融合異質信息網絡表示學習的跨領域推薦研究
2022-05-19 06:58:26馮翠翠
情報學報 2022年4期
易 明,劉 明,馮翠翠
(華中師范大學信息管理學院,武漢 430079)
1 引 言
當前,個性化推薦的應用主要局限在單一領域,即:根據某一領域(如圖書領域、音樂領域等)的用戶數據獲取其興趣偏好,并據此開展面向該領域的個性化推薦。然而,單一領域的個性化推薦不可避免地受到數據“稀疏性”和用戶“冷啟動”等問題的影響。事實上,很多互聯網平臺所涉及的領域是多樣化的。以豆瓣網為例,它同時涉及書籍、電影、音樂等多個領域,由此會產生不同領域的用戶數據。不同領域的用戶數據并不都是隨機的,可能會蘊含著許多潛在的模式,例如,喜歡推理類圖書的用戶,可能也對推理類電影非常感興趣。這種在不同領域內具有潛在相似的模式使得跨領域推薦成為可能。所謂跨領域推薦就是利用源領域的用戶數據實現目標領域的個性化推薦,其本質就是將源領域已有的知識遷移到目標領域,一方面可以緩解目標領域數據“稀疏性”、用戶“冷啟動”等問題,另一方面可以構建更為優化的推薦模型。現有的大部分跨領域推薦的工作都只使用了用戶對物品的評分信息。在領域評分數據高度稀疏的情況下,僅利用評分信息無法有效識別用戶的真實興趣偏好,尤其是在領域內用戶完全沒有數據的情況下,很可能導致跨領域推薦知識遷移的偏差以及“負遷移”的狀況。除了評分信息以外,現實世界還存在大量的物品特征信息,利用這些特征信息可以捕捉用戶高階的潛在偏好,進而提高跨領域推薦中知識遷移的效果。然而,這種復雜的高階特征關系往往難以建模。考慮到異質信息網絡表示學習可以將領域內的各種實體映射為低維稠密的向量進行輸出,且能夠捕捉到這種高階相似,對跨領域推薦中知識遷移具有較好的適用性,因此,本文試圖將異質信息網絡表示學習與跨領域推薦有機融合,并開展相應的研究探索。本文的主要貢獻如下:
(1)優化了聯合矩陣分解。傳統的聯合矩陣分解在跨領域推薦場景中共享了用戶的潛在因子,導致提取到的用戶特征沒有體現出充分的領域性,從而出現“負遷移”,為此本文利用神經網絡實現聯合矩陣分解,通過“映射函數”將用戶特征映射到不同領域,體現領域間的差異性。
(2)提出了一種新的跨領域推薦方法。該方法同時利用評分信息和特征信息,在神經網絡優化聯合矩陣分解的基礎上,融合了異質信息網絡表示學習的高階特征,從而達到充分利用領域知識的目的,有效緩解了單領域推薦中存在的數據“稀疏性”和用戶“冷啟動”問題。
2 相關研究
2.1 跨領域推薦
跨領域推薦的實質就是借助源領域用戶數據優化目標領域的推薦性能。從目前的研究現狀來看,具體的優化路徑主要包括緩解數據“稀疏性”和用戶“冷啟動”兩個方面。
在緩解數據“稀疏性”問題方面,Berkovsky等[1-2]將多個領域的評分矩陣直接合并,從而在推薦過程中引入了更多的領域信息,進而利用協同過濾完成跨領域推薦;Li 等[3]對源領域用戶和物品分別進行聚類,通過引入“密碼書”形成聚類后的“濃縮矩陣”,由此將源領域的知識遷移到數據稀疏的目標領域;Singh 等[4]提出了將相關聯的矩陣進行聯合分解的方法,從而使矩陣分解適用于跨領域推薦,通過聯合矩陣分解獲取不同領域間的潛在特征,有助于解決目標領域的數據“稀疏性”;陳文珺等[5]利用領域中的用戶-物品評分矩陣,分別對多領域用戶和物品進行潛在特征提取,并將用戶-物品特征向量分別進行特征聚類,同時對多領域特征矩陣進行領域適應融合,得到共享知識模型并進行遷移學習,提高了目標領域推薦性能;Zhu 等[6]提出了一種基于遷移學習和深度學習的跨領域推薦方法,在評分矩陣分解的基礎上利用深度學習映射不同域的特征,并用域內評分稀疏性指導參數的學習;Gao 等[7]將注意力機制引入跨領域推薦,以項目級注意力層和域級注意力層區分不同項目以及領域的重要性;Hu 等[8]和 He 等[9]提出的 CoNet(cross networks) 利 用 NCF (neural collaborative filtering)組成三個隱層和兩個交叉單元,其中NCF 是矩陣分解在神經網絡上的廣義擴展,因此,CoNet 充分利用了用戶和物品之間的非線性交互關系;Vijaiku‐mar 等[10]改進了 CMF (collective matrix factorization),并用堆棧自編碼器優化領域內用戶和物品的特征表示,使模型同時具有矩陣分解和深度學習的優點。
在緩解用戶“冷啟動”問題方面,Kazama 等[11]通過構建用戶對物品的評分網絡,利用word2vec 得到不同領域用戶的特征向量,然后學習一個線性映射函數將源領域用戶特征映射到目標領域,從而可以完成目標領域“冷啟動”用戶的推薦;Man 等[12]提出的 EMCDR (embedding and mapping framework for cross-domain recommendation) 算法通過評分矩陣進行矩陣分解得到特征向量,進而利用多層感知機學習了重疊數據的非線性映射,取得了比之前線性映射更好的效果。
由上文不難發現,目前大多數跨領域推薦算法主要利用的是評分信息,而對于源領域和目標領域所包含的其他特征信息,如電影的導演、圖書的作者等,都沒有充分融入跨領域推薦算法。評分信息的“稀疏性”是個性化推薦中無法避免的問題,過于稀疏的信息會導致用戶興趣識別的偏差,進而降低推薦效果。在跨領域推薦中也是如此,雖然能夠通過知識遷移獲取其他領域的知識,但領域內興趣識別的不充分性會增加知識遷移的誤差。解決此問題的關鍵是將領域內實體之間的相似性進行高階擴散,從簡單的一階關系擴展為高階關系。特征信息可以作為相似性擴散的橋梁,從不同的特征角度出發,獲取具有不同語義的相似性度量,能夠有效緩解興趣識別偏差問題,有利于提高跨領域推薦知識遷移的準確性。
2.2 網絡表示學習
網絡表示學習是一種將網絡中節點的結構信息和屬性信息用低維稠密向量形式表示的一種技術。傳統的網絡表示一般使用高維的稀疏向量,但高維稀疏向量在使用統計學習方法時存在諸多局限,學者們轉而探索將網絡中節點表示為低維稠密的向量表示的方法[13]。Perozzi 等[14]提出的 DeepWalk 算法通過隨機游走的方式產生訓練語料,利用word2vec的思想,學習節點表示。Grover 等[15]在DeepWalk 的基礎上提出了node2vec,并引入了偏置參數,在隨機游走的過程中運用了寬度優先搜索和深度優先搜索的策略,指導語料的生成。然而,DeepWalk 和node2vec 都只考慮了一階相似性。Tang 等[16]提出的LINE(large-scale information network embedding)算法考慮了二階相似性,認為兩個節點的共享鄰居越多,則兩個節點存在的相似性越高,并利用不同的目標函數保存網絡的一階相似性和二階相似性;Wang 等[17]提出的SDNE (structural deep network em‐bedding)算法將有監督學習的拉普拉斯矩陣和無監督學習的自編碼器進行結合,分別捕捉一階相似性和二階相似性,提出了一種半監督學習方法來學習節點的表示。然而,這些經典的網絡表示學習方法都只針對同質網絡。
異質信息網絡是一種特殊類型的網絡,由多種類型的節點、鏈接關系以及屬性信息組成,具有大規模、異質性等特點[18]。針對異質信息網絡,學者們提出了相應的網絡表示學習方法。Chang 等[19]針對不同類型的節點進行向量表示,然后將所有的向量映射到相同的空間,從而讓向量有了相同維度的表達。Dong 等[20]提出了metapath2vec 算法,先通過元路徑指導隨機游走,再用Skip-Gram 訓練節點序列產生節點嵌入向量。在元路徑的基礎上,Zhang等[21]提 出 的 MetaGraph2Vec 算法 ,以 及 Zhao 等[22]提出的FMG(factorization machine with group)算法,利用元圖的方法代替元路徑,彌補了元路徑不能獲取部分語義的缺陷。Fu 等[23]提出了HIN2Vec 算法,采用完全的隨機游走的策略選取訓練集,通過神經網絡模型預測兩個節點是否存在特定的關系,同時學習異構網絡中節點和元路徑的向量表示。異質信息網絡表示學習的優越特性使其在各種場景都得到了廣泛的應用。例如,劉云楓等[24]構建由作者、論文、出版物等節點組成的異質信息網絡,利用元結構提取語義,有效提高了學者推薦的準確性;林原等[25]構建了作者-作者、作者-機構、作者-關鍵詞、機構-關鍵詞的異質信息網絡,利用DeepWalk 得到節點低維向量,最后通過向量的相似度計算實現合作對象、合作領域挖掘;Zheng 等[26]通過元路徑提取異質信息網絡中的多種相似性,通過將相似性加入損失函數的正則項,提高了推薦算法的準確性;Shi 等[27]在傳統矩陣分解的基礎上,加入了異質信息網絡表示學習的特征向量,取得了比傳統矩陣分解更好的效果;肖璐等[28]用網絡表示學習的方法將網絡中的知識單元表示成低維稠密的向量,其中知識單元網絡可以視為一個異質信息網絡,最后以丁香園心血管論壇為例,挖掘了社區網絡中多元知識的聯系。
針對當前跨領域推薦存在的一些問題,利用異質信息網絡表示學習,可以得到用戶和物品的嵌入向量,不僅保存了異質網絡的結構特征,而且低維稠密的向量能夠很好地完成推薦任務。更重要的是,通過異質網絡表示學習得到的低維稠密向量包含了領域中豐富的特征信息,將這些特征信息在源領域和目標領域加以利用,可以同時達到緩解數據“稀疏性”和用戶“冷啟動”的目的。
3 融合異質信息網絡表示學習的跨領域推薦模型
基于上文的分析,本文提出一種融合異質信息網絡表示學習的跨領域推薦模型。該模型主要由兩個模塊組成:異質信息網絡表示學習和評分預測。其中,異質信息網絡表示學習模塊提供一個異質網絡表示學習框架(如圖1 所示),可以針對源領域異質信息網絡和目標領域異質信息網絡,通過元路徑、DeepWalk 算法生成網絡表示學習向量,獲取領域內的特征信息。評分預測是跨領域推薦的核心模塊,此部分由一個復雜的神經網絡架構組成,在神經網絡中借用了聯合矩陣分解(CMF)[4]的思想,以此獲取領域內的評分信息。具體來說,神經網絡共享了源領域和目標領域的用戶嵌入,用多層感知機(multilayer perceptron,MLP) 將共享用戶嵌入映射到不同領域,一方面體現了用戶在不同領域的差異性,另一方面對于在某一領域有數據而在另一領域沒有數據的“冷啟動”用戶,可以通過映射函數將其映射在冷啟動領域,從而完成面向“冷啟動”用戶的推薦。同時,神經網絡融入了源領域和目標領域的物品異質特征信息,并以損失函數為依據,采用梯度下降的方法學習模型的參數,從而完成最終的評分預測。
3.1 異質信息網絡表示學習
定義異質信息網絡為G=(V,E)。其中,V代表領域內節點集合(如用戶、物品、物品的特征等),E是領域節點之間邊的集合,每條邊代表各個節點之間的關系。網絡模式是對異構信息網絡的元描述,表示為S= (A,R),其中,A為節點類型,R為鏈接類型[14]。考慮到異質信息網絡包含有大量復雜的、異質的結構關系信息,其中的冗余信息(如特征節點與特征節點之間的關系)便成為了節點表示學習的“噪音”。由此,需要引入元路徑過濾掉此類冗余信息,并將異質信息網絡表示學習問題轉換為同質信息網絡表示學習問題,在降低學習難度的同時有效排除“噪音”,進而利用經典的DeepWalk算法進行特征信息的學習。
元路徑是在網絡模式上的一條路徑P=其中,A為節點類型,R為鏈接類型,R=R1°R2° … °Rl,°表示關系上的合成算子。給定一條元路徑P,便可計算節點的連接矩陣,計算方法[22]為
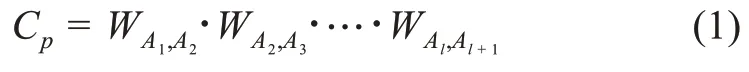
其中,WAi,Aj表示節點類型Ai到Aj的鄰接矩陣。不同的元路徑會產生不同的連接矩陣,每個連接矩陣都可以視為一個同質網絡。針對每個同質網絡,采用經典的DeepWalk 算法進行學習。DeepWalk 算法在網絡中隨機游走產生訓練語料,然后用Skip-Gram 進行訓練,目標函數[14]為
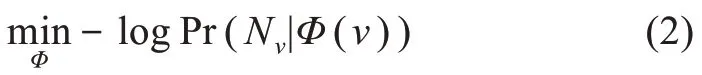
其中,Φ:V→Rd是一個將每個節點映射到d維空間上的函數;Nv?V表示在給定一個元路徑下節點v的鄰居。
通過不同元路徑生成的同質信息網絡有著不同的語義信息。這些語義信息是異質信息網絡中所包含信息的子集,是排除了“噪音”信息之后的關鍵信息。將其輸入DeepWalk 中能夠得到體現各自語義的向量,此時,多個同質信息網絡之間的關系就演變成了多個向量之間的關系,需要設置合理的融合向量的函數。用戶對不同的語義應有不同的偏好,同時,向量之間的融合關系往往不是簡單的線性關系,為了更好地擬合這種關系,個性化非線性的融合方法是相對較優的選擇。因此,融合后節點v的異質特征信息向量ev[27]為
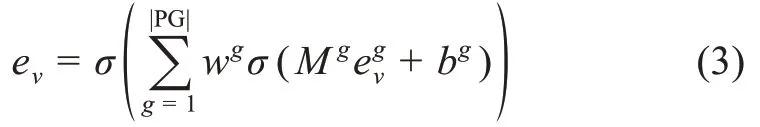
3.2 評分預測
評分預測模塊是一個復雜的神經網絡架構,借鑒了CMF 的思想。CMF 是傳統矩陣分解的擴展,在源領域和目標領域含有重疊用戶的情況下,將源領域和目標領域的評分預測用共享用戶潛在因子cu、源領域物品潛在因子和目標領域物品潛在因子之間的點積進行計算。此時,用戶u對源領域物品i的預測評分以及對目標領域物品j的預測評分分別為

由式(4)和式(5)不難發現,對于CMF,共享用戶潛在因子cu同時參與兩個領域評分預測的運算,沒有體現出源領域和目標領域的差異性,可能導致“負遷移”。為此,本文借用CMF 共享用戶特征的思想構建神經網絡,借用神經網絡強大的靈活性,引入了映射函數MLP 來體現領域的獨有特征,同時,為了充分利用領域內物品特征信息,還對物品異質特征信息向量進行聯合計算,最終完成評分預測,如圖2 所示。
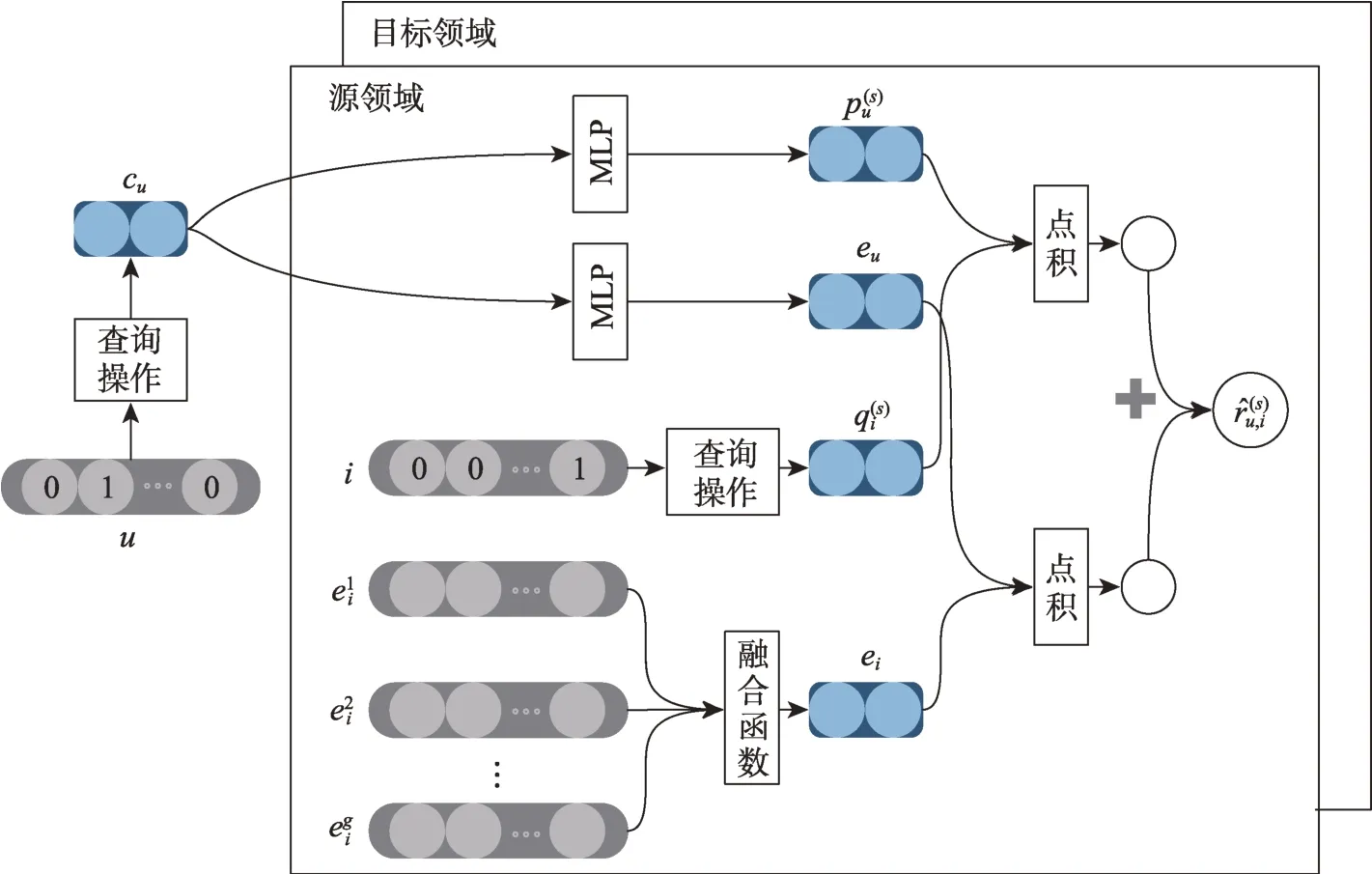
圖2 融合異質信息網絡表示學習的神經網絡架構
3.2.1 用戶和物品的評分向量表示
建立評分向量查詢層,將用戶和物品的0/1 編碼轉換為評分信息向量,即用戶和物品的評分信息表示。以源領域為例,給定一個用戶u和物品i,表 示 它 們 的 0/1 編 碼 , 評 分向量查詢層以參數矩陣表 示用戶和物品的評分信息向量,其中,d表示向量的維度,|U|和|I|分別表示用戶和物品的數量。向量查詢操作實現為

其中,cu為共享用戶向量,為源領域物品i的物品評分信息向量,分別代表了用戶和物品的評分特征。
3.2.2 共享用戶嵌入的映射
以源領域為例,在查詢到共享用戶向量cu之后,cu并不直接參與和的點積運算,而是通過MLP 的映射函數將cu映射到源領域,得到源領域用戶評分信息向量以此突出不同領域的差異性。同時,對于在某一領域完全沒有數據,而在另一領域有數據的用戶,通過映射函數就可以實現其在“冷啟動”領域的推薦,完成知識的遷移。除此之外,映射函數的引入拋棄了CMF 中必須是相同維度的前提,增強了模型的靈活性。
同理,對于由公式(3)計算得出的物品i的異質特征信息向量ei,MLP 將cu映射到相應空間得到與ei進行計算。之所以不在異質信息網絡表示學習模塊直接學習的表示,是因為對于一個領域內完全沒有數據的用戶來說,直接學習會導致模型無法進行“冷啟動”用戶的推薦。綜上,其計算方法為
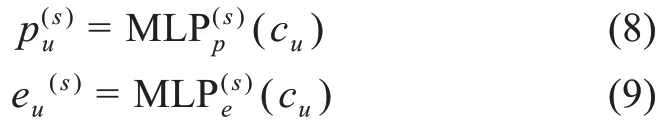
3.2.3 評分預測
評分預測由兩部分組成。第一部分為用戶和物品的評分特征的點積,借鑒了CMF 的思想,代表了用戶和物品評分模式的特征;第二部分為用戶和物品異質特征信息向量的點積,物品異質特征向量由領域內的異質信息網絡表示生成,代表了領域內豐富的領域物品特征信息。最終的預測評分由二者求和計算得出。據此,用戶u對源領域物品i的預測評分為
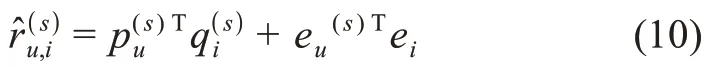
同理,用戶u對目標領域物品j的預測評分r?(t)
u,j為
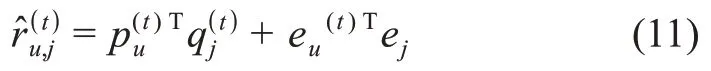
3.2.4 模型訓練
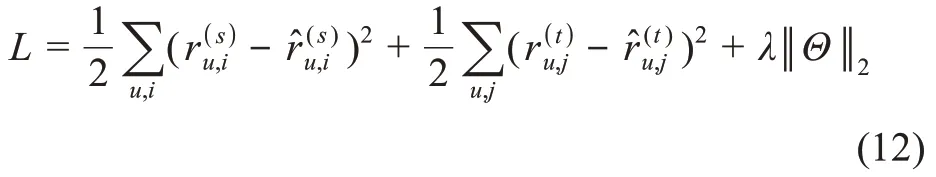
4 實驗分析
4.1 數據集
實驗數據集來自豆瓣網的電影和圖書兩個領域,主要包括用戶的評分數據和物品特征信息。其中,評分數據是用戶對某一物品的評分,評分范圍為1~5;物品屬性主要包括圖書的作者、出版商,以及電影的演員、導演、類型、地區。用Python 的Scrapy 框架編寫爬蟲程序,采用滾雪球的策略,隨機選取一批種子用戶并抓取其數據,在此基礎上,從種子用戶的關注或粉絲列表中獲取更多的用戶,不斷遞增。在獲取數據集之后,分別刪除電影和圖書領域評分數量少于10 的用戶;同時,對于那些只在單一領域內有評分行為的用戶,無法對其推薦結果進行驗證,因此將這部分用戶刪除。豆瓣網數據集最終的基本統計信息如表1 所示。由于電影領域相比于圖書領域的數據稀疏程度較低,因此,將電影領域視為源領域,圖書領域視為目標領域。
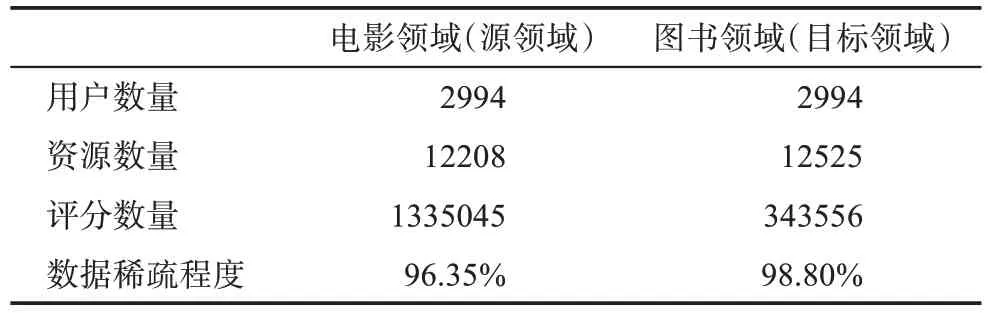
表1 豆瓣網數據集的基本統計信息
4.2 實驗設置
實驗主要分為兩個部分。第一部分為推薦效果的實驗,評分數據不包括在某一領域內沒有評分行為的用戶,即全部為“熱啟動”用戶。隨機移除一部分用戶的評分作為測試集,剩下的作為訓練集,訓練集的比例分別為80%、60%和40%。第二部分為“冷啟動”效果的實驗,將圖書領域視為目標領域,隨機選取了一定比例的用戶,保留其電影領域的數據,移除他們在圖書領域的全部評分數據,作為圖書領域的完全“冷啟動”用戶參與實驗,冷啟動用戶比例分別為10%、30%和50%,即錨用戶比例分別為90%、70%和50%。實驗環境CPU 為Inter(R) Core(TM) i7-8750H@2.20GHz, GPU 為 NVIDIA GeForce GTX 1060 6G,RAM 為 16G,并采用 Ten‐sorFlow 編寫算法。以上實驗分別做5 次,最終的數據結果為5 次實驗的平均值。
在參數設置方面,經過多次實驗,最終確認參數為:共享用戶特征向量、源領域和目標領域評分信息向量的維度都為64;根據文獻[12,27],融合后的異質特征信息向量的維度為64,MLP 和非線性融合函數都為包含一層隱藏層的神經網絡,隱藏層神經元的個數為128,其中MLP 的隱藏層的激活函數為tanh,非線性融合函數隱藏層和輸出層激活函數都為Sigmoid 函數,學習速率為0.0001,正則化參數λ為0.01,由于學習速率較低,迭代次數為3000 次。
在元路徑的選擇方面,先分別構造了圖書領域和電影領域的異質網絡。在圖書領域,提取了以圖書開頭和結尾的元路徑;同理,在電影領域,提取了以電影開頭和結尾的元路徑。不同的元路徑代表了不同的語義,例如,元路徑“BUB”表示兩本書被同一用戶閱讀,代表了兩本書在用戶層面的相似性。本實驗所使用的元路徑和代表的語義如表2所示。
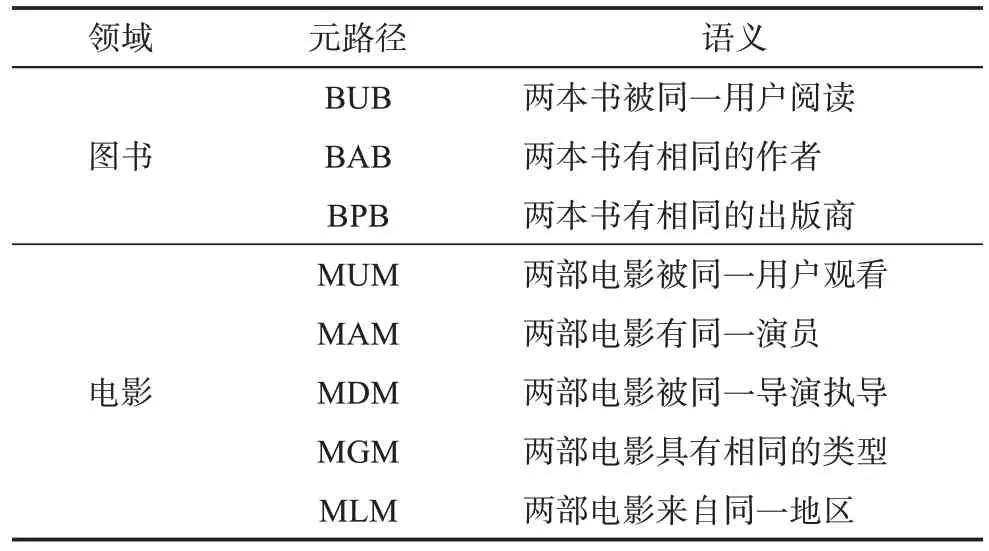
表2 豆瓣網數據集的元路徑及其語義
4.3 對比模型和評價指標
為了驗證本文方法的有效性,將選擇一系列對比模型進行效果對比。總體上說,對比模型分為單領域推薦模型和跨領域推薦模型。單領域推薦模型用來證明本文模型可以有效提升推薦效果;跨領域推薦模型則用來證明本文模型能更有效地遷移源領域數據,從而緩解目標領域的數據“稀疏性”和用戶“冷啟動”問題。由此,本文選擇了以下6 種模型作為對比模型。
(1) PMF (probabilistic matrix factorization)[29]:概率矩陣分解,經典的單領域矩陣分解算法,將某個領域的評分矩陣分解為用戶矩陣和物品矩陣,從而預測缺失評分。
(2)CDCF-U(user-based cross-domain collabora‐tive filtering)[30]:基于用戶的跨領域協同過濾模型,將多個領域視為同一領域進行矩陣合并,使用傳統的基于用戶的協同過濾進行評分的預測。
(3) CDCF-I(item-based cross-domain collabora‐tive filtering)[30]:基于物品的跨領域協同過濾模型,與CDCF-U 類似,將多個領域視為同一領域進行矩陣合并,使用傳統的基于物品的協同過濾進行評分的預測。
(4)CMF[4]:聯合矩陣分解,經典的跨領域推薦模型,將源領域和目標領域的評分矩陣進行聯合分解,共享不同領域的用戶矩陣,從而預測缺失評分。
(5)EMCDR[12]:解決“冷啟動”問題的跨領域推薦模型,對用戶評分矩陣進行分解,然后使用非線性映射函數進行領域間的知識遷移。
(6) NeuCDCF (neural cross-domain collabora‐tive filtering)[10]:一種新的跨領域推薦算法,利用用戶對物品的評分,通過構建矩陣分解和深度神經網絡兩個模塊進行評分預測。
其中,PMF 作為經典的單領域推薦方法,相關的研究成果與應用實踐都取得了較好的效果[31],故將其作為對比模型驗證跨領域推薦相比于單領域推薦的優越性;CDCF-U 和CDCF-I 將跨領域推薦問題簡單轉化為單領域推薦問題,可能導致“負遷移”,以此作為對比模型,可以有效驗證本文模型的知識遷移能力;CMF 是一種經典的跨領域推薦方法,也是本文模型思想的基點,以此作為比對模型來驗證CMF 改進后的推薦能力;EMCDR 是專門用于解決“冷啟動”問題的跨領域方法,可以有效驗證本文模型的用戶“冷啟動”的推薦效果;NeuCDCF 是一種新的跨領域推薦模型,可以進一步檢驗本文模型的跨領域推薦能力。
考慮到本文是對評分進行預測,故選擇RMSE(root mean squared error) 和MAE(mean absolute er‐ror)作為評價指標,計算公式分別為
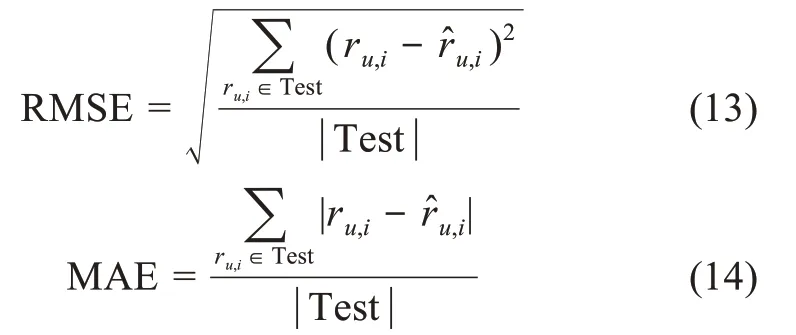
其中,Test 為測試集;ru,i為用戶u對物品i的實際評分;r?u,i為用戶u對物品i的預測評分。MAE 衡量的是預測評分與實際評分的絕對誤差的平均值;RMSE 是預測評分與實際評分之間平方差異的平均值,然后再取平方根。RMSE 和MAE 越小,代表預測評分與實際評分的差異越小,推薦準確性也越高。從總體上來說,RMSE 和MAE 的趨勢一致,但RMSE 受異常值影響更大。
4.4 實驗結果
1)推薦效果實驗結果
表3 列出了6 種模型在不同領域和訓練集比例下得到的RMSE 和MAE。總體來看,CDCF-U 模型和CDCF-I 模型取得的推薦效果較差,甚至不如單領域推薦的PMF 模型;CMF 模型雖然能夠在圖書領域超越PMF 模型,但提升幅度并不大,在電影領域還取得了相反的效果;NeuCDCF 是CMF 和堆棧自編碼器的結合,因此在推薦效果上優于CMF,但NeuCDCF 只用了評分信息,無法充分獲取用戶偏好和領域知識。本文模型的推薦效果均優于以上方法,與5 種對比模型相比,RMSE 和MAE 降低的百分比如表4 所示。同時,由于本文模型融入了異質信息網絡表示學習獲得的表示向量,包含豐富的物品特征信息,對于數據量較少的物品或用戶來說,可以通過這部分特征信息補充評價數據的缺失,使得不同訓練集比例下RMSE 和MAE 結果的變化幅度較小,進一步表明本文模型的優越性。
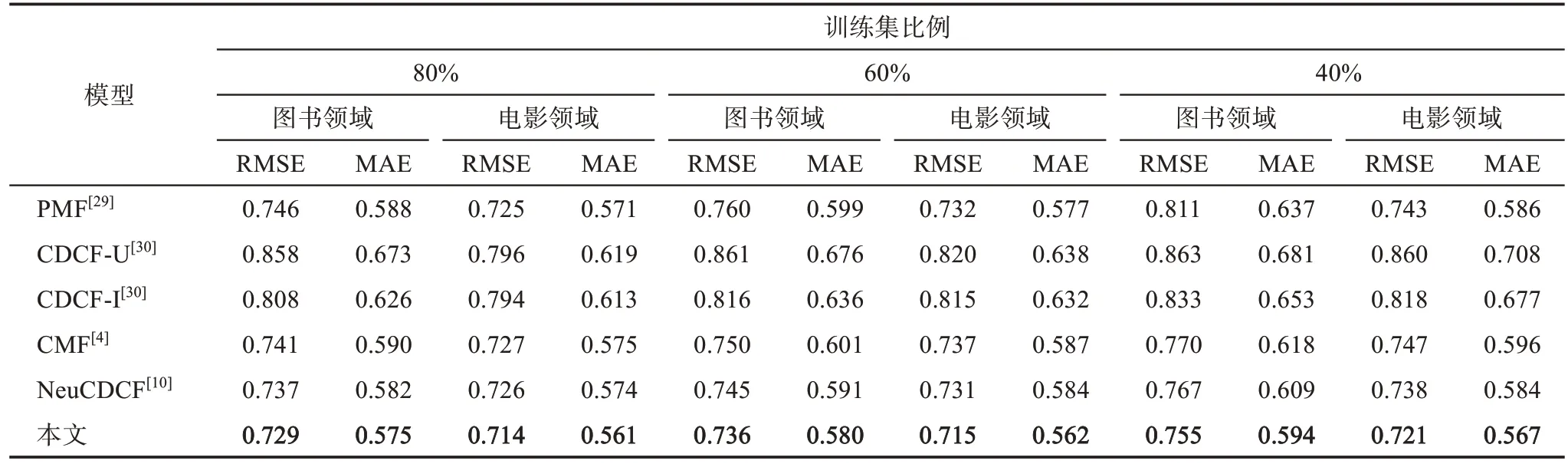
表3 6種模型推薦效果實驗結果的比較
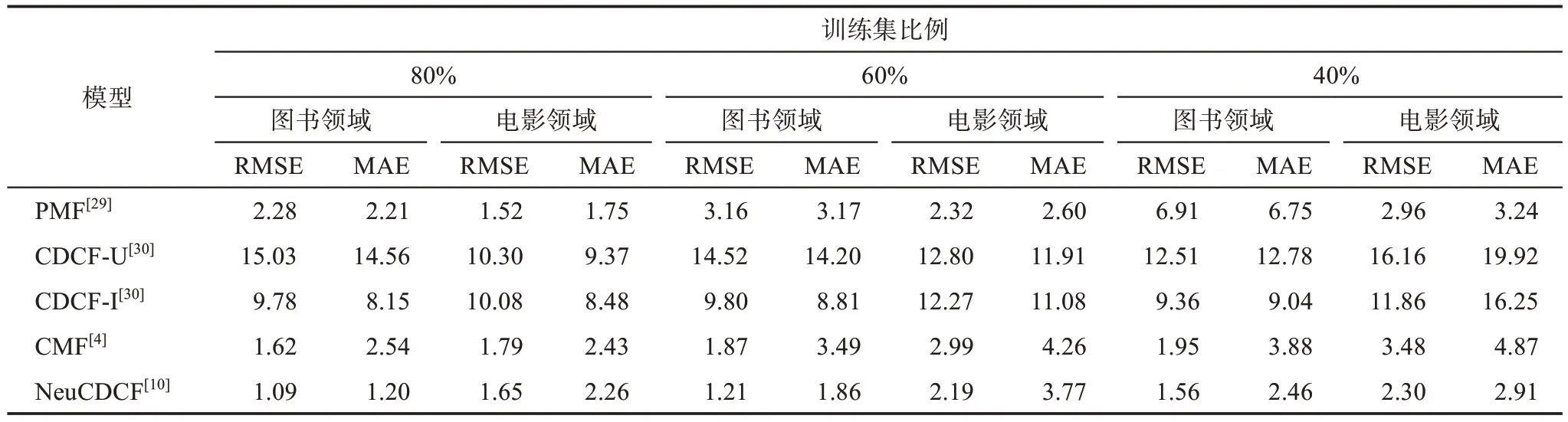
表4 本文模型與5種對比模型相比推薦效果的RMSE和MAE降低的百分比 %
2)用戶“冷啟動”實驗結果
表5 列出了6 種模型在用戶“冷啟動”方面的RMSE 和MAE。總體來看,CDCF-U 模型和CDCF-I模型表現依然較差;CMF 模型本質上是一種線性算法,所以在用戶“冷啟動”方面效果不能盡如人意;EMCDR 模型作為非線性映射算法,在兩個領域之間學習了一個非線性映射函數,針對“冷啟動”用戶具有較好的應用價值;NeuCDCF 在“冷啟動”方面表現優異,僅次于本文模型。本文模型在用戶“冷啟動”方面都優于以上模型,與5 種對比模型相比,RMSE 和MAE 降低的百分比如表6 所示。同時可以看到,隨著“冷啟動”用戶比例的上升,所有模型的RMSE 和MAE 結果都有明顯的提升,說明錨用戶的數量在各個模型中起到了舉足輕重的作用。
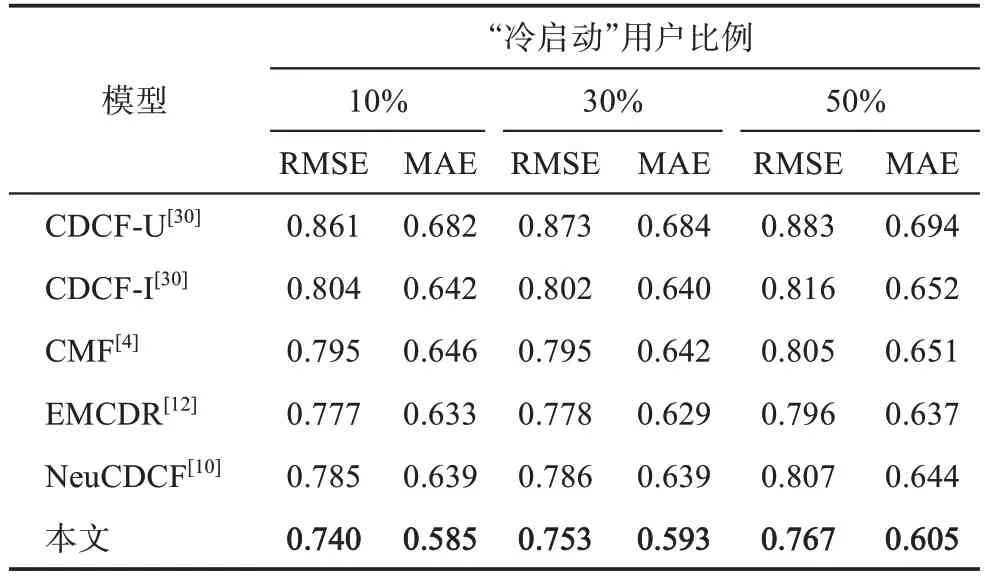
表5 6種模型用戶“冷啟動”實驗結果的比較
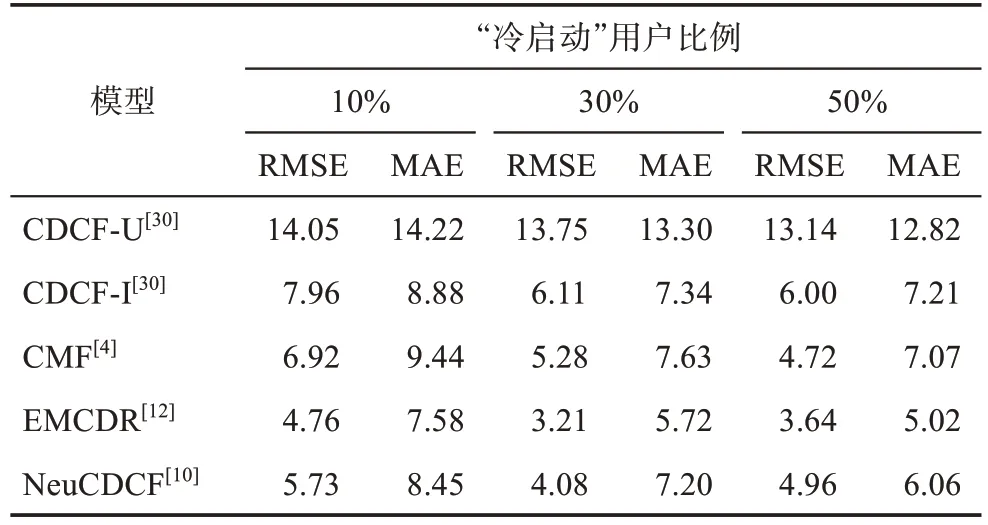
表6 本文模型與5種對比模型相比用戶“冷啟動”的RMSE和MAE降低的百分比 %
4.5 元路徑分析
不同的元路徑代表了領域內不同的語義特征。本節將從推薦效果和用戶“冷啟動”兩個方面探討元路徑對模型的影響。
在推薦效果方面,結果如圖3 所示。總體來說,在不同訓練集比例下,不管是RMSE 還是MAE,加入元路徑的模型都比不加入元路徑的模型要低,這一結果符合元路徑能有效提高推薦效果的猜想。但電影領域RMSE 和MAE 的下降幅度比圖書領域大,這是因為電影領域數據較為稠密,在加入更多的特征信息后推薦效果能得到較大幅度提升;而圖書領域數據相對稀疏,雖然能夠在一定程度上提高推薦效果,但幅度不大。

圖3 是否加入元路徑在推薦效果上的對比
在用戶“冷啟動”方面,將圖書領域的部分用戶設為完全“冷啟動”用戶,結果如圖4 所示。與上文類似,RMSE 和MAE 都有一定程度的下降。對于一個在圖書領域完全沒有數據的“冷啟動”用戶來說,一方面通過MLP 的映射,將電影領域的知識遷移到圖書領域,可以使用戶在圖書領域也能取得較好的推薦效果;另一方面,元路徑的特征知識也能為冷啟動用戶提供數據支持,從而比沒有元路徑的模型效果更好。
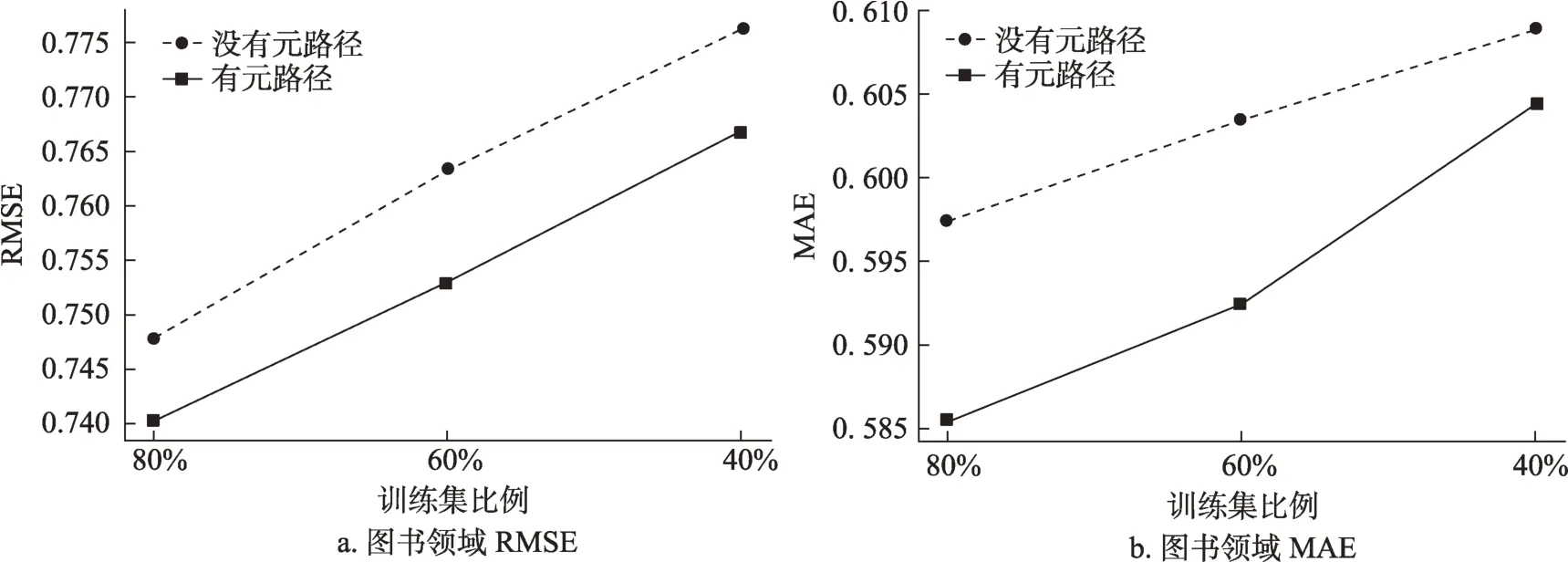
圖4 是否加入元路徑在用戶“冷啟動”上的對比
4.6 特征維度分析
本文模型的特征維度主要包括共享用戶特征嵌入cu的維度(CK)、源領域評分信息向量的維度(SK)、目標領域評分信息向量的維度(TK)、源領域異質特征信息向量和ei的維度(SHK)、目標領域異質特征信息向量和ej的維度(THK)。其中,SHK 和THK 的維度根據文獻[22]設為64,本節主要探討CK、SK 和TK 的最優參數設置。
CK 的維度特征決定了SK 和TK 的特征表示。先將CK、SK 和TK 設為相同維度,取值范圍為{8,16,32,64,128,256},試圖找出最優的CK 值,其結果如圖5 所示。當CK、SK、TK 的維度都為64 時,圖書領域和電影領域的RMSE、MAE 同時達到最小,因此,CK 的最佳維度為64。
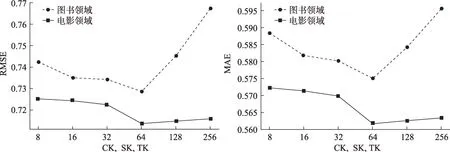
圖5 CK、SK、TK取值相同情況下不同領域的RMSE和MAE
在CK 維度為64 的情況下,分別對SK 和TK 的參數進行調整,取值范圍為{8,16,32,64,128,256},結果如圖6、圖7 所示。當SK 和TK 同時取值為64時,圖書領域和電影領域的RMSE 和MAE 達到最小。從上述結果可以發現,不管是共享用戶潛在因子還是不同領域內特有的用戶潛在因子,RMSE 和MAE 隨著特征維度的增加均呈現出先上升后下降的趨勢;同時,電影領域相對于圖書領域受到參數調整的影響較小,這是由于電影領域評分數據量較多,數據的“稀疏性”不明顯,而圖書領域評分數據量小,受參數調整影響大。

圖6 不同SK、TK取值下電影領域的RMSE和MAE(CK=64)
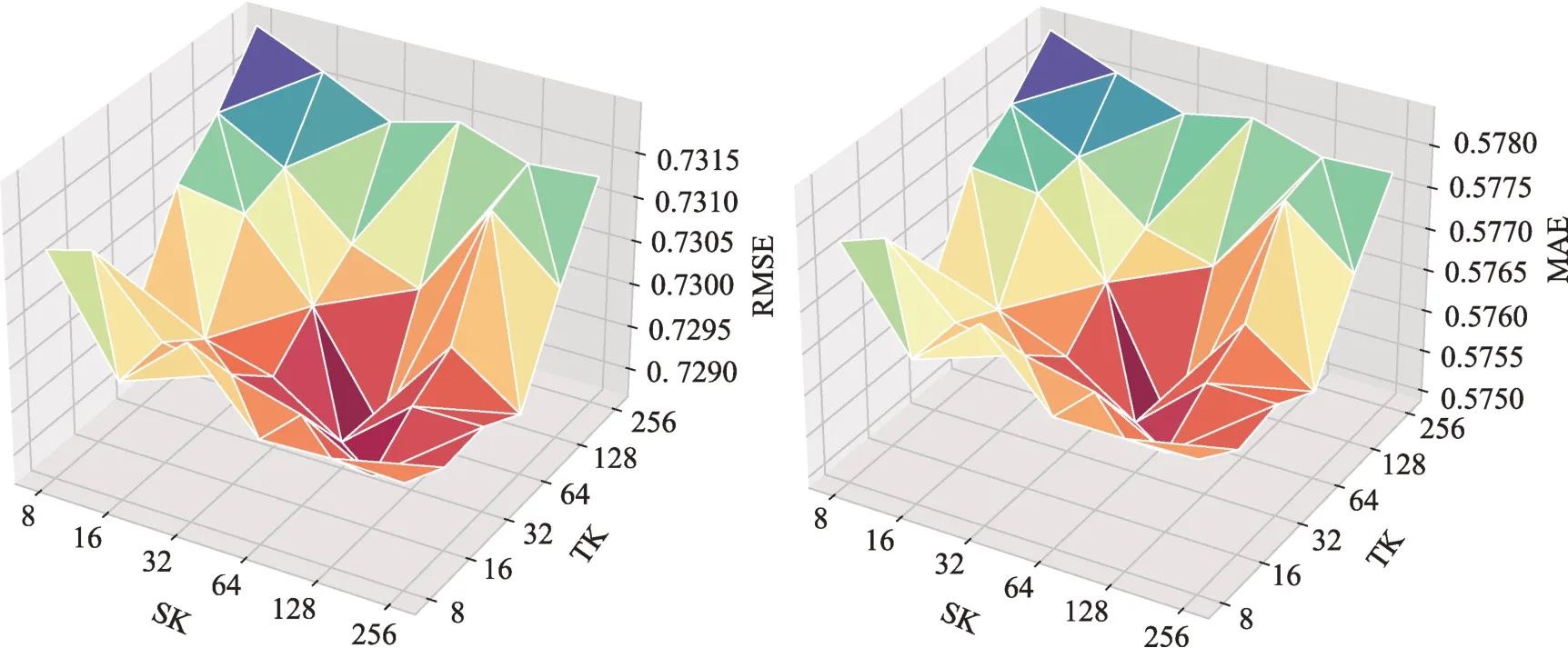
圖7 不同SK、TK取值下圖書領域的RMSE和MAE(CK=64)
4.7 模型普適性分析
以上實驗所使用的電影、圖書領域的數據集相關性較高,且只針對豆瓣網一個平臺,不足以突現本文模型的普適性。為此,本節以Amazon 平臺的電影和唱片領域為例,將電影領域作為源領域,唱片領域作為目標領域,進一步驗證模型的普適性。Amazon 數據集的基本統計信息如表7 所示。
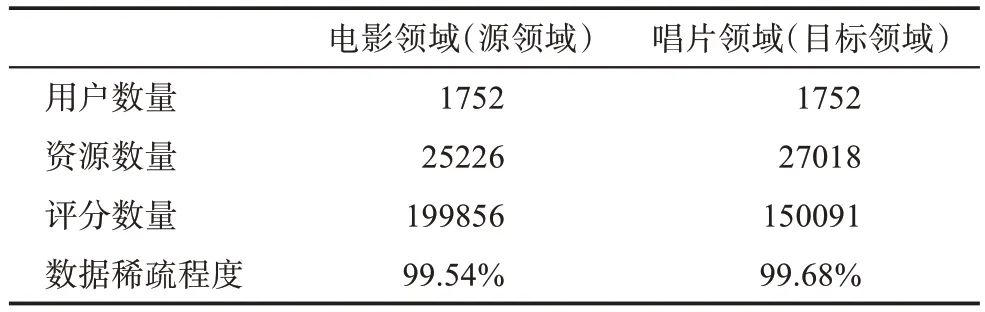
表7 Amazon數據集的基本統計信息
在元路徑的選擇方面,考慮到Amazon 數據集的特征信息較少,可用的特征信息僅包括品牌、價格、種類,其中價格和種類所包含的標簽較少,無法體現出差異性,所以僅使用品牌作為特征信息。本實驗所使用的元路徑和代表的語義如表8所示。
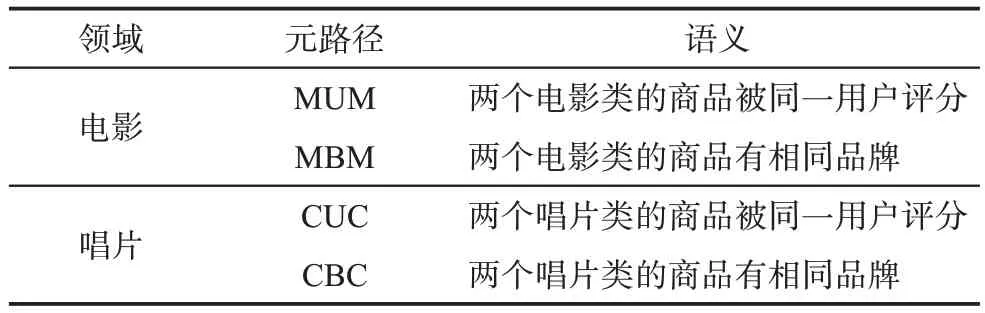
表8 Amazon數據集的元路徑及其語義
與上文相同,本實驗也分為推薦效果實驗和用戶“冷啟動”實驗。在推薦效果實驗中,同時刪除電影領域和唱片領域20%的用戶評分數據作為測試集,剩余80%的評分作為訓練集來學習模型參數;在用戶“冷啟動”實驗中,隨機挑選20%的用戶,刪除其在唱片領域的所有評分數據,作為唱片領域的完全“冷啟動”用戶參與測試。實驗參數與第4.2 節中的設置相同,最終實驗結果如圖8、圖9所示。
從圖8、圖9 可以看出,在Amazon 數據集上,不管是推薦效果還是用戶“冷啟動”效果,本文模型評分預測的準確性都是最高的。對比豆瓣網的電影領域和圖書領域,Amazon 的電影領域和唱片領域關聯性明顯更低,且數據稀疏程度更高,容易出現“負遷移”。在推薦效果方面,CMF 完全共享用戶特征的機制導致推薦效果不理想,而NeuCDCF和本文模型都設置了用戶獨特的領域特征,出現“負遷移”的可能性更低,因此推薦效果更好;在用戶“冷啟動”方面,EMCDR 作為專門處理“冷啟動”問題的跨領域推薦方法,其前提是要求兩個領域之間的用戶存在一種映射關系,在電影和唱片領域關聯性不大的情況下,用戶行為特征差異也較大,因此EMCDR 擬合出的映射關系誤差大,導致推薦結果較差。總的來說,Amazon 數據集的實驗結果充分說明了本文模型的普適性。
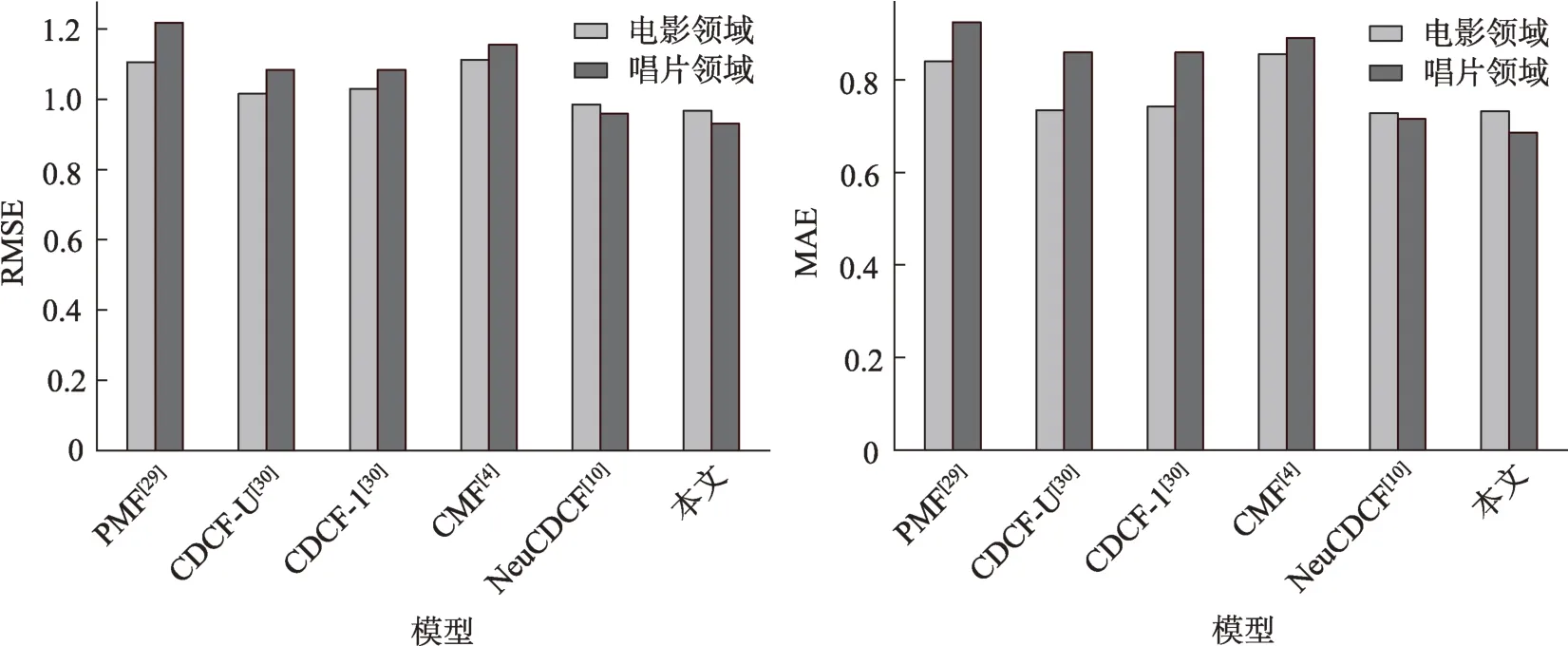
圖8 Amazon電影領域和唱片領域的推薦效果對比
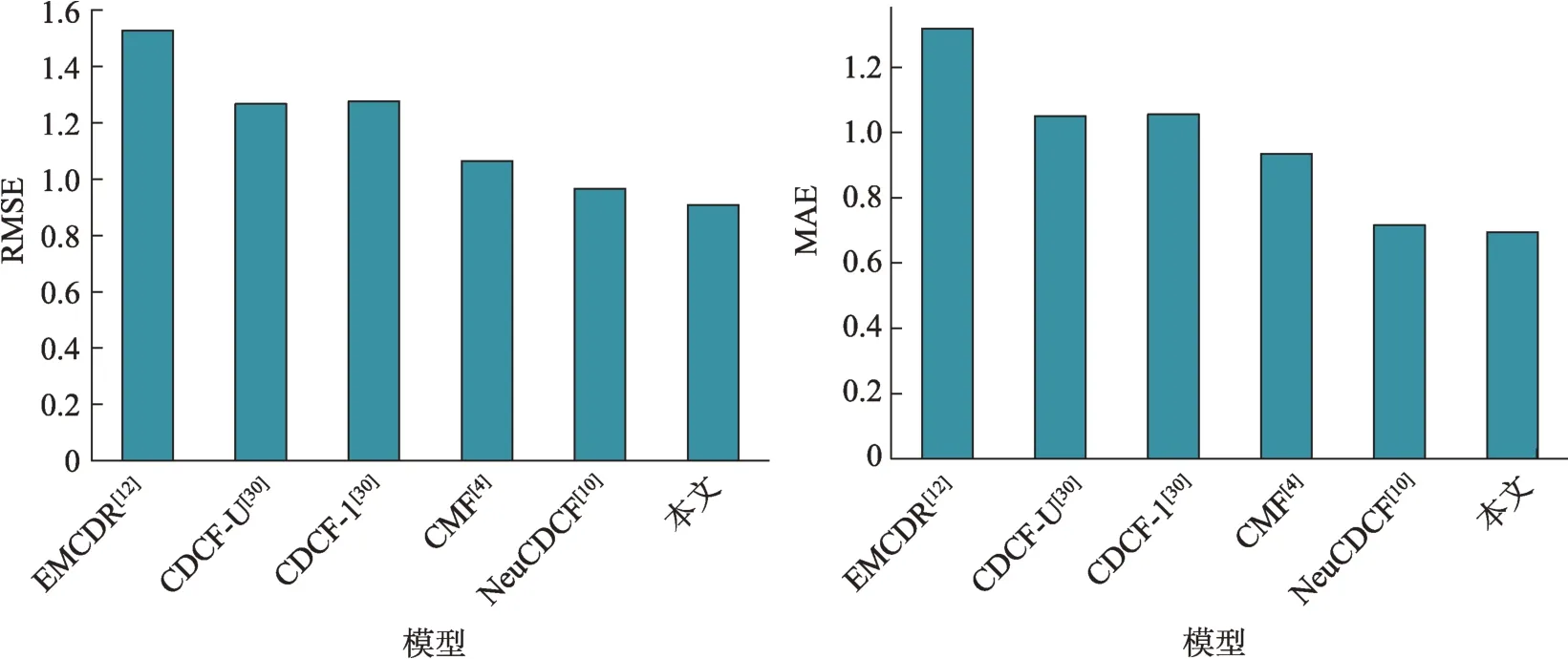
圖9 Amazon唱片領域的用戶“冷啟動”效果對比
5 結 語
針對當前跨領域推薦存在的相關問題,本文提出了一種融合異質網絡表示學習的跨領域推薦模型。該模型同時利用領域內的評分信息和特征信息,采用神經網絡架構,優化了傳統跨領域矩陣分解,利用非線性映射函數體現不同領域的差異性,同時還將物品屬性特征以異質信息網絡表示學習的形式融入跨領域推薦中,達到了有效利用領域間豐富特征信息的目的,從而進一步緩解了數據“稀疏性”和用戶“冷啟動”的問題。研究結果表明,本文模型在提高推薦效果和優化用戶“冷啟動”方面比現有相關模型更具有優越性和穩定性。然而,本文模型也存在一些不足,尤其是在算法設計過程中,需要學習的參數過多,導致算法時間成本較高。因此,在今后的研究中,應繼續優化適用于個性化推薦的異質信息網絡表示學習方法,在保留異質網絡中信息的基礎上,簡化異質信息網絡表示學習的步驟;還可以進一步深入研究多領域推薦方法,將單一的輔助領域擴展到多輔助領域,進而從不同的領域獲取更多的領域知識,增強模型的表達能力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
