識嵌入結合得到用戶和項目的擴展偏好。
直觀來說,用戶的歷史交互項目能一定程度上表示該用戶的偏好。通過將用戶歷史交互中的相關項目集與KG 中的實體對齊,轉換為在KG 中計算的特征集。用戶的特征集定義為:

對用戶的特征集歸一化:

V
為項目v
的協作項目集,表示形式如式(9)所示:
v
的特征集為:
對項目的初始集歸一化并加上項目自身對齊實體的特征:

3.5 預測層


Loss
計算如式(13)所示。其中P
為正樣本,P
為負樣本。
4 實驗與結果分析
本章將針對音樂、書籍和電影三個真實數據集來評估模型性能,探討以下研究問題:
1)與已有的基于知識圖譜的推薦算法相比,本文提出的模型表現如何?
2)模型中的關鍵組件和參數設置如何影響推薦結果?
4.1 數據集
本文使用以下三種真實數據集評估模型性能:Last.FM(Music)、Book-Crossing(Book)、MovieLens-20M(Movie),表1給出了相關統計信息。三個數據集均允許公開訪問,且規模和稀疏性有所不同。

表1 實驗數據集統計信息Tab 1 Statistical information on experimental datasets
1)Last.FM:由Last.FM 在線音樂系統提供的用戶聽歌行為和項目知識。
2)Book-Crossing:從圖書社區統計的讀者評分數據(0 到10 不等)。
3)MovieLens-20M:是一個被廣泛使用在電影推薦領域的測試數據集,文件中包含了在電影網站上的反饋信息,即用戶對每部電影的明確評分(從1 到5 不等)。
鑒于隱式反饋能提供更豐富的交互內容,有利于緩解冷啟動問題,本文首先在數據預處理部分將顯式反饋轉換為隱式反饋。其中1 表示用戶正面評分的樣本,而0 為從未交互集合中隨機采樣的負樣本。Last.FM 和Book-Crossing 的交互數據稀疏,故未設閾值,MovieLens-20M 正面評分閾值設置為4。
除了對用戶和項目的交互數據進行預處理,本文在MicrosoftSatori 中生成每個數據集的項目知識圖譜。具體來說,首先從整個KG 中提取置信度高于0.9 的三元組作為子KG。對于確定的子KG,通過匹配頭節點和尾節點的名字來收集全部有效的實體id。最后,將項目id映射到KG中的實體中,并在子KG 中匹配對應的三元組集。請注意,為了簡化整個過程,本文將排除不存在匹配或存在多個匹配的項目。
4.2 對比算法
BPRMF(Bayesian Personalized Ranking optimizations for Matrix Factorization):一種采用矩陣分解進行優化的經典CF 方法。
CKE(Collaborative Knowledge base Embedding):將CF和多種知識圖融合進行訓練,分別提取了項目知識圖譜中的結構信息、文本信息和視覺信息的特征嵌入。本文僅將結構知識同CF 結合。
PER:利用項目知識圖譜中的關系異構性,引入元路徑來表示不同關系路徑中用戶和項目的連通性,并基于路徑相似度來推薦項目。本文將元路徑定義為項目―屬性―項目屬性。
RippleNet:最近提出的基于偏好傳播的模型。通過將用戶歷史交互項作為KG 傳播中的初始集,在KG 中擴散并聚合多層鄰居信息,得到更深入的用戶潛在偏好表示。
知識圖卷積神經網絡(Knowledge Graph Convolutional Networks,KGCN):最先進的將KG 與圖卷積神經網絡融合的模型,利用圖卷積從知識圖的鄰居中獲得豐富的項目嵌入,導致推薦任務完成質量的巨大提升。
KGAT:也是最先進的融合圖卷積網絡的模型。它將項目知識圖和用戶交互數據結合組成協同知識圖,并在該圖結構上遞歸傳播鄰居來更新目標節點的嵌入。另外在傳播期間使用注意力機制來區分鄰居節點的重要性。
4.3 實驗設置
對每個數據集,按照7∶2∶1 的比例隨機劃分為訓練集、測試集和驗證集。具體來說,針對所選數據集的大小,首先采用保留法將數據集劃分為訓練集和測試集,通常情況下(非大規模數據集)為8∶2。其次,為了更好地檢驗模型訓練程度,會從訓練集中劃分一小部分為驗證集,即最終比例為7∶2∶1。本方法在以下兩個推薦場景中進行評估:1)CTR(Click Through Rate)預測,在訓練完成的推薦模型中預測特定用戶和項目間的交互概率。2)Top-k
推薦,使用從訓練集學習到的推薦模型來選擇測試集中指定用戶預測概率最高的k
項物品。為了驗證這些方法的有效性,本文應用了以下評估指標:1)Precision
:模型推薦項目的準確率。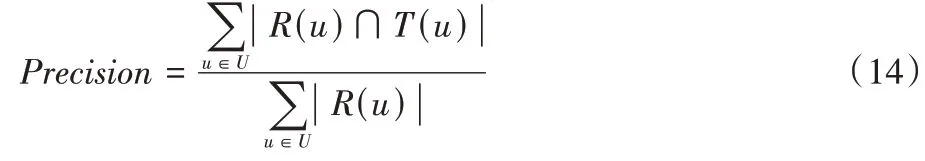
R
(u
)為根據訓練集對用戶推薦的項目列表;T
(u
)為根據測試集對用戶推薦的項目列表。2)Recall
:候選推薦列表的命中率。
F
1:Precision
與Recall
的加權結合,F
1 的值更能體現模型的性能。
AUC
:用于評估推薦系統將用戶喜歡和不喜歡的商品區分的性能。a
為用戶喜歡的商品,b
為用戶不喜歡的商品,每次比較推薦系統對a
和b
的打分,m
為比較的總次數,m
′為a
的評分大于b
的評分的次數,m
″為a
的評分等于b
的評分的次數,AUC 計算公式如式(17)所示。

4.4 實驗結果對比
在CTR 和Top-k
中的預測結果分別如表2 和圖2 所示。根據實驗結果,有以下關鍵結論:
表2 基于AUC和F1指標的CTR預測結果Tab 2 CTR prediction results based on AUC and F1 metrics
從圖2 中的結果來看,基于KG 的推薦方法遠遠優于基于CF 的方法(BPRMF),這說明引入KG 中的額外信息對推薦方法性能有很大的提升。但是,在個別指標上BPRMF 的性能超過了CKE,這表明僅建模KG 中的一階關系可能無法充分發揮KG 的作用,這同時也驗證了NCKN 聚合來自多層高階鄰居信息的有效性。

圖2 基于Recall@k指標的Top-k預測結果Fig.2 Top-k prediction results based on Recall@k metric
NCKN 在CTR 預測中取得了顯著的結果,基于三個數據集都表現最佳。基于Recall@k
的Top-k
預測中,KGAT 在音樂和圖書數據集中性能表現優越,但值得注意的是,在電影數據集中,本文方法NCKN 性能超越了KGAT。本文的推斷是:當數據集規模較小且稀疏性大時,KGAT 能作出更準確的預測;但是對于大規模且信息更稠密的電影數據集,KGAT在用戶交互圖中的高階傳播會引入過多的噪聲,而NCKN 使用一階協作信號和KG 相結合取得了更佳的效果。通過觀察發現所有的方法在三個數據集上的性能排名分別是電影、音樂、書籍。這可能是三個數據集上的用戶平均交互數量和KG 中實體的平均鏈接數量不同導致的。例如,相較于音樂數據集和圖書數據集,電影數據集具有更多的交互行為和關系鏈接數量,其豐富的信息可供推薦模型更準確地學習潛在的特征表示。
與所有的對比方法相比,本文提出的NCKN 在三個數據集上都取得了競爭優勢。具體來說,在CTR 預測中,與主流算法RippleNet、KGCN 相比,NCKN 在指標AUC 下平均分別提升了2.71%、4.60%;在F1 指標下平均分別提升了4.17%、3.28%;在Top-k
中,NCKN 在電影和書籍數據集中平均提升了5.26%、3.91%。。請注意,NCKN 在音樂數據集上表現不足但僅次于KGAT,因為音樂數據集中KG 平均鏈接數量太低,NCKN 中的無采樣策略無法發揮其最佳效果。與RippleNet 相比,證明了NCKN 不使用采樣策略和協作傳播的積極意義。4.5 消融實驗
本節對模型所涉及的關鍵參數和方法進行分析。NCKN的特色在于協同傳播層和無采樣知識圖傳播層的設計。為了驗證這些方法的有效性,進行了消融實驗。
本文分別對嵌入向量的維度和傳播的最大層數進行參數分析。具體來說:
1)在三個數據集上使用不同維度的嵌入來探索其對于模型的影響,圖3(a)顯示了直觀的結果:在一定范圍內,隨著嵌入維度d
的增加NCKN 的性能也得以提升,但超過某個值后,性能逐漸下降。這是因為當d
過大時,可能出現過擬合問題。
圖3 基于AUC的嵌入維度影響Fig.3 Impact of based on AUC embedding dimension
2)為了探索KG 中聚合不同層數的鄰域信息的影響,設置信息傳播n
跳的最大層數,以研究模型的性能會如何改變。圖4 為不同傳播層數的實驗結果,可以觀察到:音樂、書籍、電影分別為3、3、2 時達到最優性能。對這個結果的合理解釋是,高階的鄰域信息補充更豐富的潛在信息,但同時也引入了更多噪聲,特別是對于數據量很大的電影數據集,合理的傳播層數能發揮最佳的效果。

圖4 基于AUC的傳播層數的影響Fig.4 Impact of number of propagation layers based on AUC
為了證明協作傳播層和無采樣知識傳播層的有效性,本文在模型中使用了兩種變體:1)對于協同傳播層,采用兩層協作傳播的變體來進行對比實驗,它被稱NCKN;2)對于無采樣知識傳播層,使用隨機采樣固定數量鄰域節點的變體NCKN來觀察模型的表現能力。表3 的結果表明:在三個數據集上,NCKN 的一階協作傳播層比兩層協作傳播變體具有更優的性能。這說明用戶交互中相互作用的模糊性,更高階的協作傳播反而帶來了更多的噪聲。用戶一階的交互項目能最準確地表示其偏好;而采用無采樣策略的模型相較于使用隨機采樣策略也取得了優勢,這支持了采樣機制可能會帶來誤差的前提。

表3 基于AUC的協作傳播和無采樣知識傳播模塊消融實驗結果Tab 3 Experimental results of AUC-based ablation of collaborative dissemination and non-sampling knowledge dissemination modules
5 結語
本文提出了一種無采樣協作知識圖網絡NCKN。NCKN通過單層圖卷積網絡無采樣地預聚合多層鄰域信息,并將學習到的KG 嵌入和用戶交互中協作信號相結合。
本文考慮在以下兩個方面展開未來的工作:1)由于本文專注于研究無采樣策略的應用,進一步的研究方向是設計出一個更好的方法融合注意力機制,能夠更準確地利用鄰域信息;2)本文的模型為現實場景中的其他輔助信息提供了一個新的思路,比如可以嘗試應用于社交網絡來提高推薦性能。
