車企輿情正負面情感識別與預測
2022-05-07 02:38:10胡二琴
湖北工業大學學報 2022年2期
秦 苗, 胡二琴
(湖北工業大學理學院, 湖北 武漢 430068)
文本挖掘和分析已經成為各行各業研究數據模式的核心問題。對于企業來說,通過對互聯網中與自身企業有關的輿情進行分析,能幫助其獲得更多的信息,進一步了解客戶,預測和增強客戶體驗,合理改進產品性能[1-2]。HU等[3]通過情感分析挖掘出用戶對產品的情感傾向;Dasgupta等[4]通過對三星手機用戶評論進行情感分析,得到消費者對手機信息特征的反饋;李琴等[5]基于情感詞典對在線景區評論進行情感分析得到情感類別傾向性與門票波動之間客觀存在的聯系。
目前,汽車制造行業競爭激烈,有效提高汽車的品牌形象和溢價效應對于企業來說至關重要。伴隨著互聯網的發展,汽車行業的品牌質量、發展規劃、創新水平等受到了越來越多的關注[6-7],大量的網絡評論中蘊含著廣大網民的情感和觀點,通過對評論情感進行研究,車企可以深入了解到近期網絡輿論傾向,從而進行相應的調整和改進[8-9]。因此,對汽車行業輿情情感進行研究,將會有助于提高車企形象,而對文本情感進行識別是輿情分析的關鍵。目前,情感識別主要有兩類方法:基于情感詞典的方法和基于機器學習的方法[10]。李宸嚴[11]等利用注意力與Bi-LSTM混合算法進行了車企輿情的情感分析。本文主要通過情感詞典來對汽車行業的網絡輿情進行分析與預測,利用分詞繪制詞云圖、情感分類、主題分析來了解廣大網民對汽車行業的關注重點以及正負面情感聚焦。
1 數據來源與數據預處理
本文數據來自“第四屆全國應用統計專業學位研究生案例大賽”C題,數據分為訓練集與測試集,共99842 條,其文本數據部分展示見圖1。

圖 1 部分數據展示
該數據的第1列是文本小標題,第2列是正文,第3列是用戶ID,第4列是文本的網頁鏈接,第5列是其給定的情感類別。
數據的預處理對本文的分析十分重要,對后續結果分析有很大影響。我們首先依據對文章有高度概括性的標題進行刪除,去除與車企無關的輿情。在網上查詢與汽車相關的詞匯大全,利用該詞匯大全計算標題得分,若累積得分為0,則認為該標題是與車企完全無關的報道,需要刪除。繼而去除文本中的重復數據,認為標題和正文均相同的為重復數據予以刪除,最終保留與車企相關的輿情有45324條。然后進行數據清洗,去除數據中無用、停用詞和出現頻率極高但無實際情感意義的詞匯,如“汽車”等。
2 車企輿情熱點分析
在數據預處理和“Jieba”分詞后,提取分詞中的名詞詞匯,統計詞匯出現的頻率,將詞頻按降序排列,選擇前100個詞繪制詞云來直觀反映人們的關注點和關注度。

圖 2 輿情熱點詞云圖
由圖2可見,在與汽車行業相關的輿情中,人們關注較多的是駕駛、新能源、車型、上市、新款,以及豐田、奧迪、吉利等品牌。對測試集進行相同的操作,發現兩者在熱點詞匯上沒有太大差異,只是對奧迪的關注減少了而對大眾的關注度增加了,另外還增加了對車主的關注。
為進一步了解車企輿情中人們對汽車品牌和汽車功能、配件的關注熱點,我們查找了汽車品牌詞庫大全以及汽車相關配件詞匯大全(https:∥pinyin.sogou.com/dict/ cate/index/432)。將文本分詞分別與這兩組詞匯進行匹配,計算頻率,取排名前十來分析車企輿情關注最多的汽車品牌和汽車配件,其結果如圖3、圖4所示。
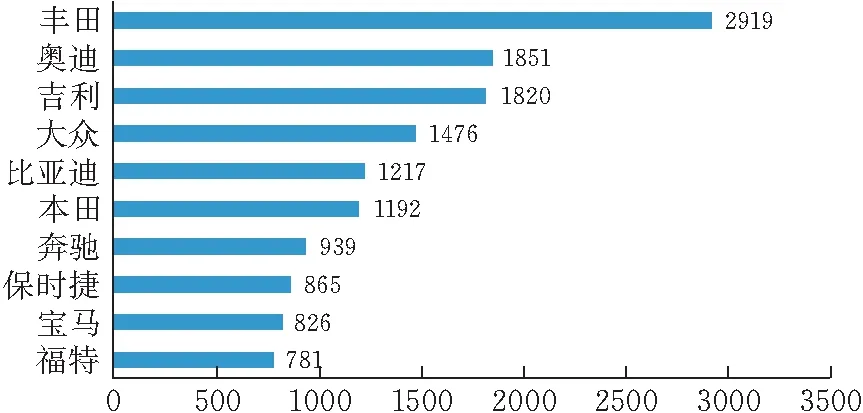
圖 3 車企輿情熱點關注品牌Top10
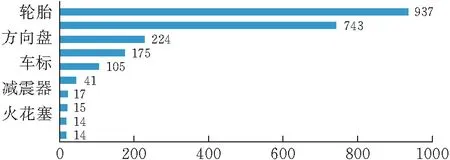
圖 4 車企輿情熱點關注配件Top10
由圖可見,訓練集中關注最多的汽車品牌依次是豐田、奧迪、吉利、大眾等;關注最多的汽車配件依次是輪胎、發動機、方向盤、輪轂等。對測試集進行相同處理,可見測試集中關注最多的汽車品牌與訓練集中大體相同,只是測試集輿情關注的汽車品牌前10少了寶馬,多了紅旗;在對汽車配件的關注中,兩個數據集也大體相同,只是測試集多了轉向燈,少了離合器。
3 車企輿情情感傾向分析
文本情感分析可以被視為一類特殊的文本分類問題。目前絕大多數研究將文本的情感傾向性分為正向、負向兩種類別。文本情感分類方法主要有機器學習方法、詞典匹配方法。機器學習方法中主要用到的是支持向量模型、樸素貝葉斯模型以及神經網絡等。這些方法各有優劣。而本文是要進行正、中、負3級分類,不適合用針對二分類的支持向量模型,所以采取情感詞典匹配的方法來對情感進行標記。
3.1 提取文本情感特征
在以情感詞典為基礎的情感分析中,情感詞庫的選擇占據十分重要的地位。高質量的情感詞庫往往可得到更好的情感分析效果,通常情況下所選取的情感詞庫是網上下載的正負面情感詞匯和正負面評論詞匯。但本文的輿情數據并非評論數據而是類似網絡小文章形式,這類數據的正負往往在其中帶有事件特征,比如文中沒有太多的情感性詞匯,但由于描述的是一件正面事件,故最終也會評為正向情感。因此若是基于傳統的情感詞庫進行分類效果并不會理想,本文經嘗試后發現準確率只有23.19%,故考慮重新提取情感特征構建新的詞庫再進行情感匹配。
本文通過詞頻來選擇特征。利用詞頻對處理后的文本分詞分別計算權重,并根據權重的大小對分詞進行排序,然后剔除一些與文章主題雖直接聯系但無實際意義的無用詞,如 “汽車”“年”“拉”等。然后統計分詞的總詞頻,從中選取若干個出現頻率最高的詞匯組成該類別的特征詞集;最后去掉每一類中都出現了的詞,形成3種類別各自特有的特征詞集(即我們用到的特征集合)。特征項的構建步驟見圖5。
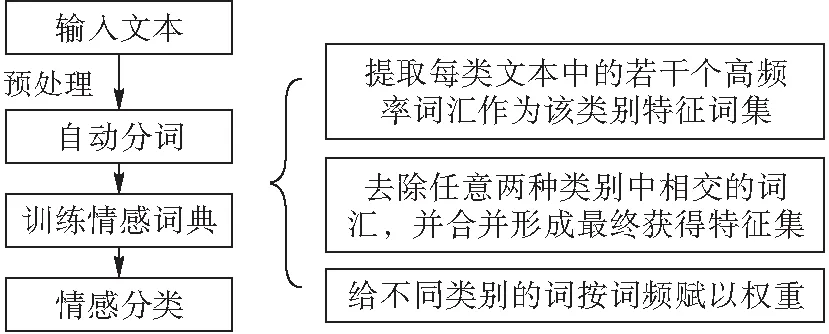
圖 5 特征項的構建流程
由于中立面的詞匯沒有明顯的實際特征,所以我們只進行正面詞匯和負面詞匯的選取。按詞頻降序排列后發現,正面詞匯中排名在第500的詞匯出現頻率只有2次,負面詞匯中排名在第300的詞匯出現頻率為5次,表2分別展示了正向詞匯排名前100、300、500的末尾詞以及負向詞匯排名前100、200、300的末尾詞。

表2 正向詞匯局部展示

表3 負向詞匯局部展示
可見,正負向中前300的詞頻詞匯的情感分級都比較明顯,初步選擇構建的情感詞典正負向均取300個詞匯。
3.2 文本特征表示
計算詞權值的方式有傳統的用權重賦值法以及TF-IDF等,TF-IDF的主要思想是:如果某個詞在一篇文章中出現頻率很高,但在其他文章中極少出現,那么這個詞就能很好地區分類別,適合用來作為分類的特征。其公式為:
其中:wik為特征詞ik的權重,tfik為特征詞ik在文本di中出現的頻率,N為總的訓練文本數,nk為訓練集中詞ik出現了的文本數。
實踐中發現,用此方法賦以權重比較繁瑣,且其不區分正負語料庫,而是直接依據每個詞在正、負、中性文本中出現的頻率來判斷其在不同情感中的權重,因此本文采用簡單的權重賦值方法,即將所有正向詞匯賦以+1的權重,所有負向詞匯賦以-1的權重。這樣的優點是操作起來比較簡單便捷,缺點是忽略了不同詞匯在情感程度上的差異。
3.3 文本情感分類
本文利用情感詞典來對文本情感進行標注。對具有積極情感的詞語賦于+1的權重,對具有消極情感的詞語賦于-1的權重,并假定情感賦值可以線性相加。由于標題對文章內容具有高度概括作用,所以選擇利用標題來對文章進行情感分類。首先對標題進行分詞,然后對分詞中包含的情感詞加上對應+1或-1的權重。此外,本文加上了否定詞和程度副詞對情感的影響,最終將得分為正的文本劃分為正面情感,得分為負的文本劃分為負面情感,其余文本記為中立情感。對訓練數據集和測試數據集分別隨機抽取10 000條進行情感劃分,其準確率達到85.73%,整體效果較好,其混淆矩陣如表4所示。

表4 訓練集情感劃分混淆矩陣
可見,負向情感正確劃分的概率為83.75%,正向情感正確劃分的概率為89.19%,對中立情感的文本劃分準確率相對低一點。考慮到整體準確率為85.73%,且正向負向情感劃分的準確率均不錯,故此方法有效。
將同樣的方法用于測試集的情感劃分,得到準確率為83.62%,整體效果較好,其混淆矩陣如表5所示。
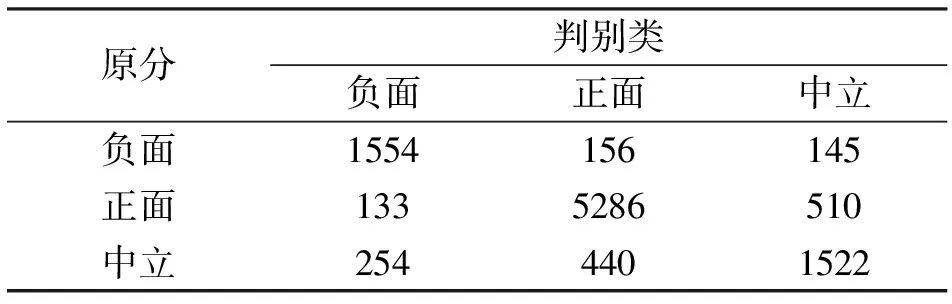
表5 測試集情感劃分混淆矩陣
可見,負向情感正確劃分的概率為83.77%,中立情感被正確分類的概率為68.68%,正向情感正確劃分的概率為89.16%,總體準確率為83.62%。
在此基礎上對訓練集分類后的正負向情感文本分詞統計詞頻,按頻率降序排列選取前100名的詞匯繪制詞云圖見圖6、7。

圖 6 訓練集正向情感文本詞云

圖 7 訓練集負向情感文本詞云
對訓練集分類后,其正向輿情信息中關注較多的是上市、車型、魅力等,負面輿情信息中關注較多的是銷量、二手車、投訴、事故、下滑等,說明分類后的分詞效果比較好,有利于后續分析。
對測試集情感劃分正負之后也分別提取了正負面的主要詞匯,將其與訓練集對比并無太大差異,我們將兩個數據集正負面提取的詞匯取前6個綜合為表6。

表6 兩個數據集正負面熱詞對比
可見訓練集與測試集在正面情感熱詞上相差不大,只是訓練集中正面輿情增加了對豐田的關注;兩個數據集在負面情感熱詞上相差也不大,只是測試集中的負面輿情減少了對疫情的關注,增加了對達利桑、德羅的關注。
4 車企輿情主題分析
4.1 LDA主題分析模型
LDA模型也叫3層貝葉斯概率模型。它由3層結構組成,分別是文檔(d)、主題(z)和詞(w)。該模型能夠有效挖掘潛藏在數據中的主題,進而分析數據中的主要關注點。
3層貝葉斯結構包括兩部分,分別是“文檔—主題”和“主題—詞”,其中“文檔—主題”表示以一定概率來通過文檔d生成主題z;“主題—詞”表示以一定概率來通過主題z生成詞w。若要生成一個文檔,文檔中每個詞出現的條件概率可以分為兩部分:
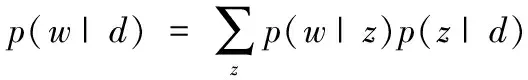
式中,p(w|d)表示文檔中分詞出現的概率;p(w|z)表示主題中分詞出現的概率;p(z|d)表示文檔中主題出現的概率。LDA模型則是利用“文檔—詞語”矩陣來進行訓練,由此推測出文檔的主題。
4.2 尋找最優主題數
由于中立情感的文本對主題分析沒有太大價值,并不能反映一些關鍵性看法和態度,所以本文選擇只對測試集中情感為正向和負向的文本進行主題分析。LDA模型可以用相對較少的迭代就找到最優的主題數。圖8展示了不同主題數下的平均余弦相似度,可見無論是正向情感還是負向情感都在主題數選2時,平均余弦相似度最低。因此,對正面數據和負面數據均選擇主題數為2來進行主題分析。對測試集進行相同的步驟,發現選擇的最優主題數也是2。
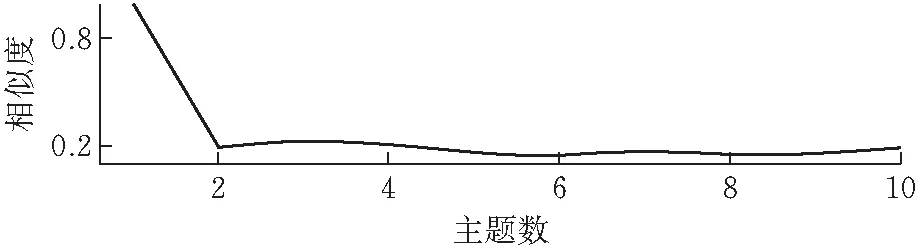
(a)正面
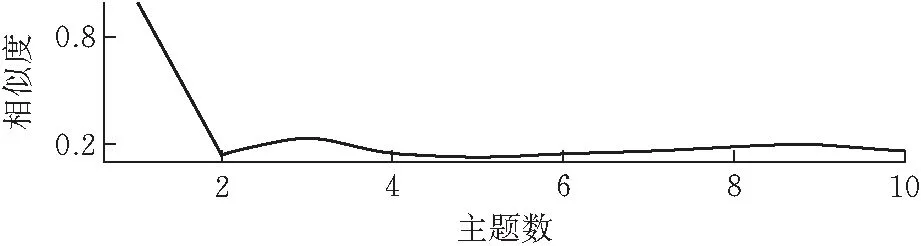
(b)負面圖 8 主題間平均余弦相似度
4.3 LDA主題分析
根據概率,在每個主題下生成10個最有可能出現的詞語。表7反映了訓練集中正面情感數據潛在的主題。主題1中的高頻詞(即關注點)主要是上市、魅力、車型、比亞迪、奧迪等主要反映人們對車的車型、特質等關注多的方面。主題2中的高頻詞(即關注點)主要是新款、動力、新能源、吉利等,說明人們對新款的車比較關注,且對它的動力、新能源方面關注較多且好評度較高。

表7 訓練集正面輿情數據中的潛在主題
表8反映了訓練集中負面情感數據潛在的主題。主題1中的高頻詞主要是銷量、同比、下降、新車、召回、投訴、司機之類,說明很多關于車企的負面輿情都較多提到新車召回、銷量下降以及服務投訴。主題2中的高頻詞主要是二手車、優信、駕駛、自動之類,說明人們對二手車的滿意度并不是很高。廣大網民對一些新興的自動駕駛持懷疑態度,對其安全性存在一些顧慮。

表8 訓練集負面輿情數據中的潛在主題
對測試集同樣提取了兩個主題的關鍵詞,其結果與訓練數據集主題所體現的關注點相似,只是正面中主題2增加了對設計、品牌、高顏值的關注,也就是對汽車的外形設計上關注較多;負面中測試集增加了對日產和豐田的關注。
5 結論
本文利用情感詞典識別和預測汽車行業的輿情情感,并對正面情感和負面情感分別進行主題分析。從分析結果可知,廣大網民對汽車行業現狀的態度和關注點,發現人們對汽車的車型、魅力等聚焦較多,且對新款車尤為關注;對汽車的動力、新能源等方面具有一定的關注度和好評度,對新車的召回率、部分汽車銷量下降情況以及出租車司機因服務不當而遭受投訴等方面帶有一定的負面情緒;對二手車的滿意度不高,對于新興的自動駕駛也持懷疑觀望態度。
猜你喜歡
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
中國生殖健康(2020年5期)2021-01-18 02:59:48
山東醫藥(2020年34期)2020-12-09 01:22:24
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
小學教學參考(2015年20期)2016-01-15 08:44:38
