
基于情感詞典和堆疊殘差的雙向長短期記憶網絡的情感分析
2022-05-07 07:07:20羅浩然
計算機應用 2022年4期
羅浩然,楊 青
(1.華中師范大學伍倫貢聯合研究院,武漢 430079;2.華中師范大學計算機學院,武漢 430079;3.國家語言資源監測與研究網絡媒體中心,武漢 430077)
0 引言
教育類機器人是教育行業和工業界的一次基于發展的人工智能技術的嘗試,然而對這一部分用戶反饋的研究大部分仍停留在人工分析使用自然語言的購物評論的階段。對于此類新興技術的文本分析,僅使用標準的情感詞典或某類神經網絡是不夠的,因為針對該領域的情感詞匯極少,也沒有有效、科學的分類模型或情感得分量化的算法。基于此,本文的工作主要在于:1)通過無監督學習、聚類算法的結合,合理設置情感分類的一、二級影響因素;2)通過構造情感詞典和深度學習模型并將兩者結合,提高特定領域的情感分類的精準度。
二分法的思想被普遍應用于情感分析中,其中情感分為“積極”和“消極”,一些學者添加了“中立”情感作為補充。對于情感分析來說,情感分類是核心步驟。在這一步中,研究人員需要識別指定文本的主觀觀點,并判斷文本的正面和負面傾向。早年,基于情感詞典的方法是根據經驗總結和整理廣泛使用的情感詞,并將預處理后的輸入與詞典中的情感詞進行匹配。具體來說,需要在輸入中搜索與情感詞典中重疊的情感詞,判斷這些詞的極性,然后得到整個句子的情感取向。分類效果取決于情感詞典的完整性。Kim 等利用詞典將手工采集的種子情感詞集進行擴展來獲取大量的情感詞,但是這種方法的效果對種子情感詞集的個數和質量依賴性比較大。在接下來的十幾年里,許多學者在情感詞匯的研究中不斷探索,李勇敢等通過以詞序流表示文本的LDA(Linear Discriminant Analysis)-Collocation 模型,采用吉布斯抽樣法推導了算法,實現中文微博情感傾向性自動分類。Tan 等提出了一種基于半監督特征提取的情感分類系統,該系統融合譜聚類、主動學習、遷移學習等不同方法提取情緒特征,應用遷移學習的方法完成整個情感分析系統的構建。在搜狐學習評論、搜狐股票評論和中關村電腦評論語料庫的實驗中,這種半監督特征提取的方法的最小f
值可達82.62%。然而,傳統的情感分類方法往往需要高質量的特征構造,如N
元模型(N
-Gram)。基于深度學習的抽象特征可以避免人工特征提取,通過詞的嵌入模擬詞與詞之間的關系,具有局部特征提取和記憶存儲的功能。Johnson 等在深層金字塔卷積神經網絡(Deep Pyramid Convolutional Neural Network for text categorization,DPCNN)中引入了殘差結構,增加了多尺度信息,并且增加了用于文本分類卷積神經網絡(Convolutional Neural Network,CNN)的網絡深度,以提取文本中遠程關系特征,并且并沒有帶來較高的復雜度。Rajasegaran 等通過借助CNN 的成功經驗引入“DeepCaps”這一種深囊網絡結構,并在其中使用基于3D 卷積的動態路由算法。借助DeepCaps,該方法在CIFAR10、Street View House Number(SVHN)和Fashion Mixed National Institute of Standards and Technology(FashionMNIST)性能上超越了最新的膠囊域網絡算法,同時減少了68%的參數量。Zhang 等針對特定任務,對于每個方面層級設計了基于注意力機制的注意力向量,該機制涉及兩個子向量,即維度注意力向量和情感注意力向量,從語義空間的角度解決了神經網絡設計過于復雜的問題。但是,這類具有特定領域屬性、短文本、復合情感的評論的情感分析模型存在著諸多局限性:單一使用情感詞典存在情感詞匯覆蓋率低,編纂、維護詞典工作量大,無法洞察語句中上下單詞的聯系的問題;而單獨使用深度學習方法,在處理一些特定領域的文本時容易出現過度過濾和錯誤處理語氣助詞、修飾詞的情況。因此,本文以科大訊飛、小度、狄刺史、天貓精靈四個智能教育機器人品牌為例,通過爬取在線評論數據、數據清洗并構建一種基于堆疊殘差的雙向長短期記憶(Bidirectional Long Short-Term Memory,Bi-LSTM)網絡和人工構建的情感詞典結合的情感分析算法來判斷評論的情感取向,量化產品質量、性價比和外觀的情感指數,然后將情感指數標準化為某個情感極性的概率,以完成分類任務。研究路徑如圖1 所示。
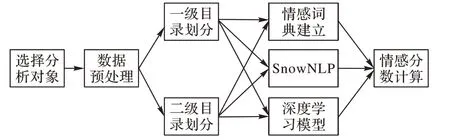
圖1 研究路徑圖Fig.1 Research roadmap
1 數據處理
1.1 數據預處理
本文選取中國四大知名教育機器人品牌旗下的最新型號機器人作為研究對象,包括天貓精靈CC10、小度智能機器人旗艦版、科大訊飛阿爾法大蛋2.0、狄刺史H2,同時選取的四款產品也屬于不同價位,以便于縱向對比。通過基于Python 的爬蟲軟件“后羿采集器”,在淘寶、京東、蘇寧易購等電商平臺上收集了2019 年至2021 年每個品牌的15 000 條在線評論,最終獲得60 000 條評論。
由于自然語言的隨機性和非標準化,原始數據中存在很多噪聲,如語法結構混亂、錯別字模糊、傳統字符和重復注釋,無效的評論、廣告和其他問題。如果這些數據被直接輸入到情感分析模型中,深度學習模型將會學習到大量無意義的數據,模型的分類精準率將嚴重降低。為了過濾冗余數據,本文采取了兩個步驟進行數據清理:首先,使用正則表達式來清理字符串。然而正則化雖然可以初步過濾數據,但仍達不到使用標準,這是因為在評論中仍有許多經常被廣泛使用但沒有實際意義的漢字或英文字母。因此本文以中國科學院開發方漢語詞法分析系統的停用詞表作為基礎停用詞表,結合購物評論的特殊性,添加了部分特定領域內的停用詞,如機器人品牌、顏色、型號、html 標簽名稱等。最終,本文使用的停用詞列表的條目總數為2 072。最后,使用“庖丁分詞”對經過正則表達式和停用詞表處理過后的文本數據進行分詞。
1.2 數據分析
1.2.1 詞頻統計
為了初步了解關鍵詞的分布情況可以計算數據的詞頻。NLTK(Natural Language Toolkit)工具包可以用來計算單詞特征,并建立頻率分布表,導入matplotlib 用來可視化單詞頻率。四個品牌的詞頻可視化結果如圖2 所示。
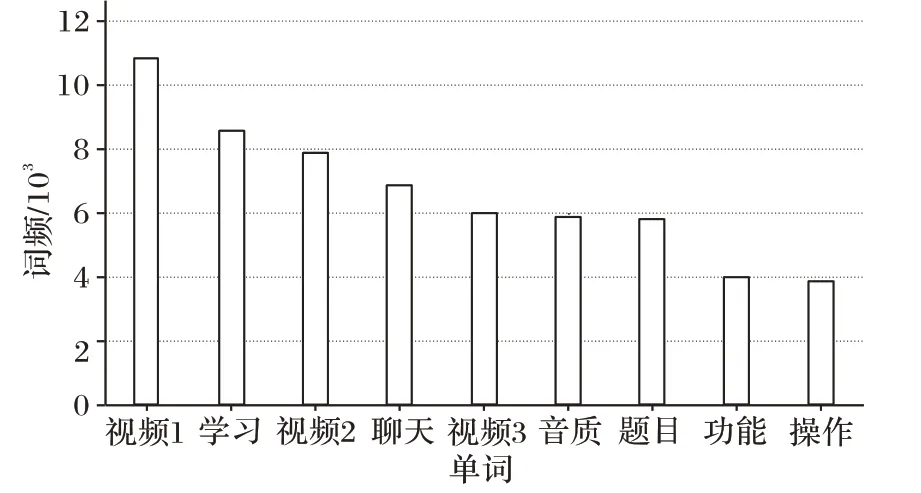
圖2 詞頻統計Fig.2 Word frequency statistics
1.2.2 關鍵詞提取
本文需要對產品的衡量維度進行劃分,主要采取“兩級”劃分法則。主要思路是:首先,通過數據處理和關鍵詞提取技術得到一定數量的關鍵詞作為一級分類,使用聚類算法衡量語句相似度劃分一級目錄下的二級目錄;然后,通過人工情感標注處理后的文本放置在各個分類目錄下,經過詞向量轉化過程進入情感分析的步驟。這樣劃分后的文本評論會根據所屬的不同維度被初步分類,方便觀察分類算法對于不同維度分類下的文本的分類效果,以上過程如圖3 所示。
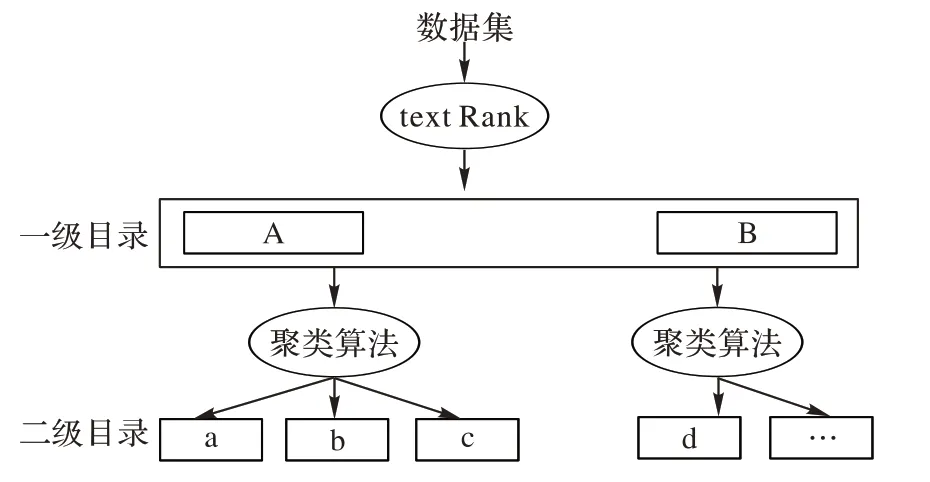
圖3 兩級劃分規則Fig.3 Two-level division rules
1)一級關鍵詞提取。在進行關鍵詞提取時,主要有三類方法:基于統計的詞頻-逆文檔頻率(Term Frequency-Inverse Document Frequency,TF-IDF)方法、基于詞共現圖的TextRank 方法和基于詞語網絡的方法。其中:單獨使用TFIDF 無法同時精準地反映單詞在一篇文本中的重要程度和特征詞的分布情況;而詞語網絡的構造相對復雜,各類參數設置復雜。因此本文采用基于詞共現圖的方法進行關鍵詞提取。
TextRank 算法是一種基于圖的排序算法,通過移動共現窗口表示詞語之間的聯系程度,對后續關鍵詞排序的同時從文本中提取出關鍵詞。TextRank 是對PageRank 的改進算法,該算法著力構造詞匯網絡圖模型,詞語間的相似關系被看成是一種投票關系,計算每一個詞語的重要程度,具體計算如式(1)所示:
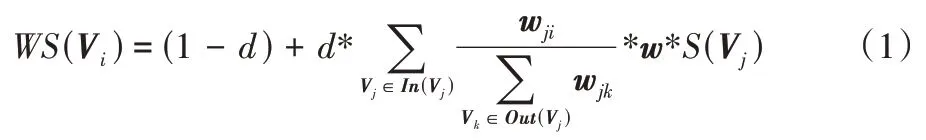
WS
(V
)體現詞語的重要程度,d
為阻尼系數,w
表示兩個節點之間的邊連接具有不同的重要程度,In
(V
)是節點V
的入度點的集合,Out
(V
)是節點V
的出度點集合。下面結合本文的中文文本評論數據集對上述公式做具體分析:首先將每個品牌的評論的評論集T
按照句子進行分割,即T=
[S
,S
,…,S
],對于每個分割結果S∈T
進行分詞和詞性標注,在過濾停用詞后只保留指定詞性為名詞的詞語,即S=
[d
,d
,…,d
],其中d
代表候選關鍵詞,并由此構建關鍵詞圖G=
(V,E
),其中V
是上一步得到的候選關鍵詞的集合;然后根據共現關系(若兩個關鍵詞在長度為k
的窗口中同時存在則認為存在共現關系)構造兩點之間的邊集E
。此外,本文中設置d
為經驗值0.85。根據式(1),遞歸傳播各關鍵詞的權重,直至收斂。將關鍵詞的權重進行倒序排序,取權重值最大的t
個單詞作為關鍵詞。雖然TextRank 可以用來計算詞語的重要性,但是算法不能解決詞語的重要性的差異對相鄰的節點權值轉移的影響問題,基于此本文最終使用了一種TextRank 的改進算法,即使用TF-IDF 和平均信息熵兩個特征來計算詞語的權重,用計算得到的綜合特征信息來改進TextRank 詞匯節點的初始權重大小以及概率轉移矩陣從而共同決定關鍵詞的選取。經計算分析,得到一級關鍵詞如下:學習、影視、交互、用戶體驗、價格。2)二級關鍵詞提取。經過獨熱編碼轉化后的數組作為數據輸入,使用Word2Vec 的CBOW(Continuous Bag-Of-Word)模式下的神經網絡層對二級影響因素的單詞進行向量化處理。因此,為了得到某一領域中某個詞的向量,首先要對該領域的評論集進行預處理,然后利用Gensim 模塊的API 接口添加Word2Vec 訓練詞向量模型。本文使用文本聚類方法K
均值(K
-Means)聚類算法獲得詞向量的聚類結果,使用輪廓系數評價聚類質量。在獲得每個單詞的詞向量后,繪制上一步收集到的特征詞的向量表示。在使用K
-Means進行聚類分析時,首先初始化K
個質心,計算屬于數據集的每個待算數據與K
個質心之間的歐氏距離,找出最小值,將數據添加到相應的簇類中。然后,計算聚類集之間的均方誤差,并對聚類類中每個向量與質心之間的距離進行累加。通過不斷調整K
值和迭代次數,最終發現當K
=5 時,均方誤差達到最小值 0.334 7,輪廓系數達到最大值0.796 8(圖4)。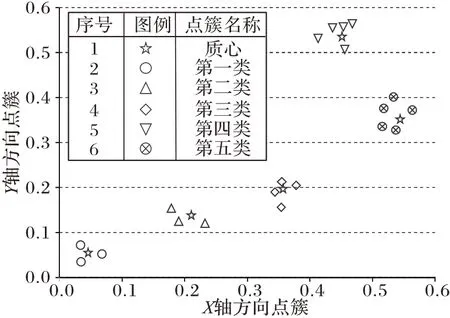
圖4 K-Means聚類結果Fig.4 K-Means clustering result
綜上所述,結合文本聚類技術和電子商務點評系統的相關研究和一級分類因素得到二級分類因素,其中:學習分類下包括教學、做題、問題、搜題;影視分類下包括視頻、音質、娛樂;交互分類下包括語音、對話、聊天、回答、陪伴;用戶體驗分類下包括顏色、手感、尺寸、外形;價格分類下包括便宜、性價比。共計一類分類因素5 個,二類分級因素18 個。
2 情感分析模型構建
構建情感分析模型是情感分析里的核心任務。本文基于傳統方法和深度學習模型相結合的思想提出了如下方法進行情感分類:將Python 的文本數據庫SnowNLP、傳統情感詞典和Bi-LSTM 共同作為情感評分模型的參考維度,通過合理設置各部分參數比重最終得到用戶的整體情感得分和各種影響因素的個人得分,并標準化為概率值作為預測結果。通過預測結果和真實值的比較,可以反映模型預測的精準度。
2.1 情感分類模型設計
在計算每個評論的情感評分時,首先要完成文本分類。目前常用的情感分類方法有機器學習中的分類算法(如支持向量機和樸素貝葉斯)和深度學習中的分類算法。
機器學習的方法主要用有監督的(需要人工標注類別)機器學習方法來對文本進行分類。循環神經網絡(Recurrent Neural Network,RNN)是一種基于時序邏輯的神經網絡結構,因此適合處理諸如天氣預測、人類自然語言語義預測等關注前后事件發生的順序及其聯系的任務。RNN 的基本結構如圖5 所示。
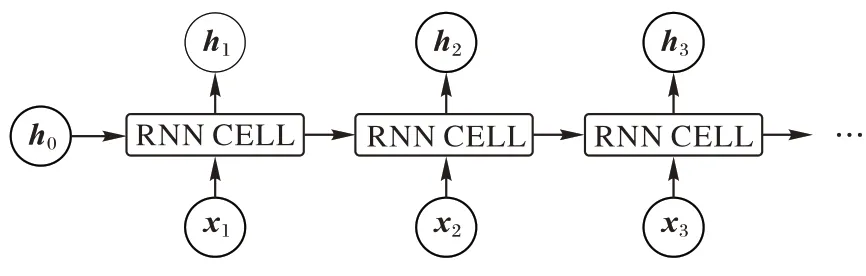
圖5 RNN結構Fig.5 Structure of RNN
如圖5 所示,拆分的RNN 結構由初始狀態h
、輸入時間序列x
和輸出時間序列h
組成,對于每一個RNN 的單元細胞都具有相同的隱層結構,根據任務需求可以增減每個細胞內隱層的層數。每一輪生成的更新狀態h
在輸出的同時還參與到下一組的運算當中,和輸入序列x
共同作為輸入參數進入細胞內的隱層迭代運算。RNN 雖然可以一定程度上處理句內前后文之間的聯系,但是在反向傳播訓練時,如果維度過大、參數過度會出現梯度彌散的問題。LSTM 是RNN 的一種改進版本,主要用來解決RNN 梯度消失和梯度爆炸的問題。Bi-LSTM 是前向LSTM 和反向LSTM 的組合。
如圖6 所示,LSTM 的一個環節中包括t
時刻的輸入數據x
、細胞狀態C
、隱層狀態h
、遺忘門f
、記憶門i
、輸出門o
。
圖6 LSTM結構Fig.6 Structure of LSTM
LSTM 的具體計算流程如下:傳遞遺忘細胞狀態下的部分信息,并記住新的信息,在隨后的時刻計算有用數據時使用這些信息。無效信息被丟棄的同時,輸出每個時間步的隱藏層狀態h
,其中忘記步驟、記憶步驟和輸出步驟被遺忘門f
、記憶門i
和輸出門o
以及前一時刻的隱層狀態h
和當前輸入間的x
共同控制計算。在一些分析情況下,預測可能需要由前一個輸入和后一個輸入來確定,后者將更準確;因此,雙向RNN 被提出,其網絡結構主要包括四個層次:詞向量層、前向傳播層、反向傳播層和連接層。在分析時,首先將句子分詞,然后經過詞映射層將單詞轉化為詞向量并傳入前向LSTM 層,而前向層和反向層與輸出層相連。前向層從時間1 到時間t
進行正向計算,每次得到并保存隱含層的輸出。反向層沿時間t
到時間1 進行反向計算,獲取并保存反向隱含層每時每刻的輸出。最后,將每一時刻前向層和后向層對應時刻的輸出結果相結合,得到每一時刻的最終輸出。就文本分類任務來說,學術界普遍認為改進的LSTM 或Bi-LSTM 相較于早期版本的RNN 有著更好的分類效果;然而,即便使用標準的Bi-LSTM,因為模型深度有限,所以在處理一下語義關系比較復雜、前后文關系比較強的文本時分類的精準度仍然有待提高。
近年來,隨著諸如VGG(Visual Geometry Group)、InceptionNet和ResNet等層數很多的神經網絡架構被提出,增加神經網絡的深度來提高學習模型的性能的猜想得以證實。由于能夠學習到更好的特征表示,對于語言建模任務,應用深層架構從理論上來說具有可行性。其中,一種較為流行的做法是使用堆疊的LSTM 模型,但是相較于DAN(Deep Averaging Network)這一類層數較淺的模型,堆疊模型很容易遇到“退化”問題。
此時,無論是增加隱層層數還是疊加LSTM 數量都無法有效地提高預測的精確度,模型也趨于飽和。由此可見,模型的優化難度和堆疊的層數是正相關的。基于此,本文將構造一種基于殘差網絡和堆疊的LSTM 結合的神經網絡預測給定文本的情感類別,將每個LSTM 層中引入殘差連接塊解決退化問題。
如圖7 所示,n
個模型層的隱層狀態h
和每一輪的輸入向量x
相加,通過殘差連接進行學習,隱層狀態h
的更新公式如式(2)所示: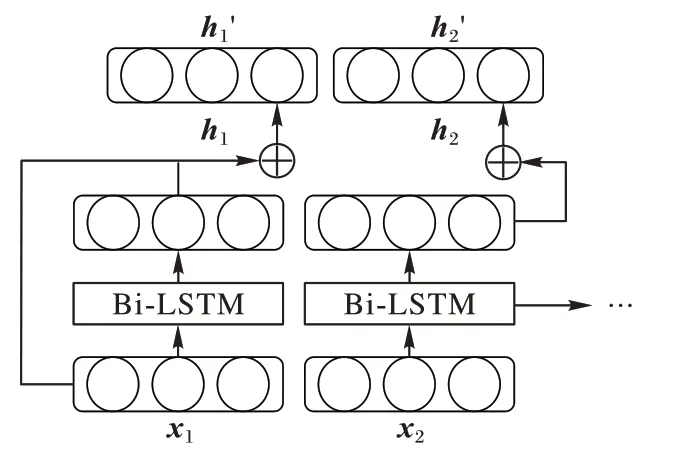
圖7 殘差連接的Bi-LSTM單元Fig.7 Bi-LSTM units with residual connection
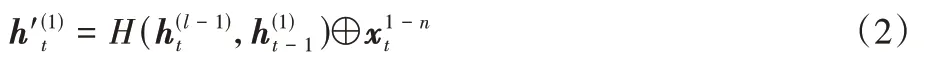
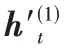
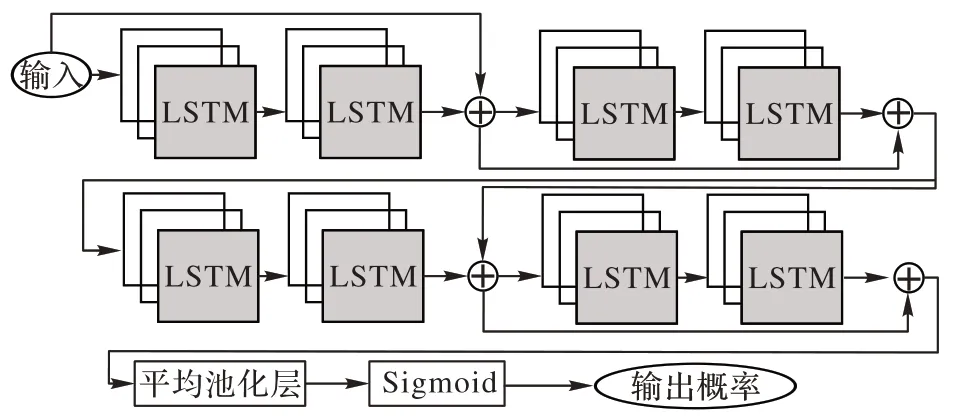
圖8 堆疊殘差的Bi-LSTMFig.8 Stacked residual Bi-LSTM
如圖8 所示,該模型為一個8 層的堆疊殘差Bi-LSTM 結構,每兩個堆疊層后連接一個殘差層。對于每個殘差連接的矩陣加法無需學習參數,從而避免模型復雜度的增加。同時由于LSTM 是以結果偏置的模型,因此句尾單詞相較于句首有更高的影響程度,然而這一點對于文本預測而言是不利因素,因為自然語言中,關鍵詞的出現位置不具有固定規律。基于此,該模型使用平均池化層學習文本向量,從而使得每個單詞對于預測結果具有同等程度的貢獻。最后,使用Sigmoid 激活函數輸出二分類的預測結果。
2.2 情感分類
市場上一些收費的自然語言處理(Natural Language Processing,NLP)功能集成平臺雖然具備一定的泛化能力,也能處理多個互聯網領域(餐飲、汽車)的情感極性分析工作,但是對于短文本的教育類產品評價的分類效果較差,本文將結合深度學習和機器學習類庫、情感詞典的方法構建基于情感詞典和堆疊殘差的Bi-LSTM 的情感分析模型。具體的構造思想是:根據預處理后的數據建設程度副詞詞典、否定詞詞典、機器人產品用戶評論詞典,SnowNLP 情感詞典計算基本情緒分值,結合Bi-LSTM 模型,將Softmax 激活函數輸出極性是0(消極)或1(積極)的概率,將概率轉化為極性對應的得分,與基本得分共同計算得到最終的情感得分;然后再通過標準化算法,輸出為0~1 的數值,當數值大于0.5 時認為是積極情感,當數值小于0.5 時認為是消極情感,從而完成情感分類工作。
2.2.1 詞典結構
1)程度副詞詞典。本文根據知網程度水平詞構建程度副詞詞匯庫,并根據極值(權重2)、高值(權重1.75)、中值(權重1.5)和低值(權重1.25)分別賦予權重,計算情感得分,以上權重皆基于程度副詞詞典構造一般經驗賦值。
2)否定詞詞典。本文收集了80 個負面詞匯作為負詞詞典的組成部分,權重設為-1。當否定詞在句子中出現的次數為奇數時,表示否定意義;當一個否定詞在句子中出現的次數是偶數時,表示肯定意義。
3)教育機器人情感詞典。本文構造的評論情感詞典充分考慮了當代電商平臺用戶在各種電子商務平臺和論壇上的公眾言論和用戶習慣,并結合了互聯網上的各種流行詞匯,這使得情感詞典具有及時性和全面性。本文在臺灣大學NTUSD 簡體中文情感詞典的基礎上根據5 個分類標準和332個對應于學習、影視、交互、用戶體驗和價格方面的常見情感詞,通過刪除多余情感詞、增加適用情感詞構造了教育機器人評論情感詞典(見表1)。
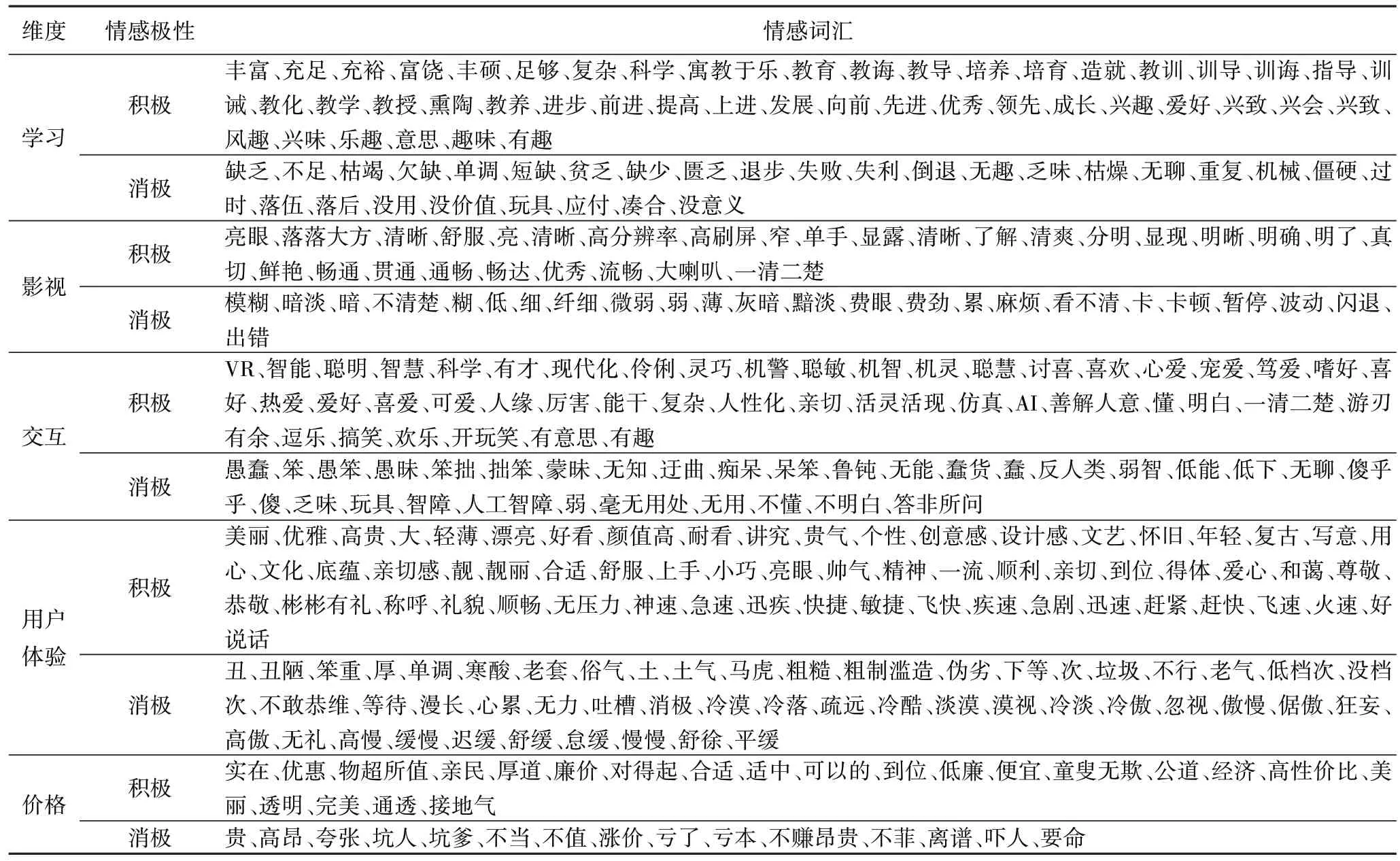
表1 教育機器人補充情感詞典Tab 1 Educational robot supplementary sentiment lexicon
2.2.2 情感得分計算
基于情感辭典的情感得分計算:當每次要分析的單詞與機器人評論詞典中的積極情感單詞匹配時得分+1 分;當與機器人評論情感詞典中的負面情感詞匯匹配時-1 分。從語句的第一個單詞開始遍歷,如果單詞前面存在一個程度副詞,則用程度副詞權重乘以單詞分數。如果在程度副詞之前仍然有否定詞,則將否定詞的權重、程度副詞的權重和詞的分數相乘。遍歷整個評論直到沒有情感詞出現,累加每個部分的分數得到機器人評論情感詞典計算的總分。基于深度學習的情感得分計算:Bi-LSTM 是一種深度學習模型,用于預測文本極性值的概率。
模型中隱層的Softmax 激活函數可以輸出判別結果的概率p
,1-p
得到相反結果的概率值。Bi-LSTM 可以通過學習大量的文本特征來反映句子中單詞和單詞之間的關系,因此,通過判斷一個句子是積極的還是消極的概率,可以從側面反映出句意是積極(消極)的程度,這種抽象意義上的度量可以量化為情感得分。在本文中,從激活函數輸出的概率值被轉換為情感得分:以判斷一處句意為積極的語意為例,當輸出概率在[0.8,1]時,情感得分+2 分;當輸出概率在[0.5,0.8)時,情感得分+1 分;當輸出概率在[0.2,0.5)時,情感得分-1分;當輸出概率在[0,0.2)時,情感得分-2 分。在計算出情感辭典和Bi-LSTM 對文本的得分計算之后,再使用SnowNLP 進行得分計算。SnowNLP 情感得分的計算方法是將句子的情感程度轉化為[0,1]的情感得分。在得到基于教育機器人評論情感詞典、SnowNLP 和Bi-LSTM 的情感得分后,可以計算總分并將其標準化到[0,1]。以評論“東西然貴,但非常智能,物流神速,視頻無比清晰”為例,從機器人評論情感詞匯中可以看出,“貴”是負面情感詞,“智能”“神速”“清晰”是正面情感詞,“非常”“無比”是極端程度副詞,基于機器人評論情感詞匯的得到分數S1(+4);分析Bi-LSTM輸出的結果為0.73,屬于范圍(0.5,0.8],因此得分S2(+1);基于SnowNLP 計算的整句情感得分為S3(+0.89)。最后,將總分標準化為[0,1]上的概率值,完成一次情感評分,并根據評分判定評論的情感極性(得分大于或等于0.5 判定為積極,得分小于0.5 判定為消極)。
根據圖9 示例語句,經過本文構造的補充機器人情感詞典后根據分值權重計算出了初步得分4 分,經過堆疊殘差的Bi-LSTM 模型后獲得情感得分1 分,經過SnowNLP 后獲得0.89 分的情感加分,最終得分5.89 分,經過標準化后得到0.83 分,根據判斷規則該語句情感傾向為積極。
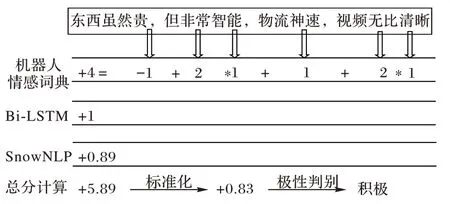
圖9 情感得分計算Fig.9 Sentiment score calculation
在這個過程中,三個部分的情感得分計算是可以同步進行的,因為它們彼此并不需要其他部分的得分或者結算數據作為自身計算時的參數,所以并不強調先后順序上的差別。
在本文實驗環境下,對于該情感得分計算模型而言,在情感傾向極為強烈時情感詞典的得分占比較大,而在情感傾向不太強烈時深度學習模型的得分占比較大。而總分計算和標準化的過程必須置于情感得分計算模型中的三個計算步驟之后。
3 實驗與結果分析
3.1 實驗數據集
在實驗階段,本文使用經過清洗的數據集中48 000 條評論作為訓練集在數據預處理后進行模型訓練,訓練的模型包括兩種分類模式(機器學習和深度學習),其中機器學習分類模式分為兩種特征提取方法(基于單詞的特征提取方法和基于雙詞的特征提取方法),共7 種分類算法;深度學習包括6種既有分類算法以及本文構建的基于堆疊殘差的Bi-LSTM和情感詞典的分類模型。在訓練集結束訓練后,對于訓練好的分類模型再使用帶有積極的標簽和消極的標簽的12 000 條評論作為測試集,用以測試不同的分類算法在各個二級分類下的準確率,最后,將各個二級分類目錄下的分類準確率累加求均值,得到一類分類目錄下的分類準確率,選擇分類準確率最高的方案。
在將該套方案存為備選之后,后續過程中如果更新、拓展數據集(該模型分類的準確率依賴于數據集的狀態,過時的數據集學習出的分類模型將損失很多準確率),會產生新的分類模型,分類準確率可能也會因此而改變,因此需要適時更新分類方案。
其中,在與其他機器學習和深度學習模型進行分類性能對比時,本文選取了機器學機器學習模型算法包括伯努利樸素貝葉斯(BernouliNB)分類器、多項式樸素貝葉斯(MultinomialNB)分類器、線性回歸(Linear Regression,LR)、支持向量機(Support Vector Machine,SVM)、線性支持向量機(Linear SVM,LinearSVM)、核支持向量機(Nuclear SVM,NuSVM)。測試的分類維度分為500、1 000、1 500、2 000、2 500 和3 000;深度學習模型包括LSTM、深層循環神經網絡(Deep Recurrent Neural Network,DRNN),雙向循環神經網絡(Bi-directional Recurrent Neural Network,BiRNN),RNN,BERT(Bidirectional Encoder Representation from Transformers),Elmo(Embeddings from Language models)。以上模型均為機器學習、深度學習領域進行NLP 尤其文本分類任務較為常用的模型。除此以上模型外,也可以使用其他的分類模型進行對比。
3.2 實驗準備
根據上述構建的影響因素規則和情緒評分系統,得到教育機器人每條評論的情感得分,再結合各影響因素的整體情感評分和情感極性,計算各二級、一級分類下評論的情感得分均值,判定不同二級、一級分類整體的情感極性。如表2所示,在一級因素中,“交互”的情感極性最傾向于負面,而對應的二級因素中大部分的品牌在“語音”“對話”“聊天”中得到的分數較低,低于0.5 的得分也對應了判定為“消極”的預測結果,而“影視”對應的評論中積極情感占據主導。從表2中可以得到以下推論:智能教育機器人在當前階段更多地承擔起一個影音、娛樂、學習、陪伴性質的工具,而在交互方面很難達到較高層次的“智能”。因此,一些AI 機器人和傳統的MP4 等影音播放器的邊界較為模糊,這一方面受限于現有人工智能技術的應用能力,一方面也和產品的價位有關。然而,雖然多數產品在“交互”分類下的“語音”“對話”“聊天”等二級分類的表現不佳,但是普遍在“陪伴”分類中獲得了較高的分數,這表明對于幼兒、兒童來說,即便是提供了傳統的影音娛樂功能的機器仍然能一定程度上滿足用戶的心理需求。
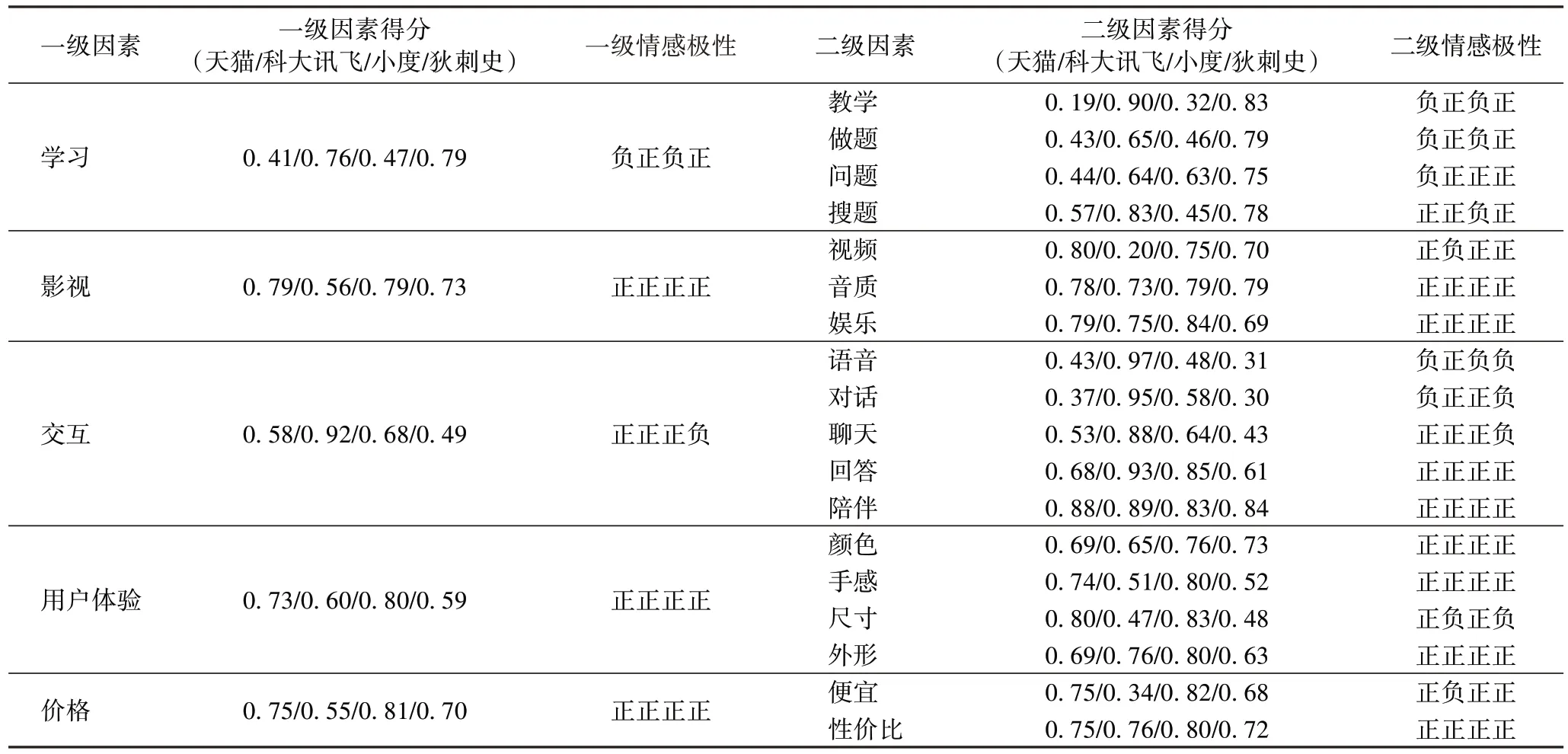
表2 各個維度情感得分及極性判別Tab 2 Sentiment score of each dimension and polarity discrimination
在搭配了一些網絡教育資源和較為成熟的教育系統后,很多AI 機器人也能滿足低年級學生的學習需求。對于一些價格較高、搭配了較強的人工智能技術的早教機器人,在“性價比”一項上得分較低,這從側面反映了許多用戶在對于該類高端產品時仍然保持觀望態度。在獲得了構建的模型的分類情況后,可以將預測結果與人工標注的真實值從不同維度做誤差分析,本文用精確率、召回率、準確率和F1 值來綜合衡量不同算法的性能表現。
3.3 結果與分析
對比分析環節將詳細對比本文模型和其他模型在訓練集上的準確表現。為對應1.2.2 節中的二級目錄,分為一級因素和二級因素分別測試每個目錄下的分類準確率情況。訓練集情況和訓練后基于本文構建的復合文本分析模型在驗證集上的準確率結果以及所屬關鍵詞的評論數目情況如表3 所示。
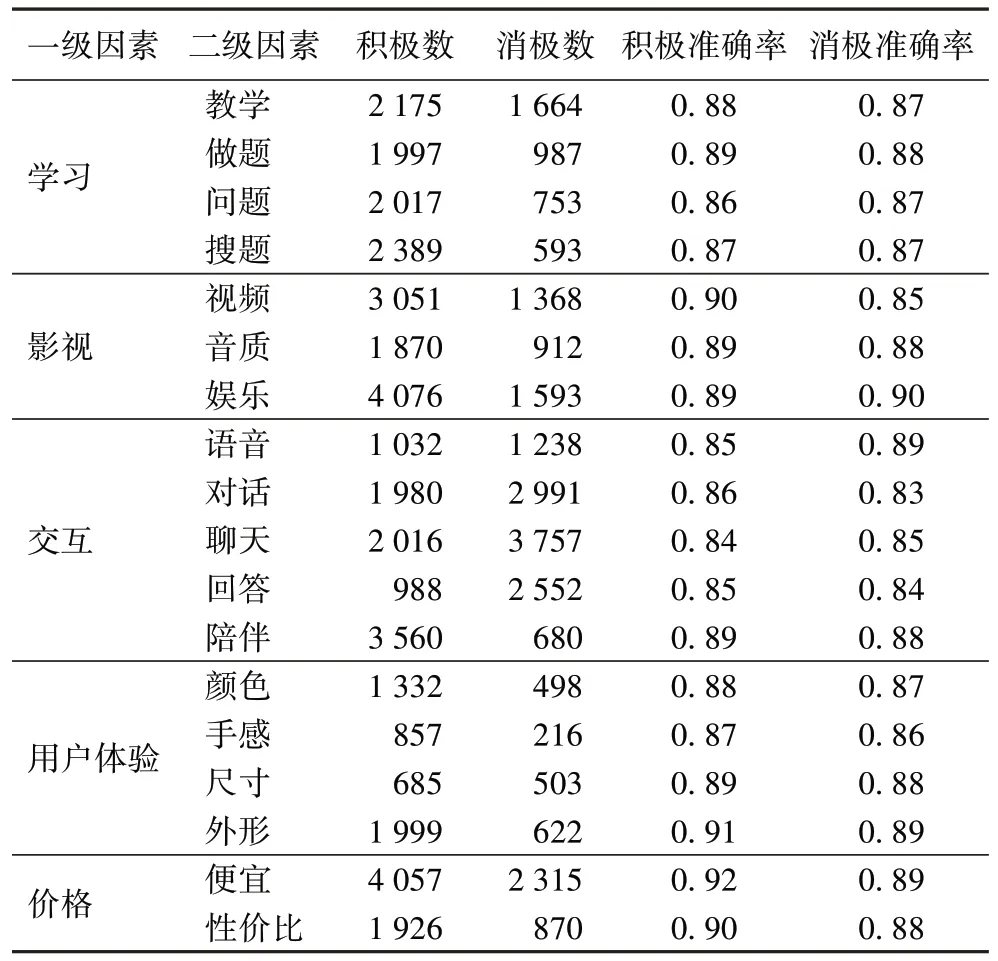
表3 基于情感詞典和堆疊殘差的Bi-LSTM的模型準確率Tab 3 Accuracy of sentiment lexicon and stack residual Bi-LSTM based model
從表3 中簡單計算可知:該模型對于積極感情的整體預測準確率約為0.883,對消極情感的整體預測準確率約為0.874,整體準確率約為0.879。對于積極情感的預測準確率高于消極情感,其中:在“價格”方面預測的整體準確率最高,約0.910;在“交互”方面預測的整體準確率最低,約0.858。回顧數據集,這和用戶在交互領域評論更趨向于使用反語、諷刺語、俗語、比喻等較難為機器理解的修辭手法和文法、語法有關,而在價格領域的評論較為直白,基本情感詞典都能做到覆蓋。
接下來使用機器學習的7 種分類算法分兩種特征提取方法計算多個維度下的準確率,結果如圖10 所示。對比以所有詞為特征提取方法的機器學習領域的分類算法和以所有雙詞搭配為特征選取方法結果的機器學習領域的分類算法可以發現,雖然準確率隨著分類維度的上升有所提高,但是普遍處于0.8 的分類準確率之下,其中:BernoulliNB 算法在所有維度始終低于0.8;NuSVM 算法的表現最好,整體的情感分類準確率維持在0.836 和0.840。
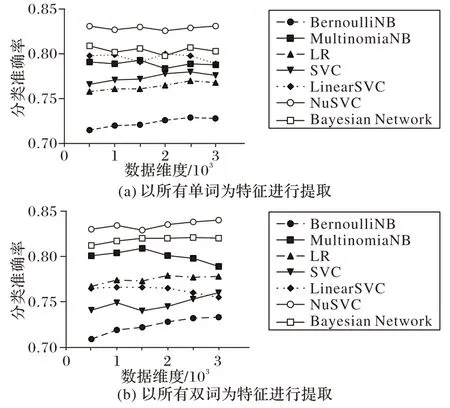
圖10 2種特征方法下提取的分類精度Fig.10 Classification accuracy extracted by two feature methods
接下來,使用幾類深度學習模型在訓練集上進行訓練,并通過驗證集計算分類算法的精確率、召回率、準確率和F1分數。為方便對比,將本文模型和其他深度學習模型并列。
觀察圖11,本文模型在四項標準上均獲得最高值,其次BERT 在各項分類指標上的數據表現最好,準確率達到0.859,LSTM 的整體準確率約為0.834。說明基于情感詞典和堆疊殘差的Bi-LSTM 模型在預測結果為積極情感的樣本空間中的成功率較高;而RNN 的整體表現較差,這可能是因為RNN 存在梯度消失和梯度爆炸問題。雖然基于本文模型取得最高的準確率,但是在“交互”領域的分析效果仍不夠理想。經分析推測原因如下:1)在該領域下存在較多的學術專業詞匯,它們應該比普通詞匯享有更高的情感權重;2)一些專業術語詞匯由較長的英文單詞或者英文和中文單詞的組合構成,這些詞組可能被正則表達式和停詞表過濾掉了詞組中的一部分,導致分詞不完整、語義破碎的情況,從而影響了最終的準確率。縱觀所有分類算法,對于正標簽的分類效果普遍稍高于負標簽、精確率普遍稍高于召回率,這說明負面情感的評論對情感詞典的覆蓋率以及模型的分析能力有著更高的要求,這可能是因為負面評論中有著更多的諷刺語、反語和借助特殊形式的表達。
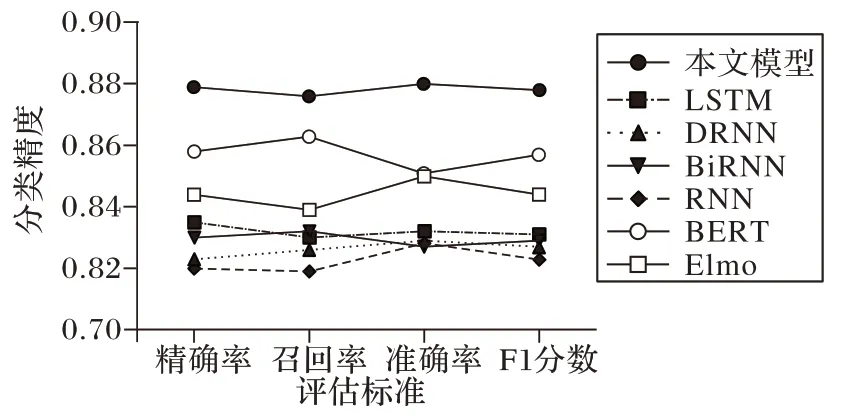
圖11 深度學習模型分類結果Fig.11 Classification results of deep learning models
本文模型相較于其他機器學習、深度學習模型分類性能評估更好的原因主要在于克服了分類問題在兩方面的不足:1)對特定領域的專業詞匯的解讀能力的不足。通過定性分析,結合二級分類目錄的設置,補充了AI 教育機器人領域情感詞匯,從而提高了對于特定詞匯的分類準確率。2)堆疊LSTM 時模型精度上限的不足。通過在堆疊的LSTM 中加入殘差連接,有效避免了高層數模型存在的網絡“退化”問題,從而提高了通過增加模型深度從而實現性能提升的上限。
4 結語
本文雖然是針對于“AI 教育機器人”的評論建立的分析模型,但整套分析邏輯對于其他各類型評論類型的短文本情感分類工作都具有一定的重構意義,通過上文分析可以論證:將針對某個領域而編纂的情感詞典和深度學習模型相結合,可以提高分析模型的準確率;而針對某個領域的情感詞典可以在一套標準化的情感詞典上根據該領域的特定情況而調整詞典的范圍,添加對于分析工作有價值的詞匯,減少對分析工作有誤導的詞匯。本文實驗的限制主要在于:1)數據集僅限于國內電子商務平臺,對海外用戶的分析仍然稀缺;2)Bi-LSTM 模型在處理帶有多個負面單詞的句子時表現不佳。增加注意機制將使模型的擬合度更高。此外,隨著時代的發展,情感詞典需要不斷更新和修改,特別是對于像中文這類結構較為復雜的語言,建立詞典的工作量相對龐大。
