
基于局部冗余混合編碼的故障快速恢復方法
2022-05-07 07:08:12劉靖宇牛秋霞李蕭言史巧碩武優西
計算機應用 2022年4期
劉靖宇,牛秋霞,李蕭言,史巧碩,武優西
(河北工業大學人工智能與數據科學學院,天津 300401)
0 引言
近年來,新產生的數據量呈艾字節(Exa Byte,EB)增長,研究表明全球數據總量將在2030 年達到2 500 ZB。磁盤以大容量、低成本的優點作為海量存儲系統的存儲介質,但磁盤故障頻發,對金融、軍事等各個領域產生了嚴重影響,因此如何滿足存儲可靠性要求具有重要意義。
獨立磁盤冗余陣列(Redundant Array of Independent Disks,RAID)為海量數據的存儲提供了可靠性保障,得到了廣泛應用。由于校驗陣列碼的重構性能可由存取數據塊的個數來衡量,基于非最大距離可分(Non-Maximum-Distance-Separable,Non-MDS)碼的RAID6 在重構過程中重構鏈較短,重構失效數據塊讀取更少的數據量,因此提升了重構性能,越來越受研究人員關注。如:WEAVER 編碼、HoVer 編碼、Code-M(s
,c
)。WEAVER 編碼可容多盤故障,缺點是存儲效率低;HoVer 編碼的重構性能不穩定;Code-M(s
,c
)在重構時,要讀取其他條帶單元組的大量數據,重構讀開銷大。針對現有Non-MDS 編碼重構時間有待減少的缺陷,基于Code-M(s
,c
)中條帶單元組的概念,提出一種支持故障快速恢復的Non-MDS 編碼:局部冗余混合編碼Code-LM(s
,c
),其與Code-M(s
,c
)的主要差異如下:1)Code-LM(s
,c
)犧牲了一定存儲空間,在每個條帶單元組中增加了局部冗余:組內水平校驗塊,進一步縮小了重構鏈長度,減少了重構失效數據塊所需讀取數據量,提高了重構性能。2)水平對角校驗塊的生成方法不同。Code-M(s
,c
)中任意水平對角校驗塊有且只有1 種生成方式,Code-LM(s
,c
)中任意水平對角校驗塊與任意組內水平校驗塊均有2 種生成方式。3)恢復失效數據塊方式不同。Code-M(s
,c
)恢復任意失效數據塊有2 種方式,Code-LM(s
,c
)恢復任意失效數據塊有4 種方式,Code-LM(s
,c
)不同數據塊的重構鏈存在公共塊,減少了重構時讀取的數據量。4)Code-LM(s
,c
)提高了存儲系統容錯性。條帶單元組均出現單盤故障時,Code-M(s
,c
)不可恢復,Code-LM(s
,c
)可恢復。1 相關工作
1988 年,Patterson 等提出了RAID 技術,RAID 以數據條帶化提升了系統性能,以數據冗余機制提升了數據可靠性。RAID 結構通常被劃分為RAID0 到RAID6。其中,RAID0 存儲效率(數據塊的數目與所有塊的數目的比值)為100%,但不具備容錯能力;RAID1 通過鏡像方式實現數據冗余,但存儲效率低;RAID4 和RAID5可容單個盤故障,RAID6 可容忍任意雙盤故障。隨著存儲規模增大,磁盤故障頻發,為提高存儲系統可靠性,RAID6 的使用日益廣泛。
副本與陣列糾刪碼是RAID6 常用的兩種保障存儲可靠性的方法,與副本相比,陣列糾刪碼存儲效率更高。根據MDS 特性,陣列糾刪碼分為最大距離可分(Maximum-Distance-Separable,MDS)編碼和Non-MDS 編碼。MDS 編碼校驗塊為全局校驗塊,重構鏈長度隨著存儲系統規模增大而增加,重構性能下降,如EVENODD 編碼、RDP(Row-Diagonal Parity)編碼、N 編碼、Short 編碼、HV(Horizontal-Vertical)編碼等。與MDS 編碼相比,Non-MDS編碼分布了更多的校驗塊,縮小了重構鏈的長度,重構失效數據塊所需數據量較少,重構性能與存儲系統規模無關。根據存儲效率的不同,Non-MDS 編碼分為兩類:存儲效率大于50%,如HoVer 編碼、Code-M(s
,c
)、V-Code(m
,n
);存儲效率低于50%,如WEAVER 編碼。WEAVER 編碼是具有對稱形式的垂直編碼,最多能容12 盤故障,缺點是存儲效率低,在絕大多數配置下低于50%。HoVer 編碼存在兩種長度的校驗鏈,分別為水平校驗鏈與對角校驗鏈,如圖1 所示。其重構性能不穩定:當故障兩個磁盤的編號間距較大時,重構效率高;當故障的磁盤為水平校驗盤或故障的兩個磁盤編號相鄰時,重構性能低。
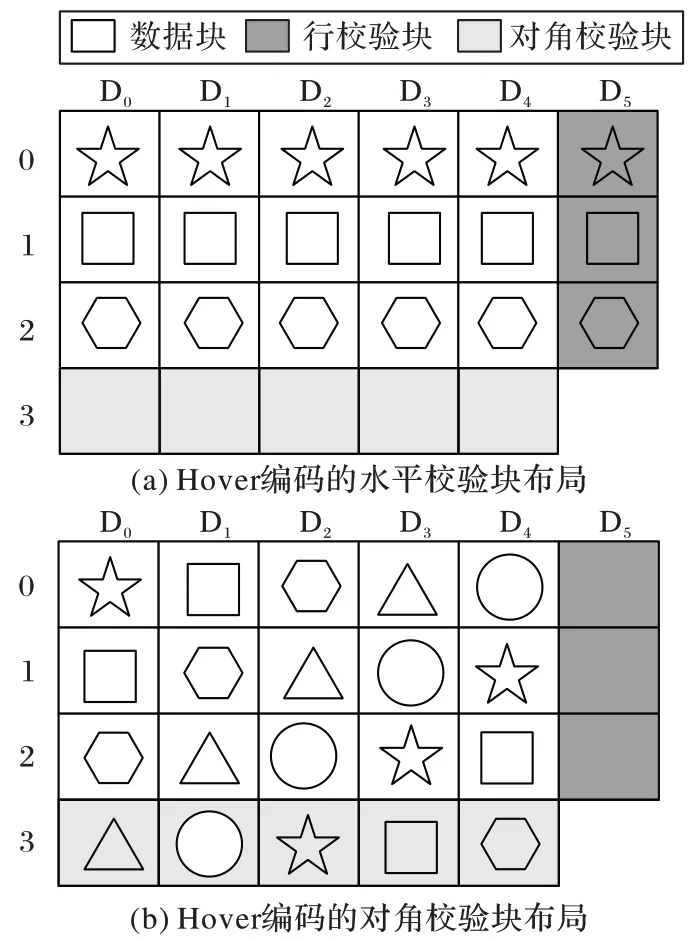
圖1 HoVer編碼的校驗布局Fig.1 Parity layout of HoVer code
D、D、D、D、D、D表示陣列中的6 塊磁盤,行校驗塊存儲在水平校驗盤D,若D失效,重構時需要讀取所有磁盤的全部數據,如圖1(a)所示。Code-M(s
,c
)引入了條帶單元組的概念,根據不同的故障情況采取對應的重構方法。Code-M(s
,c
)存在以下不足之處:1)重構時,要讀取序號相鄰的條帶單元組的大量數據,讀開銷較大,重構時間有待減少;2)容錯能力有待提升,例如當每個條帶單元組均存在一個故障磁盤時,故障不可恢復。謝平提出設計新型高容錯能力的Non-MDS 編碼成為提高重構性能的一種研究趨勢,因此通過減少重構鏈鏈長來減少重構過程中存取數據塊的個數,對于提高存儲系統重構性能具有重要意義。
2 Code-LM(s,c)編碼
Code-LM(s
,c
)中s
表示每個條帶中條帶單元組的數目,c
表示每個條帶單元組中條帶單元的數目,每個條帶單元有c
+1 個連續的塊。為具有雙盤容錯能力,s
不小于2,c
+1 為大于等于5 的質數。2.1 數據塊與校驗塊的分布
二元組(s
,c
)表示特定的條帶單元,該條帶單元所在條帶單元組的序號為s
,且s
滿足0 ≤s
≤s
-1;該條帶單元在條帶單元組s
中的列號為c
,且c
滿足0 ≤c
≤c
-1。三元組(s
,r
,c
)表示條帶單元(s
,c
)上的特定塊,該塊在條帶單元(s
,c
)中的行號為r
,且r
滿足0 ≤r
≤c
。基于Code-LM(3,4)的RAID 分組中,每個條帶有3 個條帶單元組,分別標記為條帶單元組0,條帶單元組1,條帶單元組2;每個條帶單元組有5 行,分別標記為0,1,2,3,4;每個條帶單元組有4 列,每列對應一個條帶單元,如在條帶單元組0 中有4 個條帶單元,分別標記為(0,0),(0,1),(0,2),(0,3);每個條帶單元有5 個塊,如條帶單元(0,1)中的5 個塊可分別標記為(0,0,1),(0,1,1),(0,2,1),(0,3,1),(0,4,1),如圖2 所示。

圖2 Code-LM(3,4)的校驗布局Fig.2 Parity layout of Code-LM(3,4)
對于Code-LM(s
,c
)中的塊(s
,r
,c
),當r
+c
=c
-1,(s
,r
,c
)為組內水平校驗塊;當r
=c
,(s
,r
,c
)為水平對角校驗塊,其余塊為數據塊。條帶單元(0,3)中組內水平校驗塊為(0,0,3),水平對角校驗塊為(0,4,3),數據塊為(0,1,3),(0,2,3),(0,3,3)。形狀相同的塊處于同一校驗鏈。例如在條帶單元組0中,處于行序號為0 中的數據塊(0,0,0),(0,0,1),(0,0,2)與在條帶單元組2 中同一對角線上的塊(2,2,0),(2,1,1),(2,0,2),(2,4,3)構成同一水平對角校驗鏈。

2.2 Code-LM(s,c)的構建規則
Code-LM(s
,c
)中的任意一個數據塊參與三個校驗塊的生成,分別為1 個組內水平校驗塊,2 個水平對角校驗塊。任意組內水平校驗塊()s
,r
,c
有兩種生成方式:1)由條帶單元組s
中同一行上的數據塊異或生成,形式化編碼規則如式(1);2)由條帶單元組()s
-1 mods
中的一組對角線上的塊異或生成,形式化編碼規則如式(2)。任意水平對角校驗塊(s
,r
,c
)有兩種生成方式:1)由條帶單元組s
中的一組對角線上的數據塊與條帶單元組(s
+1)mods
中的同一行上的數據塊異或生成,形式化編碼規則如式(3);2)由條帶單元組s
中的一組對角線上的數據塊與條帶單元組(s
+1) mods
中一個組內水平校驗塊異或生成,形式化編碼規則如式(4)。

2.3 Code-LM(s,c)的重構方法
任意一個失效的數據塊(s
,r
,c
)有4 種恢復方法:1)由條帶單元組s
中的同一行上的數據塊與組內水平校驗塊異或生成,重構規則如式(5);2)由條帶單元組s
中的同一行上的數據塊與條帶單元組(s
-1) mods
中的一組對角線上的塊異或生成,重構規則如式(6);3)由條帶單元組s
的一組對角線上的塊與條帶單元組(s
+1) mods
中的一個組內水平校驗塊異或生成,重構規則如式(7);4)由條帶單元組s
中的一組對角線上的塊與條帶單元組(s
+1) mods
中的同一行上的數據塊異或生成,重構規則如式(8)。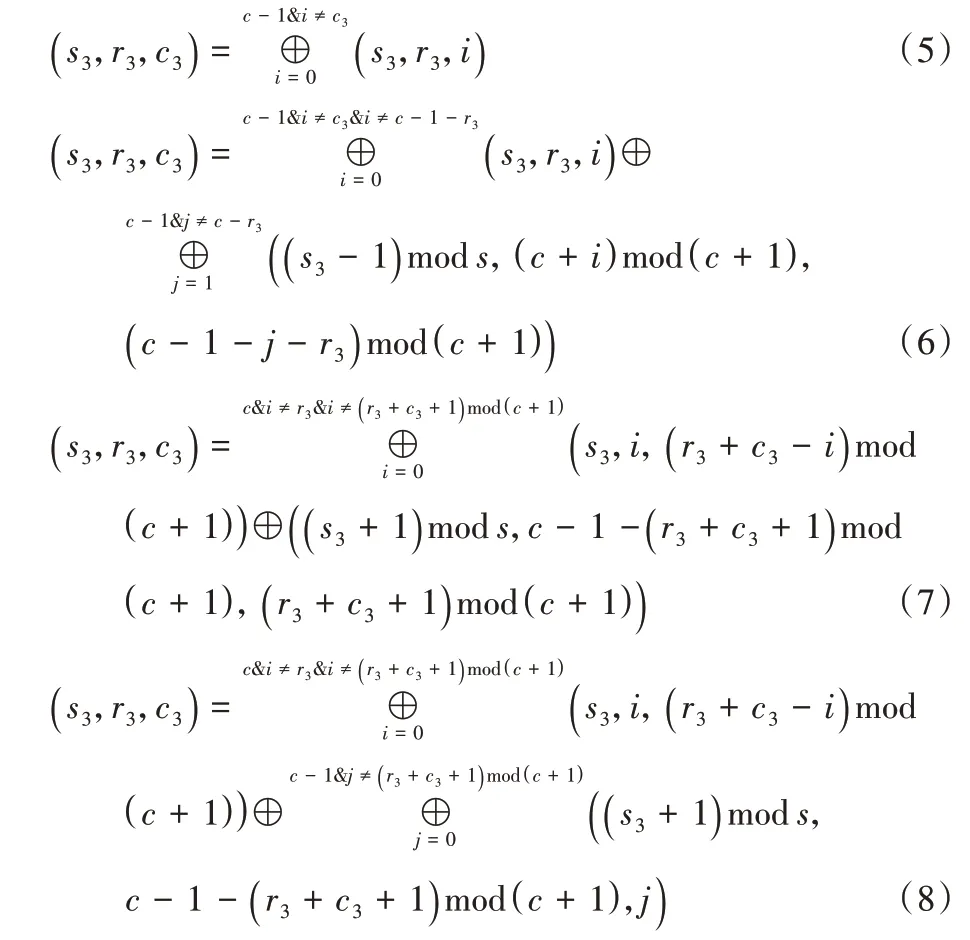
2.3.1 單條帶單元失效情況下的重構
任意單條帶單元(s
,c
)失效,(s
,r
,c
)表示失效條帶單元上的失效塊。重構條帶單元(s
,c
)時,需要讀取條帶單元組s
和(s
+1) mods
中塊。例如,Code-LM(3,4)中條帶單元(1,1)失效,恢復(1,1)時,需要讀取條帶單元組1 和2 中塊,如圖3 所示。
圖3 單個條帶單元失效,Code-LM(3,4)的重構情況Fig.3 Reconstruction with single-strip-failure in Code-LM(3,4)
重構方法如下:使用式(5)和式(1)分別恢復條帶單元(s
,c
)上的數據塊與組內水平校驗塊時,只需讀取條帶單元組s
中行r
上的數據;使用式(4)恢復條帶單元(s
,c
)上的水平對角校驗塊時,只需額外讀取條帶單元組(s
+1) mods
中一個水平校驗塊,原因在于失效水平對角校驗塊所在重構鏈與其他失效塊所在重構鏈有且只有一個交點。算法1 描述了此情況下,Code-LM(s
,c
)的重構過程。算法1 基于Code-LM(s
,c
)的RAID 組中任意失效條帶單元(s
,c
)重構算法。步驟1 標識失效條帶單元(s
,c
)。步驟2 重構失效條帶單元:

s
中同一行的塊重構失效塊。2.3.2 雙條帶單元失效情況下的重構
任意兩個條帶單元(s
,c
)、(s
,c
)失效時,分為以下3 種情況:1)條帶單元(s
,c
)、(s
,c
)在同一條帶單元組,即s
=s
,c
≠c
;2)條帶單元(s
,c
)、(s
,c
)在距離為1 的兩個條帶單元組,即(s
+1) mods
=s
;3)條帶單元(s
,c
)、(s
,c
)在距離大于1 的兩個條帶單元組(此時條帶單元組的數目不小于4)。下面根據不同故障情況給出對應的重構算法。
1)條帶單元(s
,c
)、(s
,c
)在同一條帶單元組。若存在一條校驗鏈,該校驗鏈與失效條帶單元有且僅有一個交點,即該校驗鏈中有且僅有一個塊失效,那么該失效塊可恢復,并且為恢復序列的起點。由Code-LM(s
,c
)的結構可知,存在c
條水平對角校驗鏈,它們的對角數據塊位于條帶單元組s
,水平數據塊位于條帶單元組(s
+1)mod s,由于每一個條帶單元中數據塊的數目為c
-1,因此這c
條水平對角校驗鏈中必存在一條校驗鏈的水平數據塊部分與失效條帶單元(s
,c
)沒有交點。同理可得,必然存在另外一條水平對角校驗鏈的水平數據塊部分與失效條帶單元()s
,c
沒有交點。綜上所述,這兩條水平對角校驗鏈中的失效數據塊可作為恢復序列的起點。重構失效條帶單元(s
,c
)、(s
,c
)時,需要讀取條帶單元組(s
-1) mods
、(s
+1) mods
和s
中的數據。Code-LM(3,4)中條帶單元(1,1)、(1,2)失效,重構需要讀取條帶單元組0、1和2中的塊。重構塊之間的箭頭表示重構順序關系,即只有恢復箭頭起點的塊后,才可以恢復箭頭終點的塊,如圖4所示。
圖4 兩個條帶單元失效且在同一條帶單元組,Code-LM(3,4)的重構情況Fig.4 Reconstruction with double-strip-failure in one strip-set in Code-LM(3,4)
重構方法如下:重構失效條帶單元(s
,c
)、(s
,c
),首先使用式(6)重構恢復序列起點(s
,c
-1 -c
,c
)和(s
,c
-1 -c
,c
)。若未恢復數據塊與已恢復塊處于同一對角線,使用式(7)重構,若未恢復數據塊與已恢復塊處于同一行,使用式(5)重構;若失效塊為水平對角校驗塊,使用式(4)重構。算法2 描述了此情況下,Code-LM(s
,c
)的重構過程。算法2 基于Code-LM(s
,c
)的RAID 組中,同一條帶單元組中任意兩個失效條帶單元(s
,c
)、(s
,c
)的重構算法。步驟1 標識失效的兩個條帶單元(s
,c
)、(s
,c
)。步驟2 重構失效塊:
步驟2.1 分別使用恢復序列起點所在的水平對角校驗鏈上的塊來重構恢復序列起點(s
,c
-1 -c
,c
)、(s
,c
-1 -c
,c
)。步驟2.2 重構恢復序列中剩余的失效塊:
以下兩個重構過程同時進行:
CASE 恢復序列的起點是(s
,c
-1 -c
,c
)

s
,c
)、(s
,c
)在距離為1 的兩個條帶單元組,即(s
+1) mods
=s
。重構任意失效條帶單元(s
,c
)、(s
,c
)時,需要讀取條帶單元組s
、s
和(s
+1) mods
中塊。Code-LM(3,4)中條帶單元(1,2)、(2,1)失效,重構時需要讀取條帶單元組0、1 和2 中的塊,如圖5所示。
圖5 兩個條帶單元失效且在距離為1的2個條帶單元組時,Code-LM(3,4)重構情況Fig.5 Reconstruction with double-strip-failure in two adjoining strip-sets in Code-LM(3,4)
重構方法如下:若失效塊為數據塊或組內水平校驗塊,使用式(5)重構;若失效塊為水平對角校驗塊,使用式(4)重構。算法3 描述了此情況下,Code-LM(s
,c
)的重構過程。算法3 基于Code-LM(s
,c
)的RAID 組中任意兩個失效條帶單元(s
,c
)、(s
,c
)的重構算法,(s
+1) mods
=s
。步驟1 標識失效條帶單元(s
,c
)和(s
,c
)。步驟2 重構條帶單元(s
,c
)的失效塊:
s
上同一對角線的塊和條帶單元組(s
+
s
上同一行的數據塊重構失效塊。3)兩個失效條帶單元(s
,c
)、(s
,c
)在距離大于1 的兩個條帶單元組。Code-LM(s
,c
)重構任意失效條帶單元(s
,c
)和(s
,c
)時,需要讀取條帶單元組s
、s
、(s
+1) mods
和(s
+1) mods
中塊。Code-LM(4,4)中條帶單元(1,1)和(3,1)失效,重構需要讀取條帶單元組0、1、2 和3 中的塊,如圖6 所示。
圖6 兩個條帶單元失效且在距離大于1的2個條帶單元組時,Code-LM(4,4)重構情況Fig.6 Reconstruction with double-strip-failure in two different strip-sets with strip-set distance of 1 in Code-LM(4,4)
重構方法如下:若失效塊為數據塊或組內水平校驗塊,使用式(5)重構,若失效塊為水平對角校驗塊,使用式(4)重構。算法4 描述了此情況下,Code-LM(s
,c
)的重構過程。算法4 基于Code-LM(s
,c
)的RAID 組中任意兩個失效條帶單元(s
,c
)、(s
,c
)重構算法(且兩個條帶單元在距離大于1 的條帶單元組)。步驟1 標識失效條帶單元(s
,c
)和(s
,c
)。步驟2 重構條帶單元(s
,c
)的失效塊:
3 Code-LM(s,c)性能分析
本章對Code-LM(s
,c
)的編碼效率、存儲效率、讀寫性能、重構開銷與重構性能進行分析,并將其與RDP-Code(n
-2,n
)、Code-M(s
,c
)、V-Code(m
,n
)作比較。基于不同編碼的每個RAID 分組中磁盤的總數目均為n
,n
=s
×c
。每個磁盤完全相同,設單盤容量固定為d
個塊,每個塊的大小相同。3.1 編碼效率
編碼效率可定義為編碼所需異或(Exclusive OR,EOR)運算次數與磁盤陣列中的數據塊數量的比值,因此編碼效率值越小,編碼效率越優,編碼計算負載越小。



n
-2,n
)、V-Code(m
,n
)相比,Code-LM(s
,c
)的編碼效率最優,Code-LM(s
,c
)編碼時的計算負載最小,如圖7 所示。原因在于其犧牲了一定的存儲空間,分布更多的校驗塊,生成一個校驗塊所需的數據塊更少,縮短了校驗鏈長度。
圖7 編碼效率對比結果Fig.7 Comparison results of coding efficiency
3.2 存儲效率
存儲效率可定義為磁盤陣列中數據塊的數目與磁盤陣列中所有塊的數目的比值。




n
-2,n
)、V-Code(m
,n
)和Code-M(s
,c
)相比,Code-LM(s
,c
)存儲效率最低,由于其犧牲了一定的存儲空間,存放更多的校驗塊。當c
增加時,Code-LM(s
,c
)存儲效率增加,且與其他編碼的存儲效率差距不斷減小。例如,當c
=4,6,10,12,16,18 時,對應的磁盤數目n
=12,18,30,36,48,54,對應的存儲效率分別為60%、71%、82%、85%、88%、89%,如圖8 所示。
圖8 磁盤數目相同時,編碼存儲效率比較Fig.8 Comparison of storage efficiency with same numbers of disks
3.3 無磁盤故障情況下的Code-LM(s,c)讀寫性能分析
無磁盤故障情況下,磁盤陣列存在讀和寫兩種操作。讀操作包括小讀(一次讀一個塊)和條帶單元讀(一次讀一個條帶單元),寫操作包括小寫(一次寫一個塊)和條帶單元寫(一次寫一個條帶單元)。
1)讀操作:由于Code-LM(s
,c
)是垂直編碼,其校驗塊均勻分布在每個條帶單元上,因此在無磁盤故障時,其小讀操作沒有引起額外的開銷;由于每個條帶單元都存在校驗塊且校驗塊無需讀取,所以其條帶單元讀不能完全占有單個磁盤上的連續讀帶寬。2)寫操作:由Code-LM(s
,c
)編碼規則可知,任意一個數據塊參與3 個校驗塊的生成,分別是兩個水平對角校驗塊,一個組內水平校驗塊,因此在正常模式下,其小寫操作會引起3 個校驗塊的寫操作。Code-M(s
,c
)與V-Code(m
,n
)小寫操作均引起2 個校驗塊的更新,因此與Code-M(s
,c
)、V-Code(m
,n
)相比,Code-LM(s
,c
)小寫開銷最大。由于Code-LM(s
,c
)中任意一個條帶單元數據塊的數目為c
-1,因此其條帶單元寫將更新校驗塊的數目為3(c
-1),更新磁盤的數目為2(c
-1)。由于Code-LM(s
,c
)中條帶單元組數目至少為2,因此在存儲規模相同的情況下,與水平編碼相比,其條帶單元寫開銷較大;與垂直編碼相比,其條帶單元寫開銷較小。3.4 單盤故障時,Code-LM(s,c)重構開銷
解碼復雜度決定了重構效率,影響系統可靠性。
由算法1 可知,失效數據塊與失效組內水平校驗塊所在的重構鏈長度為c
,失效水平對角校驗塊所在的重構鏈長度為c +
1;使用式(1)重構失效數據塊和組內水平校驗塊時,需要的異或操作數均為c
-2,使用式(4)重構失效水平對角校驗塊時,需要的異或操作數為c
-1。由于任意失效條帶單元中,數據塊數目為c
-1,組內水平校驗塊和水平對角校驗塊數目均為1,因此為恢復任意失效條帶單元,Code-LM(s
,c
)需要讀取的塊個數為c
×(c
-1)+1,寫入的塊的個數為c
+1,即I/O 復雜度為c
+2,計算總復雜度為c
-c
-1。3.5 雙盤故障時,Code-LM(s,c)重構開銷
雙盤故障時分為以下3 種情況:
1)任意兩個故障磁盤在同一條帶單元組。
由算法2 可知,恢復序列中恢復起點所在重構鏈長度為2c
-1,失效水平對角校驗塊所在的重構鏈長度為c
,其他失效塊所在重構鏈長度為c
+1;恢復任意兩個失效條帶單元,需要讀取的塊數目為(c
+1) ×(c
-2)+3c
,需要寫入的塊的數目為2(c
+1),I/O 復雜度為c
+4c
,計算總復雜度為2c
+c
-4。2)任意兩個故障磁盤在距離為1 的兩個條帶單元組。
使用算法3 重構時,失效數據塊與組內水平校驗塊所在的重構鏈長度為c
,失效水平對角校驗塊所在重構鏈長度為c
+1;恢復任意兩個失效條帶單元,需要讀取的塊的數目為2c
×(c
-1)+1,需要寫入的塊的數目為2(c
+1),I/O 復雜度為2c
+3,計算總復雜度為2(c
-c
-1)。3)任意兩個故障磁盤在距離大于1 的兩個條帶單元組。
使用算法4 重構時,失效數據塊與失效組內水平校驗塊所在的重構鏈的長度為c
,失效水平對角校驗塊所在的重構鏈長度為c
+1,恢復任意兩個失效條帶單元,需要讀取的塊的數目為2c
×(c
-1)+2,需要寫入的塊的數目為2(c
+1),I/O 復雜度為2c
+4,計算總復雜度為2(c
-c
-1)。3.6 Code-LM(s,c)重構性能比較
將Code-LM(s
,c
)與同時具有組內水平校驗塊和對角校驗塊的RDP-Code(n
-2,n
),具有水平對角校驗塊的Code-M(s
,c
),具有對角校驗塊V-Code(m
,n
)進行比較。為便于比較作出如下假設:用于數據重構的總帶寬是相同,即單位時間內完成與重構相關的數據讀寫總量是固定的。
重構時讀取數據塊的個數決定了重構時間,讀取數據塊個數越少,重構時間越少,重構性能越好。

任意雙盤故障分為以下3 種情況:



n
-2,n
):任意單盤故障時,失效數據塊所在重構鏈長度為n
-1,任意單盤重構需要讀取的塊個數為d
×(sc
-2);雙盤重構需要讀取的塊個數為d
×(sc
-2)。在磁盤數目相同時,Code-LM(s
,c
)的任意單盤和雙盤重構性能均優于RDP-Code(n
-2,n
)。當c
一定時,隨著s 的增加,任意單盤和雙盤重構時間比率會進一步降低。s
=3,c
=4,Code-LM(3,4)犧牲的存儲效率為0.23,任意單盤重構時間 為RDP-Code(10,12)的0.26 倍,雙盤重構時間為RDP-Code(10,12)的0.44 倍;s
=4,c
=4,Code-LM(4,4)犧牲的存儲效率為0.28 倍,任意單盤重構時間為RDP-Code(14,16)的 0.19 倍,雙盤重構時間為RDP-Code(14,16)的0.31 倍;s
=5,c
=6 時,與RDP-Code(n
-2,n
)相比,Code-LM(s
,c
)的單盤和雙盤重構時間減少最多,Code-LM(5,6)單盤和雙盤重構時間分別為RDP-Code(28,30)的0.16 倍和0.23 倍,即分別減少了84%和77%如圖9 所示。
圖9 Code-LM(s,c)與RDP-Code(n -2,n)重構時間比較Fig.9 Comparison of reconstruction time between Code-LM(s,c)and RDP-Code(n -2,n)

n
-2,n
)中的任意單盤故障情況,Xiang等提出了單盤修復優化算法RDOR(Row-Diagonal Optimal Recovery),與RDP-Code(n
-2,n
)的傳統單盤修復算法相比,其減少了單盤重構時間,提高了單盤重構性能;Code-LM(s
,c
)的單盤重構性能優于單盤恢復優化算法RDOR。當磁盤數n
=12 時,Code-LM(3,4)的單盤重構時間為RDP-Code(10,12)的0.26 倍,為RDOR 的0.42 倍;當磁盤數目n
=30 時,Code-LM(5,6)中單盤重構時間為RDP-Code(28,30)的0.16倍,為RDOR的0.23倍,如圖10所示。
圖10 Code-LM(s,c)與RDP-Code(n -2,n),RDOR單盤重構時間比較Fig.10 Comparison of reconstruction time of single disk failure between Code-LM(s,c)and RDP-Code(n -2,n),RDOR

s
,c
)的任意單盤重構性能和雙盤重構性能均優于Code-M(s
,c
)。當s
一定時,隨著c
增加,犧牲的存儲效率進一步減小,雙盤重構時間比率會進一步降低。s
=3,c
=4,Code-LM(3,4)犧牲的存儲效率為0.15,雙盤重構時間為Code-M(3,4)的0.49 倍;s
=3,c
=6,Code-LM(3,6)犧牲的存儲效率為0.12,雙盤重構時間為Code-M(3,6)的0.44 倍;s
=3,c
=10,Code-LM(3,10)犧牲的存儲效率為0.08,雙盤重構時間為Code-M(3,10)的0.40 倍,如圖11 所示。
圖11 Code-LM(s,c)與Code-M(s,c)重構時間比較Fig.11 Comparison of reconstruction time between Code-LM(s,c)and Code-M(s,c)


m
=c
+1 時,隨著c
增加,Code-LM(s
,c
)犧牲的存儲效率進一步減小,任意單盤重構性能和雙盤重構性能均優于V-Code(m
,n
)。s
=5,c
=4 時,Code-LM(5,4)犧牲的存儲效率 為0.2,雙盤重構時間為V-Code(5,20)的0.31 倍,Code-LM(5,4)單盤重構時間為V-Code(5,20)的0.33 倍,即減少了67%;s
=5,c
=6,Code-LM(5,6)犧牲的存儲效率為0.14,雙盤重構時間為V-Code(7,30)的0.30 倍;s
=5,c
=10,Code-LM(5,10)犧牲的存儲效率為0.09,雙盤重構時間為V-Code(11,50)的0.28 倍;s
=4,c
=10,與V-Code(m
,n
)相比,Code-LM(s
,c
)雙盤重構時間減少最多,Code-LM(4,10)的雙盤重構時間為V2-Code(11,40)的0.28 倍,即Code-LM(4,10)雙盤重構時間減少了72%,如圖12 所示。
圖12 Code-LM(s,c)與V2-Code(m,n)重構時間比較Fig.12 Comparison of reconstruction time between Code-LM(s,c)and V2-Code(m,n)

4 結語
本文提出了一種支持故障磁盤快速恢復,可容忍任意雙盤失效和其他形式多盤失效的新型Non-MDS 編碼:Code-LM(s
,c
)。Code-LM(s
,c
)是垂直編碼,校驗塊在每個條帶單元中均勻分布。它根據不同的故障情況采用不同的恢復方法,它與通用的MDS 編碼相比,分布了更多的校驗塊,縮短了重構鏈的長度,縮短了重構時間,提高了重構性能,重構性能穩定且與存儲系統規模無關。理論分析和實驗結果表明,Code-LM(s
,c
)可提高大規模存儲系統中數據可靠性。在未來的工作中,為了進一步提高存儲系統的可靠性和容錯性,將研究一種新型Non-MDS 編碼,該編碼可容任意多盤故障。