
支持中文醫療問答的基于注意力機制的棧卷積神經網絡模型
2022-05-07 07:07:28潘海為張可佳牟雪蓮張錫明陳偉鵬
計算機應用 2022年4期
滕 騰,潘海為,張可佳,牟雪蓮,張錫明,陳偉鵬
(哈爾濱工程大學計算機科學與技術學院,哈爾濱 150001)
0 引言
隨著智慧醫療高速發展,在線客服變得更人性化,人們會優先通過在線客服咨詢健康問題。在線網站會安排專業醫生回答用戶的問題,但是考慮到大多數人問題類似,醫生會回答重復問題,用戶花費無意義等待時間,導致醫生和用戶使用體驗差。為了減少時間浪費,基于問答匹配的智能客服應運而生,根據答案從提前設計好的問題庫匹配相應答案返回給用戶。
早期算力約束導致問答系統都是基于規則和傳統機器學習方法。20 世紀60 年代,人們建立依靠專家預設規則去回答用戶問題的智能問答系統,一旦出現效果不佳,很難處理同時觸發的多條規則,維護成本過高。在20 世紀70 至80年代,大量研究考慮通過計算語言技術去更容易構建智能問答系統。20 世紀80 年代后,人們開始用傳統機器學習和深度學習方法解決問答匹配,例如字匹配、詞匹配、雙向長短時記憶(Bi-directional Long Short-Term Memory,BiLSTM)循環神經網絡等。以上方法,更多適合英文,并未考慮中文具有一些特殊語言特征,不能直接套用英文問答匹配方案。
考慮到語言差異,解決中文問答問題時人們先用jieba、ICTCLAS(Institute of Computing Technology,Chinese Lexical Analysis System)等分詞工具將中文語句做分詞,再將詞做詞嵌入,獲得詞嵌入后再使用英文問答匹配解決方案。在語句分詞做詞嵌入后,Wang 等提出計算單詞詞向量的相似度去衡量問題和答案之間相似性。在音樂領域,Li 等將一個問題翻譯成SPARQL 查詢語句后在預設數據庫中查詢最可能的答案。通用中文問答匹配往往需要分詞才能執行后續操作,然而中文醫療領域中分詞工具對希望不被分割的專業醫療詞匯分割成幾個詞這種結果很敏感,例如,“葡萄糖注射液”就會被分詞工具切分成“葡萄”“糖”“注射液”,而導致信息受損致使后續任務效果顯著下降。雖然可以通過設置專門的中文醫療詞典緩解問題,但是詞典的設計繁瑣、維護成本過高以及即使有詞典仍然可能出現低頻醫療詞組分詞的錯誤。
Wang 等研究指出,基于字的模型優于基于詞的模型。受此啟發:對于中文醫療專業等領域,對字做處理可以避免分詞工具分詞不正確導致的信息損傷。從2017 年開始,Zhang 等提出基于字嵌入的多尺度卷積神經網絡(Multiple Convolutional Neural Networks,Multi-CNNs)模型,通過多個單層CNN 學習問題和答案,將得到的語義信息拼接在一起。2018 年,Zhang 等提出棧卷積神經網絡(Stack CNN,Stack-CNN)模型、多層CNN 分別學習問題和答案的語義信息。但是,以上工作都是對問題和答案分開建模,并未考慮問題和答案間詞匯的互相影響,不符合人們平時處理兩個相關句子時靠其中一個句子去理解另外一個句子的習慣。
為了解決以上問題,本文提出了一種基于注意力機制的棧卷積神經網絡(Attention mechanism based Stack CNN,Att-StackCNN)模型。首先,該模型使用字嵌入分別對問題、正確答案和錯誤答案進行編碼得到各自的字嵌入矩陣;然后,通過構造注意力矩陣得到特征注意力映射矩陣;接著,利用Stack-CNN 同時對上述矩陣進行學習,分別得到問題、正確答案和錯誤答案各自的語義表示;最后,對問題和答案的語義表示進行相似度計算,根據得到的兩個相似度去計算最大邊際(Max-margin)損失,根據損失函數更新網絡參數。
1 相關工作
1.1 字嵌入
在自然語言處理任務中,目前處理詞匯主要將詞語表示成連續的向量處理詞語。經典的詞向量獨熱編碼,占用內存多,訓練神經網絡時不易更新參數,需要將獨熱編碼轉化成稠密的詞向量。Bengio 等將神經網絡應用于語言模型,提出前饋神經網絡語言模型(Neural Network Language Model,NNLM),訓練后得到詞向量。在此基礎上,Mikolov 等提出了word2vec,通過三層神經網絡將獨熱編碼壓縮成稠密的詞向量。此外,由于word2vec 訓練得到的詞向量可以通過向量之間的距離揭示詞之間語義關系,word2vec 廣泛應用于自然語言處理領域。word2vec 做詞嵌入的實例1 如圖1 所示。考慮到中心詞由其相鄰詞所決定,因此希望第i
個詞出現在文本中概率最大,context(e
)為中心詞e
的周邊詞,所以此時訓練目標是最大化p
(e
|context(e
)),采用最大似然估計優化以下目標:
圖1 word2vec做詞嵌入的實例1Fig.1 Example 1 of using word2vec to character embedding

除了對中文的細粒度不同,字嵌入的處理方式和詞嵌入幾乎一致。word2vec 做字嵌入的實例2 如圖2 所示。
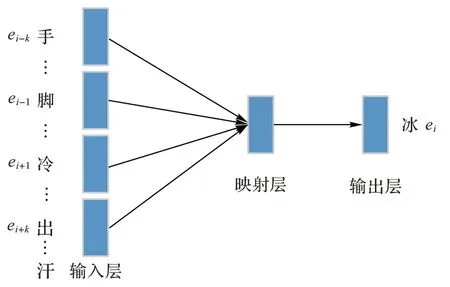
圖2 word2vec做字嵌入的實例2Fig.2 Example 2 of using word2vec to character embedding
1.2 Stack-CNN
自從Kim提出適用于文本分類的卷積神經網絡(Text CNN,TextCNN),CNN 一直是自然語言處理領域研究的熱點。CNN 通過一個“窗口”(卷積核),可以遍歷整個文本后得到一些全局信息,其作用的原理類似于N
-Gram 算法。圖3為Stack-CNN 的一個實例。
圖3 Stack-CNN的實例Fig.3 Example of Stack-CNN
給定一個句子的字嵌入編碼序列S
=(e
,e
,…,e
),其中:e
為句中第i
個字的字向量,字向量維數為d
,n
為句中字的個數。第一層的卷積神經網絡對S
做卷積得到輸出O
,第二層對O
做卷積得到輸出O
,重復以上操作得到第n
層的輸出O
,O
經過最大池化得到最終S
的語義表示S
。2 Att-StackCNN模型
2.1 Att-StackCNN模型整體框架
Att-StackCNN 模型的整體框架如圖4 所示。問題和答案經過字嵌入層得到各自的字嵌入矩陣Q
和A
,再分別與注意力矩陣(Attention Matrix,AM)相乘,得到各自的特征注意力映射矩陣F
和F
;AM
為注意力矩陣。H
和H
分別為問題和答案對應的注意力權重矩陣,Q
和A
為由字嵌入矩陣和特征注意力映射矩陣堆疊得到的三階張量,同層的Stack-CNN 顏色相同有相同參數;F
和F
與Q
和A
一起作為卷積層的輸入,進入Stack-CNN 得到各自語義的表示Q
和A
;最后通過相似度計算判斷答案是否最符合用戶的問題。
圖4 Att-StackCNN模型的整體框架Fig.4 Overall framework of Att-StackCNN model
AM
和Stack-CNN 網絡共同組成本文模型Att-StackCNN。Att-StackCNN 模型利用AM
來影響卷積運算,將問題和答案之間關聯部分賦予更高權重以提升整體效果。2.2 構建特征注意力映射矩陣
以前的問答匹配任務都是對問題和答案分開建模,不考慮兩個句子間的相互影響。但是,人們在尋找問題的答案時,會把注意力集中在問題中人們認為重要的地方,在答案中尋找其關聯部分,如同義詞和反義詞來幫助人們匹配答案。因此本文將同時對問題和答案建模,通過問題編碼序列Q
和答案編碼序列A
得到注意力矩陣AM
,借助問題去匹配正確答案。AM
的元素AM
定義如下: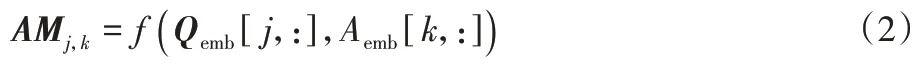


H
、H
∈R,都是模型訓練時需要學習的參數。AM
的元素AM
由問題的第j
個字開始的句子和答案的第k
個字開始的句子對應的字向量運算得到,這意味著利用問題的第j
個字開始的部分句子去輔助理解答案的第k
個字開始的部分句子,關聯程度由H
和H
體現。通過AM
改變問題和答案字嵌入矩陣的分布得到各自特征注意力映射矩陣,特征注意力映射矩陣和原來的字嵌入矩陣構成雙通道,特征注意力映射矩陣并未改變數據中特征的分布僅改變數據的分布,進而增加后續網絡可學習信息,效果隨之提升。在得到表示問題和答案的F
和F
后,F
、Q
堆疊得到三階張量Q
,F
和A
堆疊得到三階張量A
,并將其分別送入后續神經網絡中進行卷積運算。2.3 訓練過程


圖5 cMedQA數據集部分問題答案對Fig.5 Some question-answer pairs of cMedQA dataset
利用Q
和A
得到注意力矩陣AM
,用AM
分別與H
和H
相乘得到F
和F
。F
、Q
堆疊得到張量Q
,F
、A
堆疊得到張量A
,并將其分別送入Stack-CNN 神經網絡中進行卷積運算。對問題、正確答案和錯誤答案做卷積的部分具有相同參數,卷積核尺度分別為c
,c
,…,c
,則對問題編碼序列卷積運算公式如下:
W
⊙Q
表示W
和Q
中對應元素相乘;b
為偏置項。卷積核尺度選擇為2、3、4,卷積核的選擇見后文實驗對比,卷積的特征映射數為800 或者1 000 皆可。由式(4)得到,O
后經過最大池化得到問題的最終語義表示Q
;用相同的部分對A
做卷積得到正確答案的語義表示A
。同理通過上述過程,利用Q
和A
得到錯誤答案的語義表示A
。Q
和A
+的相似度度量函數公式如下:
m
=sim(Q
,A
),利用m
和m
計算損失函數。此時訓練的目的是希望m
越大越好,m
越小越好,因此本文采用Max-margin 損失作為損失函數,其定義式如下:
M
為超參數,本文設定M
=0.5。優化器采用隨機梯度下降(Stochastic Gradient Descent,SGD)算法或者自適應矩估計(Adaptive moment estimation,Adam);學習率為0.01,學習輪數100;錯誤答案和正確答案與AM
運算時使用的H
和H
相同,H
、H
、W
、b
采用隨機初始化,通過Max-margin 損失更新H
、H
、W
、b
。3 實驗與結果分析
由于中文醫療問答對匹配沒有統一的公開數據集,本文采用文獻[7]通過爬蟲主流醫療網站制作的開源數據集cMedQA(https://github.com/zhangsheng93/cMedQA)。表1 為cMedQA 的統計信息,將該數據集劃分為三部分:訓練集、開發集和測試集。

表1 cMedQA數據集的統計信息Tab 1 Statistics of cMedQA dataset
K
(ACC
@k
)作為評價本文中文醫療問答的標準,ACC
@k
的定義如下:
3.1 基準模型
3.1.1 傳統方法基準模型
1)隨機選擇:隨機從候選答案池里選擇答案。
2)字匹配:統計問題與答案中相同字的數量。
3)詞匹配:統計問題與答案中相同詞語的數量。
4)BM25:該模型的公式定義如下:

IDF
(w
)為問句中字(或者詞)w
的逆文檔頻率匹配;|a
|為答案a
的長度;|a
|為答案a
的平均長度;g
(w
,a
)為a
中w
的頻率;k
和b
是需要設定的參數,在本文中,設定k
=2.0,b
=0.75。3.1.2 深度學習方法基準模型
1)Multi-CNNs:由多個有不同卷積核的單層CNN 對句子進行卷積操作,將得到的不同語義表示拼接在一起作為最后得到的語義表示。問題和答案做卷積操作時,擁有相同卷積核的CNN 具有相同參數。
2)Stack-CNN:由多個單層CNN 組成,除卻第一層直接學習問題和答案,其他層都是對上層輸出做卷積,最后一層得到的信息為最終語義信息。問題和答案做卷積時,同層CNN具有相同卷積核和參數。
3.2 實驗結果
本文實驗采用Pytorch 框架,使用genism 訓練字向量。為避免分詞工具對結果的影響,分詞工具采用常見的jieba和ICTCLAS。對比實驗將從傳統方法和深度學習方法比較,使用不同嵌入方式的方法進行比較。
3.2.1 傳統方法對比結果
表2 為傳統基準模型方法對比結果,分別基于不同嵌入方式進行比較。
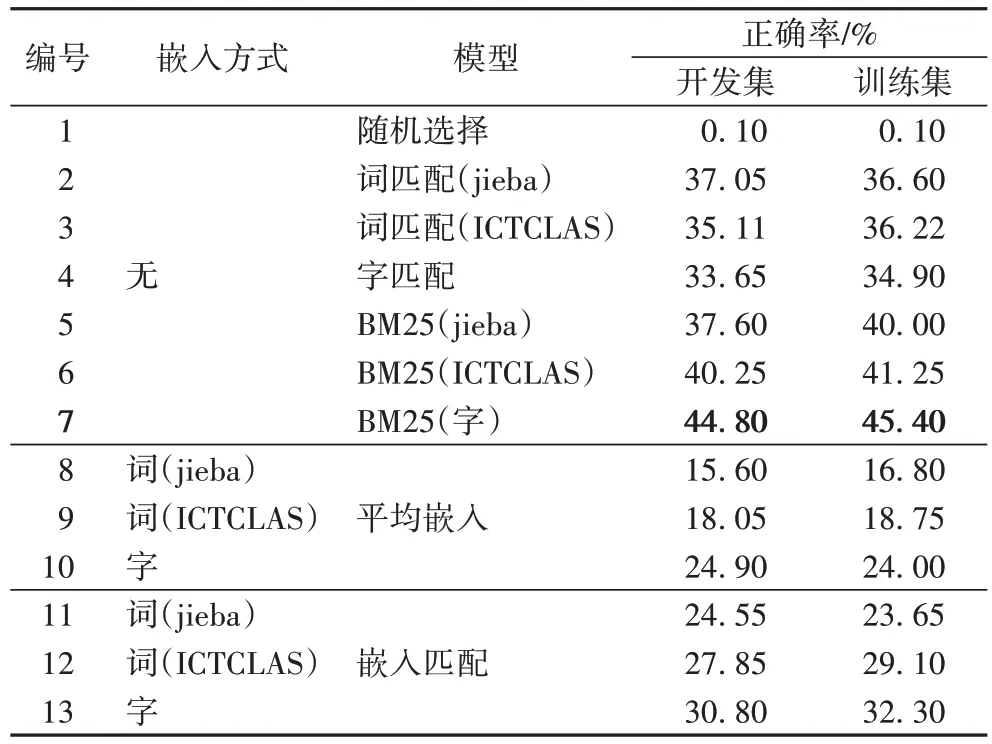
表2 傳統基準模型正確率的比較Tab 2 Accuracy comparison of traditional baseline models
表2第1行的隨機選擇由于隨機性太強,幾乎很難選中正確的回答,正確率僅為0.10%;由第2~4 行可知,詞匹配在jieba 和ICTCLAS 兩次分詞工具分詞下的結果都要比字匹配略高或者接近;由第5~7行可知,使用BM25算法時,使用字的結果很明顯高于使用分詞結果得到的詞的結果,因為BM25算法會對較短字段賦予更大的權重;第8~13行展示的是基于嵌入的結果。在嵌入方式相同的情況下,字嵌入要優于詞嵌入,中文醫療文本用分詞工具的結果會導致專業詞匯被切割導致信息損失。而模型一致情況下,嵌入匹配要優于平均嵌入。
綜上所述,傳統機器學習方法中正確率最高的為BM25,其正確率為45.40%。可能是傳統方法學習能力有限,因此本文考慮在中文醫療問答匹配中引入深度學習。
3.2.2 深度學習方法比較結果
表3 為使用jieba 作為分詞工具的詞嵌入方式的深度學習方法。在該情況下,Att-StackCNN 和Stack-CNN 的效果要差于Multi-CNNs,可能是因為分詞結果不準確導致語義信息受損。同時Att-StackCNN 和Stack-CNN 除了第一層的CNN外,其他層的CNN 學習的都不是原始分詞得到的語義,卷積運算過程中導致了一部分語義改變,致使Att-StackCNN 和Stack-CNN 正確率比Multi-CNNs 低2.0 個百分點。

表3 基于word(jieba)深度學習方法正確率比較 單位:%Tab.3 Accuracy comparison of deep learning methods based on word(jieba) unit:%
表4 為使用ICTCLAS 作為分詞工具的詞嵌入方式的深度學習方法。此時,3 個模型結果接近。在模型一致的情況下,ICTCLAS 做為分詞工具的結果要優于jieba,因為ICTCLAS 做分詞采用了層疊隱馬爾可夫模型,而jieba 做分詞是使用基于統計詞頻,分詞正確率要低于ICTCLAS。ICTCLAS 分詞正確率高,不會導致類似于jieba 分詞那樣較多語義信息損失,Att-StackCNN、Stack-CNN 的結果和Multi-CNNs 的結果基本接近,而不是出現使用jieba 分詞時出現差2.0 個百分點的情況。

表4 基于word(ICTCLAS)深度學習方法正確率比較 單位:%Tab 4 Accuracy comparison of deep learning methods based on word(ICTCLAS) unit:%
表5 為使用字嵌入方式的深度學習方法的正確率對比結果。在使用字嵌入的情況下,Stack-CNN 比Multi-CNNs 的正確率低0.7 個百分點左右,這可能是Stack-CNN 除了第一層處理的語義信息都不是原始信息,在做卷積的時候出現信息丟失,導致結果稍差。而Att-StackCNN 在Stack-CNN 的基礎上考慮了問答對詞匯之間的互相影響,引入了注意力矩陣,因此Att-StackCNN 的結果要比Stack-CNN 高1.0個百分點以上。同時注意力矩陣也彌補了Stack-CNN 做卷積時信息丟失的問題,比Multi-CNNs 高0.5 個百分點以上。

表5 基于字嵌入的深度學習方法正確率比較 單位:%Tab 5 Comparison of correct rate of deep learning methods based on character embedding unit:%
表6 為Att-StackCNN 不同卷積核對比實驗。由于自然語言處理任務中,CNN 處理中文文本卷積核尺度一般選擇2~4,因此本文的卷積核尺度對比實驗分為4 組,卷積核尺度范圍為2~4。由表6 可以看出卷積核尺度為2、3、4 效果最好,可能原因是因為中文2~4 個字的詞語較多,Att-StackCNN可以充分學習中文醫療文本中的語義信息。

表6 Att-StackCNN的不同卷積核正確率比較 單位:%Tab 6 Accuracy comparison of different convolution kernels in Att-StackCNN unit:%
4 結語
深度學習方法在中文醫療問答匹配問題中效果要比傳統方法好,在算力允許時,使用深度學習方法效果更佳,同時深度學習不需要花費過多人力手動提取特征。
對中文醫學文本使用詞嵌入時會出現分詞不正確對后續任務的影響,即便通過引入醫學詞典可以緩解此問題,詞典的維護和建立成本高,因此采用字嵌入處理中文醫學文本。本文在Stack-CNN 的基礎上在問題和答案之間引入了注意力矩陣,提出了本文的模型Att-StackCNN,利用注意力矩陣學習問題和答案詞匯間的關系,通過訓練調整問題和答案各自的注意力權重矩陣,將相關字設置高權重,不相關字設置低權重后得到特征注意力映射矩陣。特征注意力映射矩陣相較于字嵌入矩陣僅數據分布改變,特征分布并未改變,與嵌入矩陣堆疊得到三階張量送入后續網絡,使后續網絡可學習信息增加。使用字嵌入時,Att-StackCNN 模型結果高Stack-CNN接近1個百分點,高Multi-CNNs接近0.5個百分點。
目前公開廣泛使用的中文醫療問答數據集不多,接下來,可以考慮制作其他大的中文醫療問答數據集以增加其他評價標準。同時,由于目前并未有類似于英文開源的醫療字和詞向量,中文醫療領域研究的瓶頸之一在于通用領域詞向量并不能完全揭示醫療領域詞匯間關系,接下來將考慮改進訓練中文醫學詞向量方式,以得到高質量中文醫療詞向量。
