基于先精確后召回策略的作者名消歧模型研究
2022-05-19 06:58:28鞠秀芳
情報學報 2022年4期
沈 喆,王 毅,鞠秀芳,成 穎
(1. 南京大學信息管理學院,南京 210023;2. 南京大學中國社會科學研究評價中心,南京 210093)
1 引 言
目前,作者名歧義已經對科學計量與評價研究的可靠性、信息檢索的查全與查準率等產生了較大的負面影響[1]。為此,在作者個體層面建立完整且準確的學術成果集,即實現作者名消歧(author name disambiguation,AND) 已成為學界的迫切需求。鑒于AND 提供的重要數據支撐作用,學界已經對其開展了相當豐富的研究,研究成果的概貌可見之于 Smalheiser 等[2]、Elliott[3]、Hussain 等[4]、San‐yal 等[5]學者的綜述。不過,現有研究與實踐尚難以支撐后繼應用的需要,比如,ORCID、ResearchID等作者身份標識碼存在普及率不高的問題;個人或研究團隊主頁等外源性數據普遍存在數據不完整、更新不及時以及網頁的異構造成的可用性低等問題;基于機器學習的消歧模型的F1 值普遍差強人意且泛化能力弱[6],以AMiner 數據庫為例,其研究團隊利用網絡表示學習等方法建構的消歧模型的F1值僅達到了0.68[7]。
高層次科研人才作為國家科技核心競爭力和科學事業發展的領軍人物,現有的計量以及科技人才評價等研究多聚焦于此,如諾貝爾獎獲得者[8-10]、中國科學院院士[11]、長江學者[12-13]、國家杰出青年科學基金獲得者(下文簡稱“杰青”)[14]等。相關研究重點探討了人才的產出規律、成長軌跡以及影響因素等。顯然,高AND 精確率和召回率的數據集是相關研究得到可靠結論的重要前提。目前,有關諾貝爾獎獲得者的成果已經有開放的數據集,具體到院士、長江學者以及杰青等我國的高層次科研人才尚未見類似的成果,現有研究主要通過人工核驗等方式收集少量樣本數據[11-14]。諾貝爾獎獲得者等他山之石雖可攻玉,但以我國的高層次科研人才為對象的研究對國家的人才及團隊的評價、潛在優秀人才的發現和培養、學科建設與發展等方面均會有更直接的價值。因此,有必要構建以院士、長江學者以及杰青等為代表的高層次科研人才學術成果的開放數據集。
目前,采用機器學習、圖模型等的消歧方法在AND 上的表現均沒有達到實用的要求[6],而基于規則方法具有高效率和高精確率等優點;從實用性的角度出發,本研究擬采用基于規則的方法開展研究工作。擁有較強影響力和知名度的高層次科研人才的履歷、研究方向和學術成果等外部數據對于提高消歧模型的精確率和召回率有重要作用,且相關信息易于從網絡搜集,可以保證本研究的順利開展。考慮到不同類型高層次科研人才的成長性,本研究擬以杰青為例開展研究工作。據此,本研究擬采用上述外部數據并結合文獻元數據,采用“先面向精確率,后面向召回率”的逐步優化策略,構建基于規則的“兩步法”消歧模型,為解決高層次科研人才的學術文獻AND 提供一條可行的路徑。
2 文獻綜述
2.1 AND研究概況
Ferreira 等[15]提出,一人多名(synonyms)和一名多人(homonyms)是引發作者名歧義的兩個主要原因。前者多源于拼寫變體或錯誤,隨婚姻、宗教、性別等因素改名以及使用多個筆名等;后者則主要源于少數姓氏的流行和名字的常見性等[2],在亞洲國家尤為突出,并且,期刊常使用姓氏+名首字母的方式表示作者信息,進一步加劇了一名多人的情況[5]。值得注意的是,隨著我國科研實力和國際地位的提升,我國學者發表的外文文獻數量高速增長,但同音不同字、拼寫不規范、復姓、多音字等姓名翻譯問題使得國內學者外文文獻中的姓名存在歧義的程度更為嚴重[16]。同時,元數據缺失或不完整、多作者、多學科以及跨機構的合作等也為AND 帶來了更大的挑戰[2]。目前,常見的AND 系統框架通常包括特征提取、特征表示以及模型訓練與預測等模塊。
(1)特征提取。AND 的特征主要來源于文獻數據庫中的元數據和外源性數據。元數據提供了消歧的常用特征,如作者層面的合作關系、地址以及郵箱等,文獻層面的標題、出版物名、摘要以及關鍵詞等。外源性數據包括從科研機構、ResearchGate、ORCID 等平臺的個人主頁中提取的成果列表、學者ID,以及從搜索引擎的檢索結果中挖掘出的網頁共現關系等。由于元數據不同程度的缺失、個體學習或工作單位的變動、跨學科研究的增多等原因,外部數據有助于解決元數據特征明顯不同時的合并問題。
(2)特征表示。Huang 等[17]根據表示模型的數學理論基礎,將特征表示分為基于集合論、代數、概率、圖結構以及混合方法等5種。具體到AND,常見的集合論模型方法包括Jaccard 系數[18]、N-gram[19]、Jaro-Winkler 相似度[20]以及 Hamming 距離[21]等,代數模 型 方 法 則 包 括 One-Hot 編 碼[22]、 TF-IDF[23]、word2vec[7,24]、doc2vec[25-26]和語義指紋[27]等,概率模型主要使用特征共現的頻率刻畫對象間的關聯強度[28-33],圖結構模型常見的有多特征網絡[34]以及異構網絡[25-26,35],混合模型的主流方法包括成對似然排序[25,36-39]、 DeepWalk[40-41]、 node2vec[42]以 及 圖 卷積[7,26,43]等。
(3)模型訓練與預測。模型訓練與預測模塊將識別待消歧文獻所歸屬的作者實體。Ferreira 等[15]歸納了兩種實現思路,一是分組(grouping),依據共性特征歸并事先未知的作者實體文獻集;二是指派(assignment),根據特征相似度將文獻指派給已知的實體,該方法所需人工標注工作量較大。現有AND 研究多集中于分組方法,可劃分成基于機器學習、基于圖和基于啟發式規則三類。
基于機器學習的模型在AND 中應用廣泛,不過鑒于有監督的分類方法存在較多缺陷,如過度依賴標注數據的規模和質量、訓練數據分布不均等[44],現有研究中無監督的聚類方法更為多見,包括層次聚類[25,36,41-43]、譜聚類[24]、AP 聚類[37]、K-means[45]等。聚類方法的難點在于確定聚類數或者聚類結束的條件,多數研究僅設定了一個相似度閾值,即當簇間距離均低于閾值時停止。部分研究提出了更多的思路,例如,根據標注數據訓練神經網絡模型估計不同數據規模的合適聚類數[7];在特征網絡圖中,簇間沒有邊相連則停止聚類[26]等。此外,使用多特征聚類時需要判斷不同特征的重要性,有研究在少量標注數據中訓練邏輯回歸分類器,以確定不同特征的區分能力[29,46];Xu 等[47]基于每個特征都完成一次聚類,計算F1 值占比賦予權重。代表性的相關研究如表1 所示。
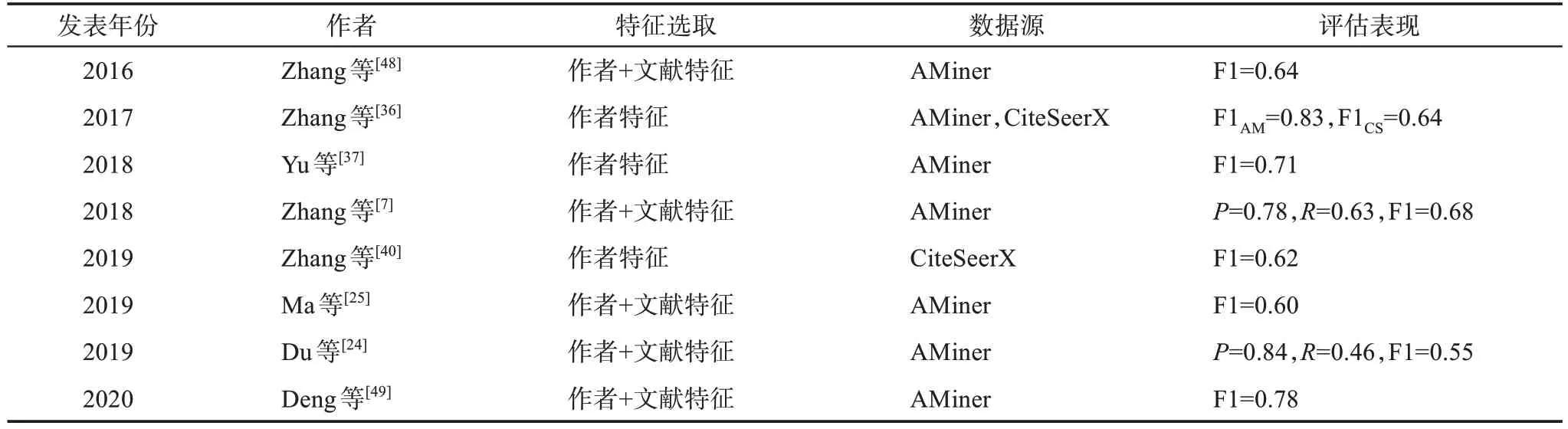
表1 基于機器學習模型的AND研究
基于圖的模型依據路徑識別同一作者實體,具體采用的判斷條件包括有效路徑強度之和高于閾值[35]、最短路徑的距離低于閾值[50]等。此外,采用連通分量方法將有邊相連的節點歸并成同一類的思路對網絡圖的構建提出了更高的要求,文獻[19,51]結合了機器學習方法用于決定網絡中邊的連接。代表性的相關研究如表2 所示。
基于規則的模型相較于時間復雜度高的機器學習和圖模型,擁有高效準確的優勢。該模型的關鍵在于確定處理順序的優先級以及合理的特征組合。例如,劉林[52]認為同一作者實體在不同機構的發文時間窗應該不同。Hazra 等[53]則認為不同機構的同一實體,其研究高峰年以及活躍區間可以相似,即存在研究者同時就職于多個單位的情況。Sun 等[54]認為在細分領域下作者重名的可能性很小,使用兩次聚類細化研究領域的描述,將其作為區分不同作者的主要依據。Cota 等[55]基于合作者姓名、論文題名以及期刊名提出了兩步法消歧策略,第一步通過合著者將同名作者進行鏈接并據此聚類,第二步通過論文題名以及期刊名的相似度迭代歸并第一步中生成的聚簇。Schulz 等[56]基于合作者、參考文獻以及被引文獻的相似度提出了三步法消歧策略。第一步,相似度超過閾值的作者生成作者對簇;第二步,基于聚簇的相似度對第一步生成的作者對簇進行歸并;第三步,歸并獨著作者。Backes[29]的模型首先計算了論文題名、摘要以及作者機構等特征的相似度,其次根據TF-IDF 的思想對特征進行加權,最后歸并得分高于閾值的作者。Caron 等[57]提出的消歧模型計算了各特征的相似度,并根據特征對消歧的重要性進行賦權,并將超過閾值的作者進行歸并。代表性的相關研究如表3 所示。
2.2 述 評
學界圍繞AND 已積累了較為豐富的研究成果,現有研究主要涉及特定學科、綜合學科以及特定機構的學者,較少有研究針對高層次科研人才這一特定群體。相關實證研究顯示,外源性數據在面向所有類型學者的姓名消歧時作用有限[23,34],主要原因在于采集難度大[52]、數據缺失嚴重[45],同時可靠性也難以保證[19]。鑒于高層次科研人才辨識度比較高的優勢,其AND 研究中所需的相關外源性數據更易于獲得,且更加全面、可靠,在消歧中能夠發揮更重要的作用。由表1 可見,基于機器學習的AND研究的F1 多在0.7 以下,新近的一項較優的研究[49]也僅0.78;表2 顯示的結果讓人欣喜,比如,其中一項研究[35]的F1 達到了0.96,不過,閱讀該項工作的實驗數據描述表發現,作者為“李強”的文獻量僅為44,與萬方數據的實際檢索結果有較大差距,提示該數據應是在受限語境下的檢索結果,因此,該項工作在非受限的場景下是否依然有如此優異的表現尚需要進一步研究的證實。表3 提示,基于規則的F1 多優于基于機器學習,其中一項工作的F1達到了接近實用要求的0.90。

表2 基于圖模型的AND研究
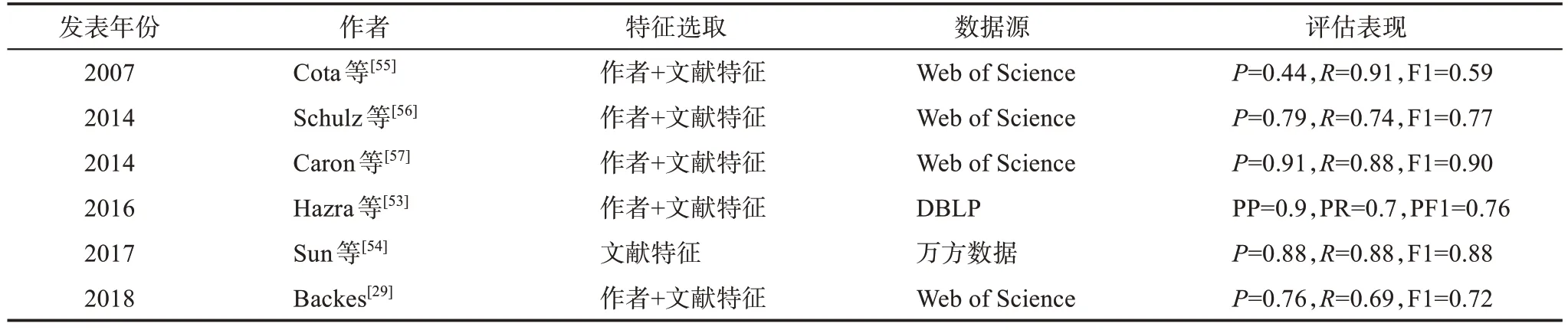
表3 基于規則的AND研究
綜上,鑒于基于機器學習算法AND 研究的F1值普遍難以滿足應用需要的現狀,以及科學計量與人才評價等研究對數據質量的高要求,本研究擬充分發揮基于規則模型在精確率方面的優勢。目前,基于規則的現有實證研究多基于計算機、物理或醫學等單一領域的數據庫,而應用于大型綜合數據集(如Web of Science)時表現難以保證,并且華人學者外文文獻消歧的相關研究較少。由于Web of Sci‐ence(WoS)等綜合性數據庫姓名歧義程度大幅提高的現狀,如基于合著關系的消歧策略的有效性難以充分彰顯[18,36]等,本研究擬采用多特征融合的策略首先面向精確率展開研究工作。同時,針對基于規則的方法在召回率上表現欠佳的問題,如針對跨學科研究、單位變動等引發的姓名歧義問題,本研究擬綜合采用現有研究中廣泛使用的基于元數據的多特征組合方法,并結合外源性數據以提高模型的召回率,建構“先面向精確率,后面向召回率”的“兩步法”消歧模型。
3 數據與方法
3.1 總體思路
目前,基于規則的AND 研究中存在一步法(Backes[29]、 Caron 等[57])、 兩 步 法 (Cota 等[55]) 以及三步法(Schulz 等[56])等不同的策略。其中,一步法難以同時滿足AND 對高精確率與召回率的要求,雖然 Caron 等[57]研究中的 F1 高于 Schulz 等[56],宜考慮是后者采用的特征集較小所致;而兩步法以及三步法提供的柔性機制更符合AND 的需要,能更好地兼顧精確率與召回率。需要說明的是,Schulz 等[56]雖比Cota 等[55]增加了獨著作者的消歧環節,不過該環節也可在第一和第二步完成,并非必需。就精確率以及召回率兩個指標而言,未消歧數據集的召回率可達100%,因此召回率在AND 研究中非首選目標;這樣,精確率必然成為AND 研究的首要著眼點,即在保證高精確率的前提下兼顧召回率,也就自然地形成了本研究的兩步法消歧模型。
據此,本研究提出的方法總體思路如圖1 所示。第一步,面向精確率。①本研究首先根據履歷信息排除與目標作者經歷不同的學者,降低待消歧文獻量;②利用郵箱、基金號、合著關系、出版物名和所屬學科類別等特征,對同一機構內的重名作者消歧;③將相關聯的文獻劃分成不同實體的文獻集;④為了從重名的不同實體中識別出目標作者文獻集,進一步引入基金名、外部數據中的代表作和研究方向特征進行優化。
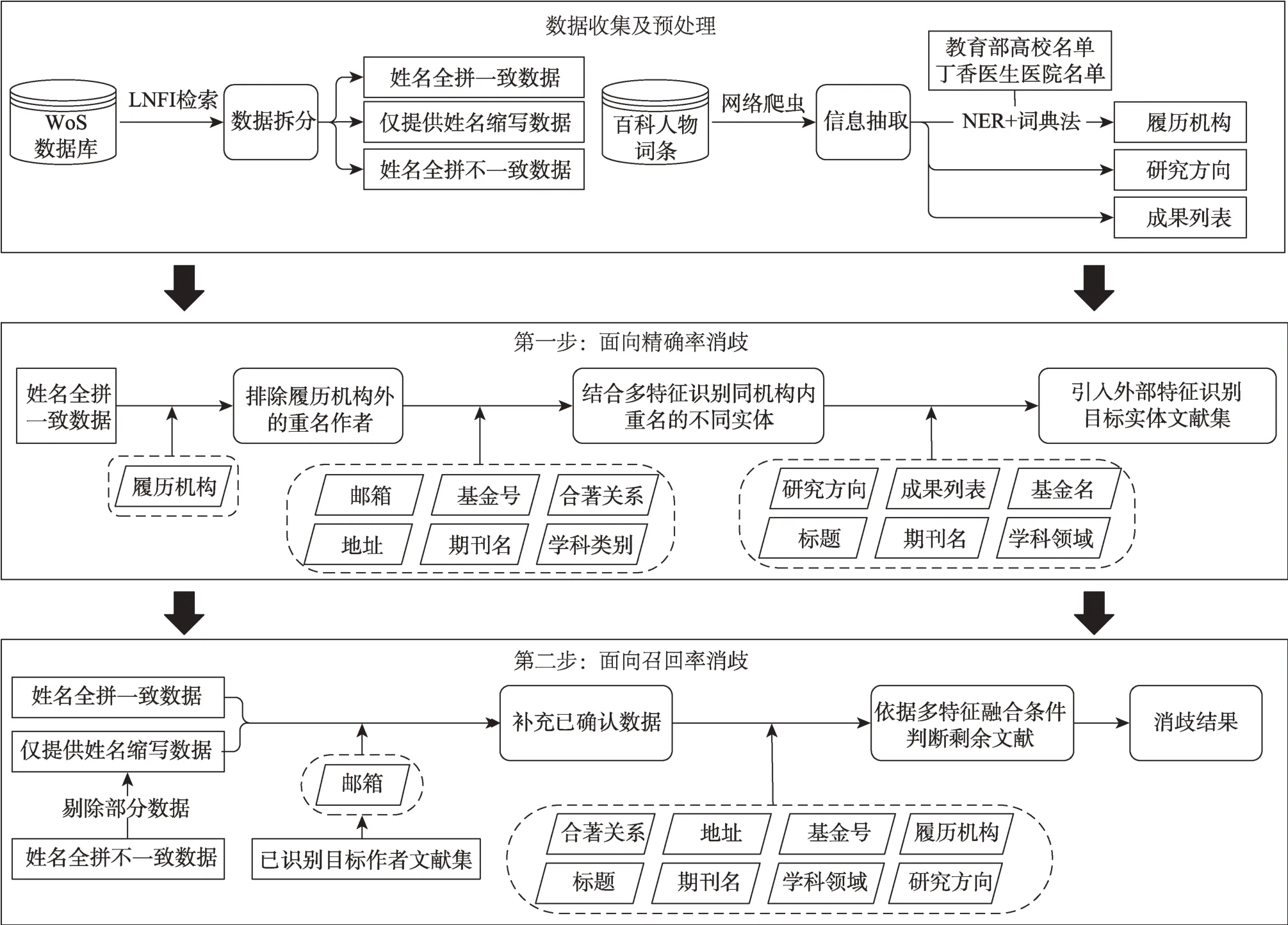
圖1 高層次科研人才兩步法姓名消歧模型
第二步,面向召回率。本研究依據第一步已確認作者身份的文獻集,對誤檢漏檢的文獻做進一步處理。①郵箱可以快速準確地識別出同一作者的文獻;②與初步擴充的文獻集進行比對,采用合著關系、地址、基金號等元數據特征,以及履歷機構、研究方向等外部特征的合理組合進行判斷;③形成目標作者的完整消歧文獻集。
3.2 數據預處理
3.2.1 文獻數據庫
根據作者名對文獻數據進行分區(blocking)通常是消歧的第一步,旨在降低后續消歧任務的復雜度以及非同名數據的干擾,現有研究多采用姓全拼+名首字母(last name-first initial,LNFI)的方式進行劃分。對華人學者的外文文獻進行消歧時,需要注意的是,WoS 數據庫自2006 年11 月開始提供作者姓氏+名全拼(last name-first name,LNFN)的信息[58],即數據集中存在LNFI 和LNFN 格式并存的現象。根據作者名是否完整可以將數據集分成LNFN 數據集與LNFI 數據集,即可以從LNFN 數據集中直接剔除縮寫一致但全拼不一致的數據。為避免不同拼寫形式導致的誤刪,本研究保留了先姓后名、先名后姓以及包含常用連字符的拼寫變體。經預處理后,原始文獻數據集被一拆為三:第一部分,姓名全拼和目標作者姓名相同的數據集Dfull,用于消歧的第一階段以保證精確率,并在第二階段進行二次判斷;第二部分,僅提供了姓名縮寫的數據集Dabbr,用于第二階段以提高召回率;第三部分,姓名全拼和目標作者姓名不一致的數據集Ddiff,可直接剔除。另外,Ddiff可用于識別Dabbr中與Ddiff為同一作者的數據Ddiff_rel,在第二階段中將Ddiff_rel數據也直接剔除。
3.2.2 外源性數據
百度百科是目前最大的中文網絡百科全書,截止到2021 年2 月,已收錄22791094 個詞條[59]。得益于百度百科詞條的質量保障機制,如關鍵信息需要權威參考資料支持,多主體的編輯、審核與完善團隊等[60],詞條內容的可信度較高,可用于獲取擁有一定學術成就的學者的履歷、代表作和研究方向信息。對于百科詞條這一外源性數據的預處理過程為:
(1)收集并解析百科人物詞條數據:為避免姓名歧義問題,在爬取詞條時根據其內容是否同時包含依托單位和所獲榮譽進行篩選。
(2)機構名提取:基于履歷信息提取出學者學習或工作過的機構名稱,目前較為成熟的命名實體識別技術(named entity recognition,NER)可以實現從文本中提取機構名,同時輔以自定義的語料庫以達到更高的精確率。本研究采用百度LAC(lexi‐cal analysis of Chinese)中文詞法分析工具對履歷文本進行機構實體的識別,并采集我國教育部發布的國內外大學名單、丁香醫生網站提供的國內醫院名單生成自定義詞典對模型進行優化。未直接采用字典法匹配的原因在于國外大學名有多種譯法,如加利福尼亞大學又稱“加州大學”,字典法不能一一列舉;此外,各研究中心、實驗室、海外醫院等機構名均難以獲得完整的名單。
(3)機構名翻譯:面向外文文獻數據消歧時,需要將中文履歷中包含的機構名翻譯成英文,鑒于現有翻譯軟件的準確率難以保證,本研究采用從機構的百科詞條中獲取其對應英文名的方式進行中英文轉換。
3.3 “兩步法”消歧模型
3.3.1 特征區分能力
從元數據和外部數據中提取出的特征,其區分不同實體的能力不同。其中,郵箱與代表作本身不存在歧義,前者可以準確歸并同一作者的成果,后者可以識別出目標作者的文獻;合著關系是AND中廣泛使用的特征,有學者[18,36,50,53]直接將具有共同合著者的文獻歸并為同一作者實體;部分研究利用了機構對作者加以區分[29,39,45],履歷的機構信息能夠排除經歷不同的學者,有助于解決人員流動問題,而WoS 提供的地址信息大部分詳細到二級機構及郵編,使得完整地址的相似度以及提取出的郵編也具有較強的消歧作用;資助基金號可以反映同一基金資助的文獻間緊密的關聯,基金名則可以識別出受特定基金資助的文獻,可用于確認作者身份。本研究將上述特征設定為強特征。
考慮到同一研究領域存在同名作者的可能性較高,本研究將與研究方向相關的特征設定為弱特征,包括文獻元數據中的標題、出版物名以及WoS提供的出版物所屬的二級學科類別列表;外源性數據中的學者研究方向,可用于排除不同領域的同名學者。
各特征的區分能力如表4 所示,除郵箱和代表作外,僅依據單一特征難以完全消解歧義。本研究擬根據消歧過程中需解決主要問題的不同,進行強弱特征的合理組合。
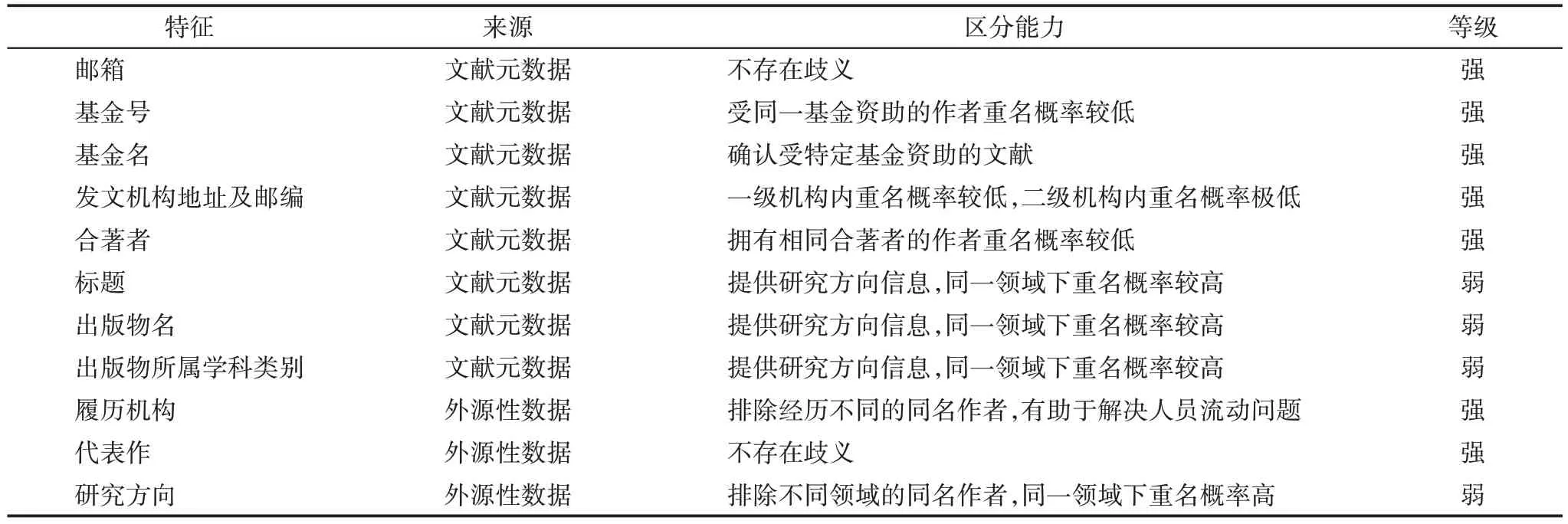
表4 各特征區分不同實體的能力
3.3.2 第一步消歧
1)不同機構間的重名消歧
為排除與目標作者經歷不同的同名作者,本研究采用發文機構與履歷信息中的機構進行匹配。為保證后續處理的準確性,首先基于Dfull進行篩選,以縮小待消歧文獻量。具體匹配過程中,WoS 提供的地址信息對常用詞進行了一定程度的縮寫,如“univ”“coll”“hosp”分別表示“university”“col‐lege”“hospital”。由于數據量龐大,窮舉所有縮寫規則的可行性很低,不過,WoS 提供了部分文獻一級機構的全稱,可用于構建機構英文名全稱和縮寫的映射表。對于存在全稱的數據,進行完全匹配;對于全稱缺失的情況,采用編輯距離大于閾值的條件判斷是否為同一機構。本研究選取了中位數、眾數以及均值等多個閾值進行測試,最終發現將閾值設定為機構名全稱和縮寫映射表中編輯距離的均值(0.783),可以保證第一步所得結果的高精確率。

2)同一機構內的重名消歧
考慮到從履歷中提取的是一級機構,僅能和WoS 地址信息中的一級機構進行匹配,且華人學者中廣泛存在的同音不同字現象提高了重名概率,因而,履歷中包含的幾個機構內的重名問題是消歧需要解決的重點之一。通過郵箱可以準確地識別出同一作者的文獻,不過,作者郵箱也會隨單位變動而發生改變,且當目標不是第一作者或通信作者時數據缺失嚴重。
鑒于上述問題,模型通過強弱特征的組合識別出同一實體,即在合著關系這一強特征基礎上,為避免可能存在的合著者重名的影響,本研究結合地址、基金號和研究方向三個特征進行限制;具體地,擁有相同合著者,并且地址、基金號或研究方向三者其一相同的文獻歸并為同一作者實體的成果。


3)消歧結果優化
經過上述兩步的處理,每個作者的全拼數據集可以劃分出多個不同的同名作者實體文獻集。在此基礎上,需要從中識別出目標作者實體,可用于判斷的條件包括:①文獻集是否包含了從百科詞條中收集到的該學者成果題名;②文獻基金信息中是否含有標注了所獲榮譽名的文獻;③在上述特征缺失的情況下,基于同一機構中存在相同研究方向的同名作者的概率極低這一消歧研究中常見的假設[28,54,61],模型根據文獻內容特征與研究方向信息進行判斷,具體采用文獻的題名、出版物名和出版物所屬學科類別與外部數據中目標作者的研究方向信息進行文本余弦相似度的計算,其相似度之和最高的文獻集合則為目標作者所著,得到的初步消歧結果記為Dconfirm。

3.3.3 第二步消歧
1)召回數據集
為提高模型召回率,消歧模型的第二階段根據已識別出的文獻集Dconfirm及相關特征數據在Dabbr中進行篩選與增補,同時,鑒于履歷信息存在更新不及時、機構識別和翻譯的遺漏和錯誤等,未通過履歷篩選的Dfull同樣需要二次判斷。為了壓縮Dabbr的規模,本研究首先在Dabbr中剔除與Ddiff存在相同郵箱或基金號的數據Ddiff_rel。

最終待消歧數據Dremain范圍包括Dfull-Dconfirm以及Dabbr-Ddiff_rel兩個部分。
2)召回算法
首先,依據已識別數據Dconfirm的作者郵箱在Dremain中快速召回同一作者的文獻,并匯總入Dcon‐firm。考慮到在縮寫數據中,合著者與同名實體合作的概率增加,本研究僅采用標注了目標作者的郵箱信息作為判據。
其次,對于郵箱特征缺失的數據,本研究依據已識別數據Dconfirm采用更多特征組合判斷Dremain剩余文獻的歸屬。使用的強特征包括是否有共同合著者、基金號、完整地址的相似性,以及發文機構是否為履歷中的機構等;弱特征涉及出版物名及其所屬學科領域是否相同,以及標題、出版物及所屬領域和外源性數據中的研究方向是否相似等。
最后,鑒于大規模數據中華人學者的外文名存在更高的重名風險以及完整地址和基金號等特征的不同程度缺失,為避免存疑單個特征造成的誤檢漏檢,本研究發現將滿足任意兩個強特征或一強一弱特征作為判斷條件,既沒有降低精確率,同時也提高了召回率。


最終,目標作者的消歧文獻集合為Dcomplete。
4 實驗與結果
4.1 實驗數據
本研究采用杰青數據驗證兩步法模型的有效性。依據1997—2019 年4107 位杰青的姓名,采集了WoS 數據庫收錄的文獻題錄共計5017168 條,其中僅提供縮寫作者名(Dabbr)的數據占27%,提供姓名全拼(LNFN)的數據集中,與目標杰青姓名一致的數據(Dfull)占23%,不一致的數據(Ddiff)占50%。除作者列表、標題、出版物名外,各特征的缺失比例不同,在Dabbr中缺失最為嚴重(圖2)。
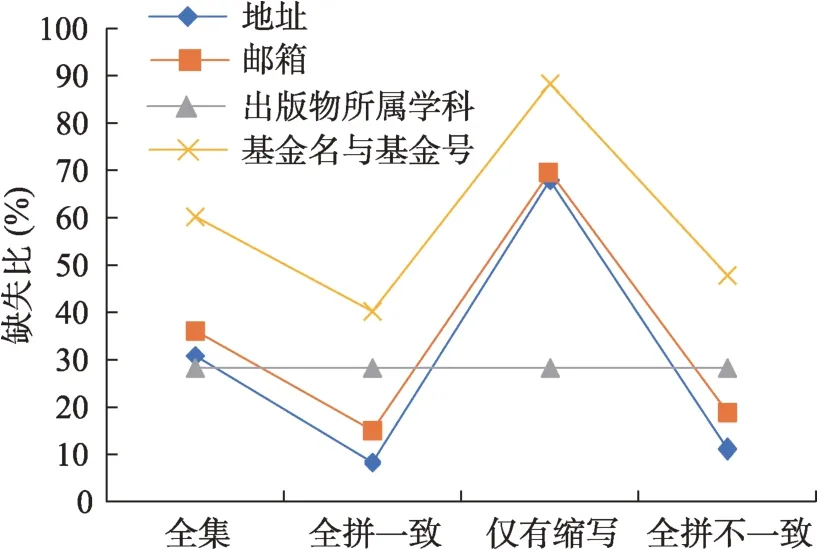
圖2 不同數據集中各特征的缺失情況
4.2 模型評估
本節將對消歧模型中的主要步驟逐步進行評估,并根據結果不斷調整模型以實現最優。
(1)依據履歷機構縮小消歧范圍。根據學者工作或學習過的機構信息進行初篩后,篩選結果中少量學者的文獻量極低,甚至為零,其主要原因在于:①中文姓名存在多音字以及非常規筆名的情況,如“單”“仇”“伯”“樂”等字的讀音以及“Rau, P. L. P.”“Chan, R. C. K”“W Hsu”等個性化的筆名,在WoS 中使用姓名檢索文獻時未將上述問題考慮在內,導致39 人的姓名和機構無法匹配;②共有7 名學者的數據中提供姓名全拼的文獻小于5 篇;③部分機構的簡寫和全稱差距過大或有多種英譯名,例如,“中國人民解放軍總醫院”中的People's Liberation Army,其簡寫為“PLA”,“中國氣象科學研究院”既有“Chinese Academy of Meteo‐rological Sciences”,也有“China Meteorological Ad‐ministration”。對此,更新履歷機構信息和全稱簡寫映射表,重新進行機構篩選,最終待消歧文獻量從人均2635 篇降至132 篇左右(圖3)。
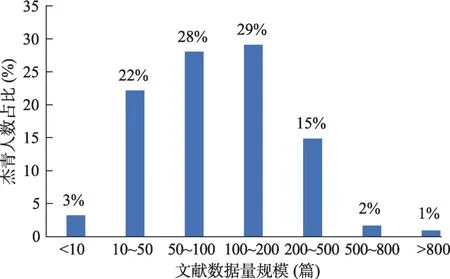
圖3 履歷機構篩選后的待消歧文獻量
(2) 同機構內不同實體的劃分及目標實體識別。采用郵箱、基金號以及合著關系輔以研究方向的判斷條件可以較為準確地劃分同名的不同實體。這一過程中,有73%的杰青其確認的文獻量約占機構篩選后文獻量的70%。
(3)基于初步篩選結果進一步增補。鑒于初步篩選后的數據較為準確,提供的目標作者的郵箱可以準確快速地補充遺漏文獻,為后續過程提供更多可依據的信息;不過郵箱特征缺失嚴重,對提高召回率的貢獻有限,因而采用多特征組合條件對剩余數據進行再次補充。本研究針對的是高層次科研人才,這類學者為科研事業做出了較大的貢獻,通常學術成果豐碩;本研究結果統計可得,90%的杰青成果數大于30 篇,54%的杰青成果數超過100 篇。需要指出的是,3 個強特征均缺失,即僅有一個作者且無機構和基金信息的5 萬余條文獻數據無法判斷其所屬的作者實體。
(4)性能評估。Caron 等[57]提出的消歧模型在Tekles 等[62]的AND 比較實驗中表現最優,本研究將其作為基線方法(簡稱為Caron 法),以驗證本研究模型的消歧性能。除了表4(兩步法,表4 特征集)列出的特征外,Caron 法還采用了引用關系特征,故本研究將引用關系特征補充至表4 作為兩步法的另一種實現(兩步法,表4 特征集+引用關系特征),具體做法借鑒Caron 的權重思想,將自引、4篇(含)以上的引文耦合和共被引設置為強特征,4 篇以下的引文耦合和共被引設置為弱特征,本研究將對3 種方法的性能進行比較。
本研究使用精確率(P)、召回率(R)與調和平均值(F1)評價消歧模型的性能,通過隨機選取的10 名杰青的文獻數據進行人工消歧,可得兩步法(表4 特征集)的模型表現,如表5 所示。由表5可以發現,在待消歧規模以及特征缺失程度不同的情況下,第一步消歧的結果均能實現近100%的精確率;第二步消歧過程使召回率也得到了較大幅度的提升,達到了0.883,最終的消歧模型的精確率穩定在0.991,平均F1 值為0.933。
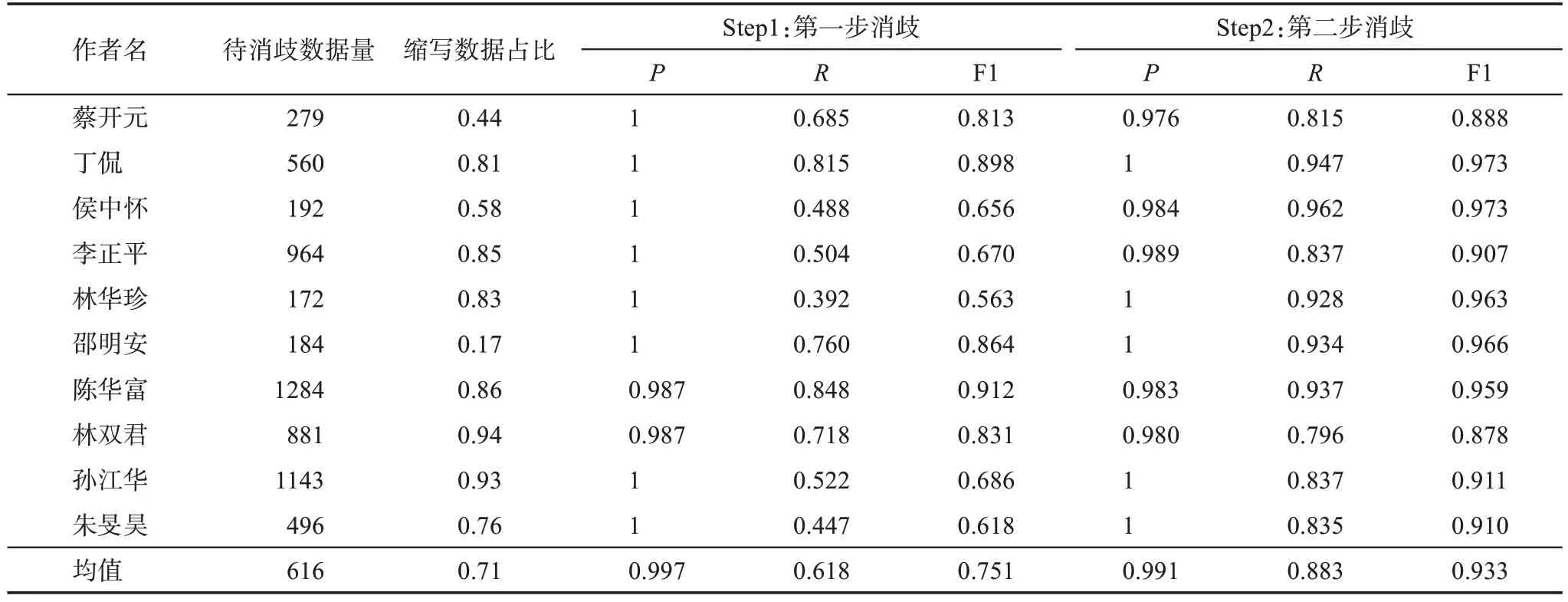
表5 基于規則的兩步法(表4特征集)作者名消歧模型表現結果評估
基線方法與采用兩個不同特征集的兩步法實驗結果如表6 所示。總體上,兩步法的F1 值均高于Caron 等[57]的方法。整體而言,兩步法(表4 特征集)與Caron 法的召回率差異甚微,從兩者采用的特征來看,前者采用了作者履歷特征,后者采用了引用關系特征,其他基本相同;而當兩步法同時采用了履歷特征+引用關系特征后,其召回率已明顯優于Caron 法。該結果表明,兩步法采用作者履歷信息+引用關系特征與其他特征結合的方式提高了對跨學科研究、單位變動等作者的識別能力。從精確率來看,Caron 法的表現不夠穩定,比如,最低的P值僅為0.335,其原因在于低引文耦合與其他弱特征匹配的得分高于閾值會使非目標作者文獻被納入。由此可見,特征的消歧能力與閾值同時影響著模型的性能。Tekles 等[62]的研究給出了不同待消歧文獻數量下的最佳閾值,但當文獻量較少即閾值較低,且同時匹配的弱特征較多時,Caron 法無法準確識別同一作者的文獻。而兩步法由于需要弱特征和強特征的同時滿足,且補充了引用關系特征,其精確率較基線方法有很大提升且性能穩定。由表6 可見,兩種兩步法實現的F1 值均優于Caron 法,從而顯示了兩步法在AND 方面的優勢。

表6 基線方法與采用兩個不同特征集的兩步法實驗結果對比
5 討 論
5.1 消歧策略
本研究設計的兩步法消歧模型符合計算機科學“自頂向下,逐步精化”以致問題解決的基本原則。第一步面向精確率的消歧包括基于履歷機構的初步篩選,以及使用多特征限制的合著關系進行實體的劃分。不同于現有研究選取的特征集較小,本研究采用多特征組合的條件判斷降低了同名合著者的干擾,保證了劃分不同同名實體的準確性。不過,難以避免的是過度分裂的問題,例如,難以識別人才流動造成的合著網絡沒有交集的文獻,對此,引用關系特征的引入從一定程度上進行了彌補。
第二步面向召回率的消歧旨在依據高精確度的結果,使用多特征組合找到更多目標作者的文獻,其中若地址信息包含了履歷中的機構并且有共同合著者或相同研究方向,則可判斷為該學者的成果,充分利用了履歷信息。未將這一條件直接應用于第一步的原因在于,劃分不同實體是一個“滾雪球”過程,在網絡中尋找連通分量,若在節點間建立了錯誤的邊,則會導致大量的錯誤數據被導入,進而使后續操作建立于錯誤的基礎之上。相比之下,在最后補充階段使用強弱特征結合的條件提高了模型的召回率,同時避免了因極少量數據的誤判而引起錯誤的連鎖反應。另外,強弱特征的結合是模型的另一個特點,同名的不同實體多個弱特征相似易帶來錯誤的結果,該問題可以通過提高閾值來解決,不過,在歧義程度不同的情況下閾值如何設定仍需進一步研究。
5.2 模型優勢
近年來,學界圍繞AND 仍在持續不斷地改進原有方法或提出新思路,通過對前人研究成果的梳理發現,研究改進主要集中于特征表示方法和機器學習模型。諸多學者采用了網絡表示學習方法[36-43]將合著網絡、引文網絡或者文本相似度網絡中的特征表示從高維轉變為低維向量以便于計算,不過該類方法對AND 性能的提升作用并不明顯,模型精確率最高僅0.8 左右。鑒于這類方法尚不成熟,本研究采用多特征融合的方式避免了單特征本身存在的歧義問題,并利用基于規則的策略保證了模型的精確率和效率。
另外,機器學習模型在AND 中應用廣泛,有監督的分類算法通過對訓練數據的學習,避免了人為地、依靠經驗確定不同特征權重的不足,能夠達到較高的精確率。不過,模型性能很大程度上依賴于學習數據的質量,在缺乏來自各學科的學者成果黃金標準數據集(golden standard dataset) 的情況下,現有研究的標注數據多源于ORCID、谷歌學術主頁等外部數據或人工標注的少量數據,這些收集方法存在數據缺失以及耗時費力等缺點,且訓練數據還存在分布不均的問題,如負例數據量常遠大于正例,其結果只是增加了計算量卻沒有顯著提升消歧性能[44]。不依靠訓練數據的無監督聚類算法更為常用,部分學者對于如何確定聚類數或停止聚類的閾值條件這一難點做出了有價值的探索,但F1 值僅0.7 左右[7,26],在大量常用名和同音名的華人學者外文文獻數據集中,估計同名的不同實體數難度更大。此外,聚類算法的時間復雜度高,不斷增長的文獻數據對計算性能提出了越來越高的要求。面向高精確率和高召回率的消歧需求,機器學習模型仍難以達到實用的要求。本研究針對高層次科研人才這一已知身份的作者名進行消歧,避免了聚類算法中確定聚類數的難點,且采用基于規則的方法能夠大幅度提高處理速度。基于兩步法的多特征融合的規則模型更重要的優勢體現在,在部分特征缺失的情況下可根據不同的特征組合進行判斷,避免了機器學習模型學習不充分導致的欠擬合問題。
5.3 履歷數據的收集與處理
履歷數據在現有AND 研究中受到的關注較少,在面向所有層次科研人才的消歧研究中,全面收集學者履歷信息的可行性較低,也有研究[63]僅對某一機構內的學者進行消歧,均未能發揮履歷信息降低待消歧數據規模和識別機構變動的作用。有研究[14,64]通過人工收集學者的履歷信息,保障了信息的完整性和準確性,但規模非常有限且不易于推廣應用。針對高層次科研人才這一研究價值更高的群體,履歷信息更易于獲得,比如,以本研究的實驗數據為例,90%的杰青都可以從百度百科詞條中獲取教育或工作經歷信息。需要指出的是,百科人物詞條存在著更新不及時、信息不全面的問題,數據質量相比于問卷調查和學者主頁較差,不過后者大規模收集的可行性低,而易于爬取、結構相近且便于信息抽取的百科詞條是更為完善的解決方案。
另外,NER 技術的限制和翻譯不準確的問題造成了部分機構信息的丟失,例如。“Bascom Palmer眼科研究所”“John Innes 研究中心”等詞典法難以列舉出的機構和中英文混雜的寫法,對NER 識別的準確率有細微的影響;外文文獻的消歧需要將中文機構名進行翻譯,中譯英的多種形式也使得匹配過程中存在誤差。本研究主要通過郵箱、合著者、基金號和研究方向等多特征組合進行判斷,以彌補履歷信息缺失造成的遺漏。
6 結 論
本研究針對高層次科研人才,在已知學者履歷和研究方向的前提下,建立了一個基于規則的“兩步法”消歧模型;兩組不同特征集的實驗顯示,模型的F1 值分別達到了0.93 和0.95,較現有研究有較大提升。鑒于百度百科數據易于獲取,模型的推廣和易用性也體現了一定的優勢,為研究高層次科研人才所需的消歧數據提供了可操作性和準確性兼具的解決方案。
需要指出的是,本研究以杰青作為研究案例,僅僅是因為杰青等高層次科研人才的辨識度比較高,能夠方便地從百度百科等途徑獲得其履歷等相關信息而已;就原理而言,本研究的模型可以推廣到所有類型科技人才的消歧研究與實踐,待他日其他類型科技人才的履歷便于獲得后即可使用本研究的模型。
另外,本研究也存在一些有待改進之處,包括NER 技術的查全查準率、中譯英的翻譯準確性、摘要關鍵詞等可以更準確提供研究方向的特征缺失等,對面向所有學者消歧研究的借鑒價值尚需進一步探索,AND 任務的全面解決仍需要科研人員、管理部門以及文獻數據庫的共同努力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
