基于深度遷移學習的地方志多模態命名實體識別研究
2022-05-19 06:58:36陳玥彤
情報學報 2022年4期
范 濤,王 昊,陳玥彤
(南京大學信息管理學院,南京 210023)
1 引 言
黨的十九屆五中全會通過的《中共中央關于制定國民經濟和社會發展第十四個五年規劃和二〇三五年遠景目標的建議》中明確提出了到2035 年建成文化強國的遠景目標,并強調在“十四五”時期推進社會主義文化強國建設,這標志著我國文化強國建設進入了一個新的歷史階段[1]。作為中華文化的載體和組成部分,地方志是建設文化強國的重要一環,對其進行挖掘和研究,有利于傳播中華文化和增強文化自信[2]。
命名實體識別作為文本挖掘中的一項基礎任務,旨在識別文本中的專有詞,如人名、地名、時間、組織等,其對后續的文本知識組織和知識圖譜的構建都具有重要影響[3]。目前,已有學者利用相關研究方法對地方志等文化資源進行了實體抽取。例如,李娜[4]以《方志物產》山西分卷作為語料,基于條件隨機場模型實現了對物產別名實體的自動抽取。黃水清等[5]將部分人工標注的先秦古漢語語料庫作為條件隨機場的訓練數據,利用訓練生成的最優模型,對語料庫中的地名實體進行自動識別。從上述工作可以看出:①當前對于地方志等文化資源命名實體識別任務的研究對象均基于文本,缺乏對多模態內容(即文本結合圖片)的探究;②自動識別文本實體的模型依賴于大規模人工標注的語料,需要耗費大量的人力資源和時間。然而,隨著地方志數字化進程的加快,地方志數據庫提供的內容并不僅局限于文本這一單模態內容,與文本相關聯的圖片資源同樣以結構化的方式呈現,這為地方志多模態內容的研究提供了契機。在文本命名實體識別任務中,當實體邊界模糊時,僅依靠上下文難以辨別其實體類型。例如,在圖1 中,倘若僅考慮文本,難以確定句子中所包含實體的邊界,“江大橋”可以被視作人名,而“長江大橋”又可以被視作地名,但是當結合文本對應的圖片時,則可以確定文本中提及的實體為“長江大橋”,從而準確地識別出實體。當面向某一具體領域展開實體識別研究時,通常會面臨標注語料匱乏的問題。常用的解決方法是利用人工去標注數據集,但是會耗費大量的人力、物力,同時,在面向新領域時,還需標注新的語料,并不能較好地解決面向特定領域的實體識別問題。然而,通過深度遷移學習方法,利用深度神經網絡預學習相關領域知識后,再對目標語料進行實體抽取,則可以有效避免對訓練語料的標注。目前,已有學者利用基于深度遷移學習的方法抽取文本中的實體,應用公開數據集訓練模型,結合微調的方法提升實體抽取模型的性能[6-7]。但是,目前的相關研究多集中于文本,利用深度遷移方法對多模態內容進行命名實體識別鮮有探索。基于此,為了解決目標領域標注數據匱乏的問題以及提升實體識別性能,本文提出利用深度遷移學習并結合文本和圖片內容展開地方志多模態命名實體識別的研究。

圖1 南京市長江大橋
多模態命名實體識別是一項新興的任務,旨在利用多模態內容挖掘文本和圖片中存在的相關語義關系,增強文本語義信息,提升模型識別實體的性能。該任務最早由Zhang 等[8]提出,其利用基于自適應多模態聯合注意力機制(adaptive co-attention)的命名實體識別模型,對推特中網民所發布的包含多模態內容的帖子進行實體識別,并獲得了最優結果;同時作者公開了文中所用的多模態數據集。目前,中文領域尚未有應用于多模態命名實體識別的公開數據集,因此,本文以文獻[8]的數據集為基礎,制作了用于深度遷移學習的平行語料。盡管圖片內容能夠在一定程度上提升命名實體識別任務的性能,但是文本中的語義信息依舊是實體抽取中的核心。基于此,本文提出基于深度遷移學習的多模態命名實體識別模型(multimodal named entity rec‐ognition model,MNERM)。該模型主要由四個部分組成,分別是BiLSTM-attention module(BAM)模塊、adaptive co-attention module(ACAM)模塊、過濾門及CRF(conditional random fields)層。為使得BAM 模塊和ACAM 模塊分別獲取預訓練權重,本文分別引入了面向人民日報語料庫的BiLSTM-atten‐tion-CRF(BAC)模型和面向中文平行推特多模態語料庫的adaptive co-attention CRF(ACAC) 模型,BAM 模塊和ACAM 模塊同樣也是BAC 模型和ACAC模型的組成部分。通過在對應語料庫預訓練模型,將權重參數分別遷移至BAM 模塊和ACAM 模塊,使MNERM 模型擁有提取多模態特征的能力。盡管應用多模態特征能夠提升模型性能,但依舊包含噪聲,本文提出利用過濾門對ACAM 模塊輸出的多模態特征進行去噪,再同BAM 模塊輸出的文本特征進行融合,最后以微調的方式將融合后的多模態特征輸入至CRF 層進行解碼。
本文的主要貢獻為:從多模態視角出發,提出結合地方志中的文本和圖片進行命名實體的識別研究;針對目標領域標注語料匱乏的問題,提出利用深度遷移學習方法進行地方志多模態命名實體識別,并構建了MNERM 模型,該模型能夠充分獲取不同模態的信息表示,并能有效捕捉不同模態間的相關關系,增強文本的特征表示能力。
本文將提出的模型在地方志多模態數據集中進行了實證研究,并與相關基線模型進行對比。研究結果表明,本文提出的模型具有一定的優越性。
2 相關研究
2.1 地方志命名實體識別研究
伴隨著數字化進程的加快,沉睡的人文資源逐步成為可計算的數據,這為數字人文計算打下堅實的基礎。而命名實體識別作為自然語言處理中的基礎性任務,其對文本的知識組織及實體間的關系抽取都有著重要的影響。為了探究古籍方志中的實體自動識別,徐晨飛等[9]采用BiLSTM-CRF、BERT 等模型對物產別名、人物、產地及引書等實體進行識別,實驗結果表明,采用基于深度學習的實體識別方法能夠取得較好的效果。崔競烽等[10]基于深度學習方法,構建BiLSTM-CRF 模型對菊花古典詩詞中的菊花花名、花色等實體進行識別,并同CRF 等基線模型作對比,實驗結果表明,該文獻提出的方法能夠取得較好的效果。史書中的歷史事件名是歷史文本知識庫的重要組成部分,唐慧慧等[11]提出以字作為最小語義單元,利用CRF 模型對魏晉南北朝史書文中的歷史事件名實體進行識別,并取得良好效果。在人民日報語料庫中,殷章志等[12]利用基于BiLSTM-CRF 的序列標注模型抽取文本序列的中間特征,并將其輸入支持向量機中進行實體識別,并取得一定的效果。石春丹等[13]提出利用雙向門控循環網絡與CRF 結合的模型對文本中人名、地名和機構名等實體進行識別,該模型能夠有效學習序列的時序信息,并能捕捉長距離依賴。
從上述研究可以看出,目前面向地方志等人文資源的命名實體識別研究多基于文本,并利用基于BiLSTM-CRF 架構的深度學習模型進行實體識別。與之不同的是,本文在BAC 模型中引入了自注意力機制,其能夠有效增強文本的特征表示,減少序列信息中的噪聲,并獲得實體識別性能上的提升。除此之外,人文資源的數字化帶來的并不止是單一的文本,同時有著大量可獲取的對應圖片資源。已有研究表明,圖片的加入能在一定程度上增強和補充對應的文本語義信息[14]。基于此,本文提出結合地方志中的文本和圖片,進行命名實體識別研究。
2.2 多模態命名實體識別研究
用戶在網絡中產生內容的多模態化,為多模態自然語言處理任務提供了豐富資源。多模態命名實體識別作為其中的一項任務,已受到學界和工業界的廣泛關注。在以文本為主要處理對象的命名實體任務中,當實體存在多義性或實體邊界難以區分時,僅依靠上下文對實體類別做出準確判斷存在一定困難。但是當文本有著與之對應的圖片時,通過觀察圖片內容出現的實體,則能對歧義實體做出準確預測。
在多模態命名實體識別中,文本和圖片存在語義相關關系。在圖片內容中,與文本中提及實體存在相關關系的僅局限于圖片的部分區域。因此,Zhang 等[8]提出基于自適應聯合注意力機制(adap‐tive co-attention)的多模態命名實體模型,利用詞引導和圖引導的注意力機制充分學習文本和圖片的語義相關關系及模態交互,應用門機制進行多模態特征融合和噪聲過濾,之后將多模態特征與經過BiLSTM 編碼后的文本特征再次拼接,獲得最終多模態融合特征,并將其輸入CRF 層中進行解碼,F1值達到70.69%。同樣地,為了充分學習圖片中與文本實體相對應的語義特征,Yu 等[14]提出基于Trans‐former 架構的多模態命名實體模型,該模型主要由單模態特征表示、多模態Transformer 及輔助實體邊界檢測組成,通過這些構件,模型能夠較好地學習文本和圖片上下文敏感特征,并能夠關注到聚合多模態信息時未被充分關注的實體。為充分理解圖片中的視覺內容,Lu 等[15]提出基于視覺注意力機制的多模態命名實體模型,該模型能夠自動忽略與文本內容無關的視覺信息并重點關注與文本內容最相關的視覺信息,其在多個數據集中取得較好結果。
上述研究主要通過挖掘圖片與文本之間的相關語義關系及不同模態間的交互,并結合注意力機制,在公開英文數據集中取得一定性能。然而,在中文領域中,多模態命名實體識別任務尚未有研究涉及,并且缺乏相關的中文多模態命名實體識別語料。因此,本文探索將公開的英文多模態命名實體識別語料庫制作成可學習的平行中文多模態命名識別語料庫,并將詞作為句子的劃分粒度,利用深度遷移學習的方法對地方志多模態數據集進行實體識別研究。
2.3 深度遷移學習研究
深度遷移學習常用的方法包括基于實例的深度遷移學習(instance-based deep transfer learning)、基于映射的深度遷移學習(mapping-based deep transfer learning)、基于神經網絡的深度遷移學習(networkbased deep transfer learning)以及基于對抗的深度遷移學習 (adversarial-based deep transfer learning)[16]。其基本思想是利用在源域(source domain)訓練的深度神經網絡中的知識解決目標域(target domain)中的問題。
目前,已有相關文獻利用深度遷移學習方法進行命名實體識別研究。武惠等[17]提出利用基于實例的深度遷移方法學習樣本特征,構建BiLSTM-CRF模型對人民日報語料庫中的實體進行識別,并取得一定效果。王瑞銀等[7]在源域中訓練語言模型預測模型,將源域模型知識遷移至目標域模型中,從而對實體進行識別,其在法律文書數據集中性能良好。為了緩解可利用標注語料的不足,Lee 等[6]提出在大型源數據集中訓練BiLSTM-CRF 實體識別模型,結合微調的方法對目標域的實體進行識別,并取得了一定的效果。
為了有效獲取文本的語義知識和文本結合圖片的多模態知識,本文應用基于神經網絡的深度遷移學習思想,提出在兩個源域數據集中訓練與目標模型對應部分有著相似結構的深度學習模型,然后將預訓練模型中的權重遷移至目標模型的對應結構中,最后結合微調的方法對地方志多模態數據進行實體識別。
3 模型設計
為了提升地方志中模型識別實體的性能并探索解決目標領域標注語料匱乏問題,本文提出基于深度遷移學習的多模態命名實體模型MNERM,結構具體如圖2 所示,其分別由BAM 模塊、ACAM 模塊、過濾門及CRF 層組成。本文首先分別在人民日報語料庫和中文推特多模態數據集這兩個源域預訓練BAC 模型和ACAC 模型。然后,利用基于神經網絡的深度遷移學習方法,將BAC 模型和ACAC 模型中的對應權重分別遷移至BAM 模塊和ACAM 模塊中,使得MNERM 具備抽取文本和圖片的多模態特征能力。接著,將文本特征和經過過濾門過濾的多模態特征進行中間層融合,輸入CRF 層中進行解碼生成標簽,并進行微調。下文將詳述MNERM 模型及建模方法。
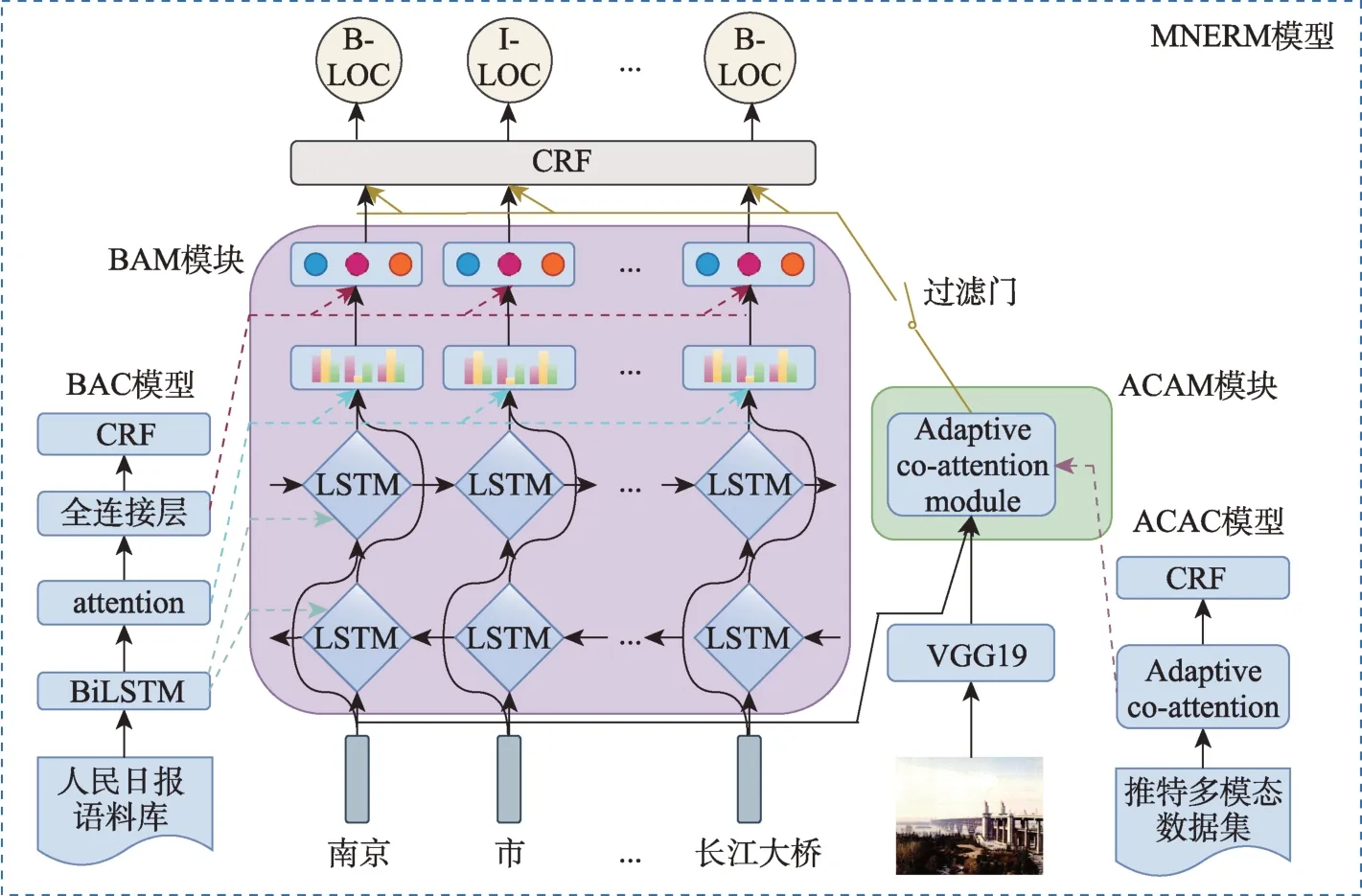
圖2 基于深度遷移學習的多模態命名實體識別模型
3.1 特征提取
1)文本特征提取
文本的特征表示對下游任務的表現有著重要影響。本文利用在百度百科大規模語料中預訓練的中文詞向量模型[18],對文本進行特征表示。MNERM模型以Skip-Gram 模型為基礎,并結合負采樣技術進行優化,其在中文類比推理任務中取得最優結果。本文利用MNERM 模型分別對人民日報語料庫、中文推特多模態語料及地方志多模態語料庫中的句子進行文本表示。
2)圖片特征提取
以卷積神經網絡(convolutional neural network,CNN)[19]為基礎構建的模型,如VGG16、VGG19等[20],在多個計算機視覺任務中均獲得了最優結果。這一方面得益于CNN 強大的特征學習建模能力,另一方面則受益于大規模的圖片訓練集,如Ima‐geNet[21]。目前常用的圖片提取方法是利用ImageNet數據集中預訓練的CNN 模型,提取最后一層全連接層的輸出作為圖片的特征表示。但為了獲取圖片的空間特征表示,本文遵循文獻[8]中的方法,以預訓練于ImageNet 數據集的VGG19 模型中的最后一層池化層的輸出作為圖片的特征表示。本文利用MNERM 模型分別提取中文推特多模態語料及地方志多模態語料中的圖片特征。
3.2 BiLSTM-attention-CRF模型
文本的語義信息是識別實體類別的核心,已有研究表明,將人民日報語料庫(1988)作為遷移學習的學習語料,并利用基于深度遷移學習的方法對其他語料庫中的相同實體進行識別,有著良好的效果[17]。為了使MNERM 模型中的BAM 模塊擁有先驗知識,本文設計了用于權重遷移的BAC 模型。目前常用的命名實體模型多基于BiLSTM-CRF 架構[7-8],與之不同的是,本文引入了自注意力機制(self-attention),而利用自注意力機制能夠有效增強文本的語義表示。BAC 模型主要由BiLSTM 網絡、自注意力層及CRF 層。BAM 模塊由BAC 模型中的BiLSTM 網絡和自注意力層組成。BiLSTM 作為循環神經網絡(recurrent neural network,RNN)的變體,能夠較好地學習句子中的上下文關系,具有捕捉長距離依賴的能力,并能夠克服因序列長度過長所帶來的梯度消失和梯度爆炸的問題。給定人民日報語料庫中的句子S={s1,s2,…,si,…,sn},進行特征表示后 的 句 子 為其 中 ,n表示句子長度,dw表示向量維度,大小為300。BiLSTM 獲得的隱藏層狀態hi∈Rd由前向的LSTM輸出和反向的LSTM 輸出拼接而成,d表示隱藏層單元數,具體公式為
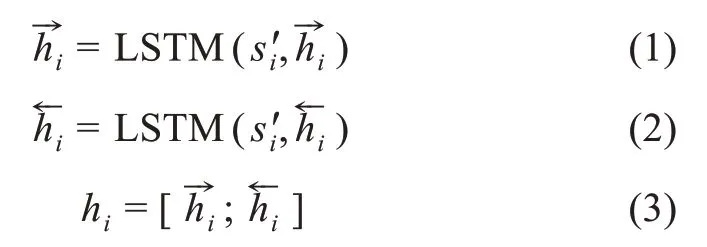
注意力機制起源于人類視覺,當人觀察物體或閱讀書本時,會對其中的某一區域投入大量注意力,獲取富含價值的信息,并抑制對其他區域的注意力投入。目前已有工作利用注意力機制進行自然語言處理任務,如機器翻譯、情感分析等;而有關利用自注意力機制進行命名實體識別任務的研究相對較少。通過利用注意力機制,能夠確定在決定詞的標簽時,有多少詞的信息被利用,從而提升模型性能。自注意力機制關注句子內部的特征相關性,并能夠減少對外部特征的依賴。在自注意力機制中,句子中的每個語義單元同其他語義單元進行注意力權重計算,可以有效捕捉詞間的相互關系,獲取句子結構信息,增強特征表示。自注意力機制本質上是輸入Query(Q) 到一系列鍵值對(Key(K),Value(V))的映射函數,對BiLSTM 生成的句子表示H={hi|hi∈ Rd,i= 1,2,…,n},應用自注意力機制獲得的編碼表示為E={ei|ei∈Rd,i= 1,2,…,n},具體公式為

其中,Q、K、V為隱藏層狀態hi的特征;Softmax 為歸一化函數。將編碼后的文本表示輸入CRF 層進行解碼,獲得文本中詞對應的預測標簽Y={y1,y2,…,yi,…,yn},
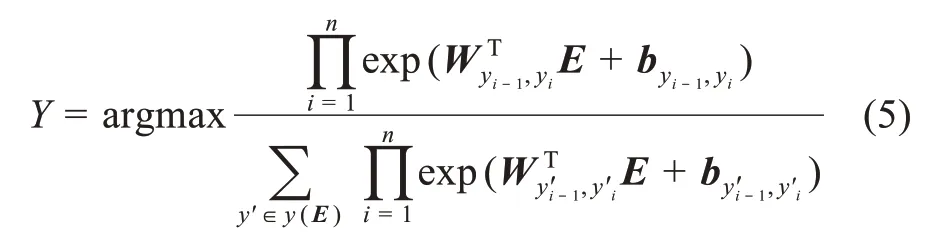
其中,W、b表示全權重矩陣。本文利用經典的最大條件似然估計對CRF 層進行訓練,具體公式為
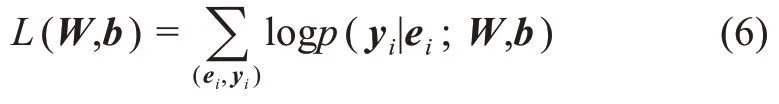
3.3 自適應聯合注意力機制模型
鑒于當前尚未有中文多模態命名實體識別公開數據集,僅有英文推特多模態命名實體識別公開數據集,目前已有研究涉及利用英譯漢平行語料來進行深度遷移學習,并在公開數據集中取得了較好的性能[22]。因此,本文制作了推特多模態數據集的中文平行語料作為ACAC 模型的訓練語料,將ACAC模型中自適應聯合注意力網絡的權重灌入ACAM 模塊中,其主要由自適應聯合注意力機制網絡和CRF層組成。不同于自適應聯合注意力機制結構[8],在ACAC 模型中,本文將VGG-16 圖片特征提取模型替換成性能更佳的VGG-19[23],其余部分保持一致。
自適應聯合注意力機制由詞引導的注意力機制(word-guided attention,WGA)、圖引導的注意力機制(image-guided attention,IGA)和門機制組成。由圖1 可以看出,圖片中僅包含長江大橋的區域與文本中的“長江大橋”有關,如果考慮圖片中的全部區域,那么會帶來噪聲和信息冗余。詞引導的注意力機制核心思想是給序列中的一個詞,利用Softmax函數計算圖片中的各個區域同該詞的相關程度,過濾掉與其不相關的區域和信息,減少計算復雜度,以達到最優結果。應用詞引導的注意力機制,則能讓模型過濾掉噪音并找出與當前詞最為相關的圖片區域。給定文本序列X={x1,x2,…,xt,…,xn},利用BiLSTM 編碼后的輸出表示為M={mt|mt∈Rd,t=1,2,…,n},利用VGG19 模型提取與文本相對應的圖片特征為T={ti|ti∈ R512,i= 1,2,…,49},其中特征圖的數量為49,512 表示特征圖的維度。應用詞引導的注意力機制得到與詞mt相關的圖片特征向量
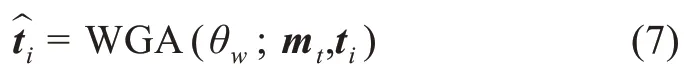
其中,θw為詞引導的注意力機制中的參數。利用WGA 能夠獲得與詞mt相關的圖片特征向量但是并不知道序列中的哪個詞與mt相關。因此,需要利用圖引導的注意力機制去尋找與圖片特征的最相關的詞。圖引導的注意力機制的核心思想是在給定新的圖片特征向量下,計算序列中的詞同圖片特征向量的相關程度,從而提升序列的特征表達能力。因此,利用IGA 可以計算出與圖片特征表示相關的詞
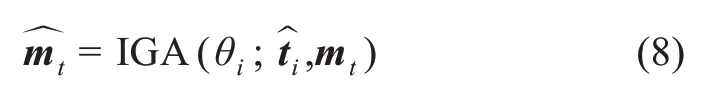
其中,θi為圖引導的注意力機制中的參數。門機制主要由融合門和過濾門組成。為獲得文本和圖片的多模態特征表示,利用門機制中的融合門對新獲得的依賴于IGA 的詞特征和依賴于WGA 的圖片特征向量進行拼接,獲得多模態融合后的中間特征表示。盡管利用WGA 和IGA 能夠生成富含多模態語義特征的中間表示,但是依然存在噪聲。例如,當預測文本中實體所包含的副詞或形容詞標簽時,與之對應的圖片特征并不能提供語義表示的增強,反而會引入噪聲。因此,應用門機制中的過濾門,采用Sigmoid 函數對融合后的多模態中間表示特征進行噪聲過濾,獲得高質量多模態中間特征表示gt。盡管融合后的多模態中間特征能夠在一定程度上完成對文本和圖片語義的聯合表達,但是命名實體識別的核心語義依舊在于文本。因此,通過將BiLSTM 編碼后序列特征與多模態中間表示特征相拼接,獲得最終多模態表示特征ut,具體過程為
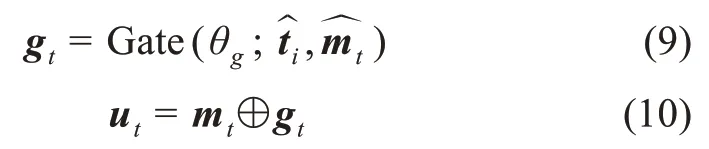
其中,gt,ut∈Rd;θg為門機制中的全部參數。將編碼的多模態特征ut表示輸入CRF 層中進行標簽解碼,并利用最大似然估計對CRF 層進行訓練,獲得解碼標簽。
3.4 深度遷移學習
為了緩解當前可利用標注語料匱乏的現狀,本文提出利用深度遷移學習方法探索解決這一問題,并設計了基于深度遷移學習的MNERM 模型。利用預訓練完成的BAC 模型和ACAC 模型,將相應的權重分別遷移至BAM 模塊和ACAM 模塊中,使得MNERM 模型具備對目標域(地方志多模態數據集)抽取文本和多模態特征的能力。
給定用于進行實體識別的地方志文本圖片對(C,P),C經過加載權重后的BAM 模塊得到的編碼輸 出 為C'={ci|ci∈ Rd,i= 1,2,…,n},(C,P) 經 過 加載權重后的ACAM 模塊得到的多模態特征表示K={ki|ki∈Rd,i= 1,2,…,n}。盡管利用遷移學習后的多模態特征能夠在一定程度上增強文本語義信息,但是其仍包含一定的噪聲,并且模型學習的語料并不是原始中文語料,而是英譯漢平行語料,經過翻譯后會部分丟失原意,引入噪聲。因此,本文提出應用過濾門對提取的多模態特征進行噪聲過濾,得到過濾后的多模態特征V={vi|vi∈Rd,i= 1,2,…,n},之后將文本語義特征表示C'與多模態特征表示V進行融合輸入至一層全連接層中進行非線性激活,獲得最終的多模態特征表示Z={zi|zi∈R2d,i=1,2,…,n},具體過程為
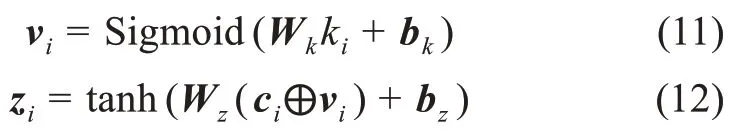
其中,Wk和Wz為權重矩陣;bk和bz為偏置項;tanh 為非線性激活函數。本文將多模態特征Z輸入CRF 層中,微調后獲得最終的預測標簽。
4 實證研究
4.1 實驗數據集
1)人民日報語料庫
本文使用的是1998 年1 月的人民日報語料庫,該語料庫由北京大學計算語言學研究所和富士通公司聯合制作并發布,被廣泛應用在命名實體識別研究中。語料庫中包含人名、地名及機構名實體,本文以行對語料進行切分,共獲得19484 條句子,將語料庫的80%作為訓練集,剩余的20%作為測試集。
2)中文推特多模態數據集
本文使用的是Zhang 等[8]用于多模態命名實體任務的英文推特數據集。該數據集共包含8257 個句子和圖片對,標注實體類別為人名、地名、機構名及其他實體,利用BIO(begin,inside,outside)規則[24]進行實體標注。該數據集經雙人標注完成,包含的實體數量為12784,訓練集句子數量為4000,驗證集數量為1000,測試集數量為3257。為了制作平行語料,本文首先利用科大訊飛翻譯API(appli‐cation programming interface) 對數據集進行翻譯,并召集5 位研究生對平行語料進行檢查,使其通順并保持原意;然后利用jieba 包對語料進行分詞,并使用相同標注規則對照原英文語料進行實體標注;最后得到中文推特多模態數據集。在英文推特中,語料中常包含縮寫詞及非中文對應實體詞,同時考慮到遷移應用的語料,本文在中文平行數據集中去除了其他實體類別。該平行數據集中的訓練集、驗證集及測試集數量均與原數據集保持一致,在實體對照的標注過程中,當中文出現了英文中未標注的實體,本文則加以補充,最后得到的實體數量為10636。
3)地方志多模態數據集
利用本課題組編寫的爬蟲對《南京簡志》①江蘇古籍出版社,1986年出版。《南京人物志》②學林出版社,2001年出版。《南京園林志》③方志出版社,1997年出版。《南京城墻志》④鳳凰出版社,2008年出版。、百度中的南京地方志等資源進行爬取,獲取志書中的圖片及相應文本描述,文本均為現代文。搜集到的文本及圖片對數量為2885,經過過濾及去重,共獲得1659 個文本圖片對。之后對數據進行實體標注,標注由組內的兩位研究生完成,標注規則為BIO[24],標注實體類別分別為人名、地名及機構名,實體總量為2908。標注后的地方志多模態數據集作為檢驗本文提出的MNERM 模型的性能測試語料。本文同時標注了500 個用于微調的文本圖片對。
4.2 實驗設置
本文所用編程語言為Python 3.6,使用的深度學習框架為tensorflow2.3.0,本文的實驗均在兩塊GPU型號為NVIDIA GeForce RTX 2080ti、內存為16G 的服務器中完成。
4.3 基線模型
基于深度遷移學習的MNERM 模型主要由BAM模塊、ACAM 模塊、過濾門及CRF 層構成,組成模塊的性能影響著整體模型的表現。因此,本文按照使用的數據集,分別是人民日報語料庫和中文推特數據集,將組成模塊對應的模型(BAC 和ACAC)與不同的基線模型進行對比,以驗證其性能。最后,本文將MNERM 模型在地方志多模態數據集進行性能驗證,并與基線模型作對比。
1)人民日報語料庫
本文選擇了幾種具有優異性能的文本實體識別模型,將其與BAC 模型作對比,具體如下。
BiLSTM-Att[25]:該模型使用的注意力機制同BAC 模型相同,解碼層使用Softmax 函數作為標簽解碼層。
BiLSTM-CRF[26]:該模型結合了BiLSTM 模型和CRF 模型,具有良好的實體識別效果,并被廣泛應用在命名實體識別任務中。
BiLSTM[27]:相較于BiLSTM-CRF 模型,該模型利用Softmax 函數作為序列解碼層,具有一定的實體識別性能。
CRF[28]:該模型為命名實體識別任務中的經典模型,能夠較好地考慮到序列特征并避免標簽偏置問題。
1.1 研究對象 本研究以上海市某地區失去獨生子女的父母作為研究對象。納入標準:(1)沒有領養意愿及行為,已經喪失再生育能力的夫婦;(2)年齡≥50 歲;(3)失去獨生子女 1年以上;(4)能獨立完成問卷調查。排除認知障礙及患有重大精神疾病者。
2)中文推特多模態數據集
ACAM 模塊主要由WGA、IGA 和門機制組成,為驗證組成部分的優越性,本文對基于ACAM 的ACAC 模型進行了消融實驗,分別去除了WGA、IGA 和門機制,形成Without-WGA、Without-IGA 和Without-Gate 等模型。同時,為了驗證多模態融合的性能,本文將其與僅基于文本的BiLSTM-CRF 作對比,具體如下。
Without-WGA:該模型去除了詞引導的注意力機制,僅保留了圖引導的注意力機制。
Without-IGA:該模型去除了圖引導的注意力機制,僅保留了詞引導的注意力機制。
Without-Gate:該模型在自適應聯合注意力網絡中去除了門機制。
BiLSTM-CRF[27]:該模型對文本序列進行命名實體識別,參數與ACAC 保持一致。
3)地方志多模態測試數據集
為了驗證MNERM 模型的性能,本文將僅在人民日報語料庫和中文推特數據集中進行預訓練的BAC 和ACAC 作為對比模型,微調方式均保持一致。同時,為了驗證過濾門的性能,本文設計了去除過濾門的模型Without-FGate 作為對比。本文還將哈爾濱工業大學提供的Language Technology Plat‐form(LTP)[29]中的命名實體工具作為對比模型。
4.4 實驗結果及分析
1)人民日報語料庫
表1 呈現的是BAC 模型與其他模型的對比結果。從表1 可以看出,本文提出的模型在各個指標中均表現最優。在同BiLSTM-CRF 的比較中可以發現,當模型的解碼層均保持相同時,引入自注意力機制能夠使模型更為關注那些能夠決定序列標簽的信息,生成富含語義特征的序列特征,從而提升模型識別實體的性能,這也是BAC 模型具有一定優勢的原因。在同BiLSTM-Att 的對比中,當模型的編碼層保持一致時,利用Softmax 層作為識別實體的解碼層,盡管能夠取得一定的性能,但依舊劣于BAC 模型。相較于Softmax 層,CRF 能夠對隱藏層的各個時間步進行有效建模,學習并觀察序列中的標簽特點,從而提升模型的解碼性能。這樣的優勢同樣體現在BiLSTM 和BiLSTM-CRF 的對比中。當忽略文本的上下文關系,僅用詞向量對文本進行表示時,將其輸入CRF 層進行解碼,從結果可以發現,CRF 模型均劣于使用BiLSTM 或結合自注意力機制的模型作為上下文建模的模型,這充分說明了文本上下文在命名實體識別任務中的重要作用,同時也表明利用BiLSTM 等時間序列模型能夠較好地學習文本上下文關系,并能生成富含上下文關系及語義信息的序列特征。
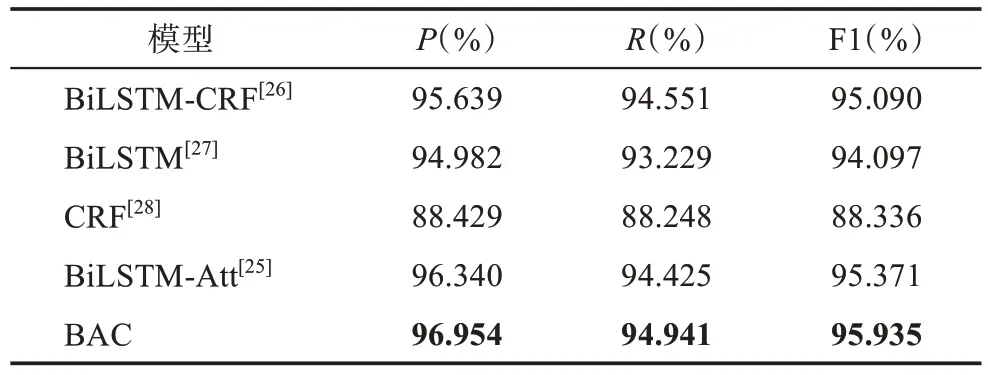
表1 模型在人民日報語料庫中的測試結果
通過比較分析發現,本文引入的BAC 模型具有較好的實體識別性能,而模型包含的BiLSTM 和自注意力網絡在其中發揮了充分抽取語義特征的重要作用,這也是本文將BiLSTM 和自注意力網絡(BAM 模塊)作為MNERM 模型組成部分的原因。
2)中文推特數據集
自適應聯合注意力機制由圖引導的注意力機制、詞引導的注意力機制及門機制組成。每個組成部分均能對ACAC 模型性能產生影響,為了探究不同組成成分的作用及整體組合的性能,本文對此進行了探究。
表2 呈現的是各對比模型在中文推特多模態數據集中的結果,可以看出,ACAC 模型在F1 這一指標上表現最優。當去除圖引導的注意力機制后,Without-IGA 模型在精確率(P) 這一指標上優于ACAC 模型,但是在召回率(R)和F1 指標上均劣于ACAC。盡管ACAC 模型在預測序列正標簽樣本中并沒有表現出最優性能,但是在序列中的各實體類別真實標簽樣本識別中效果最佳,并在召回率這一指標上超出With-IGA 模型近7%。當去除詞引導的注意力機制后,僅利用圖引導的注意力機制并不能較好地學習到文本和圖片之間的模態交互和關聯關系,這也是Without-WGA 劣于ACAC 的原因。在同Without-FGate 模型的對比中,可以發現門機制在模型中的重要作用,引入門機制能夠較好地聚合多模態融合特征,同時有效過濾來自模態融合中的噪聲。當不考慮文本對應的圖片時,通過對比BiLSTMCRF,可以發現圖片信息在增強文本語義特征中的作用,這也是ACAC 模型表現良好的原因。因此,本文將去除了CRF 層的ACAC 模型作為MNERM 模型中的ACAM 模塊,用于提取地方志數據中的多模態特征。
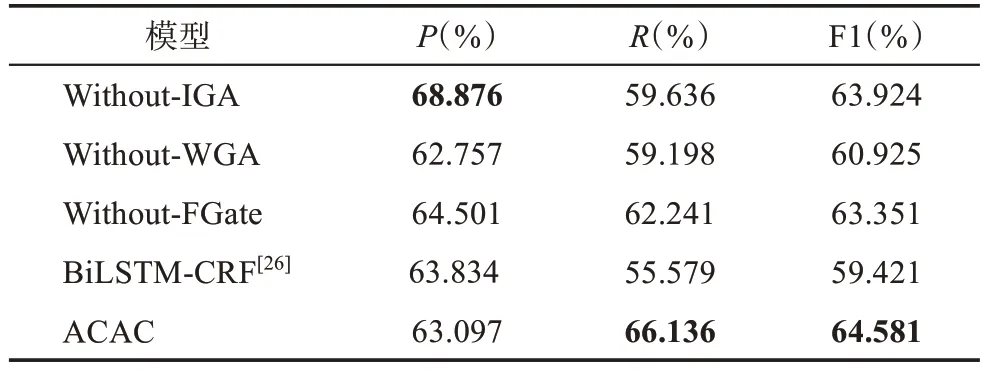
表2 模型在中文推特數據集的測試結果
3)地方志多模態數據集
表3 呈現的是經過微調后的不同對比模型對地方志多模態數據集進行實體識別的結果,各模型所用的微調數據均一致。利用通用模型LTP 對地方志語料進行實體識別并沒有取得較好的效果。與BAC模型比較可以發現,當MNERM 模型聯合多模態語料庫知識后,模型性能有了較大提升。這表明在多模態語料庫中預訓練實體識別模型后,利用基于神經網絡的深度遷移學習方法,將權重灌入MNERM模型對應模塊中,能夠使得MNERM 具備捕捉不同模態間的語義相關關系及動態交互的能力,從而獲得更優的性能。在與ACAC 的比較中可以發現,盡管利用在中文推特多模態語料庫中的預訓練模型ACAC 能夠取得一定優勢,但是劣于含有人民日報語料庫知識的BAC 模型以及MNERM 模型。一方面是因為在制作平行語料的過程中,會伴隨著部分英文原意信息的丟失;另一方面是因為源域英文推特數據集大多由推特平臺上用戶的發帖組成,內容大多關于用戶生活的分享,而目標域則是地方志多模態內容,目標域與源域之間存在著部分不相關的知識。當本文引入過濾門后可以看出,采用過濾門的MNERM 模型在精確率和F1 指標上均優于Without-FGate 模型。盡管應用過濾門機制使得召回率輕微下降,但是F1 值提升了1.042%。這表明,應用過濾門能夠對深度遷移學習得到的多模態融合特征噪聲進行有效過濾,同時能夠彌補因源域和目標域之間存在不匹配知識所造成的性能損失。
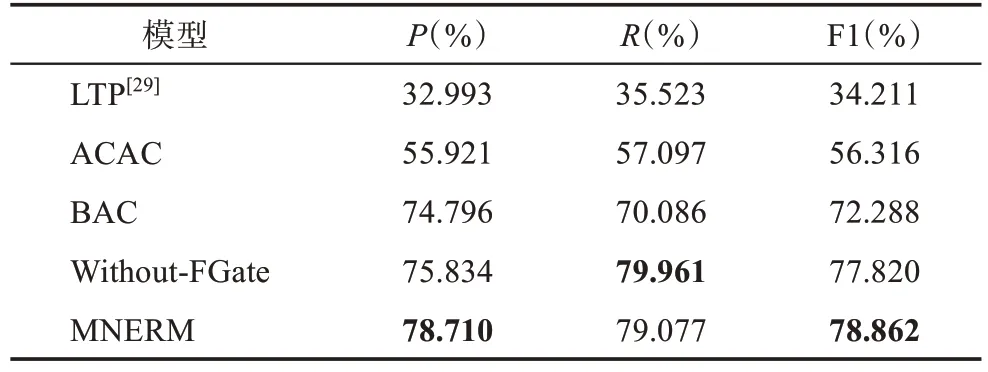
表3 地方志多模態數據集深度遷移學習結果
4)深度遷移學習有效性分析
為了探究深度遷移學習在地方志多模態命名實體任務中的有效性以及模型對目標領域的適配性,本文通過調節預訓練模型中訓練集大小進行驗證[6]。圖3 展示的是當人民日報語料庫訓練集大小成比例增加時,BAC 模型在人民語料庫中的測試性能及在地方志多模態數據集中的文本進行深度遷移學習的結果。從圖3 可以看出,隨著預訓練模型中訓練集數量的增加,經過微調后的權重遷移模型對地方志文本進行實體識別的性能呈上升趨勢。該趨勢同樣呈現在ACAC 模型對地方志多模態數據的實體識別中。
從圖4 可以看出,當人民日報語料庫及中文推特多模態數據集中的訓練集同步成比例上升時,應用深度遷移學習的MNERM 模型在對地方志多模態數據集中的實體進行預測時,性能總體呈上升趨勢。綜合圖3、圖4 中的結果可以發現,預訓練模型中訓練集的大小影響著后續應用深度遷移學習的效果,這表明本文提出的深度遷移方法具有一定的有效性,并且顯示出本文提出的MNERM 模型對目標領域具有較強的適配性。
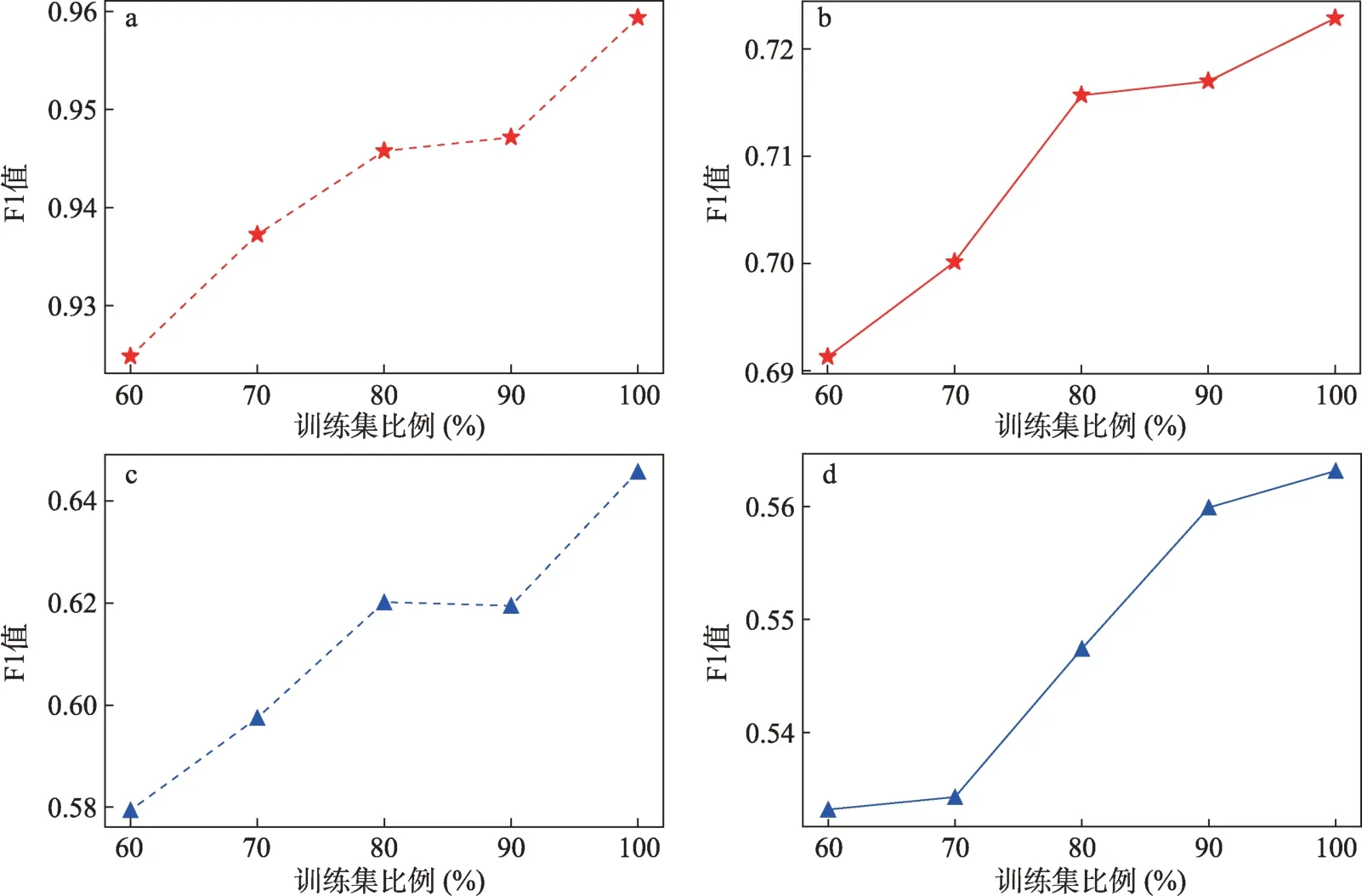
圖3 訓練集比例對BAC模型和ACAC模型性能及應用深度遷移學習的影響
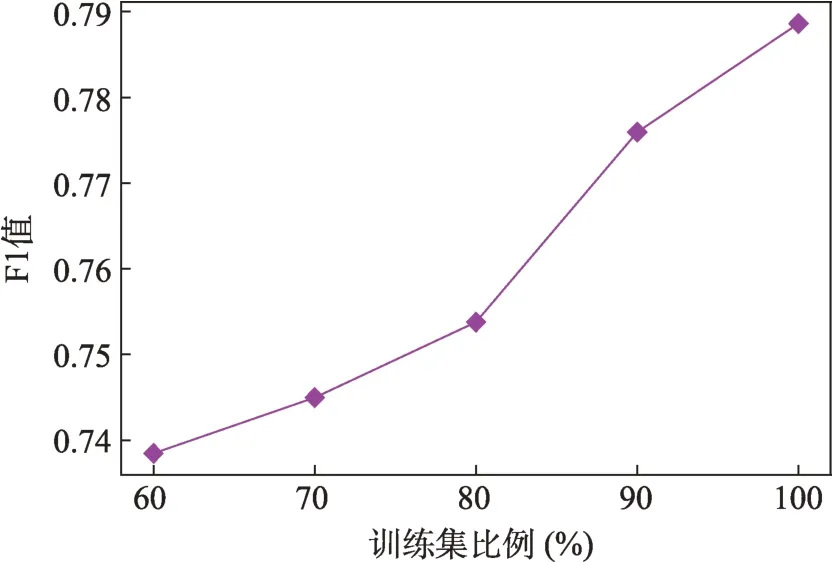
圖4 預訓練模型中的訓練集比例對MNERM模型性能的影響
4.5 誤差分析
表4 呈現的是利用不同模型對地方志多模態數據集中的部分數據進行預測的結果。在例1 中,MNERM 模型和ACAC 模型均對地名實體做出了準確的預測,而BAC 模型則做出了錯誤判斷。例1 圖片中的大樓為文本的地名實體提供了語義增強作用,通過多模態融合則可以產生更富含語義的表示,從而提升實體識別的性能。在多模態命名實體中,文本的語義信息依舊是實體識別的核心信息。在例2 中,盡管利用ACAC 模型未能對人名實體進行有效識別,但僅依靠文本語義信息,BAC 模型做出了準確判斷,而作為ACAC 模型和BAC 模型兩者的結合,依靠捕捉文本語義信息的BAM 模塊,MNERM 模型同樣預測成功。在例3 中,MNERM模型和BAC 模型均對人名和組織實體做出了準確判斷,而ACAC 模型僅識別出了人名實體,未能識別出組織實體。例3 圖片中的人像為人名實體的識別提供了語義增強作用,但是在組織實體識別中,與文本相對應的圖片未提供相應的補充特征,ACAC模型未能對組織實體進行識別。盡管MNERM 模型在利用深度遷移學習的多模態命名實體識別任務中能夠取得一定效果,但其未能夠有效利用文本中的字級特征,而聯合字級的特征則可以增強文本的表示能力,能夠進一步改善多模態特征融合后的語義表示特征,從而提升遷移學習后實體識別的性能。

表4 不同模型對地方志多模態數據進行實體識別的結果
5 總結與展望
當前,面向地方志等文化資源的命名實體識別研究主要基于文本,忽略了文本對應的圖片信息,同時還面臨著在領域內訓練實體識別模型缺乏已標注數據集的困境。為了解決該問題,本文從多模態視角出發,結合地方志對應的圖片信息,并提出基于深度遷移學習的MNERM 模型。該模型由四個部分組成,分別是BAM 模塊、ACAM 模塊、過濾門及CRF 層。為了驗證模型組成部分的有效性,本文將包含對應模塊的模型(BAC 和ACAC)與不同基線模型進行對比,實驗結果表明,模型各組成部分均包含一定的優勢。利用經過權重遷移后的BAM模塊和ACAM 模塊,MNERM 模型能夠有效獲取文本語義特征及多模態特征,應用過濾門對ACAM 模塊輸出的多模態特征進行去噪,最后將BAM 模塊輸出的文本語義特征及過濾后的多模態特征進行融合,輸入至CRF 層進行解碼。實驗結果表明,本文提出的模型在同基線模型的比對中具有一定優勢。同時,為了驗證深度遷移學習的有效性和對目標領域的適配性,本文將預訓練模型中的訓練集比例作為參數進行調節,發現當源域訓練集越大,經過深度遷移學習后的模型表現越佳。
本文提出的模型和方法不僅適用于地方志多模態命名實體識別,也適用于數字人文領域中標注數據集匱乏的文化資源,如非遺等。在未來的研究中,本課題組將進一步提升模型的領域泛化能力,提升模型利用深度遷移學習進行多模態實體識別的性能以及中文多模態命名實體識別數據集的構建。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學院學報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:39
語文知識(2014年1期)2014-02-28 21:59:13
