
基于標簽分層延深建模的企業畫像構建方法
2022-05-07 07:07:50丁行碩
計算機應用 2022年4期
丁行碩,李 翔*,謝 乾
(1.淮陰工學院計算機與軟件工程學院,江蘇淮安 223003;2.江蘇卓易信息科技股份有限公司,江蘇宜興 214200;3.南京百敖軟件有限公司,南京 210032)
0 引言
近年來,隨著知識圖譜與大數據的快速發展,畫像技術受到工業界和學術界廣泛的關注。目前比較流行的企業畫像在電子商務、風險評估、市場監管等方面有著廣泛的應用,其網站不僅具備傳統門戶網站的信息服務功能,還能提供許多與標簽相關的服務如熱點分析和企業推薦等。作為一種新型的畫像技術應用,企業畫像中不僅包含大量企業、位置等多模實體,還擁有大量的異質關系和文本特征,比如企業位置關系、企業競爭合作關系以及企業研究者發表的論文專利關系。企業畫像的實質是基于企業結構化和半結構數據,抽取出標簽化的企業模型,這些大量數據混合在一起形成了非常復雜的結構特征。
企業文本是企業向社會展示企業基本信息和綜合實力的載體。通過畫像技術對不同維度信息篩選整合,以不同的形式向企業、政府提供服務。在企業畫像中,標簽體系建設是畫像研究的重要部分,是通過企業基礎的統計類標簽,以及行為產生的規則類標簽,最后是數據挖掘產生的挖掘類標簽共同構建而成。然而,由于大量不同維度企業信息過于雜亂,導致信息處理、標簽提取等任務難度較大,因此標簽建模的合理性以及標簽抽取的精確程度直接影響到畫像的表達能力及畫像應用效果。目前,在傳統的標簽建模領域已有許多成果,總體上看,現階段主流的標簽建模方法大致有3 種:基于傳統模式的方法、基于機器學習的方法和基于神經網絡的方法等。一方面,這些方法雖然能準確地發現文本標簽,但都存在的問題是僅適用于同一實體或單一關系,特別是對于企業文本這種既有多模實體,又有因多維度實體形成的異質關系,比如企業在行為空間活躍形成發展趨勢主題,還在結構空間由多源信息形成趨勢點,上述標簽建模方法顯然無法有效地融合多維實體和異質關系;另一方面,信息的多樣性給數據處理、分析帶來挑戰,在傳統標簽建模過程中易出現模糊標簽集合,但較少有學者關注于企業模糊標簽特點,例如批發業、零售業等無法完整概括企業特點的標簽。自然語言處理(Natural Language Processing,NLP)和數據挖掘能夠從非結構化數據中得到具有高度概括能力的標簽,并呈現語義化和短文本兩個主要特征,為標簽建模提供新的思路,但這些方法仍未能準確、真實反映企業特點和關聯性。因此,為了更好地對復雜信息標簽建模,多源信息融合與NLP 相結合成為新的標簽建模方式。
本文針對以上問題提出了一種基于標簽分層延深建模的企業畫像構建方法EPLLD(Enterprise Portrait of Label Layering and Deepening)。首先,基于企業畫像指標體系建立模糊標簽指標體系;然后,闡述模糊標簽處理和EPLLD 建模的過程;最后,以企業信息文本作為實驗數據,根據實驗結果分析EPLLD 的優勢以及未來工作。概括來看,本文的主要工作如下:
1)提出了一種基于標簽分層延深建模的企業畫像構建方法,該方法對模糊標簽進行模糊標簽延深,然后使用關鍵詞提取實現標簽分層延深建模,可以形象展示企業特點。
2)以企業標簽指標體系為基線,建立企業模糊標簽指標體系,由此展示模糊標簽在畫像維度上的分布與規律。
3)本文使用特征融合的方法對多源文本進行向量拼接,并充分利用BERT(Bidirectional Encoder Representation from Transformers)語言模型和深度學習抽取企業文本的多特征信息,最后通過TF-IDF(Term Frequency-Inverse Document Frequency)、TextRank、隱含狄利克雷分布(Latent Dirichlet Allocation,LDA)模型進行標簽抽取。在真實企業數據集上的實驗結果表明本文所提的EPLLD 方法在標簽延深和標簽體系結構上都具有最好的表示效果。
1 相關工作
現有畫像技術研究工作主要有三大類:面向應用畫像的研究發現、面向標簽體系建設的研究發現以及面向NLP 的標簽建模。
在面向應用畫像的研究發現中,大多數的畫像研究都是基于用戶畫像而產生,Alan 在1999 年提出Persona 的概念,它是一種建立在真實數據之上的目標用戶模型,被作為一種交互設計工具;2006 年Chun 等提出了Corporate Character Scale的相關概念,討論了Agreeableness、Competence、Enterprise、Ruthlessness、Chic 五個主要維度和Informality、Machismo 兩個次要維度,用于評估企業聲譽對員工和客戶的影響;2015 年Ma?ová 等在Corporate Character Scale 的概念上進行擴展,仍使用七個維度標簽對兩個著名零售企業進行調查,分析和揭示它們的企業形象;2019 年楊沛安等將畫像技術應用于網絡安全,通過分析威脅情報從而提高網絡攻擊識別的效率與準確性;2021 年李曉敏等通過了解用戶認知需求以及用戶畫像在圖書館的應用實踐,提出了一種面向用戶認知需求的圖書館用戶畫像推薦模型,促進了用戶畫像的構建與完善。
在面向標簽體系建設的研究發現中,其關鍵問題是如何有效地融合多模實體和多維關系。劉海鷗等對用戶畫像研究成果進行細致的梳理,揭示了用戶畫像建模的不同方法,總結出了各類建模方法的特點與發展趨勢;Che 等對多標簽任務中的標簽相關性進行了深入研究,并提出了一種新 的FL-MLC(Feature distribution-based Label correlation in Multi-Label Classification)方法,描述特征變量和標簽變量之間的關系;Lin 等提出了一種消費者需求標簽提取方法,將電子口碑與信息技術結合在一起,提高企業市場競爭力。從已有的研究成果來看,標簽體系建設又可分為兩種維度:一種是使用標簽分類建設標簽體系,例如Pan 等提出了一種社交標簽擴展模型,利用標簽之間的關系擴展標簽,緩解標簽稀疏問題;黃曉斌等融合多源數據進行企業競爭對手畫像構建,通過整合數據類型和增加權重,使用多種聚類算法對企業進行競爭者推薦;另一種是標簽分層建設標簽體系,標簽分層因具有高效、具體化優勢,逐漸受到研究者們的廣泛關注。例如An 等使用交互式設計技術,基于對社交媒體數據的自動分析,實現了對畫像內容的層次性更新;Zhang 等利用數據驅動構建畫像,提出了一種從下至上的定量數據驅動方法,并結合混合模型更新畫像內容。此外,還可以通過融合結構信息進行特征擴展,提高標簽準確率。
在面向NLP 的標簽建模中,研究者通常會采用NLP 來發現企業文本的隱藏特征,而傳統的文本處理方法會導致文本特征稀疏和語義敏感等問題。為更精準地建立全方面、多維度的企業畫像,多源信息融合為企業畫像構建提供了新的思路,神經網絡依據出色的自適應和實時學習特點成為畫像構建的常用方法,關鍵詞提取因其適應性強廣泛應用于畫像標簽構建。Mikolov 等提出Word2Vec 證明了在向量空間中單詞表示的有效性;Pennington 等和Peters 等提出的全局向量(Global Vectors,GloVe)和 ELMo(Embeddings from Language Models)取得了很大成功,解決了Word2Vec 只考慮詞的局部特征問題;Du 等提出了一種多級用戶畫像模型,通過集成標簽和評分來實現個性化推薦,反映用戶的喜好特點。在關鍵詞提取中,能把非結構化文本中包含的信息進行結構化處理,并將提取的信息以統一形式集成在一起。有監督的關鍵詞提取精度高,需大量標注數據,人工成本過高,無監督提取應用廣泛,有基于統計特征的TF-IDF 算法、基于詞圖模型的TextRank 算法和基于主題的LDA 主題模型算法等。不同類型文本中,同一算法應用效果存在差異,因此組合算法的應用彌補了單算法不足。
綜上可知,目前學者研究中,基于機器學習模型和深度學習模型的標簽抽取、標簽分類任務已經取得了很高的成就,但較少有學者關注企業模糊標簽特點,建立自上而下的標簽分層延深建模體系。雖然已有一些研究嘗試采用集成方法來融合多維信息,但這些方法都存在局限性,有些方法忽略了多源文本的交互關系或關聯性,而另一些方法則無法充分發現企業文本特征,容易丟失重要信息。針對標簽體系建設特別是標簽建模中存在的標簽概括能力差、模糊標簽處理難、標簽提取不合理等問題,本文結合數據特點和企業特性來規約數據實體,依據企業領域專業術語進行企業詞庫特征拓展,提出了一種EPLLD 方法。首先,利用分布式爬蟲爬取企業信息并進行數據清洗,標注和構建企業標簽、詞庫,對企業模糊標簽進行統計和篩選,篩選出如批發業、零售業等不能完整概括企業特點的標簽信息;接著,通過對各企業類別、標簽等要素分析進行多源信息融合,并將整合后的特征信息使用BERT 語言模型進行字嵌入表示,利用注意力(Attention)機制發現文本信息長距離依賴關系;然后,將處理后的向量序列傳入雙向長短期記憶(Bi-directional Long Short-Term Memory,BiLSTM)網絡,依據企業特征信息和企業標簽進行模糊標簽延深;最后,使用綜合抽取算法從多特征信息中提取關鍵詞,將處理后的關鍵詞作為更深層的企業延深標簽。EPLLD 方法能夠挖掘深層次的標簽信息,并進行由淺入深的標簽體系構建,從而解決企業標簽建模難度大和標簽分層效果差等問題。
2 標簽分層延深建模的企業畫像構建模式
2.1 相關概念及形式化描述
標簽體系建設是企業畫像建設中的基本任務,本文以企業數據指標體系為基線,建立企業模糊標簽指標體系,通過EPLLD 實現模糊標簽的自動延深。即結構化標簽無法概括企業特點,從企業網絡文本提取具有實際意義的標簽來表示企業形象。
相較于基線體系,企業模糊標簽指標體系在標簽的類型劃分和模糊標簽的處理上有很大改變。本文依據標簽抽取方法的不同來劃分標簽類型,該指標體系能夠對處理方法相同的企業數據進行數據分群,從而有效篩選和處理模糊標簽,企業模糊標簽指標體系如表1 所示,共包含三種標簽類型:1)統計類標簽,包括基本信息、科研信息以及其他信息;2)規則類標簽,包含企業規模、企業價值以及風險等級;3)挖掘類標簽,包含企業需求、企業特點等,其中x
、y
為二級標簽。第二類中的規則類標簽抽取主要為統計學方法,能夠避免模糊標簽出現,而統計類和挖掘類標簽中的結構化數據易出現標簽表達不明確的現象,本方法對其進行了模糊標記。同時,本文針對二級指標的直觀表達展開研究,依據數據的差異對一級指標和二級指標進行微調。
表1 模糊標簽指標體系Tab 1 Fuzzy label index system
基于模糊標簽指標體系存在的相關問題,本文建立的企業標簽分層延深模型如圖1所示。分為以下三部分:1)基于多源異構分布式爬蟲獲取企業網絡文本,并對內部數據和網絡文本進行數據清洗,包括去重、去空以及缺失值填補等;2)使用特征融合的方法進行向量拼接,將多源企業信息融合為多特征語料,基于融合的多特征語料進行特征抽取,將抽取的隱藏特征傳入BiLSTM獲取模糊標簽延深結果;3)結合模糊標簽延深信息實現進一步的標簽抽取延深,完成EPLLD建模。
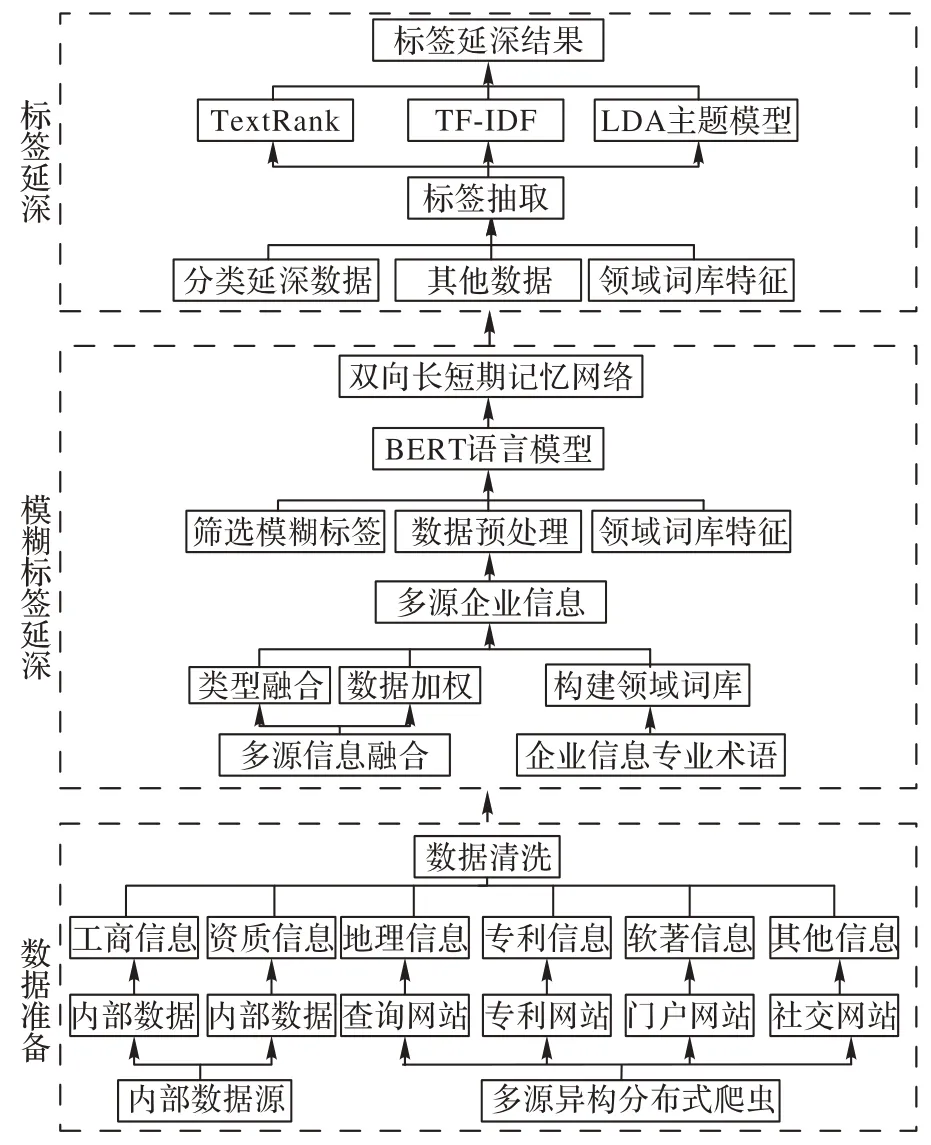
圖1 EPLLD建模過程Fig.1 EPLLD modeling process
2.2 數據準備
在明確企業畫像指標體系后,進一步獲取各指標數據。獲取指標數據的方式主要分為兩種:一種是通過企業內部數據源得到企業基本信息、企業資質信息和企業交易數據等;另一種是通過分布式爬蟲爬取各信息網站中的網絡文本,間接獲得如專利信息、招聘信息和企業評價信息等。本文結合兩種方法獲得指標數據,首先從企業內部得到企業核心數據;其次使用Scrapy 爬蟲框架建立分布式爬蟲,從社交平臺、招聘網站和門戶網站等進一步得到指標數據。
獲取各維度的指標數據后,對其進行數據清洗,本文數據清洗包含:重復數據的檢測及消除、缺失數據的統計及填補以及異常值的篩選和清理。
2.3 模糊標簽延深中的特征抽取
特征抽取是NLP 中的基本任務,特征抽取直接影響到EPLLD 建模的質量,也是EPLLD 建模的核心內容。由于中文語言無法用空格直接分詞,因此數據預處理的方式會對模型結果產生關鍵影響。為尋找更多特征信息,本文基于多源信息融合,使用企業名稱、經營范圍等信息,通過特征融合方法對不同的數據類型進行向量拼接,對其賦予權重后提煉多特征企業信息,并構建領域專業詞庫處理詞嵌入和保證分詞效果。例如,某商貿企業的名稱中通常含有企業偏好和特點的詞語,使用本方法將其向量化后乘以權重并與經營范圍的特征向量進行拼接,讓后續的網絡層對參數之間的聯系進行自適應調整。然后引入BERT 模型依據待處理文本內容,抽取出潛在特征,得到向量序列S
=T
,T
,…,T
,其中n
為字向量序列長度,將此向量表示作為深度神經網絡的輸入。BERT 模型是基于雙向Transformer 編碼器構建的語言模型,能夠發現詞語間的相互關系,此過程如圖2 所示。Transformer 是由編碼器和解碼器堆疊而成,在經過6 個編碼器處理后在傳入6 個解碼器進行解碼。而編碼器和解碼器的核心是注意力機制,它能聚焦句子中的關鍵點,并整合到Value 上,從而計算其價值。通過不斷進行這樣的注意力機制層和非線性層交疊來得到最終的文本表達,更容易地捕獲長距離依賴信息。
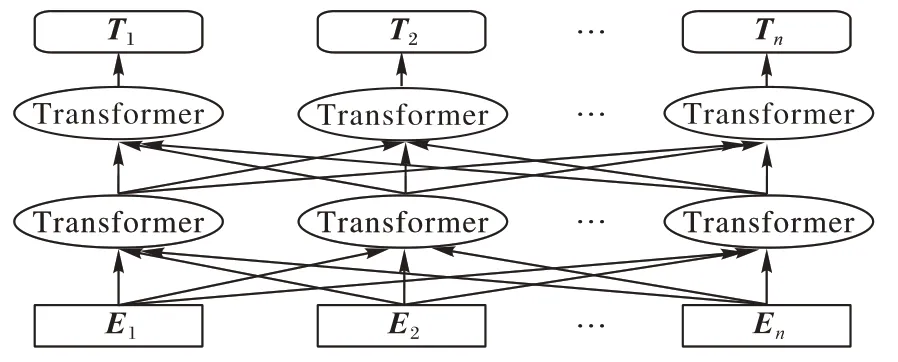
圖2 BERT語言模型Fig.2 BERT language model
注意力機制的定義如式(1)所示,其計算流程如圖3所示:
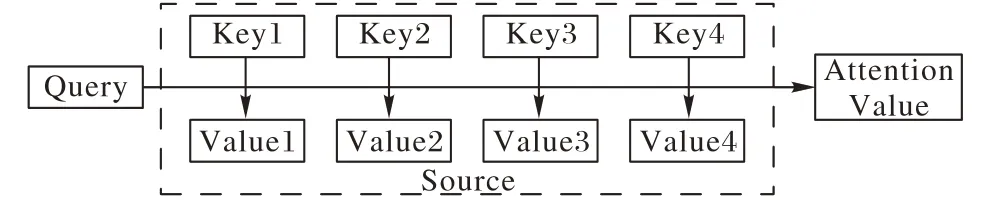
圖3 Attention計算流程Fig.3 Attention calculation flow
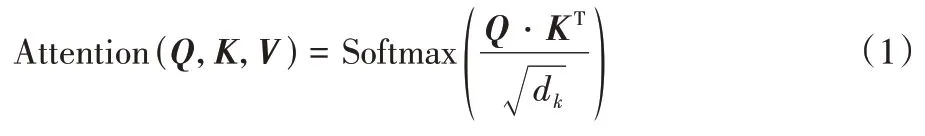
d
為向量的維度,Q
、K
、V
為輸入的字向量矩陣。此語言模型將兩個單詞直接計算并將其相互聯系,通過將所有單詞表示加權求和,縮短特征間距離,提高特征的有效利用率。2.4 模糊標簽延深中的BiLSTM
循環神經網絡(Recurrent Neural Network,RNN)是一種用于處理序列數據的神經網絡。相較于一般的神經網絡模型,能夠有效處理序列變化的數據。LSTM 是一種特殊的RNN,LSTM 的提出解決了普通RNN 在訓練過程中出現的梯度消失和梯度爆炸問題。LSTM 通過簡單的網絡結構,使用門控機制保留序列中的長期信息,引入遺忘門、輸入門、輸出門3 個門控單元,來實現模型的有效訓練。
本文采用LSTM 處理文本多特征向量信息,其內部結構如圖4 所示。圖4中,σ
是為Sigmoid 激勵函數;C
表示細胞狀態;h
表示隱藏層狀態;x
表示t
時刻網絡輸入。在LSTM 網絡中,f
、i
、o
分別表示遺忘門、輸入門和輸出門,W
和b
分別表示權重矩陣和偏置項,LSTM 網絡首先需要計算它的遺忘程度,即將t
時刻的記憶狀態乘以一個記憶衰減系數f
,衰減系數f
是根據t
時刻網絡輸入x
和t
-1 時刻的網絡輸入f
所決定,定義如式(2)所示: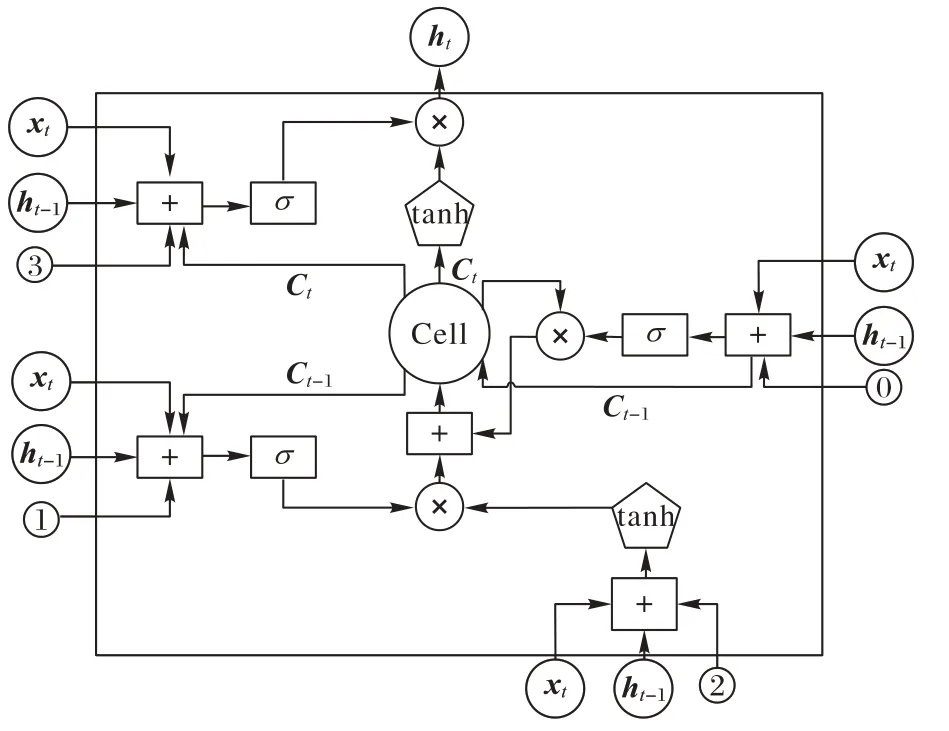
圖4 LSTM結構Fig.4 LSTM structure

i
,它是由t
-1 時刻的h
和t
時刻的x
所決定,定義如式(3)所示:
t
時刻記憶C
ˉ是經過線性變換所得到,它也是由t
-1 時刻的h
和t
時刻的x
所決定,定義如式(4)所示: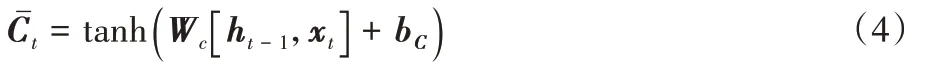
t
時刻的新記憶乘以衰減系數i
得到此時刻的學習記憶,然后計算保留的t
-1 時刻記憶f
*C
,將兩者相加作為t
時刻的記憶狀態,定義如式(5)所示:
t
-1 時刻的h
和t
時刻網絡輸入中的x
計算輸出門o
,定義如式(6)所示:
最終網絡經過tanh 轉化并輸出結果,由式(7)所計算:


ω
、υ
、b
分別為正向輸出權重矩陣、反向輸出權重矩陣和偏置。2.5 模糊標簽延深
在標簽體系構建中,經常會得到不能完整表示企業形象的模糊標簽,而較少有學者關注模糊標簽的規范表示。本文設計了一種模糊標簽延深算法(Fuzzy Label Deepening Algorithm),在基于多源信息融合和專業領域詞庫的多特征選擇上,使用BiLSTM 網絡并添加注意力機制,得到企業的延深標簽信息。模糊標簽延深結構如圖5 所示。
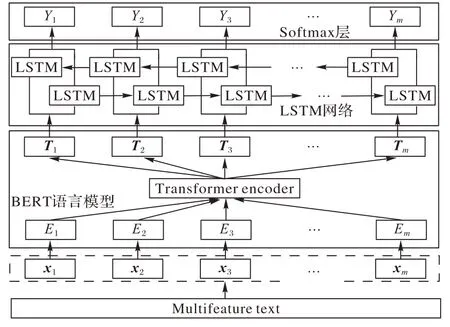
圖5 模糊標簽延深結構Fig.5 Fuzzy label deepening structure
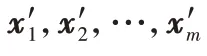
算法1 模糊標簽延深算法。
輸入 字向量特征表示x
,x
,…,x
,BiLSTM 網絡參數。輸出 模糊標簽延深序列Y
,Y
,…,Y
。待處理文本固定為統一長度L
令i
=1,依據統一長度進行向量標準化通過符號分割得到融合全文語義信息的向量表示T
,T
,…,T
通過式(1)對向量進行編碼和解碼
REPEAT
通過式(2)傳入h
和x
計算遺忘門f
值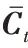
C
通過式(6)~(7)計算輸出門o
和正向輸出結果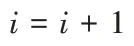
通過式(9)進行反向編碼
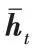
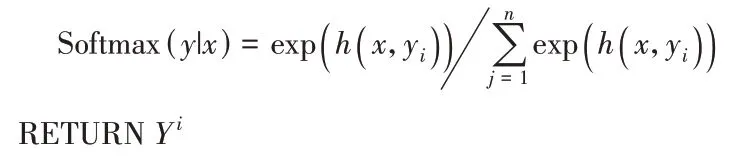
2.6 標簽延深
標簽延深是基于已獲得的模糊標簽以及構建的領域詞庫,使用綜合提取算法對多特征信息提取關鍵詞匯。在關鍵詞提取任務中,不同算法的提取結果存在明顯差異,因此綜合提取算法能夠彌補單一算法的不足。本文使用基于統計特征的TF-IDF 算法、基于詞圖模型的TextRank 算法和基于主題的LDA 主題模型算法建立標簽延深模型;然后,依據需求定義單個標簽提取數量N
,讓待延深文本依次傳入三種算法抽取標簽,從不同維度獲取企業核心詞匯;最后,對抽取到的標簽進行劃分,相同標簽作為標簽延深的重要標簽,其余標簽作為重要的補充標簽,實現EPPLD 建模,其中label_number
≤3N
,label_number
為標簽延深后的標簽數量。通過多算法綜合提取,能夠發現文本的特征與聯系,使得整個模型獲得更好的效果。同時綜合提取算法主要面向企業經營范圍和專利等信息進行提取,這些信息一般具有較強的企業特點和興趣偏好,因此延深后的標簽可以避免模糊標簽情況出現。3 實驗與結果分析
3.1 實驗數據
實驗數據本文使用行業網站收集的企業文本作為實驗數據,由于沒有現有的公共數據集,本文構建了企業網絡文本數據集,數據集公開地址:https://github.com/Dingxingshuo/Corporate-portrait,其中包含244 890 篇企業文檔,共1 682 萬個漢字。使用2 880 條中英文企業領域關鍵詞進行特征擴展。將244 890 篇企業文檔以6∶2∶2 的比例分為訓練集、驗證集和測試集,數據描述如表2 所示。
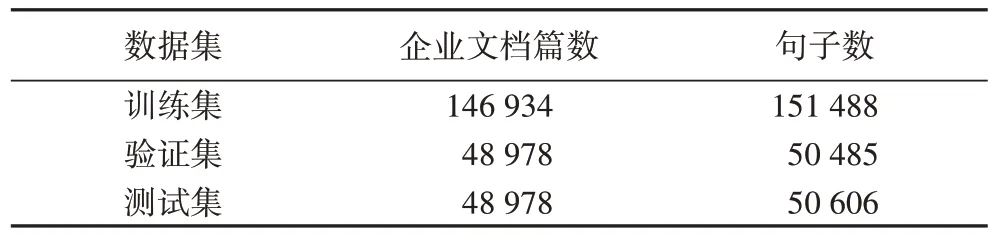
表2 實驗數據集詳細信息Tab 2 Detail information of experimental datasets
3.2 評價指標
為了驗證本模型實用性,本文使用準確率(Acc
)、精確率(P
)、召回率(R
)和F
1_
score 來評價模型效果。準確率是文本問題中最基本的評價指標;精確率是預測正確的數據量與被預測為正確的數據量之比,衡量的是查準率;召回率是預測為正確的數據量與實際類別為正確的數據量之比,衡量的是查全率;F
1_
score 是精確率和召回率的調和平均數。各個評價指標的計算公式如式(11)~(14)所示: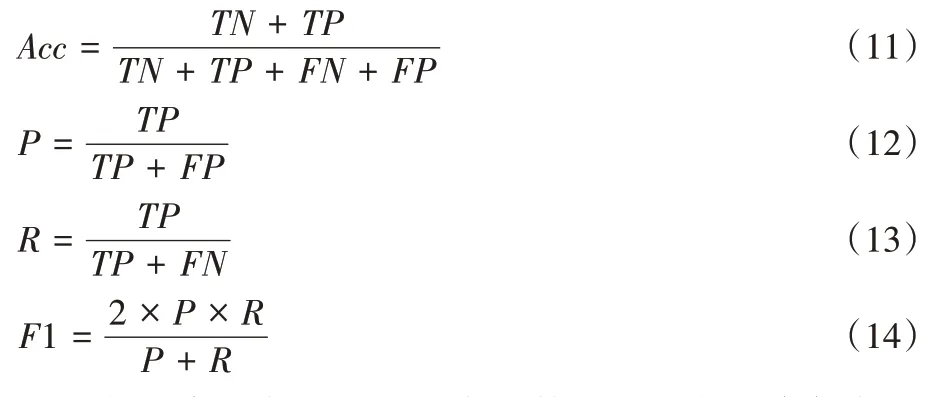
TP
表示將正類預測為正類的數量;TN
表示將負類預測為負類的數量;FP
表示將負類預測為正類的數量;FN
表示將正類預測為負類的數量。3.3 實驗與結果分析
實驗使用百分比表示本文模型的延深結果,通過對2 880 條中英文企業領域關鍵詞進行特征擴展,以BiLSTM 為基線加入特征提取算法進行測試,模型通過多特征提取隨機生成向量作為神經網絡模型的輸入,所有模型若超過1 000 batch 效果沒有提升,則提前結束模型訓練。
為了驗證模型的優越性,將本文所提EPLLD 與傳統標簽構建算法K 近鄰(K-NearestNeighbor,KNN)、樸素貝葉斯分類器(Naive Bayesian Classifier,NBC)、卷積神經網絡(Convolutional Neural Network,CNN)、Deep CNN、BiGRU(Bidirectional Gated Recurrent Unit)、RNN+CNN、BiLSTM+Attention 和BERT+Deep CNN 在企業數據集上分別進行實驗,實驗結果如表3 所示。相較于其他標簽處理的機器學習和神經網絡模型,EPLLD 的結果最好。EPLLD 的F1_score 值達到91.08%,高于其他機器學習和深度學習模型。
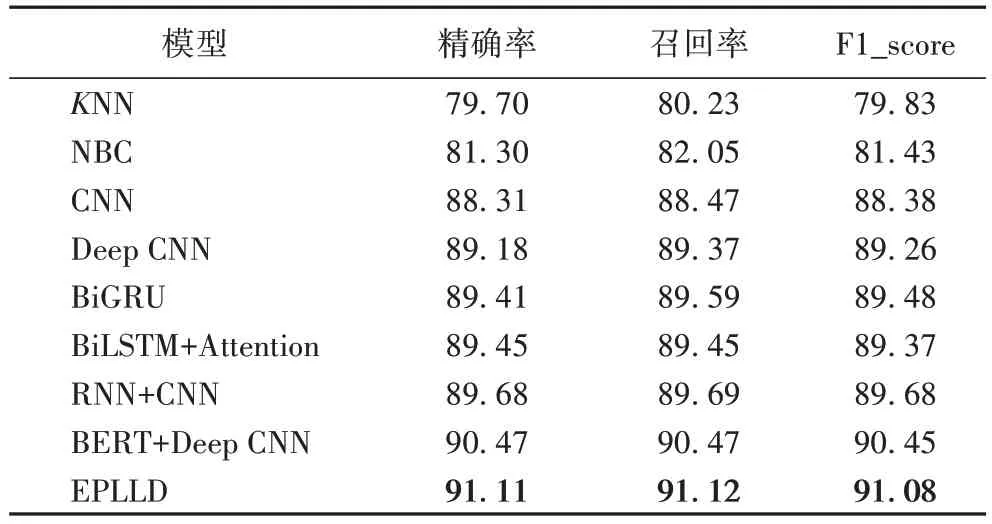
表3 對比實驗結果 單位:%Tab 3 Comparative experimental results unit:%
為直觀表示各模型優劣,挑選傳統深度學習模型使用驗證集進行迭代測試,結果如圖6 所示。由圖6 可以看出,隨著迭代次數的增加,所有模型損失值都在減小,損失值的大小表明模型訓練中的收斂情況。EPLLD 模型使用雙向Transformer 生成特征向量傳入神經網絡不僅能夠獲得字嵌入特征,還能夠發現文本的層級特征和上下文特征,因此可以在較少的迭代中實現較好的收斂效果,而其他模型在EPLLD模型收斂后損失值依舊波動較大,易出現過擬合的情況。
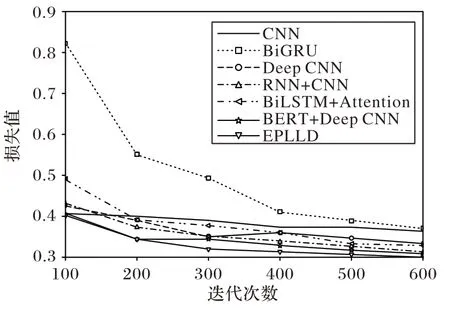
圖6 驗證集損失值變化曲線Fig.6 Validation set loss value change curve
同時,挑選不同維度的4 種模型:能夠發現局部特征的Deep CNN 模型,發現上下文特征并聚焦關鍵點的BiLSTM+Attention 模型,發現上下文特征后在池化層進行最大池化的RNN+CNN 模型,以及多特征融合的EPLLD 模型,記錄4 種模型驗證集在每輪epoch 后的準確率變化,結果如圖7 所示。由圖7 可以看出,EPLLD 從第一輪迭代開始,準確率明顯高于其他模型,且在第二輪后準確率一直穩定在90%以上。由此可見,雙向transformer 具備更強的學習能力,能夠發現長距離依賴關系和企業文本中的隱藏特征,說明EPLLD 方法對企業模糊標簽延深的有效性。

圖7 驗證集準確率變化曲線Fig.7 Validation set accuracy change curve
實驗最終使所有模型趨于平穩,學習能力達到飽和。為進一步說明這種快速收斂是由于模型的優劣,本實驗給出了訓練集的損失值變化曲線,如圖8 所示。由圖8 可以看出,訓練集損失值一直在合理范圍上下波動,因此驗證集的快速收斂不是過早陷入局部最優引起的。
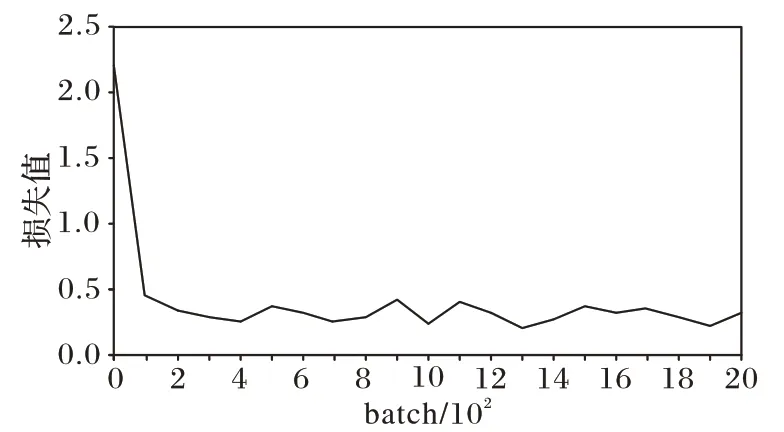
圖8 訓練集損失值變化曲線Fig.8 Training set loss value change curve
將EPLLD 與傳統數據分析處理方法進行對比,在畫像的體系建設中存在明顯差異。以連云港市H 有限公司為例,建立標簽詞云圖,結果如圖9 所示。由圖9(a)可知,在傳統的數據分析處理標簽主題中僅有工程和化工標簽較為突出,此標簽無法直觀表示企業形象,且沒有表達出最重要的批發和商貿公司的特點。由圖9(b)可知,在EPLLD 標簽主題中,企業所屬的批發業標簽最為突出,在經過多特征模糊標簽延深后獲得商貿標簽,然后使用綜合提取算法得到化工、鋼材以及工程等標簽,最后是普通標簽。因此,相較于傳統數據分析處理方法,EPLLD具有標簽層次好和概括能力強的優點。

圖9 傳統數據分析處理方法與EPLLD的標簽主題Fig.9 Label themes of traditional data analysis and processing and EPLLD
EPLLD 標簽分層延深建模和傳統分析處理方法的對比結果如表4 所示。由表4 可知,EPLLD 能夠對企業模糊標簽進行延深,形成分級表示的多特征標簽,具有標簽層次好、概括能力強的特點,同時表明EPLLD 在標簽處理和關鍵詞提取方面具有很好的效果。
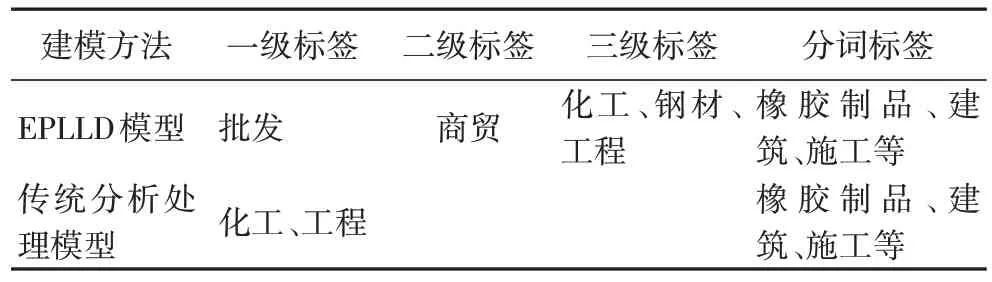
表4 標簽建模對比結果Tab 4 Label modeling comparison results
4 結語
本文所提出的基于標簽分層延深建模的企業畫像構建方法EPLLD,在分析處理標簽的同時,能夠對模糊信息建立由淺入深的標簽延深。該方法通過分析處理多維度信息來融合企業特征,采用BiLSTM 網絡完成模糊標簽延深;接著基于多源信息融合后的企業數據,通過TF-IDF、TextRank、LDA主題模型提取算法,完成標簽分層延深建模。使用企業數據集實驗,結果表明EPLLD 能有效提高企業畫像標簽建模準確率;并以連云港市H 有限公司為例,構建標簽主題來展示由淺入深的標簽建模體系。
在多特征抽取中不同的特征融合方法對后續特征選擇存在影響,因此,在標簽分層延深建模之后,如何利用特征間的關系進行特征分析,使得標簽建模具有關聯性是日后的研究重點。
