
改進的聯邦加權平均算法
2022-05-07 07:07:30羅長銀王君宇陳學斌馬春地張淑芬
計算機應用 2022年4期
羅長銀,王君宇,陳學斌*,馬春地,張淑芬
(1.華北理工大學理學院,河北唐山 063210;2.河北省數據科學與應用重點實驗室(華北理工大學),河北唐山 063210;3.唐山市數據科學重點實驗室(華北理工大學),河北唐山 063210)
0 引言
自谷歌于2016 年提出聯邦學習(Federated Learning,FL)以來,聯邦學習受到國內外專家學者的廣泛關注,因具有保護隱私數據的潛力,被廣泛應用于多個領域。
聯邦學習的訓練數據是基于各個數據源本地的數據進行訓練的,不需要收集、存儲數據到云端和整合多方數據,這種方法大幅降低了敏感信息泄露的風險。文獻[9]中,使用區塊鏈來存儲各時間段內訓練的模型參數,降低了在存儲方面的成本,同時也降低了因模型參數還原原始數據的風險。但因聯邦學習的訓練數據來源于不同數據源,訓練數據并不能滿足獨立分布和訓練數量一致這兩個能影響聯邦模型的條件。若數據源的訓練數據分布不同,那么整合多方的子模型成為巨大的難題。
在聯邦學習框架的應用中,最常見的算法是聯邦平均(Federal Average,FedAvg)算法。文獻[17]從數據質量的角度對原有的FedAvg 算法進行改進,考慮到數據源之間數據質量的差異導致權重的不合理分配問題,文獻[17]使用層次分析法對權重進行改進;但層次分析法中比較矩陣的數值由人為確定,存在不可靠因素。因此,本文采用預訓練機制來計算各客戶端的精度,將其作為各客戶端的質量,并結合客戶端數據量的大小,重新計算全局模型中權重更新的方法,能夠給出相對合理的權重分配方案。實驗結果表明,改進的聯邦加權平均算法與傳統聯邦平均算法相比準確率有所提升。
1 改進的聯邦加權平均算法
1.1 聯邦學習
聯邦學習(FL)是一種隱私保護算法,是算法優化實現路徑和保護數據安全的前提下解決數據孤島問題的解決方案。具體實現過程為:對多個參與方在本地私有數據上進行模型訓練,然后將不同的模型參數上傳到云端進行整合和更新,之后將更新的參數發送至各參與方。整個過程私有數據不出本地,既保證了數據隱私,又解決了各參與方“數據孤島”的困境。根據聯邦學習的實現過程使得FL 具有保護隱私和本地數據安全的優勢。
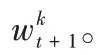

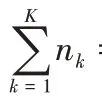
1.2 改進的聯邦加權平均算法
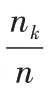
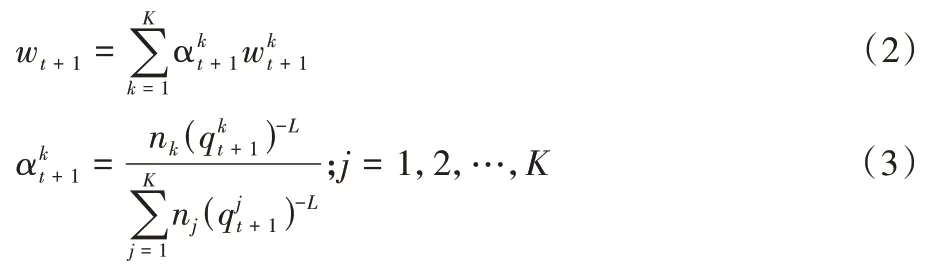
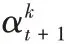
q
的計算公式為:
C
表示第t
個客戶端建立的模型在與測試樣本上預測正確的樣本數;X
表示預測試樣本數。1.3 算法的流程
步驟1 各客戶端將數據樣本按照一定的比例劃分為訓練樣本和測試樣本;
步驟2 各客戶端將訓練樣本按照比例劃分為預訓練樣本和預測試樣本;
步驟3 中心服務器使用由RSA(Rivest-Shamir-Adleman)加密算法產生的公鑰對隨機森林、樸素貝葉斯、神經網絡、決策樹4 種初始全局模型加密并傳輸至客戶端;
步驟4 客戶端使用私鑰解密后,獲取4 種初始全局模型;
步驟5 各客戶端使用不同類型的初始全局模型在預訓練樣本上進行訓練,獲得本地模型;
步驟6 各客戶端將本地模型在預測試樣本上進行預測,獲取預測正確的樣本數C
;步驟7 客戶端使用式(4)來計算其數據的質量;
步驟8 從客戶端的數據數量與質量兩方面來使用式(3)計算出客戶端的權重;
步驟9 將客戶端上使用4 種初始全局模型訓練的本地模型與步驟7 計算的客戶端的權重相乘,并以此獲取更新的全局模型;
步驟10 不斷迭代優化其客戶端的權重,直到達到停止條件。
1.4 算法性能
本文采用預訓練的方法對各客戶端的權重進行優化,并與聯邦平均算法進行結合,從而獲取各客戶端的權重變化。
1.4.1 算法的復雜度分析
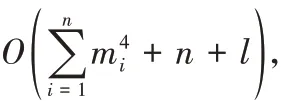
1.4.2 算法的安全性分析
本文算法采用預訓練的方法,在數據層面上,因采用聯邦平均算法的框架結構,其訓練所用的數據僅在本地進行訓練,滿足模型找數據的本質要求,使數據在使用方面的安全性得到提升;在模型層面上,因采用非對稱加密算法對本地模型與初始全局模型進行分發與整合,使模型在傳輸過程中的安全性得到提升。
2 實驗與結果分析
2.1 實驗設置
實驗硬件環境為:Inter Core i5-4200M CPU 2.50 GHz 處理器,內存8 GB;操作系統為Windows10。
2.2 實驗數據分析
實驗數據采用UCI(University of California-Irvine)數據集中 的digits數據集、recognition 數據集、segment 數據集、segmentation 數據集與telescope 數據集進行實驗。表1 列出了實驗中所使用的5 組數據集的基本信息。對于每個數據集,重復進行了100 次實驗,用100 次準確度的均值作為準確率,將準確率與方差作為算法性能差異比較的依據。
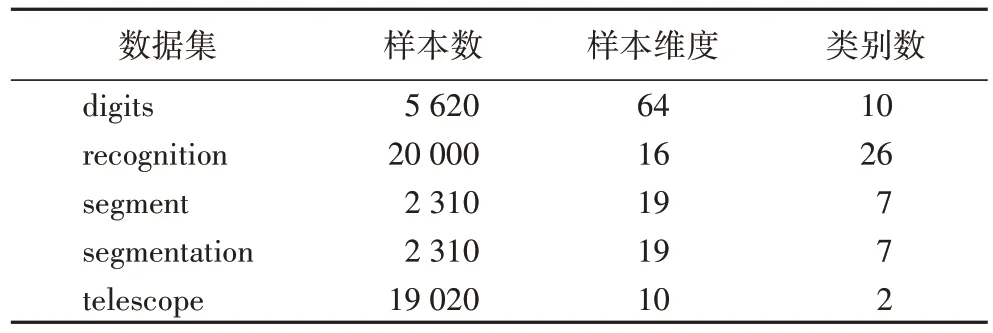
表1 實驗所使用的數據集Tab 1 Datasets used for experiment
為充分模擬多源數據的特點,將各數據集隨機劃分,其中包括均分與非均分兩種情況。均分的情況是:將各數據集的數據隨機劃分100 次且每次都均等劃分,同時將初始全局模型在均等隨機劃分100 次的數據上進行訓練,所獲得的準確度的均值來作為準確率,使用方差來衡量模型的收斂情況。非均分的情況采取相同的方法。
實驗分為兩部分:第一部分是模型權重中參數的調整與計算。首先客戶端將自身的數據劃分為訓練樣本與測試樣本,并將訓練樣本再次劃分為預訓練樣本與預測試樣本,其次將隨機森林、樸素貝葉斯、神經網絡、決策樹在預訓練樣本上訓練的得分作為該客戶端的數據質量,最后根據客戶端的數據數量與質量綜合給出客戶端的權重。第二部分是可信第三方使用公鑰對隨機森林、樸素貝葉斯、神經網絡、決策樹、加密并傳輸至客戶端,客戶端使用私鑰解密后,獲取4 種初始全局模型,且使用4 種初始全局模型分別進行訓練,客戶端獲取本地模型,使用公鑰對客戶端上的本地模型進行加密并傳輸至可信第三方,可信第三方將多個本地模型與權重相乘獲取更新的全局模型,并不斷優化迭代,直到更新的全局模型的準確率滿足停止條件。
第一部分:各客戶端(k
=1,2,3)將自身的訓練樣本劃分為預訓練樣本與預測試樣本,并使用不同的初始全局模型在預訓練樣本上的得分作為該客戶端的數據質量,同時對式(3)中的L
取值為-10。對數據進行均等劃分和非均等劃分兩種情況,表2 為不同的初始全局模型在均等情況下預測試樣本的得分情況;表3 為不同的初始全局模型在非均等情況下預測試樣本的得分情況。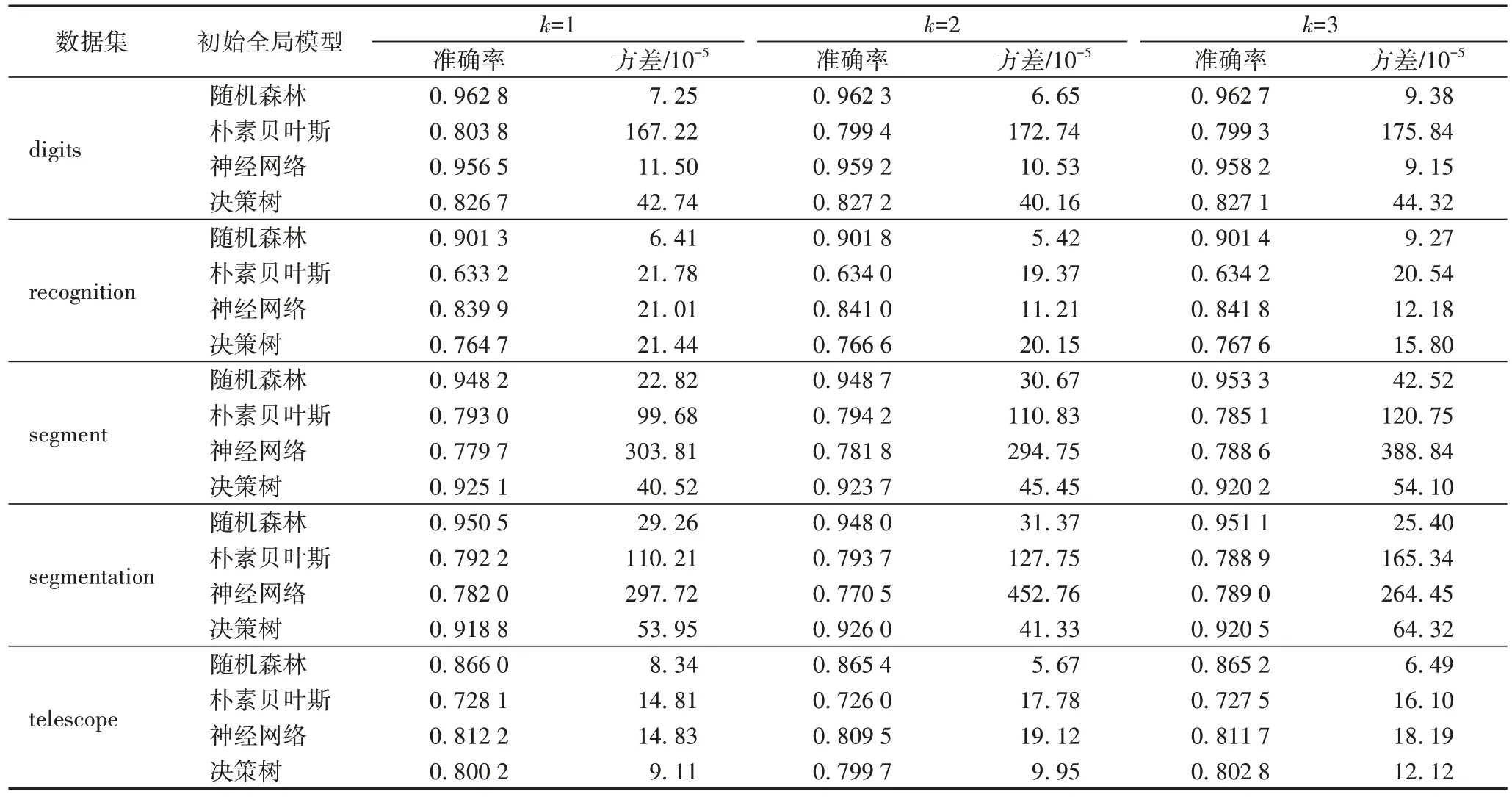
表2 不同初始全局模型在不同數據集均等分割的預測試樣本上的準確率及方差Tab 2 Accuracy and variance of different initial global models on pre-test samples of different equal divided datasets
從表2 中可以看到將各數據集分別進行均等分割,使用不同的初始全局模型在均等分割的數據上進行訓練,不同的初始全局模型在不同的客戶端的預訓練樣本上進行訓練,其建立的模型在預測試樣本上的得分情況,即各客戶端上數據質量的情況。當數據集選用digits 時,4 種初始全局模型在各客戶端上的數據為均等情況下的訓練得分,其中:隨機森林在預測試樣本上準確率在96.23%以上,同時方差最大的為9.38 × 10;樸素貝葉斯在預測試樣本上準確率在79.94%以上,方差最大的為167.22 × 10;神經網絡在預測試樣本上準確率在95.65%以上,方差最大的為11.5 × 10;決策樹在預測試樣本上準確率在82.67%以上,方差最大的為44.32 ×10。當數據集選用recognition 時,4 種初始全局模型在各客戶端上的數據為均等情況下的訓練得分,其中:隨機森林在預測試樣本上準確率在90.13%以上,同時方差最大的為9.27 × 10;樸素貝葉斯在預測試樣本上準確率在63.32%以上,方差最大的為21.78 × 10;神經網絡在預測試樣本上準確率在83.99%以上,方差最大的為21.01 × 10;決策樹在預測試樣本上準確率在76.47%以上,方差最大的為21.44 ×10。當數據集選用segment 時,4 種初始全局模型在各客戶端上的數據為均等情況下的訓練得分,其中隨機森林在預測試樣本上準確率在94.82%以上,同時方差最大的為45.52 ×10;樸素貝葉斯在預測試樣本上準確率在78.51%以上,方差最大的為120.75 × 10;神經網絡在預測試樣本上準確率在77.97%以上,方差最大的為388.84 × 10;決策樹在預測試樣本上準確率在92.02% 以上,方差最大的為54.10 × 10。當數據集選用segmentation 時,4 種初始全局模型在各客戶端上的數據為均等情況下的訓練得分,其中:隨機森林在預測試樣本上準確率在94.81%以上,同時方差最大的為31.37 × 10;樸素貝葉斯在預測試樣本上準確率在78.89%以上,方差最大的為165.34 × 10;神經網絡在預測試樣本上準確率在77.05%以上,方差最大的為452.76 ×10;決策樹在預測試樣本上準確率在91.88%以上,方差最大的為64.32 × 10。當數據集選用telescope 時,4 種初始全局模型在各客戶端上的數據為均等情況下的訓練得分,其中:隨機森林在預測試樣本上準確率在86.52%以上,同時方差最大的為8.34 × 10;樸素貝葉斯在預測試樣本上準確率在72.60%以上,方差最大的為17.78 × 10;神經網絡在預測試樣本上準確率在80.95%以上,方差最大的為19.12 ×10;決策樹在預測試樣本上準確率在79.97%以上,方差最大的為12.12 × 10。
將各數據集分別進行非均等分割,使用不同的初始全局模型在非均等分割的數據上進行訓練,不同的初始全局模型在不同客戶端的預訓練樣本上進行訓練,其建立的模型在預測試樣本上的得分情況,即各客戶端上數據質量的情況如表3 所示。
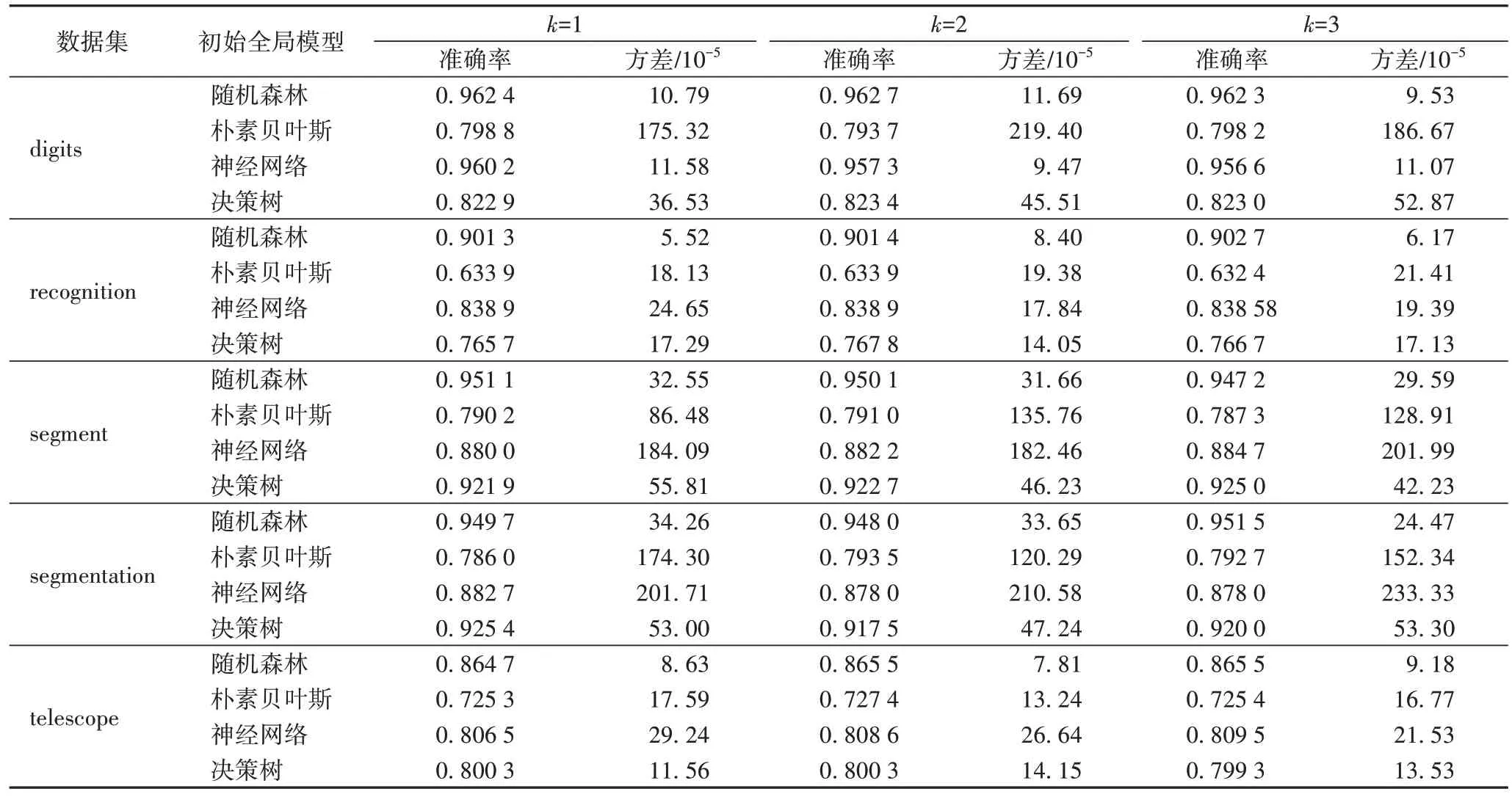
表3 不同初始全局模型在不同數據集非均等分割的預測試樣本上的準確率及方差情況Tab 3 Accuracy and variance of different initial global models on pre-test samples of different unequal divided datasets
第二部分:各客戶端在預訓練樣本上訓練得到本地模型,將本地模型使用第一部分所計算的權重進行匯總,建立更新的全局模型。表4 為加權聯邦平均算法和傳統未加權聯邦平均算法所得到的更新的全局模型的準確率的情況。
從表4 中可以很明顯地得到數據在均分與非均分的情況下,不同初始全局模型在各客戶端的數據上進行訓練的情況,同時使用準確度均值與方差來衡量模型的性能。
傳統聯邦平均算法是可信第三方將4 種初始全局模型分別傳輸至客戶端,客戶端進行訓練后得到本地模型,再采用平均法整合多個數據源的本地模型,匯總成更新的全局模型。從表4 中可以看出,無論是加權聯邦平均算法還是傳統的聯邦平均算法,其隨機森林的準確率均高于其他三種模型的準確率,且方差最小。同時當數據為非均分情況下建立的模型準確率都大于均分情況下的建立的模型的準確率。與傳統聯邦平均算法相比,改進的聯邦加權平均算法的準確率最高分別提升了1.59%和1.24%。
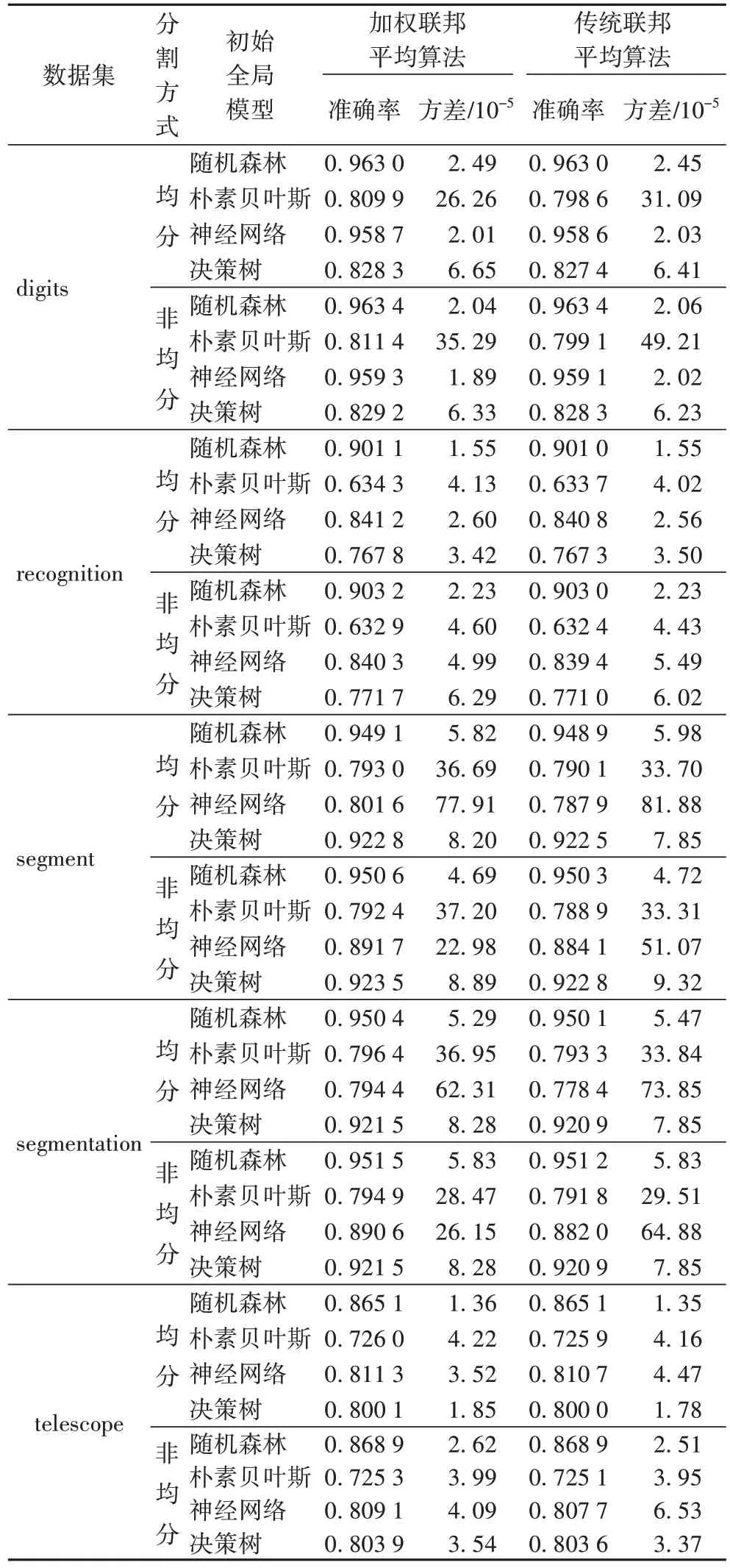
表4 加權聯邦平均算法和傳統聯邦平均算法準確率比較Tab 4 Accuracy comparison of weighted federated average algorithm and traditional federated average algorithm
傳統的多源數據處理方法整合多方數據存放在數據中心,再進行訓練而得到全局模型。表5 為傳統的多源數據處理方法在digits 數據集、recognition 數據集、segment 數據集、segmentation 數據集與telescope 數據集上模型訓練的情況。
從表5 中可以得到使用傳統多源數據處理技術建立的模型的準確率的情況,同時表格中的數據為十折交叉得到的數值,可以很明顯看出,在digits 數據集、recognition 數據集、segment數據集、segmentation數據集與telescope 數據集中隨機森林的準確率最高。
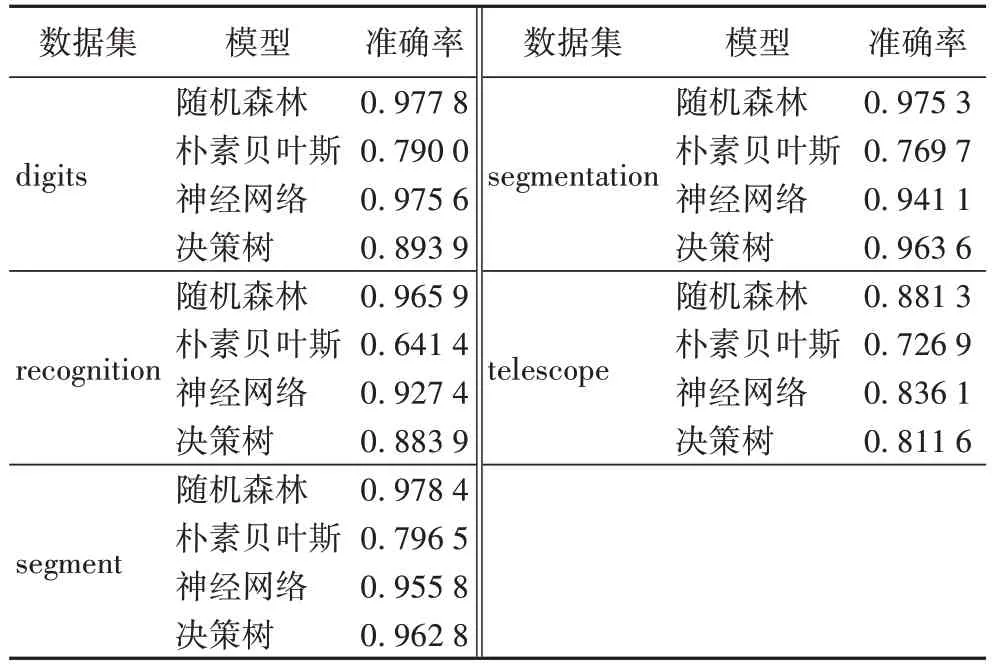
表5 傳統的多源數據處理方法建立的模型準確率Tab 5 Accuracies of models established by traditional multi-source data processing method
文獻[17]采用層次分析法對聯邦平均算法進行改進,表6 為根據層次分析法改進的聯邦平均算法建立的模型的準確率的情況。
從表6 中可以看出,改進模型在digits 數據集、recognition數據集、segment 數據集、segmentation 數據集與telescope 數據集中隨機森林的準確率最高。將本文算法的準確率最優值與基于層次分析法改進的聯邦平均算法相比,本文算法在digits 數據集中,隨機森林的準確率降低了1.13%,樸素貝葉斯的準確率提升了8.06%,神經網絡的準確率降低了1.13%,決策樹的準確率降低了5.75%;在recognition 數據集中,隨機森林的準確率降低了3.94%,樸素貝葉斯的準確率提升了5.58%,神經網絡的準確率提升了3.76%,決策樹的準確率提升了13.07%;在segment 數據集中,隨機森林的準確率降低了1.59%,樸素貝葉斯的準確率提升了2.48%,神經網絡的準確率提升了3.78%,決策樹的準確率降低了1.47%;在segmentation 數據集中,隨機森林的準確率降低了1.31%,樸素貝葉斯的準確率提升了3.42%,神經網絡的準確率提升了0.94%,決策樹的準確率降低了1.63%;在telescope 數據集中,隨機森林的準確率提升了0.31%,樸素貝葉斯的準確率降低了0.51%,神經網絡的準確率提升了25.55%,決策樹的準確率降低了2.96%。
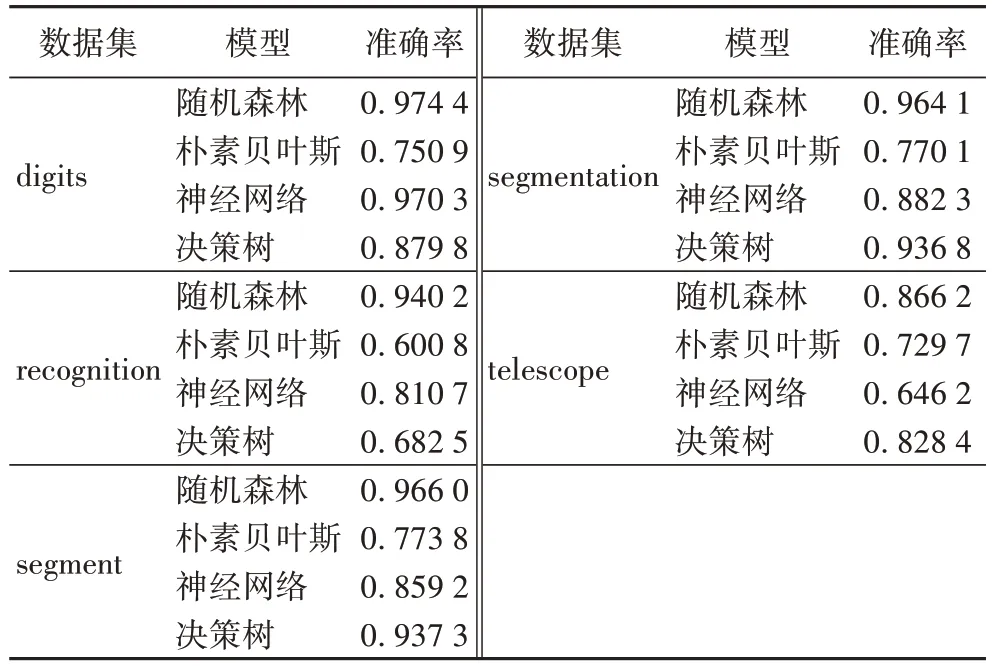
表6 基于層次分析法改進的聯邦平均算法建立的模型準確率Tab 6 Accuracies of models established by the improved federated average algorithm based on analytic hierarchy process
2.3 實驗小結
該算法將訓練樣本劃分為預訓練樣本與預測試樣本,且將在預訓練樣本上建立的本地模型在預測試樣本得到的分數作為各客戶端的數據質量,并計算出各客戶端的權重;可信第三方將4 種初始全局模型加密傳輸至客戶端,客戶端解密后并進行訓練,獲取本地模型,客戶端將本地模型傳輸至可信第三方,可信第三方將根據數據質量計算得到的權重來整合多個本地模型。對于digits 數據集、recognition 數據集、segment 數據集、segmentation 數據集與telescope 數據集而言,不論數據是否為均分,當初始全局模型為隨機森林、樸素貝葉斯、神經網絡和決策樹時,與傳統聯邦平均算法相比,其準確率均有所提升。與傳統多源數據處理技術相比,雖然準確率略有下降,但數據的安全性得到了提升。
3 結語
本文在消除主觀因素的情況下,從數據質量的角度對聯邦平均算法進行優化,將訓練樣本劃分為預訓練樣本與預測試樣本,將初始全局模型在預訓練樣本上訓練,所建立的模型在預測試樣本上進行預測所得到的分數作為其數據質量,并計算出相應的權重;同時采用加密傳輸的方式將不同模型類型傳輸至各數據源,各數據源在訓練后并進行整合,獲取更新后的全局模型,在提升模型準確率的同時兼顧了模型與多源數據的安全性。未來的工作中,將差分隱私應用到該算法中,進一步提升數據的隱私性和模型的可用性、安全性。
