深度多模態表征學習概述
2022-05-10 05:25:16謝亦才易云
電腦知識與技術 2022年9期
謝亦才 易云

摘要:多模態表征學習旨在縮小不同模態數據之間的異質性差距。近年來,基于深度學習的多模態表征學習因其強大的多層次抽象表征能力而備受關注。文章提供了關于深度多模態表征學習的全面調查。文章將深度多模態表示學習方法分為三個框架:聯合表示、協調表示和編解碼器。此外,還回顧了該領域的一些典型模型,從傳統模型到新開發的技術。重點介紹了新開發技術的關鍵問題,如編碼器-解碼器模型、生成性對抗網絡等。最后,對今后的工作提出了一些重要的方向。
關鍵詞:多模態表征學習;多模態深度學習;深度多模態融合
中圖分類號:TP311? ? ? ? ?文獻標識碼:A
文章編號:1009-3044(2022)09-0067-03
1引言
多模態數據是指描述同一對象的數據記錄在不同類型的媒體中例如文本、圖像、視頻、聲音和圖形。在表征學習領域,“模態”一詞指編碼信息的特定方式或機制。因此,上面列出的不同類型的媒體也指模態,涉及多種模態的表征學習任務將被描述為多模態表征學習。由于多模態數據從不同的角度描述對象,通常在內容上是互補的或補充的,因此它們比單模態數據信息更豐富。例如,學者們在有關語音識別的研究中發現,視覺模式能提供嘴唇運動和嘴的關節(包括張開和閉合)之間的關聯信息,這一視覺模式對提高語音識別性能有幫助。因此,彌合語義鴻溝,綜合利用幾種模臺提供的綜合語義是很有價值的。
為了縮小異質性差距,在過去的幾十年中,學者們用各種方法進行了大量的研究。因此,多模態表征學習的發展使許多應用受益。例如,通過利用來自多通道的融合特征,可以在跨媒體分析任務中實現性能改進,例如視頻分類、事件檢測和情感分析等。此外,通過利用跨模態相似性或跨模態相關,使我們能夠使用句子作為輸入來檢索圖像,反之亦然,即跨模態檢索。最近,一種新型的多模態應用——跨模態翻譯在計算機視覺界引起了極大的關注。顧名思義,它將一種情態轉化為另一種情態。該類別中的示例性應用包括圖像標題、視頻描述和文本到圖像合成。
近年來,由于具有多層次抽象的強大表示能力,深度學習在有關自然語言處理、語音識別和計算機視覺等應用中取得了優良成果[1]。此外,深度學習的另一個關鍵優勢是,可以使用通用學習程序直接學習層次表示,而無須手工設計或選擇功能。在這一成功的推動下,深度多模態表征學習獲得了巨大關注。
2深度多模態表征學習框架
為了便于討論如何縮小異質性差距,將深度多模態表示方法分為三類框架:(1)協同表示,旨在學習協同子空間中每個模態的分離和受限表示,包括跨模態相似模型和典型相關分析;(2)編碼器-解碼器模型,努力學習用于將一種模態映射到另一種模態的中間表示。每個框架都有其集成多種模態的方式,并由一些應用程序共享。在應用多模態表征學習之前,應通過適當的方法提取特定模態的特征;(3)聯合表示,它將單模態特征表示投影到一個共享語義子空間中,以利于融合多模態特征。因此,在本節中,首先介紹可能顯著影響性能的單模態表示方法,然后開始討論三種類型的框架。
2.1特定模態表征
盡管各種不同的多模態表示學習模型可能共享相似的體系結構,但用于提取特定模態特征的基本組件可能彼此有很大不同。在這里,將介紹適用于不同模式的一些最流行的組件,而不涉及技術細節。
用于圖像模態特征提取的深度學習模型有LeNet[2], AlexNet[3], GoogleNet[4], VGGNet[5]和ResNet[6]等。它們可以集成到多模式學習模型中,并與其他組件一起進行培訓。然而,考慮到對足夠的訓練數據和計算資源的需求,預訓練好的CNN模型是多模態表示學習的更好選擇。
至于視頻模態,由于每個時間步長的輸入是圖像,因此可以通過用于處理圖像的技術來提取其特征。除了深層特征外,手工特征仍然廣泛用于視頻和音頻模式。此外,還開發了一些工具包來提取特征。例如,OpenFace可用于提取面部特征,如面部地標、頭部姿勢和眼睛注視。另一個工具是Opensmile,可用于提取聲學特征包括Mel頻率倒譜系數(MFCC)、聲音強度、音調及其統計信息。在視頻和音頻的幀被編碼之后,可以使用CNN或RNN網絡將序列匯總為單個向量表示。
用于文本模態特征提取的深度模型有word2vec[7],Glove[8]等,它將單詞映射到向量空間,在該空間中可以測量單詞之間的相似性。在NLP任務中,應該考慮的一個常見問題是未知單詞問題,也稱為詞匯表外(OOV)單詞,它可能會影響許多系統的性能。
2.2聯合表征
集成不同類型的特征以提高機器學習方法性能的策略長期以來被研究者所采用。這種策略在多模態環境中的自然延伸是利用融合的異構特征。根據這一策略,在許多多模態分類或聚類任務中,如視頻分類、事件檢測、情感分析和視覺問答等,都展示了應用前景。
融合多模態特征的最簡單方法是直接連接它們。然而,這個子空間大部分是由一個不同的隱藏層實現的,在該隱藏層中,將添加轉換的特定模態向量,從而將來自不同模態的語義組合起來。
除了在不同的隱藏層中進行融合過程(通常稱為加法方法)之外,一些文獻中還采用了乘法方法。在情感分析任務中,Zadeh等人[9]提出了基于模態內和模態間動力學建模的多模態情感分析問題,并提出了張量融合網絡模型,它可以端到端地學習這兩種動力學。這個方法是針對在線視頻中口語的易變性以及伴隨的手勢和聲音而定制的。
與其他框架相比,聯合表示的優點之一是,由于不需要顯式協同模態,因此可以方便地融合多種模態。另一個優點是共享的公共子空間趨向于模態不變,這有助于將知識從一個模態轉移到另一個模態。然而,該框架的缺點之一是它不能用于推斷分離結果的每種形態的表征。
2.3編碼解碼器表征
近年來,編解碼框架得到了廣泛的應用,用于將一種模態映射到另一種模態的多模態翻譯任務,如圖像標題、視頻描述和圖像合成。通常編碼器-解碼器框架主要由兩部分組成,即編碼器和解碼器。其中編碼器通過多層神經網絡將源模態降維映射為潛在向量f,然后,解碼器對向量f升維,生成新的目標模態樣本。
編碼器-解碼器模型有一些變體包含多個編碼器或解碼器。例如,Mor等人[11]提出了一種跨樂器、流派和風格的翻譯音樂方法。該方法基于多域wavenet自動編碼器,具有共享編碼器和端到端訓練波形的解糾纏潛在空間。其中,共享編碼器負責提取獨立于域的音樂語義,每個解碼器將在目標域中再現一段音樂。一個包括兩個編碼器的示例包括Huang等人提出的圖像到圖像轉換模型。其中一個編碼器負責對圖像風格樣式編碼,另一個編碼器負責對圖像內容編碼。
2.4協同表征
多模態學習中流行的另一種方法是協同表示法。協同表示框架在某些約束條件下學習每個模態的分離但協同表示,而不是學習聯合子空間中的表示。由于不同模態中包含的信息是不平等的,學習分離表征有助于保持獨有的有用模態特定特征[10]。通常,在約束類型的條件下,協同表示方法可分為兩組,基于跨模態相似性的和基于跨模態相關性的。基于跨模態相似性的方法可以直接測量向量與不同模態的距離,而基于模態相關的方法使來自不同模態的表征的相關性最大化。
跨模態相似方法是學習相似性度量約束下的協同表示。該模型的學習目標是保持模態間和模態內的相似結構,期望與相同語義或對象相關的跨模態相似距離盡可能小,而與不同語義相關的距離盡可能大。
與其他框架相比,協同表征傾向于在每種模態中保持唯一和有用的模態特定特征。由于不同的模態編碼在分離的網絡中,其優點之一是每個模態的表征可以獨立推斷。這一特性也有利于跨模態知識遷移學習。該框架的一個缺點是,在大多數情況下,很難學習兩種以上模態的表示。
3典型模型
在本節中,將總結一些深度多模態表征學習的典型模型。它們的范圍從傳統模型,包括概率圖形模型、多模態自動編碼器和深度典型相關分析,與新開發的技術相結合,包括生成對抗網絡和注意機制。這里描述的典型模型可以分為上面介紹的一個或多個框架,也可以與它們集成。
3.1概率圖模型
在深度表征學習領域,概率圖形模型包括深度信念網絡(DBN)和深度玻爾茲曼機器(DBM)。雖然它們都是從堆疊受限玻爾茲曼機器(RBM)層訓練出來的,但它們的結構是不同的。前者是由有向信念網絡和RBM層組成的部分有向模型,后者是完全無向模型。
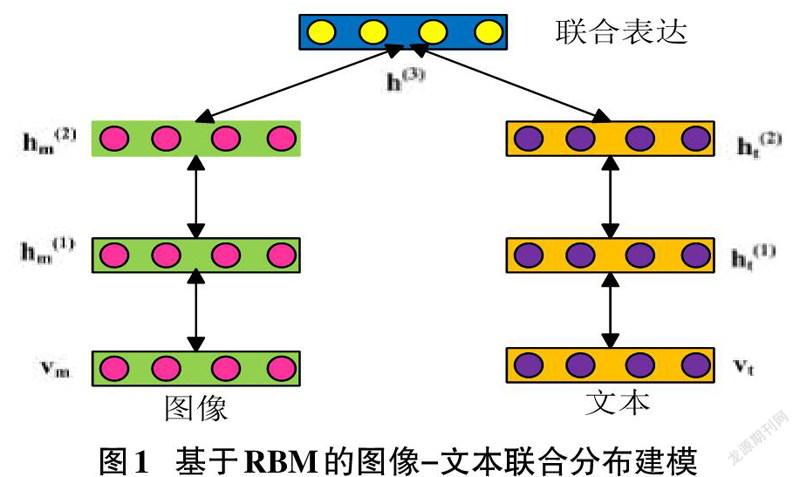
概率圖形模型的一個例子是Srivastava和Salakhutdinov[12]提出的多模態DBN。通過在特定于模態的DBN上添加共享RBM隱藏層,它可以學習跨模態的聯合表示。Srivastava和Salakhutdinov的另一個模型是多模深層玻爾茲曼機器,它交替使用DBMs作為處理每個模態數據的基本單元。作為一個完全無向的模型,隱藏單元的狀態將在各個模式之間相互影響。因此,模態融合過程是分布式的跨越所有層的所有隱藏單元,如圖1所示。
與通過共享表示層連接不同模式的策略不同,Feng等人[15]傾向于巧妙的最大化模式層之間的對應關系。在每個等效隱藏層,來自不同模態的兩個RBM分別通過相關損失函數連接。通過這種方式,獲取了跨模態檢索的基本互模型相關性。
3.2多模態自動編碼器
自動編碼器因其學習表示的能力而廣受歡迎,在無監督的情況下,不需要標簽。這個自動編碼器的基本結構包括兩個組件,一個是編碼器,另一個是解碼器。編碼器也可以將輸入轉換為壓縮的隱藏向量被稱為潛在表示,而解碼器基于此潛在表示重構輸入使重建損失最小化。受去噪自動編碼器的啟發,Ngiam等人[13]將自動編碼器擴展到多模態。他們訓練了一個雙模深度自動編碼器來學習音頻和視頻模式的共享表示。在該模型中,兩個分離的自動編碼器組合在公共潛在表示層中,同時保持其編碼器和解碼器獨立。
3.3生成對抗網絡
生成對抗網絡(GAN)是一種新興的深度對抗網絡學習技巧。作為一種無監督的學習方法,它可以在不涉及標簽的情況下學習數據表示,這將顯著降低對手動注釋的依賴性。此外,作為一種生成方法,它可以根據訓練數據的分布生成高質量的新樣本。自2014年以來,在Goodfellow等人[14]提出后,生成性對抗學習策略已成功應用于各種單模態應用。最著名的應用之一是圖像合成,它根據隨機輸入生成高質量圖像從正態分布中提取。其他成功的例子包括圖像到圖像的轉換和圖像超分辨率。最近,生成對抗性學習策略進一步擴展到多模態情況,如文本到圖像合成、視覺字幕、跨模態檢索、多模態特征融合和多模態講故事。
一般來說,生成對抗網絡由兩個部分組成,一個生成網絡G作為生成器,另一個判別網絡D作為鑒別器,相互競爭。網絡G負責根據學習到的數據分布生成新樣本。而網絡D旨在區分網絡G生成的實例與從訓練集中采樣的項目之間的差異。通常,G和D這兩個分量都是通過深度神經網絡實現的,如圖2所示。
與經典的表示學習方法相比,GANs的一個明顯區別在于數據表示的學習過程并不簡單。這是一種隱含的范式。與傳統的無監督表示方法(如自動編碼器)不同,GANs直接學習從數據到潛在變量的映射,而GANs學習從潛在變量到數據樣本的反向映射。具體地說,生成器將隨機向量映射到獨特的樣本中。因此,該隨機信號是對應于生成的數據的表示。在隨機信號概率很好地擬合真實數據概率的條件下,該隨機信號對于真實的訓練數據是足夠好的表示。
4結論和未來展望
在本文中,提供了一個全面的調查,深入研究多模態表征學習。根據整合不同模態的底層結構分為三類框架:聯合表示、編解碼器表示和協同表示。此外,總結了該領域的一些典型模型,從傳統模型到新開發的技術,包括概率圖模型、多模態自動編碼器、生成對抗網絡等。
長期以來,雖然注意力機制可以部分解決多模態表征學習的語義沖突、重復和噪聲等問題,但它們是隱性的,不能有計劃的可度量的主動控制。為此,可以通過推理機制,將能夠主動選擇急需的證據,并在減輕這些問題的影響方面發揮重要作用。可以預測,表征學習及其推理機制的緊密結合將賦予機器智能認知能力。
參考文獻:
[1] LeCun Y,BengioY,Hinton G.Deep learning[J].Nature,2015,521(7553):436-444.
[2] LeCun Y,Bottou L,Bengio Y,etal.Gradient-based learning applied to document recognition[J].ProceedingsoftheIEEE,1998,86(11):2278-2324.[LinkOut]
[3] A. Krizhevsky,I.Sutskever,and G.E. Hinton,“ImageNet classification with deep convolutional neural networks”[C]//in Proc. Adv. Neural Inf.Process. Syst., 2012:1097–1105.
[4]Szegedy C,LiuW,Jia YQ,et al.Going deeper with convolutions[C]//2015IEEEConferenceonComputerVisionand Pattern Recognition.June7-12,2015,Boston,MA.IEEE,2015:1-9.
[5]K.Simonyanand A.Zisserman,“Very deep convolutional networks for large-scale image recognition”[C]//in Proc. Int. Conf. Learn. Represent.,2015:1-14.
[6] He K M,Zhang X Y,Ren S Q,etal.Deep residual learning for image recognition[C]//2016IEEEConferenceonComputerVisionand Pattern Recognition.June27-30,2016,LasVegas,NV,USA.IEEE,2016:770-778.
[7] T. Mikolov, K. Chen, G. Corrado, and J. Dean. (2013).“Efficient estimation of word representations in vector space.”[Online]. Available:https://arxiv.org/abs/1301.3781.
[8] Pennington J,Socher R,Manning C.Glove:global vectors for word representation[C]//Proceedingsofthe2014 Conference on Empirical Methods in Natural LanguageProcessing (EMNLP).Doha,Qatar.Stroudsburg,PA,USA:AssociationforComputational Linguistics,2014:1532-1543.
[9] Zadeh A,Chen M H,PoriaS,etal.Tensor fusion network for multimodal sentiment analysis[C]//Proceedingsofthe2017 Conference on Empirical Methods in Natural LanguageProcessing.Copenhagen,Denmark.Stroudsburg,PA,USA:AssociationforComputational Linguistics,2017:1103-1114.
[10] Peng Y X,Qi J W,Yuan Y X.Modality-specific cross-modal similarity measurement with recurrent attention network[J].IEEE Transactions on Image Processing,2018,27(11):5585-5599.
[11] Mor N,Wolf L,Polyak A,etal.A universal music translation network[EB/OL].2018:arXiv:1805.07848[cs.SD].https://arxiv.org/abs/1805.07848
[12] N. Srivastava and R. Salakhutdinov.“Learning representations for multimodal data with deep belief nets”[C]//in Proc. Int. Conf. Mach. Learn. Workshop, vol. 79, 2012:1-8.
[13] J. Ngiam, A. Khosla, M. Kim, J,et al.‘‘Multimodal deep learning,’’ in Proc. 28th Int. Conf. Mach. Learn., 2011: 689-696.
[14] I. J. Goodfellow et al., “Generative adversarial nets,” in Proc. 27th Int. Conf. Neural Inf. Process. Syst. (NIPS), vol. 2. Cambridge, MA, USA: MIT Press, 2014:2672-2680.
[15] Feng F X,Li R F,Wang X J.Deep correspondence restricted Boltzmann machine for cross-modal retrieval[J].Neurocomputing,2015,154:50-60.
【通聯編輯:梁書】
