
基于場景變化的傳輸控制協議擁塞控制切換方案
2022-05-07 07:08:08賴涵光
計算機應用 2022年4期
賴涵光,李 清,江 勇*
(1.清華大學深圳國際研究生院,廣東深圳 518055;2.南方科技大學未來網絡研究院,廣東深圳 518055)
0 引言
傳輸控制協議(Transmission Control Protocol,TCP)擁塞控制是網絡傳輸的傳統問題,也是核心問題,傳統的TCP 通過調整擁塞窗口的方式來進行擁塞控制。而擁塞窗口的調整主要通過慢啟動、擁塞避免、快速重傳和快速恢復四個機制來實現,從而在避免擁塞的情況下實現吞吐量的最大化。
當前,在學術界和工業界,人工智能(Artificial Intelligence,AI)的研究與應用發展迅猛,包含機器學習、深度學習和深度強化學習等人工智能方法正越來越多地被應用于解決各種實際問題,并在人臉識別、推薦系統、語音識別、工業機器人等一系列領域取得了相當顯著的成果。
近年來,許多學者開始將人工智能方法用于TCP 擁塞控制的領域,并取得了一定的成果,但尚無法達到替代傳統方法的程度。主要原因在于,基于AI 的擁塞控制方法在不同場景下仍然存在著一定的不足。例如,在基于強化學習的擁塞控制算法中,Aurora雖然取得了較好的吞吐量但犧牲了收斂性和公平性,而Orca為了解決收斂性和強化學習的可解釋性問題,不得不在吞吐量和時延性能上作出讓步。而對于目前主流的研究方案,即測量瓶頸鏈路帶寬和時延的擁塞控制(congestion control based on measuring Bottleneck Bandwidth and Round-trip propagation time,BBR)、面向性能的擁塞控制(Performance-oriented Congestion Control,PCC)、Copa等相對輕量級基于人工智能的擁塞控制方法而言,雖然它們具備一定的可解釋性,且在一定場景下能夠實現較高的網絡性能,但普遍存在TCP 友好性的問題,同時在某些特定場景下性能表現會出現斷崖式下跌。
本文綜合已有研究方案,針對輕量級基于學習的擁塞控制算法在某些場景下性能會出現斷崖式下跌的問題,提出一個基于場景變化的傳輸控制協議擁塞控制切換方案。首先,在全場景下分析基于學習的擁塞控制算法的優缺點,著重考察它們在不同場景、維度下的性能指標;然后,提出基于場景變化的傳輸控制協議擁塞控制切換方案;最后,在網絡仿真器3(Network Simulator 3,NS3)平臺上進行仿真實驗以驗證其性能,并將實驗結果與已有方法進行對比。
1 相關工作
1.1 輕量級基于學習的擁塞控制
隨著傳統擁塞控制在吞吐量、時延、丟包率等指標上的表現越來越不符合用戶的需求,以及近年來計算機算力的提升與人工智能的重新興起,許多研究人員開始將機器學習、深度學習和強化學習等基于人工智能的方法應用到擁塞控制研究當中,亦取得了一定的成果。而這其中的主流是輕量級基于學習的擁塞控制,所謂“輕量級”,就是指這其中使用啟發式算法、效用函數、梯度下降等未涉及深度學習(包括深度強化學習)的一類擁塞控制算法,這類算法訓練時間短、成本低,因而稱其“輕”。以下簡要敘述使用該類方法的幾項研究工作。
1.1.1 PCC和PCC-Vivace
PCC 是一個直接由發送端觀測到的性能表現來決定下一時刻動作的算法。每個發送端只觀察其動作與性能表現的聯系,采用能帶來最佳性能的動作。
TCP 硬連接映射需要對網絡條件作出假設,但現實網絡狀況往往比假設復雜得多,且一旦不滿足假設,后續的動作對性能非常有害(例如窗口減半)。而PCC 使用實時數據,無任何假設,使用效用函數來描述“高吞吐量和低丟失率”。其收斂速度與TCP 相近,且速率方差更小。
下一時刻的發送速率由效用函數u
決定,u
是關于吞吐量T
和丟包率L
的函數,如式(1)所示: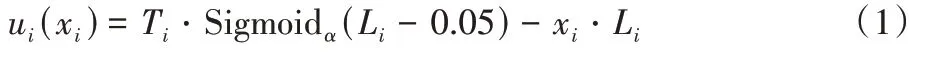
PCC 的控制算法分為以下幾種狀態:

+ε
)r
,另一個MI 嘗試(1-ε
)r
,r
為原始速率。之后速率調整回r
并等待結果。根據u
函數算出的結果,如果兩組的(1+ε
)r
都獲得較好的u
,則選擇之;(1+ε
)r
同理。如果兩組結果不同,則速率回到r
并重新進入決策狀態并嘗試更大的ε
,ε
最小值為0.01,最大值為0.05。3)速率調整狀態。決策狀態之后得到的速率r
,PCC 會以越來越大的幅度來調整之。若效用函數增大,則采用下一時刻的速率,如式(2)所示: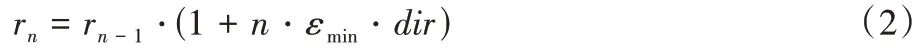
dir
表示±號。一旦效用函數變小,則采用r
并重新進入決策狀態。PCC 相較于TCP 的優點:同一個PCC 學習算法可以適應不同的情況,但TCP 不行。從基于延遲變換到基于丟包率,TCP 需要例如active queue management等復雜機制,而PCC只需要修改一行代碼而已;PCC 部署時不需要路由器支持、無新協議、不需要接收端的調整,只修改發送端,其余與TCP一致。
PCC 存在的問題主要在于效用函數的選擇:是否存在效用函數收斂到納什均衡同時TCP 友好(TCP 友好性表示該算法能夠與傳統TCP 流友好共處、公平競爭)。本文中介紹的效用函數都不包含時延,那么包含時延的效用函數是否可被證明收斂并且與默認效用函數表現一樣好?這些問題都有待解決。
針對PCC 存在的問題,該研究小組之后又發表了PCC的升級版PCC-Vivace,在新的效用函數中引入了時延:
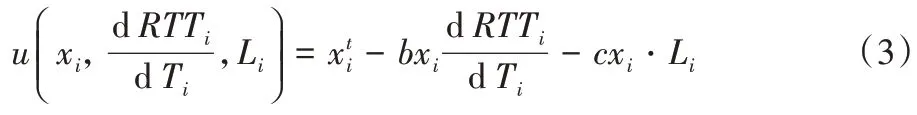
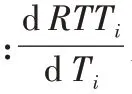
PCC-Vivace 使用了修改后的同樣是基于梯度上升的速率調節算法,并證明了其收斂性,也在實驗中驗證了其TCP友好性。
1.1.2 BBR和Copa
與傳統擁塞控制算法顯著不同的是,BBR 算法不以數據包丟失或傳輸時延增加作為識別網絡擁塞的標準,而是使用帶寬時延乘積(Bandwidth-Delay Product,BDP)作為識別指標,當網絡中的數據包總量大于BDP 時,BBR 才認為網絡出現了擁塞。因此,BBR 也被恰如其分地稱為基于擁塞的擁塞控制算法。
在網絡中可以觀察到這樣的現象:當帶寬非常大時,網絡將被填滿而導致排隊,此時網絡延遲必定非常大;反之,當網絡延遲非常小時,網絡中的數據包需要避免排隊直接轉發,此時帶寬必定會非常小。因此可以得出結論:網絡中的流不可能同時獲得非常大的鏈路帶寬和非常小的網絡延遲。根據這一結論,BBR 算法對網絡容量進行周期性的探測,對一段時間內鏈路帶寬的極大值和網絡延遲的極小值進行交替性的測量,再將它們的乘積作為擁塞窗口大小,從而就能用擁塞窗口來表征網絡容量,使擁塞的識別更加準確。
由于BBR 算法特有的測量擁塞窗口的機制,它不會像傳統擁塞控制算法那樣無限地增加擁塞窗口,也就不會用盡交換機節點的緩存,從而避免了Bufferbloat(緩沖區溢出)現象的出現,進一步就可以讓傳輸時延顯著降低。
另一方面,BBR 算法使用通過主動探測網絡容量來調節擁塞窗口的機制,此種自主調節的機制使BBR 算法可以自行控制流的發送速率。與之相反的是,傳統擁塞控制算法只完成了將擁塞窗口計算出來的工作,而將流的發送速率完全交由TCP 決定,造成的后果便是在當速率接近瓶頸鏈路帶寬時,容易因發送速率的陡增而使得數據包排隊或數據包丟失的現象產生。
BBR 算法的缺陷在于:當交換機節點的緩存較大時,BBR 的吞吐量表現可能會遜色于Cubic等相對激進的擁塞控制算法。原因是BBR 算法不會主動去占據節點的緩存,而一旦Cubic 流基于其激進的速率增加策略,長時間占據隊列緩存,則很容易導致BBR 算法在鄰近的多個周期內所測得的網絡延遲的極小值增大,進而導致BBR 流的吞吐量減小。
Copa 算法的整體思路與BBR 類似,都是以端系統采集得到的RTT 信息推測網絡狀態從而進行速率調整。相較于BBR 其優勢在于對鏈路中隊列長度的主動且細粒度的控制,而非基于BDP 的主動排空。
Copa 的核心思想在于,當一個流在鏈路中產生排隊延遲時,給定一個當前擁塞狀態下的目標速率λ
,并控制當前速率在該目標上下的一定范圍內進行波動。而為了使流在競爭時能同時滿足高吞吐量和低延遲,文獻[7]對第i
條流給出了目標函數如式(4)所示:
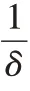

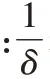
1.1.3 Remy
Winstein 等所探究的問題是:TCP 擁塞控制本身是一個動態的過程,每一步的選擇都可能造成后面所有反饋的不同,如何能判定一個擁塞控制是“表現得最好”的?給出的解決辦法是:既然人看不出好不好,那就用機器預先算出給定網絡里每個決策可能造成的所有后果,選最終評分最高的,將其一路過來的所有決策用來生成一個擁塞控制算法,那肯定就是“表現得最好的”。
因此,Winstein 等設計了Remy 算法來算出不同參數的擁塞控制策略產生的結果,細化較優結果的參數并進行優化,經過幾輪迭代后,用生成最優結果的所有決策生成最優擁塞控制(Congestion Control,CC),就是RemyCC。
Remy 的輸入包括:網絡的參數,即瓶頸鏈路的速度、網絡路徑傳輸時延和多路復用的程度;發送端的流量發送模型,Remy 建模時把流量變化過程看作很多對獨立的發送-接收端鏈路隨機開/關的過程,每條鏈路開的持續時間遵循特定的分布;目標函數,算法的總得分可以通過計算每條流的分數之和得到,鏈路中不同的數據流獲得的分數為:

x
是該流的吞吐量,α
表示公平性的重要程度。在Remy 算法中,公平性被定義為:
y
表示平均RTT;U
(y
)是RTT 的效用函數;系數δ
是平衡系數,作用是改變Remy 算法在吞吐量和時延上的側重點。文獻[7]把發送端觀測到的指標用三個參數來表示,統稱memory:ack_ewma 表示確認字符(ACKnowledge character,ACK)的到達間隔的指數加權移動平均值;send_ewma 表示ACK 的發送間隔的指數加權移動平均值;rtt_ratio 表示最新RTT 除以最小RTT。
把發送端的action(控制擁塞窗口大小)也用三個參數來表示:m
≥0 表示擁塞窗口的倍數;b
表示擁塞窗口的增量;r
>0 表示連續發送的最小間隔時間。把一條memory 映射到一條action 的過程稱為一條rule。一個完整的擁塞控制策略由很多條rule 構成,即一張rule table。Remy 的自動搜索過程就是用貪心算法建立和優化這張rule table 的過程。
以下簡要描述Remy 算法的主要過程:首先,通過迭代修正action,找到最合適的將memory 映射到action 的方法,即最合適的rule;其次,將常用的rule 和不常用的rule 進行區分;在合理的統計與分類之后,可以生成一個完整的rule table,即一張統計了所有映射方式的表格,表格中每個rule 的action 都是基于當前網絡狀態,對擁塞窗口大小進行最優方向上的調整。同時,在最常用的rule 附近,劃分粒度非常細,而較不常用的rule 其劃分粒度則較粗糙。
Remy 算法存在的問題:用Remy 搜索找到的最佳RemyCC,當把它用于和生成RemyCC 時使用的網絡相似的網絡上時,效果非常不錯;一旦用于不同類型網絡時,效果就不太理想了。這是因為RemyCC 只能預測它所見過的網絡的最優決策,一旦遇到沒見過的網絡,RemyCC 仍使用本身的預見方法來應對,就會顯得不夠靈活。
1.2 基于強化學習的擁塞控制
隨著強化學習(Reinforcement Learning)在游戲博弈(圍棋、星際爭霸)、機器人控制等領域取得卓越成就,有學者開始將強化學習用于網絡擁塞控制的研究。近年來,深度強化學 習(Deep Reinforcement Learning),包 含DQN(Deep Q Network)、DDPG(Deep Deterministic Policy Gradient)等算法的出現也為強化學習用于擁塞控制提供了強有力的理論武器。
強化學習用于擁塞控制方面有其先天優勢,首先深度強化學習不必依賴于模型,這就增強了其在不可預測行為的復雜網絡中的適用性;其次它可以處理復雜的狀態空間,這與實際網絡的情況十分吻合。
但是,使用強化學習算法也有其缺點,普遍的共性就是訓練時間太長,這會導致擁塞控制的開銷過大,以至于無法被廣泛應用于網絡中。此外,在使用深度強化學習這類復雜算法進行擁塞控制時,其收斂性較難保證。
以下簡要介紹幾項基于強化學習進行網絡擁塞控制的工作。
1.2.1 Aurora
Aurora是最早使用強化學習方法進行網絡擁塞控制的研究之一,盡管存在著一些不足,其理念仍是具有開創性的。
文獻[3]根據擁塞控制的特點設計了強化學習智能體的動作與狀態。由于發送端是通過調整發送速率來適應網絡擁塞狀況,因此智能體的動作也就是發送端的發送速率。狀態空間則由三維向量組成,每個向量v
包含延遲梯度、延遲比率、發送比率三個維度。其中,延遲梯度指的是網絡延遲關于時間的導數,延遲比率表示當前MI 的平均延遲與此前MI 中觀測到的最小平均延遲之比,發送比率表示發送端發送的數據包數量與接收端接收到的數據包數量之比。同時,智能體在決定下一時刻的動作時需要根據過去一段時間的向量來觀測網絡變化的趨勢,因此t
時刻的狀態空間s
為: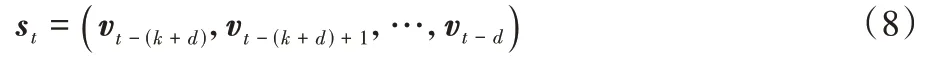
k
是常數,代表過去這段時間的長度;d
表示選擇從發送速率到收集到結果的這一小段延時。在k
值的選擇上,文獻[3]以MI 為單位進行實驗,結果表明,除了在只有1 個MI 時算法無法得出理想的獎賞值,其余情況即當采用2 個及以上MI 的訓練時長時,算法都能達到相似的理想獎賞值。Aurora 的獎賞函數設計如下:
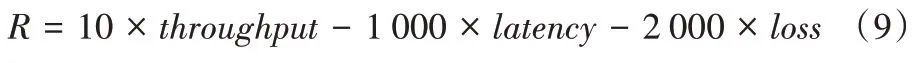
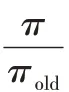
π
得出當前時刻的動作a
(發送速率的增加或減少),從而計算出當前時刻的發送速率x
: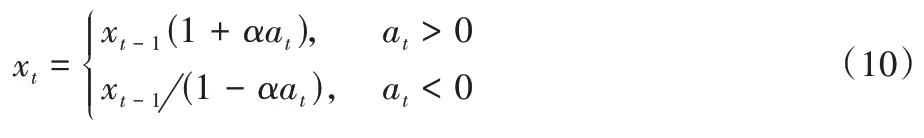
α
是常數,用于減小速率的波動。Aurora 存在的問題主要有:1)公平性差,在與TCP 流進行競爭時,會急劇限制TCP 流的吞吐量,導致算法的TCP 友好性不佳,主要原因在于Aurora 在訓練時會主動學習出偶爾丟包的能力,以讓TCP 吞吐量下降從而釋放鏈路帶寬;2)算法的收斂性較差,即收斂時間過長。
1.2.2 Orca
基于學習的擁塞控制算法適應復雜網絡環境的能力更強,因為不需要將環境與動作進行硬編碼。但文獻[4]認為,單純的基于學習的擁塞控制也有以下問題:1)在未知的網絡條件下有過度(Aurora、PCC-Vivace)或過少(Indigo、Remy)利用帶寬的問題;2)收斂到錯誤的值(Indigo、Remy)或根本不收斂(Aurora);3)開銷即中央處理器(Central Processing Unit,CPU)占用率非常高。
因此,文獻[4]設計了一個實用的擁塞控制算法框架Orca,將傳統擁塞控制的設計與深度強化學習技術結合起來。使用強化學習的原因:網絡擁塞控制作為一個順序的決策制定過程,與強化學習的特性非常吻合。
具體地,Orca 在底層使用傳統TCP 調節擁塞窗口的邏輯(文獻[4]中選用Cubic),上層的強化學習智能體通過監控獲取網絡狀態和底層傳來的擁塞窗口變化,計算出新的擁塞窗口。這樣做的好處有:1)能夠持續探測帶寬并收斂到正確的值;2)因為底層使用傳統TCP,其動作調節更具可預測性(相對于深度學習的不可解釋性而言);3)能夠以更小的開銷,即更低的CPU 占用率來達到既定目標;4)相較于其他單純基于強化學習的擁塞控制算法,其訓練速度更快。
Orca 的獎賞函數設計來源于Giessler 等提出的Power指標,Gail 等證明,當Power=Throughput/Delay
取得最大值時,網絡擁塞狀況達到最優,因而Power
也被廣泛應用于衡量網絡擁塞的指標,Orca 根據這一指標得出式(11)~(13)所示的獎賞:
ζ
是吞吐量和丟包率的平衡系數,代表二者對總獎賞的影響程度。同時,由于TCP 調節擁塞窗口具有連續的動作空間,Orca 為了減少強化學習中智能體的動作空間,設計新的cwnd
來代替底層TCP 的擁塞窗口cwnd
,并通過式(12)~(14),使得算法可以通過調節α
來調節cwnd
:
π
在當前狀態s
下給出動作a
,觀測到獎賞r
和新狀態s′
,并將這一經驗(s
,a
,r
,s′
)存儲到Replay Memory 中;Learner 負責更新神經網絡模型,每一個迭代中它從Replay Memory 中隨機抽取一組經驗樣本,計算其梯度并更新TD3 算法中的參數。Actor 和Learner 的工作在這里是異步進行的,如此則Learner 對模型的更新不會受阻于Actor(相對于之前的Actor-Critic 架構而言)。實際訓練中,將多個Actor 放置于不同的物理服務器中以觀測不同的環境,同時將它們連接到一個中心化的Learner,并將Replay Memory 與Learner 放置于同一臺物理機上。2 全場景性能分析
本章主要對現有較流行的幾種輕量級基于學習的擁塞控制方案在各種場景下的性能進行了測試與結果對比。對照傳統擁塞控制方法,分析出各場景下性能較優的擁塞控制方案。
2.1 實驗設置與參數
2.1.1 實驗設置
本文實驗在開源仿真模擬器NS3 平臺上進行,在多種帶寬、延遲、隨機丟包率的場景下,比較吞吐量、時延、公平性、TCP 友好性等性能指標。實驗在DELL ECM PowerEdge R840服務器上運行,其CPU 為Intel Xeon Platinum 8168。
實驗拓撲為端到端拓撲,在指定的鏈路帶寬和網絡延遲下,由發送端向接收端發送一到多條流。默認的數據包大小為100 b。實驗運行時長為300 s。
2.1.2 實驗參數
實驗中使用四種已知的擁塞控制方法,包括三種輕量級基于學習的擁塞控制(BBR、Copa、PCC-Vivace)和作為對比的傳統擁塞控制方法Cubic。
實驗中使用的網絡帶寬有1 Mb/s、5 Mb/s、20 Mb/s、100 Mb/s、500 Mb/s;網絡延遲的設定有1 ms、10 ms、100 ms、500 ms;實驗中使用四種不同的隨機丟包率設定:0%、0.1%、0.5%、1%。
2.2 性能分析示例
以下各以一種場景為例,展示考察指標分別為吞吐量、時延、公平性、TCP 友好性時的性能測試結果,并進行分析。
2.2.1 平均吞吐量與時延
表1 展示了鏈路帶寬仍為5 Mb/s,網絡延遲100 ms 時各擁塞控制算法的平均吞吐量與平均時延。在該場景下,BBR的平均吞吐量最高,達到了4.87 Mb/s,但相較于另外三者并無明顯優勢,四者的平均吞吐值非常接近。而在時延方面,時延最高者是Cubic,其時延顯著高出其他三者,比時延最低的Copa 算法高出了接近30%,BBR 的時延僅次于Cubic,PCC-Vivace 的時延達到了113 ms;Copa 的平均時延仍最低,約為106 ms。

表1 網絡帶寬為5 Mb/s 和網絡延遲為100 ms時的平均吞吐量與平均時延Tab 1 Average throughput and average delay with network bandwidth of 5 Mb/s and network delay of 100 ms
從實驗結果來看,BBR 在絕大多數場景下的平均吞吐量都是領先的,原因在于BBR 的帶寬探測機制,可以充分利用鏈路中的富余帶寬;隨著隨機丟包率的增加,PCC-Vivace 的吞吐量不斷下降,原因是PCC-Vivace 在PCC 原始版本的基礎上引入了RTT 梯度來表征時延,但對丟包率的系數設置未作改動,因此在隨機丟包增加的情況下,為了達到低時延,勢必要犧牲吞吐量;Copa 的平均吞吐量在隨機丟包0%、0.1%、0.5%時幾乎都是最低的;Cubic 的吞吐量較高,總體而言僅次于BBR,但在隨機丟包率增加之后,Cubic 的吞吐量急劇下降,原因是Cubic 是基于丟包的擁塞控制,隨機丟包會顯著影響其對網絡狀況的判斷從而導致性能的下降。
時延方面,BBR 在幾乎所有場景下時延都是最高的;PCC-Vivace 在絕大多數時候都是時延最低的,可見效用函數中RTT 梯度的引入是卓有成效的;Cubic 的時延在大多數情況下都較高,反而是在隨機丟包率達到1%時,時延明顯下降,可能的原因是Cubic 是基于丟包的擁塞控制方法,丟包率對其時延的影響遠大于對其他方案的影響;Copa 的時延相對較低,但在均值附近震蕩的幅度大。
2.2.2 單一方法多條流的公平性
為了測試同一方案在多條流共存時分享鏈路帶寬的公平性,實驗中在0 s、40 s、80 s 時分別發送一條流,考察這三條流最終是否能夠均分鏈路帶寬,以及均分帶寬并達到收斂的時間長短。
以下以鏈路帶寬為3 Mb/s,網絡延遲為100 ms,隨機丟包率0.1%為例,簡要展示各方案公平性的測試結果。
圖1 展示了四種擁塞控制算法的公平性。從圖1 中可以看到:BBR(圖1(a))的三條流帶寬差距較大,無法實現公平性;Copa(圖1(c))則實現了公平性;PCC-Vivace(圖1(b))在大部分時刻仍能保持公平,個別時段帶寬的極差能達到0.8 Mb/s;Cubic(圖1(d))三條流的帶寬能夠收斂到均值,但帶寬的波動幅度比Copa 還要高,在均值上下0.25 Mb/s波動。
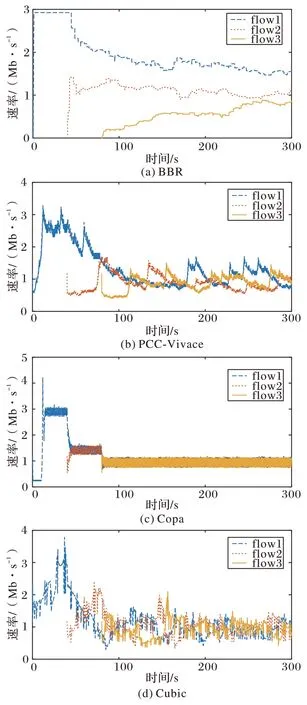
圖1 隨機丟包率0.1%時各方案的公平性Fig.1 Fairness of each scheme with random packet loss rate of 0.1%
2.2.3 TCP友好性
TCP 友好性,即新的擁塞控制方法在與現有的TCP 擁塞控制方案共存時的性能表現,著重關注其是否擠占TCP 流的帶寬,能否與TCP 友好共存。因此,本文通過測試不同擁塞控制方法在與Cubic 競爭時的吞吐量表現來表征其TCP 友好性。
以下以網絡延遲1 ms,隨機丟包率0%為例,擁塞控制算法以BBR 為例,簡要展示其TCP 友好性隨帶寬變化的結果。
如圖2 所示,在隨機丟包為0%時,在網絡延遲為1 ms 的狀況下,在帶寬為1 Mb/s 時,BBR 搶占Cubic 帶寬的情況非常嚴重,二者的平均帶寬之比約為3∶1,此時BBR 的TCP 友好性較差。而在帶寬為5 Mb/s、20 Mb/s、100 Mb/s 時,BBR 與Cubic 能夠在鏈路中友好共存,二者的平均吞吐量之比小于等于1∶1,也就表明BBR 的TCP 友好性較優。
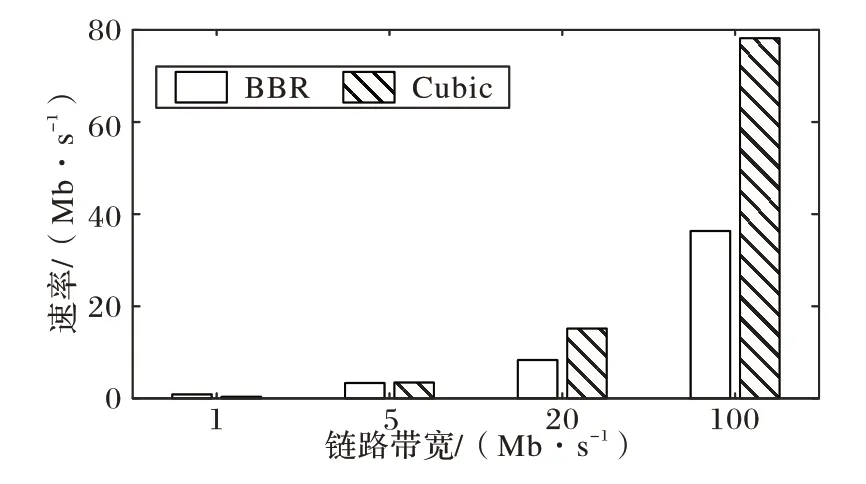
圖2 隨機丟包率0%時BBR的TCP友好性Fig.2 TCP friendliness of BBR with random packet loss rate of 0%
2.3 性能分析總結
表2~5 簡要總結了各類場景下,根據所考察的性能指標的不同,以三種輕量級基于學習的擁塞控制算法(BBR、PCCVivace、Copa)及作為對比的Cubic 為備選項,應選取何種擁塞控制算法,方能在指定場景下達到網絡性能的相對最優。
表2 展示了當考察的性能指標為吞吐量時,各場景下所應采用的最優擁塞控制算法。

表2 考察吞吐量時的最優擁塞控制算法Tab 2 Optimal congestion control algorithm when focusing on throughput
表3 展示了各場景下所應采用的能使時延最低的擁塞控制算法。其中隨機丟包率為0%時列舉了所有可能的鏈路帶寬和網絡延遲的參數,而隨機丟包率為0.1%、0.5%、1%時則以網絡延遲10 ms 為代表,列舉了所有可能的鏈路帶寬參數。
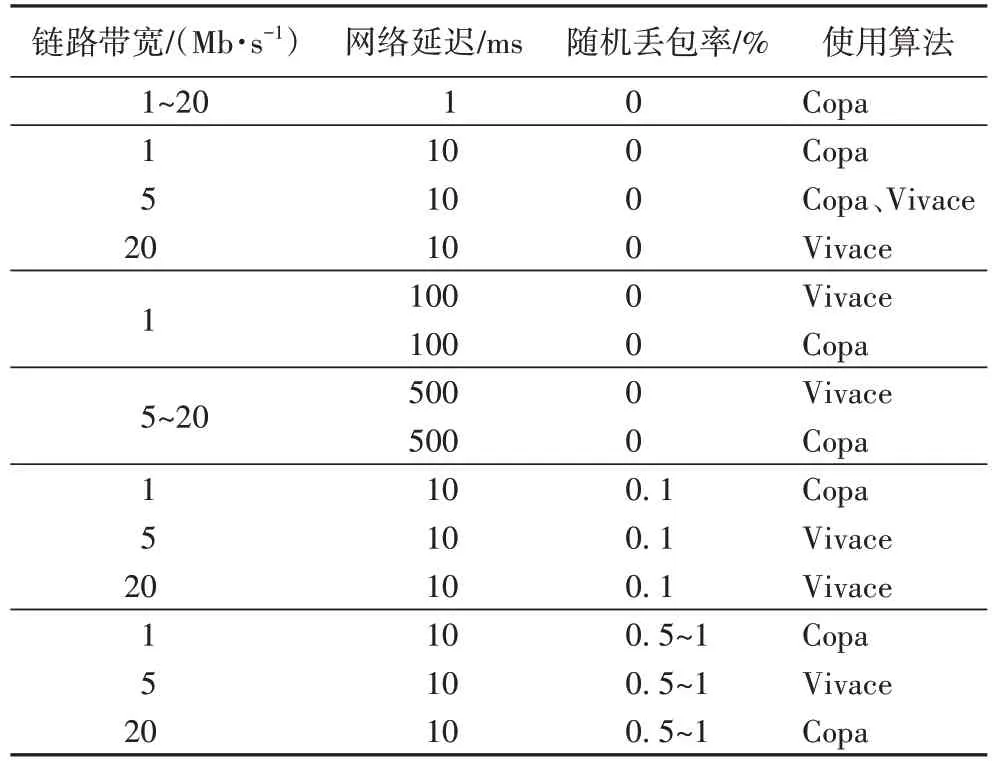
表3 考察時延時的最優擁塞控制算法Tab 3 Optimal congestion control algorithm when focusing on delay
表4 展示了當考察的性能為公平性,各場景下所應采用的擁塞控制算法。其中,網絡延遲以100 ms 為代表,列舉了所有的鏈路帶寬和隨機丟包率的可能參數,其他網絡延遲的情況下,最優擁塞控制算法的選擇與100 ms 幾乎相同。

表4 考察公平性時的最優擁塞控制算法Tab 4 Optimal congestion control algorithm when focusing on fairness
表5 展示了各場景下所應采用的能使TCP 友好性最優的擁塞控制算法。其中網絡延遲以1 ms 為代表,列舉了所有鏈路帶寬和隨機丟包率的可能參數。
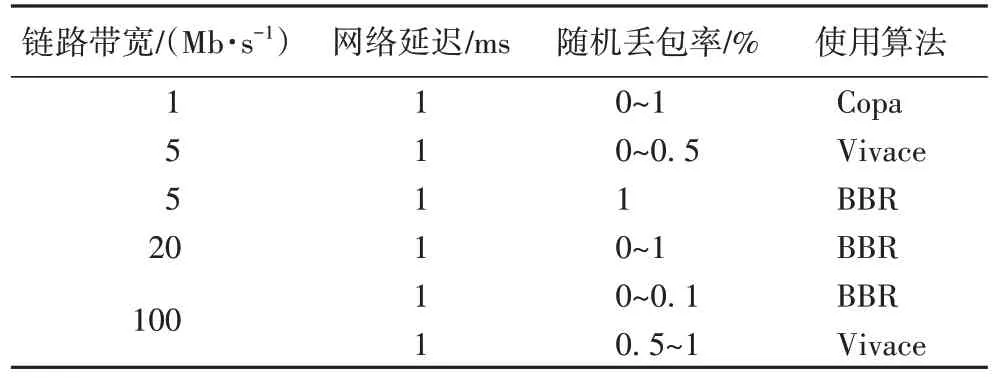
表5 考察TCP友好性時的最優擁塞控制算法Tab 5 Optimal congestion control algorithm when focusing on TCP friendliness
3 本文方案
3.1 設計動機與總覽
實際網絡環境中,不同應用場景的環境參數差異非常大。例如,在廣域網中,網絡帶寬在100 Mb/s 量級,延遲在40 ms 左右;衛星網絡的帶寬則只有10 Mb/s 以內,延遲則達到了500 ms;而數據中心的帶寬通常達到了100 Gb/s 以上,而延遲則只有1 ms 級別。同時,即使在同一應用下,網絡環境參數也可能發生顯著的變化。那么,在網絡環境不斷變化時,如果仍只使用單一的擁塞控制方法,勢必網絡的性能,例如吞吐量、時延等,會受到極大的影響,因此,必須設計一個能夠對網絡環境變化進行適應的擁塞控制方案,針對特定的性能指標,能夠比原來使用單一擁塞控制方法時有明顯的優勢。
基于此前章節的分析,各種擁塞控制算法在不同場景下各有優劣,尤其在極端條件下這樣的優缺點體現得更為顯著,因此本文設計一個根據場景來切換擁塞控制方法的方案。具體地,本文通過對場景指標(帶寬、網絡延遲、隨機丟包率)的識別,選擇當前場景下表現較好的擁塞控制方法,而在網絡環境發生顯著變化時,切換到其他備選的擁塞控制方法,以期實現總體性能的優化;并且,方案還應考慮與鏈路中的其他流尤其是傳統TCP 流友好的共存,根據這一指標對方案進行相應的調整,在兼顧TCP 友好性的情況下實現吞吐量最大化、時延最小化。
3.2 根據環境指標變化量觸發場景變換
3.2.1 方案框架
在實際網絡環境中,各項環境指標是不斷變化的,并且各項指標的變化范圍是連續值而非離散值。然而,不能將無數個連續的參數值視為無數個場景,因此,必須要對連續的參數值進行一定的離散化,當環境參數在某個固定的范圍內波動時,將其視為同一個場景,而一旦波動超出這個指定的范圍,則將其識別為另一個場景,并由此觸發擁塞控制方案的切換。
實踐中,本文在此前的100 多種實驗場景的基礎上,為每一個場景的鏈路帶寬和網絡延遲設定一個連續的波動范圍,當實際網絡的帶寬與延遲落在范圍內時,將其識別為特定的場景,而當系統監測到實時的帶寬或延遲超出了指定范圍時,根據其所屬的新的范圍,識別得到下一個場景,并觸發擁塞控制方法的切換。
對于實時的帶寬和延遲值所應落在的范圍,以帶寬為例,基于前述實驗中各帶寬值正好分別間隔約5 倍,考慮將帶寬值取以5 為底的對數,當實時帶寬落在某兩個前述實驗帶寬值的范圍內時,若其超出前一帶寬值在一定范圍內,則判定為前一帶寬值所對應的場景,否則判定為后一帶寬值所對應的場景。數學表達式如下:將實時帶寬設為B
,前述實驗的離散帶寬值為B
,B
,…,B
,而B
實際落在了B
與B
之間,即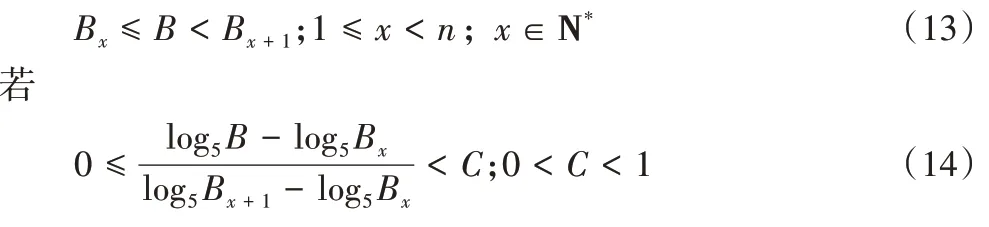
則令

否則有

C
是常數,表示變化的幅度。網絡延遲的處理方法與帶寬相同,但需要將式(14)中以5 為底的對數改為以10 為底的對數。擁塞控制決策方式如算法1 所示。算法1 擁塞控制算法決策流程。
輸入 實時鏈路帶寬B
,實時網絡延遲D
,實時隨機丟包率L
,閾值C
,帶寬檔位數n
。輸出 決策后的擁塞控制算法。

C
和決策檔位數n
輸入擁塞控制決策模塊。擁塞控制決策模塊根據算法1 求出下一時刻的擁塞控制算法,傳給流產生模塊。流產生模塊根據新的擁塞控制算法產生流,并將吞吐量和時延實時回報給系統。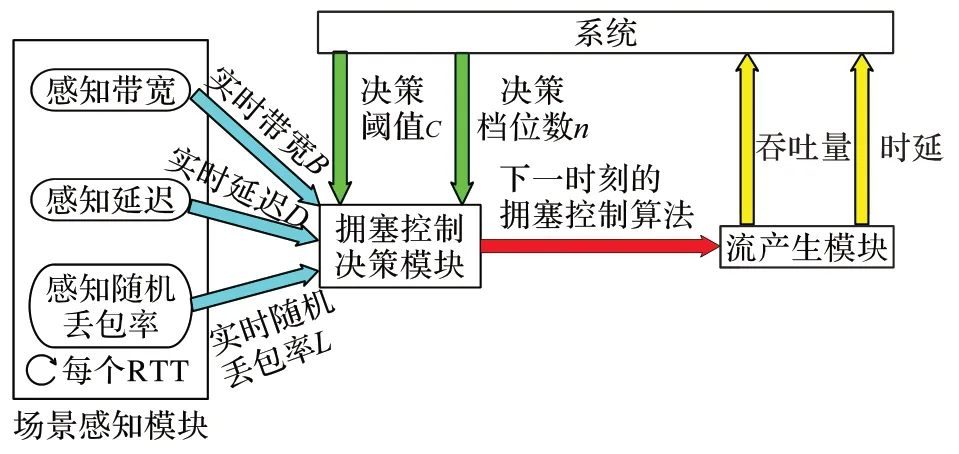
圖3 方案架構Fig.3 Scheme architecture
3.2.2 實驗設置與結果分析
實驗總時長為500 s。設置初始的鏈路帶寬和網絡延遲,并設置帶寬的變化范圍在1 Mb/s~100 Mb/s,延遲的變化范圍為1 ms~500 ms,隨機丟包率的變化范圍為0%~1%。實驗中設置對照組與實驗組,對照組一直使用初始鏈路帶寬和網絡延遲下的最優擁塞控制方法(以下稱為原方案),實驗組則根據系統實時監測到的當前的鏈路帶寬與網絡延遲,確定其所落在的范圍來決定所應切換的擁塞控制算法。
具體地,本文進行3 組實驗,實驗時長均為500 s,每組實驗除開始和結束的時刻外,隨機生成4 個時刻,當實驗進行到這些時刻時,網絡環境參數即帶寬、延遲和丟包率發生隨機的改變,模擬實際網絡環境的變化。3 組實驗起始的鏈路帶寬都為5 Mb/s,網絡延遲都為10 ms,隨機丟包率都為0%。在以吞吐量為考察指標時,對照組全程使用Copa 作為擁塞控制算法,而實驗組初始狀態使用Copa,其后根據網絡環境的變化自行切換擁塞控制算法。若以時延為考察指標,則對照組應全程使用PCC-Vivace,實驗組同理,初始狀態使用PCC-Vivace,之后根據環境進行切換。實驗中取式(14)中的常數C
為0.5。實際實驗過程中,本文對于3 組實驗分別都在0 s~500 s隨機生成4 個時刻t
、t
、t
、t
,在這些時刻,網絡環境即鏈路帶寬和網絡延遲發生隨機變化,變化的情況見表6。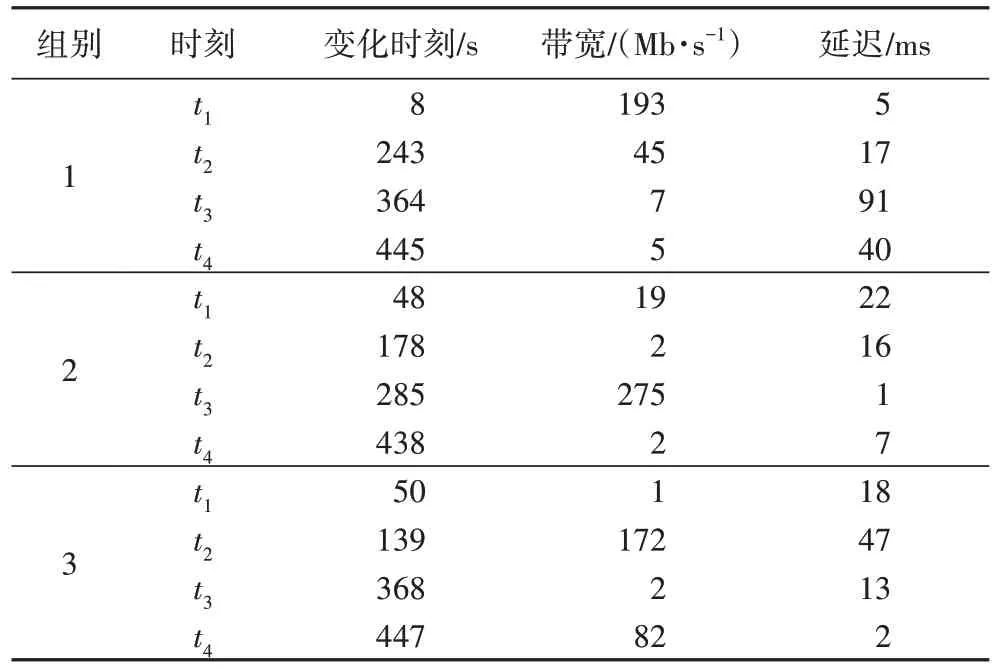
表6 三組實驗隨機產生的參數Tab 6 Randomly generated parameters in 3 sets of experiments
由表6 和算法1,當考察指標分別為吞吐量和時延時,得到在4 個隨機時刻切換到的擁塞控制算法,如表7。
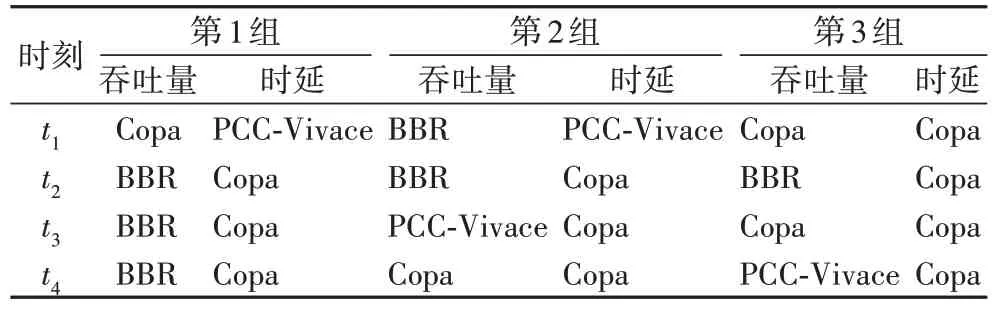
表7 四個隨機時刻下3組實驗根據環境參數求得的擁塞控制算法Tab 7 Obtained congestion control algorithm based on environmental parameters at 4 random moments in 3 sets of experiments
根據以上隨機生成的環境參數和求得應切換的擁塞控制算法,運行實驗后得到的結果如下。
圖4(a)是第1 組實驗以吞吐量為性能指標的實驗結果。在8 s、243 s、364 s、445 s 時網絡發生變化。從實驗結果可以得到,8 s~243 s 這一過程中由于擁塞控制算法沒有改變,因此吞吐量沒有增加。而在243 s~364 s 時,擁塞控制算法切換為BBR,此過程中本文方案的平均吞吐為44.06 Mb/s,比原方案的43.75 Mb/s 高出了0.7%。此后,在364 s~445 s 這個過程中,本文方案的平均吞吐量達到了6.793 Mb/s,高出原方案的6.681 Mb/s 達16.8%。而在445 s 到實驗結束時,本文方案同樣取得了更高的平均吞吐量,為4.88 Mb/s,而原方案為4.762 Mb/s。
時延如圖4(b)所示,從243 s~364 s 這個過程中,本文方案的平均時延為17.76 ms,比原方案20.73 ms 顯著降低了14.3%。此外,在445 s~500 s 這個過程中,本文方案的平均時延也比原方案低了2.01 ms,降幅達4.2%。
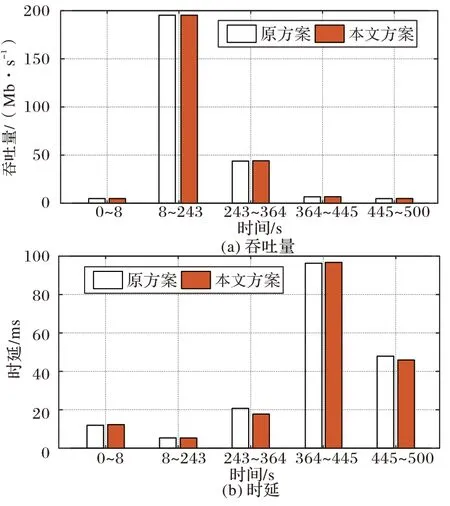
圖4 第1組實驗中,原方案與本文方案的平均吞吐量和平均時延比較Fig.4 Comparison of average throughput and average delay between original and proposed schemes in experiment 1
圖5(a)是第2 組實驗以吞吐量為性能指標的實驗結果。從實驗結果中可以看到,基于場景切換的擁塞控制方案在0 s~178 s 沒有顯著的優勢,但從第178 秒開始取得比原方案更高的吞吐量,尤其是從285 s~438 s 時,本文方案328.9 Mb/s的平均吞吐量比原方案的247.8 Mb/s 高出了32.7%。
圖5(b)是第2 組實驗以時延為性能指標的實驗結果。可以觀察到,在178 s~285 s 時,本文方案比原方案的平均時延略增加了10%。但在438 s~500 s 時,基于場景切換的擁塞控制方案的時延有顯著降低,從原來的78.3 ms 降為21.18 ms,降幅多達73%。
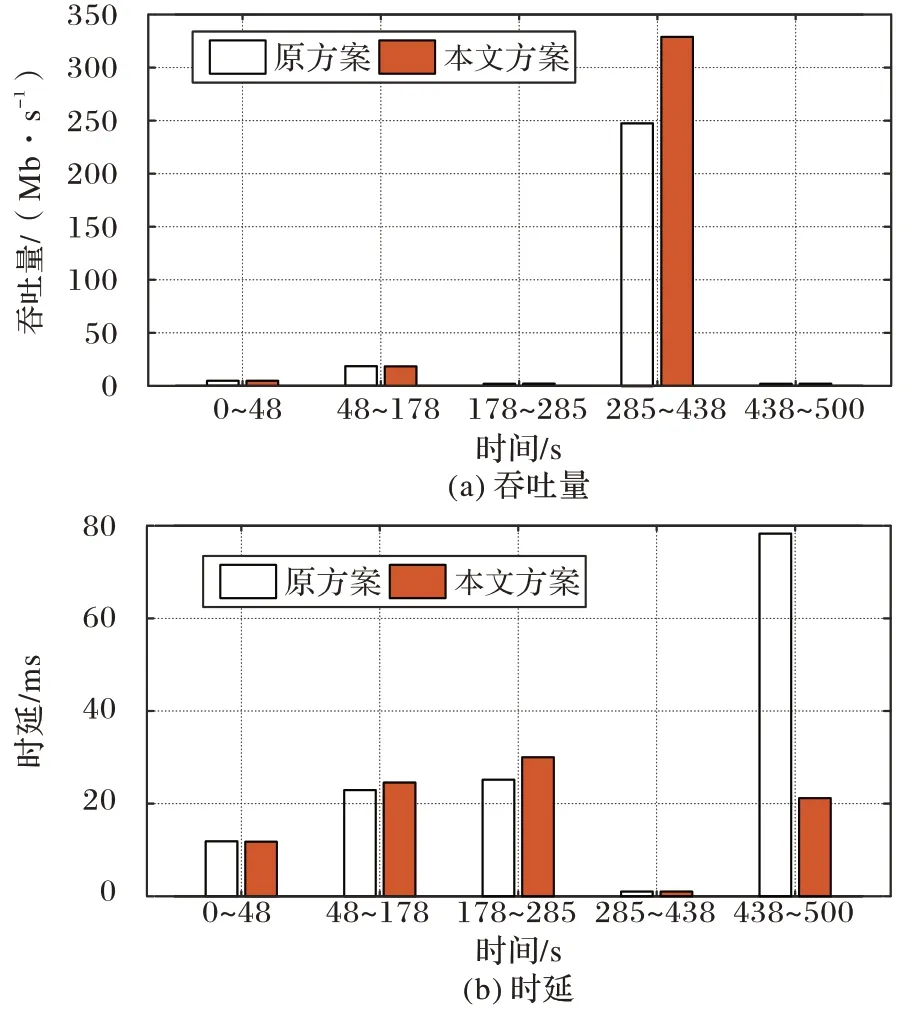
圖5 第2組實驗中,原方案與本文方案的平均吞吐量和平均時延比較Fig.5 Comparison of average throughput and average delay between original and proposed schemes in experiment 2
如圖6(a)所示,在139 s~368 s 這個過程中,本文方案切換到的BBR 取得了167.3 Mb/s 的平均吞吐量,比原方案的161.7 Mb/s 高出了3.5%。但從第447 秒到實驗結束的過程中,本文方案使用的PCC-Vivace 的平均吞吐量比原方案略低了8 Mb/s。
如圖6(b)所示,基于場景變化的本文方案50 s~447 s 的時延都有顯著降低,其中50 s~139 s 這一過程降低的幅度最大,從61.48 ms 降為44.55 ms,降幅達到了27.5%。在139 s~368 s 以及368 s~447 s 的時延降低量分別有10.79 ms 和3.62 ms,降幅分別為18.7%和11.3%。
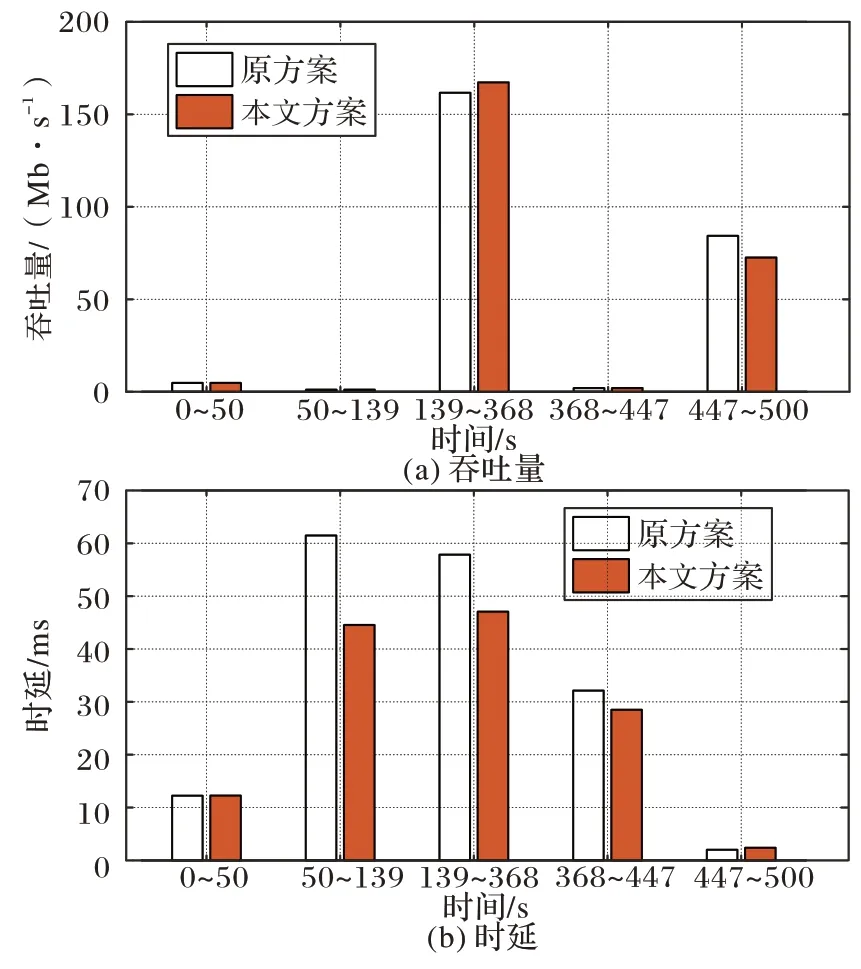
圖6 第3組實驗中,原方案與本文方案的平均吞吐量和平均時延比較Fig.6 Comparison of average throughput and average delay between original and proposed schemes in experiment 3
從以上實驗中可以得出清晰的結論:在網絡環境隨機變化的情況下,相較于使用單一擁塞控制方案,基于場景變化的擁塞控制切換方案在吞吐量和時延上都能取得明顯的性能優勢,總吞吐量增幅達到5%以上,總時延降幅達到10%以上。
4 結語
本文的工作主要分為兩部分:第一部分,對網絡環境參數如鏈路帶寬、網絡延遲和隨機丟包率等通過枚舉組合出多種網絡場景,在這些場景下進行大量的仿真實驗,得到已有的輕量級基于學習的擁塞控制方案在各場景下的性能表現,性能指標包括方案的吞吐量與時延,同時也考慮方案的公平性與TCP 友好性,并對以上性能表現進行比較與總結;第二部分在第一部分的基礎上,提出了一個基于場景變化的擁塞控制切換方案,從固定切換周期單項環境參數的變化、多項環境參數的變化,到根據網絡環境參數變化的幅度觸發場景的變化,由淺入深地闡述方案的設計思路與實現邏輯,目的是為了逐步模擬實際網絡環境的變化情況。系統在識別到場景的變化之后切換至更優的擁塞控制算法,從而取得更佳的性能表現。利用仿真實驗對方案的思路進行驗證。實驗結果表明,基于場景變化的擁塞控制切換方案在網絡環境不斷變化的情況下,能夠比原來使用單一的擁塞控制算法在吞吐量和時延上都取得顯著的優勢,同時兼顧TCP 友好性。
未來的研究勢必要提高對場景識別的精細程度,當前的場景識別相對粗糙,雖然實驗中針對每種擁塞控制方案列舉的場景超過了100 種,但仍然是許多離散值,需要對實際網絡的場景進行近似之后方能采用本文提出的擁塞控制切換方案。而實際網絡環境的場景指標都是連續值,其多樣化程度必然超出了實驗所列舉的范圍,因而必須要提高場景識別的精細程度,使其能夠更真實地反映實際網絡狀況。特別地,場景與擁塞控制方案之間的映射關系也是值得重新思考的。同時,隨著強化學習技術的不斷發展,當其訓練的時間成本與應用上的開銷下降到可接受范圍內時,必然要將強化學習的擁塞控制方案加入到備選方案中,屆時切換方案的成本和難度也會相應增加,而這也是需要努力的方向之一。
