基于對抗訓(xùn)練的中文電子病歷命名實體識別
2022-05-11 05:47:34孔令巍朱艷輝歐陽康黃雅淋金書川沈加銳
湖南工業(yè)大學(xué)學(xué)報 2022年3期
關(guān)鍵詞:模型
孔令巍 ,朱艷輝 ,張 旭 ,歐陽康 ,黃雅淋,金書川 ,沈加銳
(1.湖南工業(yè)大學(xué) 計算機(jī)學(xué)院,湖南 株洲 412007;2.湖南省智能信息感知及處理技術(shù)重點(diǎn)實驗室,湖南 株洲 412007)
1 研究綜述
近年來,人工智能的相關(guān)技術(shù)發(fā)展迅速,現(xiàn)已在不同領(lǐng)域中得到了廣泛應(yīng)用。如在醫(yī)療領(lǐng)域中,電子病歷(electronic medical record,EMR)的普及化為疾病的診斷與治療、病歷信息的管理等提供了有效支持。電子病歷是由記錄病人的全部就診檔案所形成的文字、數(shù)據(jù)、醫(yī)療圖像、圖表等一切資料的總和,它具有簡便性、快捷性、環(huán)保性等優(yōu)點(diǎn)。電子病歷不僅能方便醫(yī)務(wù)人員了解患者疾病的發(fā)生、檢查、診斷、治療等醫(yī)療活動,還能在疾病預(yù)防等方面發(fā)揮巨大的作用[1-2]。但是當(dāng)前的電子病歷文本大部分是以非結(jié)構(gòu)化的形式存儲,因而如何快速從電子病歷中提取所需要的信息,是命名實體識別(named entity recognition,NER)技術(shù)在電子病歷文本分析中的重要應(yīng)用。
命名實體識別任務(wù),是指從非結(jié)構(gòu)化的文本中識別出蘊(yùn)含具體涵義的實體,例如電子病歷中的疾病和診斷、檢查、藥物以及手術(shù)部位等,并將之劃分到預(yù)定義的類別中。關(guān)于在命名實體識別任務(wù)中出現(xiàn)的問題,研究者們也曾開展過廣泛的研究。R.Panchendrarajan 等[3]提出了一種包含雙向LSTM(bidirectional long short-term memory ,BiLSTM)和雙向條件隨機(jī)場(bi-directional conditional random fields,Bi-CRF)的神經(jīng)網(wǎng)絡(luò),其利用單詞和字符級別的信息,以及相鄰標(biāo)簽之間的依賴關(guān)系進(jìn)行命名實體識別,該模型在多個數(shù)據(jù)集上被證明是有效的,但是它存在實體邊界檢測不清晰的問題。王若佳等[4]將Bi-LSTM模型應(yīng)用到中文電子病歷上,并在詞的不同標(biāo)注方案下進(jìn)行了實驗對比,取得了不錯的實驗效果,但是其模型存在魯棒性不高的缺點(diǎn)。李綱等[5]通過結(jié)合Word2Vec和外部的詞典資源,對輸入的詞嵌入進(jìn)行了更改,并通過Bi-LSTM-CRF模型,在電子病歷的數(shù)據(jù)集中也取得了較高的F1值,但是其數(shù)據(jù)集存在實體類別不均衡、模型魯棒性較差等缺點(diǎn)。楊文明等[6]提出了加入獨(dú)立循環(huán)神經(jīng)網(wǎng)絡(luò)(indenpendnetly recurrent neural network,IndRNN)的IndRNN-CRF模型和加入膨脹卷積(dilated convolution,DC)的IDCNN-BiLSTM-CRF模型,并通過在線醫(yī)療文本進(jìn)行了命名實體識別,發(fā)現(xiàn)該模型的整體性能都優(yōu)于BiLSTM-CRF模型的。張旭等[7]將SoftLexicon與BiLSTM-CRF相結(jié)合,以引入外部詞典資源方法對電子病歷進(jìn)行命名實體識別,實驗結(jié)果表明,相較于NER傳統(tǒng)方法,所提出的方法在識別性能和效率上均顯著提升。2018年,谷歌[8]發(fā)布了一種新的語言表示模型BERT(bidirectional encoder representation from transformers),它將自然語言任務(wù)的處理結(jié)果推上了更高的階段。此后,Jia C.等[9]提出了一種半監(jiān)督實體增強(qiáng)的BERT預(yù)訓(xùn)練方法,此方法將詞典整合到NER的預(yù)訓(xùn)練中。CCKS2020評測中,晏陽天等[10]通過將BERT與字形字音特征相融合,完成了對電子病歷的命名實體識別。楊文明等[11]通過將ChiEHRBERT與多個不同模型進(jìn)行投票融合,在醫(yī)學(xué)領(lǐng)域的命名實體識別上取得了不錯的成績。
但在上述研究中,詞嵌入層均存在實體邊界檢測不清晰的問題,即位于邊界旁側(cè)的樣本比遠(yuǎn)離邊界的樣本更加容易出現(xiàn)識別錯誤,從而影響模型的實體識別性能,同時,模型的預(yù)測能力以及魯棒性能均不強(qiáng)。為了解決上述問題,本研究提出將對抗訓(xùn)練融合到BERT-BiLSTM-CRF模型中進(jìn)行命名實體識別。
對抗訓(xùn)練是新興起的一門技術(shù),由于早期在自然語言任務(wù)上難以有效生成對抗樣本,所以多數(shù)被應(yīng)用于計算機(jī)視覺領(lǐng)域中。近年來,隨著對抗樣本相關(guān)問題的解決,對抗訓(xùn)練在自然語言的各個方面都漸有成效。C.Szegedy等[12]首次提出對抗樣本(adversarial examples)的概念,旨在數(shù)據(jù)集中添加一些細(xì)微的干擾,從而形成對抗樣本。I.J.Goodfellow等[13]設(shè)計了一種快速生成對抗樣本的方法(fast gradient sign method,F(xiàn)GSM),該方法簡單可行,并且可以利用該攻擊方法產(chǎn)生的對抗樣本再次進(jìn)行對抗訓(xùn)練,它系統(tǒng)地闡釋了對抗樣本的存在性、攻擊性、防御方法3個方面,該方法之后被廣泛應(yīng)用于各領(lǐng)域中。Zhang H.Z.等[14]提出MHA(master high availability)算法,它基于Metropolis-Hastings算法的采樣法來生成對抗樣本。T.Miyato等[15]又在FGSM的計算擾動部分做了一些修改,并根據(jù)具體的梯度進(jìn)行標(biāo)準(zhǔn)化,從而得到了更好的對抗樣本,但存在其實驗所花費(fèi)的時間會大幅度增加的缺點(diǎn);A.Madry等[16]提出了PGD(projected gradient descent)模型,該模型通過多次迭代,以“小步走,走多次”的策略找到最優(yōu)擾動。董哲等[17]融合了BERT和對抗訓(xùn)練,從而在食品領(lǐng)域進(jìn)行命名實體識別,提高了識別實體邊界的精準(zhǔn)率。
本研究擬將對抗訓(xùn)練融合到BERT-BiLSTM-CRF模型中,并通過對抗訓(xùn)練,在詞嵌入層加入擾動因子,生成的對抗樣本可以增強(qiáng)模型的抗干擾能力,從而提高模型的魯棒性和預(yù)測能力,解決了模型中魯棒性不強(qiáng)的問題。
2 基于對抗訓(xùn)練的中文電子病歷實體識別模型
2.1 基于對抗訓(xùn)練的實體識別模型
本研究基于對抗訓(xùn)練的模型結(jié)構(gòu)由Embedding層、BiLSTM層和CRF層3部分組成,如圖1所示。中文電子病歷數(shù)據(jù)在進(jìn)入深度學(xué)習(xí)模型之前,先將分字后的文本經(jīng)預(yù)訓(xùn)練語言模型BERT轉(zhuǎn)換為對應(yīng)的字向量表示。以圖1中的“膽囊多發(fā)結(jié)石”為例,其中每個字都被處理為字向量,然后將對抗訓(xùn)練的擾動因子與字向量相加得到對抗樣本,并將對抗樣本送到BiLSTM神經(jīng)網(wǎng)絡(luò)中。經(jīng)前向傳播和反向傳播獲取序列的特征,隨后通過CRF層學(xué)習(xí)序列標(biāo)簽的約束信息,最后得到正確的序列標(biāo)簽。

圖1 基于對抗訓(xùn)練的模型結(jié)構(gòu)Fig.1 Model structure based on adversarial training
圖1中,“[CLS]膽囊多發(fā)結(jié)石[SEP]”為輸入的文本序列,Ei(i=1~8)為輸入離散的字轉(zhuǎn)換為連續(xù)的字向量表示,ri(i=1~8)為字向量層的擾動。
2.2 BERT模型
BERT是基于深度學(xué)習(xí)的網(wǎng)絡(luò)架構(gòu),它通過預(yù)訓(xùn)練,從大量文本中獲取了語義和語法的基礎(chǔ)知識,解決了自然語言處理任務(wù)中詞與詞之間顆粒度不同、指代現(xiàn)象,以及詞的理解依賴于上下文等問題。其中,BERT模型創(chuàng)新性地給出了MLM(masked language model)和NSP(next sentence prediction)2個任務(wù),各自捕獲詞級別和句級別的表達(dá),并進(jìn)行聯(lián)合訓(xùn)練。MLM主要用于訓(xùn)練深度雙向語言的表示向量,方法為遮住句子中的某些詞匯,讓解碼器預(yù)測此單詞的原始詞匯。NSP是指通過預(yù)訓(xùn)練一個二分類的語句模塊來學(xué)習(xí)語句之間的關(guān)聯(lián),具體是讓模型學(xué)習(xí)區(qū)分訓(xùn)練語句中的兩個輸入語句之間是否為連續(xù)片段。本研究中建立的BERT預(yù)訓(xùn)練語言模型的網(wǎng)絡(luò)結(jié)構(gòu),如圖2所示。

圖2 BERT預(yù)訓(xùn)練語言模型的網(wǎng)絡(luò)結(jié)構(gòu)圖Fig.2 Network structure diagram of BERT pre-training language model
BERT預(yù)訓(xùn)練語言的輸入是電子病歷中的每一個字符,而輸出則是每個字符所對應(yīng)的特征向量。特征向量由字向量、句子的切分向量和位置向量相加得出。模型的輸入如圖3所示,第一個位置的符號[CLS]和最后一個位置的符號[SEP]分別代表輸入序列的開始位置和結(jié)束位置。例如輸入的文本是“病人患有膽結(jié)石”,經(jīng)標(biāo)記處理就變成“[CLS]病人患有膽結(jié)石[SEP]”,這兩個特殊字符將在分類和劃分句子中起到作用。

圖3 BERT模型輸入示例Fig.3 BERT model input samples
在BERT中,字嵌入層是將每個字轉(zhuǎn)化為768維的向量表示,并且文本在輸入到字嵌入層之前,會進(jìn)行標(biāo)記化處理,即在文本的開頭和結(jié)尾處插入兩個特殊的標(biāo)記——[CLS]和[SEP],分字后的文本通過字嵌入層轉(zhuǎn)換為對應(yīng)的向量表示。切分嵌入層主要用來區(qū)別兩種句子,即判斷兩個句子的先后順序,前一個句子的標(biāo)記都用A表示,后一個句子的標(biāo)記都用B表示。位置嵌入層則是用來對序列中的每個標(biāo)記進(jìn)行編號,用以記錄每個標(biāo)記的位置信息,同時每個編號都對應(yīng)一個向量。在BERT的一條序列語句中,如果其長度被設(shè)置為512,那么位置嵌入層的向量表示為(512,768),位置向量的計算公式如式(1)和式(2)所示。最后,將這3個嵌入層相加,即可以得到其特征向量。

式(1)(2)中:i為電子病歷中字的維度;
pos為字所在位置;
dmodel為編碼后的向量維度。
本文選用BERT來獲取輸入向量表示而非傳統(tǒng)Word2VEC的原因,在于BERT提高了詞與詞之間的聯(lián)系性和表達(dá)性,在Word2VEC中,詞向量的表達(dá)是靜態(tài)的,即一個詞無論在何種上下文環(huán)境中,它的向量表示都是相同的。而由于BERT的向量表示中包含了關(guān)于周圍詞的信息,在截然不同的上下文環(huán)境中,對這個詞向量的表示方式也是截然不同的,即是動態(tài)的。因此,BERT為進(jìn)行對抗訓(xùn)練提供了更加全面的詞向量表達(dá)。
2.3 對抗訓(xùn)練
對抗訓(xùn)練(adversarial training)是一種引入噪聲的規(guī)范化監(jiān)督學(xué)習(xí)方法,用于提高分類器對于樣本數(shù)量小或者有損壞情況的樣本魯棒性。該方法通過在嵌入層的字向量中添加一些較小的干擾,而不是在對原始輸入的樣本本身加以干擾,將獲得的對抗樣本再饋送給模型。對抗訓(xùn)練也可以認(rèn)為是在加入擾動后的對抗樣本下,預(yù)測出真實標(biāo)簽的概率,對抗訓(xùn)練的定義可簡化為如下公式 :

式中:y為真實標(biāo)簽;
x為原始樣本;
Δx為添加的擾動;
θ為模型參數(shù);
p為增加擾動后預(yù)測真實標(biāo)簽的概率。
在實驗中,醫(yī)療文本“膽囊多發(fā)結(jié)石,入院予以治療”,經(jīng)過BERT預(yù)訓(xùn)練語言模型生成對應(yīng)的字向量,然后根據(jù)字向量、字向量對應(yīng)標(biāo)簽及模型參數(shù)計算出擾動值,將擾動值與字向量相加即可得到對抗樣本。其中,常見的擾動計算方法有兩種,其一為FGM(fast sign method)法,具體思路以輸入序列的嵌入向量x=[v1,v2, …,vt](式中v為字向量,t為字的位置下標(biāo))為例,首先復(fù)制預(yù)訓(xùn)練階段的詞向量字典,計算出x的梯度,并且根據(jù)梯度作標(biāo)準(zhǔn)化處理得到擾動值Δx,擾動值的計算公式如式(4)所示;隨后將得到的擾動值與x相加,用新的詞向量重新求出其梯度,并累加到原梯度上,然后根據(jù)此時的梯度對參數(shù)進(jìn)行更新。

式中:ε為一個縮放因子;
g為損失函數(shù)關(guān)于x的偏導(dǎo),即梯度,且

其中,L(x,y,θ)為損失函數(shù)。
2.3.1 FGM算法描述
對于數(shù)據(jù)集中的x:
1)計算x的前向損失、反向傳播得到梯度;
2)通過embedding矩陣的梯度算出Δx,并加在當(dāng)前embedding上,結(jié)果相當(dāng)于是x+Δx;
3)計算x+Δx的前向損失,反向傳播得到對抗的梯度,累加到1)的梯度上;
4)將embedding恢復(fù)為1)時的值,并根據(jù)3)的梯度對參數(shù)進(jìn)行更新;
5)重復(fù)以上過程,直到模型訓(xùn)練全部完成。
FGM的思路是梯度上升,但是由于它的跨步大,有可能無法找到約束內(nèi)的最優(yōu)點(diǎn);相較于FGM來說,PGD進(jìn)行數(shù)次迭代,運(yùn)用“小步走”的策略,從而找到最優(yōu)解。PGD的擾動值計算公式如式(6)和式(7)所示。

式(6)(7)中:
α為步長;
xt、xt+1分別為前一次和后一次的詞向量。
2.3.2 PGD算法描述
1)對于數(shù)據(jù)集中的x,通過計算x的前向損失以及反方向傳播,獲得梯度并備份;
2)對于每步k,通過embedding矩陣的梯度計算出Δx,并且加到當(dāng)前的embedding上,就相當(dāng)于x+Δx;
3)如果k不是最后一步,則將梯度歸零,根據(jù)1)的x+Δx計算前向和后向的梯度;
4)如果k是最后一步,則恢復(fù)1)的所有梯度,計算最后的x+Δx,并把所有梯度累加到1)上;
5)將embedding恢復(fù)為1)時的值,并根據(jù)4)的梯度對參數(shù)進(jìn)行更新;
6)重復(fù)以上過程,直到模型訓(xùn)練全部完成。
2.4 BiLSTM網(wǎng)絡(luò)
LSTM(long short-term memory)模型是一種RNN(recurrent neural network)模型,它是對Simple RNN的改進(jìn),同時LSTM模型通過門控制單元避免了梯度爆炸。相比RNN來說,LSTM對于輸入中長期依賴的信息擁有更優(yōu)秀的表達(dá),單個LSTM神經(jīng)元及其運(yùn)行機(jī)制如圖4所示。
美國學(xué)者Tamanaha在闡述法治的作用時說:“法治不是有關(guān)人民寄希望于政府的任何美好事物。對它作這種解讀的終極誘惑是法治具有象征性力量的實際證明,但我們不能沉迷于它。”[16]對“法不禁止皆自由”這條奉為圭臬的法治原則亦應(yīng)當(dāng)辯證地看待,缺乏法律邊界的自治并非解決任何問題的靈丹妙藥。政府對網(wǎng)約車的管理正體現(xiàn)了自由狀態(tài)下的適度管制,網(wǎng)約車管理領(lǐng)域適用負(fù)面清單模式并非完全照搬,也需要因地制宜、適度修正。
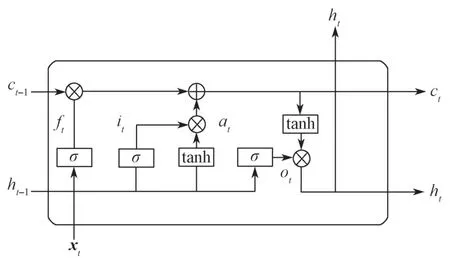
圖4 LSTM內(nèi)部結(jié)構(gòu)示意圖Fig.4 LSTM internal structure diagram
LSTM模型的遺忘門、輸入門、輸出門,以及隱藏狀態(tài)的計算公式分別如下:

式(8)~(12)中:xt為t時刻的輸入;
ht-1為t-1時刻的隱藏層狀態(tài)值;
Wf、Wi、Wo、Wa分別為遺忘門、輸入門、輸出門以及在特征提取過程中ht-1的權(quán)重系數(shù);
Uf、Ui、Uo、Ua分別為遺忘門、輸入門、輸出門以及在特征提取過程中xt的權(quán)重系數(shù);
bf、bi、bo和ba分別為遺忘門、輸入門、輸出門以及在特征提取過程中的偏置值;
由于遺忘門和輸入門計算的結(jié)果作用于c(t-1),構(gòu)成t時刻的細(xì)胞狀態(tài)c(t)表示為

最終t時刻的隱藏層狀態(tài)h(t),可由輸出門o(t)和當(dāng)前時刻的細(xì)胞狀態(tài)c(t)求出:

由于LSTM只能保留處理過的信息,但是在序列標(biāo)注任務(wù)中,上下文的信息同樣重要,于是提出在原本的模型結(jié)構(gòu)上再加上一層反向的LSTM,從而組成BiLSTM,如此,便可以對上下文同時進(jìn)行信息處理。在本實驗中,經(jīng)Embedding層得到的對抗樣本分別以正序和逆序方式被注入到LSTM中,然后將兩個輸出的特征向量加以拼接,作為最后的特征向量表達(dá)式。
2.5 CRF層
在本實驗中,BiLSTM層輸出的特征向量經(jīng)由CRF層確定最終的輸出標(biāo)簽,即“膽:B-PAT”、“囊:I-PAT”、“多:O”等。CRF層相較于BiLSTM層,不僅能確保輸出標(biāo)簽之間的關(guān)系,而且會在標(biāo)簽之間創(chuàng)造規(guī)則,起到了約束作用。對于每一個序列的輸入x,得到了預(yù)測標(biāo)簽序列y,定義預(yù)測得分函數(shù)S的表達(dá)式如下:

此函數(shù)有效彌補(bǔ)了BiLSTM的不足,對標(biāo)簽之間的關(guān)系起到約束作用,如在一個以人名為實體的例子中,I-Person不能存在于B-person前。隨后對每個訓(xùn)練樣本X,求出代表每個可能性的標(biāo)注序列y的分?jǐn)?shù)S,并且對每個分?jǐn)?shù)進(jìn)行歸一化處理,公式如式(15)所示:

式中:y為正確的標(biāo)注序列;
YX為所有出現(xiàn)的標(biāo)簽序列。
然后,利用對數(shù)似然法求出它的損失函數(shù):
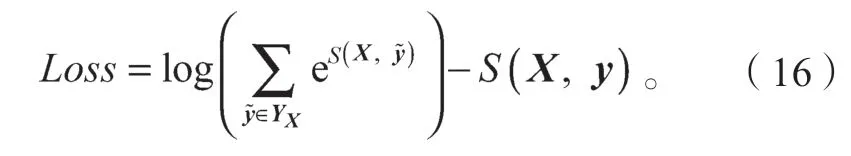
隨后,用梯度下降法進(jìn)行網(wǎng)絡(luò)學(xué)習(xí),更新參數(shù),直到訓(xùn)練結(jié)束。
預(yù)測時,通過訓(xùn)練好的參數(shù)求出每個可能的y序列所對應(yīng)的S得分,本文在此處采用維特比算法,算出最高概率標(biāo)簽序列y*。

3 實驗設(shè)計與結(jié)果分析
3.1 中文電子病歷數(shù)據(jù)集
為了能更加全面地評估本文中對抗訓(xùn)練模型的效果,在兩個數(shù)據(jù)集上對模型進(jìn)行相關(guān)實驗。其一為CCKS2021面向中文電子病歷的醫(yī)療實體以及事件抽中任務(wù)一的數(shù)據(jù)集,以下簡稱為數(shù)據(jù)集1 ;另一個數(shù)據(jù)集同樣為醫(yī)療電子病歷數(shù)據(jù),不同的是,相比于數(shù)據(jù)集1,其中“疾病和診斷”與“解剖部位”兩類數(shù)據(jù)略多于其它4類數(shù)據(jù),此數(shù)據(jù)集各類別的數(shù)據(jù)分布更加均勻,以下簡稱為數(shù)據(jù)集2。CCKS(China Conference on Knowledge Graph and Semantic Computing)評測目的是為了建立檢測知識圖譜與語義計算相關(guān)技術(shù),以及軟件系統(tǒng)的網(wǎng)絡(luò)平臺與信息資源,而本次CCKS2021的實體識別任務(wù)是環(huán)繞中文電子病歷語義化展開的系列評測的一種擴(kuò)展,它是在CCKS2020評測任務(wù)的基石上做出的繼續(xù)與擴(kuò)充。數(shù)據(jù)集1具體標(biāo)注有實體的起始位置和終止位置,以及預(yù)定義類別,其類別依次為疾病和診斷、檢查、檢驗、手術(shù)、藥物、解剖部位等6種,具體的類別定義參考表1。

表1 CCKS2021預(yù)定義實體類型Tabel 1 CCKS2021 predefined entity categories
數(shù)據(jù)的標(biāo)注方法為BIO 三位標(biāo)注法,即B-X代表實體的開頭,I-X代表實體的結(jié)尾,O代表不屬于任何類型的非實體。數(shù)據(jù)集1有1 500條數(shù)據(jù),數(shù)據(jù)集2與數(shù)據(jù)集1的標(biāo)注方法以及預(yù)定義類別相似,共有1 300條數(shù)據(jù)。將各數(shù)據(jù)集中的數(shù)據(jù)按照6∶2∶2的比例,劃分為訓(xùn)練集、驗證集和測試集,具體的劃分情況參見表2。

表2 實驗數(shù)據(jù)集的劃分Table 2 Experimental data division
3.2 評價指標(biāo)
此次實驗采用精確率P(precision)、召回率R(recall)和F1值為主要評價指標(biāo)。精確率又稱查準(zhǔn)率,是指實際預(yù)測正確的標(biāo)簽數(shù)量占全部預(yù)測正確標(biāo)簽的比率;召回率又稱查全率,是指實際預(yù)測正確標(biāo)簽占全部正確標(biāo)簽的比率;F1值則是精確率與召回率之間的調(diào)和平均值。各指標(biāo)的計算公式如(18)~(20)所示。

式(18)~(20)中:
TP為序列中實際預(yù)測正確的標(biāo)簽;
FP為實體為非正確標(biāo)簽卻被預(yù)測為正確的標(biāo)簽;
FN為實體為正確標(biāo)簽卻被預(yù)測為非正確的標(biāo)簽。
3.3 實驗環(huán)境及參數(shù)設(shè)置
本次實驗環(huán)境如下:操作系統(tǒng)為Ubuntu 16.04 LTS,CPU i7-10750H@2.60 GHz,內(nèi) 存 為8 GB,GPU NVIDIA Geforce RTX2080Ti,Python3.8,Pytorch1.6.0+cu101。
本次實驗的參數(shù)設(shè)置如下: BiLSTM隱藏層單元數(shù)為768,Batch_size為8,學(xué)習(xí)率設(shè)置為0.000 1,Epoch為40。
3.4 實驗方案
為了驗證對抗訓(xùn)練在中文電子病歷上命名實體識別的表現(xiàn),將BERT-BiLSTM-CRF、BERT-FGMBiLSTM-CRF、BERT-PGD-BiLSTM-CRF模型分別在數(shù)據(jù)集1和數(shù)據(jù)集2上進(jìn)行實驗,具體實驗步驟如表3所示。

表3 實驗設(shè)計方案Table 3 Experimental design scheme
3.5 實驗結(jié)果與分析
根據(jù)上述實驗方案,得到的各實驗方法下的數(shù)據(jù)集識別結(jié)果如表4所示。

表4 實驗結(jié)果對比Table 4 Comparison of experimental results %
分析表4中的實驗數(shù)據(jù)可以得知,相對于基線模型BERT-BiLSTM-CRF,基于對抗訓(xùn)練的BERTFGM-BiLSTM-CRF模型和BERT-PGD-BiLSTM-CRF模型,它們在兩個數(shù)據(jù)集上的實體識別效果、識別精度均有不同程度的提升,其中加入FGM的實體識別模型,其F1值在兩個數(shù)據(jù)集上分別提升了約0.86%和0.62%;而加入PGD方法的實體識別模型,其F1值在兩個數(shù)據(jù)集上分別提升了約1.05%和0.93%,由此可見,加入了PGD法的模型的識別效果要略優(yōu)于加入FGM法的模型。究其原因,很可能是由于這兩種對抗訓(xùn)練迭代攻擊的次數(shù)不同,F(xiàn)GM只進(jìn)行了一次迭代,而PGD是一種迭代攻擊的方法,它進(jìn)行了多次迭代,并且每次迭代都將擾動投射到規(guī)定范圍內(nèi),從而造成了結(jié)果上的差異。
加入了FGM法和PGD法的模型在面對輸入數(shù)據(jù)的微小變動時,依然能夠保持高精度的識別效果,而且本文模型不只在一個特定的數(shù)據(jù)集上保持良好的識別效果,對于新數(shù)據(jù),它依然能夠保持敏感性,說明加入對抗訓(xùn)練的模型在面對數(shù)據(jù)變化時依然能夠保持其穩(wěn)定性及魯棒性。
綜上所述,加入對抗訓(xùn)練的模型能夠提升命名實體識別在中文電子病歷上的準(zhǔn)確性以及模型的穩(wěn)定性,同時對于實體標(biāo)簽的預(yù)測能力也相應(yīng)提高。
4 結(jié)語
為了進(jìn)一步提高命名實體識別在中文電子病歷上的精確率,本文提出了加入FGM和PGD對抗訓(xùn)練方法的命名實體識別模型,該方法在中文電子病歷評測任務(wù)中達(dá)到了良好的成效。但是中文電子病歷的命名實體識別尚有較大的改善空間,在后續(xù)研究中可從如下方面著重加以完善:
1)由于中文電子病歷中存在大量的專有詞匯,導(dǎo)致識別困難,可加入專有醫(yī)療詞典提升實體識別對于專業(yè)醫(yī)療詞匯的識別率;
2)加入對抗訓(xùn)練的模型普遍具有需要花費(fèi)較長時間的特點(diǎn),后續(xù)將研究更有效的方法,以提升模型的識別效率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(2021年2期)2021-07-19 08:35:14
新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
