大數據可視化系統在智慧城市領域的設計與應用
2022-05-19 00:46:37李宇陳丹紅鞏震李科慧
消費電子 2022年2期
李宇 陳丹紅 鞏震 李科慧
科技在發展,社會在進步,各類智能產品層出不窮,人們對生活質量的便捷舒適度要求也越來越高,智慧城市的建設已成為大勢所趨,對于數據的自主學習和可視化的城市運行全景圖也逐漸成為主流。無論對企業還是居民個人,直觀的數據展示為城市居民提供了清晰的認知,調動全民為城市建設作出積極的行動,提高其“主人翁”意識,發揮群眾自主性,共同為城市的發展做出貢獻和努力,這也是智慧城市大數據可視化的魅力所在。隨著人類社會的不斷地發展,未來城市面對的大數據處理將會越來越多。大數據可視化系統在智慧城市領域的應用,不僅有利于解決城市發展中存在的問題,還可以拉動國民經濟和產業發展結構戰略性調整,提高人們生活的效率,促進社會快速的發展,最終實現企業的可持續發展。本文運用信息通信技術手段構建智慧城市大數據可視化系統,將政府、企業和居民感興趣的信息三維化呈現在大眾視野,從而達到對城市的智能管理。
首先,構建智慧城市大數據可視化系統網絡時,本文選擇使用注意力機制。注意力機制來源于人的視覺系統,人在注意一樣事物時是有選擇性的,一般來說,會先提取關鍵詞來進行處理,基于注意力機制的智慧城市大數據可視化平臺可以以端到端的方式自動學習,更多關注計算中的重點問題。其次,對于可視化的圖片成像來說,編碼和解碼是必不可少的任務。在初始階段,輸入一個初始向量,用卷積神經網絡進行編碼,解碼可以采用注意力機制的循環神經網絡,提高機器自主學習能力。智慧城市大數據可視化系統網絡的一個詳細運行過程見圖1。
(一)矩陣分解算法
矩陣分解算法的意義在于提高計算速度。本文對城市中每個居民和項目構建一個向量因子模型,由k維向量表示,其中每個分量代表居民在一個因子上的偏好程度或者項目在一個因子上的側重程度。而在矩陣分解中,評分矩陣是很重要的,為此本文可以構建:
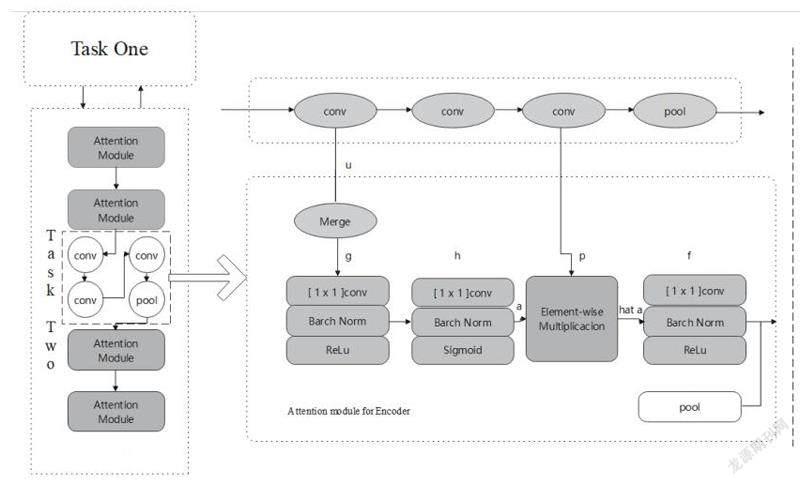
圖1 系統網絡結構設計圖
用戶對項目的評分矩陣是M,用戶因子矩陣是U,項目因子矩陣V,則矩陣分解算法可表示為:M=UV
實現該矩陣分解,轉變為解下面的最優化問題:

(三)交替下降算法
交替下降算法的實質就是先固定一個變量,使函數對另外一個變量求偏導,更新其變量,接著對更新后的變量進行固定,使函數對另一變量求偏導,再更新。如此反復交替

大數據可視化決策系統在智慧城市領域進行實驗與應用。本文采用動態權重平均法,獲得表1的結果。
從表格中可以看出,利用動態加權平均算法可以很好地適用于各種前饋型神經網絡。從這個結果可以看出,動態加權平均算法會是未來智慧城市可視化發展的一個很好的趨勢。
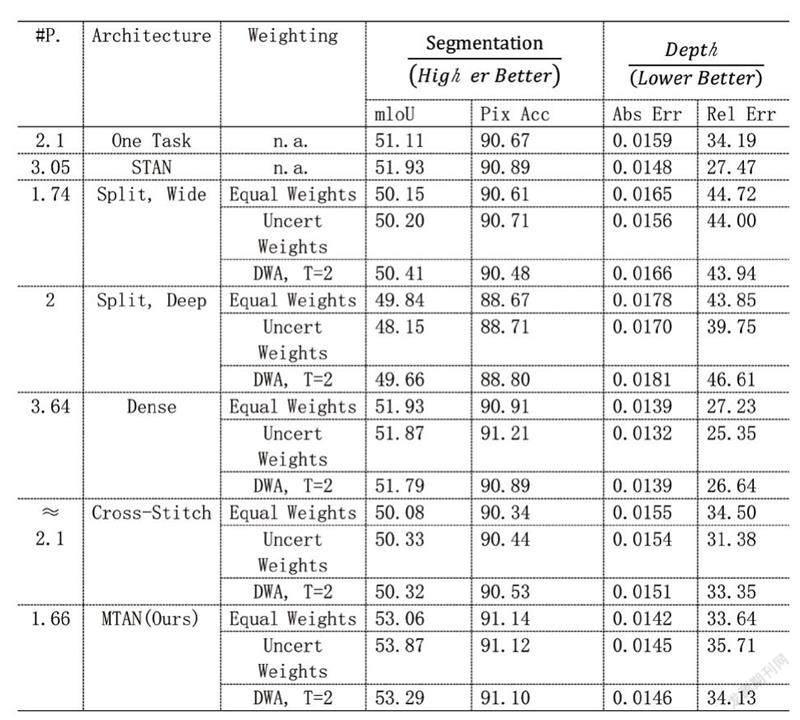
表1 動態權重平均實驗結果
隨著人類社會的不斷地發展,未來城市面對的大數據處理將會越來越多。大數據可視化系統在智慧城市領域進行應用,不僅有利于解決城市發展中存在的問題,也可以拉動國民經濟和產業發展結構戰略性調整,提高人們生活效率、促進社會快速發展以及實現企業的可持續發展。智慧城市大數據可視化系統是運用信息通信技術手段,對一個城市內部運行的各項關鍵信息進行統計計算進而整合信息,從而對政府、企業和居民的各項需求作出便捷的響應。其實質是利用先進的信息技術,將二維數據三維化呈現在大眾視野,從而達到對城市的智能管理,為城市中生活的人創造更高效美好的生活,促進城市的可持續發展。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
世界科學技術-中醫藥現代化(2022年3期)2022-08-22 00:32:50
云南化工(2021年8期)2021-12-21 06:37:54
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
傳媒評論(2019年4期)2019-07-13 05:49:14
家庭影院技術(2017年9期)2017-09-26 03:41:45
小天使·一年級語數英綜合(2014年6期)2014-07-22 23:32:38
智慧與創想(2013年7期)2013-11-18 08:06:04
