
結合BERT和特征投影網(wǎng)絡的新聞主題文本分類方法
2022-05-07 07:07:24張海豐郝儒松溫超東
計算機應用 2022年4期
張海豐,曾 誠,2,3*,潘 列,郝儒松,溫超東,何 鵬,2,3
(1.湖北大學計算機與信息工程學院,武漢 430062;2.湖北省軟件工程工程技術研究中心,武漢 430062;3.智慧政務與人工智能應用湖北省工程研究中心,武漢 430062)
0 引言
新聞文本分類包括主題分類和內(nèi)容分類,而新聞主題文本分類任務中,新聞主題文本通常是由一些高度概括新聞內(nèi)容的詞匯組成,由于用詞缺乏規(guī)范、語義模糊,使得現(xiàn)有的文本分類方法表現(xiàn)不佳。新聞主題文本長度短,在有限長度的新聞主題文本中提取其完整語義特征進行分類挑戰(zhàn)極大。
新聞主題分類屬于自然語言處理(Natural Language Processing,NLP)短文本分類任務,文本分類任務首先需要對相關文本進行文本處理,并進行文本向量化表示。隨著深度學習方法的興起,目前普遍使用的詞嵌入方式有兩種,一種是靜態(tài)的語言模型Word2Vec、GloVe;另一種是預訓練模型BERT(Bidirectional Encoder Representations from Transformers)、XLNet 等動態(tài)語言模型。Word2Vec 方法可以較好地體現(xiàn)上下文信息,被大量應用于自然語言任務中。而預訓練模型BERT 的出現(xiàn),解決了靜態(tài)詞向量無法解決的一詞多義問題,在多個NLP 任務中表現(xiàn)優(yōu)異。
本文結合BERT 和特征投影網(wǎng)絡(Feature Projection network,F(xiàn)Pnet),提出了新聞主題分類方法BERT-FPnet,通過梯度反轉(zhuǎn)網(wǎng)絡提取共性特征,以特征投影方式,將BERT 模型提取特征進行特征投影提純,提取強分類特征,提升新聞主題文本分類效果。
1 相關工作
新聞主題分類是指將新聞主題通過NLP 技術對新聞文本進行特征處理、模型訓練、輸出分類。新聞主題分類是當前NLP 文本分類的重要研究方向之一,互聯(lián)網(wǎng)發(fā)展至今,每天產(chǎn)生海量新聞,各種新聞類別混雜其中,如何更好地對其分類有著重要研究意義。
1.1 文本向量化
文本向量化表示就是用數(shù)值向量來表示文本的語義,對文本進行向量化,構建合適的文本表示模型,讓機器理解文本,是文本分類的核心問題之一。傳統(tǒng)的機器學習中樸素貝葉斯模型不需要將文本向量化表示,它記錄詞語的條件概率值,對輸入各詞語的條件概率值進行計算即可得到預測數(shù)值。但是目前絕大多數(shù)線性分類模型還是需要對文本進行向量化表示,必須輸入一個數(shù)值向量才能計算得到預測數(shù)值。傳統(tǒng)的特征表示中,使用詞袋表示文本,這種方式容易導致特征出現(xiàn)高維、稀疏問題,不僅影響文本分析的效率和性能,可解釋性也比較差。隨著深度學習的發(fā)展,一些優(yōu)秀的神經(jīng)網(wǎng)絡語言模型被提出,極大地推動了NLP 領域的發(fā)展。Mikolov 等提出一種神經(jīng)網(wǎng)絡概率語言模型Word2Vec,它包括連續(xù)詞袋(Continuous Bag-Of-Words,CBOW)和Skip-Gram 兩種模型訓練方法,讓詞向量很好地表達上下文信息,并提出了負采樣的方式來減少Softmax 的計算時間,但它只考慮了文本的局部信息,未有效利用整體信息。針對此問題,Pennington 等提出全局詞向量(Global Vectors,GloVe)模型,同時考慮了文本的局部信息與整體信息。
Word2Vec、GloVe 模型等訓練詞向量的方法,得到的詞向量文本特征表示為下游文本分類任務性能帶來了有效提升,但是它們的本質(zhì)是一種靜態(tài)的預訓練技術,在不同的上下文中,同一詞語具有相同的詞向量,這顯然是不合常理的,它無法解決自然語言中經(jīng)常出現(xiàn)的一詞多義問題,也導致下游分類任務的性能受到限制。隨著預訓練技術的發(fā)展,GPT(Generative Pre-Training)、BERT、XLNet 等一些優(yōu)秀的預訓練模型相繼被提出,其中最具代表的BERT預訓練模型,它的動態(tài)字向量可以更好地表示文本特征,有效地解決一詞多義問題,并在多個NLP 任務上效果顯著,尤其適合新聞主題短文本分類任務。因此本文利用BERT 模型在短文本處理上的優(yōu)勢,在其基礎上結合FPnet 進行改進。
1.2 文本分類方法
現(xiàn)有的深度學習文本分類方法主要包括卷積神經(jīng)網(wǎng)絡(Convolutional Neural Network,CNN)、循環(huán)神經(jīng)網(wǎng)絡(Recurrent Neural Network,RNN)、注意力機制以及根據(jù)這些模型的優(yōu)缺點互相融合的組合模型。Kim提出一種文本卷積神經(jīng)網(wǎng)絡TextCNN,利用多窗口一維CNN 在Word2Vec 詞向量上進行特征提取分類,效果卓越;Zhang 等提出了一種字符級的卷積神經(jīng)網(wǎng)絡(character-level CNN,char-CNN)分類模型,采用字符級向量輸入的6 層卷積網(wǎng)絡,并將多卷積層網(wǎng)絡連接到一個雙向循環(huán)層在短文本分類上進行文本分類。在RNN 的應用上,Mikolov 等利用RNN進行文本分類,取得了不錯的效果。但CNN 不能直接獲得數(shù)據(jù)中的長期依賴關系,RNN 在處理文本時可能會出現(xiàn)梯度爆炸和消失問題。針對這些問題,一些組合模型相繼被提出,Lai等針對可能導致上下文語義缺失的問題,使用RNN 提取上下文語義信息,并融合原有的特征,通過結合單層池化網(wǎng)絡提出了一個循環(huán)卷積神經(jīng)網(wǎng)絡模型TextRCNN;Xiao 等提出了一個char-CRNN(character-level Convolutional RNN)模型,用另一種方式將CNN 與雙向長短期記憶(Bidirectional Long Short-Term Memory,BiLSTM)結合,先進行卷積操作,然后再進行RNN 特征提取。
注意力機制的提出,讓神經(jīng)網(wǎng)絡模型對訓練文本中的不同語句有不同的關注度,實現(xiàn)了更加合理的自然語言建模,越來越多的神經(jīng)網(wǎng)絡中開始加入注意力機制。Zhou等提出的TextRNN-Attention 模型結合雙向RNN 與注意力機制,在特定任務上取得了不錯的效果。而BERT 模型所基于的Transformer 架構更是一種完全基于注意力機制的模型。
在新聞主題分類任務上過去一般使用TextCNN 在Word2Vec 訓練的字向量上進行特征提取,分類效果比詞粒度效果更好,但詞向量也有其價值。楊春霞等提出了一種字粒度和詞粒度融合的新聞主題分類方法,將字粒度的Word2Vec 向量和詞粒度的Word2Vec 向量進行融合。付靜等將詞向量和位置向量作為BERT 的輸入,通過多頭自注意力機制獲取長距離依賴關系,提取全局語義特征;然后利用Word2Vec 模型融合LDA(Linear Discriminant Analysis)主題模型擴展短文本的特征表示方法,解決短文本數(shù)據(jù)稀疏和主題信息匱乏的問題。
BERT 模型性能強大,許多優(yōu)秀的模型都是在BERT 模型基礎上進行改進。Lan 等提出一種基于BERT 的輕量級預訓練語言模型ALBERT(A Lite BERT),通過嵌入層參數(shù)因式分解減少BERT 參數(shù)量,擴展了BERT 模型的可用性。溫超東等結合ALBERT 與門控循環(huán)單元(Gated Recurrent Unit,GRU)模型在專利文本分類任務上取得了不錯的效果,但模型分類精度相較于BERT 會有一定程度的下降。Chen等提出了一種半監(jiān)督文本分類方法MixText,使用一種全新文本增強方式TMix,在BERT 編碼層進行隱空間插值,生成全新樣本,相較于直接在輸入層進行Mixup,TMix 的數(shù)據(jù)增強的空間范圍更加廣闊。Meng 等提出一種不需要任何標注數(shù)據(jù),只利用標簽進行文本分類的方法LOTClass,使用BERT 模型訓練標簽的類別詞匯,利用BERT 的MLM(Mask Language Model)進行標簽名稱替換、類別預測,然后通過自訓練加強分類效果,達到了接近有監(jiān)督學習的分類效果。
本文主要研究有監(jiān)督方法對BERT 模型進行改進提升。Qin 等在2020 年首次提出一種提升文本分類的特征投影網(wǎng)絡(FPnet),在多個文本分類模型上加入FPnet,有效提升了分類模型的文本分類效果。本文在其基礎上以雙BERT模型融合FPnet,提取域共性特征和特性特征,結合特征投影方法,以端到端的方式采用兩種融合方式進行融合。
2 相關技術
2.1 預訓練語言模型BERT
BERT 模型采用雙向Transformer 編碼器獲取文本的特征表示,模型結構如圖1 所示,將訓練文本以字符級別輸入到多層雙向Transformer 編碼器中進行訓練,輸出文本字符級特征。
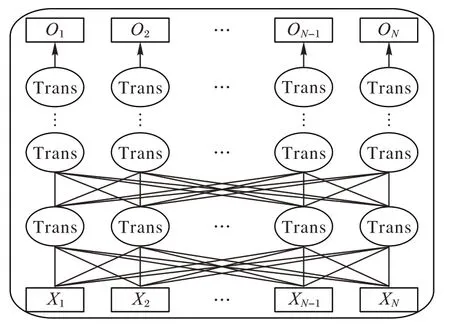
圖1 BERT模型結構Fig.1 BERT model structure
在預訓練階段,BERT 模型通過MLM 任務結合Transformer 架構注意力機制本身全局可視性,增加了BERT模型的信息獲取,且隨機掩碼使得BERT 模型不能獲得全量信息,避免過擬合。通過NSP(Next Sentence Prediction)任務讓模型更好地理解句子之間的聯(lián)系,從而使預訓練模型更好地適應下游任務。因此,BERT 模型具有強大的文本語義理解能力,在文本分類任務上效果顯著。
2.2 FPnet
FPnet 是一種強化文本分類效果的神經(jīng)網(wǎng)絡結構。主要利用梯度反轉(zhuǎn)網(wǎng)絡來實現(xiàn),使用梯度反向?qū)樱℅radient Reversal Layer,GRL)提取多個類的共性特征。Ganin等詳細介紹了GRL 的實現(xiàn)原理,并將其用于領域自適應(Domain Adaptation)中提取共性特征。它將領域自適應嵌入到學習表示的過程中,以便最終分類決策對于域的改變?nèi)阅芴崛〉讲蛔兲卣鳌Pnet 利用GRL 的這一特點來提取共性特征,并采用類似對抗學習方法通過特征投影改進表示學習。
如圖2 所示,F(xiàn)Pnet 由兩個子網(wǎng)絡組成:右邊為共性特征學習網(wǎng)絡(Common feature learning network,C-net);左邊為投影網(wǎng)絡(Projection network,P-net)。
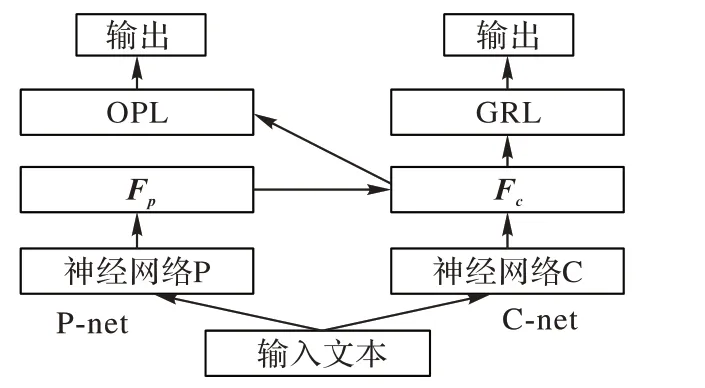
圖2 特征投影網(wǎng)絡的結構Fig.2 Structure of FPnet
FPnet 的主要重點在于使用雙網(wǎng)絡進行不同的任務,兩個神經(jīng)網(wǎng)絡所提取的特征不同,通過特征投影的方式,強化主網(wǎng)絡的分類特征,從而提升文本分類效果。FPnet 可以與現(xiàn)有的LSTM、CNN、Transformer、BERT 神經(jīng)網(wǎng)絡進行融合,在與不同的神經(jīng)網(wǎng)絡相結合時候,只需要將FPnet 結構中的神經(jīng)網(wǎng)絡P 和神經(jīng)網(wǎng)絡C 特征提取器換成LSTM、CNN、Transformer、BERT 即可。FPnet 作為一種神經(jīng)網(wǎng)絡結構并沒有固定的形式,其主要思想在于強化提純特征,從而達到強化神經(jīng)網(wǎng)絡的分類效果。在TextCNN-FPnet中使用了2 個TextCNN 網(wǎng)絡作為FPnet 的C-net 和P-net 特征提取器來提取共性特征和特性特征。OPL(Original Projection Layer)處于卷積池化層之后,在神經(jīng)網(wǎng)絡最后一層進行特征投影,從而提升了TextCNN 模型的分類性能。
C-net 模塊在正常的文本分類神經(jīng)網(wǎng)絡結構中加入GRL會使得神經(jīng)網(wǎng)絡C 所提取的特征F
為共性特征。由于C-net輸出通過損失函數(shù)計算,在反向傳播過程中受到GRL 反轉(zhuǎn)作用,使得整個網(wǎng)絡損失函數(shù)loss 值逐漸增大,無法正確分類,神經(jīng)網(wǎng)絡C 所提取的特征F
在神經(jīng)網(wǎng)絡參數(shù)更新過程中逐漸丟棄類別信息,只帶有共性信息,在向量空間中表現(xiàn)為沒有正確的類別指向。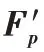
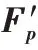
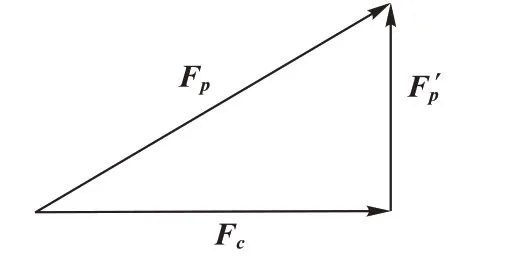
圖3 特征投影Fig.3 Feature projection
FPnet 使用雙網(wǎng)絡合作進行文本分類任務,神經(jīng)網(wǎng)絡Pnet 和神經(jīng)網(wǎng)絡C-net 結構相同但參數(shù)并不共享,C-net 中加入梯度反轉(zhuǎn)層GRL,P-net 中加入特征投影層OPL,雙網(wǎng)絡使用相同的交叉熵損失函數(shù),C-net 中的梯度反轉(zhuǎn)使得網(wǎng)絡提取的特征并不能正確分類,即提取到了共性特征。
在新聞主題文本分類任務難點主要包括兩個方面:1)主題文本長度過短,語義信息少,普通文本分類模型不易提取其有效分類語義信息,一些主題詞可能屬于多個類別,而另一些主題詞并不能指向任何類別,更適合使用BERT 模型作為特征提取器;2)部分新聞包含多個類別信息,例如財經(jīng)類新聞與房產(chǎn)類新聞通常不易區(qū)分,科技新聞又容易和汽車類新聞混淆。使用FPnet 后,通過計算凈化提純后的向量特征,可以將學習到的輸入新聞主題文本的信息向量投影到更具區(qū)分性的語義空間中來消除共同特征的影響。
BERT 模型與一般的文本分類模型不同,不僅可以使用分類器最終提取的特征進行特征投影融合,也可以在BERT網(wǎng)絡的隱藏層中融合FPnet 進行改進。
3 BERT-FPnet框架及其實現(xiàn)
本文BERT-FPnet 新聞主題文本分類方法主要包括兩種實現(xiàn)方式:
1)BERT-FPnet-1。使用BERT-FPnet 的MLP 層輸出進行特征投影結合,使用預訓練模型BERT 構建文本分類模型時需要在BERT 的輸出后加入MLP(MultiLayer Perceptron)層進行進一步特征提取,MLP 層使用多個全連接網(wǎng)絡。
2)BERT-FPnet-2。使用BERT-FPnet 模型中BERT 的隱藏層進行特征投影結合。
BERT-FPnet-1 的整體模型結構如圖4 所示,模型網(wǎng)絡主要分為兩部分,左邊為BERT 投影網(wǎng)絡P-net,右邊為BERT 共性特征學習網(wǎng)絡C-net。
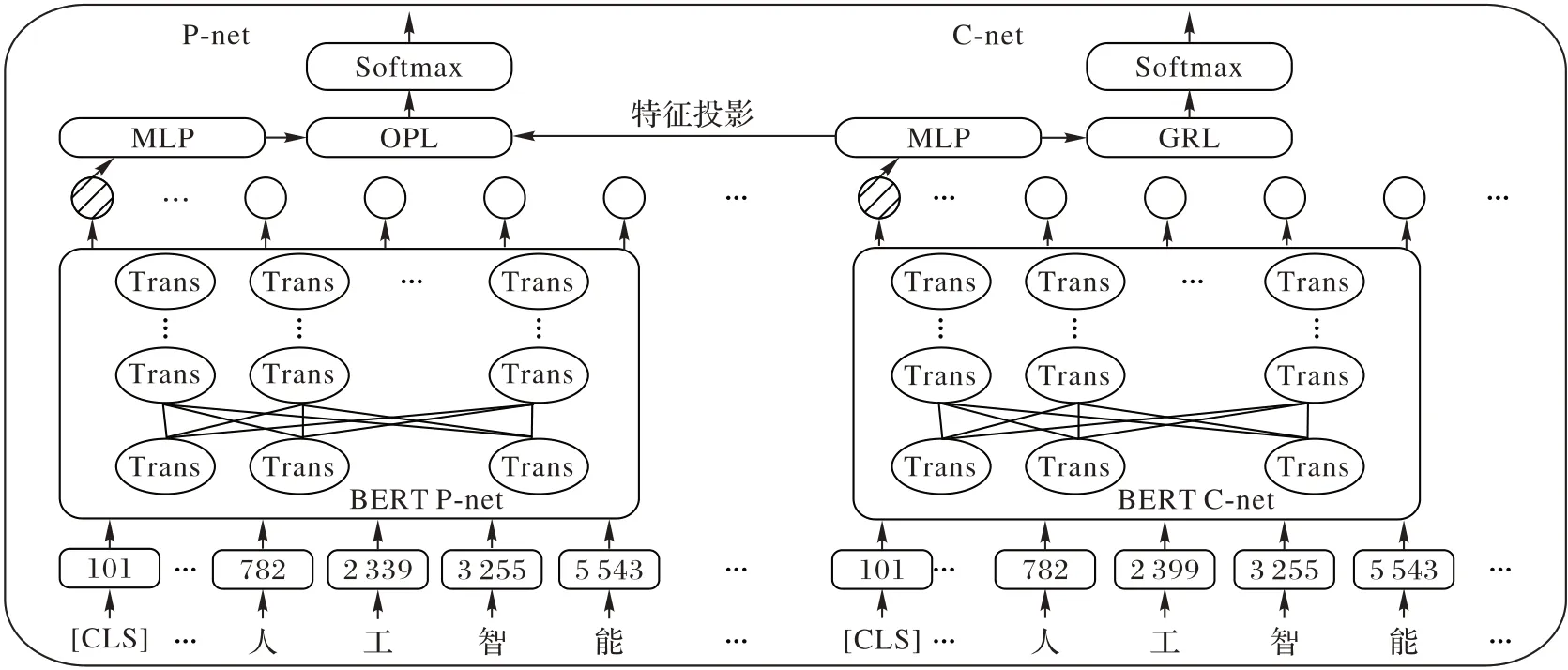
圖4 BERT-FPnet模型框架Fig.4 BERT-FPnet model framework
BERT-FPnet-1 模型工作流程如下:在新聞文本輸入到BERT 層之前需要進行特征處理,將輸入新聞文本的開頭加上[CLS]字符,然后根據(jù)BERT 字典將所有的字符轉(zhuǎn)化為字典中對應id,輸入到BERT 模型中。如式(1)~(2)所示:

E
取出,放入MLP 層中進行進一步特征提取,得到文本特征E
和E
。如式(3)~(5)所示:
在MLP 層中包含2 個全連接層和激活函數(shù)tanh,第一個全連接層維度參數(shù)設置為[768,768],輸出特征通過激活函數(shù)tanh 后進入第二個全連接層,其維度參數(shù)設置為[768,class_dim],class_dim 根據(jù)新聞文本標簽類別數(shù)來設置,如式(6)~(7)所示:

分別通過P-net 模塊和C-net 模塊的MLP 層提取原始特征和共性特征,如式(8)~(9)所示:

如前文所述,C-net 模塊主要提取共性特征,共性特征是指對分類任務不做區(qū)分的特征,它是所有類的共性特征,C-net 通過MLP 層后特征提取完畢,將特征放入GRL 中進行梯度反轉(zhuǎn)。如式(10)~(11)所示:

λ
值為GRL 梯度反轉(zhuǎn)超參數(shù)。梯度反轉(zhuǎn)層在正向傳播時對特征f
不做修改,在反向傳播時傳遞了-λ
使得整個C-net 網(wǎng)絡的損失函數(shù)LOSS 求反。特征投影方法是將特征向量投影到共性特征向量上,投影公式如式(12)所示:

f
向量中只包含公共語義信息。而第二次投影得到提純后的特征向量,只包含分類語義信息,如式(13)~(14)所示:
兩個網(wǎng)絡在結構上相同,參數(shù)上并不共享。C-net 中加入GRL 梯度反轉(zhuǎn)層后,和P-net 的輸出一樣,P-net 和C-net 的輸出都使用Softmax 歸一化激活函數(shù),如式(15)~(16)所示:

雙網(wǎng)絡使用交叉熵損失函數(shù)進行計算。C-net 通過GRL使網(wǎng)絡損失增大,所提取的特征不能正確分類,即提取到了共性特征。如式(17)~(18)所示:
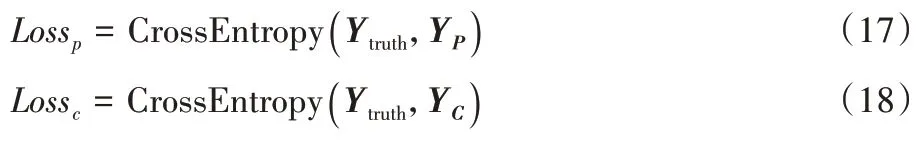
Loss
反向傳播只更新右側(cè)C-net 網(wǎng)絡參數(shù),Loss
反向傳播只更新左側(cè)P-net 網(wǎng)絡參數(shù)。C-net 中雖然同樣使用Softmax 和交叉熵損失函數(shù),但是由于在反向傳播時候C-net模塊中GRL 層進行梯度反轉(zhuǎn),因此Loss
的值會逐漸變大。進行Loss
計算和反向傳播只是為讓神經(jīng)網(wǎng)絡得到共性特征。P-net 模塊中Loss
為最終整個模型預測分類損失函數(shù)值,Y
值為整個特征投影網(wǎng)絡的最終預測輸出。BERT-FPnet-2 主要區(qū)別在于OPL 特征投影層處于BERT內(nèi)部的隱藏層之間。BERT-BASE 中文預訓練模型為12 層Transformer 結構,由于BERT 模型各個隱藏層中所提取的語義信息各不相同,從低層到高層分別提取的是短語級別、句法級別以及深度語義級別的特征語義信息,而文本特征的長期依賴需要對模型多層輸出進行建模。因此本文分別對BERT 的低、中、高隱藏層進行特征投影結合,通過實驗對比提出了BERT-FPnet模型第二種特征投影方式BERT-FPnet-2。
BERT 隱藏層特征投影是將當前隱藏層輸出進行特征投影后,輸入到下一層隱藏層中,BERT-BASE 中文預訓練模型隱藏層為12 層,如圖5 所示,以BERT 模型第6 層特征投影為例,在BERT-FPnet-2 的第6 層加入OPL 層進行特征投影提純,BERT-Cnet 網(wǎng)絡結構不變。
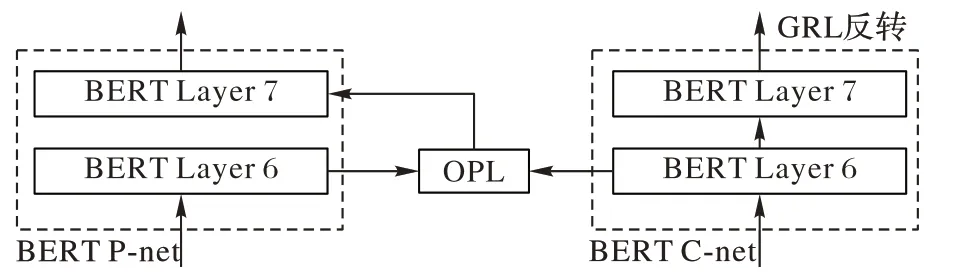
圖5 BERT-FPnet-2隱藏層特征投影Fig.5 BERT-FPnet-2 hidden layer feature projection
由于BERT模型有多個隱藏層,本文通過多種實驗選取不同的隱藏層進行特征投影實驗對比,從而得到最優(yōu)實驗效果。
4 實驗與結果分析
4.1 實驗環(huán)境與數(shù)據(jù)
本文實驗環(huán)境如表1 所示。為了評估本模型方法在新聞主題文本分類任務上的有效性,本文使用四個新聞主題數(shù)據(jù)集進行模型實驗,如表2 所示。
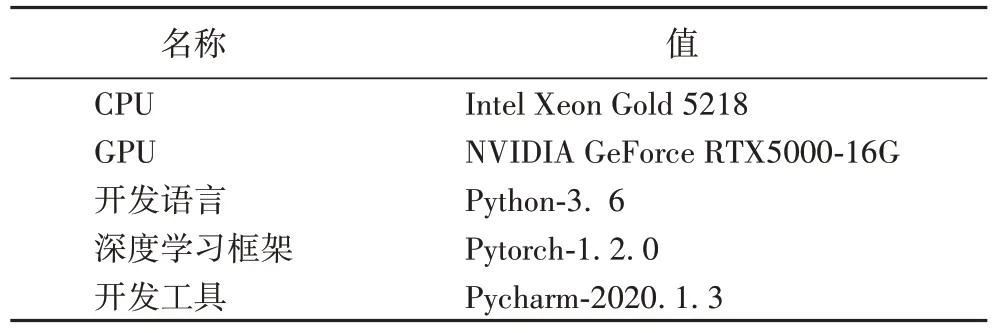
表1 實驗環(huán)境Tab 1 Experimental environment
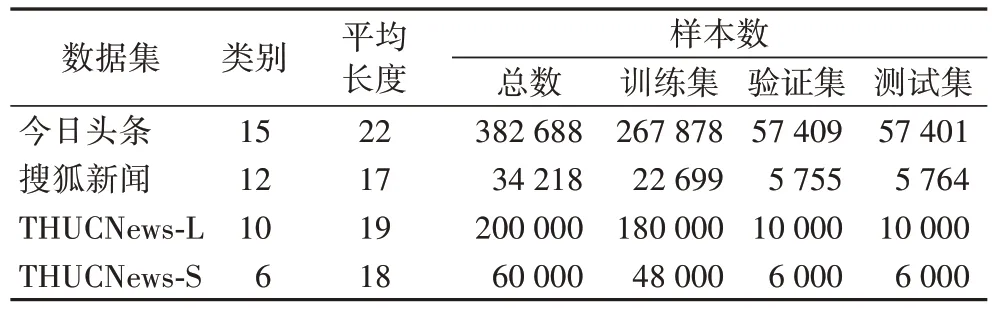
表2 數(shù)據(jù)集詳情Tab 2 Dataset details
1)今日頭條數(shù)據(jù)集:根據(jù)今日頭條客戶端收集而來,分別包括民生、文化、娛樂、體育、財經(jīng)、房產(chǎn)、汽車、教育、科技、軍事、旅游、國際、證券、農(nóng)業(yè)、電競共15 個類別。
2)搜狐新聞數(shù)據(jù)集:通過網(wǎng)絡開源搜狐新聞數(shù)據(jù)集進行數(shù)據(jù)清洗,去除數(shù)據(jù)中部分缺少標簽數(shù)據(jù),去除新聞內(nèi)容,只保留新聞主題。數(shù)據(jù)集共包含娛樂、財經(jīng)、房地產(chǎn)、旅游、科技、體育、健康、教育、汽車、新聞、文化、女人共12 個類別。
3)THUCNews-L 數(shù)據(jù)集:THUCNews 是根據(jù)新浪新聞RSS訂閱頻道2005—2011 年的歷史數(shù)據(jù)篩選過濾生成,包含約74 萬篇新聞文檔。本文在原始數(shù)據(jù)集上進行數(shù)據(jù)清洗,重新整合劃分出財經(jīng)、房產(chǎn)、股票、教育、科技、社會、時政、體育、游戲、娛樂,共計10 個類別,每個類別數(shù)據(jù)約2 萬條。
4)THUCNews-S 數(shù)據(jù)集:在THUCNews 基礎上進行數(shù)據(jù)清洗的小型數(shù)據(jù)集,共包含財經(jīng)、股票、科技、社會、時政、娛樂6 個類別,每個類別數(shù)據(jù)1 萬條。
4.2 對比實驗設置
為驗證本文所提出的結合BERT 和特征投影網(wǎng)絡的新聞主題分類方法的有效性,選擇了8 個在新聞文本分類上效果較好的分類模型作為對比。其中:TextCNN、FastText、Transformer 和DPCNN,結合Word2Vec 字粒度詞向量進行文本分類實 驗;ALBERT-FC、BERT-FC、BERT-CNN 和BERTBIGRU 結合預訓練模型進行文本分類實驗。具體如下:
1)TextCNN:多窗口超參數(shù)設置為[2,3,4],4 窗口可以很好地提取中文新聞數(shù)據(jù)的四字成語語義,卷積核數(shù)量設置為256。
2)FastText:將輸入文本的序列投射到詞嵌入空間,然后通過池化層得到文本特征向量分類,F(xiàn)astText 沒有卷積操作,模型結構簡單、速度快。
3)Transformer:使用encoder 作為特征提取器,本次實驗使用了單組注意力機制和3 個encoder 塊作為模型組成。
4)深層金字塔模型(Deep Pyramid Convolutional Neural Network,DPCNN):該模型參考深度殘差網(wǎng)絡(Residual Network,ResNet),解決深層模型的梯度消失問題。通過固定特征圖(feature map)的數(shù)量,采用步長為2 的最大池化操作,使每個卷積層的數(shù)據(jù)大小減半,同時相應的計算時間減半,從而形成一個金字塔(Pyramid)。
5)ALBERT:使用ALBERT-BASE 中文預訓練模型,在模型最后一層pooling 層輸出連接全連接層(Fully Connected layer,F(xiàn)C)進行Softmax 分類。
6)BERT-FC:使用BERT 模型最后的[CLS]向量連接FC進行分類。
7)BERT-CNN:使用BERT 模型的最后一層的encoder輸出的每個字向量特征,通過卷積池化進一步提取特征進行分類任務,其中CNN 也使用[2,3,4]窗口卷積池化,卷積核數(shù)量256。
8)BERT-BIGRU(BERT-Bidirectional Gated Recurrent Unit):使用BERT 模型的最后一層的encoder 輸出,提取每個字向量特征,輸入雙向門控單元(Bidirectional Gated Recurrent Unit,BiGRU)提取上下文語義特征從而進行文本分類。
在實驗之前對四個新聞數(shù)據(jù)集進行預處理,過濾掉非ASCII 字符,清洗換行符等標點符號,對英文字符進行大小寫轉(zhuǎn)換,并對中文文字進行簡繁字體轉(zhuǎn)換。
對比實驗中TextCNN、FastText、Transformer 和DPCNN 模型結合Word2Vec 字粒度詞向量進行文本分類實驗,并分別在訓練集上訓練Word2Vec 字向量,本次對比實驗中Word2Vec 字典大小設置為5 000,字符映射為300 維字向量。
對比實驗中ALBERT-FC、BERT-FC、BERT-CNN 和BERT-BIGRU 結合預訓練模型進行文本分類實驗。ALBERT-FC 使用ALBERT-BASE-CHINESE 中文預訓練模型,BERT-FC、BERT-CNN 和BERT-BIGRU 使 用BERT-BASECHINESE 中文預訓練模型。對比模型超參數(shù)均在新聞主題文本分類數(shù)據(jù)集上進行調(diào)優(yōu)。
4.3 評價指標
本文采用準確率Acc(Accuracy)、精確率P
(Precision)與召回率R
(Recall)的F
1 值對模型效果進行評價,其計算公式如下:
TP
表示實際正樣本預測為正,TN
表示負樣本預測為負,FP
表示負樣本預測為正,FN
表示正樣本預測為負。由于本次實驗任務為多類別新聞主題文本分類任務,因此使用精確率P
、召回率R
和F
1 值的宏平均(Macroaveraging)值M_F1 作為評價指標。宏平均計算方式將每個類別的精確率、召回率和F
1 值分別計算出來,然后對所有類求算術平均值,如式(23)~(25)所示。宏平均值更適合作為多類別分類任務評價指標。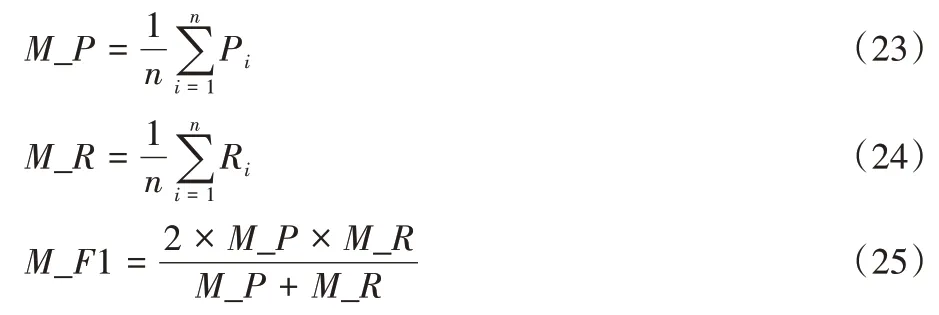
4.4 實驗參數(shù)
本文所提出的結合BERT 和FPnet 的新聞主題分類方法的兩種實現(xiàn)方式的基本參數(shù)設置相同,主要包括BERT 模型參數(shù)和綜合模型訓練參數(shù)設置,BERT 模型采用谷歌開源的BERT-BASE 中文預訓練語言模型。模型主要參數(shù)如表3所示。

表3 BERT模型主要參數(shù)Tab 3 Major parameters of BERT model
優(yōu)化策略使用更適合于BERT 模型的BertAdam 優(yōu)化器,warmup 模型預熱設置為0.05,模型學習率設置為5E-5,并且使用動態(tài)學習率策略進行學習率衰減,衰減系數(shù)為0.9。
由于四個數(shù)據(jù)集的平均長度都在20 左右,多次微調(diào)長度超參數(shù)后選取文本輸入長度超參數(shù)pad_size
=32,梯度反轉(zhuǎn)GRL 超參數(shù)λ
設置為[0.05,0.1,0.2,0.4,0.8,1.0],隨著模型訓練梯度下降變化,可以有效提取共性特征,具體如表4所示。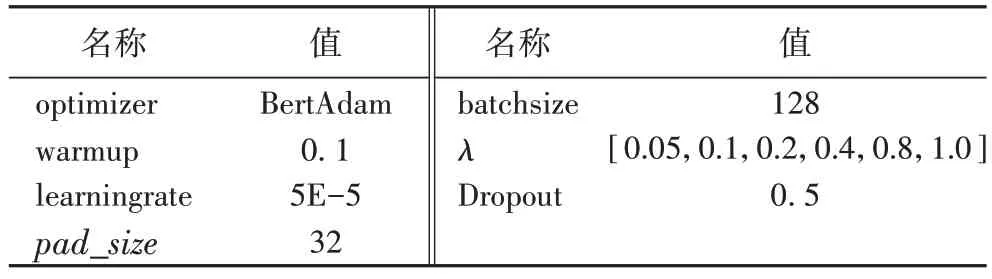
表4 BERT-FPnet模型超參數(shù)Tab 4 Hyperparameters of BERT-FPnet model
在BERT-FPnet-2 中,對BERT 模型各個隱藏層進行特征投影,對比各個隱藏層特征投影分類效果:
1)單層投影:分別對BERT 模型第3、6、9、12 層隱藏層進行特征投影;
2)雙層投影:分別在第3、6、9、12 層隱藏層以及最后一層MLP 層進行特征投影;
3)所有層投影:在BERT 模型的12 個隱藏層均進行特征投影。
4.5 實驗結果分析
如表5 所示,在搜狐新聞數(shù)據(jù)集上進行BERT-FPnet-2 隱藏層特征投影實驗,3、6、9、12 分別表示在BERT 的單層隱藏層特征投影層;3-MLP、6-MLP、9-MLP、12-MLP 分別是表示雙層特征投影;ALL 代表所有層均進行特征投影;MLP 為BERT-FPnet最后一層MLP 層。
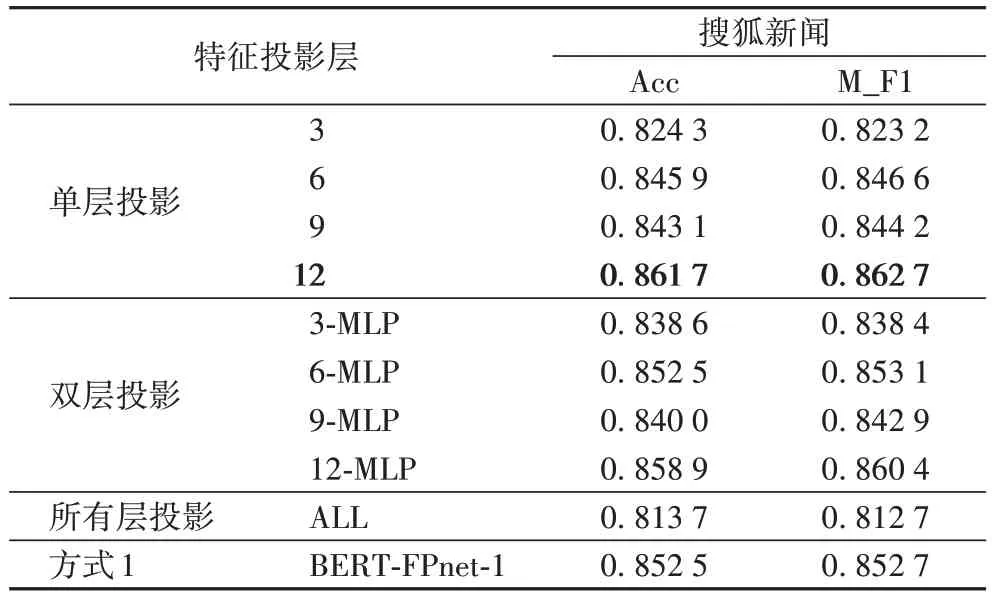
表5 搜狐新聞數(shù)據(jù)集上BERT-FPnet-2隱藏層特征投影實驗結果Tab 5 Experimental results of BERT-FPnet-2 hidden layer feature projection on Sohu News dataset
在單層特征投影對比可以看出,第12 層隱藏層特征投影效果最好,準確率和F1 值分別達到了0.861 7 和0.862 7。從雙層特征投影對比實驗可以看出,6-MLP 投影和12-MLP層特征投影效果最好,但是雙層投影效果相較于單層第12層隱藏層投影效果有所降低。而使用所有層進行特征投影分類效果下降較多。對比BERT-FPnet-1 可以發(fā)現(xiàn),在BERTFPnet-2 使用第12 層隱藏層進行特征投影效果最好。
為進一步驗證BERT-FPnet 第12 層隱藏層特征投影的效果,將其在THUCNews-S 數(shù)據(jù)集上進行對比實驗,實驗結果如表6 所示。可以看到在THUCNews-S 數(shù)據(jù)集下隱藏層投影分類效果和BERT-FPnet-1 效果接近。
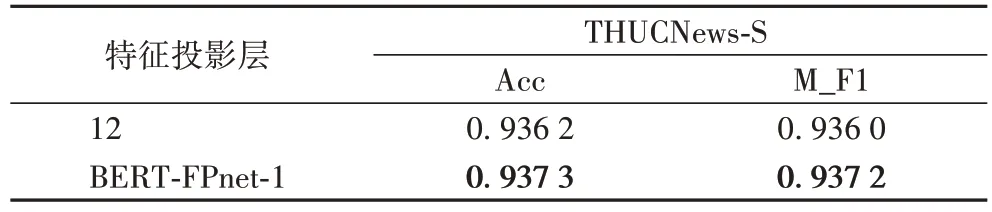
表6 THUCNews-S數(shù)據(jù)集上BERT-FPnet的特征投影結果對比Tab 6 Comparison of BERT-FPnet feature projection results on THUCNews-S dataset
上述實驗通過在BERT 模型部分隱藏層進行層次特征投影實驗對比,表明BERT 模型融合特征投影層適合在語義特征提取層進行特征投影。
在四個數(shù)據(jù)集上進行多個模型實驗對比實驗,實驗結果如表7 所示,其中BERT-FPnet-1 為在模型MLP 層最終特征輸出進行特征投影,而BERT-FPnet-2 為在BERT 輸出的第12 層隱藏層進行特征投影后再放入MLP 層進行分類。
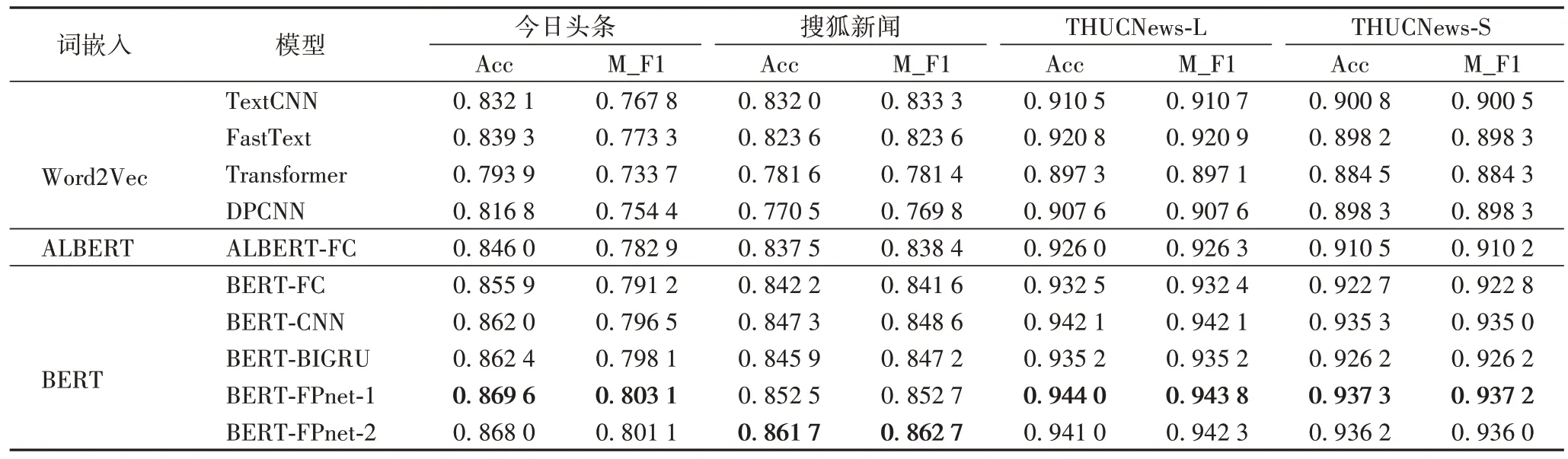
表7 各模型在不同數(shù)據(jù)集上的實驗結果Tab 7 Experimental results of different models on different datasets
從表7 可以看出本文所提出的結合BERT 和FPnet 的新聞主題分類方法的兩種實現(xiàn)方式,在準確率、宏平均F1 值都優(yōu)于其他文本分類模型,尤其優(yōu)于目前基于BERT 模型融合較好的BERT-CNN 和BERT-BIGRU。為更加直觀地對各模型性能進行分析,采用柱狀圖的形式對各模型的M_F1(宏平均F1 值)實驗結果進行展示,如圖6 所示。
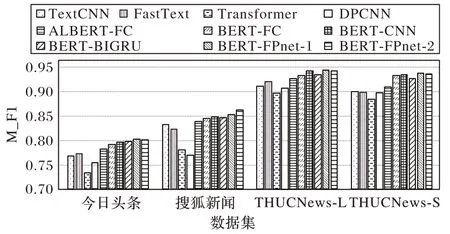
圖6 各模型在不同數(shù)據(jù)集上的宏平均F1值Fig.6 M_F1 value of different models on different datasets
從圖6 可以看出,本文模型在各個數(shù)據(jù)集上效果均優(yōu)于其他對比模型,在THUCNews-L 和THUCNews-S 數(shù)據(jù)集上只有BERT-CNN 模型F1 值接近本文模型。
并且分析表7 中數(shù)據(jù)可知,使用Word2Vec 向量的TextCNN、FastText、Transformer、DPCNN,分類效果顯然差于融合預訓練模型的ALBERT-FC、BERT-FC、BERT-CNN 和BERT-BIGRU 方法,說明預訓練語言模型在提取的句子語義特征表示比Word2Vec 更好,這也是本文使用BERT 模型融合特征投影的原因。而ALBERT 模型雖然在BERT 模型上進行創(chuàng)新,消減了BERT 模型的參數(shù),但是在一定程度上降低了模型準確率。
在今日頭條、THUCNews-L、THUCNews-S 這3 個數(shù)據(jù)集上BERT-FPnet-1 在MLP 層投影效果更好,而搜狐新聞數(shù)據(jù)集上在BERT-FPnet-2 使用BERT 模型第12 層隱藏層投影效果更好,因此可以針對不同數(shù)據(jù)集選擇不同的特征投影方式得到最好的分類效果。
4.6 超參數(shù)影響
本文所提新聞主題文本分類模型影響最終分類效果的參數(shù)主要包括:新聞主題文本輸入長度pad_size
、GRL 梯度反轉(zhuǎn)參數(shù)λ
以及雙網(wǎng)絡學習率。新聞主題文本一般長度不一,模型輸入長度pad_size
不宜過長也不宜過短:過短的輸入長度顯然無法有效獲取完整語義信息;而設置過長的pad_size
進行數(shù)據(jù)對齊時,填充值會造成噪聲影響語義提取效果,并且由于BERT 模型注意力機制的特性,模型的計算時間也會呈指數(shù)增長,從而影響模型分類性能。GRL 梯度反轉(zhuǎn)參數(shù)主要作用在于幫助C-net 提取有效的共性特征。雙網(wǎng)絡學習率在微調(diào)時可分為同步學習率和異步學習率。同步學習率是指雙網(wǎng)絡采用相同梯度下降策略和學習率,異步學習率是指雙網(wǎng)絡采用不同的梯度下降策略和學習率。雖然在DANN 中采用的是ADam 和SGD的雙網(wǎng)絡不同優(yōu)化策略,文獻[22]中也是使用這種方式,但是本文使用同步學習率獲得了更好的效果。在THUCNews-S 數(shù)據(jù)集上進行參數(shù)對比實驗,結果如表8 所示。可以看出pad_size
取值從平均長度18 到40,本文模型的準確率和F1 值變化。從實驗結果中可以看到pad_size
值依次取18、24、32 時,模型的準確率和F1 值逐步提升,但當pad_size
值取40 時,模型準確率和F1 值并未得到有效提升。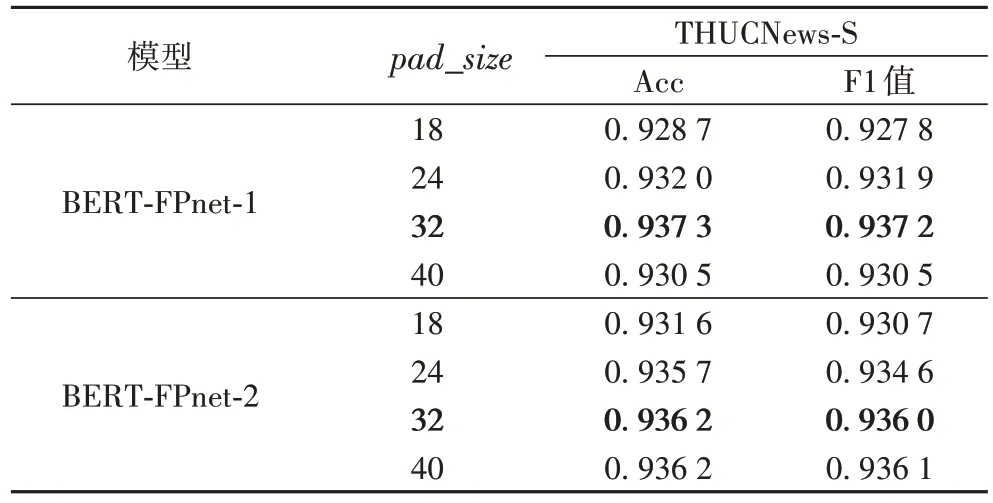
表8 各pad_size 下本文模型在THUCNews-S數(shù)據(jù)集上的性能對比Tab 8 Perfomance comparison of proposed models under different pad_size on THUCNews-S dataset
GRL 超參數(shù)λ
分別取靜態(tài)值1 和兩種動態(tài)λ
進行實驗對比,實驗結果如表9 所示。可以看出不同的λ
值對模型分類效果會產(chǎn)生細微影響,更加細膩度的λ
變化幅度對模型的分類效果更好,更有助于C-net 提取共性特征。
表9 各λ下本文模型在THUCNews-S數(shù)據(jù)集上的性能對比Tab 9 Performance comparison of proposed models under different λ on THUCNews-S dataset
在雙網(wǎng)絡優(yōu)化策略方面,本文對比了文獻[22]中所用的ADam 和SGD 的雙網(wǎng)絡不同優(yōu)化策略,以及本文所用的雙BERTAdam、同步學習率方式。實驗結果如表10 所示。可以看出本文所用方法對以BERT為基礎的FPnet分類效果更好。
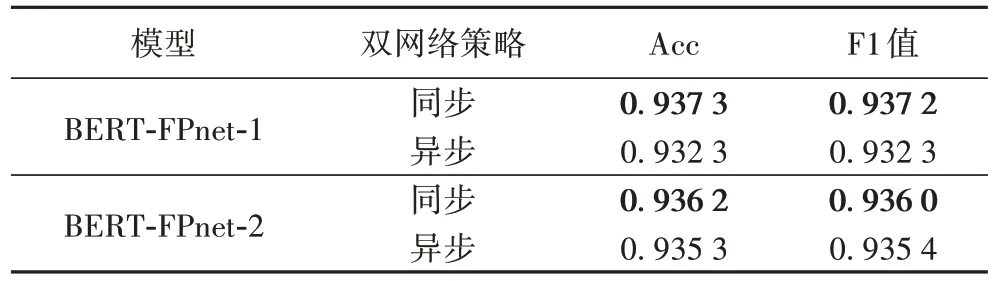
表10 各優(yōu)化策略下本文模型在THUCNews-S數(shù)據(jù)集上的性能對比Tab 10 Performance comparison of proposed models under different optimization strategies on THUCNews-S dataset
因此最終各數(shù)據(jù)集實驗對比部分并未參照文獻[22]中在FPnet 的雙網(wǎng)絡結構中使用Adam 和SGD 兩種梯度下降優(yōu)化策略,而是使用了更適合于BERT 模型的雙BERTAdam 優(yōu)化器。
5 結語
本文提出兩種結合BERT 和FPnet 的新聞主題文本分類方法。利用BERT 模型對新聞主題文本的完美語義特征提取能力,使用雙BERT 模型以特征投影的方式結合完成新聞主題文本分類任務。在其中一個BERT 網(wǎng)絡中加入GRL 梯度反轉(zhuǎn)層,提取新聞主題文本的共性特征;然后使用另一個BERT 網(wǎng)絡OPL 將提取的特征在共性特征上進行投影,從而提取特性特征,提升文本分類效果。在四個新聞主題數(shù)據(jù)集上進行大量對比實驗,驗證了本文所提出的結合BERT 和FPnet 的新聞主題文本分類方法的有效性。
本文模型缺點在于模型參數(shù)量較大,可嘗試使用知識蒸餾消減模型參數(shù)。在下一步工作中,將使用BERT 的字序列向量通過CNN、RNN 進行特征提取后融合特征投影進行網(wǎng)絡融合,以完成新聞主題分類任務。
